Python爬虫之lxml&&BeautifulSoup库基本使用
活动地址:CSDN21天学习挑战赛
:以下是关于lxml&&BeautifulSoup库的使用
: 点击跳转到上一篇续文
快,跟我一起爬起来


目录
- 简介
-
- 解析的几种方法
- lxml库的使用✍
-
- 安装Xpath Helper插件
- lxml库的使用
-
- lxml库之Xpath(解析本地文件)的简单使用
- lxml库之Xpath(解析爬取的文件)&& Xpath插件的简单使用
- lxml库之Xpath(解析爬取的文件)&& Xpath插件的简单使用 && 下载图片
- BeautifulSoup库的使用
-
- BeautifulSoup 配合 Xpath插件爬取的产品名字
- 最后
简介
简单理解:(简单爬虫是爬取整个页面的内容)解析就是通过某种方法去得到我们想要的数据而不是全部都要。
解析的几种方法
- path
- JsonPath 点击跳转至JsonPath相关使用
- BeautifulSoup
- 正则表达式
lxml库的使用✍
安装Xpath Helper插件
Xpath Helper插件的作用:可以让我们高效解析网页内容
Xpath Helper插件安装包链接:点击跳转至GitHub
安装插件步骤:
(1)打开chrome浏览器
(2)点击右上角小圆点
(3)更多工具
(4)扩展程序
(5)拖拽xpath插件到扩展程序中
(6)关闭浏览器重新打开
(7)ctrl + shift + x
(8)出现小黑框
如下图(安装成功):
![]()
lxml库的使用
W3c中文官方:点击跳转
官方:点击跳转
使用步骤:
- 安装lxml库
pip install lxml ‐i - 导入lxml.etree
from lxml import etree - etree.parse() 解析本地文件
result = etree.parse(‘xxx.html’) - etree.HTML() 服务器响应文件
result = etree.HTML(response.read().decode(‘utf‐8’) - result .xpath(xpath路径)
xpath常用表达式(太多就不一一列出用到的时候可以去中文官方查看就可以了):
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点 |
| / | 从当前节点选取直接子节点 |
| // | 从当前节点选取子孙节点 |
| . | 选取当前节点 |
| … | 选取当前节点的父节点 |
| @ | 选取属性 |
| * | 通配符,选择所有元素节点与元素名 |
| @* | 选取所有属性 |
| [@attrib] | 选取具有给定属性的所有元素 如://@class |
| [@attrib=‘value’] | 选取给定属性具有给定值的所有元素 如://div[@id=“maincontent”] 或 //div[@id] |
| [tag] | 选取所有具有指定元素的直接子节点 |
| [tag=‘text’] | 选取所有具有指定元素并且文本内容是text节点 |
| 模糊查询 | //div[contains(@id, “he”)] 或 //div[starts‐with(@id, “he”)] |
| 内容查询 | //div/h1/text() |
| 逻辑运算 | //div[@id=“head” and @class=“s_down”] 或 //title |
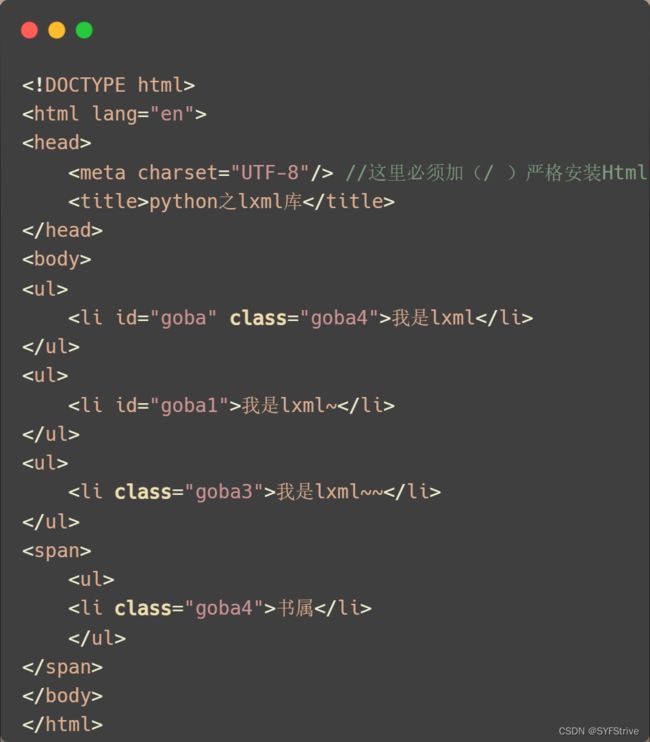
lxml库之Xpath(解析本地文件)的简单使用
模拟被解析的数据如下:
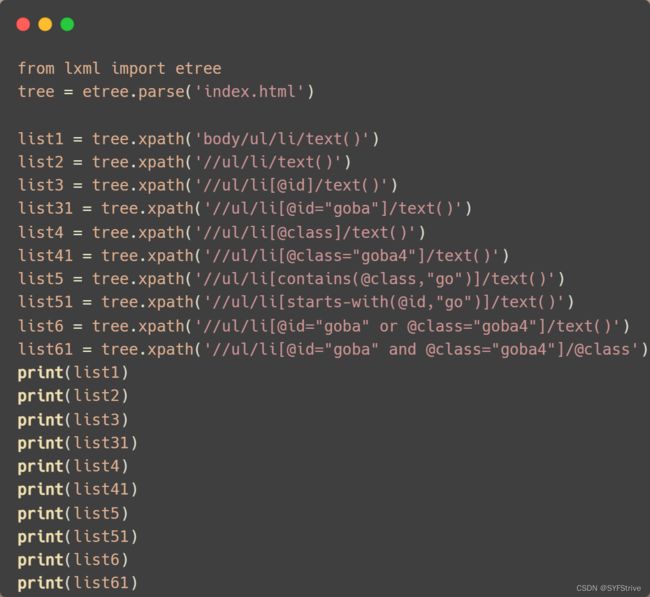
代码演示
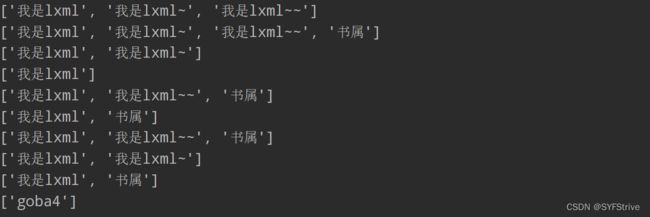
结果如下图所示:
lxml库之Xpath(解析爬取的文件)&& Xpath插件的简单使用
通过xpath获取想要的数据如://input[@id=“su”]/@value(获取一下的文字)

代码演示

如下图所属(获取数据成功):

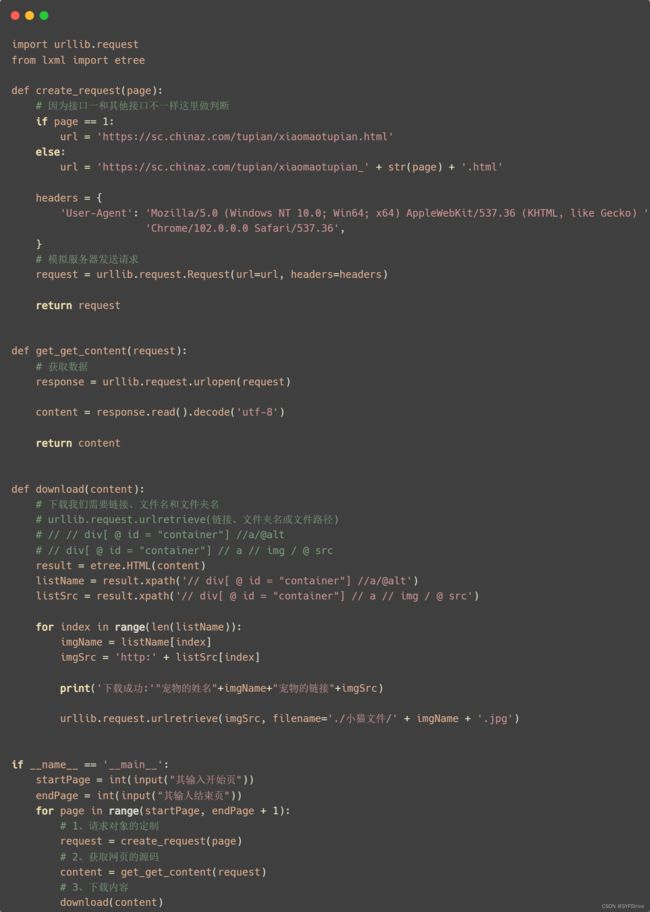
lxml库之Xpath(解析爬取的文件)&& Xpath插件的简单使用 && 下载图片
步骤如图:
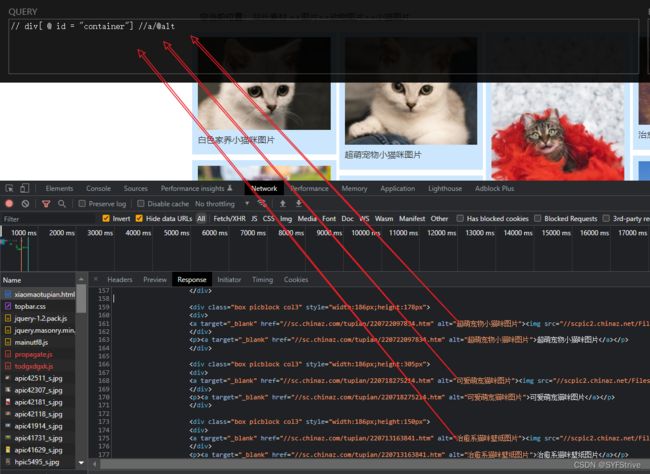
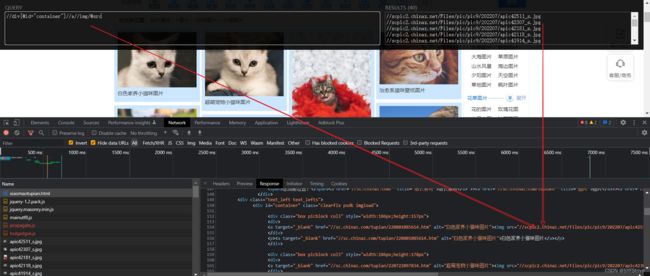
代码演示
如下图(爬取成功):
分享几张爬到的图片:








BeautifulSoup库的使用
官方:点击跳转
使用步骤:
- 安装BeautifulSoup库
pip install bs4 - 导入BeautifulSoup
from bs4 import BeautifulSoup - etree.parse() 解析本地文件
result= BeautifulSoup(open(‘1.html’), ‘lxml’) - etree.HTML() 服务器响应文件
result= BeautifulSoup(response.read( ,decode()), ‘lxml’)
⚠注意:默认打开文件的编码格式gbk所以需要指定打开编码格式
ba4常见表达式:
result= BeautifulSoup(open(‘1.html’), decode(),‘lxml’)
节点定位
1. 根据标签名查找节点
result.a【注】 只能找到第一个a
result.a.name //
result.a.attrs //获取标签的属性和属性值
2. 函数
(1).find(返回一个对象)
find(‘a’):只找到第一个a标签
find(‘a’, title = ‘名字’)
find(‘a’, class_ = ‘名字’)
(2).find_all(返回一个列表)
find_all(‘a’) 查找到所有的a
find_all([‘a’, ‘span’]) 返回所有的a和span
find_all(‘a’, limit = 2) 只找前两个a(3).select(根据选择器得到节点对象)【推荐】
1. element
eg: p
2…class
eg: .firstname
3.# id
eg: #firstname
4. 属性选择器
[attribute]
eg: li = result.select(‘li[class]’)[attribute = value]
eg: li = result.select(‘li[class=“hengheng1”]’)
5. 层级选择器
5.1、element element
div p
5.2、element > element
div > p
5.3、element, element
div, p
eg: result = result.select(‘a,span’)节点信息
(1).获取节点内容: 适用于标签中嵌套标签的结构
obj.string
obj.get_text()【推荐】
(2).节点的属性
tag.name 获取标签名
eg: tag = find('li)
print(tag.name)
tag.attrs将属性值作为一个字典返回
(3).获取节点属性
obj.attrs.get(‘title’)【常用】
obj.get(‘title’)
obj[‘title’]
模拟被解析的数据如下:
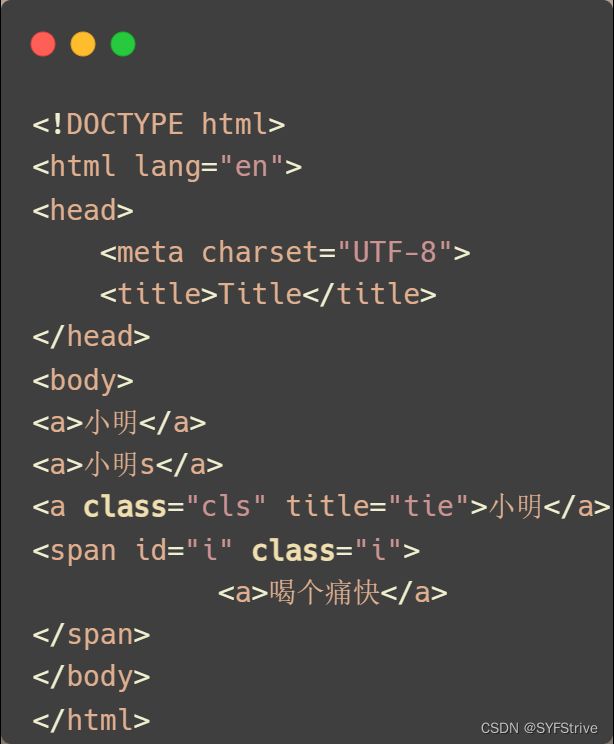
代码演示
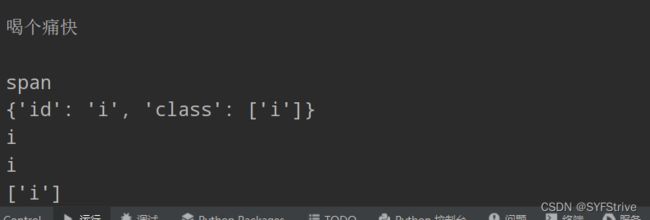
结果如下图所示:
BeautifulSoup 配合 Xpath插件爬取的产品名字
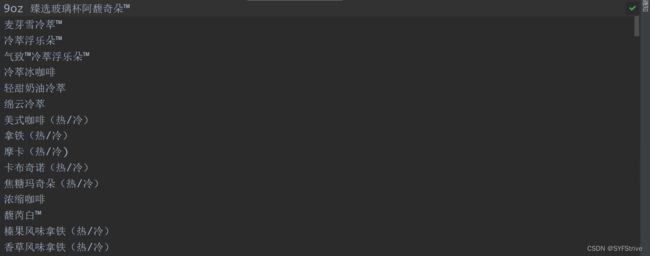
获取想要数据的步骤:先通过xpath插件获取对应的数据然后再将其转成对应的Ba4语法即可
代码演示

如下图(爬取成功):

最后
本文章到这里就结束了,觉得不错的请给我专栏点点订阅,你的支持是我们更新的动力,感谢大家的支持,希望这篇文章能帮到大家
点击跳转到我的Python专栏

下篇文章再见ヾ( ̄▽ ̄)ByeBye
