yolov5模型与代码解读
Backbone: new CSPDarknet-53
Neck: SPPF, New CSP-PAN
Head: yolov3 head
下图是v5l:

改进部分:
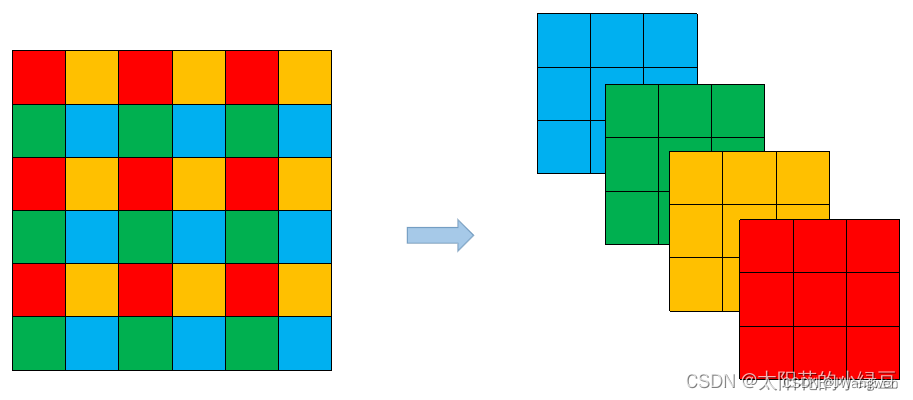
1.Focus模块
Focus模块将每个2x2的相邻像素划分为一个patch,然后将每个patch中相同位置(同一颜色)像素给拼在一起就得到了4个feature map,然后在接上一个3x3大小的卷积层。这和直接使用一个6x6大小的卷积层等效
Coding:
class Focus(nn.Module):
# Focus wh information into c-space
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act)
# self.contract = Contract(gain=2)
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))
# return self.conv(self.contract(x))
::2 :表示第一行开始到最后一行结束,步长为2的所有值(图中第一行,第三行所有值)
::2 :表示第一列开始到最后一列结束,步长为2的所有值(图中第一列,第三列所有值)

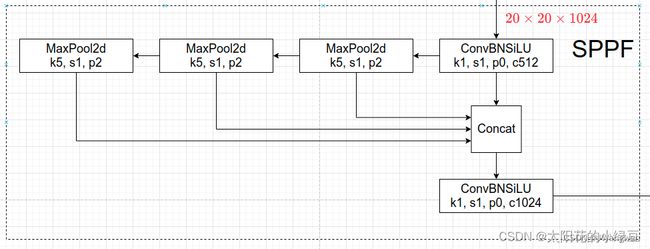
2. SPPF
将SPP改为SPPF
两个k=5的Maxpool相当于一个k=9的Maxpool
三个k=5的Maxpool相当于一个k=13的Maxpool
作者串行多个k=5的Maxpool,然后做进一步融合,能在一定程度上解决目标多尺度问题。

Coding:
class SPPF(nn.Module):
# Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher
def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1) #这里对应第一个CBL
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
y1 = self.m(x)
y2 = self.m(y1)
# 上述两次池化
return self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1))
# 将原来的x,一次池化后的y1,两次池化后的y2,3次池化的self.m(y2)先进行拼接,然后再CBL
3. 数据增强
3.1 Mosaic
将四张图片拼成一张图片(没变)

Coding:
def load_mosaic(self, index):
# YOLOv5 4-mosaic loader. Loads 1 image + 3 random images into a 4-image mosaic
labels4, segments4 = [], []
s = self.img_size #图片大小
'''
Mosaic流程:
1.初始化背景图,大小为(img*2,img*2)
2.随机选取一个中心点,范围为(-x,2*s+x)
3.随机选取三张图,基于中心点分别将四张图放在左上,右上,左下,右下,部分会由于小于4张图片的宽高因此会进行裁剪
4.重新计算打标边框的偏移量计算上
'''
# 随机选取拼接四张图的中心点[-320,960]
yc, xc = (int(random.uniform(-x, 2 * s + x)) for x in self.mosaic_border) # mosaic center x, y self.mosaic_border=[-320,320]
indices = [index] + random.choices(self.indices, k=3) # 3 additional image indices 随机选三张图
random.shuffle(indices)
for i, index in enumerate(indices):
# Load image
img, _, (h, w), img_label = load_image_label(self, index)
# place img in img4
if i == 0: # top left
img4 = np.full((s * 2, s * 2, img.shape[2]), 114, dtype=np.uint8) # base image with 4 tiles 初始化背景图------填充一个背景图s*2
# 先计算出第一张图贴到左上角的起点xy,终点就是xc,yc
x1a, y1a, x2a, y2a = max(xc - w, 0), max(yc - h, 0), xc, yc # xmin, ymin, xmax, ymax (large image)
# 计算裁剪的要贴的图,避免越界,这里就会裁掉多余的一部分
x1b, y1b, x2b, y2b = w - (x2a - x1a), h - (y2a - y1a), w, h # xmin, ymin, xmax, ymax (small image)
elif i == 1: # top right
x1a, y1a, x2a, y2a = xc, max(yc - h, 0), min(xc + w, s * 2), yc
x1b, y1b, x2b, y2b = 0, h - (y2a - y1a), min(w, x2a - x1a), h
elif i == 2: # bottom left
x1a, y1a, x2a, y2a = max(xc - w, 0), yc, xc, min(s * 2, yc + h)
x1b, y1b, x2b, y2b = w - (x2a - x1a), 0, w, min(y2a - y1a, h)
elif i == 3: # bottom right
x1a, y1a, x2a, y2a = xc, yc, min(xc + w, s * 2), min(s * 2, yc + h)
x1b, y1b, x2b, y2b = 0, 0, min(w, x2a - x1a), min(y2a - y1a, h)
img4[y1a:y2a, x1a:x2a] = img[y1b:y2b, x1b:x2b] # img4[ymin:ymax, xmin:xmax]
padw = x1a - x1b
padh = y1a - y1b
# Labels 裁剪过后,对应标签也要往下移动
labels, segments = img_label.copy(), self.segments[index].copy() # labels (array): (num_gt_perimg, [cls_id, poly])
if labels.size:
# labels[:, 1:] = xywhn2xyxy(labels[:, 1:], w, h, padw, padh) # normalized xywh to pixel xyxy format
labels[:, [1, 3, 5, 7]] = img_label[:, [1, 3, 5, 7]] + padw
labels[:, [2, 4, 6, 8]] = img_label[:, [2, 4, 6, 8]] + padh
segments = [xyn2xy(x, w, h, padw, padh) for x in segments]
labels4.append(labels)
segments4.extend(segments)
3.2 Copy paste
将部分目标随机的粘贴到图片中,前提是数据要有segments数据才行,即每个目标的实例分割信息

3.3 Random affine(Rotation, Scale, Translation and Shear)
随机进行仿射变换,但根据配置文件里的超参数发现只使用了Scale和Translation即缩放和平移。
3.4 MixUp
就是将两张图片按照一定的透明度融合在一起,具体有没有用不太清楚,毕竟没有论文,也没有消融实验。代码中只有较大的模型才使用到了MixUp,而且每次只有10%的概率会使用到。

3.5 Albumentations
主要是做些滤波、直方图均衡化以及改变图片质量等等,我看代码里写的只有安装了albumentations包才会启用,但在项目的requirements.txt文件中albumentations包是被注释掉了的,所以默认不启用。
3.6 Augment HSV(Hue, Saturation, Value)
随机调整色度,饱和度以及明度
3.7 Random horizontal flip,随机水平翻转
4.训练策略
Multi-scale training(0.5~1.5x),多尺度训练,假设设置输入图片的大小为640 × 6400,训练时采用尺寸是在0.5 × 640 ∼ 1.5 × 640之间随机取值,注意取值时取得都是32的整数倍(因为网络会最大下采样32倍)。
AutoAnchor(For training custom data),训练自己数据集时可以根据自己数据集里的目标进行重新聚类生成Anchors模板。
Warmup and Cosine LR scheduler,训练前先进行Warmup热身,然后在采用Cosine学习率下降策略。
EMA(Exponential Moving Average),可以理解为给训练的参数加了一个动量,让它更新过程更加平滑。
Mixed precision,混合精度训练,能够减少显存的占用并且加快训练速度,前提是GPU硬件支持。
Evolve hyper-parameters,超参数优化,没有炼丹经验的人勿碰,保持默认就好。
5.边框预测

Coding:
y = x[i].sigmoid()
y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh

IOU coding:
# 计算两个框的iou(DIOU,GIOU,CIOU)
def bbox_iou(box1, box2, x1y1x2y2=True, GIoU=False, DIoU=False, CIoU=False, eps=1e-7):
# Returns the IoU of box1 to box2. box1 is 4, box2 is nx4
box2 = box2.T
# Get the coordinates of bounding boxes
if x1y1x2y2: # x1, y1, x2, y2 = box1
b1_x1, b1_y1, b1_x2, b1_y2 = box1[0], box1[1], box1[2], box1[3]
b2_x1, b2_y1, b2_x2, b2_y2 = box2[0], box2[1], box2[2], box2[3]
else: # transform from xywh to xyxy
b1_x1, b1_x2 = box1[0] - box1[2] / 2, box1[0] + box1[2] / 2
b1_y1, b1_y2 = box1[1] - box1[3] / 2, box1[1] + box1[3] / 2
b2_x1, b2_x2 = box2[0] - box2[2] / 2, box2[0] + box2[2] / 2
b2_y1, b2_y2 = box2[1] - box2[3] / 2, box2[1] + box2[3] / 2
# Intersection area 计算交集
inter = (torch.min(b1_x2, b2_x2) - torch.max(b1_x1, b2_x1)).clamp(0) * \
(torch.min(b1_y2, b2_y2) - torch.max(b1_y1, b2_y1)).clamp(0)
# Union Area
w1, h1 = b1_x2 - b1_x1, b1_y2 - b1_y1 + eps
w2, h2 = b2_x2 - b2_x1, b2_y2 - b2_y1 + eps
union = w1 * h1 + w2 * h2 - inter + eps
iou = inter / union
if CIoU or DIoU or GIoU:
# c是包含两个包围框的最小外接矩形
cw = torch.max(b1_x2, b2_x2) - torch.min(b1_x1, b2_x1) # convex (smallest enclosing box) width
ch = torch.max(b1_y2, b2_y2) - torch.min(b1_y1, b2_y1) # convex height
if CIoU or DIoU: # Distance or Complete IoU https://arxiv.org/abs/1911.08287v1
# c2是包围框的对角线的平方
c2 = cw ** 2 + ch ** 2 + eps # convex diagonal squared
# 中心点的距离
rho2 = ((b2_x1 + b2_x2 - b1_x1 - b1_x2) ** 2 +
(b2_y1 + b2_y2 - b1_y1 - b1_y2) ** 2) / 4 # center distance squared
if CIoU: # https://github.com/Zzh-tju/DIoU-SSD-pytorch/blob/master/utils/box/box_utils.py#L47
v = (4 / math.pi ** 2) * torch.pow(torch.atan(w2 / h2) - torch.atan(w1 / h1), 2)
with torch.no_grad():
alpha = v / (v - iou + (1 + eps))
return iou - (rho2 / c2 + v * alpha) # CIoU
else:
return iou - rho2 / c2 # DIoU
else: # GIoU https://arxiv.org/pdf/1902.09630.pdf
c_area = cw * ch + eps # convex area
return iou - (c_area - union) / c_area # GIoU
else:
return iou # IoU
5. 损失计算
主要分为三部分:
- Classes loss,分类损失,采用的是BCE loss,注意只计算正样本的分类损失。
- Objectness loss,obj损失,采用的依然是BCE loss,注意这里的obj指的是网络预测的目标边界框与GT Box的CIoU。这里计算的是所有样本的obj损失。(这里与v3v4不同,v3v4只判断是否有目标,v5要计算边界框与GT)
- Location loss,定位损失,采用的是CIoU loss,注意只计算正样本的定位损失

预测特征层采用不同权重,小目标的权重会相对较大。

边框回归说白了就是:
找到一个平移和放缩系数,使得目标值与真值去无限接近。满足这个无限接近条件的系数就是回归系数了。
无限接近的意思就是两者尽量像呗,量化的话就是构造个损失函数,让这个函数代表二者相似程度呗,越像,二者之差越小, 通过不断缩小损失函数值,就可以获得一个合适的平移和放缩系数了啊。缩小损失函数值的过程就是优化啊。神经网络的常规套路吧。
compute_loss就是构造损失函数过程,其中边框回归损失函数的组成部分就是
损失函数 = 边框回归系数*anchors - 正样本真值
边框回归神经网络训练的目的就是找到这组回归系数使得正样本对应的anchors无限接近正样本的真值。最终程序输出的置信度是存在置信度*分类置信度,切记,切记。
coding:
smooth_BCE

对标签做平滑处理[1,0]=>[0.95,0.05],可以防止过拟合
def smooth_BCE(eps=0.1): # https://github.com/ultralytics/yolov3/issues/238#issuecomment-598028441
# return positive, negative label smoothing BCE targets
return 1.0 - 0.5 * eps, 0.5 * eps
self.cp, self.cn = smooth_BCE(eps=h.get('label_smoothing', 0.0))
FocalLoss
默认不开启,保证最后正负样本的结果都接近于1,使预测对的样本权重变得很小,预测错的样本权重变得很大,从而解决类别不均衡问题
1.解决了one-stage object detection中图片正负样本不均衡的问题
2.降低简单样本的权重,使损失函数更关注困难样本
class FocalLoss(nn.Module):
# Wraps focal loss around existing loss_fcn(), i.e. criteria = FocalLoss(nn.BCEWithLogitsLoss(), gamma=1.5)
def __init__(self, loss_fcn, gamma=1.5, alpha=0.25):
super().__init__()
self.loss_fcn = loss_fcn # must be nn.BCEWithLogitsLoss()
self.gamma = gamma
self.alpha = alpha
self.reduction = loss_fcn.reduction
self.loss_fcn.reduction = 'none' # required to apply FL to each element
def forward(self, pred, true):
loss = self.loss_fcn(pred, true)
# p_t = torch.exp(-loss)
# loss *= self.alpha * (1.000001 - p_t) ** self.gamma # non-zero power for gradient stability
# TF implementation https://github.com/tensorflow/addons/blob/v0.7.1/tensorflow_addons/losses/focal_loss.py
pred_prob = torch.sigmoid(pred) # prob from logits
# 只留下正样本概率true * pred_prob,让负样本也接近1
p_t = true * pred_prob + (1 - true) * (1 - pred_prob)
alpha_factor = true * self.alpha + (1 - true) * (1 - self.alpha)
# 调整正负样本权重
modulating_factor = (1.0 - p_t) ** self.gamma
loss *= alpha_factor * modulating_factor
if self.reduction == 'mean':
return loss.mean()
elif self.reduction == 'sum':
return loss.sum()
else: # 'none'
return loss
bulid_targets
def build_targets(self, p, targets):
假设p 是每个预测头输出的结果
p[0].shape: torch.Size([16, 3, 80, 80, 85]) # 16是btachsize,3是Anchor的数量,80/40/20: 3个检测头特征图大小,85: coco数据集80个类别+4(x,y,w,h)+1(是否为前景)
p[1].shape: torch.Size([16, 3, 40, 40, 85])
p[2].shape: torch.Size([16, 3, 20, 20, 85])
targets:gt box信息,维度是(n, 6),其中n是整个batch的图片里gt box的数量,以下都以gt box数量为190来举例。
6的每一个维度为(图片在batch中的索引, 目标类别, x, y, w, h)
build_targets主要工作:
主要是处理gt box
1、将gt box复制3份,原因是有三种长宽的anchor, 每种anchor都有gt box与其对应,也就是在筛选之前,一个gt box有三种anchor与其对应。
2、过滤掉gt box的w和h与anchor的w和h的比值大于设置的超参数anchor_t的gt box。
3、剩余的gt box,每个gt box使用至少三个方格来预测,一个是gt box中心点所在方格,另两个是中心点离的最近的两个方格,如下图:

如果gt box的中心坐标是(51.7, 44.8),则由gt box中心点所在方格(51, 44),以及离中心点最近的两个方格(51, 45)和(52, 44)来预测此gt box
#Build targets for compute_loss(), input targets(image,class,x,y,w,h)
na, nt = self.na, targets.shape[0] # na:3, nt:190
#对应类别,边框,对应的Anchor的索引,对应的anchor
tcls, tbox, indices, anch = [], [], [], []
ai = torch.arange(na, device=targets.device).float().view(na, 1).repeat(1, nt) #anchor的索引,shape为(3, 190), 3个anchor因此要复制三份
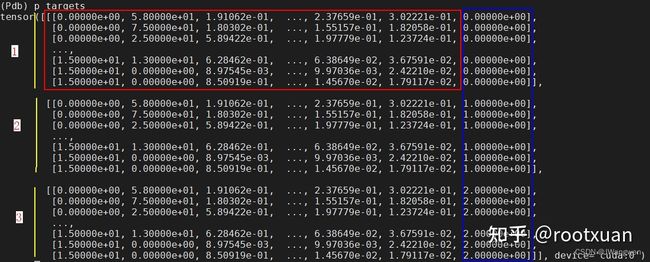
targets = torch.cat((targets.repeat(na, 1, 1), ai[:, :, None]), 2)
#给原始target加上anchor索引,表示对应哪种anchor,重复三遍target对应着三种anchor,下图显示了处理过后的targets内容,其shape为(3, 190, 7), 红色框中是原始的targets, 蓝色框是给每个gt box加上索引
g = 0.5** # bias
off = torch.tensor([[0, 0],
[1, 0], [0, 1], [-1, 0], [0, -1],** # j,k,l,m
# [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
**], device=targets.device).float() * g** # offsets
#遍历feature map self.nl是anchor layer
for i in range(self.nl): // 针对每一个检测头
anchors = self.anchors[i]
当i=0时, anchors值为:
anchors
tensor([[1.25000, 1.62500],
[2.00000, 3.75000],
[4.12500, 2.87500]], device=‘cuda:0’)
gain[2:6] = torch.tensor(p[i].shape)[[3, 2, 3, 2]]
#gain的值是[ 1., 1., 80., 80., 80., 80., 1.], 80的位置对应着gt box信息的xywh
t = targets * gain
#targets里的xywh是归一化到0 ~ 1之间的, 乘以gain之后,将targets的xywh映射到检测头的特征图大小上。
if nt:
r = t[:, :, 4:6] / anchors[:, None]
#这里的r的shape为[3, 190, 2], 2分别表示gt box的w和h与anchor的w和h的比值。
j = torch.max(r, 1. / r).max(2)[0] < self.hyp['anchor_t']
#留下比率在0.25-4之间的
gxy = t[:, 2:4] #取出过滤后的gt box的中心点浮点型的坐标
gxi = gain[[2, 3]] - gxy #将以图像左上角为原点的坐标变换为以图像右下角为原点的坐标
#假设3个anchor总的gt box是3 * 190 = 570个,过滤后还剩余271个
j, k = ((gxy % 1. < g) & (gxy > 1.)).T
#以图像左上角为原点的坐标,取中心点的小数部分,小数部分小于0.5的为ture,大于0.5的为false。true的位置分别表示靠近方格左边的gt box和靠近方格上方的gt box,则j,k的shape就是(271)
l, m = ((gxi % 1. < g) & (gxi > 1.)).T
#以图像右下角为原点的坐标,取中心点的小数部分,小数部分小于0.5的为ture,大于0.5的为false。 l和m的shape都是(271),true的位置分别表示靠近方格右边的gt box和靠近方格下方的gt box,则l,m的shape就是(271)
j和l的值是刚好相反的,k和m的值也是刚好相反的。
j = torch.stack((torch.ones_like(j), j, k, l, m))
#将j, k, l, m组合成一个tensor,另外还增加了一个全为true的维度。组合之后,j的shape为(5, 271)
t = t.repeat((5, 1, 1))[j]
t之前的shape为(271, 7), 这里将t复制5个,然后使用j来过滤,
第一个t是保留所有的gt box,因为上一步里面增加了一个全为true的维度,
第二个t保留了靠近方格左边的gt box,
第三个t保留了靠近方格上方的gt box,
第四个t保留了靠近方格右边的gt box,
第五个t保留了靠近方格下边的gt box,
过滤后,t的shape为(808, 7), 表示保留下来的所有的gt box。
offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]
offsets的shape为(808, 2), 表示保留下来的808个gt box的x, y对应的偏移,
第一个t保留所有的gt box偏移量为[0, 0], 即不做偏移
第二个t保留的靠近方格左边的gt box,偏移为[0.5, 0],即向左偏移0.5(后面代码是用gxy - offsets,所以正0.5表示向左偏移),则偏移到左边方格,表示用左边的方格来预测
第三个t保留的靠近方格上方的gt box,偏移为[0, 0.5],即向上偏移0.5,则偏移到上边方格,表示用上边的方格来预测
第四个t保留的靠近方格右边的gt box,偏移为[-0.5, 0],即向右偏移0.5,则偏移到右边方格,表示用右边的方格来预测
第五个t保留的靠近方格下边的gt box,偏移为[0, 0.5],即向下偏移0.5,则偏移到下边方格,表示用下边的方格来预测
一个gt box的中心点x坐标要么是靠近方格左边,要么是靠近方格右边,y坐标要么是靠近方格上边,要么是靠近方格下边,所以一个gt box在以上五个t里面,会有三个t是true。
也即一个gt box有三个方格来预测,一个是中心点所在方格,另两个是离的最近的两个方格。而yolov3只使用中心点所在的方格预测,这是与yolov3的区别。
else:
t = targets[0]
offsets = 0
b, c = t[:, :2].long().T # image, class
gxy = t[:, 2:4] # grid xy
gwh = t[:, 4:6] # grid wh
gij = (gxy - offsets).long()**
将中心点偏移到相邻最近的方格里,然后向下取整, gij的shape为(808, 2)
gi, gj = gij.T # grid xy indices
#Append
a = t[:, 6].long() # anchor indices
indices.append((b, a, gj.clamp_(0, gain[3] - 1), gi.clamp_(0, gain[2] - 1))) # image, anchor, grid indices
tbox.append(torch.cat((gxy - gij, gwh), 1)) # box
anch.append(anchors[a]) # anchors
tcls.append(c) # class
return tcls, tbox, indices, anch
6. Grid敏感度
在v3中,作者引入sigmoid函数为了使预测坐标最终落在该cell中,但如果落在了边界上或者右下角点,网络的预测值需要负无穷或者正无穷时才能取到,而这种很极端的值网络一般无法达到。

为了解决这个问题,作者对偏移量进行了缩放从原来的( 0 , 1 )缩放到( − 0.5 , 1.5 ) 这样网络预测的偏移量就能很方便达到0或1
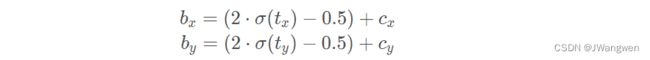
在YOLOv5中除了调整预测Anchor相对Grid网格左上角偏移量之外,还调整了预测目标w,h计算公式,作者解释说原来的计算公式并没有对预测目标宽高做限制,这样可能出现梯度爆炸,训练不稳定等问题,之前是:
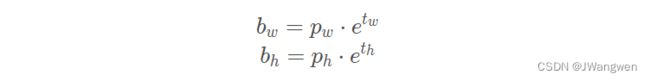
调整为:

下图是修改前y=e^x 和修改后的变化曲线,调整后的倍率因子被限制在(0,4)之间,此处的4在下文正样本匹配会用到。

7. 匹配正样本方式
v4和v5的GT和Anchor匹配方式不同
在YOLOv4中是直接将每个GT Box与对应的Anchor Templates模板计算IoU,只要IoU大于设定的阈值就算匹配成功。
但在YOLOv5中,作者先去计算每个GT Box与对应的Anchor Templates模板的高宽比例
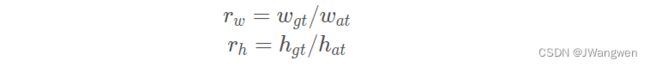
然后统计这些比例和它们倒数之间的最大值,这里可以理解成计算GT Box和Anchor Templates分别在宽度以及高度方向的最大差异(当相等的时候比例为1,差异最小)

若r_max<4(4是调整后的倍率因子),则匹配成功
x1是Anchor原始大小
x4是Anchor尺寸乘4的大小
第一幅图就超过了Anchor x 4 的尺寸

正样本采样细节:
剩下将GT投影到对应预测特征层上,根据GT的中心点定位到对应Cell,注意图中有三个对应的Cell。因为网络预测中心点的偏移范围已经调整到了( − 0.5 , 1.5 ) ,所以按理说只要Grid Cell左上角点距离GT中心点在( − 0.5 , 1.5 )范围内它们对应的Anchor都能回归到GT的位置处。这样会让正样本的数量得到大量的扩充。
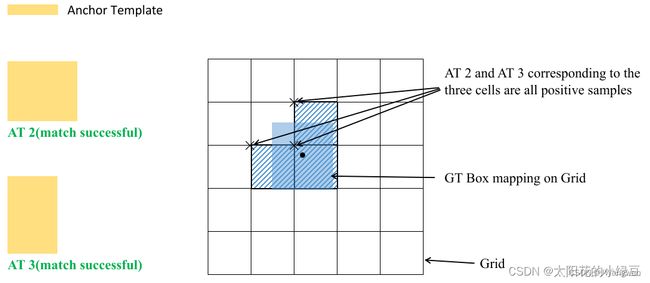

Tips:
1. EMA
问题背景:
由于深度学习训练往往不能找到全局最优解,大部分的时间都是在局部最优来回的晃动,我们所取得到的权重很可能是局部最优的最差的那一个,所以一个解决的办法就是把这几个局部最优解拿过来,做一个均值操作,再让网络加载这个权重进行预测,那么有了这个思想,就衍生了如下的权重平均的方法。
定义:

EMA可以近似看成过去 1/(1-β) 个时刻v值的平均。
普通的过去n时刻的平均是这样的:

类比EMA,可以发现当 β=n-1/n 时,两式形式上相等。需要注意的是,两个平均并不是严格相等的,这里只是为了帮助理解。
实际上,EMA计算时,过去**1/(1-β)**个时刻之前的数值平均会decay到 1/e 的加权比例,如果将这里的v_t展开,可以得到:
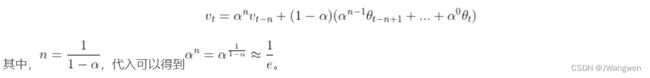
在深度学习中, θt 是t时刻的模型权重weights, vt 是t时刻的影子权重(shadow weights)。在梯度下降的过程中,会一直维护着这个影子权重,但是这个影子权重并不会参与训练。基本的假设是,模型权重在最后的n步内,会在实际的最优点处抖动,所以我们取最后n步的平均,能使得模型更加的鲁棒。
深度学习中公式为:

步骤:
- 初始化EMA
- EMA.register()
- 训练过程中,更新参数EMA.update(),同步update shadow weights
- EMA.apply_shadow()
如何取平均?
这里假设 decay=0.999,一个更直观的理解,在最后的 1000 次训练过程中,模型早已经训练完成,正处于抖动阶段,而滑动平均相当于将最后的 1000 次抖动进行了平均,这样得到的权重会更加 robust。
优点:
1.占内存少,不需要保存过去10个或者100个历史v值,就能够估计其均值。(当然,滑动平均不如将历史值全保存下来计算均值准确,但后者占用更多内存和计算成本更高)
2.不需要增加额外的训练时间,也不需要手动调参,只需要在测试阶段,多进行几组测试挑选最好偶的结果即可
下图是温度数据(蓝点)和拟合曲线(红线)、EMA曲线(绿线),可以看到绿线有明显滞后性,亦步亦趋,如影随形,所以称之为影子变量

2. 参数
在pytorch中模型需要保存下来的参数包括:
parameter:反向传播需要被 optimizer 更新的,可以被训练。
buffer:反向传播不需要被 optimizer 更新,不可被训练。
这两种参数都会分别保存到 一个OrderDict 的变量中,最终由 model.state_module() 返回进行保存。
示例说明:
当我们想要将一些变量保存(如yolov5中的anchor),可以用作简单的后处理,就需要将这种变量注册到网络中,可以使用的api为:
- self.register_buffer() :不可被训练;
- self.register_parameter()、nn.parameter.Parameter()、nn.Parameter():可以被训练。
成员变量:
_buffers:由self.register_buffer() 定义,requires_grad默认为False,不可被训练。
_parasmeter:self.register_parameter()、nn.parameter.Parameter()、nn.Parameter() 定义的变量都存放在该属性下,且定义的参数的 requires_grad 默认为 True。
_module:nn.Sequential()、nn.conv() 等定义的网络结构中的结构存放在该属性下。
成员函数:
self.state_dict():OrderedDict 类型。保存神经网络的推理参数,包括parameter、buffer
self.name_parameters():为迭代器。self._module 和 self._parameters中所有的可训练参数的名字+tensor。包括 BN的 bn.weight、bn.bias。
self.parameters():与self.name_parameters()一样,但不包含名字
self.name_buffers():为迭代器。网络中所有的不可训练参数和自己注册的buffer 中的参数的名字+tensor。包括 BN的 bn.running_mean、bn.running_var、bn.num_batches_tracked。
self.buffers():与self.name_buffers()一样,但不包含名字
net.named_modules():为迭代器。self._module中定义的网络结构的名字+层
net.modules()

3. IOU
Bounding Box Regeression的Loss近些年的发展过程是:Smooth L1 Loss-> IoU Loss(2016)-> GIoU Loss(2019)-> DIoU Loss(2020)->CIoU Loss (2020)
a.IOU_Loss
IOU:GT与predict 的交并比
IOU_Loss = 1 - IOU
然而,存在两个问题:
1. 当IOU=0 时,无法反应两个框距离的远近,此时损失函数不可导,IOU_Loss无法优化两个框不相交的情况。
2. 两个IOU相同,并且两个预测框大小也相同时,IOU_Loss无法区分两个相交情况
因此,引入GIOU_Loss来进行改进。
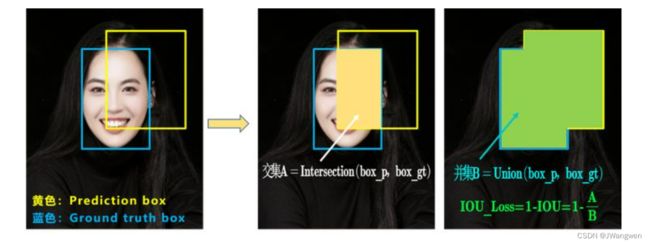


b. GIOU_Loss
GIOU_Loss = 1 - GIOU = 1- ( IOU - 差集/外接矩形 )
其中,A是预测框,B是真实框,C是A和B的最小包围框,A、B、C的关系具体如下图所示。
GIOU解决了IOU=0时的问题,然而IOU相同的问题并没有解决,预测框在目标框内部且预测框大小一致的情况,这时预测框和目标框的差集都是相同的,因此这三种状态的GIOU值也都是相同的,这时GIOU退化成了IOU,无法区分相对位置关系。
因此,引入DIOU_Loss来进行改进。




c. DIOU_Loss
好的目标框回归函数应该考虑三个重要几何因素:重叠面积、中心点距离,长宽比
GIOU_Loss = 1 - GIOU = 1- ( IOU - 中心点距离 / 对角线距离 )
DIOU_Loss考虑了重叠面积和中心点距离,当目标框包裹预测框的时候,直接度量2个框的距离,因此DIOU_Loss收敛的更快
但是,没有考虑到长宽比。
比如上面三种情况,目标框包裹预测框,本来DIOU_Loss可以起作用。
但预测框的中心点的位置都是一样的,因此按照DIOU_Loss的计算公式,三者的值都是相同的。
因此,引入CIOU_Loss来进行改进。
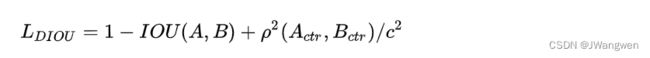


d. CIOU_Loss
CIOU_Loss和DIOU_Loss前面的公式都是一样的,不过在此基础上还增加了一个影响因子,将预测框和目标框的长宽比都考虑了进去。
其中v是衡量长宽比一致性的参数,我们也可以定义为
这样CIOU_Loss就将目标框回归函数应该考虑三个重要几何因素:重叠面积、中心点距离,长宽比全都考虑进去了。


总结:
IOU_Loss:主要考虑检测框和目标框重叠面积。
GIOU_Loss:在IOU的基础上,解决边界框不重合时的问题。
DIOU_Loss:在IOU和GIOU的基础上,考虑边界框中心点距离的信息。
CIOU_Loss:在DIOU的基础上,考虑边界框宽高比的尺度信息。
Yolov4中采用了CIOU_Loss的回归方式,使得预测框回归的速度和精度更高一些。
Related:
1.https://blog.csdn.net/qq_37541097/article/details/123594351
2.指数移动平均(EMA)的原理及PyTorch实现
3.【炼丹技巧】指数移动平均(EMA)【在一定程度上提高最终模型在测试数据上的表现(例如accuracy、FID、泛化能力…)】
4.【笔记】 提升分类模型ACC,BatchSize&LARS、Bag of Tricks:tirck不一定适用于不同的数据场景
5.YOLOV5使用到的trick(一)
6.未看:深度神经网络模型训练中的 tricks(原理与代码汇总)
7.IOU、GIOU、DIOU、CIOU损失函数详解
8.coding解析很详细:
2021SC@SDUSC山东大学软件学院软件工程应用与实践–YOLOV5代码分析(十一)loss.py
YoloV5代码详细解读