循环神经网络实现股票预测
活动地址:CSDN21天学习挑战赛
目录
1.跑通代码
2.代码分析:
2.1
2.2
2.3
2.4
2.5
2.6
补充说明
新的概念
2模型保存
(10条消息) tensorflow零基础入门学习_重邮研究森的博客-CSDN博客_tensorflow 学习 https://blog.csdn.net/m0_60524373/article/details/124143223
https://blog.csdn.net/m0_60524373/article/details/124143223
>- 本文为[365天深度学习训练营](https://mp.weixin.qq.com/s/k-vYaC8l7uxX51WoypLkTw) 中的学习记录博客
>- 参考文章地址: [深度学习100例-循环神经网络(RNN)实现股票预测 | 第9天]((10条消息) 机器学习第10天:模型评价方法及代码实现_K同学啊的博客-CSDN博客_机器学习模型评价代码)
本文开发环境:tensorflowgpu2.5,pychrm
1.跑通代码
我这个人对于任何代码,我都会先去跑通之和才会去观看内容,哈哈哈,所以第一步我们先不管37=21,直接把博主的代码复制黏贴一份运行结果。(PS:做了一些修改,因为原文是jupyter,而我在pycharm)
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
tf.config.experimental.set_memory_growth(gpus[0], True) #设置GPU显存用量按需使用
tf.config.set_visible_devices([gpus[0]],"GPU")
import os,math
from tensorflow.keras.layers import Dropout, Dense, SimpleRNN
from sklearn.preprocessing import MinMaxScaler
from sklearn import metrics
import numpy as np
import pandas as pd
import tensorflow as tf
import matplotlib.pyplot as plt
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
data = pd.read_csv('./dataset/SH600519.csv') # 读取股票文件
print(data)
# inputs = np.random.random([5, 3, 4]).astype(np.float32)
# print(inputs)
# print("---------")
# simple_rnn = tf.keras.layers.SimpleRNN(6)
#
# output = simple_rnn(inputs)
# print(output)
"""
前(2426-300=2126)天的开盘价作为训练集,表格从0开始计数,2:3 是提取[2:3)列,前闭后开,故提取出C列开盘价open
后300天的开盘价作为测试集
"""
training_set = data.iloc[0:2426 - 300, 2:3].values
test_set = data.iloc[2426 - 300:, 2:3].values
sc = MinMaxScaler(feature_range=(0, 1))#归一化
training_set = sc.fit_transform(training_set)
test_set = sc.transform(test_set)
x_train = []
y_train = []
x_test = []
y_test = []
"""
使用前60天的开盘价作为输入特征x_train
第61天的开盘价作为输入标签y_train
for循环共构建2426-300-60=2066组训练数据。
共构建300-60=240组测试数据
"""
for i in range(60, len(training_set)):
x_train.append(training_set[i - 60:i, 0])
y_train.append(training_set[i, 0])
for i in range(60, len(test_set)):
x_test.append(test_set[i - 60:i, 0])
y_test.append(test_set[i, 0])
# 对训练集进行打乱
np.random.seed(7)
np.random.shuffle(x_train)
np.random.seed(7)
np.random.shuffle(y_train)
tf.random.set_seed(7)
"""
将训练数据调整为数组(array)
调整后的形状:
x_train:(2066, 60, 1)
y_train:(2066,)
x_test :(240, 60, 1)
y_test :(240,)
"""
x_train, y_train = np.array(x_train), np.array(y_train) # x_train形状为:(2066, 60, 1)
x_test, y_test = np.array(x_test), np.array(y_test)
"""
输入要求:[送入样本数, 循环核时间展开步数, 每个时间步输入特征个数]2066组数据,60个记忆体,一组一个数据
"""
x_train = np.reshape(x_train, (x_train.shape[0], 60, 1))
print(x_train.shape[0])
x_test = np.reshape(x_test, (x_test.shape[0], 60, 1))
print(x_test.shape[0])
model = tf.keras.Sequential([
SimpleRNN(100, return_sequences=True), #布尔值。是返回输出序列中的最后一个输出,还是全部序列记忆体个数越多越好
Dropout(0.1), #防止过拟合
SimpleRNN(20),
Dropout(0.1),
Dense(1)
])
# 该应用只观测loss数值,不观测准确率,所以删去metrics选项,一会在每个epoch迭代显示时只显示loss值
model.compile(optimizer=tf.keras.optimizers.Adam(0.001),
loss='mean_squared_error') # 损失函数用均方误差
history = model.fit(x_train, y_train,
batch_size=64,
epochs=20,
validation_data=(x_test, y_test),
validation_freq=1) #测试的epoch间隔数
model.summary()
plt.plot(history.history['loss'] , label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.title('Training and Validation Loss by jason')
plt.legend()
plt.show()
predicted_stock_price = model.predict(x_test) # 测试集输入模型进行预测
predicted_stock_price = sc.inverse_transform(predicted_stock_price) # 对预测数据还原---从(0,1)反归一化到原始范围
real_stock_price = sc.inverse_transform(test_set[60:]) # 对真实数据还原---从(0,1)反归一化到原始范围
# 画出真实数据和预测数据的对比曲线
plt.plot(real_stock_price, color='red', label='Stock Price')
plt.plot(predicted_stock_price, color='blue', label='Predicted Stock Price')
plt.title('Stock Price Prediction by jason')
plt.xlabel('Time')
plt.ylabel('Stock Price')
plt.legend()
plt.show()
"""
MSE :均方误差 -----> 预测值减真实值求平方后求均值
RMSE :均方根误差 -----> 对均方误差开方
MAE :平均绝对误差-----> 预测值减真实值求绝对值后求均值
R2 :决定系数,可以简单理解为反映模型拟合优度的重要的统计量
详细介绍可以参考文章:https://blog.csdn.net/qq_38251616/article/details/107997435
"""
MSE = metrics.mean_squared_error(predicted_stock_price, real_stock_price)
RMSE = metrics.mean_squared_error(predicted_stock_price, real_stock_price)**0.5
MAE = metrics.mean_absolute_error(predicted_stock_price, real_stock_price)
R2 = metrics.r2_score(predicted_stock_price, real_stock_price)
print('均方误差: %.5f' % MSE)
print('均方根误差: %.5f' % RMSE)
print('平均绝对误差: %.5f' % MAE)
print('R2: %.5f' % R2)
点击pycharm即可运行出最后的预测结果!

2.代码分析:
神经网络的整个过程我分为如下六部分,而我们也会对这六部分进行逐部分分析。那么这6部分分别是:
六步法:
1->import
2->train test(指定训练集的输入特征和标签)
3->class MyModel(model) model=Mymodel(搭建网络结构,逐层描述网络)
4->model.compile(选择哪种优化器,损失函数)
5->model.fit(执行训练过程,输入训练集和测试集的特征+标签,batch,迭代次数)
6->验证
2.1
导入:这里很容易理解,也就是导入本次实验内容所需要的各种库。在本案例中主要包括以下部分:
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
tf.config.experimental.set_memory_growth(gpus[0], True) #设置GPU显存用量按需使用
tf.config.set_visible_devices([gpus[0]],"GPU")
import os,math
from tensorflow.keras.layers import Dropout, Dense, SimpleRNN
from sklearn.preprocessing import MinMaxScaler
from sklearn import metrics
import numpy as np
import pandas as pd
import tensorflow as tf
import matplotlib.pyplot as plt这里开头的部分就是一个设置GPU的部分,你也可以选择不设置,然后下面很多库都是用来计算的。
对于这里的话我们可以直接复制黏贴,当需要一些其他函数时,只需要添加对应的库文件即可。
2.2
设置训练集和测试集:对于神经网络的训练包括了两种数据集合,一个是训练集,一个是测试集。其中训练集数据较多,测试集较少,因为训练一个模型数据越多相对的模型更准确。
本文中利用的数据集在文章下方,该数据集是一个excel表,存放了股票信息
本文中数据集处理较为复杂,包括了随机数,中文格式显示,数据集设置等,我们将分别对代码进行解释。
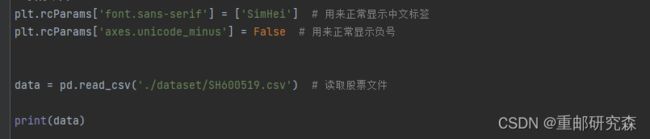
这里主要是设置中文显示,以及加载我们的数据集文件

设置训练集合为前2426-300个,且标签为excel文件的第3列(因为文件从第0列开始,且第四列为开区间)
设置后300个数据为测试集。

对sc设置为0-1之间数据归一化
第二行是找出training_set的均值和标准差等数据
第三行是找出test_set的均值和标准差等数据
注意事项:为什么第二行和第三行多了一个fit呢?这是因为在使用时,必须先fit,下一个就不用再fit
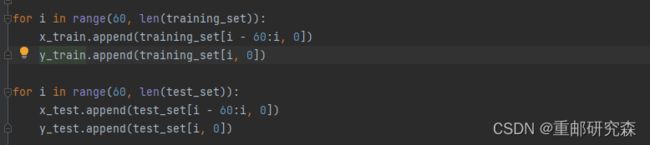
这里是一个for i in range(start, end)):
也就是说i的取值为60-traing_set进行取值。所以,x_train为前60个开盘价,y_train为61之后的开盘价,其中x为特征,y为标签
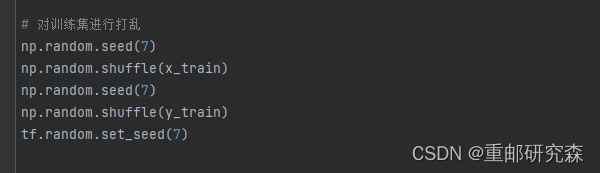
如上为随机数种子的设置,神经网络的方法起始我感觉就是扩展变量法,所以为了保证初始情况都一样,因此设置随机数种子。

先把数据转为np形式,然后修改各种的格式,满足输入要求。
2.3
网络模型搭建:这里也是神经网络的重点了!废话不多说,直接开始!
本文的神经网络的结构图如下:
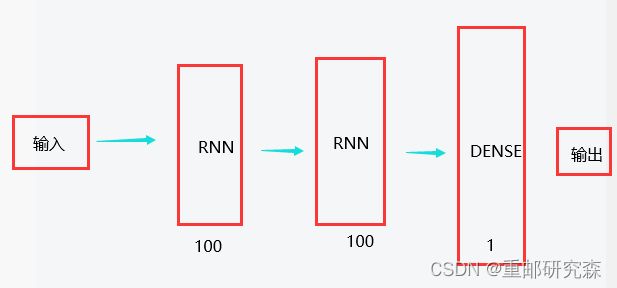
在搭建模型的时候,我们将按照这个图片进行模型的搭建。
循环层1:输出维度100
SimpleRNN(100, return_sequences=True)过滤层1(防止过拟合)详细解释参考本文开头的另外一篇基础介绍
Dropout(0.1)循环层2:输出维度100
SimpleRNN(100, return_sequences=True)过滤层2
Dropout(0.1)全连接层1:输出维度1
Dense(1)重点:
现在我们来分析一下图片中经过每层后数据的维度怎么来的
经过循环层1之后,原数据有2046个,循环核展开步数60,特征1变为60x100,公式为:输入步长x循环网络输出维度
经过循环层1之后,原数据60x100,变为100,公式为:循环网络输出维度
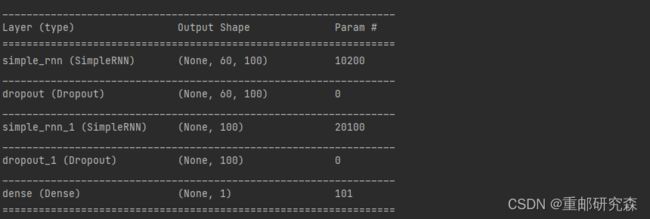
到此,网络模型我们变分析完了。
循环网络每经过一次,就会变成这样,我也不太理解。但从下面截图可以看出是这样的。
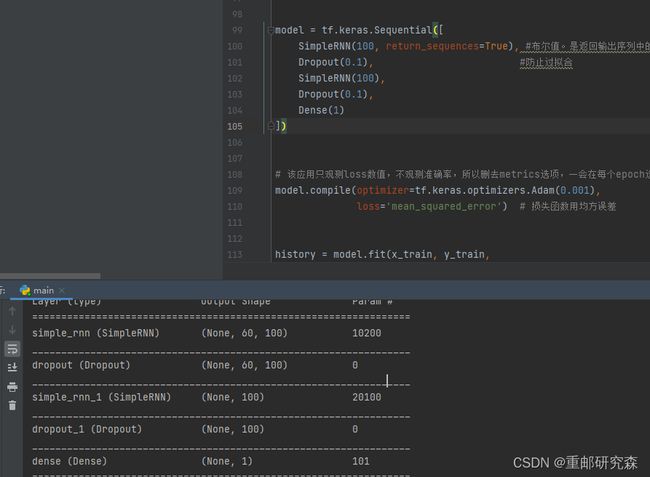

到此,我们便把网络模型设置的原因以及网络模型的输出结果进行了对应,我们可以看到网络模型的输出和我们分析的一致。
2.4
该部分也同样重要,主要完成模型训练过程中的优化器,损失函数,准确率的设置。
我们结合本文来看。
# 该应用只观测loss数值,不观测准确率,所以删去metrics选项,一会在每个epoch迭代显示时只显示loss值
model.compile(optimizer=tf.keras.optimizers.Adam(0.001),
loss='mean_squared_error') # 损失函数用均方误差其中:对于这2个内容的含义可以参考我的文章开头的另外一篇基础博文进行了详细的介绍
2.5
该部分就是执行训练了,那么执行训练肯定需要设置训练集数据及其标签,测试集数据及其标签,训练的epoch
history = model.fit(x_train, y_train,
batch_size=64,
epochs=20,
validation_data=(x_test, y_test),
validation_freq=1) #测试的epoch间隔数
model.summary()2.6
当训练执行完毕,我们就可以拿一个测试集合中或者其他满足格式的数据进行验证了
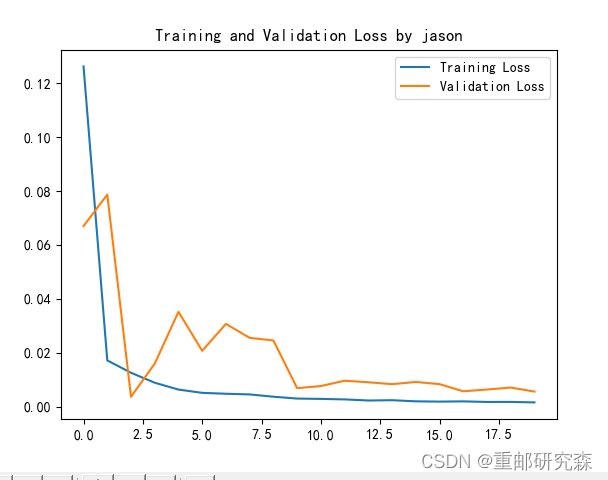
plt.plot(history.history['loss'] , label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.title('Training and Validation Loss by jason')
plt.legend()
plt.show()
predicted_stock_price = model.predict(x_test) # 测试集输入模型进行预测
predicted_stock_price = sc.inverse_transform(predicted_stock_price) # 对预测数据还原---从(0,1)反归一化到原始范围
real_stock_price = sc.inverse_transform(test_set[60:]) # 对真实数据还原---从(0,1)反归一化到原始范围
# 画出真实数据和预测数据的对比曲线
plt.plot(real_stock_price, color='red', label='Stock Price')
plt.plot(predicted_stock_price, color='blue', label='Predicted Stock Price')
plt.title('Stock Price Prediction by jason')
plt.xlabel('Time')
plt.ylabel('Stock Price')
plt.legend()
plt.show()这里就是绘制训练集和测试集的损失函数图像
我们取测试集合进行模型验证,查看预测值和真实的值的情况。
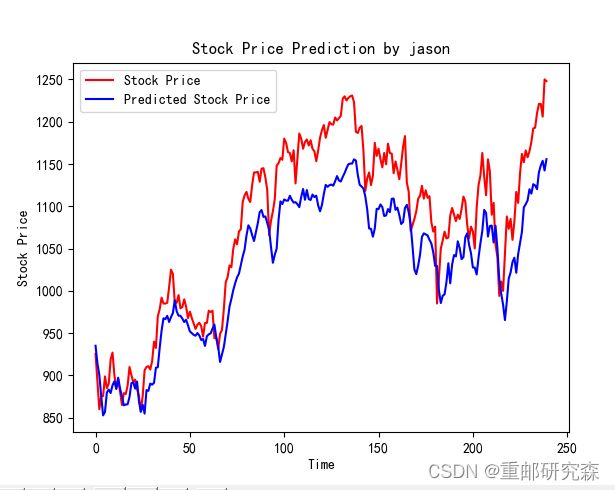
可以看出,到了后面,预测值和真实值差距还是很大。
补充说明
新的概念
"""
MSE :均方误差 -----> 预测值减真实值求平方后求均值
RMSE :均方根误差 -----> 对均方误差开方
MAE :平均绝对误差-----> 预测值减真实值求绝对值后求均值
R2 :决定系数,可以简单理解为反映模型拟合优度的重要的统计量
详细介绍可以参考文章:https://blog.csdn.net/qq_38251616/article/details/107997435
"""
MSE = metrics.mean_squared_error(predicted_stock_price, real_stock_price)
RMSE = metrics.mean_squared_error(predicted_stock_price, real_stock_price)**0.5
MAE = metrics.mean_absolute_error(predicted_stock_price, real_stock_price)
R2 = metrics.r2_score(predicted_stock_price, real_stock_price)
print('均方误差: %.5f' % MSE)
print('均方根误差: %.5f' % RMSE)
print('平均绝对误差: %.5f' % MAE)
print('R2: %.5f' % R2)这里我们引入了一些新的概念,而这些概念是用来对于模型准确率进行验证的一些值。其中我主要说明一下R2的含义。

2模型保存
为了不重复训练,这里我们加一个模型保存的部分,其实很简单,步骤如下:
1.新建一个python文件
2.复制数据集到新文件
3.使用下列代码
#模型保存
model.save(r'model_data/model.h5')# 模型的恢复
model = tf.keras.models.load_model(r'model_data/model.h5')4.预测开始