【自然语言处理】【向量检索】面向开放域稠密检索的多视角文档表示学习
论文地址:https://arxiv.org/pdf/2203.08372.pdf
相关博客:
【自然语言处理】【对比学习】SimCSE:基于对比学习的句向量表示
【自然语言处理】BERT-Whitening
【自然语言处理】【Pytorch】从头实现SimCSE
【自然语言处理】【向量检索】面向开发域稠密检索的多视角文档表示学习
【自然语言处理】【向量表示】AugSBERT:改善用于成对句子评分任务的Bi-Encoders的数据增强方法
【自然语言处理】【向量表示】PairSupCon:用于句子表示的成对监督对比学习
一、简介

过去几年里,随着预训练语言模型的进步,稠密检索已经成为开发域文本检索的重要且有效的方法。一个典型的稠密检索通常会采用一个双编码器架构来将query和document编码为单个低维向量,并基于它们的表示来计算相关分数。在线上场景的应用中,所有文档的嵌入向量都是提前预计算的,并且利用近似最近邻 ( ANN ) (\text{ANN}) (ANN)技术有效地提高检索过程。为了增强双编码器的能力,最近的研究仔细设计了复杂的方法来高效训练,包含构建更具有挑战性的难负样本并继续预训练语言模型。
然而,由于单个向量表示的限制,根据理论分析双编码器面临着表示能力的上界。在 SQuAD \text{SQuAD} SQuAD开发集上的真实样本中,作者发现单个向量表示不能很好的匹配多视角的query,如上图所示。一个文档对应不同视角的4个不同的问题,它们中的每个都匹配不同的句子和答案。在传统双编码器中,文档会被表示为单个向量,而它会被各种queries召回,其限制了双编码器的能力。
对于多向量模型,交叉编码器架构通过计算query-document对的深度上下文表示得到更好的表现,但是计算代价昂贵且对于大规模检索的第一阶段并不适合。一些最近的研究尝试中交叉编码器进行借鉴并通过更精细的结构来扩展编码器,其允许query和document嵌入向量间的多向量表示和稠密检索。然而,它们中的大多数包含softmax或者sum操作,其不能被分解为内积的最大值,所有 ANN \text{ANN} ANN检索不能被直接应用。
基于这些观察,作者提出了Multi-View document Representations learning framework,简称MVR。 MVR \text{MVR} MVR来源于一个观察:一个文档通常包含若干个语言单元,并且能够回答多个包含独立语义的query。这就像是给定一个特定的文档,不同的提问者会从不同的角度提出不同的问题。因此,作者提出一种简单有效的方法,即通过viewers生成多个视角的表示,通过优化具有退火温度的global-local损失函数来改善表示空间。
先前的工作发现[CLS] token倾向于聚合整个输入的含义,其与作者期望生成多视角嵌入并不一致。所以作者首先修改了双编码器架构,在文档输入中抛弃了[CLS]并添加了多个[Viewer]。最后一层的viewers表示被用于多视角表示。
为了鼓励多个viewers来更好的对齐不同潜在的queries,作者提出了一个具有退火温度的全局-局部损失函数。
二、相关工作
1. 检索器和排序器架构
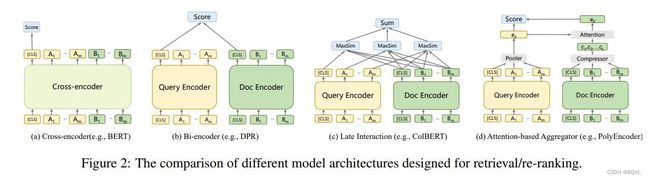
随着深度语言模型的发展,微调的预训练 BERT \text{BERT} BERT实现了非常好的re-ranking效果。最初的方式是基于re-ranker的交叉编码器,如下图 ( a ) (a) (a)所示。其会将query和document进行拼接后输入至 BERT \text{BERT} BERT,并输入[CLS]的嵌入向量来生成相关分数。受益于query-document对的深度上下文表示,深度语言模型有助于解决词汇不匹配和语义不匹配问题。然而,基于ranker的交叉编码器需要计算量昂贵的交叉注意力操作,因此其并不适合大规模第一阶段检索,其通常被用于第二阶段的重排序。
对于第一阶段检索,双编码器是目前最常用的架构,因为其能够在近似最近邻 ANN \text{ANN} ANN的支持下方便有效的使用。如下图 ( b ) (b) (b)所示,其将query和document分别输入至独立的编码器来生成单个向量表示,然后通过嵌入向量的相似度来衡量相关分数。由于采用了深度语言模型,基于retriever的双编码器实现了良好的性能。后来的研究通过不同的精心设计来进一步改善性能。
除了典型的双编码器,也存在一些变体利用基于双编码器的稠密交互。如下图 ( c ) (c) (c)所示, ColBERT \text{ColBERT} ColBERT采用后交互范式,其会计算所有term向量的点积分数,随后使用max-pooler和sum-pooler来生成相关分数。后来,Gao et al.通过仅对与倒排列表重叠的token进行评分来改善模型。另一个变体是基于注意力机制的聚合器,如下图 ( d ) (d) (d)所示。其利用注意力机制来压缩document嵌入向量来与query向量,用于生成最终的相关分数。有一些工作时建立在这个范式上的。具体来说, Poly-Encoder \text{Poly-Encoder} Poly-Encoder设置了 k k k个可学习codes来添加至document嵌入中。 DRPQ \text{DRPQ} DRPQ通过在document向量上迭代 K-means \text{K-means} K-means聚类来生成多个嵌入向量,然后通过注意力机制与query进行交互,从而实现了更好的结果。然而,稠密交互方法并不能直接应用 ANN \text{ANN} ANN,由于sum-pooler和注意力机制并不能分解为内积上的max操作,并且不能应用快速 ANN \text{ANN} ANN。所以这些方法通常会近似召回候选集,然后通过re-ranking进行细化,而 MVR \text{MVR} MVR能够直接应用在第一阶段检索。
另一个相关的方法是 ME-BERT \text{ME-BERT} ME-BERT,其采用前 k k k个文档的token嵌入向量作为文档的表示。然而,仅采用前k个嵌入向量可能会失去文档后面部分的信息,而本文的viewer tokens能够从整个文档中抽取信息。
2. 有效的稠密检索
除了前面专注在架构设计上的工作外,也有一些工作来改善稠密检索的有效性。现有的学习稠密文章检索器的方法能够被划分为两个类别:(1) 用于检索的预训练;(2) 在标注数据上微调预训练语言模型。
在第一个类别中,Lee et al.和Chang et.al提出了不同的预训练任务并证明了在稠密检索上预训练的有效性。最近, DPR-PAQ \text{DPR-PAQ} DPR-PAQ提出了领域匹配预训练,而 Condenser \text{Condenser} Condenser使用继续预训练来强制模型生成信息丰富的[CLS]表示。
对于第二类别,近期的工作展示了微调一个有效的稠密检索器的关键是难负样本。 DPR \text{DPR} DPR采用batch内负样本和 BM25 \text{BM25} BM25难负样本。 ANCE \text{ANCE} ANCE提出了在训练过程中构造难负样本。 RocketQA \text{RocketQA} RocketQA展示了交叉编码器能够过滤和挖掘高质量的难负样本。Li et al.和Ren et al.展示了以文章为中心和以query为中心的负样本能够使训练更加鲁棒。值得一提的是,从基于交叉编码器的re-ranker中蒸馏知识至双编码器retriever能够改善双编码器的效果。这些工作的大多数都是建立在双编码器上,并且天然继承了单向量表示的限制,而本文的工作修改双编码器来产生多视角嵌入,并且与这些策略正交。
三、方法
1. 前言
开始时会使用 BERT \text{BERT} BERT作为backbone网络结构,如上图 b b b所示。一个典型的双编码器采用对偶编码架构将query和document映射为单维实质向量。
给定一个 query \text{query} query q和一个文档集合 D = { d 1 , … , d j , … , d n } D=\{d_1,\dots,d_j,\dots,d_n\} D={d1,…,dj,…,dn},稠密检索会利用相同的 BERT \text{BERT} BERT编码器来获得queries和documents的表示。 query \text{query} query q和 document \text{document} document d的相似度分数 f ( q , d ) f(q,d) f(q,d)可以使用稠密表示来计算:
f ( q , d ) = s i m ( E Q ( q ) , E D ( d ) ) (1) f(q,d)=sim(E_Q(q),E_D(d)) \tag{1} f(q,d)=sim(EQ(q),ED(d))(1)
其中, s i m ( ⋅ ) sim(\cdot) sim(⋅)评估两个嵌入向量的相似度函数,例如cosine距离或者欧式距离。并且[CLS]表示的内积是被广泛使用的。
传统对比损失函数被广泛应用在训练query和passage编码器。对于给定的 query \text{query} query q,其会计算与负样本集合 { d 1 − , d 2 − , … , d l − } \{d_1^-,d_2^-,\dots,d_l^-\} {d1−,d2−,…,dl−}中正文档 d + d^+ d+的负对数似然
L = − log e f ( q , d + ) / τ e f ( q , d + ) / τ + ∑ l e f ( q , d l − ) / τ (2) \mathcal{L}=-\text{log}\frac{e^{f(q,d^+)/\tau}}{e^{f(q,d^+)/\tau}+\sum_l e^{f(q,d_l^-)/\tau}} \tag{2} L=−logef(q,d+)/τ+∑lef(q,dl−)/τef(q,d+)/τ(2)
其中, τ \tau τ是超参数,合适的 τ \tau τ有助于更好的优化。
2. 基于多查看器 (Multi-Viewer) \text{(Multi-Viewer)} (Multi-Viewer)的架构
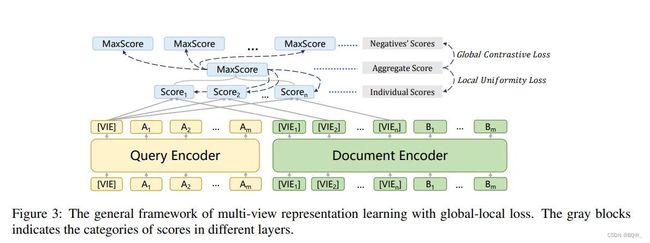
首先于单向量表示,典型的双编码器面临一个挑战:一个文档会包含多个语义,并且会被从多个视角的不同潜在queries进行查询。虽然先前的研究合并了稠密交互来允许多重表示并且提高了有效性,他们通常会导致额外的计算和复杂的结构。因此,作者提出了一种简单有效的方法,通过多查看器 (multiple viewers) \text{(multiple viewers)} (multiple viewers)来生成多视角表示。
由于预训练 BERT \text{BERT} BERT已经广泛应用于下游任务,包括句子级的任务。一些工作发现[CLS]倾向于聚合整个句子的含义。然而,本文的模型倾向于捕获一个文档中更加细粒度的语义单元,因此引入了多查看器 (multiple viewers) \text{(multiple viewers)} (multiple viewers)。作者使用新添加的多查看器tokens [VIE]来替换[CLS],其是被随机初始化。对于文档输入,在句子开始的位置添加不同的 [ VIE i ] ( i = 1 , 2 , … , n ) [\text{VIE}_i](i=1,2,\dots,n) [VIEi](i=1,2,…,n)。为了避免影响原始输入句子的位置编码,设置 [ VIE i ] [\text{VIE}_i] [VIEi]的所有位置ids为0,文档句子的tokens仍然是从1开始。然后,利用双编码器来获得queries和documents的表示
E ( q ) = Enc q ( [ V I E ] ∘ q ∘ [ S E P ] ) E ( d ) = Enc d ( [ V I E 1 ] … [ V I E n ] ∘ d ∘ [ S E P ] ) (3) E(q)=\text{Enc}_q([VIE]\circ q\circ [SEP]) \\ E(d)=\text{Enc}_d([VIE_1]\dots[VIE_n]\circ d\circ [SEP]) \tag{3} E(q)=Encq([VIE]∘q∘[SEP])E(d)=Encd([VIE1]…[VIEn]∘d∘[SEP])(3)
其中, ∘ \circ ∘是拼接操作。[VIE]和[SEP]是 BERT \text{BERT} BERT中的特殊tokens。 Enc q \text{Enc}_q Encq和 Enc d \text{Enc}_d Encd意味着query和document编码器。使用最后一层隐藏状态作为query和document的嵌入向量。
[VIE]的表示被用于查询 q q q和文档 d d d的表示,其被表示为 E 0 ( q ) E_0(q) E0(q)和 E i ( d ) ( i = 0 , 1 , … , k − 1 ) E_i(d)(i=0,1,\dots,k-1) Ei(d)(i=0,1,…,k−1)。由于query通常比document短,且代表一个具体的含义。这里保留了典型的设置来为query生成唯一的嵌入向量。
query q q q和document d d d的相似度分数 f ( q , d ) f(q,d) f(q,d)通过稠密表示来计算。如上图所示,先计算单个query嵌入向量和文档多个视角嵌入向量的Individual Scores,这里采用内积。 [ VIE i ] [\text{VIE}_i] [VIEi]对应的分数表示为 f i ( q , d ) ( i = 0 , 1 , … , k − 1 ) f_i(q,d)(i=0,1,\dots,k-1) fi(q,d)(i=0,1,…,k−1)。然后采用max-pooler来聚合这些Induividual score为Aggregate Score f ( q , d ) f(q,d) f(q,d),其作为query和document的相似分数:
f ( q , d ) = Max i { f i ( q , d ) } = Max i { s i m ( E 0 ( q ) , E i ( d ) ) } \begin{align} f(q,d)&=\mathop{\text{Max}}_i\{f_i(q,d)\} \\ &=\mathop{\text{Max}}_i\{sim(E_0(q),E_i(d))\} \tag{4} \end{align} f(q,d)=Maxi{fi(q,d)}=Maxi{sim(E0(q),Ei(d))}(4)
3. 全局-局部损失函数( Global-Local Loss \text{Global-Local Loss} Global-Local Loss)
为了鼓励多查看器更好的对齐不同的潜在query,作者引入了Global-Local损失函数来优化多视角架构的训练。其会合并全局对比损失函数和局部一致性损失函数
L = L g l o b a l + λ L l o c a l (5) \mathcal{L}=\mathcal{L}_{global}+\lambda\mathcal{L}_{local} \tag{5} L=Lglobal+λLlocal(5)
全局对比损失函数来自于传统的双编码器。给定query和一个正向文档 d + d^+ d+,以及一系列负样本 { d 1 − , d 2 − , … , d l − } \{d_1^-,d_2^-,\dots,d_l^-\} {d1−,d2−,…,dl−},其计算如下
L g l o b a l = − log e f ( q , d + ) / τ e f ( q , d + ) / τ + ∑ l e f ( q , d l − ) / τ (6) \mathcal{L}_{global}=-\text{log}\frac{e^{f(q,d^+)/\tau}}{e^{f(q,d^+)/\tau}+\sum_l e^{f(q,d_l^-)/\tau}} \tag{6} Lglobal=−logef(q,d+)/τ+∑lef(q,dl−)/τef(q,d+)/τ(6)
为了改善多视角嵌入空间的一致性,作者在不同查看器间应用局部一致性损失函数,如等式 ( 7 ) (7) (7)。对于一个具体的query,多视角文档表示之一将会与等式 ( 4 ) (4) (4)中的max-score匹配。局部一致性损失函数强制选择的查看器与query更紧密的对齐,并且区别于其他的查看器
L l o c a l = − log e f ( q , d + ) / τ ∑ k e f i ( q , d + ) / τ (7) \mathcal{L}_{local}=-\text{log}\frac{e^{f(q,d^+)/\tau}}{\sum_k e^{f_i(q,d^+)/\tau}} \tag{7} Llocal=−log∑kefi(q,d+)/τef(q,d+)/τ(7)
为了进一步鼓励更多的不同查看器被激活,作者采用了等式 ( 8 ) (8) (8)的退化温度,来逐步调整查看器softmax分布的陡峭性。训练开始阶段具有高temperature,查看器的softmax值倾向于均匀分布,为了使查看器被公平选择并从训练数据中获得梯度的反馈。在训练过程中,temperature逐步减低使得优化更加稳定
τ = m a x { 0.3 , e x p ( − α t ) } (8) \tau=max\{0.3,exp(-\alpha t)\} \tag{8} τ=max{0.3,exp(−αt)}(8)
其中, α \alpha α是控制退火速度的超参数, t t t表示训练的 epochs \text{epochs} epochs,每个 epoch \text{epoch} epoch的temperature更新。为了简化设置,在 L l o c a l \mathcal{L}_{local} Llocal和 L g l o b a l \mathcal{L}_{global} Lglobal中使用相同的退火稳定,并且实验验证了退火温度主要与多个查看器的 L l o c a l \mathcal{L}_{local} Llocal相关联。
在推断过程中,为文档的所有查看器嵌入向量建立索引,并且模型利用 ANN \text{ANN} ANN技术直接从建立的索引上进行检索。然而, Poly-Encoder \text{Poly-Encoder} Poly-Encoder和 DRPQ \text{DRPQ} DRPQ采用包含softmax和sum操作的基于注意力的聚合器,以至于快速 ANN \text{ANN} ANN不能直接被应用。虽然 DRPQ \text{DRPQ} DRPQ提出了近似softmax,其仍然需要先召回候选集合,然后使用复杂的聚合器进行重排序,导致了昂贵的计算和复杂的处理过程。相反, MVR \text{MVR} MVR不需要后处理就能直接应用在第一阶段检索。尽管索引的规模会随着查看器数量 k k k的增长而增长,但是由于 ANN \text{ANN} ANN技术的有效性,时间复杂度是索引尺寸的次线性。