数仓4.0(二)------ 业务数据采集平台
目录
一:电商业务简介
1.1 电商业务流程
1.2 电商常识
二:业务数据采集模块
2.1 安装MySQL及配置
2.2 业务数据生成
2.2.1 连接Mysql以及建表
2.2.2 生成业务数据
2.3 安装Sqoop
2.3.1 安装
2.3.2 修改配置文件
2.3.3 拷贝JDBC驱动
2.3.4 验证Sqoop
2.3.5 测试Sqoop是否能够成功连接数据库
2.3.6 Sqoop基本使用
2.4 同步策略
2.4.1 全量同步策略
2.5 业务数据导入HDFS
2.5.1 分析表同步策略
2.5.2 业务数据首日同步脚本
2.5.3 业务数据每日同步脚本
2.5.4 项目经验
三:数据环境准备
3.2 Hive元数据配置到MySQL
3.2.1 拷贝驱动
3.2.2 配置Metastore到MySQL
3.3 启动Hive
3.3.1 初始化元数据库
3.3.2 启动Hive客户端
一:电商业务简介
1.1 电商业务流程
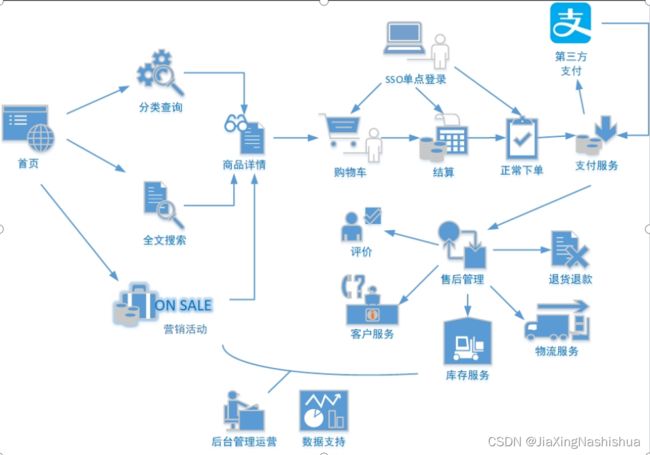
电商的业务流程可以以一个普通用户的浏览足迹为例进行说明,用户点开电商首页开始浏览,可能会通过分类查询也可能通过全文搜索寻找自己中意的商品,这些商品无疑都是存储在后台的管理系统中的。
当用户寻找到自己中意的商品,可能会想要购买,将商品添加到购物车后发现需要登录,登录后对商品进行结算,这时候购物车的管理和商品订单信息的生成都会对业务数据库产生影响,会生成相应的订单数据和支付数据。
订单正式生成之后,还会对订单进行跟踪处理,直到订单全部完成。
电商的主要业务流程包括用户前台浏览商品时的商品详情的管理,用户商品加入购物车进行支付时用户个人中心&支付服务的管理,用户支付完成后订单后台服务的管理,这些流程涉及到了十几个甚至几十个业务数据表,甚至更多。
1.2 电商常识
SKU:
SKU = Stock Keeping Unit(库存量基本单位)。现在已经被引申为产品统一编号的简称,每种产品均对应有唯一的SKU号。
SPU:
SPU(Standard Product Unit):是商品信息聚合的最小单位,是一组可复用、易检索的标准化信息集合。
例如:iPhoneX手机就是SPU。一台银色、128G内存的、支持联通网络的iPhoneX,就是SKU。
平台属性:

销售属性:
二:业务数据采集模块

2.1 安装MySQL及配置
由于篇幅原因,这里就不记录安装MySQL的流程了。
2.2 业务数据生成
2.2.1 连接Mysql以及建表
通过MySQL可视化客户端(我用的是Navicat)连接数据库。
1)通过Navicat创建数据库
2)设置数据库名称为gmall,编码为utf-8,排序规则为utf8_general_ci
3)导入数据库结构脚本(gmall.sql)
注意:完成后,要记得右键,刷新一下对象浏览器,就可以看见数据库中的表了。
2.2.2 生成业务数据
1)在hadoop102的/opt/module/目录下创建db_log文件夹
2)把gmall2020-mock-db-2021-01-22.jar和application.properties上传到hadoop102的/opt/module/db_log路径上。
3)根据需求修改application.properties相关配置(主要修改主机名、数据库名、用户名及密码),这里注意,在第一次生成业务数据的时候,要将重置的配置修改为1,后续不要重置,所以改成0


4)并在该目录下执行,如下命令,生成2020-06-14日期数据
[axing@hadoop102 db_log]$ java -jar gmall2020-mock-db-2021-01-22.jar5)查看gmall数据库,观察是否有2020-06-14的数据出现
2.3 安装Sqoop
2.3.1 安装
1)上传安装包sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz到hadoop102的/opt/software路径中
2)解压sqoop安装包到指定目录
[axing@hadoop102 software]$ tar -zxf
sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz -C /opt/module/5)解压sqoop安装包到指定目录
[axing@hadoop102 module]$ mv sqoop-1.4.6.bin__hadoop-2.0.4-alpha/ sqoop2.3.2 修改配置文件
1)进入到/opt/module/sqoop/conf目录,重命名配置文件
[axing@hadoop102 conf]$ mv sqoop-env-template.sh sqoop-env.sh2)修改配置文件
[axing@hadoop102 conf]$ vim sqoop-env.sh 增加如下内容
export HADOOP_COMMON_HOME=/opt/module/hadoop-3.1.3
export HADOOP_MAPRED_HOME=/opt/module/hadoop-3.1.3
export HIVE_HOME=/opt/module/hive
export ZOOKEEPER_HOME=/opt/module/zookeeper-3.5.7
export ZOOCFGDIR=/opt/module/zookeeper-3.5.7/conf2.3.3 拷贝JDBC驱动
1)将mysql-connector-java-5.1.48.jar 上传到/opt/software路径
2)进入到/opt/software/路径,拷贝jdbc驱动到sqoop的lib目录下。
[axing@hadoop102 software]$ cp mysql-connector-java-5.1.48.jar
/opt/module/sqoop/lib/2.3.4 验证Sqoop
(1)我们可以通过某一个command来验证sqoop配置是否正确:
[axing@hadoop102 sqoop]$ bin/sqoop help2.3.5 测试Sqoop是否能够成功连接数据库
[atguigu@hadoop102 sqoop]$ bin/sqoop list-databases --connect
jdbc:mysql://hadoop102:3306/ --username root --password 0000002.3.6 Sqoop基本使用
将mysql中user_info表数据导入到HDFS的/test路径
bin/sqoop import \
--connect jdbc:mysql://hadoop102:3306/gmall \
--username root \
--password 000000 \
--table user_info \
--columns id,login_name \
--where "id>=10 and id<=30" \
--target-dir /test \
--delete-target-dir \
--fields-terminated-by '\t' \
--num-mappers 2 \
--split-by id2.4 同步策略
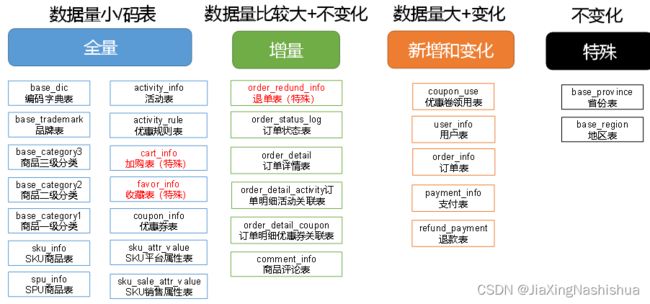
数据同步策略的类型包括:全量同步、增量同步、新增及变化同步、特殊情况
- 全量表:存储完整的数据。
- 增量表:存储新增加的数据。
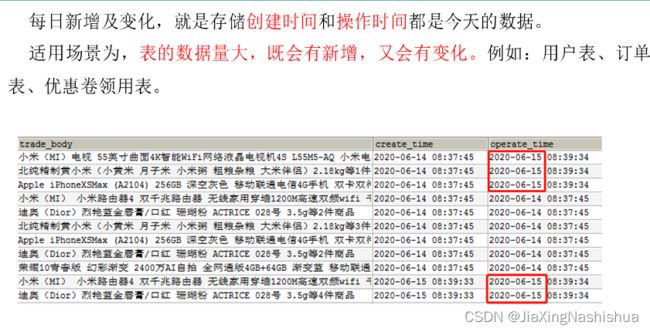
- 新增及变化表:存储新增加的数据和变化的数据。
- 特殊表:只需要存储一次。
2.4.1 全量同步策略

2.4.2 增量同步策略
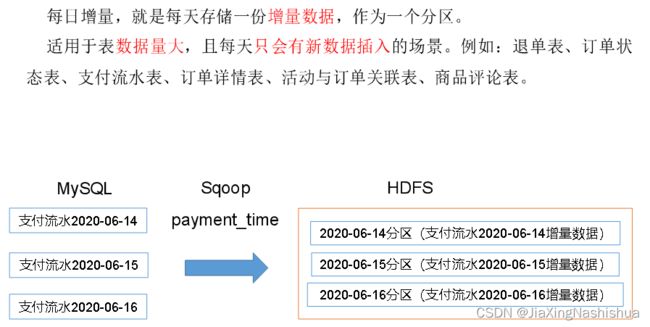
2.4.3 新增及变化策略
2.4.4 特殊策略
某些特殊的表,可不必遵循上述同步策略。例如某些不会发生变化的表(地区表,省份表,民族表)可以只存一份固定值。
2.5 业务数据导入HDFS
2.5.1 分析表同步策略
在生产环境,个别小公司,为了简单处理,所有表全量导入。
中大型公司,由于数据量比较大,还是严格按照同步策略导入数据。
2.5.2 业务数据首日同步脚本
由于篇幅原因,就不列出脚本代码了
2.5.3 业务数据每日同步脚本
由于篇幅原因,就不列出脚本代码了
2.5.4 项目经验
Hive中的Null在底层是以“\N”来存储,而MySQL中的Null在底层就是Null,为了保证数据两端的一致性。在导出数据时采用--input-null-string和--input-null-non-string两个参数。导入数据时采用--null-string和--null-non-string。
三:数据环境准备
1)把apache-hive-3.1.2-bin.tar.gz上传到Linux的/opt/software目录下
2)解压apache-hive-3.1.2-bin.tar.gz到/opt/module/目录下面
3)修改apache-hive-3.1.2-bin.tar.gz的名称为hive
4)修改/etc/profile.d/my_env.sh,添加环境变量,添加完后source一下,使环境变量生效
添加内容
#HIVE_HOME
export HIVE_HOME=/opt/module/hive
export PATH=$PATH:$HIVE_HOME/bin5)解决日志Jar包冲突,进入/opt/module/hive/lib目录
3.2 Hive元数据配置到MySQL
3.2.1 拷贝驱动
将MySQL的JDBC驱动拷贝到Hive的lib目录下
[axing@hadoop102 lib]$ cp /opt/software/mysql-connector-java-5.1.27.jar
/opt/module/hive/lib/3.2.2 配置Metastore到MySQL
(1)在$HIVE_HOME/conf目录下新建hive-site.xml文件,并添加如下内容
javax.jdo.option.ConnectionURL
jdbc:mysql://hadoop102:3306/metastore?useSSL=false
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
javax.jdo.option.ConnectionUserName
root
javax.jdo.option.ConnectionPassword
000000
hive.metastore.warehouse.dir
/user/hive/warehouse
hive.metastore.schema.verification
false
hive.server2.thrift.port
10000
hive.server2.thrift.bind.host
hadoop102
hive.metastore.event.db.notification.api.auth
false
hive.cli.print.header
true
hive.cli.print.current.db
true
3.3 启动Hive
3.3.1 初始化元数据库
(1)登陆MySQL
[axing@hadoop102 conf]$ mysql -uroot -p000000(2)新建Hive元数据库
mysql> create database metastore;(3)初始化Hive元数据库
[axing@hadoop102 conf]$ schematool -initSchema -dbType mysql -verbose3.3.2 启动Hive客户端
(1)启动Hive客户端
[axing@hadoop102 hive]$ bin/hive(2)查看一下数据库
hive (default)> show databases;
OK
database_name
default