【表面缺陷检测】常用开源表面缺陷检测数据集 整理
数据集是深度学习研究的基础,开源数据集为各种方法提供了比较的基准(benchmark)。
不同于经典计算机视觉任务中的 ImageNet、PASCAL VOC2007/2012 和 COCO 等数据集,表面缺陷检测并没有一个统一的,大规模的数据集,不同的缺陷检测数据集,在 样本数量,正负样本比例,复杂度 等方面都有很大的不同。
不同的缺陷数据集往往适用于不同的方法。
不同的检测设定下的研究往往基于不同的缺陷数据集。
这里对一些 常用的开源表面缺陷检测数据集 进行了整理汇总。
1、NEU surface defect database
热轧带钢(钢材)表面缺陷 东北大学
项目官网【之前的链接挂掉了,这是 新的地址】
数据集介绍:
该数据集收集了 热轧带钢表面的6类典型缺陷:
- (rolled-in scale, RS)
- 斑块(patches, Pa)
- 开裂(crazing, Cr)
- 点蚀(pitted surface, PS)
- 包含(inclusion, In)
- 划痕(scratches, Sc)。
每种类型缺陷各 300 个样本,总共 1800 张灰度图像,每张图像的 原始分辨率 为 200×200 像素。对于缺陷检测任务,作者还 提供了 bounding box 标注,注明了每个图像中缺陷的类别和位置。
下图展示了六种缺陷的样本图像。
从图中可以清楚地看出,类内(intra-class)缺陷在外观上存在较大的差异,比如划痕(最后一列)可能是水平划痕、垂直划痕、倾斜划痕等。同时,类间(inter-class)缺陷也存在相似之处,如 rolled-in scale, crazing(龟裂), and pitted surface(凹凸不平)等。
此外,由于光照和具体材质的影响,类内(intra-class)缺陷图像的灰度值也会发生变化
总而言之,NEU表面缺陷数据库包括两个challenge:
- 类内缺陷存在较大的外观差异,类间缺陷具有相似的方面
- 缺陷图像受到光照和具体材质变化的影响。
下图展示了在NEW-DET上的一些检测结果示例。

2、KolektorSDD (Kolektor Surface-Defect Dataset)
电子换向器(金属)表面缺陷
项目官网

数据集介绍:
该数据集收集了电子换向器的缺陷图像。具体地,在电子换向器的塑料包埋表面上,存在微小的破损或裂缝。
图像是在受控条件下【光照均匀等】采集的。
为缺陷图像提供了缺陷的像素级标注。
该数据集包括对50个缺陷电子换向器的每个换向器表面采集8张不重叠的图像,得到共399张图像,其中包括:
- 52张缺陷图像
- 347张无缺陷图像
3、Magnetic-tiledefect-datasets (MT Defect Dataset)
磁瓦表面缺陷 中科院自动化所
官方github
数据集介绍:
该数据集总共包含 1344张图像,对磁瓦的感兴趣区域 (ROI) 进行了裁剪【每张图片有不同的尺寸】。共包含6类图片 (5类缺陷+1类正常):
- 气孔 (blowhole)
- 裂纹 (crack)
- 磨损 (fray)
- 断裂 (break)
- 凹凸不平 (uneven)
- 无缺陷
每张图像都做了pixel-level标注。
为了模拟真实的装配线上的制造过程,对一个给定的磁瓦,在多种光照条件下进行图像的采集。【除此之外,缺陷形状的多样性,纹理的复杂性等因素,都给检测带来了很大的挑战】

气孔和裂纹对磁瓦质量的影响最大,气孔和裂纹两种缺陷之间有许多共同的特征,比如它们的颜色比周围的环境深。
凹凸不平是最难检测的,因为它的颜色和纹理与背景高度匹配。
磨损的颜色和纹理与深色表面污垢相似。然而,污垢并不影响磁砖的功能【磨损是异常,污垢不是异常】。
4、RSDDs dataset
钢轨表面缺陷
项目官网
RSDDs数据集包含两个子数据集:
- 一种是Type-I RSDDs数据集,采集自express rails,包括67张图像(160×1000)。
- 另一种是Type-II RSDDs数据集,采集自common/heavy haul rails,包括128张图像(55×1250)。
两个数据集的每张图像至少包含一个缺陷,并且具有复杂的背景和大量的噪声。
数据集中的缺陷由轨道表面检测领域的一些专业人员进行了标注。
一些典型的图像如下图所示


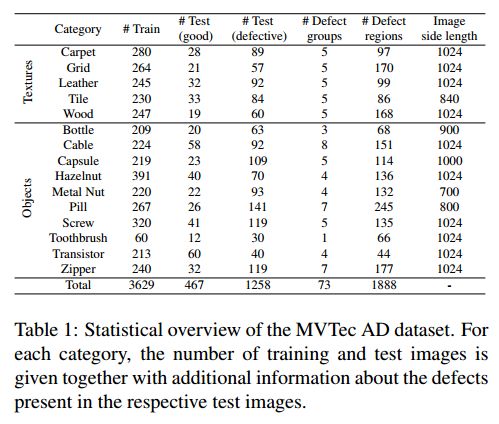
5、MVTec Anomaly Detection (MVTec AD)
真实世界异常分割数据集
项目官网;数据集论文
该数据集包含 15 个不同物件和纹理类别 的 总共 5354 张 高分辨率 彩色 图像。其中,3629 张图像用于训练和验证,1725 张图像用于测试(训练集只包含无缺陷图像,测试集包括缺陷图像和无缺陷图像)。
15 个类别中,5 个纹理类别 涵盖了不同类型的 规则纹理(如地毯,网格) 和 随机纹理(如皮革,瓷砖,木材)。
剩余的 10 个物件类别中,有的是 具有固定外观的刚性物件(比如瓶子、金属螺母),而有些是 非刚性可形变的物件(比如电缆),有的则 包含自然的多样性(比如榛子)。
一部分物体以 大致对齐的姿态(如牙刷、胶囊和药丸) 被拍摄,而其他物体则以 随机角度的方式(如金属螺母、螺钉和榛子) 被拍摄。
检测图像中的异常样本包含 多种缺陷,如 表面缺陷(例如,划痕、凹痕),结构缺陷,如变形的实物部件,或 因缺少某些部分而表现出来的缺陷。总共有 73种不同的缺陷类型,平均每个类别有5种。
缺陷都是 手工生成的,目的是为了产生 真实的工业检测场景会出现的 真实的 异常。
所有的图像 分辨率都在700×700和1024×1024像素之间。
此外,该数据集 为所有异常提供了像素级精度的ground truth注释。


6、DAGM 2007
纹理表面缺陷
项目官网
该数据集是 由人工生成的 纹理背景下的缺陷,和真实世界的图像非常接近。
该数据集包含了多个类别的表面缺陷,每张图像的分辨率为 512×512。提供了粗略的缺陷标注【用 椭圆 对缺陷区域进行粗糙的覆盖】。
数据集描述
The data is artificially generated, but similar to real world problems. The first six out of ten datasets, denoted as development datasets, are supposed to be used for algorithm development. The remaining four datasets, which are referred to as competition datasets, can be used to evaluate the performance. Researchers should consider not using or analyzing the competition datasets before the development is completed as a code of honour.
In the following we provide some details about the datasets:
- Each development (competition) dataset consists of 1000 (2000) ‘non-defective’ and of 150 (300) ‘defective’ images saved in grayscale 8-bit PNG format.
- Each dataset is generated by a different texture model and defect model.
- ‘Non-defective’ images show the background texture without defects, ‘defective’ images have exactly one labelled defect on the background texture.
- All datasets has been randomly split into a training and testing sub-dataset of equal size.
- Weak labels are provided as ellipses roughly indicating the defective area. Technically, defective images are augmented with a separate grayscale 8-bit image in the PNG format located in a folder ‘Label’. The values 0 and 255 denote background and defective area, respectively.
All meta-data is subsumed in a separate ASCII textfile called ‘Labels.txt’ which is located in the ‘Label’ folder. The structure is as follows:
1 \n
[id of item no. 1] \t [0 if non-defective, 1 if defective] \t [filename of raw image no. 1] \t 0 \t [filename of label image no. 1 if defective, 0 otherwise] \n
…
[id of item no. N] \t [0 if non-defective, 1 if defective] \t [filename of raw image no. N] \t 0 \t [filename of label image no. N if defective, 0 otherwise] \n
The following figure illustrates one defective image from each of the ten datasets.

7、AITEX
织物数据集
项目官网;数据集论文
该数据集包含了 7种不同的织物,共245张图像,每张图像的 分辨率为4096x256。
数据集中的面料以素色为主。其中有 140张没有瑕疵的图片,每种面料有20张。缺陷图片共有105张,包含了纺织行业常见的织物缺陷类型(共有12种缺陷)。
为所有缺陷提供了像素级标注,以白色像素表示缺陷区域,其余像素为黑色。
