【JAVA知识梳理】集合万字总结!
活动地址:CSDN21天学习挑战赛
集合
集合体系图
单列集合:
Collection 的子接口下的 List 和 Set 的实现子类均为单列集合
包括:
Set: Hash、TreeSet
List: Vector 、 ArrayList、LinkList、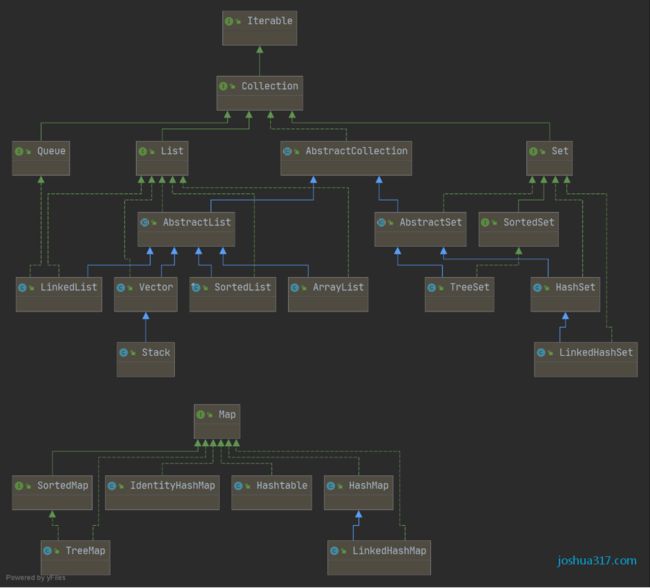
双列集合:
Map的实现子类均为双列集合
包括:
TreeMap
Hashtable: Properties
HashMap: LinkedHashMap
Collection
Collection 接口
1)子类均可以存放多个元素,每个元素可以是Object
2)Collection接口没有直接实现的子类,是通过它的子接口 Set(无序)和 List(有序) 来实现的
3)Collectio的实现类,有些可以存放重复的元素,有些不可以
常用方法
List list = new ArrayList();
List list = new ArrayList();
// add:添加单个元素
list.add("jack");
list.add(10);//list.add(new Integer(10))
list.add(true);
System.out.println("list=" + list);
// remove:删除指定元素
//list.remove(0);//删除第一个元素
list.remove(true);//指定删除某个元素
System.out.println("list=" + list);
// contains:查找元素是否存在
System.out.println(list.contains("jack"));//T
// size:获取元素个数
System.out.println(list.size());//2
// isEmpty:判断是否为空
System.out.println(list.isEmpty());//F
// clear:清空
list.clear();
System.out.println("list=" + list);
// addAll:添加多个元素
ArrayList list2 = new ArrayList();
list2.add("红楼梦");
list2.add("三国演义");
list.addAll(list2);
System.out.println("list=" + list);
// containsAll:查找多个元素是否都存在
System.out.println(list.containsAll(list2));//T
//removeAll:删除多个元素
list.add("聊斋");
list.removeAll(list2);
System.out.println("list=" + list);//[聊斋]
// 说明:以 ArrayList 实现类来演示.
集合的遍历
//1. 先得到 col 对应的 迭代器
Iterator iterator = col.iterator();
//2. 使用 while 循环遍历
while (iterator.hasNext())//判断是否还有数据
{
// 返回下一个元素,类型是 Object
Object obj = iterator.next();
System.out.println("obj=" + obj);
}
//快速生成 while => itit
//显示所有的快捷键的的快捷键 ctrl + j
while (iterator.hasNext()) {
Object obj = iterator.next();
System.out.println("obj=" + obj);
//3. 当退出 while 循环后 , 这时 iterator 迭代器,指向最后的元素
iterator.next();//NoSuchElementException
//4. 如果希望再次遍历,需要重置我们的迭代器
iterator = col.iterator();
System.out.println("===第二次遍历===");
while (iterator.hasNext()) {
Object obj = iterator.next();
System.out.println("obj=" + obj);}
增强for循环
for(元素类型 元素名 :集合或数组){
}
for (Object dog : list) {
System.out.println("dog=" + dog);
}
List
特性
List 集合类中元素有序(即添加顺序和取出顺序一致)、且可重复
List list = new ArrayList();
list.add("jack");
list.add("tom");
list.add("mary");
list.add("hsp");
List 集合中的每个元素都有其对应的顺序索引,即支持索引
// 索引是从 0 开始的
System.out.println(list.get(3));//hsp
常用方法
Object get(int index):获取指定 index 位置的元素
int indexOf(Object obj):返回 obj 在集合中首次出现的位置
int lastIndexOf(Object obj):返回 obj 在当前集合中末次出现的位置
Object remove(int index):移除指定 index 位置的元素,并返回此元素
Object set(int index, Object ele):设置指定 index 位置的元素为 ele , 相当于是替换.
List subList(int fromIndex, int toIndex):返回从 fromIndex 到 toIndex 位置的子集合
// 注意返回的子集合 fromIndex <= subList < toIndex
//手写 List 排序
public static void sort(List list) {
int listSize = list.size();
for (int i = 0; i < listSize - 1; i++) {
for (int j = 0; j < listSize - 1 - i; j++) {
//取出对象 Book
Book book1 = (Book) list.get(j);
Book book2 = (Book) list.get(j + 1);
if (book1.getPrice() > book2.getPrice()) {//交换
list.set(j, book2);
list.set(j + 1, book1);
}
ArrayList
ArrayList源码剖析
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fyxxKkS2-1659533159166)(C:\Users\Lenovo\AppData\Roaming\Typora\typora-user-images\image-20220603151001901.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JHXlzb69-1659533159167)(C:\Users\Lenovo\AppData\Roaming\Typora\typora-user-images\image-20220603151036828.png)]
注意事项:
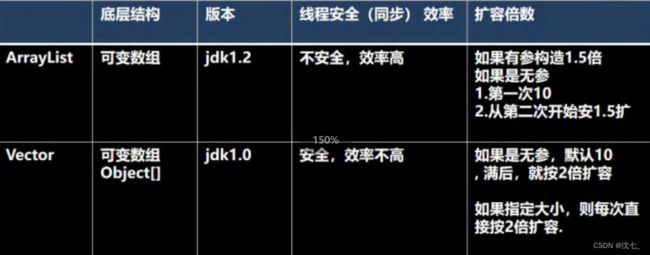
ArrayList 基本等同于 Vector ,除了 ArrayList是线程不安全(执行效率高)。
在多线程情况下,不建议使用 ArrayList
源码分析:
1)ArrayList 中维护了一个 Object 类型 的数组 elementData
2)当创建 ArrayList 对象是,如果使用的是无参构造器,则初始 elementDate 容量为 0 ,第1 次添加,则扩容elementDate为10,如需要再次扩容,则扩容elementDate为1.5倍。
3)如果使用的是指定大小的构造器,则初始elementDate容量为指定大小,如果需要扩容,则直接扩容elementDate为1.5倍。
Vector
1)Vector底层也是一个对象数组
protected Object[ ] elementDate
2)Vector 是线程同步的,即线程安全,Vector类的操作方法带有synchronized
3)在开发中,需要线程同步安全时,考虑使用Vector
LinkedList
模拟双向链表
package Link_;
public class Link_{
public static void main(String args[]) {
Node jack = new Node("jack");
Node hh = new Node("hh");
Node tom = new Node("tom");
jack.next = tom;
tom.next = hh;
hh.pre=tom;
tom.pre = jack;
Node first = jack;
Node last = hh;
while(true){
if(first==null){
break;
}
System.out.println(first);
first = first.next;
}
}
}
class Node{
public Object item;
public Node next;
public Node pre;
public Node(Object name) {
this.item = name;
}
@Override
public String toString() {
return "Node name = "+ item ;
}
}
LinkedList全面说明:
1)LinkedList 底层实现了双向链表和双端队列特点
2)可以添加任意元素,包括null
3)线程不安全,没有实现同步
LinkedList源码分析:
1)LinkedList 底层维护了一个双向链表
2)LinkedList 中维护了两个属性 first 和 last 分别指向 首节点和尾结点
3)每一个节点(Node对象),里面有维护了 pre 、 next、item 三个属性。
pre:指向前一个节点
next:指向后一个节点
item:储存实际的值
4)所以 LinkedList 的元素的添加和删除,效率相对数组来说较高。
ArrayList 和 LinkedList 比较
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oHT512fV-1659533159168)(C:\Users\Lenovo\AppData\Roaming\Typora\typora-user-images\image-20220603191021886.png)]
ArrayListt 查询效率高的原因:可以使用索引访问,而LinkedList不行。
面试题
请问 ArrayList/LinkedList/Vector的异同?谈谈你的理解?ArrayList底层是什么?扩容机制? Vector和 ArrayList的最大区别?
-
ArrayList和 Linkedlist的异同:
二者都线程不安全,相比线程安全的 Vector,ArrayList执行效率高。 此外,ArrayList是实现了基于动态数组的数据结构,Linkedlist基于链表的数据结构。对于随机访问get和set,ArrayList觉得优于Linkedlist,因为Linkedlist要移动指针。对于新增和删除操作add(特指插入)和 remove,Linkedlist比较占优势,因为 ArrayList要移动数据。
-
ArrayList和 Vector的区别:
Vector和ArrayList几乎是完全相同的,唯一的区别在于Vector是同步类(synchronized),属于强同步类。因此开销就比 ArrayList要大,访问要慢。正常情况下,大多数的Java程序员使用ArrayList而不是Vector,因为同步完全可以由程序员自己来控制。Vector每次扩容请求其大小的2倍空间,而ArrayList是1.5倍。Vector还有一个子类Stack.
Set
Set 接口
-
以 Set 接口的实现类 HashSet 来讲解 Set 接口的方法
-
set 接口的实现类的对象(Set 接口对象), 不能存放重复的元素, 可以添加一个 null
-
set 接口对象存放数据是无序(即添加的顺序和取出的顺序不一致)
-
注意:取出的顺序的顺序虽然不是添加的顺序,但是他的固定
-
set 接口对象,不能通过索引来获取。
-
Set判断两个对象是否相同不是使用==运算符,而是根据equals()方法
HashSet
1.无序性:不等于随机性。存储的数据在底层数组中并非
2.不可重复性:保证添加的元素照equals()判断时,不能返回true.即:相同的元素只能添加一个
源码分析:
我们向HashSet中添加元素a,首先调用元素a所在类的hashCode()方法。
计算元素a的哈希值,此哈希值接着通过某种算法计算出在HashSet底层数组中的存放位置(即为:索引位置)。
判断数组此位置上是否已经有元素:
-
如果此位置上没有其他元素,则元素a添加成功。 —>情况1
-
如果此位置上有其他元素b(或以链表形式存在的多个元素),则比较元素a与元素b的hash值:
- 如果hash值不相同,则元素a添加成功。—>情况2
- 如果hash值相同,进而需要调用元素a所在类的equals()方法:
- equals()返回true,元素a添加失败
- equals()返回false,则元素a添加成功。—>情况3
对于添加成功的情况2和情况3而言:元素a 与已经存在指定索引位置上数据以链表的方式存储。
JDK 7.0 :元素a放到数组中,指向原来的元素。
JDK 8.0 :原来的元素在数组中,指向元素a
总结:七上八下
HashSet底层:数组+链表的结构。(JDK 7.0以前)

常用方法:
Set接口中没额外定义新的方法,使用的都是Collection中声明过的方法。
重写hashCode()的基本方法
- 在程序运行时,同一个对象多次调用
hashCode()方法应该返回相同的值。 - 当两个对象的
equals()方法比较返回true时,这两个对象的hashCode()方法的返回值也应相等。 - 对象中用作
equals()方法比较的Field,都应该用来计算hashCode值。
重写 equals() 方法基本原则
-
以自定义的 Customer类为例,何时需要重写
equals()? -
当一个类有自己特有的“逻辑相等”概念,当改写equals()的时候,总是要改写
hash Code(),根据一个类的 equals方法(改写后),两个截然不同的实例有可能在逻辑上是相等的,但是,根据Object.hashCode()方法,它们仅仅是两个对象。 -
因此,违反了相等的对象必须具有相等的散列码.
-
结论:复写equals方法的时候一般都需要同时复写 hashCode 方法。通常参与计算 hashCode的对象的属性也应该参与到
equals()中进行计算。
IDEA工具里hashCode()重写
以IDEA为例,在自定义类中可以调用工具自动重写 equals() 和 hashCode()
问题:为什么用 Eclipse/IDEA复写 hash Code方法,有31这个数字?
- 选择系数的时候要选择尽量大的系数。因为如果计算出来的hash地址越大,所谓的“冲突”就越少,查找起来效率也会提高。(减少冲突)
- 并且31只占用5bits,相乘造成数据溢出的概率较小。
- 31可以由i*31==(<<5)-1来表示,现在很多虚拟机里面都有做相关优化。(提高算法效率)
- 31是一个素数,素数作用就是如果我用一个数字来乘以这个素数,那么最终出来的结果只能被素数本身和被乘数还有1来整除!(减少冲突)
代码示例:
@Override
public boolean equals(Object o) {
System.out.println("User equals()....");
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
User user = (User) o;
if (age != user.age) return false;
return name != null ? name.equals(user.name) : user.name == null;
}
@Override
public int hashCode() { //return name.hashCode() + age;
int result = name != null ? name.hashCode() : 0;
result = 31 * result + age;
return result;
}
LinkedHashSet
LinkedhashSet是HashSet的子类
LinkedhashSet根据元素的hashCode值来决定元素的存储位置但它同时使用双向链表维护元素的次序,这使得元素看起来是以插入顺序保存的。
LinkedhashSet插入性能略低于HashSet,但在迭代访问Set里的全部元素时有很好的性能。
LinkedhashSet不允许集合元素重复。
图示:

代码:
@Test
//LinkedHashSet使用
public void test2(){
Set set = new LinkedHashSet();
set.add(454);
set.add(213);
set.add(111);
set.add(123);
set.add(23);
set.add("AAA");
set.add("EEE");
set.add(new User("Tom",34));
set.add(new User("Jarry",74));
Iterator iterator = set.iterator();
while (iterator.hasNext()){
System.out.println(iterator.next());
}
}
TreeSet
- Treeset是SortedSet接口的实现类,TreeSet可以确保集合元素处于排序状态。
- TreeSet底层使用红黑树结构存储数据
- 新增的方法如下:(了解)
Comparator comparator()Object first()Object last()Object lower(object e)Object higher(object e)SortedSet subSet(fromElement, toElement)SortedSet headSet(toElement)SortedSet tailSet(fromElement)
- TreeSet两种排序方法:自然排序和定制排序。默认情况下,TreeSet采用自然排序。
红黑树图示:
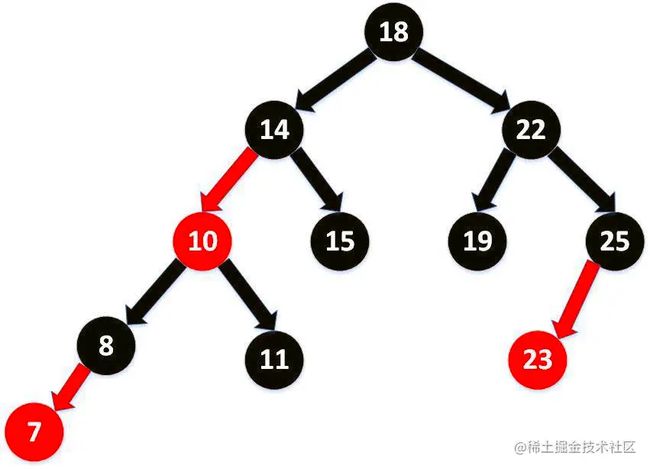
红黑树的特点:有序,查询效率比List快
详细介绍:www.cnblogs.com/LiaHon/p/11…
代码示例:
@Test
public void test1(){
Set treeSet = new TreeSet();
treeSet.add(new User("Tom",34));
treeSet.add(new User("Jarry",23));
treeSet.add(new User("mars",38));
treeSet.add(new User("Jane",56));
treeSet.add(new User("Jane",60));
treeSet.add(new User("Bruce",58));
Iterator iterator = treeSet.iterator();
while (iterator.hasNext()){
System.out.println(iterator.next());
}
}
复制代码
存储对象所在类的要求:
HashSet/LinkedHashSet:
- 要求:向Set(主要指:HashSet、LinkedHashSet)中添加的数据,其所在的类一定要重写hashCode()和equals()
- 要求:重写的 hashCode()和equals()尽可能保持一致性:相等的对象必须具有相等的散列码
重写两个方法的小技巧:对象中用作 equals() 方法比较的 Field,都应该用来计算 hashCode 值。
排序细节
- 自然排序中,比较两个对象是否相同的标准为:
compareTo()返回0.不再是equals() - 定制排序中,比较两个对象是否相同的标准为:
compare()返回0.不再是equals()
常用的排序方式:
方式一:自然排序
- 自然排序:TreeSet会调用集合元素的
compareTo(object obj)方法来比较元素之间的大小关系,然后将集合元素按升序(默认情况)排列 - 如果试图把一个对象添加到Treeset时,则该对象的类必须实现Comparable接口。
- 实现Comparable的类必须实现
compareTo(Object obj)方法,两个对象即通过compareTo(Object obj)方法的返回值来比较大小
- 实现Comparable的类必须实现
- Comparable的典型实现:
- BigDecimal、BigInteger以及所有的数值型对应的包装类:按它们对应的数值大小进行比较
- Character:按字符的unicode值来进行比较
- Boolean:true对应的包装类实例大于fase对应的包装类实例
- String:按字符串中字符的unicode值进行比较
- Date、Time:后边的时间、日期比前面的时间、日期大
- 向TreeSet中添加元素时,只有第一个元素无须比较
compareTo()方法,后面添加的所有元素都会调用compareTo()方法进行比较。 - 因为只有相同类的两个实例才会比较大小,所以向 TreeSet中添加的应该是同一个类的对象。 对于TreeSet集合而言,它判断两个对象是否相等的唯一标准是:两个对象通过
compareTo(Object obj)方法比较返回值。 - 当需要把一个对象放入TreeSet中,重写该对象对应的equals()方法时,应保证该方法与
compareTo(Object obj)方法有一致的结果:如果两个对象通过equals()方法比较返回true,则通过compareTo(object ob)方法比较应返回0。否则,让人难以理解。
@Test
public void test1(){
TreeSet set = new TreeSet();
//失败:不能添加不同类的对象
// set.add(123);
// set.add(456);
// set.add("AA");
// set.add(new User("Tom",12));
//举例一:
// set.add(34);
// set.add(-34);
// set.add(43);
// set.add(11);
// set.add(8);
//举例二:
set.add(new User("Tom",12));
set.add(new User("Jerry",32));
set.add(new User("Jim",2));
set.add(new User("Mike",65));
set.add(new User("Jack",33));
set.add(new User("Jack",56));
Iterator iterator = set.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
}
复制代码
方式二:定制排序
- TreeSet的自然排序要求元素所属的类实现Comparable接口,如果元素所属的类没有实现 Comparable接口,或不希望按照升序(默认情况)的方式排列元素或希望按照其它属性大小进行排序,则考虑使用定制排序。定制排序,通过 Comparator接口来实现。需要重写 compare(T o1,T o2)方法。
- 利用
int compare(T o1,T o2)方法,比较o1和o2的大小:如果方法返回正整数,则表示o1大于o2;如果返回0,表示相等;返回负整数,表示o1小于o2。 - 要实现定制排序,需要将实现Comparator接口的实例作为形参传递给TreeSet的构造器。
- 此时,仍然只能向Treeset中添加类型相同的对象。否则发生
ClassCastException异常 - 使用定制排序判断两个元素相等的标准是:通过 Comparator比较两个元素返回了0
@Test
public void test2(){
Comparator com = new Comparator() {
//照年龄从小到大排列
@Override
public int compare(Object o1, Object o2) {
if(o1 instanceof User && o2 instanceof User){
User u1 = (User)o1;
User u2 = (User)o2;
return Integer.compare(u1.getAge(),u2.getAge());
}else{
throw new RuntimeException("输入的数据类型不匹配");
}
}
};
TreeSet set = new TreeSet(com);
set.add(new User("Tom",12));
set.add(new User("Jerry",32));
set.add(new User("Jim",2));
set.add(new User("Mike",65));
set.add(new User("Mary",33));
set.add(new User("Jack",33));
set.add(new User("Jack",56));
Iterator iterator = set.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
}
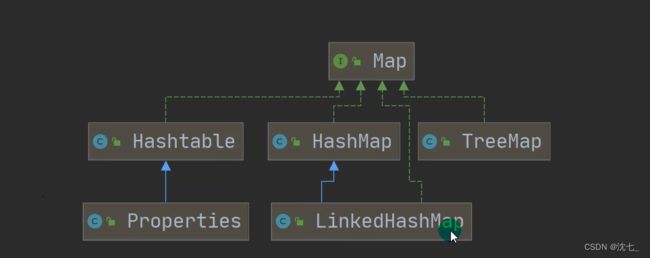
Map
- Map与Collection并列存在。用于保存具有映射关系的数据:key-value
- Map中的key和value都可以是任何引用类型的数据
- Map中的key用set来存放,不允许重复,即同一个Map对象所对应的类,须重写
hashCode()和equals()方法 - 常用 String类作为Map的“键”
- key和value之间存在单向一对一关系,即通过指定的key总能找到唯一的、确定的value
- Map接口的常用实现类:HashMap、TreeMap、LinkedHashMap和Properties。其中,HashMap是Map接口使用频率最高的实现类
Map实现集合简述
|----Map:双列数据,存储key-value对的数据 ---类似于高中的函数:y = f(x)
|----HashMap:作为Map的主要实现类:线程不安全的,效率高,存储null的key和value
|------LinkedHashMap:保证在遍历map元素时,可以照添加的顺序实现遍历。
原因:在原的HashMap底层结构基础上,添加了一对指针,指向前一个和后一个 元素。
对于频繁的遍历操作,此类执行效率高于HashMap。
|----TreeMap:保证照添加的key - value 对进行排序,实现排序遍历。此时考虑key的自然排序和定制排序
底层使用红黑树实现。
|----Hashtable:作为古老的实现类:线程安全的,效率低;不能存储null的key和value。
|----Properties:常用来处理配置文件。key和value都是String类型。
HashMap 的底层:数组+链表(JDK 7.0 及之前)
数组+链表+红黑树(JDK 8.0 以后)
HashMap
- HashMap是Map接口使用频率最高的实现类。
- 允许使用null键和null值,与 HashSet一样,不保证映射的顺序。
- 所有的key构成的集合是set:无序的、不可重复的。所以,key所在的类要重写equals()和 hashCode()
- 所有的value构成的集合是Collection:无序的、可以重复的。所以,value所在的类要重写:equals()
- 一个key-value构成一个entry
- 所有的entry构成的集合是Set:无序的、不可重复的
- HashMap判断两个key相等的标准是:两个key通过
equals()方法返回true,hashCode值也相等。 - HashMap判断两个value相等的标准是:两个value通过
equals()方法返回true.
@Test
public void test1(){
Map map = new HashMap();
map.put(null,123);
}
使用方法
遍历
Set keySet():返回所有key构成的Set集合Collection values():返回所有value构成的Collection集合Set entrySet():返回所有key-value对构成的Set集合
Map map = new HashMap();
map.put("熊大", "棕色");
map.put("熊二", "黄色");
//key
for(String key : map.keySet()){
String value = map.get(key);
System.out.println(key+":"+value);
}
//value
for(String value : map.values()){
System.out.println(value);
}
@Test
public void test3() {
Map map = new HashMap();
map.put("AA", 123);
map.put("ZZ", 251);
map.put("CC", 110);
map.put("RR", 124);
map.put("FF", 662);
System.out.println(map);//{AA=123, ZZ=251, CC=110, RR=124, FF=662}
//遍历所有的key集:Set keySet():返回所有key构成的Set集合
Set set = map.keySet();
Iterator iterator = set.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
System.out.println("--------------");
//遍历所有的value集:Collection values():返回所有value构成的Collection集合
Collection values = map.values();
for (Object obj :
values) {
System.out.println(obj);
}
System.out.println("---------------");
//Set entrySet():返回所有key-value对构成的Set集合
Set entrySet = map.entrySet();
Iterator iterator1 = entrySet.iterator();
//方式一:
while (iterator1.hasNext()) {
Object obj = iterator1.next();
//entrySet集合中的元素都是entry
Map.Entry entry = (Map.Entry) obj;
System.out.println(entry.getKey() + "-->" + entry.getValue());
}
System.out.println("--------------");
//方式二:
Set keySet = map.keySet();
Iterator iterator2 = keySet.iterator();
while (iterator2.hasNext()) {
Object key = iterator2.next();
Object value = map.get(key);
System.out.println(key + "==" + value);
}
}
实现原理
JDK 7.0 及以前的版本:HashMap 是数组+链表结构(地址链表法)
JDK 8.0 之后:HashMap 是数组+链表+红黑树的实现
JDK 7.0 的原理

对象创建和添加过程:
HashMap map = new HashMap():
在实例化以后,底层创建了长度是16的一维数组 Entry[] table。
…可能已经执行过多次put…
map.put(key1,value1):
-
首先,调用key1所在类的
hashCode()计算key1哈希值,此哈希值经过某种算法计算以后,得到在Entry数组中的存放位置。 -
如果此位置上的数据为空,此时的key1-value1添加成功。 ----情况1
-
如果此位置上的数据不为空,(意味着此位置上存在一个或多个数据(以链表形式存在)),比较key1和已经存在的一个或多个数据的哈希值:
-
如果key1的哈希值与已经存在的数据的哈希值都不相同,此时key1-value1添加成功。----情况2
-
如果key1的哈希值和已经存在的某一个数据(key2-value2)的哈希值相同,
继续比较:调用key1所在类的equals(key2)方法,比较:
- 如果
equals()返回false:此时key1-value1添加成功。----情况3 - 如果
equals()返回true:使用value1替换value2。
- 如果
-
补充:关于情况2和情况3:此时key1-value1和原来的数据以链表的方式存储。
在不断的添加过程中,会涉及到扩容问题,当超出临界值(且要存放的位置非空)时,扩容。
默认的扩容方式:扩容为原来容量的2倍,并将原有的数据复制过来。
HashMap的扩容
当HashMap中的元素越来越多的时候,hash冲突的几率也就越来越高,因为数组的长度是固定的。
所以为了提高查询的效率,就要对 HashMap的数组进行扩容,
而在HashMap数组扩容之后,原数组中的数据必须重新计算其在新数组中的位置,并放进去,这就是 resize。
当HashMap中的元素个数超过数组大小
(数组总大小 length,不是数组中个数)* loadFactor(加载因子)时,就会进行数组扩容。
loadFactor的默认值(DEFAULT_LOAD_ FACTOR)为0.75,这是一个折中的取值。
也就是说,默认情况下,数组大小(DEFAULT INITIAL CAPACITY)为16,那么当 HashMap中元素个数超过16 * 0.75=12(这个值就是代码中的 threshold值,也叫做临界值)的时候,就把数组的大小扩展为2 * 16=32,即扩大一倍,然后重新计算每个元素在数组中的位置,而这是一个非常消耗性能的操作,所以如果我们已经预知 HashMap中元素的个数,那么预设元素的个数能够有效的提高HashMap的性能。
JDK 8.0 的原理
HashMap的内部存储结构其实是数组+链表+红黑树的组合。
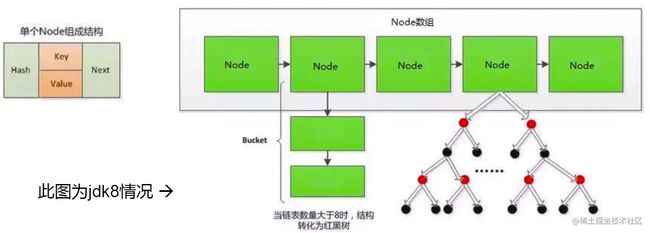
HashMap添加元素的过程:
当实例化一个HashMap时,会初始化 initialCapacity和loadFactor。
在put第一对映射关系时,系统会创建一个长度为 initialCapacity的Node数组,这个长度在哈希表中被称为容量(Capacity)。
在这个数组中可以存放元素的位置我们称之为“桶”( bucket),每个bucket都有自己的索引,系统可以根据索引快速的查找bucket中的元素。
每个 bucket中存储一个元素,即一个Node对象,但每一个Noe对象可以带个引用变量next,用于指向下一个元素,因此,在一个桶中,就有可能生成一个Node链。也可能是一个一个 TreeNode对象,每一个Tree node对象可以有两个叶子结点left和right,因此,在一个桶中,就有可能生成一个TreeNode树。而新添加的元素作为链表的last,或树的叶子结点。
HashMap的扩容机制:
- 当HashMapl中的其中一个链的对象个数没有达到8个和JDK 7.0以前的扩容方式一样。
- 当HashMapl中的其中一个链的对象个数如果达到了8个,此时如果 capacity没有达到64,那么HashMap会先扩容解决。
- 如果已经达到了64,那么这个链会变成树,结点类型由Node变成 Tree Node类型。当然,如果当映射关系被移除后,下次resize方法时判断树的结点个数低于6个,也会把树再转为链表。
JDK 8.0与JDK 7.0中HashMap底层的变化:
new HashMap():底层没有创建一个长度为16的数组
JDK 8.0底层的数组是:Node[],而非 Entry[]
首次调用put()方法时,底层创建长度为16的数组
JDK 7.0底层结构只有:数组+链表。JDK 8.0中底层结构:数组+链表+红黑树。
- 形成链表时,七上八下(jdk7:新的元素指向旧的元素。jdk8:旧的元素指向新的元素)
- 当数组的某一个索引位置上的元素以链表形式存在的数据个数 > 8 且当前数组的长度 > 64时,此时此索引位置上的所数据改为使用红黑树存储。
HashMap中内部类Node源码:
static class Node<K,V> implements Map.Entry<K,V>{
final int hash;
final K key;
V value;
Node<K,V> next;
}
LinkedHashMap中内部类Entry源码:
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;//能够记录添加的元素的先后顺序
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
HashMap底层典型属性的属性的说明:
DEFAULT_INITIAL_CAPACITY: HashMap的默认容量,16DEFAULT_LOAD_FACTOR:HashMap的默认加载因子:0.75threshold:扩容的临界值,= 容量*填充因子:16 * 0.75 => 12TREEIFY_THRESHOLD:Bucket中链表长度大于该默认值,转化为红黑树:JDK 8.0引入MIN_TREEIFY_CAPACITY:桶中的Node被树化时最小的hash表容量:64
LinkedHashMap
- LinkedHashMap底层使用的结构与HashMap相同,因为LinkedHashMap继承于HashMap.
- 区别就在于:LinkedHashMap内部提供了Entry,替换HashMap中的Node.
- 与Linkedhash Set类似,LinkedHashMap可以维护Map的迭代顺序:迭代顺序与Key-value对的插入顺序一致
代码示例:
@Test
public void test2(){
Map map = new LinkedHashMap();
map.put(123,"AA");
map.put(345,"BB");
map.put(12,"CC");
System.out.println(map);
}
复制代码
TreeMap
- TreeMap存储Key-Value对时,需要根据key-value对进行排序。TreeMap可以保证所有的 Key-Value对处于有序状态。
- TreeSet底层使用红黑树结构存储数据
- TreeMap的Key的排序:
- 自然排序: TreeMap的所有的Key必须实现Comparable接口,而且所有的Key应该是同一个类的对象,否则将会抛出ClasssCastEXception()
- 定制排序:创建 TreeMap时,传入一个 Comparator对象,该对象负责对TreeMap中的所有key进行排序。此时不需要Map的Key实现Comparable接口
- TreeMap判断两个key相等的标准:两个key通过 compareTo()方法或者compare()方法返回0.
Hashtable
- Hashtable是个古老的Map实现类,JDK1.0就提供了。不同于 HashMap,Hashtable是线程安全的.
- Hashtable实现原理和HashMap相同,功能相同。底层都使用哈希表结构,查询速度快,很多情况下可以互用
- 与HashMap不同,Hashtable不允许使用null作为key和value.
- 与HashMap一样,Hashtable也不能保证其中Key-value对的顺序.
- Hashtable判断两个key相等、两个value相等的标准,与HashMap-致.
Properties
- Properties类是Hashtable的子类,该对象用于处理属性文件
- 由于属性文件里的key、value都是字符串类型,所以Properties里的key和value都是字符串类型
- 存取数据时,建议使用
setProperty(String key,String value)方法和getProperty(String key)方法
Collections工具类的使用
1.作用:
Collections是一个操作Set、Lit和Map等集合的工具类
Collections中提供了一系列静态的方法对集合元素进行排序、査询和修改等操作,还提供了对集合对象设置不可变、对集合对象实现同步控制等方法
2.常用方法:
2.1排序操作
reverse(List):反转 List 中元素的顺序shuffle(List):对 List 集合元素进行随机排序sort(List):根据元素的自然顺序对指定 List 集合元素升序排序sort(List,Comparator):根据指定的 Comparator 产生的顺序对 List 集合元素进行排序swap(List,int, int):将指定 list 集合中的 i 处元素和 j 处元素进行交换
完结散花
ok以上就是对 【JAVA知识梳理】集合万字总结! 的全部讲解啦,很感谢你能看到这儿。如果有遗漏、错误或者有更加通俗易懂的讲解,欢迎小伙伴私信我,我后期再补充完善。
参考文献
https://javaguide.cn
https://www.acwing.com/activity/content/19/