深度学习笔记-10.几种权重初始化方法
深度学习中神经网络的几种权重初始化方法
https://zhuanlan.zhihu.com/p/25110150
https://blog.csdn.net/attitude_yu/article/details/81458172
https://www.cnblogs.com/hutao722/p/9796884.html
目录
梯度爆炸和梯度消失的原因
一、 常数初始化(constant)
二、随机分布初始化
三、 xavier 初始化
四、He初始化
Xavier初始化和He初始化推导
Xavier初始化推导
He初始化推导
梯度爆炸和梯度消失的原因
深层网络需要一个优良的权重初始化方案,目的是降低发生梯度爆炸和梯度消失的风险。先解释下梯度爆炸和梯度消失的原因,假设我们有如下前向传播路径:
a1 = w1x + b1
z1 = σ(a1)
a2 = w2z1 + b2
z2 = σ(a2)
...
an = wnzn-1 + bn
zn = σ(an)
简化起见,令所有的b都为0,那么可得:
zn = σ(wnσ(Wn-1σ(...σ(w1x))),
若进一步简化,令z = σ(a) = a,那么可得:
zn = wn * Wn-1 * Wn-1 *...* X
而权重w的选择,假定都为1.5,那么可观察到 zn是呈现指数级递增,深层网络越深,意味着后面的值越大,呈现爆炸趋势;反之,w假定都为0.5,那么可观察到 zn是呈现指数级递减,深层网络越深,意味着后面的值越小,呈现消失趋势。
若令z = σ(a) = sigmoid(a),且a= ∑nwixi + b,其中n为输入参数的个数,当输入参数很多时,猜测|a|很大概率会大于1,对于sigmoid函数而言,|a|>1,则意味着曲线越来越平滑,z值会趋近于1或0,从而也会导致梯度消失。
那我们在每一层网络进行初始化权重时,若能给w一个合适的值,则能降低这种梯度爆炸或梯度消失的可能性吗?我们看看该如何选择。
总的框架如下,加上每个初始化代码即可运行:
def relu(Z):
"""
:param Z: Output of the linear layer
:return:
A: output of activation
"""
A = np.maximum(0,Z)
return A
def initialize_parameters(layer_dims):
"""
:param layer_dims: list,每一层单元的个数(维度)
:return:dictionary,存储参数w1,w2,...,wL,b1,...,bL
"""
np.random.seed(3)
L = len(layer_dims)#the number of layers in the network
parameters = {}
for l in range(1,L):
parameters["W" + str(l)] = np.random.randn(layer_dims[l],layer_dims[l-1])*np.sqrt(2 / layer_dims[l - 1])
parameters["b" + str(l)] = np.zeros((layer_dims[l],1))
return parameters
def forward_propagation(initialization="he"):
data = np.random.randn(1000, 100000) # 数据
layers_dims = [1000,800,500,300,200,100,10] # 每层节点个数
num_layers = len(layers_dims) # 总共7层数据
# Initialize parameters dictionary.
if initialization == "zeros":
parameters = initialize_parameters_zeros(layers_dims)
elif initialization == "random":
parameters = initialize_parameters_random(layers_dims)
elif initialization == "xavier":
parameters = initialize_parameters_xavier(layers_dims)
elif initialization == "he":
parameters = initialize_parameters_he(layers_dims)
A = data
for l in range(1,num_layers):
A_pre = A
W = parameters["W" + str(l)] # 从参数字典中获取权重
b = parameters["b" + str(l)] # 从参数字典中获取偏值
z = np.dot(W,A_pre) + b # 计算z = wx + b
# A = np.tanh(z) #relu activation function
A = relu(z) # 激活
plt.subplot(2,3,l) # 两行三列
plt.hist(A.flatten(),facecolor='g')
plt.xlim([-1,1])
plt.yticks([])
plt.show()
if __name__ == '__main__':
forward_propagation("he")目前,大部分深度学习框架都提供了各类初始化方式,其中一般常用的会有如下几种:
一、 常数初始化(constant)
把权值或者偏置初始化为一个常数,例如设置为0,偏置初始化为0较为常见,权重很少会初始化为0。tf.constant_initializer(value, dtype) 生成一个初始值为常量value的tensor对象 ,value:指定的常量, dtype:数据类型。TensorFlow中也有zeros_initializer()、ones_initializer()等特殊常数初始化函数。
下面是初始化为0的代码:
#初始化为0
def initialize_parameters_zeros(layers_dims):
"""
Arguments:
layer_dims -- python array (list) containing the size of each layer.
Returns:
parameters -- python dictionary containing your parameters "W1", "b1", ..., "WL", "bL":
W1 -- weight matrix of shape (layers_dims[1], layers_dims[0])
b1 -- bias vector of shape (layers_dims[1], 1)
...
WL -- weight matrix of shape (layers_dims[L], layers_dims[L-1])
bL -- bias vector of shape (layers_dims[L], 1)
"""
parameters = {}
L = len(layers_dims) # number of layers in the network
for l in range(1, L):
parameters['W' + str(l)] = np.zeros((layers_dims[l], layers_dims[l - 1]))
parameters['b' + str(l)] = np.zeros((layers_dims[l], 1))
return parameters经过y=w*x+b,并y'=relu(y)后的图像如下所示,可以看到从第一层开始输出值基本上为0,神经网络基本没法训练:
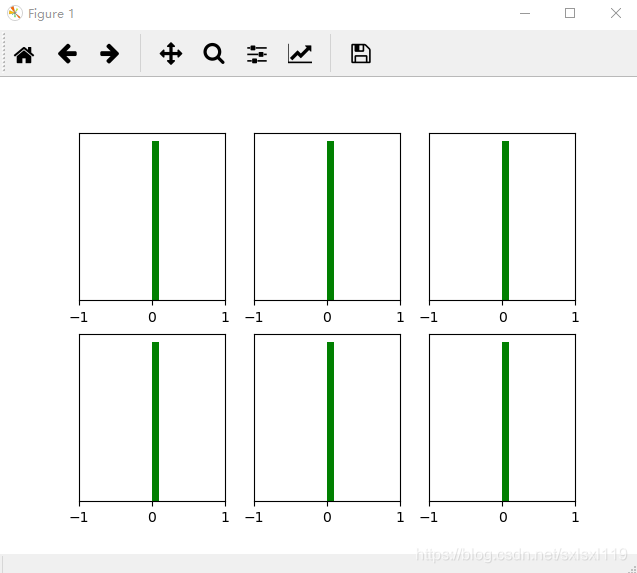
二、随机分布初始化
也叫均匀分布初始化(uniform),给定最大最小的上下限,参数会在该范围内以均匀分布方式进行初始化,常用上下限为(0,1)。先看代码:
#2,随机初始化
def initialize_parameters_random(layers_dims):
"""
Arguments:
layer_dims -- python array (list) containing the size of each layer.
Returns:
parameters -- python dictionary containing your parameters "W1", "b1", ..., "WL", "bL":
W1 -- weight matrix of shape (layers_dims[1], layers_dims[0])
b1 -- bias vector of shape (layers_dims[1], 1)
...
WL -- weight matrix of shape (layers_dims[L], layers_dims[L-1])
bL -- bias vector of shape (layers_dims[L], 1)
"""
np.random.seed(3) # This seed makes sure your "random" numbers will be the as ours
parameters = {}
L = len(layers_dims) # integer representing the number of layers
for l in range(1, L):
parameters['W' + str(l)] = np.random.randn(layers_dims[l], layers_dims[l - 1])*0.01
parameters['b' + str(l)] = np.zeros((layers_dims[l], 1))
return parameters经过y=w*x+b,并y'=relu(y)后的图像如下所示,可以看到前几层输出值还行,后几层输出值基本上为0,神经网络也基本没法训练:
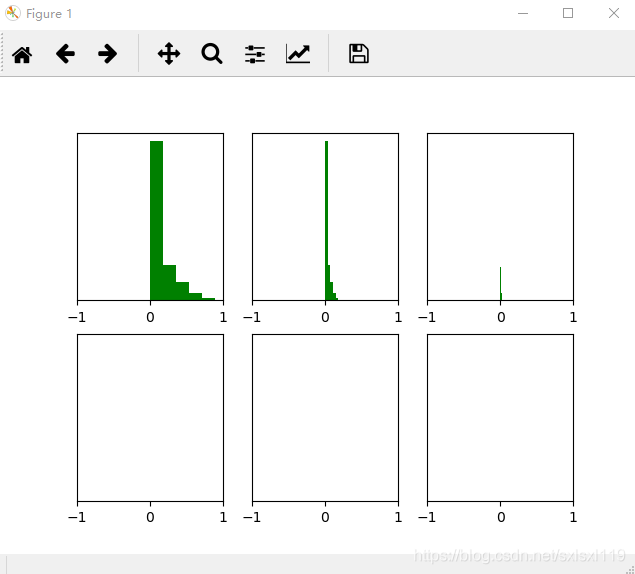
三、 xavier 初始化
在batchnorm还未出现之前,要训练较深的网络,防止梯度弥散,需要依赖非常好的初始化方式。xavier 就是一种比较优秀的初始化方式,也是目前最常用的初始化方式之一。其目的是为了使得模型各层的激活值和梯度在传播过程中的方差保持一致。
先看代码:
#3,xavier initialization
def initialize_parameters_xavier(layers_dims):
"""
Arguments:
layer_dims -- python array (list) containing the size of each layer.
Returns:
parameters -- python dictionary containing your parameters "W1", "b1", ..., "WL", "bL":
W1 -- weight matrix of shape (layers_dims[1], layers_dims[0])
b1 -- bias vector of shape (layers_dims[1], 1)
...
WL -- weight matrix of shape (layers_dims[L], layers_dims[L-1])
bL -- bias vector of shape (layers_dims[L], 1)
"""
np.random.seed(3)
parameters = {}
L = len(layers_dims) # integer representing the number of layers
for l in range(1, L):
parameters['W' + str(l)] = np.random.randn(layers_dims[l], layers_dims[l - 1]) * np.sqrt(1 / layers_dims[l - 1])
parameters['b' + str(l)] = np.zeros((layers_dims[l], 1))
return parameters经过y=w*x+b,并y'=tanh(y)后的图像如下所示,可以看到各层的输出值基本比较稳定,随着层数的增加,输出值在缓慢的向0靠拢,可以说xavier在tanh()激活函数中效果较好。
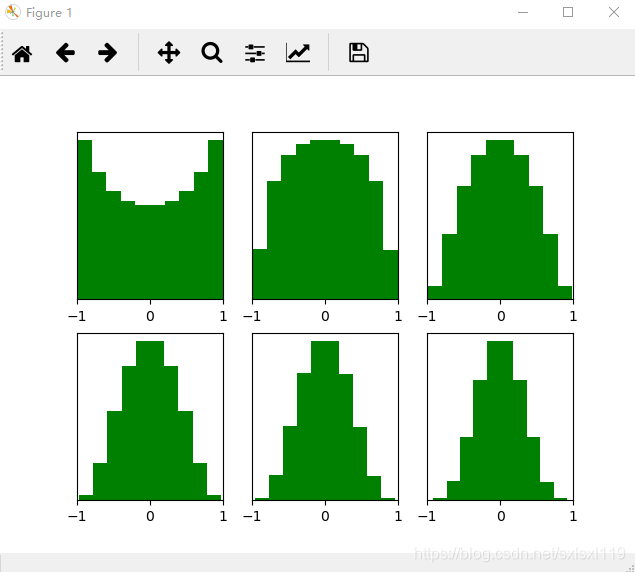
经过y=w*x+b,并y'=relu(y)后的图像如下所示,可以看到前几层输出值还行,后几层输出值变得越来越小,更深层的话很明显又会趋向于0。神经网络也基本没法训练:
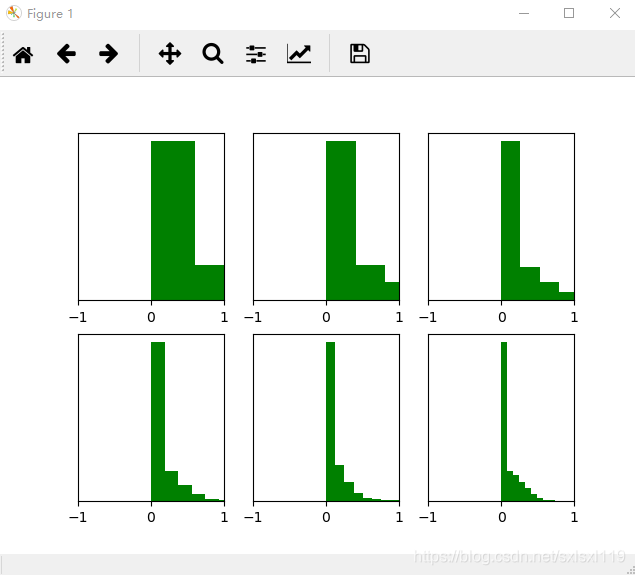
四、He初始化
Xavier在tanh中表现的很好,但在Relu激活函数中表现的很差,所何凯明提出了针对于Relu的初始化方法。
He初始化和xavier 一样都是为了防止梯度弥散而使用的初始化方式。He初始化的出现是因为xavier存在一个不成立的假设。xavier在推导中假设激活函数都是线性的,而在深度学习中常用的ReLu等都是非线性的激活函数。而He初始化本质上是高斯分布初始化,与上述高斯分布初始化有所不同,其是个满足均值为0,方差为2/n的高斯分布。
先看代码:
#4,He initialization
def initialize_parameters_he(layers_dims):
"""
Arguments:
layer_dims -- python array (list) containing the size of each layer.
Returns:
parameters -- python dictionary containing your parameters "W1", "b1", ..., "WL", "bL":
W1 -- weight matrix of shape (layers_dims[1], layers_dims[0])
b1 -- bias vector of shape (layers_dims[1], 1)
...
WL -- weight matrix of shape (layers_dims[L], layers_dims[L-1])
bL -- bias vector of shape (layers_dims[L], 1)
"""
np.random.seed(3)
parameters = {}
L = len(layers_dims) # integer representing the number of layers
for l in range(1, L):
parameters['W' + str(l)] = np.random.randn(layers_dims[l], layers_dims[l - 1]) * np.sqrt(2 / layers_dims[l - 1])
parameters['b' + str(l)] = np.zeros((layers_dims[l], 1))
return parameters经过y=w*x+b,并y'=relu(y)后的图像如下所示,可以看到各层的输出值基本比较稳定,效果是比Xavier initialization好很多。现在神经网络中,隐藏层常使用ReLU,权重初始化常用He initialization这种方法。
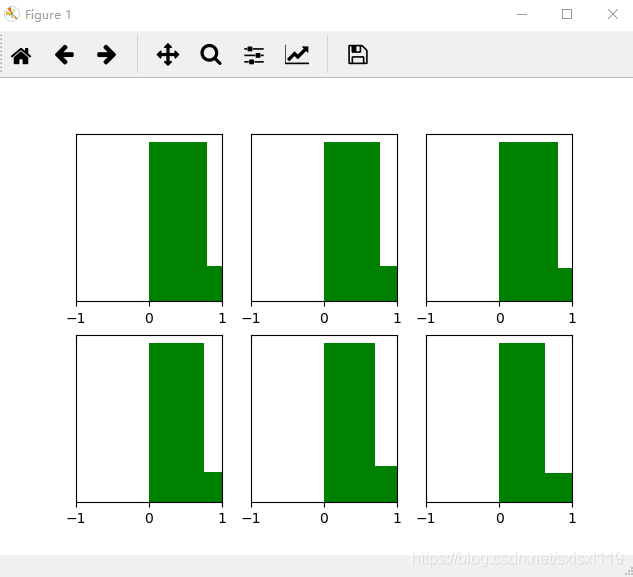
现在深度学习中常用的隐藏层激活函数是ReLU,因此常用的初始化方法就是 He initialization。
Xavier初始化和He初始化推导
下面分别说一下Xavier初始化推导和He初始化推导(不好意思,又要祭出我的手稿大法了[捂脸])
Xavier初始化推导

He初始化推导
He初始化基本思想是,当使用ReLU做为激活函数时,Xavier的效果不好,原因在于,当RelU的输入小于0时,其输出为0,相当于该神经元被关闭了,影响了输出的分布模式。
因此He初始化,在Xavier的基础上,假设每层网络有一半的神经元被关闭,于是其分布的方差也会变小。经过验证发现当对初始化值缩小一半时效果最好,故He初始化可以认为是Xavier初始/2的结果。根据上面xavier推导的公式,改为:
![]()
![]()
