YoloV5代码详细解读
本文重点描述开源YoloV5代码实现的细节,不会对YoloV5的整体思路进行介绍,整体思路可以参考江大白的博客
江大白:深入浅出Yolo系列之Yolov3&Yolov4&Yolov5&Yolox核心基础知识完整讲解2644 赞同 · 332 评论文章正在上传…重新上传取消
讲解的很细致,建议阅读之后再来看本篇文章。
声明:本文有些图摘自江大白的上述博客,如有侵权,请联系本人删除
本文所使用的代码为2021-08-23日flok的官网YoloV5代码仓
GitHub - xuanzhangyang/yolov5: YOLOv5 in PyTorch > ONNX > CoreML > TFLitegithub.com/xuanzhangyang/yolov5正在上传…重新上传取消
(又发现一篇还不错的介绍 进击的后浪yolov5深度可视化解析 - 知乎)
一、数据集相关代码解读
create_dataloader函数代码解读(utils/datasets.py)
该函数在train.py的205和215行调用,分别用来创建训练数据集的loader和评估数据集的loader。
def create_dataloader(path, imgsz, batch_size, stride, single_cls=False, hyp=None, augment=False, cache=False, pad=0.0,
rect=False, rank=-1, workers=8, image_weights=False, quad=False, prefix=''):
# Make sure only the first process in DDP process the dataset first, and the following others can use the cache
with torch_distributed_zero_first(rank):torch_distributed_zero_first函数的作用是只有主进程来加载数据,其他进程处于等待状态直到主进程加载完数据,该函数具体实现说明参考下面的torch_distributed_zero_first函数解读
dataset = LoadImagesAndLabels(path, imgsz, batch_size,
augment=augment, # augment images
hyp=hyp, # augmentation hyperparameters
rect=rect, # rectangular training
cache_images=cache,
single_cls=single_cls,
stride=int(stride),
pad=pad,
image_weights=image_weights,
prefix=prefix)
LoadImagesAndLabels函数加载数据集,该函数具体实现说明参考下面的LoadImagesAndLabels类代码解读
batch_size = min(batch_size, len(dataset))
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, workers]) # number of workers
sampler = torch.utils.data.distributed.DistributedSampler(dataset) if rank != -1 else None
loader = torch.utils.data.DataLoader if image_weights else InfiniteDataLoader
# Use torch.utils.data.DataLoader() if dataset.properties will update during training else InfiniteDataLoader()
dataloader = loader(dataset,
batch_size=batch_size,
num_workers=nw,
sampler=sampler,
pin_memory=True,
collate_fn=LoadImagesAndLabels.collate_fn4 if quad else LoadImagesAndLabels.collate_fn)
return dataloader, datasettorch_distributed_zero_first函数解读(utils/torch_utils.py)
pytorch在分布式训练过程中,对于数据的读取是采用主进程预读取并缓存,然后其它进程从缓存中读取,不同进程之间的数据同步具体通过torch.distributed.barrier()实现。
def torch_distributed_zero_first(local_rank: int):
"""
Decorator to make all processes in distributed training wait for each local_master to do something.
"""
if local_rank not in [-1, 0]:
dist.barrier(device_ids=[local_rank])
yield
if local_rank == 0:
dist.barrier(device_ids=[0])torch_distributed_zero_first是在create_dataloader函数中调用的,如果执行create_dataloader()函数的进程不是主进程,即rank不等于0或者-1,上下文管理器会执行相应的torch.distributed.barrier(),设置一个阻塞栅栏,让此进程处于等待状态,等待所有进程到达栅栏处(包括主进程数据处理完毕);
如果执行create_dataloader()函数的进程是主进程,其会直接去读取数据并处理,然后其处理结束之后会接着遇到torch.distributed.barrier(),此时,所有进程都到达了当前的栅栏处,这样所有进程就达到了同步,并同时得到释放。
LoadImagesAndLabels类代码解读(utils/datasets.py)
该类继承pytorch的Dataset类,需要实现父类的__init__方法, __getitem__方法和__len__方法, 在每个step训练的时候,DataLodar迭代器通过__getitem__方法获取一批训练数据。
__init__函数解读
def __init__(self, path, img_size=640, batch_size=16, augment=False, hyp=None, rect=False, image_weights=False,
cache_images=False, single_cls=False, stride=32, pad=0.0, prefix=''):
...
self.albumentations = Albumentations() if augment else None
try:
f = [] # image files
for p in path if isinstance(path, list) else [path]:
p = Path(p) # os-agnostic
if p.is_dir(): # dir
f += glob.glob(str(p / '**' / '*.*'), recursive=True)
# f = list(p.rglob('**/*.*')) # pathlib
elif p.is_file(): # file
with open(p, 'r') as t:
t = t.read().strip().splitlines()
parent = str(p.parent) + os.sep
f += [x.replace('./', parent) if x.startswith('./') else x for x in t] # local to global path
# f += [p.parent / x.lstrip(os.sep) for x in t] # local to global path (pathlib)
else:
raise Exception(f'{prefix}{p} does not exist')
self.img_files = sorted([x.replace('/', os.sep) for x in f if x.split('.')[-1].lower() in IMG_FORMATS])self.img_files里面存放的就是所有的图片的路径, 并且是排序好的, 类似[‘coco128/images/train2017/000000000009.jpg’, ‘coco128/images/train2017/000000000025.jpg’, ‘coco128/images/train2017/000000000030.jpg’]
# self.img_files = sorted([x for x in f if x.suffix[1:].lower() in img_formats]) # pathlib
assert self.img_files, f'{prefix}No images found'
except Exception as e:
raise Exception(f'{prefix}Error loading data from {path}: {e}\nSee {HELP_URL}')
# Check cache
self.label_files = img2label_paths(self.img_files) # labels通过图像的路径找到图片对应的标注文件的路径,类似[‘coco128/labels/train2017/000000000009.txt’, ‘coco128/labels/train2017/000000000025.txt’, ‘coco128/labels/train2017/000000000030.txt’]
cache_path = (p if p.is_file() else Path(self.label_files[0]).parent).with_suffix('.cache')catch_path: ‘coco128/labels/train2017.cache’
try:
cache, exists = np.load(cache_path, allow_pickle=True).item(), True # load dict
assert cache['version'] == 0.4 and cache['hash'] == get_hash(self.label_files + self.img_files)
except:
cache, exists = self.cache_labels(cache_path, prefix), False # cachecache是个字典,key的个数为图像个数+4,存储了每张图像对应的所有gt box标签和图像宽高,以及cache的hash值等不太重要的信息, 存储的标签如下:
(Pdb) p cache['coco128/images/train2017/000000000625.jpg']
[array([[ 0, 0.725, 0.69758, 0.1875, 0.47982],
[ 0, 0.50391, 0.64675, 0.15781, 0.60762],
[ 0, 0.36186, 0.73258, 0.14428, 0.41798],
[ 29, 0.45219, 0.27519, 0.052734, 0.048498]], dtype=float32), (640, 446), []].
# Display cache
nf, nm, ne, nc, n = cache.pop('results') # found, missing, empty, corrupted, total
if exists:
d = f"Scanning '{cache_path}' images and labels... {nf} found, {nm} missing, {ne} empty, {nc} corrupted"
tqdm(None, desc=prefix + d, total=n, initial=n) # display cache results
if cache['msgs']:
logging.info('\n'.join(cache['msgs'])) # display warnings
assert nf > 0 or not augment, f'{prefix}No labels in {cache_path}. Can not train without labels. See {HELP_URL}'
# Read cache
[cache.pop(k) for k in ('hash', 'version', 'msgs')] # remove items
labels, shapes, self.segments = zip(*cache.values())label就是gt box的信息,包括类别的坐标。 shapes是图像宽高信息。 segments都是空。
self.labels = list(labels)
self.shapes = np.array(shapes, dtype=np.float64)
self.img_files = list(cache.keys()) # update
self.label_files = img2label_paths(cache.keys()) # update
if single_cls:
for x in self.labels:
x[:, 0] = 0
n = len(shapes) # number of images
bi = np.floor(np.arange(n) / batch_size).astype(np.int) # batch index
nb = bi[-1] + 1 # number of batches
self.batch = bi # batch index of image
self.n = n
self.indices = range(n)
# Rectangular TrainingRectangular Training: 因yolov5在经过网络层后,特征图缩放为原来的1/32,所以输入yolov5模型的分辨率必需能够被32整除,例如当原始图像是1280x720时,先等比缩放到640x360, 此时图像的高为360,不是32的倍数,则将高填充到到384(比360大,且离360最近的能被32整除的数,计算方法为360/32向上取整,得到12,再用12*32即得到384), 这样高就是32地倍数,且填充的像素最少。此时高的两边需要分别填充(384-360)/2 = 12个像素。
if self.rect:
# Sort by aspect ratio
s = self.shapes # wh
ar = s[:, 1] / s[:, 0] # aspect ratio
irect = ar.argsort()
self.img_files = [self.img_files[i] for i in irect]
self.label_files = [self.label_files[i] for i in irect]
self.labels = [self.labels[i] for i in irect]
self.shapes = s[irect] # wh
ar = ar[irect]以上操作是将数据按照图像的宽高比排序。
# Set training image shapes
shapes = [[1, 1]] * nb
for i in range(nb):
ari = ar[bi == i]
mini, maxi = ari.min(), ari.max()
if maxi < 1:
shapes[i] = [maxi, 1]
elif mini > 1:
shapes[i] = [1, 1 / mini]
self.batch_shapes = np.ceil(np.array(shapes) * img_size / stride + pad).astype(np.int) * stride按照宽高比排序后,将宽高比接近的数据放到同一个batch。 因同一个batch里的数据,在输入网络时必需有相同的宽和高,这样将宽高比接近的数据放到同一个batch,则batch内的数据,填充的无效像素就是最少的。
self.batch_shapes里面存放的就是每个batch最终输入网络的图像的shape,这个shape是已经经过计算补充了无效像素的shape。
# Cache images into memory for faster training (WARNING: large datasets may exceed system RAM)
self.imgs, self.img_npy = [None] * n, [None] * n
if cache_images:
if cache_images == 'disk':
self.im_cache_dir = Path(Path(self.img_files[0]).parent.as_posix() + '_npy')
self.img_npy = [self.im_cache_dir / Path(f).with_suffix('.npy').name for f in self.img_files]
self.im_cache_dir.mkdir(parents=True, exist_ok=True)
gb = 0 # Gigabytes of cached images
self.img_hw0, self.img_hw = [None] * n, [None] * n
results = ThreadPool(NUM_THREADS).imap(lambda x: load_image(*x), zip(repeat(self), range(n)))
pbar = tqdm(enumerate(results), total=n)
for i, x in pbar:
if cache_images == 'disk':
if not self.img_npy[i].exists():
np.save(self.img_npy[i].as_posix(), x[0])
gb += self.img_npy[i].stat().st_size
else:
self.imgs[i], self.img_hw0[i], self.img_hw[i] = x # im, hw_orig, hw_resized = load_image(self, i)
gb += self.imgs[i].nbytes
pbar.desc = f'{prefix}Caching images ({gb / 1E9:.1f}GB {cache_images})'
pbar.close()将数据集中所有图像读取进来,并等比缩放,保存到self.imgs里,当设置了本地保存时,保存为本地.npy文件
__getitem__函数解读
想要使用pdb断点到__getitem__函数,必需将dataloader的num_workers设置为0,如启动训练时将–workers参数设置为0即可。
该函数在train.py的292行 for i, (imgs, targets, paths, _) in pbar 调用,pbar = enumerate(train_loader)
def __getitem__(self, index):输入的index即是for i, (imgs, targets, paths, _) in pbar的值, 范围是0 ~ batch num-1
index = self.indices[index] # linear, shuffled, or image_weights
hyp = self.hyp
mosaic = self.mosaic and random.random() < hyp['mosaic']
if mosaic:
# Load mosaic
img, labels = load_mosaic(self, index)训练时采用mosaic数据增强方式,load_mosaic将随机选取4张图片组合成一张图片,输出的img size为self.img_size*self.img_size,如 640*640,参见load_mosaic函数解读
shapes = None
# MixUp augmentation
if random.random() < hyp['mixup']:
img, labels = mixup(img, labels, *load_mosaic(self, random.randint(0, self.n - 1)))重新选取4张图像mosaic增强,将mosaic增强后的图像与之前mosaic增强后的数据进行mixup数据增强。
else:
# Load image
img, (h0, w0), (h, w) = load_image(self, index)在推理时,单张图片推理,yolov5使用自适应图片缩放的方式,减少填充的黑边以减少计算量。
# Letterbox shape = self.batch_shapes[self.batch[index]] if self.rect else self.img_size # final letterboxed shape 在__init__函数讲解中有介绍过self.batch_shapes里面存放的是每个batch最终输入网络的图像的shape,这个shape是已经经过计算补充了无效像素的shape。
img, ratio, pad = letterbox(img, shape, auto=False, scaleup=self.augment)letterbox具体实现自适应缩放过程,scaleup控制是否向上缩放(即放大图片)参见letterbox函数解读。
shapes = (h0, w0), ((h / h0, w / w0), pad) # for COCO mAP rescaling
labels = self.labels[index].copy()
if labels.size: # normalized xywh to pixel xyxy format
labels[:, 1:] = xywhn2xyxy(labels[:, 1:], ratio[0] * w, ratio[1] * h, padw=pad[0], padh=pad[1])img缩放与补黑边后,label的框需要适配,xywhn2xyxy是将标注的label中归一化的xywh中心点+宽高 -> xyxy左上角+右下角坐标,再加上补边的偏移。
if self.augment:
img, labels = random_perspective(img, labels,
degrees=hyp['degrees'],
translate=hyp['translate'],
scale=hyp['scale'],
shear=hyp['shear'],
perspective=hyp['perspective'])随机裁剪缩放等数据增强。
nl = len(labels) # number of labels
if nl:
labels[:, 1:5] = xyxy2xywhn(labels[:, 1:5], w=img.shape[1], h=img.shape[0], clip=True, eps=1E-3)xyxy左上角+右下角坐标 -> 归一化的xywh中心点+宽高, clip规范xyxy坐标在图片宽高内。
if self.augment:
# Albumentations
img, labels = self.albumentations(img, labels)对图像进行模糊等数据增强操作
nl = len(labels) # update after albumentations
# HSV color-space
augment_hsv(img, hgain=hyp['hsv_h'], sgain=hyp['hsv_s'], vgain=hyp['hsv_v'])augment_hsv函数将图像转到HSV空间进行数据增强,再转回BGR
# Flip up-down
if random.random() < hyp['flipud']:
img = np.flipud(img)
if nl:
labels[:, 2] = 1 - labels[:, 2]
# Flip left-right
if random.random() < hyp['fliplr']:
img = np.fliplr(img)
if nl:
labels[:, 1] = 1 - labels[:, 1]
# Cutouts
# labels = cutout(img, labels, p=0.5)
labels_out = torch.zeros((nl, 6))
if nl:
labels_out[:, 1:] = torch.from_numpy(labels)
# Convert
img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
img = np.ascontiguousarray(img)
return torch.from_numpy(img), labels_out, self.img_files[index], shapesload_mosaic函数解读
mosaic数据增强是随机选取4张图片,然后拼合成一张图片,整体步骤如下(以网络的输入img_size=640为例):
1、 生成一张1280*1280的背景图片,1280*1280的图片是可以容纳4张640*640的图片的。
2、在1280*1280的背景图片的中心附近区域(图片中心点的上下左右1/4区域,见下图中的黄色虚线框)随机选取一个点,这个点作为4张图片的接合点,见下图中的红色点。
3、随机选取4张图片,以上一步随机选取的点为接合点,将4张图片排列在背景图片上作为前景。

4、裁剪掉超出背景图片边界的前景图,得到1280*1280的图像(代码实现中是在每一张图贴到背景图的时候就去裁剪)。

5、将1280*1280的图像缩放,随机裁剪等方法得到640*640的图像。

# loads images in a 4-mosaic
labels4, segments4 = [], []
s = self.img_size
yc, xc = [int(random.uniform(-x, 2 * s + x)) for x in self.mosaic_border]图片中心点的上下左右1/4区域随机选取一个点,这个点作为4张图片的接合点。
# mosaic center x, y
indices = [index] + random.choices(self.indices, k=3) # 3 additional image indices随机选取3张图片,加上当前图片,就是4张图片
for i, index in enumerate(indices):
# Load image
img, _, (h, w) = load_image(self, index)4张图片分别贴到背景图的top left,top right,bottom left,bottom right
# place img in img4
if i == 0: # top left
img4 = np.full((s * 2, s * 2, img.shape[2]), 114, dtype=np.uint8)第一张图的时候创建背景图
# base image with 4 tiles
x1a, y1a, x2a, y2a = max(xc - w, 0), max(yc - h, 0), xc, yc # xmin, ymin, xmax, ymax (large image)x1a, y1a, x2a, y2a表示要贴在背景图的位置
x1b, y1b, x2b, y2b = w - (x2a - x1a), h - (y2a - y1a), w, h # xmin, ymin, xmax, ymax (small image)x1b, y1b, x2b, y2b表示裁剪后的前景图坐标
elif i == 1: # top right
x1a, y1a, x2a, y2a = xc, max(yc - h, 0), min(xc + w, s * 2), yc
x1b, y1b, x2b, y2b = 0, h - (y2a - y1a), min(w, x2a - x1a), h
elif i == 2: # bottom left
x1a, y1a, x2a, y2a = max(xc - w, 0), yc, xc, min(s * 2, yc + h)
x1b, y1b, x2b, y2b = w - (x2a - x1a), 0, w, min(y2a - y1a, h)
elif i == 3: # bottom right
x1a, y1a, x2a, y2a = xc, yc, min(xc + w, s * 2), min(s * 2, yc + h)
x1b, y1b, x2b, y2b = 0, 0, min(w, x2a - x1a), min(y2a - y1a, h)
img4[y1a:y2a, x1a:x2a] = img[y1b:y2b, x1b:x2b] # img4[ymin:ymax, xmin:xmax]将裁剪后的前景图贴在背景图上
padw = x1a - x1b
padh = y1a - y1b
# Labels
labels, segments = self.labels[index].copy(), self.segments[index].copy()
if labels.size:
labels[:, 1:] = xywhn2xyxy(labels[:, 1:], w, h, padw, padh) # normalized xywh to pixel xyxy format归一化的xywh中心点+宽高 -> xyxy左上角+右下角坐标
segments = [xyn2xy(x, w, h, padw, padh) for x in segments]
labels4.append(labels)
segments4.extend(segments)
# Concat/clip labels
labels4 = np.concatenate(labels4, 0)
for x in (labels4[:, 1:], *segments4):
np.clip(x, 0, 2 * s, out=x) # clip when using random_perspective()
# img4, labels4 = replicate(img4, labels4) # replicate以上都是在根据mosaic数据增强处理label,让label能对应上拼合后的4合1图像。
# Augment
img4, labels4, segments4 = copy_paste(img4, labels4, segments4, p=self.hyp['copy_paste'])copy paste数据增强,在分割中使用,检测中未使用,copy paste数据增强方式如下图:

img4, labels4 = random_perspective(img4, labels4, segments4,
degrees=self.hyp['degrees'],
translate=self.hyp['translate'],
scale=self.hyp['scale'],
shear=self.hyp['shear'],
perspective=self.hyp['perspective'],
border=self.mosaic_border) # border to remove缩放,随机裁剪等,最终得到self.img_size*self.img_size大小的图像
return img4, labels4letterbox函数解读(utils/augmentations.py)
def letterbox(im, new_shape=(640, 640), color=(114, 114, 114), auto=True, scaleFill=False, scaleup=True, stride=32):letterbox函数将输入图像im等比缩放到new_shape大小, 不够的地方补充黑边(或灰边)
# Resize and pad image while meeting stride-multiple constraints
shape = im.shape[:2] # current shape [height, width]
if isinstance(new_shape, int):
new_shape = (new_shape, new_shape)
# Scale ratio (new / old)
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
if not scaleup: # only scale down, do not scale up (for better val mAP)
r = min(r, 1.0)
# Compute padding
ratio = r, r # width, height ratios
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding
if auto: # minimum rectangle
dw, dh = np.mod(dw, stride), np.mod(dh, stride) # wh paddingauto表示是否自动补齐到32的整数倍
elif scaleFill: # stretch
dw, dh = 0.0, 0.0
new_unpad = (new_shape[1], new_shape[0])
ratio = new_shape[1] / shape[1], new_shape[0] / shape[0] # width, height ratiosscaleFill表示不采用自适应缩放,直接resize到目标shape,无需补边
dw /= 2 # divide padding into 2 sides
dh /= 2
if shape[::-1] != new_unpad: # resize当原始图像与目标shape不一致的时候,缩放
im = cv2.resize(im, new_unpad, interpolation=cv2.INTER_LINEAR).
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))dw与dh在上面除以2之前可能是个奇数,那么补边的时候,两侧的边补充的像素数应该是相差1的,上面两步是在处理此种情况。
im = cv2.copyMakeBorder(im, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add border两侧补边操作
return im, ratio, (dw, dh)二、模型构建代码解读
这里只介绍检测头的构建,模型主干的构建没有什么大的难点。
Detect类代码解读(models/yolo.py)
Detect类负责yolov5的3个检测头层的构建, 对应模型配置文件models/yolov5s.yaml中的最后一层,实现上只有一个卷积层,卷积核为1x1, 输入是P3, P4, P5层。 Detect层位于下图中的红框处
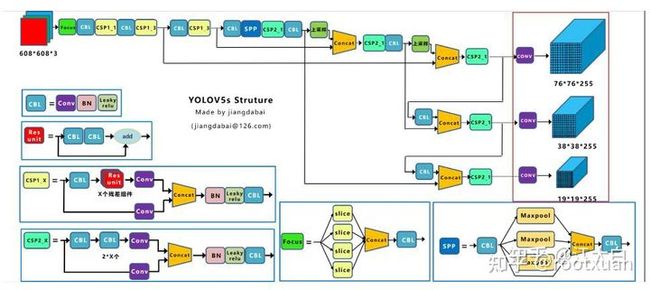
__init__函数解读
def __init__(self, nc=80, anchors=(), ch=(), inplace=True): # detection layer
super().__init__()
self.nc = nc # number of classes对于coco数据集来说, nc = 80
self.no = nc + 5 # number of outputs per anchor需要预测的box的维度, xywh+正样本置信度+80个类别每个类别的概率。
self.nl = len(anchors) # number of detection layers
self.na = len(anchors[0]) // 2 # number of anchors
self.grid = [torch.zeros(1)] * self.nl # init grid
a = torch.tensor(anchors).float().view(self.nl, -1, 2)
self.register_buffer('anchors', a) # shape(nl,na,2)
self.register_buffer('anchor_grid', a.clone().view(self.nl, 1, -1, 1, 1, 2)) # shape(nl,1,na,1,1,2)
self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output convch = 3,表示输入detect层的channel数, detect层的实现就是这个卷积核为1x1, 输出channel为self.no*self.na = 85*3 = 255的卷积层。
self.inplace = inplace # use in-place ops (e.g. slice assignment)forward函数解读
def forward(self, x):x是一个list,是detect层的输入,list的长度为3,shape分别是(n, 128, 80, 80), (n, 256, 40, 40), (n, 512, 20, 20)
# x = x.copy() # for profiling
z = [] # inference output以下代码解读均以i = 0来说明:
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv将执行卷积操作,执行完后,x[0]的shape为(n, 256, 80, 80)
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()将x[0]的shape从(n, 256, 80, 80)转换为(n, 3, 80, 80, 85), 训练时,直接返回这个x
if not self.training: # inference
if self.grid[i].shape[2:4] != x[i].shape[2:4] or self.onnx_dynamic:
self.grid[i] = self._make_grid(nx, ny).to(x[i].device)预测的box的中心点x和y是相对位置, 在推理的时候,需要映射到原图上,因此需要先加上grid的坐标,再乘以stride映射回原图。这里就是先把grid坐标计算出来。grid其实就是特征图的每一个点的坐标。
y = x[i].sigmoid()
if self.inplace:
y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy这里将预测框的中心点坐标转化到-0.5~1.5范围,然后将中心点映射回原图。至于为什么要将预测框的中心点坐标转化到-0.5~1.5范围,可以参考后面ComputeLoss代码解读的 __call__函数解读部分。
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh这里将预测框的宽和高转化到0~4范围,然后乘以预设anchor的宽和高(预设的anchor是基于原图的,乘以anchor后可以将宽和高映射到原图),这里和计算loss时也是一致的。
else: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953
xy = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i].view(1, self.na, 1, 1, 2) # wh
y = torch.cat((xy, wh, y[..., 4:]), -1)
z.append(y.view(bs, -1, self.no))推理时,将每一个检测头的预测结果存放在z中,z[0]的shape为(n, 19200, 85), 其中19200 = 3 * 80 * 80, 表示第一层detect检测头所有grid预测的box信息。
return x if self.training else (torch.cat(z, 1), x)三、loss计算代码解读
ComputeLoss代码解读(utils/loss.py)
__init__函数解读
该函数在train.py的258行compute_loss = ComputeLoss(model)调用
def __init__(self, model, autobalance=False):
super(ComputeLoss, self).__init__()
self.sort_obj_iou = False
device = next(model.parameters()).device # get model device
h = model.hyp # hyperparameters
# Define criteria
BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['cls_pw']], device=device))
BCEobj = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['obj_pw']], device=device))
# Class label smoothing https://arxiv.org/pdf/1902.04103.pdf eqn 3
self.cp, self.cn = smooth_BCE(eps=h.get('label_smoothing', 0.0)) # positive, negative BCE targets
# Focal loss
g = h['fl_gamma'] # focal loss gamma
if g > 0:
BCEcls, BCEobj = FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)
det = model.module.model[-1] if is_parallel(model) else model.model[-1] # Detect() module这里det返回的是检测层,对应的是models/yolo.py->class Detect->__init__->self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch)构建的检测头。详见class Detect章节
返回的det层打印如下:
(Pdb) p det
Detect(
(m): ModuleList(
(0): Conv2d(128, 255, kernel_size=(1, 1), stride=(1, 1))
(1): Conv2d(256, 255, kernel_size=(1, 1), stride=(1, 1))
(2): Conv2d(512, 255, kernel_size=(1, 1), stride=(1, 1))
)
).
self.balance = {3: [4.0, 1.0, 0.4]}.get(det.nl, [4.0, 1.0, 0.25, 0.06, .02]) # P3-P7det.nl是3,表示检测头的数目,self.balance的结果还是[4.0, 1.0, 0.4],标识三个检测头对应输出的损失系数。
self.ssi = list(det.stride).index(16) if autobalance else 0 # stride 16 indexdet.stride是[ 8., 16., 32.], self.ssi表示stride为16的索引,当autobalance为true时,self.ssi为1.
self.BCEcls, self.BCEobj, self.gr, self.hyp, self.autobalance = BCEcls, BCEobj, 1.0, h, autobalance
for k in 'na', 'nc', 'nl', 'anchors':
setattr(self, k, getattr(det, k))__call__函数解读
该函数在train.py的318行loss, loss_items = compute_loss(pred, targets.to(device))调用。
函数定义
def __call__(self, p, targets):输入1:
p, 是每个预测头输出的结果,
[
p[0].shape: torch.Size([16, 3, 80, 80, 85])
p[1].shape: torch.Size([16, 3, 40, 40, 85])
p[2].shape: torch.Size([16, 3, 20, 20, 85])
]p[0]的每个维度解释:
16: batch size
3: anchor box数量
80/40/20: 3个检测头特征图大小
85: coco数据集80个类别+4(x,y,w,h)+1(是否为前景)
输入2:
targets: gt box信息,维度是(n, 6),其中n是整个batch的图片里gt box的数量,以下都以gt box数量为190来举例。 6的每一个维度为(图片在batch中的索引, 目标类别, x, y, w, h)
device = targets.device
lcls, lbox, lobj = torch.zeros(1, device=device), torch.zeros(1, device=device), torch.zeros(1, device=device)
tcls, tbox, indices, anchors = self.build_targets(p, targets) # targetstcls的shape为(3, 808), 表示3个检测头对应的gt box的类别。
tbox的shape为(3, ([808, 4])), 表示3个检测头对应的gt box的xywh, 其中x和y已经减去了预测方格的整数坐标,
比如原始的gt box的中心坐标是(51.7, 44.8),则该gt box由方格(51, 44),以及离中心点最近的两个方格(51, 45)和(52, 44)来预测(见build_targets函数里的解析),
换句话说这三个方格预测的gt box是同一个,其中心点是(51.7, 44.8),但tbox保存这三个方格预测的gt box的xy时,保存的是针对这三个方格的偏移量,
分别是:
(51.7 - 51 = 0.7, 44.8 - 44 = 0.8)
(51.7 - 51 = 0.7, 44.8 - 45 = -0.2)
(51.7 - 52 = -0.3, 44.8 - 44 = 0.8)
indices的shape为(3, ([808], [808], [808], [808])), 4个808分别表示每个gt box(包括偏移后的gt box)在batch中的image index, anchor index, 预测该gt box的网格y坐标, 预测该gt box的网格x坐标。
anchors的shape为(3, ([808, 2])), 表示每个检测头对应的808个gt box所对应的anchor。
以下都以第一个检测头对应的808个gt box讲解,其他检测头的gt box个数不同,但逻辑相同
for i, pi in enumerate(p): # layer index, layer predictions
b, a, gj, gi = indices[i] # image, anchor, gridy, gridx
tobj = torch.zeros_like(pi[..., 0], device=device) # target obj
n = b.shape[0] # number of targets
if n:
ps = pi[b, a, gj, gi] # prediction subset corresponding to targets将808个gt box对应的预测框选取出来。 ps的shape为(808, 85)。
# Regression
pxy = ps[:, :2].sigmoid() * 2. - 0.5参考
https://github.com/ultralytics/yolov5/issues/1585#issuecomment-739060912github.com/ultralytics/yolov5/issues/1585#issuecomment-739060912
将预测的中心点坐标变换到-0.5到1.5之间,如下图所示:

因为像素是没有小数的,但预测出来的坐标都是带小数位的,所以这里把一个像素当成一个方格来对待,如上图所示,将中心坐标变换到-0.5到1.5之间就相当于预测的中心点范围限制在图中的绿色框中,也就是说(51, 44)这个方格可预测的目标中心点范围是(50.5, 43.5)到(52.5, 45.5)之间。
pwh = (ps[:, 2:4].sigmoid() * 2) ** 2 * anchors[i]参考
https://github.com/ultralytics/yolov5/issues/471#issuecomment-662009779github.com/ultralytics/yolov5/issues/471#issuecomment-662009779
大概意思解释下:
ps[:, 2:4].sigmoid() * 2) ** 2的范围是0~4, 再乘以anchors[i], 表示把预测框的宽和高限制在4倍的anchors内,这是为了解决yolov3和yolov4对预测框宽高无任何约束的问题,这个4和默认的超参数anchor_t是相等的,也是有关联的,调整时建议一起调整。
pbox = torch.cat((pxy, pwh), 1) # predicted box
iou = bbox_iou(pbox.T, tbox[i], x1y1x2y2=False, CIoU=True) # iou(prediction, target)此处就是计算808个预测框与gt box的giou了, 得到的iou的shape是(808)。
lbox += (1.0 - iou).mean() # iou loss
# Objectness
score_iou = iou.detach().clamp(0).type(tobj.dtype)detach函数使得iou不可反向传播, clamp将小于0的iou裁剪为0
if self.sort_obj_iou:
sort_id = torch.argsort(score_iou)torch.argsort返回的是排序后的score_iou中的元素在原始score_iou中的位置。
b, a, gj, gi, score_iou = b[sort_id], a[sort_id], gj[sort_id], gi[sort_id], score_iou[sort_id]得到根据iou从小到大排序的image index, anchor index, gridy, gridx, iou。
tobj[b, a, gj, gi] = (1.0 - self.gr) + self.gr * score_iou # giou ratiotobj[b, a, gj, gi]的shape为808,表示选择有对应gt box的808个预测框的位置赋值,其他位置的值为初始值0。 tobj的shape为(16, 3, 80, 80), 表示每个grid的预测框与gt box的iou。
# Classification
if self.nc > 1: # cls loss (only if multiple classes)
t = torch.full_like(ps[:, 5:], self.cn, device=device) # targets
t[range(n), tcls[i]] = self.cp
lcls += self.BCEcls(ps[:, 5:], t) # BCEps[:, 5:]取808个预测框信息的第6-85个数据,即目标是每个类别的概率。
http://self.cn和self.cp分别是标签平滑的负样本平滑标签和正样本平滑标签, 参考https://blog.csdn.net/qq_38253797/article/details/116228065
tcls的shape为(3, 808), 表示3个检测头对应的gt box的类别,tcls[i]的shape为(808), 表示808个gt box的类别, 取值为0~79。
t[range(n), tcls[i]]的shape是(808, 80), t的每一行里面有一个值是self.cp(即正样本平滑标签),其他值是http://self.cn(即负样本平滑标签)
# Append targets to text file
# with open('targets.txt', 'a') as file:
# [file.write('%11.5g ' * 4 % tuple(x) + '\n') for x in torch.cat((txy[i], twh[i]), 1)]
obji = self.BCEobj(pi[..., 4], tobj)tobj的shape为(16, 3, 80, 80), 表示每个grid的预测框与gt box的iou。
pi[…, 4]取每个grid预测的object为正样本的概率。
将每个grid预测框和gt box的iou与每个grid预测的object为正样本的概率计算BCE loss,做为object loss。
lobj += obji * self.balance[i] # obj loss
if self.autobalance:
self.balance[i] = self.balance[i] * 0.9999 + 0.0001 / obji.detach().item()
if self.autobalance:
self.balance = [x / self.balance[self.ssi] for x in self.balance]
lbox *= self.hyp['box']
lobj *= self.hyp['obj']
lcls *= self.hyp['cls']
bs = tobj.shape[0] # batch size
return (lbox + lobj + lcls) * bs, torch.cat((lbox, lobj, lcls)).detach()build_targets函数解读
函数定义
def build_targets(self, p, targets):输入1:p, 是每个预测头输出的结果,
[
p[0].shape: torch.Size([16, 3, 80, 80, 85])
p[1].shape: torch.Size([16, 3, 40, 40, 85])
p[2].shape: torch.Size([16, 3, 20, 20, 85])
]p[0]的每个维度解释:
16: batch size
3: anchor box数量
80/40/20: 3个检测头特征图大小
85: coco数据集80个类别+4(x,y,w,h)+1(是否为前景)
输入2: targets: gt box信息,维度是(n, 6),其中n是整个batch的图片里gt box的数量,以下都以gt box数量为190来举例。 6的每一个维度为(图片在batch中的索引, 目标类别, x, y, w, h)
该函数主要是处理gt box,先介绍一下gt box的整体处理策略:
1、将gt box复制3份,原因是有三种长宽的anchor, 每种anchor都有gt box与其对应,也就是在筛选之前,一个gt box有三种anchor与其对应。
2、过滤掉gt box的w和h与anchor的w和h的比值大于设置的超参数anchor_t的gt box。
3、剩余的gt box,每个gt box使用至少三个方格来预测,一个是gt box中心点所在方格,另两个是中心点离的最近的两个方格,如下图:
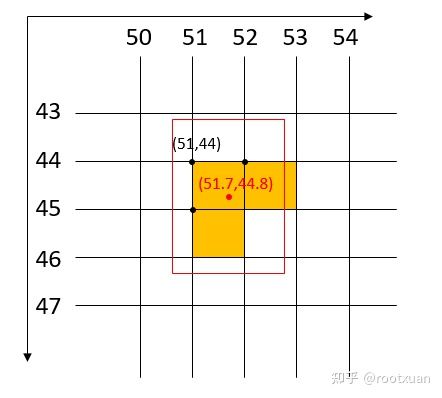
如果gt box的中心坐标是(51.7, 44.8),则由gt box中心点所在方格(51, 44),以及离中心点最近的两个方格(51, 45)和(52, 44)来预测此gt box。
# Build targets for compute_loss(), input targets(image,class,x,y,w,h)
na, nt = self.na, targets.shape[0] # number of anchors: 3, gt box的数量:190
tcls, tbox, indices, anch = [], [], [], []
gain = torch.ones(7, device=targets.device) # normalized to gridspace gaingain = [1, 1, 1, 1, 1, 1, 1], 是7个数,前6个数对应targets的第二维度6,先不用关注用途,后面会讲到。
ai = torch.arange(na, device=targets.device).float().view(na, 1).repeat(1, nt) # same as .repeat_interleave(nt)anchor的索引,shape为(3, gt box的数量), 3行里,第一行全是0, 第2行全是1, 第三行全是2,表示每个gt box都对应到3个anchor上。
targets = torch.cat((targets.repeat(na, 1, 1), ai[:, :, None]), 2) # append anchor indices下图显示了处理过后的targets内容,其shape为(3, 190, 7), 红色框中是原始的targets, 蓝色框是给每个gt box加上索引,表示对应着哪种anchor。 然后将gt box重复3遍,对应着三种anchor.

g = 0.5 # bias
off = torch.tensor([[0, 0],
[1, 0], [0, 1], [-1, 0], [0, -1], # j,k,l,m
# [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
], device=targets.device).float() * g # offsets以下都以第一个检测头为例讲解,其他检测头的逻辑相同
for i in range(self.nl): // 针对每一个检测头
anchors = self.anchors[i]i=0时, anchors值为:
(Pdb) p anchors
tensor([[1.25000, 1.62500],
[2.00000, 3.75000],
[4.12500, 2.87500]], device='cuda:0').
gain[2:6] = torch.tensor(p[i].shape)[[3, 2, 3, 2]] # xyxy gaingain的值是[ 1., 1., 80., 80., 80., 80., 1.], 80的位置对应着gt box信息的xywh。
# Match targets to anchors
t = targets * gaintargets里的xywh是归一化到0 ~ 1之间的, 乘以gain之后,将targets的xywh映射到检测头的特征图大小上。
if nt:
# Matches
r = t[:, :, 4:6] / anchors[:, None] # wh ratio这里的r的shape为[3, 190, 2], 2分别表示gt box的w和h与anchor的w和h的比值。
j = torch.max(r, 1. / r).max(2)[0] < self.hyp['anchor_t'] # compare当gt box的w和h与anchor的w和h的比值比设置的超参数anchor_t大时,则此gt box去除,这一步得到的j的shape为(3, 190), 里面的值均为true或false, 表示每一个gt box是否将要过滤掉。
# j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n)=wh_iou(anchors(3,2), gwh(n,2))
t = t[j] # filter此步就是去除gt box的w和h与anchor的w和h的比值大于anchor_t的gt box,得到的t的shape为(271, 7), 这个271是本人试验的结果,不同的数据集会不一样,可以看到过滤前,3个anchor总的gt box是3 * 190 = 570个,过滤后还剩余271个。过滤的原因是和anchor的宽高差别较大的gt box,是非常难预测的,不适合用来训练。
# Offsets
gxy = t[:, 2:4] # grid xy取出过滤后的gt box的中心点浮点型的坐标。
gxi = gain[[2, 3]] - gxy # inverse将以图像左上角为原点的坐标变换为以图像右下角为原点的坐标。
j, k = ((gxy % 1. < g) & (gxy > 1.)).T以图像左上角为原点的坐标,取中心点的小数部分,小数部分小于0.5的为ture,大于0.5的为false。 j和k的shape都是(271),true的位置分别表示靠近方格左边的gt box和靠近方格上方的gt box。
l, m = ((gxi % 1. < g) & (gxi > 1.)).T以图像右下角为原点的坐标,取中心点的小数部分,小数部分小于0.5的为ture,大于0.5的为false。 l和m的shape都是(271),true的位置分别表示靠近方格右边的gt box和靠近方格下方的gt box。
j和l的值是刚好相反的,k和m的值也是刚好相反的。
j = torch.stack((torch.ones_like(j), j, k, l, m))将j, k, l, m组合成一个tensor,另外还增加了一个全为true的维度。组合之后,j的shape为(5, 271)
t = t.repeat((5, 1, 1))[j]t之前的shape为(271, 7), 这里将t复制5个,然后使用j来过滤,
第一个t是保留所有的gt box,因为上一步里面增加了一个全为true的维度,
第二个t保留了靠近方格左边的gt box,
第三个t保留了靠近方格上方的gt box,
第四个t保留了靠近方格右边的gt box,
第五个t保留了靠近方格下边的gt box,
过滤后,t的shape为(808, 7), 表示保留下来的所有的gt box。
offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]offsets的shape为(808, 2), 表示保留下来的808个gt box的x, y对应的偏移,
第一个t保留所有的gt box偏移量为[0, 0], 即不做偏移
第二个t保留的靠近方格左边的gt box,偏移为[0.5, 0],即向左偏移0.5(后面代码是用gxy - offsets,所以正0.5表示向左偏移),则偏移到左边方格,表示用左边的方格来预测
第三个t保留的靠近方格上方的gt box,偏移为[0, 0.5],即向上偏移0.5,则偏移到上边方格,表示用上边的方格来预测
第四个t保留的靠近方格右边的gt box,偏移为[-0.5, 0],即向右偏移0.5,则偏移到右边方格,表示用右边的方格来预测
第五个t保留的靠近方格下边的gt box,偏移为[0, 0.5],即向下偏移0.5,则偏移到下边方格,表示用下边的方格来预测
一个gt box的中心点x坐标要么是靠近方格左边,要么是靠近方格右边,y坐标要么是靠近方格上边,要么是靠近方格下边,所以一个gt box在以上五个t里面,会有三个t是true。
也即一个gt box有三个方格来预测,一个是中心点所在方格,另两个是离的最近的两个方格。而yolov3只使用中心点所在的方格预测,这是与yolov3的区别。
else:
t = targets[0]
offsets = 0
# Define
b, c = t[:, :2].long().T # image, class
gxy = t[:, 2:4] # grid xy
gwh = t[:, 4:6] # grid wh
gij = (gxy - offsets).long()将中心点偏移到相邻最近的方格里,然后向下取整, gij的shape为(808, 2)
gi, gj = gij.T # grid xy indices
# Append
a = t[:, 6].long() # anchor indices
indices.append((b, a, gj.clamp_(0, gain[3] - 1), gi.clamp_(0, gain[2] - 1))) # image, anchor, grid indices
tbox.append(torch.cat((gxy - gij, gwh), 1)) # box
anch.append(anchors[a]) # anchors
tcls.append(c) # class
return tcls, tbox, indices, anch