目前网络上开源的网络爬虫以及一些简介和比较
目前网络上有不少开源的网络爬虫可供我们使用,爬虫里面做的最好的肯定是google ,不过google公布的蜘蛛是很早的一个版本,下面是几种开源的网络爬虫的简单对比表:
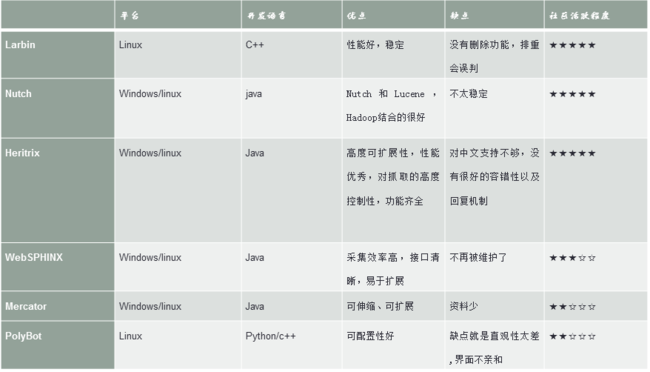
下面我们再对Nutch、Larbin、Heritrix这三个爬虫进行更细致的比较:
Nutch
开发语言:Java
http://lucene.apache.org/nutch/
简介:
Apache的子项目之一,属于Lucene项目下的子项目。
Nutch是一个基于Lucene,类似Google的完整网络搜索引擎解决方案,基于Hadoop的分布式处理模型保证了系统的性能,类似Eclipse的插件机制保证了系统的可客户化,而且很容易集成到自己的应用之中。
Larbin
开发语言:C++
http://larbin.sourceforge.net/index-eng.html
简介
larbin是一种开源的网络爬虫,由法国的年轻人 Sébastien Ailleret独立开发。larbin目的是能够跟踪页面的url进行扩展的抓取,最后为搜索引擎提供广泛的数据来源。
Larbin只是一个爬虫,也就是说larbin只抓取网页,至于如何parse的事情则由用户自己完成。另外,如何存储到数据库以及建立索引的事情 larbin也不提供。
latbin最初的设计也是依据设计简单但是高度可配置性的原则,因此我们可以看到,一个简单的larbin的爬虫可以每天获取500万的网页,非常高效。
Heritrix
开发语言:Java
简介
与Nutch比较
和 Nutch。二者均为Java开源框架,Heritrix 是 SourceForge上的开源产品,Nutch为Apache的一个子项目,它们都称作网络爬虫它们实现的原理基本一致:深度遍历网站的资源,将这些资源抓取到本地,使用的方法都是分析网站每一个有效的URI,并提交Http请求,从而获得相应结果,生成本地文件及相应的日志信息等。
Heritrix 是个 "archival crawler" -- 用来获取完整的、精确的、站点内容的深度复制。包括获取图像以及其他非文本内容。抓取并存储相关的内容。对内容来者不拒,不对页面进行内容上的修改。重新爬行对相同的URL不针对先前的进行替换。爬虫通过Web用户界面启动、监控、调整,允许弹性的定义要获取的URL。
二者的差异:
Nutch 只获取并保存可索引的内容。Heritrix则是照单全收。力求保存页面原貌
Nutch 可以修剪内容,或者对内容格式进行转换。
Nutch 保存内容为数据库优化格式便于以后索引;刷新替换旧的内容。而Heritrix 是添加(追加)新的内容。
Nutch 从命令行运行、控制。Heritrix 有 Web 控制管理界面。
Nutch 的定制能力不够强,不过现在已经有了一定改进。Heritrix 可控制的参数更多。
Heritrix提供的功能没有nutch多,有点整站下载的味道。既没有索引又没有解析,甚至对于重复爬取URL都处理不是很好。
Heritrix的功能强大 但是配置起来却有点麻烦。