【目标检测】yolo系列:从yolov1到yolov5之YOLOv5训练自己数据集(v6.0)
一、源码下载及requirments
源码下载地址:https://github.com/ultralytics/yolov5 (持续更新中)
本人所用环境如下:
pytorch:1.8(因为cuda版本用了pytorch1.8)
cuda:10.1
Python:3.8
官方要求:Python>=3.6.0 并且PyTorch>=1.7,并通过pip安装requirements.txte文件。
$ git clone https://github.com/ultralytics/yolov5
$ cd yolov5
$ pip install -r requirements.txt
二、准备自己的数据集
因为学长已经将数据集和标注好的txt文件直接发给了我,所以如何标注数据集这里就不详细介绍了。
总之就是要把你的图像数据转换成yolo.txt文件的形式,就是把将每个xml标注提取bbox信息为txt格式,文件的每一行作为一个目标的信息,从左到右依次是(class, X_center, Y_center, width, height)。

参考如下:https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data#2-create-labels
在yolov5目录下创建Adata文件夹(名字可以自定义),要注意的是yolov5曾经的版本和最新的不同,最新版本目录结构要求如下,将之前标注好的txt文件和图片划分为训练集和验证集后放到对应目录下:
- Adata
- images # 存放图片
- train # 存放训练集图片
- val #存放验证集图片
- labels # 存放图片对应的yolo_txt文件
- train # 存放训练集标注好的文件
- val #存放验证集标注好的文件
- images # 存放图片
trainval = random.sample(list_index, num * trainval_percent)
三、配置文件
yolov5是个集成好的目标检测框架,根据自己整理好的数据集来修改其中配置。
1. 数据集的配置
在yolov5目录下的data文件夹下新建一个c.yaml文件(可以自定义命名),用来存放训练集和验证集的划分文件(train和val文件夹的路径),这两个文件夹就是通过我们上述标注和划分得到的,然后是目标的类别数目nc和具体类别名列表names,c.yaml内容如下(可以参考官方数据集data/coco128.yaml的格式):
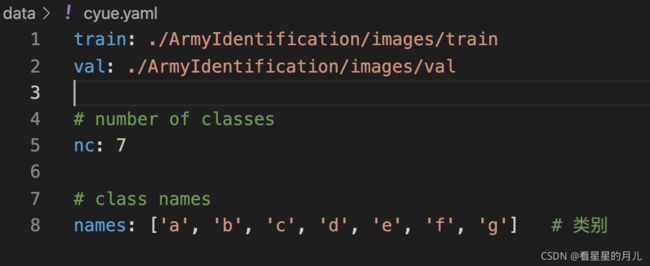
2. 预训练模型的配置
预训练模型主要是先验框和权重文件的配置。
最新版的yolov5会自动使用kmeans算出anchors的取值。如果想要自己生成先验框可使用kmeans算法聚类生成新anchors。
选择一个你需要的模型,在yolov5目录的model文件夹下是模型的配置文件,v6.0版本为我们提供n、s、m、l、x五个版本,模型架构的增大,模型也更为复杂,训练时间也会增大。我这里采用了yolov5m.yaml,只用修改nc为自己的类别数。
如果anchors是重新生成的,也需要修改,根据anchors.txt 中的 Best Anchors 修改。
如下面一个例子:

上图中的参数解释如下:
- nc:类别数目。
- depth_multiple / width_multiple:通过两个参数来进行控制网络的深度和宽度。
- backbone:网络结构定义。
- anchors:yolov5中默认保存了一些针对官方coco数据集的预设锚定框,在 yolov5 的配置文件*.yaml 中已经预设了640×640图像大小下锚定框的尺寸,但yolov5 中不是只使用默认锚定框,在开始训练之前会对数据集中标注信息进行核查,计算此数据集标注信息针对默认锚定框的最佳召回率,当最佳召回率大于或等于0.98,则不需要更新锚定框;如果最佳召回率小于0.98,则需要重新进行K-means聚类计算得到符合此数据集的锚定框anchors。
anchors参数共有三行,每行9个数值,且每一行代表应用不同的特征图:第一行是在最大的特征图上的锚框;第二行是在中间的特征图上的锚框;第三行是在最小的特征图上的锚框。
在目标检测任务中,一般希望在大的特征图上去检测小目标,因为大特征图才含有更多小目标信息,因此大特征图上的anchor数值通常设置为小数值,而小特征图上数值设置为大数值检测大的目标。
至此,配置已经定义完成,然后就是训练模型。
三、训练模型
3.1 模型训练
在train.py中进行如下几个参数的修改:
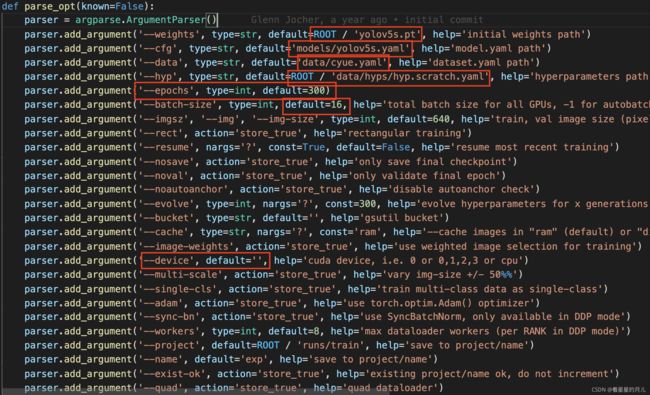
部分以上参数解释如下:
- weights:加载的权重文件的路径(预训练模型的权重文件会在训练前自动下载并加载)
- cfg:模型配置文件,backbone网络结构等内容
顺便说一句,我看了一下yolo.py的源码,发现yolov5是把配置模型文件加载进去,然后解析模型的网络结构并构建。(也就是说你可以自己定义backbone,当然如果你有能力你的性能超过它!!!哈哈哈) - data:数据集配置文件的路径
- hyp:超参数文件的路径(后面调参可能会用)
- epochs:训练总轮次(默认300)
- batch-size:批次大小(看你自己电脑运行能力)
- evolve:是否进行超参数进化,默认False
- device:训练的设备,cpu;0(表示一个gpu设备cuda:0);0,1,2,3(多个gpu设备)
主要用到的参数如上。然后去进行训练。
#前台运行
python train.py --device '0' # 0号GPU
# 如果上述参数的default都已经输入可以不用带--后缀参数
#后台运行
nohup python -u train.py > log_t.txt 2>&1
根据自己的硬件配置修改参数,训练好的模型会被保存在yolov5目录下的runs/exp/weights/last.pt和best.pt,(多次训练会保存为exp2.3.4等形式),详细训练数据和结果图会保存在runs/exp/文件中,包括confusion_matrix(混合矩阵)、f1-score、设置的超参数等等,可以详细看看来判断模型的表现。
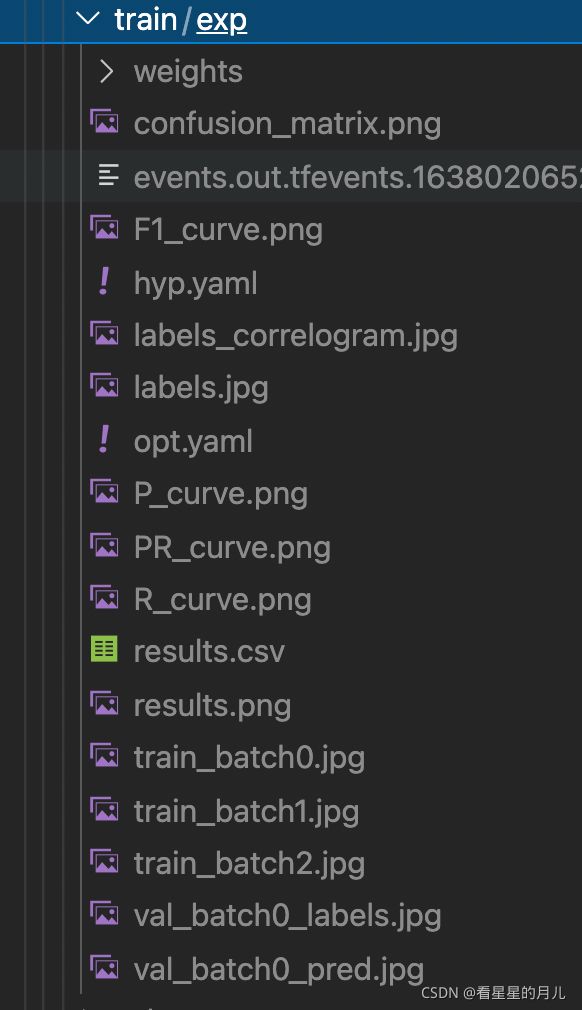
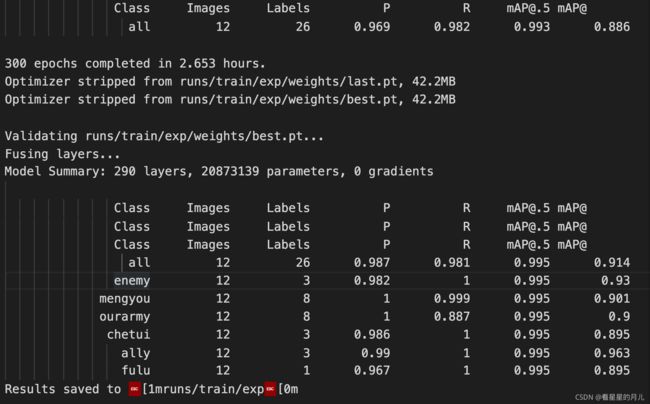
我通过查看log文件发现,yolov5最新版会在训练的最后自动进行验证,所以可以直接通过验证后的模型表现来进行相应的调参。
log文件如下:
3.3 训练可视化
利用tensorboard可视化训练过程,执行下列命令,可以打开tensorboard的相关网站查看即时的训练日志。(图忘截屏了,大家打开之后可以自己体会哈,有各种指标的变化,包含精度率,召回率,mAP等)
tensorboard --logdir=runs
四、模型验证
找到val.py。
评估模型好坏就是在有标注的测试集或者验证集上进行模型效果的评估,在目标检测中最常使用的评估指标为mAP。
在val.py文件中指定数据集配置文件和训练结果模型,将训练生成的最优权重路径导入模型,进行验证,如下所示:
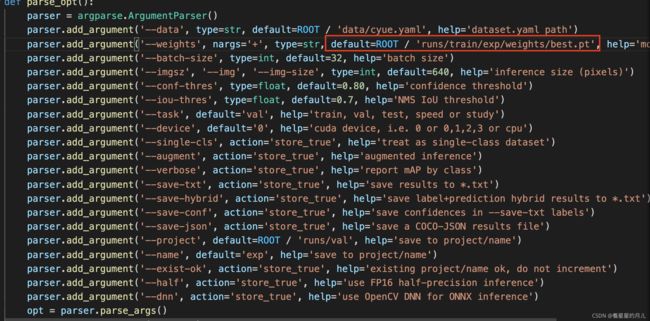
运行代码和训练一样:
#前台运行
python val.py --device '0' # 0号GPU
# 如果上述参数的default都已经输入可以不用带--后缀参数
#后台运行
nohup python -u val.py > log_v.txt 2>&1
调参在data/hyps下的hyp.finetune.yaml或者hyp.scratch.yaml进行超参数调优,可自行选择,hyp.scratch.yaml是针对官方给出的coco数据集最优化的参数。(我这里因为模型在我的数据集上表现的非常好,所以没有进行长时间调参)
五、模型推理
最后,模型在没有标注的数据集上进行推理,在detect.py文件中指定数据图片和模型的路径,其他参数(置信度object confidence threshold、交并比IOU threshold for NMS、save_txt选项用于生成结果的txt标注文件等),如下:
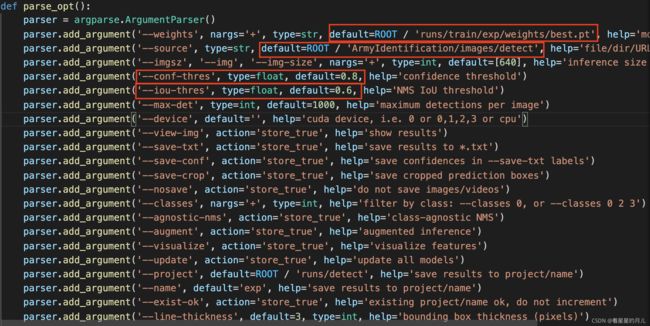
推理完毕后,在runs文件夹下会生成detect文件夹,其中会生成数据集的检测信息以及目标框的置信比。如果不指定save_txt则只会生成结果图像,如果指定了save_txt,每个txt会生成一行一个目标的信息,信息包括(class, xcenter, ycenter, w, h),后面四个为bbox位置,均为归一化数值。
总结
YOLOv5训练自己的数据集整个过程:制作数据集----模型训练----模型验证----模型推理阶段已全部完成。