睿智的目标检测61——Tensorflow2 Focal loss详解与在YoloV4当中的实现
睿智的目标检测61——Tensorflow2 Focal loss详解与在YoloV4当中的实现
- 学习前言
- 什么是Focal Loss
-
- 一、控制正负样本的权重
- 二、控制容易分类和难分类样本的权重
- 三、两种权重控制方法合并
- 实现方式
学习前言
TF2的也补上咯。其实和Keras的一摸一样0 0。

什么是Focal Loss
Focal Loss是一种Loss计算方案。其具有两个重要的特点。
1、控制正负样本的权重
2、控制容易分类和难分类样本的权重
正负样本的概念如下:
目标检测本质上是进行密集采样,在一张图像生成成千上万的先验框(或者特征点),将真实框与部分先验框匹配,匹配上的先验框就是正样本,没有匹配上的就是负样本。
容易分类和难分类样本的概念如下:
假设存在一个二分类问题,样本1和样本2均为类别1。网络的预测结果中,样本1属于类别1的概率=0.9,样本2属于类别1的概率=0.6,前者预测的比较准确,是容易分类的样本;后者预测的不够准确,是难分类的样本。
如何实现权重控制呢,请往下看:
一、控制正负样本的权重
如下是常用的交叉熵loss,以二分类为例:
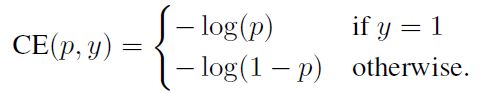
我们可以利用如下Pt简化交叉熵loss。
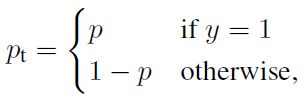
此时:

想要降低负样本的影响,可以在常规的损失函数前增加一个系数αt。与Pt类似:
当label=1的时候,αt=α;
当label=otherwise的时候,αt=1 - α。
a的范围是0到1。此时我们便可以通过设置α实现控制正负样本对loss的贡献。
分解开就是:
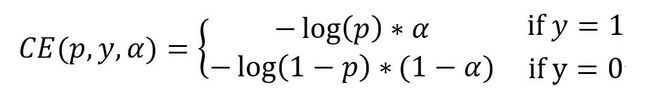
二、控制容易分类和难分类样本的权重
样本属于某个类,且预测结果中该类的概率越大,其越容易分类 ,在二分类问题中,正样本的标签为1,负样本的标签为0,p代表样本为1类的概率。
对于正样本而言,1-p的值越大,样本越难分类。
对于负样本而言,p的值越大,样本越难分类。
Pt的定义如下:
所以利用1-Pt就可以计算出每个样本属于容易分类或者难分类。
具体实现方式如下。

其中:
( 1 − p t ) γ (1-p_{t})^{γ} (1−pt)γ
就是每个样本的容易区分程度, γ γ γ称为调制系数
1、当pt趋于0的时候,调制系数趋于1,对于总的loss的贡献很大。当pt趋于1的时候,调制系数趋于0,也就是对于总的loss的贡献很小。
2、当γ=0的时候,focal loss就是传统的交叉熵损失,可以通过调整γ实现调制系数的改变。
三、两种权重控制方法合并
通过如下公式就可以实现控制正负样本的权重和控制容易分类和难分类样本的权重。
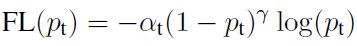
实现方式
本文以Keras版本的YoloV4为例,给大家进行解析,YoloV4的坐标如下:
https://github.com/bubbliiiing/yolov4-tf2
首先定位YoloV4中,正负样本区分的损失部分,YoloV4的损失由三部分组成,分别为:
location_loss(回归损失)
confidence_loss(目标置信度损失)
class_loss(种类损失)
正负样本区分的损失部分是confidence_loss(目标置信度损失),因此我们在这一部分添加Focal Loss。
首先定位公式中的概率p。raw_pred代表每个特征点的预测结果,取出其中属于置信度的部分,取sigmoid,就是概率p
tf.sigmoid(raw_pred[...,4:5])
首先进行正负样本的平衡,设立参数alpha。
alpha # 正样本的平衡参数
1-alpha # 负样本的平衡参数
然后进行难易分类样本的平衡,设立参数gamma。
(tf.ones_like(raw_pred[...,4:5]) - tf.sigmoid(raw_pred[...,4:5])) ** gamma # 正样本的平衡参数
tf.sigmoid(raw_pred[...,4:5]) ** gamma # 负样本的平衡参数
乘上原来的交叉熵损失即可。
confidence_loss = object_mask * (tf.ones_like(raw_pred[...,4:5]) - tf.sigmoid(raw_pred[...,4:5])) ** gamma * alpha * K.binary_crossentropy(object_mask, raw_pred[...,4:5], from_logits=True) + \
(1 - object_mask) * ignore_mask * tf.sigmoid(raw_pred[...,4:5]) ** gamma * (1 - alpha) * K.binary_crossentropy(object_mask, raw_pred[...,4:5], from_logits=True)