Python数据分析(二)—— Pandas快速入门
Pandas快速入门
- 1 数据加载
- 2 数据探索
-
- (1)Series
- (2) DataFrame
- 3 数据合并
-
- (1) merge
- (2)concat
- (3)join
- 4 数据处理
-
- (1)去重
- (2)数据转换
- (3)缺失值处理
- (4)apply方法
- (5)计算哑变量
- (6)离散化
- (7)排序
Pandas是基于NumPy的数据分析包,兼具NumPy高性能的数组计算功能以及电子表格和关系型数据库(SQL)灵活的数据处理功能,提供了大量快速处理数据的方法以及适用于金融数据的高性能时间序列功能和工具。
Pandas的名称来自于Panel data和Python data analysis,最初由AQR Capital Management在2008年4月作为金融数据分析工具开发出来,并于2009年底开源,目前由PyData开发和维护。
MovieLens(https://movielens.org/ )美国Minnesota 大学计算机科学与工程学院的 GroupLens 项目组(https://grouplens.org ) 创办,是一个非商业性质的、以研究为目的的实验性站点,通过使用 Collaborative Filtering 和 Association Rules 相结合的技术,向用户推荐他们感兴趣的电影。
MovieLens数据集(http://files.grouplens.org/datasets/movielens/ ) 是GroupLens 项目组采集的一组从20世纪90年代末到21世纪初由MovieLens用户提供的电影评分数据,该数据集包括电影评分、电影元数据(时间与类型)以及关于用户的数据(年龄、性别、职业、邮编)。
本文使用MovieLen 1M版本(m1-1m.zip),该数据集包括三个文件:用户信息、影片信息(1919-200年的3883部电影)、评分信息,readme为说明文件,包括了年龄和职业的编码说明。
1 数据加载
pandas通过以下方法将数据加载到pandas的DataFrame对象中:
read_csv默认分隔符为逗号read_table默认分隔符为制表符(\t)
主要参数如下:
path: 文件的系统路径sep或delimiter: 对各字段拆分的字符序列或正则表达式index_col: 行索引的列编号或列名names: 列名的列表parse_dates: 尝试将数据解析为日期(默认False)encoding: 文本编码格式(utf-8, gb18030, gb2312),文件中中文需要使用encoding='gb18030'或encoding='gb2312'engine:路径中有中文需要使用engine='python'
2 数据探索
(1)Series
Series是一种类似于一维数组的对象,由一组数据及一组与之相关的数据标签(索引)组成。通过一组数组可产生最简单的Series
obj = pd.Series([4,7,-5,3])
进行NumPy数组运算(如根据布尔型数组进行过滤、标量乘法、应用数据函数等)都会保留索引和值之间的链接,如
obj[obj>2]
Series对象本身及其索引都有一个name属性,可以对其进行赋值。
obj = pd.Series([4,7,-5,3])
obj[obj>2]

(2) DataFrame
DataFrame是一个表格型的数据结构(面向列的二维表),含有一组有序的列,每列可以是不同的值类型;既有行索引也有列索引,可看做由Series组成的字典。
#查看数据整体信息
users.info()
#查看数据统计相关信息,包括最大、最小、平均值、标准差等
users.describe()
#查看用户数据前5行
users.head()
users[:5]
users.iloc[:5] #通过行号索引行数据
users.loc[:4] #通过行标签索引数据
# 查看数据第5行
users.iloc[5]
users.loc[5]
# 按照步长查看特定行
users[1:5:2] #(start:end-1:step)
users.iloc[1:5:2] #(start:end-1:step)
users.loc[1:5:2] #(start:end:step)
# 根据条件选择特定行
users[(users.age>50)&(users.sex=='F')]
movies[movies.title.str.contains('Titanic')]
# 选定一组列
users.iloc[:,1:4]
users[['sex','age']]
3 数据合并
(1) merge
merge可根据一个或多个键将不同DataFrame中的行连接起来(类似于SQL中join操作)。默认情况下,merge做的是inner连接,结果中的键是交集,其他方式还有left、right以及outer。outer(外连接)求取的是键的并集,组合了左连接和右连接的效果。
pd.merge(left,right,how='inner',on=None,left_on=None,right_on=None,left_index=False,right_index=False)
主要参数如下:
left: 参与合并的左侧DataFrameright: 参与合并的右侧DataFramehow: inner/outer/left/right,默认inneron: 用于连接的列名,若不指定,将重叠列的列名当做键left_on: 左侧DataFrame中用作连接键的列right_on: 右侧DataFrame中用作连接键的列left_index: 左侧行索引作为连接键right_index: 右侧行索引作为连接键
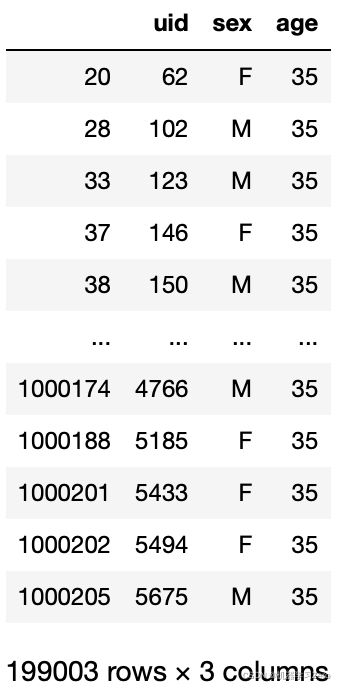
data = pd.merge(pd.merge(users,ratings),movies)
data.head()

data[(data.age>=30)&(data.age<40)][["uid","sex","age"]]
(2)concat
concat方法将两个对象按指定轴连接(concatenation),这个过程也被称作绑定(binding)或堆叠(stacking)。
concat默认是在**axis=0(row)**上进行连接(类似于SQL中union all操作),axis=1(column)。
pd.concat([df1,df2])等同于df1.append(df2)pd.concat([df1,df2],axis=1)等同于pd.merge(df1,df2,left_index=True,right_index=True,how='outer')
主要参数如下:
objs:Series,DataFrame或Panel对象的序列或映射。如果传递了dict,则排序的键将用作键参数,除非它被传递,在这种情况下,将选择值(见下文)。任何无对象将被静默删除,除非它们都是无,在这种情况下将引发一个ValueError。axis:连接轴向,默认为0join:{‘inner’,‘outer’},默认为“outer”ignore_index:不保留连接轴上的索引,产生一组新索引range(total_length),默认False。join_axes:Index对象列表。用于其他n-1轴的特定索引,而不是执行内部/外部设置逻辑。keys:序列,默认值无。使用传递的键作为最外层构建层次haunted索引。如果为多索引,应该使用元组。levels:序列列表,默认值无。用于构建MultiIndex的特定级别(唯一值)。否则,它们将从键推断。names:结果层次索引中的级别的名称。verify_integrity:检查新连接的轴是否包含重复项
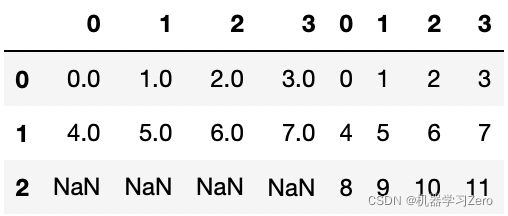
df1 = pd.DataFrame(np.arange(8).reshape(2,4))
df2 = pd.DataFrame(np.arange(12).reshape(3,4))
pd.concat([df1,df2])

pd.concat([df1,df2],axis=1)
(3)join
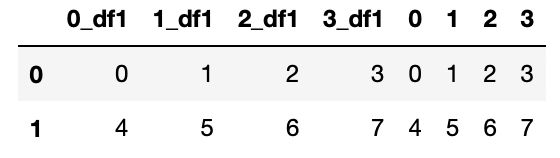
join方法提供了两个DataFrame基于索引的连接,其中参数的意义与merge方法基本相同,join方法默认为左外连接how=‘left’。
df1.join(df2,lsuffix = '_df1')
4 数据处理
(1)去重
drop_duplicates返回一个移除了重复行的DataFrame,默认保留第一个出现的值组合。
(2)数据转换
map接受一个函数或含有映射关系的字典型对象,实现元素级转换。
replace提供了一种更简单灵活的方式。
data = pd.DataFrame({'gender':['F','F','M','M','F','M',]})
mapTran = {'F':0,'M':1}
data.gender.map(mapTran) # 使用map函数
data.gender.replace(mapTran) #使用replace函数
(3)缺失值处理
pandas使用浮点值NaN(Not a Number)表示浮点和非浮点数组中的缺失数据。
dropna:根据个标签的值中是否存在缺失数据对轴标签(默认axis=0,丢弃列传入axis=1)进行过滤。默认丢弃任何含有缺失值的行,传入how='all'fillna:使用指定值或插值方法填充缺失数据,默认返回新对象。isnull:返回一个含有布尔值的对象,表示那些只是缺失值
通过字典调用fillna,可实现对不同的列填充不同的值,可以看做replace的一种特殊情况,如
df.fillna({'tz':'missing'})
(4)apply方法
每部电影的上映时间包含在title字段中,如’One Flew Over the Cuckoo’s Nest (1975)’,可以通过使用一个lambda函数提取出上映时间:
movies['year'] = movies.title.apply ( lambda x : x [- 5 :- 1 ]) # 分析电影时间
(5)计算哑变量
机器学习中常将分类变量(categorical variable)转换为“哑变量矩阵”(dummy matrix)或“指标矩阵”(indicator matrix)。如果DataFrame的某一列中有 k k k个不同值,则可以派生出一个k列矩阵或DataFrame(其值全为0和1)。可以使用get_dummies。
df = pd.DataFrame({'key':['b','b','a','c','a','b'],'data1':range(6)})
pd.get_dummies(df['key'])
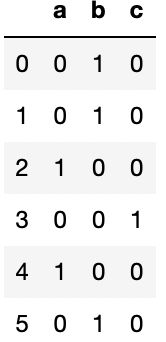
每部电影有多个类型标签,如Saving Private Ryan (1998)同属于Action|Drama|War三种类型。首先构建一个所有电影类型的列表genre;然后初始化一个全零的DataFrame,通过使用enumerate方法遍历电影类型,将DataFrame对应行列的值置为1,进行One-hot encoding,并连接形成新的DataFrame。
# 分析电影类型
genre_iter = [set(x.split('|')) for x in movies.genres]
genre = sorted(set.union(*genre_iter))
genre_matrix = pd.DataFrame(np.zeros((len(movies),len(genre))),columns=genre)
for i,gen in enumerate(movies.genres):
genre_matrix.loc[i][gen.split('|')] = 1
movies_new = movies.join(genre_matrix)
(6)离散化
连续数据常常被离散化,使用cut或qcut。qcut使用的是样本分位数,可以得到大小基本相当的区间。
ages = [20,22,25,27,21,24,37,21,31,61,45,41,32]
bins = [18,30,50,100]
ages_cut = pd.cut(ages,bins)
ages_cut.codes #每个分类名称
pd.value_counts(ages_cut) #不同面元的计数
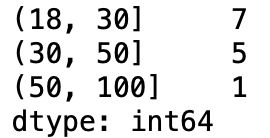
(7)排序
要对行或列索引进行排序(按字典排序),可使用sort_values方法(sort_index已废弃),返回一个已排序的新对象。
要对多个列进行排序,传入名称的列表即可。
movies.sort_values(by = ['genres','title'])[:5]
数据默认是升序排序的,使用ascending=False可以降序排序。默认axis=0对行(row)进行排序,使用axis=1对列(column)进行排序。
reindex方法会根据新索引对数据进行重排,使用columns关键字可重新索引列;rename方法可以重命名行列名。
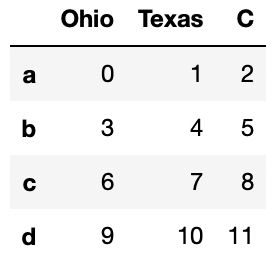
frame = pd.DataFrame(np.arange(12).reshape(4,3),index=['a','b','c','d'],columns=['Ohio','Texas','Cali'])
frame

frame.reindex(['a','c','b','d'],columns=['Cali','Texas','Ohio'])
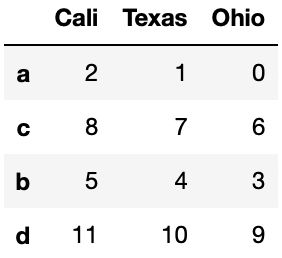
frame.rename(columns={'Cali':'C'}) #重命名