YOLO系列 --- YOLOV7算法(四):YOLO V7算法网络结构解析
YOLO系列 — YOLOV7算法(四):YOLO V7算法网络结构解析
今天来讲讲YOLO V7算法网络结构吧~
在train.py中大概95行的地方开始创建网络,如下图(YOLO V7下载的时间不同,可能代码有少许的改动,所以行数跟我不一定一样)
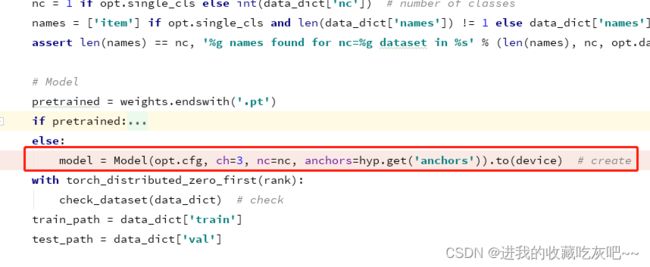
我们进去发现,其实就是在yolo.py里面。后期,我们就会发现相关的网络结构都是在该py文件里面。这篇blog就主要讲讲Model这个类。
def __init__(self, cfg='yolor-csp-c.yaml', ch=3, nc=None, anchors=None):
先来说下,传入的参数:
- cfg:传入的网络结构yaml文件路径,这里已经默认的是
yolor-csp-c.yaml,就是说如果你在train.py中没有传入网络结构yaml文件的话默认使用yolor-csp-c.yaml这个网络结构 - ch:预测头的数量
- nc:数据集类别数
super(Model, self).__init__()
self.traced = False
if isinstance(cfg, dict):
self.yaml = cfg # model dict
else: # is *.yaml
import yaml # for torch hub
self.yaml_file = Path(cfg).name
with open(cfg) as f:
self.yaml = yaml.load(f, Loader=yaml.SafeLoader) # model dict
首先判断传入的yaml网络结构文件是不是字典形式的,我们一般直接就是传入的是yaml的路径,所以直接用yaml.load解析yaml文件,如下图
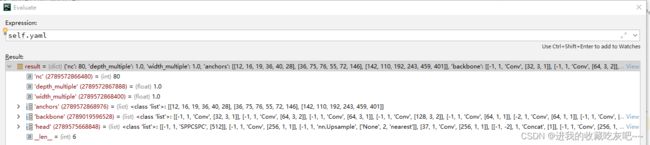
# Define model
ch = self.yaml['ch'] = self.yaml.get('ch', ch) # input channels
if nc and nc != self.yaml['nc']:
logger.info(f"Overriding model.yaml nc={self.yaml['nc']} with nc={nc}")
self.yaml['nc'] = nc # override yaml value
if anchors:
logger.info(f'Overriding model.yaml anchors with anchors={anchors}')
self.yaml['anchors'] = round(anchors) # override yaml value
self.model, self.save = parse_model(deepcopy(self.yaml), ch=[ch]) # model, savelist
self.names = [str(i) for i in range(self.yaml['nc'])] # default names
这段代码值得好好看看,首先第一行代码出现了两个=号,其实代表的含义就是最右边的变量同时赋值给中间的和最左边的。而self.yaml.get('ch', ch)就是在寻找yaml字典中是否存在ch这个key,这里是不存在的,我们可以在yolov7.yaml中找找看,里面是没有的,如果没有的话就直接用Model类中__init__初始化定义的ch=3,表示该模型一共有三个预测头。
然后,判断一下custom_data.yaml中的nc是否与yolov7.yaml中的nc是否一致,如果不一致的话就默认将custom_data.yaml中的nc赋值给self.yaml中的nc。
接着,将yolov7.yaml中的anchors赋值给self.yaml。
最后,我们将解析后的yaml字典和预测头数量传入parse_model函数,最后一行代码其实就没什么的了,就是将所有类别变成[0,1,2,…]
进入parse_model函数:
logger.info('\n%3s%18s%3s%10s %-40s%-30s' % ('', 'from', 'n', 'params', 'module', 'arguments'))
anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple']
na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors
no = na * (nc + 5) # number of outputs = anchors * (classes + 5)
首先是从yaml字典中获取anchor尺寸,类别数,网络深度,网络宽度。这里,详细说下网络深度,网络宽度到底是什么意思:
我们先来看下yolov7.yaml中backbone和head中每个列表的含义:

第一个:表示该层是源自于上面哪一层,一般-1就表示的是上一层
第二个:表示该层一共有几个,就比如说这里有一个卷积层是2的话,那么这层就是有两个串联卷积层
第三个:表示该层是什么模块
第四个:表示的是该层的一些参数,比如说如果该层是Conv卷积层的话,那么后面接一个【32,3,1】就表示的是输出channel数是32,卷积核大小为3*3
介绍完每个参数,我们就可以介绍什么是网络深度,网络宽度了:
- 网络深度:实际在构建网络模型的时候,并不是直接使用上述第二个参数,即有几个模块层。而是用网络深度去乘以第二个参数,最终获得的数量才是真正的层数量。举个例子,此时网络深度是0.33,某个层的第二个参数是3,那么实际在构建网络模型的时候只创建了0.33*3=1个,并不是三个。
- 网络宽度:再举个例子吧,比如此时该层是卷积层Conv,输出channels数设置为64,但是同时网络宽度设置的是0.5,那么在实际构建网络模型的时候,该层最后的输出channels数其实是64*0.5=32。
同时,在yolov7.yaml中anchors表示的是每个预测头所对应的anchors长宽大小,如下图(随意画的,能理解含义就ok了):

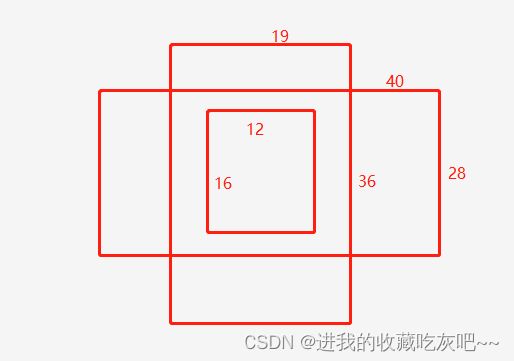
那么na就表示的是每个预测头有几组比例不同的anchor,no表示的是最后预测头输出的通道数,其中5表示的是四个位置信息和置信度大小。
layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
m = eval(m) if isinstance(m, str) else m # eval strings
for j, a in enumerate(args):
try:
args[j] = eval(a) if isinstance(a, str) else a # eval strings
except:
pass
遍历backbone和head所有层,获取得到每一层到底是什么模块,然后利用eval函数进行解析。这里简单介绍下eval函数,遍历所得到的m只是一个字符串,表示该层的类型,但是并不是该层的类,而eval函数就是实例化该层类。而args也是同理。
n = max(round(n * gd), 1) if n > 1 else n # depth gain
if m in [nn.Conv2d, Conv, RobustConv, RobustConv2, DWConv, GhostConv, RepConv, RepConv_OREPA, DownC,
SPP, SPPF, SPPCSPC, GhostSPPCSPC, MixConv2d, Focus, Stem, GhostStem, CrossConv,
Bottleneck, BottleneckCSPA, BottleneckCSPB, BottleneckCSPC,
RepBottleneck, RepBottleneckCSPA, RepBottleneckCSPB, RepBottleneckCSPC,
Res, ResCSPA, ResCSPB, ResCSPC,
RepRes, RepResCSPA, RepResCSPB, RepResCSPC,
ResX, ResXCSPA, ResXCSPB, ResXCSPC,
RepResX, RepResXCSPA, RepResXCSPB, RepResXCSPC,
Ghost, GhostCSPA, GhostCSPB, GhostCSPC,
SwinTransformerBlock, STCSPA, STCSPB, STCSPC,
SwinTransformer2Block, ST2CSPA, ST2CSPB, ST2CSPC]:
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
第一行代码就是我上述所说的网络深度,真正的层数量取决于yaml文件中的第二个参数和网络深度的乘积。前提是yaml中层的数量是大于1才进行计算。然后判断该层的类型,这个判断大多是判断是不是卷积层。计算c1和c2,这两个数字分别表示输入channels数和输出channels数。接着判断遍历的该层是不是最后一层,而判断的标注就是看最后输出的channels数c2是不是等于no,no上述已经说过了表示最后预测头的通道数。如果不是最后一层,那表示是网络中间的层,那么就来到了上述说的网络宽度部分了。
c2 = make_divisible(c2 * gw, 8)
该层最终的输出通道数其实就是网络宽度和该层第一个参数的乘积,make_divisible函数之前已经说过了,作用是自动调整为32的倍数。
args = [c1, c2, *args[1:]]
if m in [DownC, SPPCSPC, GhostSPPCSPC,
BottleneckCSPA, BottleneckCSPB, BottleneckCSPC,
RepBottleneckCSPA, RepBottleneckCSPB, RepBottleneckCSPC,
ResCSPA, ResCSPB, ResCSPC,
RepResCSPA, RepResCSPB, RepResCSPC,
ResXCSPA, ResXCSPB, ResXCSPC,
RepResXCSPA, RepResXCSPB, RepResXCSPC,
GhostCSPA, GhostCSPB, GhostCSPC,
STCSPA, STCSPB, STCSPC,
ST2CSPA, ST2CSPB, ST2CSPC]:
args.insert(2, n) # number of repeats
n = 1
args是拼凑喂入网络的参数列表, 我们可以看下models/common.py中Conv类的__init__初始化函数:

卷积层需要输入的参数格式为:[输入通道数,输出通道数,卷积核大小,步长],正好与args = [c1, c2, *args[1:]]相对应上了。然后进一步判断层是否属于列表中这些层,因为这些层的参数形式与卷积不一样。
elif m is nn.BatchNorm2d:
args = [ch[f]]
elif m is Concat:
c2 = sum([ch[x] for x in f])
elif m is Chuncat:
c2 = sum([ch[x] for x in f])
elif m is Shortcut:
c2 = ch[f[0]]
elif m is Foldcut:
c2 = ch[f] // 2
elif m in [Detect, IDetect, IAuxDetect, IBin]:
args.append([ch[x] for x in f])
if isinstance(args[1], int): # number of anchors
args[1] = [list(range(args[1] * 2))] * len(f)
elif m is ReOrg:
c2 = ch[f] * 4
elif m is Contract:
c2 = ch[f] * args[0] ** 2
elif m is Expand:
c2 = ch[f] // args[0] ** 2
else:
c2 = ch[f]
判断如果不是卷积等操作,再看看是不是属于下面elif中的哪个层,这里我就不多说了,也没啥难的。
m_ = nn.Sequential(*[m(*args) for _ in range(n)]) if n > 1 else m(*args) # module
t = str(m)[8:-2].replace('__main__.', '') # module type
np = sum([x.numel() for x in m_.parameters()]) # number params
m_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number params
logger.info('%3s%18s%3s%10.0f %-40s%-30s' % (i, f, n, np, t, args)) # print
save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
layers.append(m_)
if i == 0:
ch = []
ch.append(c2)
return nn.Sequential(*layers), sorted(save)
torch.nn.Sequential是一个Sequential容器,模块将按照构造函数中传递的顺序添加到模块中。然后获取遍历的每一层的参数量大小。save.extend这一行代码是遍历所有的层,找到第一个参数不是等于-1的,也就是该层的数据不是来源于上一层,也就是意味着是来自上面的多个层,那么就要进行保存操作。最后判断下是不是输入层,如果是输入层的话,就将输出通道数放进ch里面去。最后返回Sequential容器和需要保存的层的索引号。
我们回到Model类中:
# Build strides, anchors
m = self.model[-1] # Detect()
if isinstance(m, Detect):
s = 256 # 2x min stride
m.stride = torch.tensor([s / x.shape[-2] for x in self.forward(torch.zeros(1, ch, s, s))]) # forward
m.anchors /= m.stride.view(-1, 1, 1)
check_anchor_order(m)
self.stride = m.stride
self._initialize_biases() # only run once
# print('Strides: %s' % m.stride.tolist())
if isinstance(m, IDetect):
s = 256 # 2x min stride
m.stride = torch.tensor([s / x.shape[-2] for x in self.forward(torch.zeros(1, ch, s, s))]) # forward
m.anchors /= m.stride.view(-1, 1, 1)
check_anchor_order(m)
self.stride = m.stride
self._initialize_biases() # only run once
# print('Strides: %s' % m.stride.tolist())
if isinstance(m, IAuxDetect):
s = 256 # 2x min stride
m.stride = torch.tensor([s / x.shape[-2] for x in self.forward(torch.zeros(1, ch, s, s))[:4]]) # forward
#print(m.stride)
m.anchors /= m.stride.view(-1, 1, 1)
check_anchor_order(m)
self.stride = m.stride
self._initialize_aux_biases() # only run once
# print('Strides: %s' % m.stride.tolist())
if isinstance(m, IBin):
s = 256 # 2x min stride
m.stride = torch.tensor([s / x.shape[-2] for x in self.forward(torch.zeros(1, ch, s, s))]) # forward
m.anchors /= m.stride.view(-1, 1, 1)
check_anchor_order(m)
self.stride = m.stride
self._initialize_biases_bin() # only run once
# print('Strides: %s' % m.stride.tolist())
得到一个Sequential容器,里面包含着所有层。我们先获取到最后一层,一般来说,最后一层都是检测层,就是将所有的预测头进行融合。判断下是属于哪种检测层。
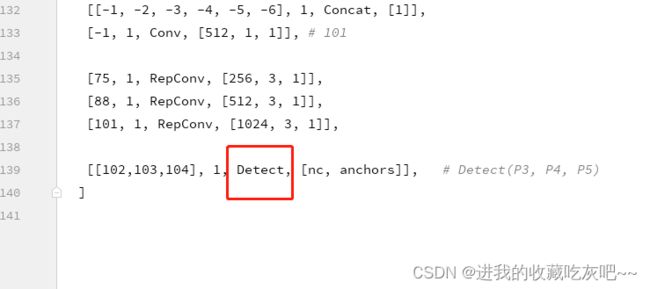
我们通过yolov7.yaml文件可以看到,这里最后一层是Detect类型,那么我就进入第一个if分支里面。我们本身是知道这个网络的步长是32,16和8的,但是模型是不知道的,所以我们需要喂入一个测试tensor进行一次正向传播来得到网络的步长大小。m.anchors表示的是基于原始图片的,所以我们要相对应的除以步长,得到的m.anchors才是真正的基于最后预测头特征图的anchors尺寸。check_anchor_order函数的作用就是检测anchor的顺序是不是正确的,在yolov7.yaml中应该是从小到大的顺序排列。
# Init weights, biases
initialize_weights(self)
self.info()
logger.info('')
最后,就是初始化一下权重大小。