RepVGG网络中重参化网络结构解读【附代码】
YOLOv7论文中会遇到一个词叫“重参化网络”或者“重参化卷积”,YOLOV7则是用到了这种网络结构,里面参考的论文是“RepVGG: Making VGG-style ConvNets Great Again”。该网络是在预测阶段采用了一种类似于VGG风格的结构,均有3X3卷积层与ReLU激活函数组成,而在训练阶段网络结构类似ResNet具有多分支。训练和推理时候的解耦合是通过结构重参数(re-parameterization)技术实现的,所以叫RepVGG,而这种方法不仅拥有很好的准确率,同时也可以降低计算开销,提升速度。所以本文章也算是进一步理解YOLOV7的补充。
YOLOv7论文部分解读【含自己的理解】_爱吃肉的鹏的博客-CSDN博客
在训练阶段网络结构长这个下面这个样子,作者说到RepVGG有5个stage,下面展示的仅是其中之一,其实这个结构与ResNet很相似,有1X1的Conv,也有一个残差边identity分支,在每个stage开始的阶段,会采用一个stride=2的卷积进行下采样,同时该层仅有1X1卷积,也能看到最上面这一部分是没有identity分支,这个分支仅在in_channels=out_channels且stride=1才有,代码里有体现:

RepVGG training
在正常推理阶段,网络结构又会变成下面的这个样子,与上面的图对比,在推理阶段少了一些分支网络但主体结构是一样的,而这种结构与VGG很相似。但这个分支去哪了呢?是直接删了么?【我刚开始看到这里就是这样人为,因为有其他论文重要做过】
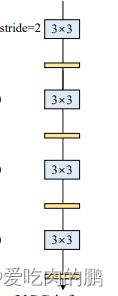
RepVGG inference
其实上面的实现原理也是很简单,方法也很直接,可以使用原始3×3核、identity和1×1分支以及批归一化(BN)层来构造单个3×3核。就是用一个3X3代替原来的3X3 、1X1以及identity。在推理阶段会将卷积层与BN层进行一个融合,identity、1X1卷积分支,可以将其通过padding的方式扩成3X3卷积,最后将三个3X3的卷积相加后形成一个新的3X3卷积即可,这就好像把原来的分支与主干进行了融合,变成了一个卷积层。

先来看一下RepVGG的卷积块代码【也是网络基本组成单元】。
class RepVGGBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size,
stride=1, padding=0, dilation=1, groups=1, padding_mode='zeros', deploy=False, use_se=False):
super(RepVGGBlock, self).__init__()
self.deploy = deploy
self.groups = groups
self.in_channels = in_channels
assert kernel_size == 3
assert padding == 1
padding_11 = padding - kernel_size // 2
self.nonlinearity = nn.ReLU() # 激活函数
if use_se: # 是否使用注意力机制
self.se = SEBlock(out_channels, internal_neurons=out_channels // 16)
else: # 残差边
self.se = nn.Identity()
if deploy:
self.rbr_reparam = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride,
padding=padding, dilation=dilation, groups=groups, bias=True, padding_mode=padding_mode)
else:
self.rbr_identity = nn.BatchNorm2d(num_features=in_channels) if out_channels == in_channels and stride == 1 else None
self.rbr_dense = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding, groups=groups)
self.rbr_1x1 = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride, padding=padding_11, groups=groups)
print('RepVGG Block, identity = ', self.rbr_identity)
def forward(self, inputs):
if hasattr(self, 'rbr_reparam'):
return self.nonlinearity(self.se(self.rbr_reparam(inputs)))
if self.rbr_identity is None: # 是否使用identity,当in_channels ≠ out_channels,且stride!=1 则不使用,实际就是每个stage开始的时候不用
id_out = 0
else:
id_out = self.rbr_identity(inputs)
"""
x-->conv_bn--------add--->ReLu
|_________>1X1______|
|_________>BN_______|
"""
return self.nonlinearity(self.se(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out))从上面代码中也能看出identity使用的先决条件是in_channels与out_channels相等,并且stride=1。可以根据return的返回结果去自己写一下网络结构【我已画出】。为了可以更直观的看一下代码到底和论文中的结构以及我们自己画的结构一不一样,可以直接将这个RepVGGBlock作为一个单元,保存一下结构图看一下。这里我假设的输入shape为【1,32,224,224】,即输入通道32,大小为224X224,同时RepVGGBlock的in_channels和out_channels均等于32,stride=1,padding=1。

可以看到从输入出来后有三个分支,图中那个BN分支就是identity,然后是3X3的主干与1X1的分支。三个分支最终相加后再经过Relu通道维度也未改变,与论文中是一致的。上面的结构就是组成训练阶段的基本网络单元。
在RepVGG官方代码中提供网络融合的函数:repvgg_model_convert()。
def repvgg_model_convert(model:torch.nn.Module, save_path=None, do_copy=True):
if do_copy:
model = copy.deepcopy(model) # 深拷贝
for module in model.modules():
if hasattr(module, 'switch_to_deploy'):
module.switch_to_deploy()
if save_path is not None:
torch.save(model.state_dict(), save_path)
return model参数model:是训练时的网络模型,也就是含有各个分支的。
返回值model:时最终我们要的推理时的结构,即去掉了各个分支。
在代码中可以看到有个module.switch_to_deploy(),这个是调用model中的该属性,这个函数在源码中RepVGGBlock有定义。
以RepVGG_A0为例,打印的网络模型如下,一共有5个stage【从0~4】:
RepVGG(
(stage0): RepVGGBlock(
(nonlinearity): ReLU()
(se): Identity()
(rbr_dense): Sequential(
(conv): Conv2d(3, 48, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(rbr_1x1): Sequential(
(conv): Conv2d(3, 48, kernel_size=(1, 1), stride=(2, 2), bias=False)
(bn): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(stage1): Sequential(
(0): RepVGGBlock(
(nonlinearity): ReLU()
(se): Identity()
(rbr_dense): Sequential(
(conv): Conv2d(48, 48, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(rbr_1x1): Sequential(
(conv): Conv2d(48, 48, kernel_size=(1, 1), stride=(2, 2), bias=False)
(bn): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): RepVGGBlock(
(nonlinearity): ReLU()
(se): Identity()
(rbr_identity): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(rbr_dense): Sequential(
(conv): Conv2d(48, 48, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(rbr_1x1): Sequential(
(conv): Conv2d(48, 48, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(stage2): Sequential(
(0): RepVGGBlock(
(nonlinearity): ReLU()
(se): Identity()
(rbr_dense): Sequential(
(conv): Conv2d(48, 96, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(rbr_1x1): Sequential(
(conv): Conv2d(48, 96, kernel_size=(1, 1), stride=(2, 2), bias=False)
(bn): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): RepVGGBlock(
(nonlinearity): ReLU()
(se): Identity()
(rbr_identity): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(rbr_dense): Sequential(
(conv): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(rbr_1x1): Sequential(
(conv): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(2): RepVGGBlock(
(nonlinearity): ReLU()
(se): Identity()
(rbr_identity): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(rbr_dense): Sequential(
(conv): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(rbr_1x1): Sequential(
(conv): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(3): RepVGGBlock(
(nonlinearity): ReLU()
(se): Identity()
(rbr_identity): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(rbr_dense): Sequential(
(conv): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(rbr_1x1): Sequential(
(conv): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(stage3): Sequential(
(0): RepVGGBlock(
(nonlinearity): ReLU()
(se): Identity()
(rbr_dense): Sequential(
(conv): Conv2d(96, 192, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(rbr_1x1): Sequential(
(conv): Conv2d(96, 192, kernel_size=(1, 1), stride=(2, 2), bias=False)
(bn): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): RepVGGBlock(
(nonlinearity): ReLU()
(se): Identity()
(rbr_identity): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(rbr_dense): Sequential(
(conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(rbr_1x1): Sequential(
(conv): Conv2d(192, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(2): RepVGGBlock(
(nonlinearity): ReLU()
(se): Identity()
(rbr_identity): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(rbr_dense): Sequential(
(conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(rbr_1x1): Sequential(
(conv): Conv2d(192, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(3): RepVGGBlock(
(nonlinearity): ReLU()
(se): Identity()
(rbr_identity): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(rbr_dense): Sequential(
(conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(rbr_1x1): Sequential(
(conv): Conv2d(192, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(4): RepVGGBlock(
(nonlinearity): ReLU()
(se): Identity()
(rbr_identity): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(rbr_dense): Sequential(
(conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(rbr_1x1): Sequential(
(conv): Conv2d(192, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(5): RepVGGBlock(
(nonlinearity): ReLU()
(se): Identity()
(rbr_identity): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(rbr_dense): Sequential(
(conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(rbr_1x1): Sequential(
(conv): Conv2d(192, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(6): RepVGGBlock(
(nonlinearity): ReLU()
(se): Identity()
(rbr_identity): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(rbr_dense): Sequential(
(conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(rbr_1x1): Sequential(
(conv): Conv2d(192, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(7): RepVGGBlock(
(nonlinearity): ReLU()
(se): Identity()
(rbr_identity): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(rbr_dense): Sequential(
(conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(rbr_1x1): Sequential(
(conv): Conv2d(192, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(8): RepVGGBlock(
(nonlinearity): ReLU()
(se): Identity()
(rbr_identity): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(rbr_dense): Sequential(
(conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(rbr_1x1): Sequential(
(conv): Conv2d(192, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(9): RepVGGBlock(
(nonlinearity): ReLU()
(se): Identity()
(rbr_identity): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(rbr_dense): Sequential(
(conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(rbr_1x1): Sequential(
(conv): Conv2d(192, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(10): RepVGGBlock(
(nonlinearity): ReLU()
(se): Identity()
(rbr_identity): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(rbr_dense): Sequential(
(conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(rbr_1x1): Sequential(
(conv): Conv2d(192, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(11): RepVGGBlock(
(nonlinearity): ReLU()
(se): Identity()
(rbr_identity): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(rbr_dense): Sequential(
(conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(rbr_1x1): Sequential(
(conv): Conv2d(192, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(12): RepVGGBlock(
(nonlinearity): ReLU()
(se): Identity()
(rbr_identity): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(rbr_dense): Sequential(
(conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(rbr_1x1): Sequential(
(conv): Conv2d(192, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(13): RepVGGBlock(
(nonlinearity): ReLU()
(se): Identity()
(rbr_identity): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(rbr_dense): Sequential(
(conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(rbr_1x1): Sequential(
(conv): Conv2d(192, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(stage4): Sequential(
(0): RepVGGBlock(
(nonlinearity): ReLU()
(se): Identity()
(rbr_dense): Sequential(
(conv): Conv2d(192, 1280, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(1280, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(rbr_1x1): Sequential(
(conv): Conv2d(192, 1280, kernel_size=(1, 1), stride=(2, 2), bias=False)
(bn): BatchNorm2d(1280, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(gap): AdaptiveAvgPool2d(output_size=1)
(linear): Linear(in_features=1280, out_features=1000, bias=True)
)在repvgg_model_convert()函数的for循环中,对上述打印的模型进行遍历,刚开始循环可以获得module为:
RepVGGBlock(
(nonlinearity): ReLU()
(se): Identity()
(rbr_dense): Sequential(
(conv): Conv2d(3, 48, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(rbr_1x1): Sequential(
(conv): Conv2d(3, 48, kernel_size=(1, 1), stride=(2, 2), bias=False)
(bn): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)由于上述的Block类中有switch_to_deploy(),调用该模块的该函数,然后进入switch_to_deploy()中:
def switch_to_deploy(self):
if hasattr(self, 'rbr_reparam'):
return
kernel, bias = self.get_equivalent_kernel_bias()
self.rbr_reparam = nn.Conv2d(in_channels=self.rbr_dense.conv.in_channels, out_channels=self.rbr_dense.conv.out_channels,
kernel_size=self.rbr_dense.conv.kernel_size, stride=self.rbr_dense.conv.stride,
padding=self.rbr_dense.conv.padding, dilation=self.rbr_dense.conv.dilation, groups=self.rbr_dense.conv.groups, bias=True)
self.rbr_reparam.weight.data = kernel
self.rbr_reparam.bias.data = bias
for para in self.parameters():
para.detach_()
self.__delattr__('rbr_dense')
self.__delattr__('rbr_1x1')
if hasattr(self, 'rbr_identity'):
self.__delattr__('rbr_identity')
if hasattr(self, 'id_tensor'):
self.__delattr__('id_tensor')
self.deploy = True首先先判断有没有‘rbr_reparam’属性。【在对stage0的循环中没有该属性】,再进入get_equivalent_kernel_bias()函数,这里又会进入另一个函数fuse_bn_tensor【进行卷积层的融合】:
def get_equivalent_kernel_bias(self):
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense) # rbr_dense为主干3*3卷积
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1) # rbr_1x1为 1X1卷积
kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid def _fuse_bn_tensor(self, branch):
if branch is None:
return 0, 0
if isinstance(branch, nn.Sequential):
kernel = branch.conv.weight # 获得卷积权值
running_mean = branch.bn.running_mean # 获得BN层均值
running_var = branch.bn.running_var # 获得BN层方差
gamma = branch.bn.weight # 获得BN层权值
beta = branch.bn.bias # 获得BN层偏置值
eps = branch.bn.eps
else:
assert isinstance(branch, nn.BatchNorm2d)
if not hasattr(self, 'id_tensor'):
input_dim = self.in_channels // self.groups
kernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32)
for i in range(self.in_channels):
kernel_value[i, i % input_dim, 1, 1] = 1
self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std此时,上述代码中的branch是3X3的卷积层和BN层。通过断点运行也可以看出:

由于branch不为None,因此代码可以进行执行,分别获得卷积层和BN层的各自的权值。最后分别也对1X1卷积进行卷积和BN层的融合。然后对1X1卷积进行padding后与3X3卷积相加。
接着是在switch_to_deploy中的定义rbr_reparam,这是一个卷积,这个卷积的输入通道数为3X3卷积的输入通道数,输出通道数为3X3卷积的输出通道数,卷积核大小为3X3卷积核大小,步长、padding等均与原3X3卷积一样。【该卷积层是用来后面接受融合后的卷积参数的】
由于我们前面利用get_equivalent_kernel_bias()函数得到了融合后的权重和偏置值,因此可以将这些融合后参数传入我们前面定义的新卷积内:
self.rbr_reparam.weight.data = kernel
self.rbr_reparam.bias.data = bias然后对参数仅进行前向传播,阻断反向传播,并删除原模型中的分支,仅保留了我们定义的新卷积rbr_reparam。并将deploy置为True【刚开始为False】,置为True以后就用rbr_reparam这个新卷积代替原来的卷积分支了。
for para in self.parameters():
para.detach_()
self.__delattr__('rbr_dense')
self.__delattr__('rbr_1x1')
if hasattr(self, 'rbr_identity'):
self.__delattr__('rbr_identity')
if hasattr(self, 'id_tensor'):
self.__delattr__('id_tensor')
self.deploy = True可以看到stage0中的卷积结构已经发生了改变,变成了conv(3,48,3,2,1)

经过上述步骤不断的遍历,对卷积层进行融合,形成新的网络结构,最终结构如下,可以看到这里已经没有了原来训练时结构的分支。
