Common Pitfalls In Machine Learning Projects
Common Pitfalls In Machine Learning Projects
In a recent presentation, Ben Hamner described the common pitfalls in machine learning projects he and his colleagues have observed during competitions on Kaggle.
The talk was titled “Machine Learning Gremlins” and was presented in February 2014 at Strata.
In this post we take a look at the pitfalls from Ben’s talk, what they look like and how to avoid them.
Machine Learning Process
Early in the talk, Ben presented a snap-shot of the process for working a machine learning problem end-to-end.
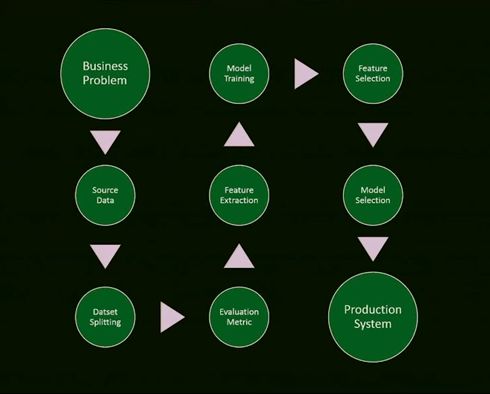
Machine Learning Process
Taken from “Machine Learning Gremlins” by Ben Hamner
This snapshot included 9 steps, as follows:
- Start with a business problem
- Source data
- Split data
- Select an evaluation metric
- Perform feature extraction
- Model Training
- Feature Selection
- Model Selection
- Production System
He commented that the process is iterative rather than linear.
He also commented that each step in this process can go wrong, derailing the whole project.
Discriminating Dogs and Cats
Ben presented a case study problem for building an automatic cat door that can let the cat in and keep the dog out. This was an instructive example as it touched on a number of key problems in working a data problem.

Discriminating Dogs and Cats
Taken from “Machine Learning Gremlins” by Ben Hamner
Sample Size
The first great takeaway from this example was that he studied accuracy of the model against data sample size and showed that more samples correlated with greater accuracy.
He then added more data until accuracy leveled off. This was a great example of understanding how easy it can be get an idea of the sensitivity of your system to sample size and adjust accordingly.
Wrong Problem
The second great takeaway from this example was that the system failed, it let in all cats in the neighborhood.
It was a clever example highlighting the importance of understanding the constraints of the problem that needs to be solved, rather than the problem that you want to solve.
Pitfalls In Machine Learning Projects
Ben went on to discuss four common pitfalls in when working on machine learning problems.
Although these problems are common, he points out that they can be identified and addressed relatively easily.
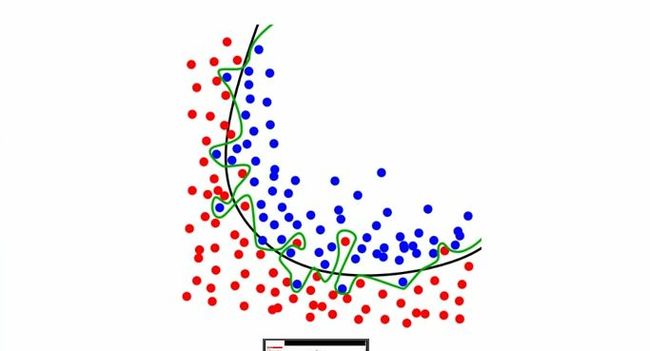
Overfitting
Taken from “Machine Learning Gremlins” by Ben Hamner
- Data Leakage: The problem of making use of data in the model to which a production system would not have access. This is particularly common in time series problems. Can also happen with data like system id’s that may indicate a class label. Run a model and take a careful look at the attributes that contribute to the success of the model. Sanity check and consider whether it makes sense. (check out the referenced paper “Leakage in Data Mining” PDF)
- Overfitting: Modeling the training data too closely such that the model also includes noise in the model. The result is poor ability to generalize. This becomes more of a problem in higher dimensions with more complex class boundaries.
- Data Sampling and Splitting: Related to data leakage, you need to very careful that the train/test/validation sets are indeed independent samples. Much thought and work is required for time series problems to ensure that you can reply data to the system chronologically and validate model accuracy.
- Data Quality: Check the consistency of your data. Ben gave an example of flight data where some aircraft were landing before taking off. Inconsistent, duplicate, and corrupt data needs to be identified and explicitly handled. It can directly hurt the modeling problem and ability of a model to generalize.
Summary
Ben’s talk “Machine Learning Gremlins” is a quick and practical talk.
You will get a useful crash course in the common pitfalls we are all susceptible to when working on a data problem.
机器学习项目中常见的误区