【目标检测】(15) YOLOV4 损失函数,附TensorFlow完整代码
大家好,今天和各位分享一下 YOLOV4 的损失函数的构建方法,YOLOV4和损失函数的组成和YOLOV3类似,只是YOLOV4使用了CIOU损失作为目标边界框的定位损失。强烈建议大家在阅读本文之前,先看以下文章:
预测框解码,调整先验框:https://blog.csdn.net/dgvv4/article/details/124076352
预测框定位损失,各种 iou:https://blog.csdn.net/dgvv4/article/details/124039111
1. 损失函数介绍
1.1 预测框的正负样本
网络生成的预测框分为三种情况:正样本、负样本、忽略部分
正样本:负责预测目标物体。物体的真实标签框的中心点落在某个网格中,该物体就是由该网格生成的三个先验框中,和真实标签框的 iou 交并比最大的那个先验框去预测,不断拟合逼近标签框。其他网格和先验框都不负责该物体。因此,把生成的预测框中,与标签框iou最大的那个预测框,作为正样本。
负样本:图像背景。计算各个预测框和所有的真实标签框之间的 iou 交并比,如果某先验框和图像中所有物体的标签框的最大的IOU都小于阈值(一般0.5),那么就认为该先验框不含目标,记作负样本,其置信度应当为0。
忽略部分:将预测框和标签框的iou大于阈值0.5,但iou不是最大的那些预测框忽略掉。
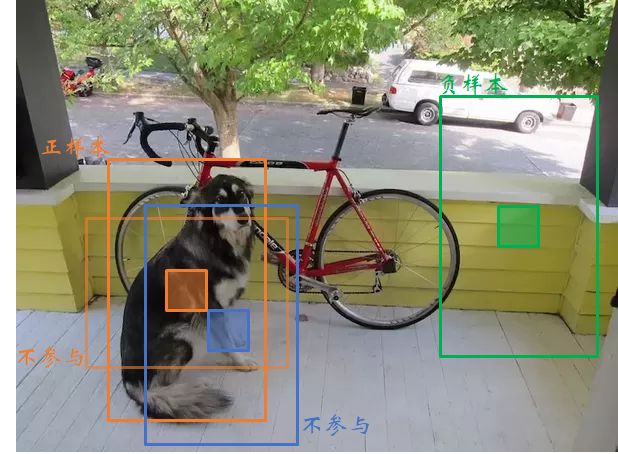
因此在YOLOV3中产生损失函数的只有正样本和负样本。正样本有坐标损失函数、置信度损失函数、类别损失函数,而负样本只有置信度损失函数。
1.2 损失函数公式
YOLOV3 损失函数的公式如下:
 代表遍历 S*S 个网格,遍历每个网格生成的 B 个预测框。该式子代表遍历所有预测框
代表遍历 S*S 个网格,遍历每个网格生成的 B 个预测框。该式子代表遍历所有预测框
(1)正样本的坐标损失函数。计算正样本预测框和标签框之间的中心点坐标偏差,和宽高偏差。
(2)正样本置信度损失函数 ![]() ,正样本预测框的置信度越接近1,该损失就越接近0。
,正样本预测框的置信度越接近1,该损失就越接近0。
正样本类别损失函数 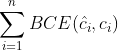 ,对每个正样本预测框,逐类别和标签框计算二元交叉熵损失函数。预测值越接近1,损失函数越小
,对每个正样本预测框,逐类别和标签框计算二元交叉熵损失函数。预测值越接近1,损失函数越小
(3)负样本置信度损失函数 ![]() ,负样本即图片中的背景部分,置信度越接近0,损失函数越小。
,负样本即图片中的背景部分,置信度越接近0,损失函数越小。

2. 代码展示
iou 交并比和 Ciou损失的理论部分我已经在之前的文章中详述过了,这里就简单复习一下,有疑惑的看上面的链接。
2.1 iou 交并比
iou 是指预测框和真实框的 交集和并集的比值,无论边界框的尺度大小,输出的 iou 总是在0到1之间,因此能够比较好的反映预测框和真实框之间的检测效果。如下图。iou值越大,表明两个框的重叠程度越高。当iou为0时,两个框一点也没有重合部分,当iou为1时,说明两个框完全重合。

代码如下,命名为 iou.py
输入参数:box1代表预测框信息,shape=[b, w, h, num_anchor, 4],其中4代表预测框的中心点坐标和宽高。box2代表标签框信息,shape=[b, w, h, num_anchor, 4],其中4代表标签框的中心点坐标和宽高。
输出结果:iou交并比,shape=[b, w, h, num_anchor, 1],代表每个网格生成的num_anchors个预测框,每个预测框有一个iou交并比
import tensorflow as tf
#(1)定义iou损失
def IOU(box1, box2):
# 接收预测框的坐标信息
box1_xy = box1[..., :2] # 处理所有batch所有图片的检测框,中心坐标
box1_wh = box1[..., 2:4] # 所有图片的宽高
box1_wh_half = box1_wh // 2 # 一半的宽高
box1_min = box1_xy - box1_wh_half # 左上角坐标
box1_max = box1_xy + box1_wh_half # 右下角坐标
# 接收真实框的左上和右下坐标, 方法和上面一样
box2_xy = box2[..., :2]
box2_wh = box2[..., 2:4]
box2_wh_half = box2_wh // 2
box2_min = box2_xy - box2_wh_half
box2_max = box2_xy + box2_wh_half
# 预测框的面积
box1_area = box1_wh[..., 0] * box1_wh[..., 1]
# 真实框的面积
box2_area = box2_wh[..., 0] * box2_wh[..., 1]
# 找出交集区域的xy坐标
intersect_min = tf.maximum(box1_min, box2_min) # 交集的左上角坐标
intersect_max = tf.minimum(box1_max, box2_max) # 交集的右下角坐标
# 所有图片的交集区域的宽和高,如果两个框分离,宽高就是0
intersect_wh = tf.maximum(intersect_max - intersect_min, 0)
# 计算交集区域面积
intersect_area = intersect_wh[..., 0] * intersect_wh[..., 1]
# 计算并集区域面积
union_area = box1_area + box2_area - intersect_area
# 计算交并比,分母加上一个很小的数防止为0
iou = intersect_area / (union_area + tf.keras.backend.epsilon())
# 维度扩充[b, w, h, num_anchor]==>[b, w, h, num_anchor,1]
iou = tf.expand_dims(iou, axis=-1)
return iou2.2 Ciou交并比
Ciou交并比在iou计算重叠面积的基础上引入了中心点距离和长宽比。

长宽比公式如下,其中 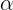 代表权衡因子,
代表权衡因子,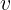 用来评定纵横比的统一性。
用来评定纵横比的统一性。

Ciou损失计算公式如下:b 代表预测框的中心点坐标,b_gt 代表真实框的中心点坐标, 代表两个中心点之间的欧式距离,c 代表两个目标边界框外接矩形的对角线的长度。
代表两个中心点之间的欧式距离,c 代表两个目标边界框外接矩形的对角线的长度。

代码如下,命名为 Ciou.py
'''
参数
box1: 输入的预测框信息, [b, w, h, num_anchor, 4], 其中4代表该框的中心坐标xy和宽高wh
box2: 输入的真实框信息, [b, w, h, num_anchor, 4], 其中4代表该框的中心坐标xy和宽高wh
返回值
Ciou: 输出的每个预测框的CIOU值, [b, w, h, num_anchor, 1], 其中1代表Ciou值
'''
import tensorflow as tf
import math
#(1)定义CIOU计算方法
def CIOU(box1, box2):
# ① 先计算iou
# 接收预测框的坐标信息
box1_xy = box1[..., 0:2] # 预测框的中心坐标
box1_wh = box1[..., 2:4] # 预测框的宽高
box1_wh_half = box1_wh // 2 # 一半的预测框的宽高
box1_min = box1_xy - box1_wh_half # 预测框的左上角坐标
box1_max = box1_xy + box1_wh_half # 预测框的右下角坐标
# 预测框的面积
box1_area = box1_wh[..., 0] * box1_wh[..., 1]
# 接收真实框的坐标信息
box2_xy = box2[..., 0:2] # 真实框的中心坐标
box2_wh = box2[..., 2:4] # 真实框的宽高
box2_wh_half = box2_wh // 2 # 一半的宽高
box2_min = box2_xy - box2_wh_half # 真实框的左上角坐标
box2_max = box2_xy + box2_wh_half # 真实框的右下角坐标
# 真实框的面积
box2_area = box2_wh[..., 0] * box2_wh[..., 1]
# 交集的左上角和右下角坐标
intersect_min = tf.maximum(box1_min, box2_min)
intersect_max = tf.minimum(box1_max, box2_max)
# 交集的宽高
intersect_wh = intersect_max - intersect_min
# 交集的面积
intersect_area = intersect_wh[..., 0] * intersect_wh[..., 1]
# 并集的面积
union_area = box1_area + box2_area - intersect_area
# 计算iou,分母加上很小的数防止为0
iou = intersect_area / (union_area + tf.keras.backend.epsilon())
# ② 求出包含两个框的最小封闭矩形
enclose_min = tf.minimum(box1_min, box2_min) # 左上坐标
enclose_max = tf.maximum(box1_max, box2_max) # 右下坐标
# 计算对角线距离
enclose_distance = tf.reduce_sum(tf.square(enclose_max - enclose_min), axis=-1)
# 计算两个框中心点之间的距离,计算方法同上
center_distance = tf.reduce_sum(tf.square(box1_xy - box2_xy), axis=-1)
# ③ 考虑长宽比
# tf.math.atan2()返回[-pi, pi]之间的角度
v = 4 * tf.square(tf.math.atan2(box1_wh[..., 0], box1_wh[..., 1]) - tf.math.atan2(box2_wh[..., 0], box2_wh[..., 1])) / (math.pi * math.pi)
alpha = v / (1.0 - iou + v)
# 计算ciou
ciou = iou - center_distance / enclose_distance - alpha * v
# 维度扩充[b, w, h, num_anchor]==>[b, w, h, num_anchor,1]
ciou = tf.expand_dims(ciou, axis=-1)
return ciou2.3 预测框解码,微调先验框
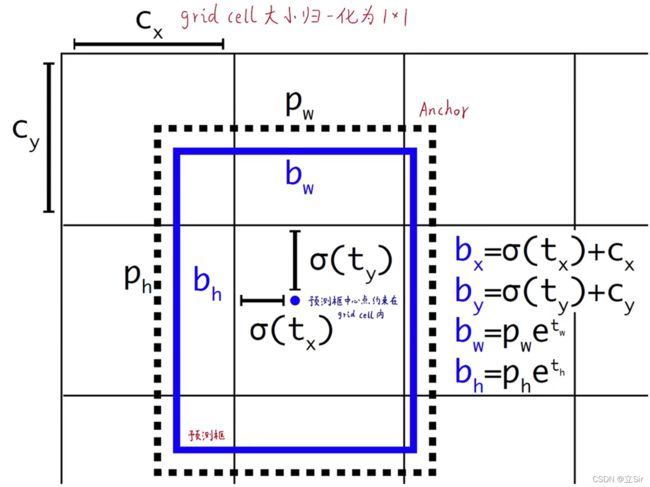
以某个网格的先验框的调整为例,如下图所示,虚线框代表:和物体的真实标签框 iou 值最大的那个先验框,该先验框的宽高为(pw, ph);蓝色框代表微调先验框后生成的预测框。
(cx,cy)是先验框中心点所在的网格的左上坐标(归一化后的坐标),由于坐标偏移量 (tx,ty) 可以是从负无穷到正无穷的任何数,为了防止坐标调整偏移过大,给偏移量添加sigmoid函数。将坐标偏移量限制在0-1之间,将预测框的中心点限制在它所在的网格内。高宽偏移量 (tw, th) 是归一化后的宽高调整值。最终预测框的宽高 (bw, bh)
代码如下,命名为 anchors.py
import tensorflow as tf
#(一)解码网络的输出层的信息
def anchors_decode(feats, anchors, num_classes, input_shape):
'''
feats是某一个特征层的输出结果, 如shape=[b, 13, 13, 3*(5+num_classes)]
anchors代表每个特征层, 每个特征点的三个先验框[3,2]
num_classes代表分类类别的数量
input_shape网络输入图像高宽[416,416]
'''
# 计算每个网格几个先验框=3
num_anchors = len(anchors)
# 获得图像网格的宽和高的shape=[h,w]=[13,13]
grid_shape = feats.shape[1:3]
#(1)获得网格中每个网格点的坐标信息
# 获得网格点的x坐标信息[1]==>[1,13,1,1]
grid_x = tf.reshape(range(0, grid_shape[1]), shape=[1,-1,1,1])
# 在y维度上扩张,将前面的数据进行复制然后直接接在原数据后面
# [1,13,1,1]==>[13,13,3,1]
grid_x = tf.tile(grid_x, [grid_shape[0], 1, num_anchors, 1])
# 获得网格点的y坐标信息,方法同上[13]==>[13,1,1,1]
grid_y = tf.reshape(range(0, grid_shape[0]), shape=[-1,1,1,1])
# 维度扩张[13,1,1,1]==>[13,13,3,1]
grid_y = tf.tile(grid_y, [1, grid_shape[1], num_anchors, 1])
# 在通道维度上合并[13,13,3,2],每个网格的坐标信息, 横纵坐标都是0-12,
grid = tf.concat([grid_x, grid_y], axis=-1)
# 转换成tf.float32类型
grid = tf.cast(grid, tf.float32)
#(2)调整先验框的信息,13*13个网格,每个网格有3个先验框,每个先验框有(x,y)坐标
# [3,2]==>[1,1,3,2]
anchors_tensor = tf.reshape(anchors, shape=[1,1,num_anchors,2])
# [1,1,3,2]==>[13,13,3,2]
anchors_tensor = tf.tile(anchors_tensor, [grid_shape[0], grid_shape[1], 1, 1])
# 转换成float32类型
anchors_tensor = tf.cast(anchors_tensor, tf.float32)
#(3)调整网络输出特征图的结果
# [b, 13, 13, 3*(5+num_classes)] = [b, 13, 13, 3, (5+num_classes)]
'''
代表13*13个网格, 每个网格有3个先验框, 每个先验框有(5+num_classes)项信息
其中, 5代表: 中心点坐标(x,y), 宽高(w,h), 置信度c
num_classes: 检测框属于某个类别的条件概率, VOC数据集中等于20
'''
feats = tf.reshape(feats, shape=[-1, grid_shape[0], grid_shape[1], num_anchors, 5+num_classes])
#(4)调整先验框中心坐标及宽高
# 对预测框中心点坐标归一化处理,只能在所处的网格中调整
anchor_xy = tf.nn.sigmoid(feats[..., :2])
box_xy = anchor_xy + grid # 每个网格的预测框坐标
# 将每个坐标归一化, 从range(0,13)变成0-1之间
box_xy = box_xy / tf.cast(grid_shape[::-1], dtype=feats.dtype)
# 网格的预测框宽高默认是归一化之后的,对宽高取指数
anchors_wh = tf.exp(feats[..., 2:4])
box_wh = anchors_wh * anchors_tensor # 预测框的宽高
# 将宽高的值归一化, 从416变到0-1之间
box_wh = box_wh / tf.cast(input_shape[::-1], dtype=feats.dtype)
# 返回预测框信息
return feats, box_xy, box_wh2.4 YOLOV4 损失函数
代码如下,我已经把注释都标注好了,根据公式计算置信度损失、分类损失、定位损失。一定要注意正负样本取值。文中的注释都是以网络的第三个有效输出层[b,13,13,3*(5+num_classes)]为例的。如果大家发现代码有错,请及时在评论区指出来
import numpy as np
import tensorflow as tf
from iou import IOU # 导入两个框的iou计算方法
from Ciou import CIOU # 导入两个框的Ciou计算方法
from anchors import anchors_decode # 先验框解码调整,得到归一化的坐标和宽高
'''
# 定义损失函数计算方法
# ---------------------------------------------------------------------- #
# features: 列表, [outputs_1, outputs_2, outputs_3, y_true1, y_true2, y_true3]
# outputs 网络输出的三个有效特征层: (b,13,13,num_anchors*(5+num_classes))大目标, (b,26,26,num_anchors*(5+num_classes))中目标, (b,52,52,num_anchors*(5+num_classes))小目标
# y_true 每个特征层对应的标签框: (b,13,13,num_anchors,5+num_classes)大目标, (b,26,26,num_anchors,5+num_classes)中目标, (b,52,52,num_anchors,5+num_classes)小目标
# input_shape: 网络的输入特征图的尺寸, (h,w)=(416,416)
# anchors: 每个网格生成的9个先验框的尺寸
# 每个特征层的三个先验框对应先验框列表中的索引
# num_classes: 分类的类别个数
# ignore_thresh: 算各个先验框和所有的目标ground truth之间的IOU, 如果某先验框和图像中所有物体最大的IOU都小于阈值(一般0.5),那么就认为该先验框不含目标,记作负样本,其置信度应当为0。
# 剩下的参数就是损失计算公式里面的权重参数
# ---------------------------------------------------------------------- #
'''
def yolo_loss(features, input_shape, anchors, anchors_mask, num_classes, ignore_thresh=0.5,
box_ratio=0.05, balance=[0.4,1.0,4.0], obj_ratio=1.0, cls_ratio=0.125):
# 从输入特征中提取三个有效输出层,以及真实标签框
outputs = features[:3]
y_true = features[3:]
# 将输入特征图的高宽转换为tensor类型, (h,w)=(416,416)
input_shape = tf.cast(input_shape, outputs[0].dtype)
# 初始化损失函数值=0
loss = 0
# 遍历三个有效特征层
for layer in range(3):
# -------------------------------------------------------------------- #
# 取出某个特征层的所有真实标签框是否包含物体的置信度c,有物体c=1,没有c=0
# 特征层(b,13,13,num_anchors,5+num_classes)中最后一维的5代表中心坐标(x,y)宽高(w,h)置信度c
# shape从[b,13,13,num_anchors,5+num_classes]变成[b,13,13,num_anchors,1]
# -------------------------------------------------------------------- #
object_mask = y_true[layer][..., 4:5]
# 取出某个特征层的所有真实标签框所包含物体的类别的条件概率
true_class_probs = y_true[layer][..., 5:]
# ---------------------------------------------------- #
# 对网络的某个预测输出特征层解码,获得该特征层的预测框信息
# anchors[anchors_mask[layer]]代表某个特征层的三个先验框的(h,w)
# raw_pred: 调整后的某个特征层,[b, 13, 13, num_anchors*(5+num_classes)] => [b, 13, 13, num_anchors, (5+num_classes)]
# box_xy: 解码后的预测框的中心点坐标,已归一化
# box_wh: 解码后的预测框的宽高,已归一化
# ---------------------------------------------------- #
raw_pred, box_xy, box_wh = anchors_decode(outputs[layer], anchors[anchors_mask[layer]], num_classes, input_shape)
# ---------------------------------------------------- #
# 将每个网格生成的预测框位置信息保存在一起
# box_xy: [b, 13, 13, 3, 2], box_wh: [b, 13, 13, 3, 2]
# pred_box: [b, 13, 13, 3, 4]
# ---------------------------------------------------- #
pred_box = tf.concat([box_xy, box_wh], axis=-1)
'''
Loss计算中, 主要包含正样本, 负样本, 以及不参与计算loss的部分.
# ---------------------------------------------------- #
# 正样本: 负责预测目标:
# 首先计算目标中心点落在哪个网格上,然后计算这个网格的9个先验框和目标真实位置的IOU值,取IOU值最大的先验框和目标匹配。其余的先验框都不负责。
# ---------------------------------------------------- #
# 负样本: 代表图像背景:
# 计算各个先验框和所有的目标真实框之间的IOU, 如果某先验框和图像中所有物体最大的IOU都小于阈值(一般0.5), 那么就认为该先验框不含目标, 记作负样本, 其置信度应当为0
# ---------------------------------------------------- #
# 不参与计算部分: IOU超过阈值ignore_thresh但不是最大的一部分
# 这部分虽然不负责预测对象, 但IOU较大, 可以认为包含了目标的一部分, 不可简单当作负样本, 所以这部分不参与误差计算。
'''
# ---------------------------------------------------- #
# 计算预测框和标签框的iou
# pred_box和true_box的shape=[b,13,13,3,4]
# 输出iou的shape=[b,13,13,3,1]
# 找出每个网格的三个预测框中,与标签框的iou的最大值
# best_iou的shape=[b,13,13,3] 代表13*13个网格,每个网格包含三个预测框的最大iou
# ---------------------------------------------------- #
# 取出所有标签框的位置信息(x,y,w,h)
true_box = y_true[layer][..., 0:4]
# 计算两个框的交并比
iou = IOU(pred_box, true_box)
# 找出每个网格的三个先验框中,预测框和真实框的最大的iou
best_iou = tf.reduce_max(iou, axis=-1)
# ---------------------------------------------------- #
# 负样本部分[b,13,13,3]
# 判断两个框的最大iou是否小于阈值,如果小于,那么认为该预测框没有与之对应的真实框
# 如果某先验框和图像中所有物体最大的IOU都小于阈值(一般0.5),那么就认为该先验框不含目标,记作负样本,其置信度应当为0。
# 记录负样本框, 从bool类型转换成float类型
# ---------------------------------------------------- #
ignore_mask = tf.cast(best_iou < ignore_thresh, dtype=true_box.dtype)
# ignore_mask 用于提取所有的负样本和不参与计算部分的框,维度扩充
# [b,13,13,3]==>[b,13,13,3,1]
ignore_mask = tf.expand_dims(ignore_mask, axis=-1)
# ---------------------------------------------------- #
# 计算ciou损失, 即目标边界框定位损失
# ---------------------------------------------------- #
# 计算预测框和标签框的Ciou交并比 [b,13,13,3,1]
ciou = CIOU(pred_box, true_box)
# 计算ciou损失, 预测框置信度*(1-ciou交并比)
ciou_loss = object_mask * (1-ciou)
# ciou损失值求和
location_loss = tf.reduce_sum(ciou_loss)
# ---------------------------------------------------- #
# 计算置信度损失 [b,13,13,3,1]
# ---------------------------------------------------- #
# object_mask代表某个特征层的所有真实标签框是否包含物体的置信度c,有物体c=1,没有c=0
# raw_pred[4:5]代表某个特征层所有预测框的置信度
# ---------------------------------------------------- #
#(1)如果该位置本来有标签框,那么计算1与预测框置信度的交叉熵
#(2)如果该位置本来没有标签框,那么计算0与预测框置信度的交叉熵
# 其中(2)也会删除一部分样本,这些被忽略的样本满足条件best_iou[所有置信度为1的标签框个数], 如果一个正样本都没有就为1
# 负样本数同理,所有置信度为0的标签框个数,还包含不参与计算的部分best_iou 构造网络输出层和真实标签,验证代码
if __name__ == '__main__':
# 网络输出的三个有效特征层
feat1 = tf.fill([4, 16, 16, 3*25], 50.0)
feat2 = tf.fill([4, 16, 16, 3*25], 50.0)
feat3 = tf.fill([4, 16, 16, 3*25], 50.0)
# 真实标签框
true1 = tf.fill([4, 16, 16, 3, 25], 40.0)
true2 = tf.fill([4, 16, 16, 3, 25], 40.0)
true3 = tf.fill([4, 16, 16, 3, 25], 40.0)
# 组合输入特征
features = [feat1, feat2, feat3, true1, true2, true3]
# 输入特征图尺寸[h,w]
input_shape = [416,416]
# 先验框
anchors = np.array([[12, 16], [19, 36], [40, 28], [36, 75], [76, 55], [72, 146], [142, 110], [192, 243], [459, 401]])
# 每个特征层对应的三个先验框的索引
anchors_mask = [[6,7,8], [3,4,5], [0,1,2]]
# 计算损失
loss = yolo_loss(features, input_shape, anchors, anchors_mask, num_classes=20)
print(loss) # tf.Tensor(-994.3477, shape=(), dtype=float32)