
作者:韩信子@ShowMeAI
深度学习实战系列:https://www.showmeai.tech/tutorials/42
TensorFlow实战系列: https://www.showmeai.tech/tutorials/43
本文地址:https://www.showmeai.tech/article-detail/290
声明:版权所有,转载请联系平台与作者并注明出处
收藏ShowMeAI查看更多精彩内容
深度学习是机器学习的一类算法,它应用各种结构的神经网络解决问题(深度学习中的『深度』指的是我们会通过深层次的神经网络构建强大的学习器),模仿人类获得某些类型知识的方式,与传统机器学习模型相比,神经网络有更灵活的结构设计,更强的学习能力,能支撑更大量级的数据学习,因此广泛引用于各种业务中。

神经网络是简化人脑的学习思考过程构建的结构,它是一个连接单元(神经元)的连接堆叠结构,我们设计这些单元,希望它们能在一定程度上模仿大脑中的突触,将信号传递给其他神经元,就像相互连接的脑细胞一样,可以在更多的时间里学习和做出决定。如下是简单的神经网络拆解图。

深度学习与神经网络有很多不同的结构和应用,想要系统学习这部分知识的同学,可以查看ShowMeAI制作的下列教程:
ShowMeAI 将在本文中,全面图解展示使用 Python 构建神经网络的过程,覆盖TensorFlow建模、可视化网络、模型预测结果归因与解释。
文中讲解到的板块和对应的实现 Python 代码,可以很容易地迁移应用于其他类似情况(复制、粘贴、运行),我们对代码做了详尽的注释讲解。
全文的总体内容结构包括:
- 环境设置与TensorFlow工具库简介
- 神经网络分解、输入、输出、隐藏层、激活函数
- 使用深度神经网络进行深度学习
- 进行模型设计(基于TensorFlow)
- 可视化神经网络
- 模型训练和测试
- 模型可解释性
环境设置
目前主流的神经网络工具库有2个:TensorFlow https://www.tensorflow.org/(由 Google 开发)和 PyTorch https://pytorch.org/ (由 Facebook 开发) 。 他们有很多相似之处,功能也都很全面,但总体来说前者更适合生产,而后者更适合构建快速原型。
这两个库都可以利用 GPU 的强大矩阵运算功能去加速神经网络的训练和预估,这对于处理大型数据集(如文本语料库或图像库)非常有用,而其对应的开发社区也有着丰富的资源,不管你解决何种问题,总可以找到相关的参考资料。
本篇内容使用到的是 TensorFlow 工具库。

对于本篇使用到的工具,ShowMeAI制作了快捷即查即用的工具速查表手册,大家可以在下述位置获得:
我们先在终端通过 pip install 命令安装 TensorFlow。
pip install tensorflow
现在我们可以在 Notebook 上导入 TensorFlow Keras 并开始编码:
# 导入所需的工具库
# tensorflow建模
from tensorflow.keras import models, layers, utils, backend as K
# 可视化
import matplotlib.pyplot as plt
# 特征重要度与模型归因分析
import shap
神经网络拆解
神经网络的结构拆解的详细内容,推荐大家查看ShowMeAI的教程 深度学习教程 | 吴恩达专项课程 · 全套笔记解读下述文章:
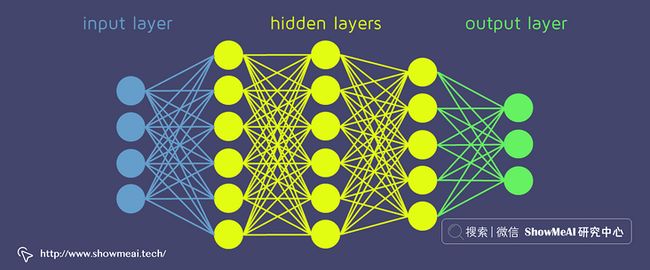
人工神经网络由若干层组成(每一层有独立的输入和输出维度)。这些层可以分组为:
- 输入层 : 负责将输入向量传递给神经网络。如果我们有一个包含 3 个特征的矩阵(形状 N x 3),则该层将 3 个数字作为输入,并将相同的 3 个数字传递给下一层。
- 隐藏层 : 代表中间节点,它们对数字进行多次变换以提高最终结果的准确性,输出由神经元的数量定义。
- 输出层 : 返回神经网络最终输出的 如果我们进行简单的二元分类或回归,输出层应该只有 1 个神经元(因此它只返回 1 个数字)。在具有 5 个不同类别的多类别分类的情况下,输出层应有 5 个神经元。
最简单的神经网络形式是感知器,一个只有一层的模型,与线性回归/逻辑回归模型非常相似。
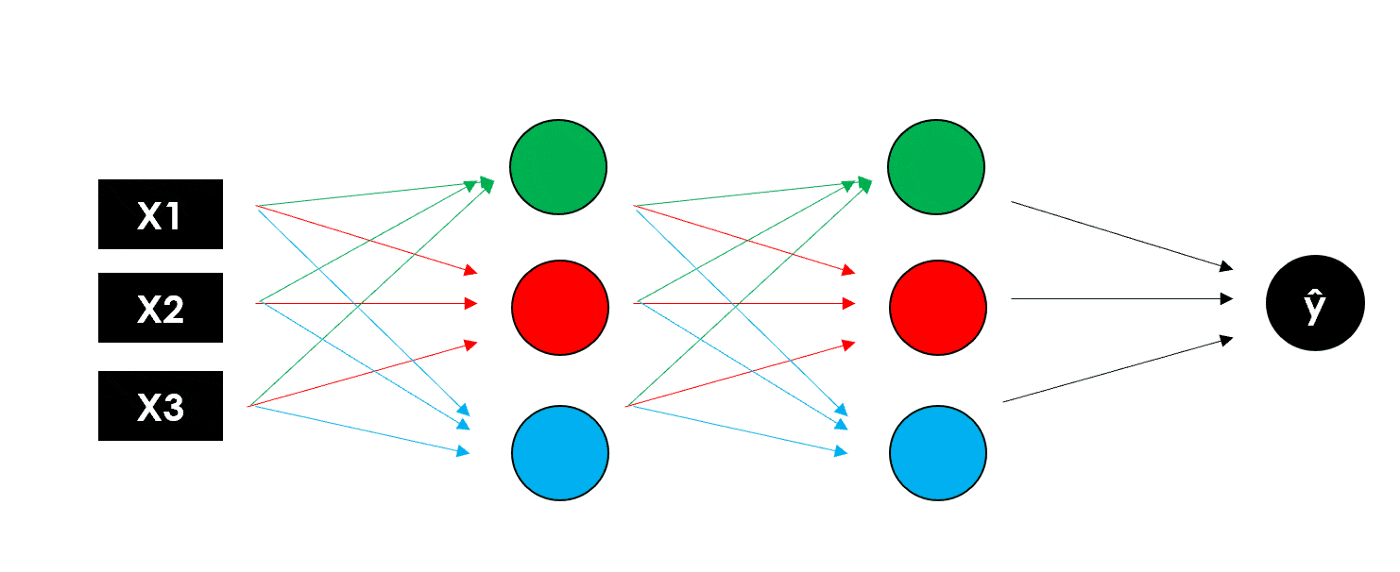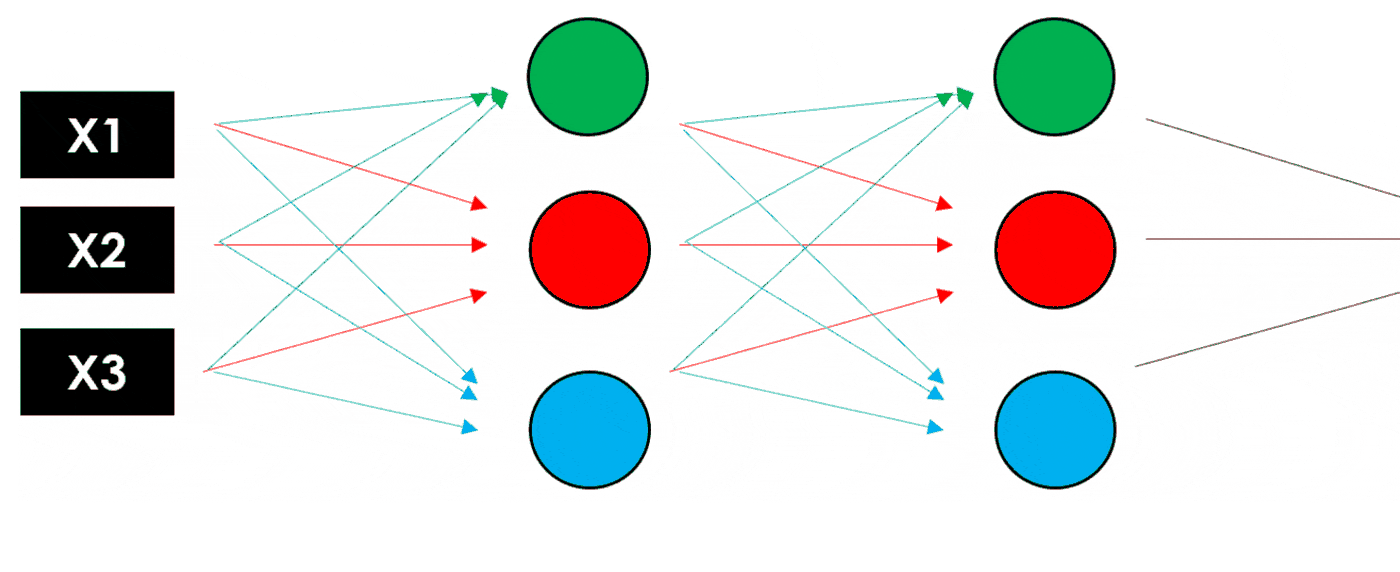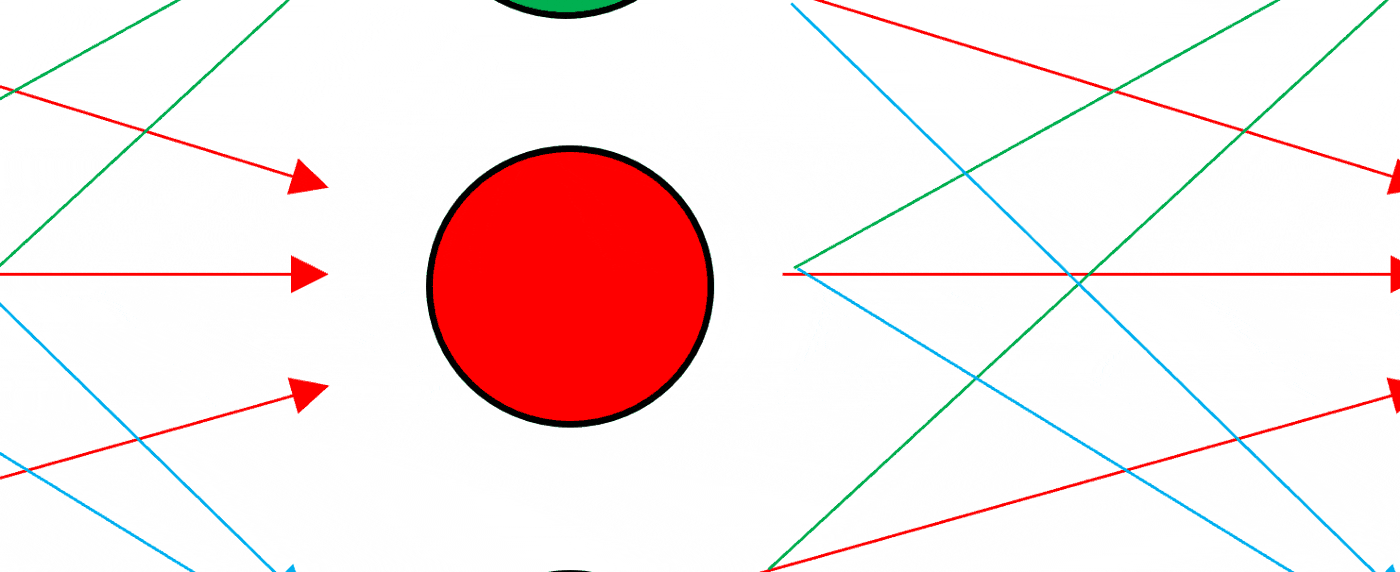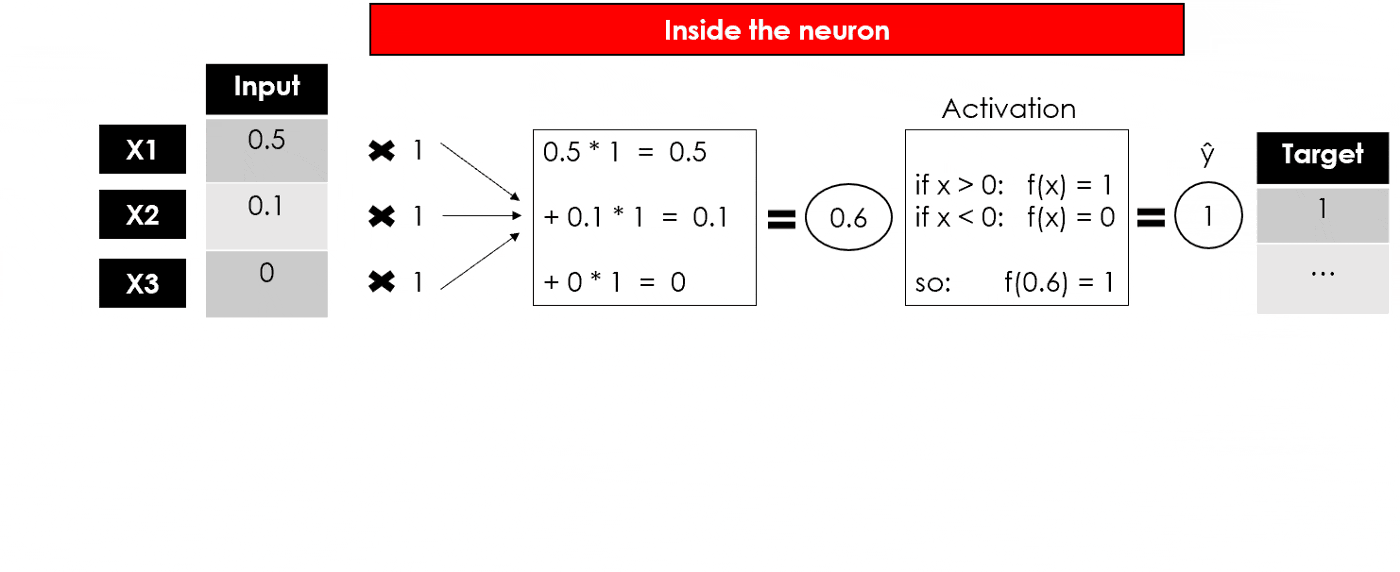
举个例子:假设我们有一个包含 N 行、3 个特征和 1 个目标变量(二分类,取值0或1)的数据集,如下图所示:

实际上,数据在输入神经网络之前应该进行幅度缩放,我们这里举例的输入数据直接用了0-1之间的值。类似其他机器学习模型,我们使用输入X去预测输出y:

而当我们提到『训练模型』时,我们指的是寻找最佳参数,使得模型预测的结果能最准确地预估目标值。
这里的最佳参数,在不同的情形下,有不同的解释:
- 在线性回归中,是找到最佳权重w
- 在基于树的模型(比如随机森林)中,它是找到最佳分裂点
- 如下的感知器中,我们希望找到最佳的W(w1,w2,w3)

我们有一些权重初始化方法,在这里我们采用最简单的随机初始化,然后随着学习的进行调整优化参数。如下图,我们将权重 w 全部初始化为 1:

接下来我们要进行一个简单的计算来对结果进行预估,下面的操作类似于单个神经网络的计算,f(WX+b),其中f函数叫做激活函数。

激活函数是非线性的映射函数,使得神经网络具备强大的非线性拟合学习能力,如下是一些激活函数示意图(当然,实际我们可能会更多地使用ReLU等激活函数)。
激活函数详细讲解可以参考ShowMeAI的文章 深度学习教程 | 浅层神经网络。
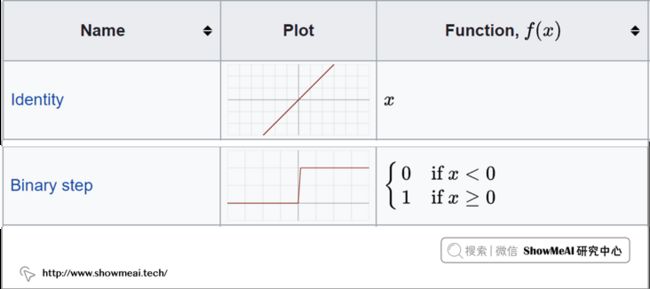
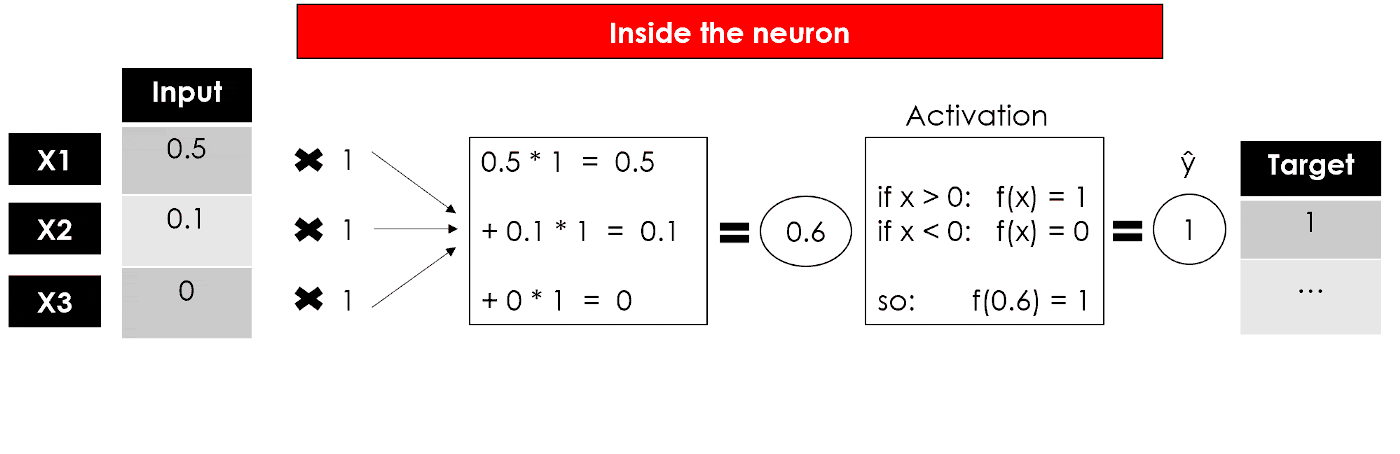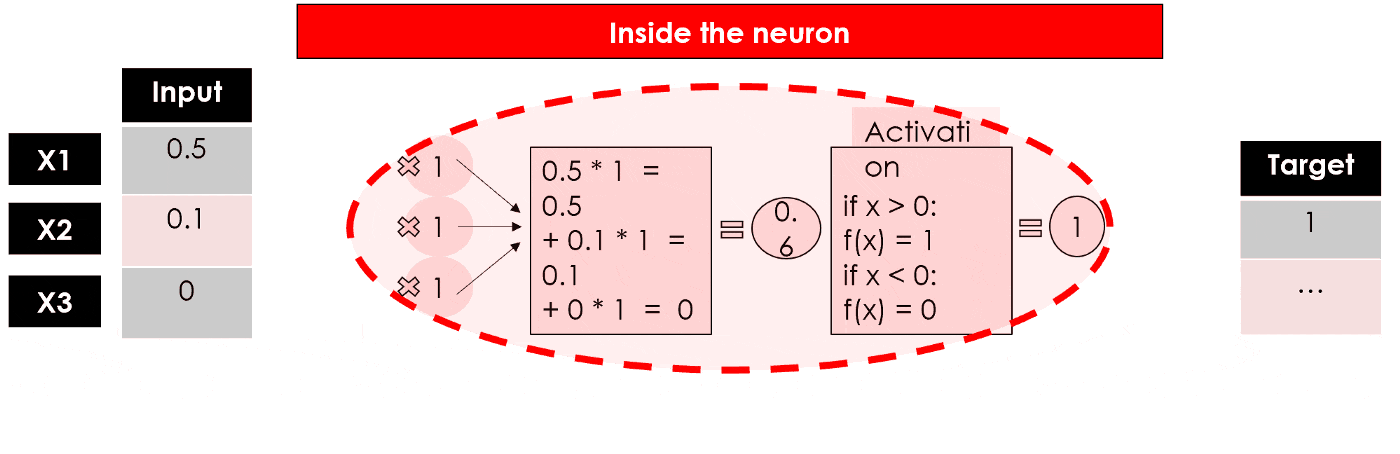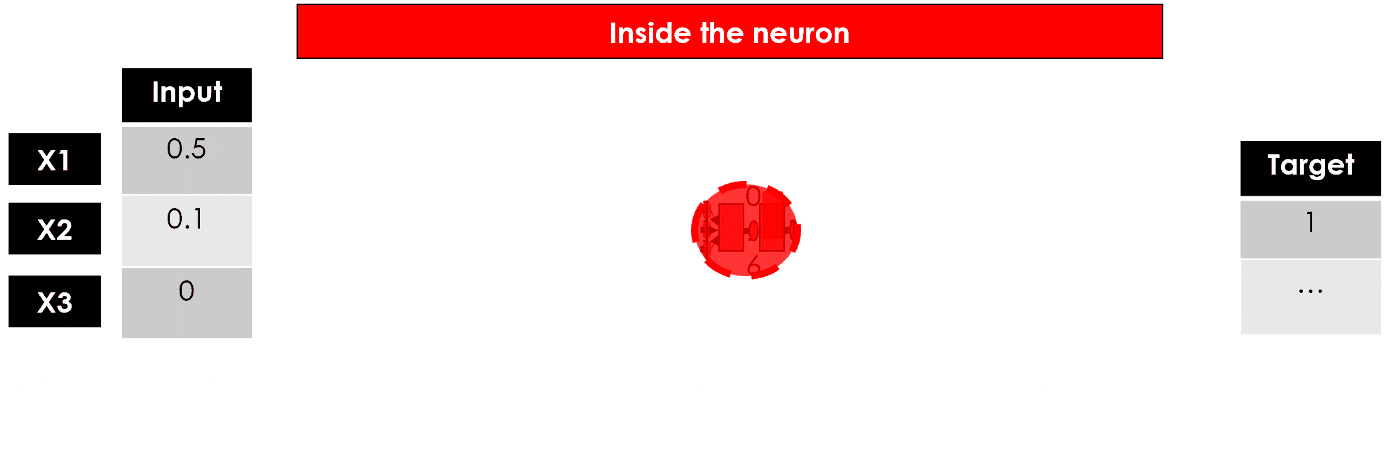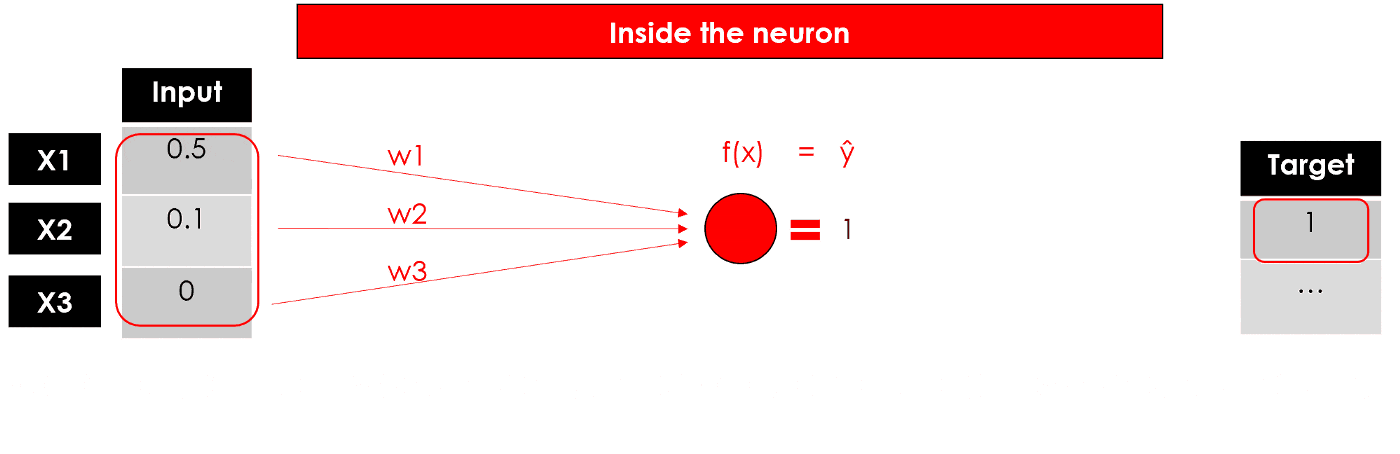
加入我们采用上面的阶跃激活函数,那简单的计算过程如下:
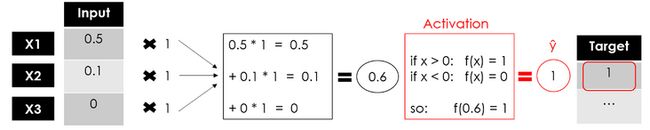
我们得到了感知器的输出,这是一个单层神经网络,它接受一些输入并返回 1 个输出。现在模型的训练将继续通过将输出与目标进行比较,计算误差并优化权重,一遍又一遍地重复整个过程。
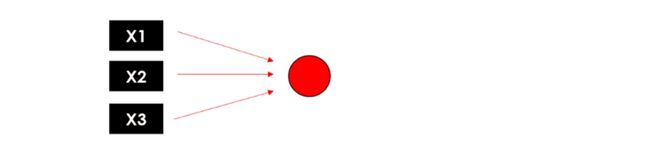
总结一下,这就是最简单的神经元,简化的结构表示如下:
深度神经网络
可以说所有深度学习模型都是神经网络,但并非所有神经网络都是深度学习模型。一般来说,『深度』学习适用于算法至少有 2 个隐藏层(因此总共 4 层,包括输入和输出)。
关于深度神经网络的详细知识,大家可以阅读学习ShowMeAI的文章 深度学习教程 | 深层神经网络。
想象一下在中间层添加3个和刚才一样的神经元:由于每个节点(加权和和激活函数)都返回一个值,我们将得到具有 3 个输出的 隐藏层。
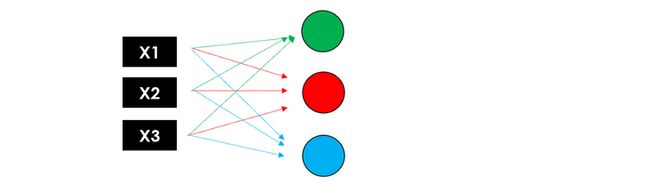
接下来我们使用这 3 个输出作为 第2个隐藏层 的输入,第2个隐藏层也同样计算得到 3 个结果值。最后,我们将添加一个 输出层 (仅 1 个节点),用它的结果作为我们模型的最终预测。如下图所示
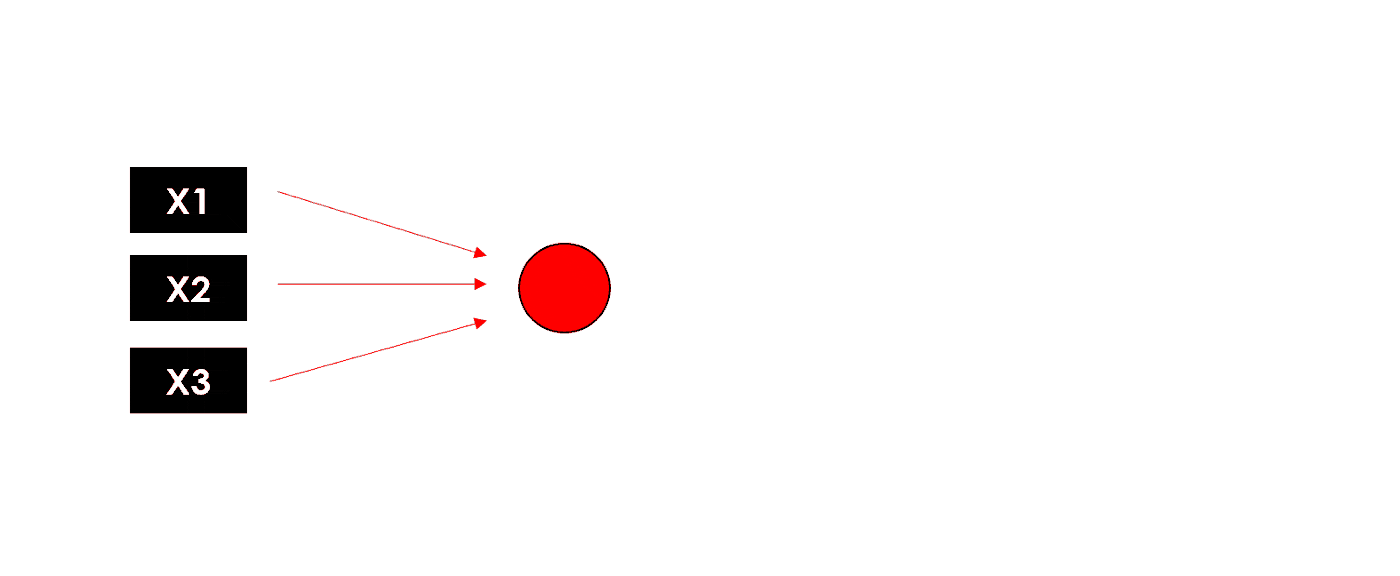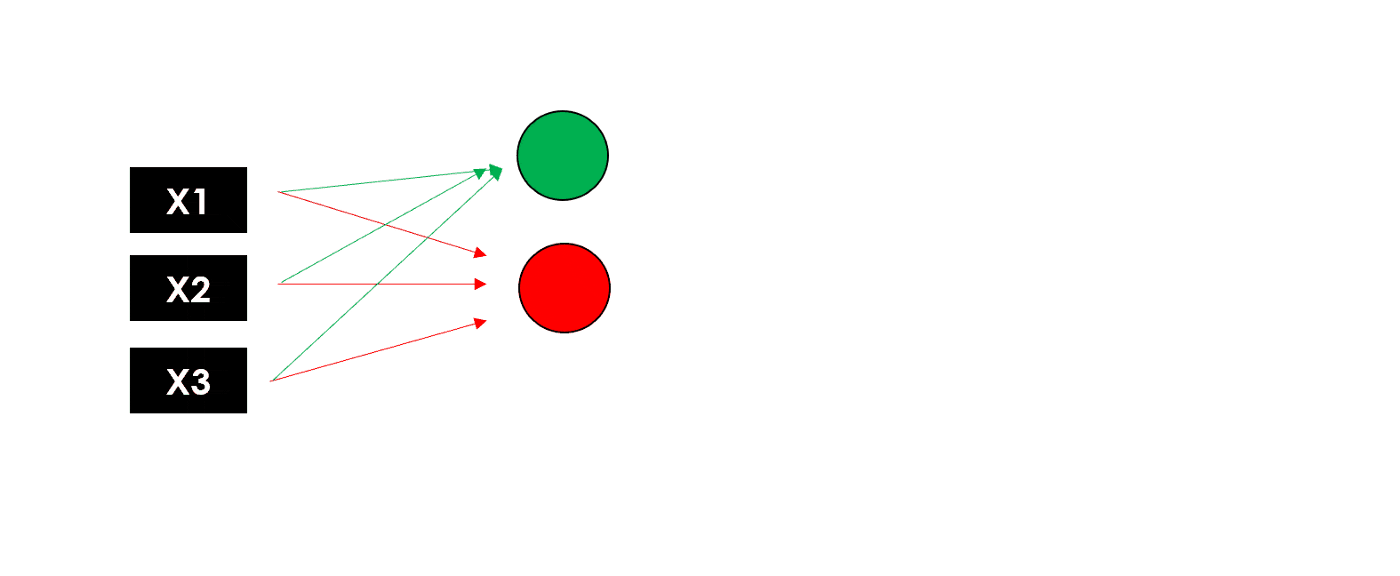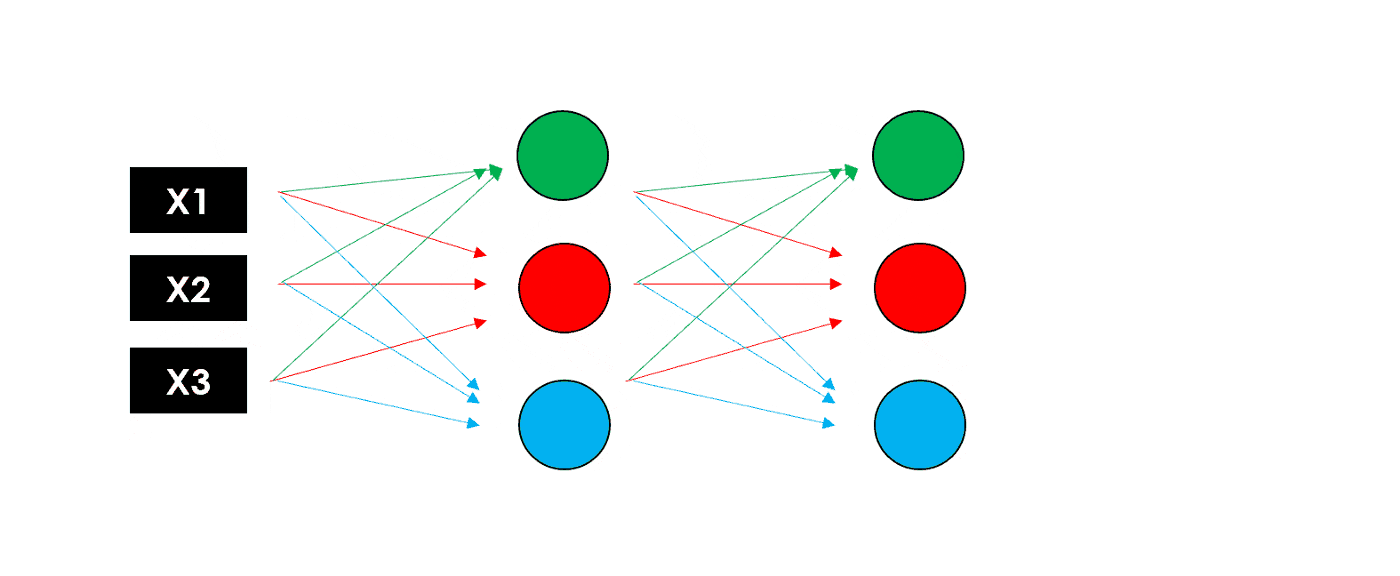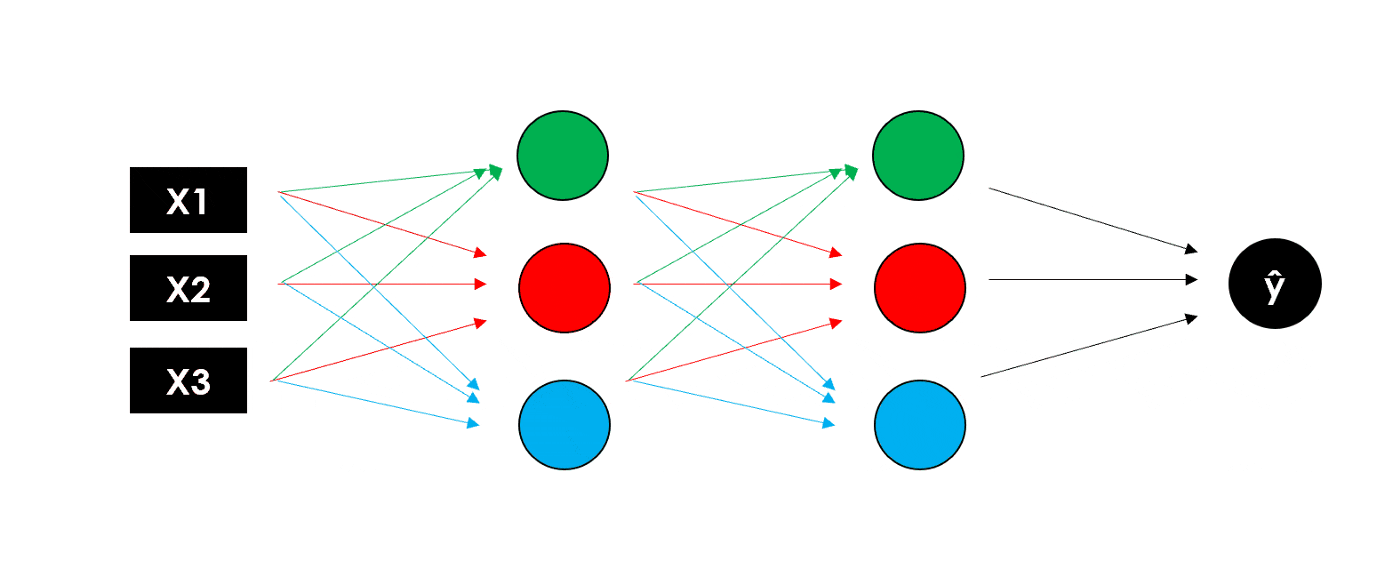
注意,这些中间层可以具有不同数量的神经元,使用不同的激活函数。每个神经元计算都会有对应的权重,因此添加的层数越多,可训练参数的数量就越大。
完整的神经网络全貌如下图所示:

我们刚才是以口语化的方式来叙述整个神经网络的结构和计算过程的,但实际有一些细节点,包括:
- 偏置项bias:在每个神经元内部,输入和权重的线性组合也包括一个偏差,类似于线性方程中的常数,因此神经元的完整公式是
来学习以最小化损失。
- 梯度下降:用于训练神经网络的优化算法,通过在最陡下降方向上重复步骤来找到损失函数的局部最小值。
模型搭建
我们使用 TensorFlow 的 high level API(也就是 tensorflow.keras)来快速搭建神经网络 。
ShowMeAI制作了快捷即查即用的 Tensorflow 工具速查表手册,大家可以在下述位置获得:
我们先搭建刚才提到的最简单的感知器结果,它是一个只有一个 Dense 层的模型。 Dense层是最基本的层结构,是一个全连接的结构。
model = models.Sequential(name="Perceptron",
layers=[
layers.Dense( # 全连接层
name="dense",
input_dim=3, # 输入维度为3
units=1, # 1个节点
activation='linear' # 激活函数(这里是线性函数)
)
])
model.summary()

model.summary操作可以输出网络的结构和参数等信息。当前情况下,我们只有 4 个(3 个权重和 1 个偏置项),所以它非常精简。
要说明一点的是,如果我们这里要使用阶跃函数作为激活函数,我们需要自己定义(目前Tensorflow中的激活函数不包含这个我们临时设置的函数)
import tensorflow as tf
# 定义激活函数
def binary_step_activation(x):
# 如果x>0返回1否则返回0
return K.switch(x>0, tf.math.divide(x,x), tf.math.multiply(x,0))
# 构建模型
model = models.Sequential(name="Perceptron", layers=[
layers.Dense(
name="dense",
input_dim=3,
units=1,
activation=binary_step_activation
)
])
如果我们从感知器转延展到深度神经网络,大家可能会冒出来一些问题,比如:
❓ 应该设置多少层?
- 这是一个没有标准答案的问题,隐层的加入对于模型的学习能力提升有帮助,可以拟合更复杂的非线性情况,但也可能会导致过拟合(当然我们可以通过 Dropout 等技术来缓解过拟合,关于 Dropout,大家可以阅读学习ShowMeAI的文章 深度学习教程 | 深度学习的实用层面。
- 一般来说,简单的问题我们会用很少的层数(不超过3个隐层),复杂的问题我们使用的层数更多
下图是层数和学习能力的一个示意图。
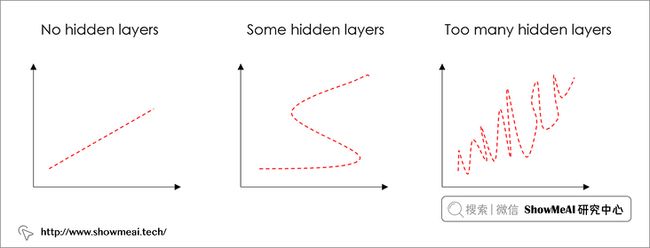
❓ 应该设定多少个神经元?
- 这个有不同的设置方法,一个常用的设置方式是 (输入维度 + 输出维度)/2 。
❓ 选用什么激活函数?
- 激活函数有很多选择,其中没有哪一个一定好于另外一个。最常用的是 ReLU ,一个分段线性函数,仅在输出为正时才返回。
- 注意,在输出层必须具有与任务输出兼容的激活。例如,linear函数适用于回归问题,而 Sigmoid/softmax 经常用于分类。

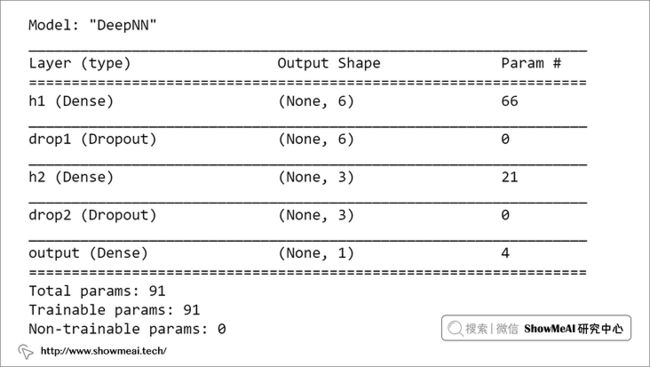
我们来解决一个二分类问题,它有 N 个输入特征和 1 个二进制目标变量。
n_features = 10
model = models.Sequential(name="DeepNN", layers=[
# 第1个隐层
layers.Dense(name="h1", input_dim=n_features,
units=int(round((n_features+1)/2)),
activation='relu'),
layers.Dropout(name="drop1", rate=0.2),
# 第2个隐层
layers.Dense(name="h2", units=int(round((n_features+1)/4)),
activation='relu'),
layers.Dropout(name="drop2", rate=0.2),
# 第3层
layers.Dense(name="output", units=1, activation='sigmoid')
])
model.summary()
除了这种汉堡包式地堆叠神经网络层次构建网络的 Sequential 方法。tensorflow.keras 还有函数式编程结构,它可用于构建具有多个输入/输出的更复杂的模型。函数式编程接口相对 Sequential 有两个主要区别:
- 需要指定输入层,而在 Sequential 类中它隐含在第一个 Dense 层的输入维度中。
- 每一层可以直接应用于其他层的输出,形如: output = layer(...)(input)
我们用函数式方式重写上面的网络,代码如下:
# 感知器
inputs = layers.Input(name="input", shape=(3,))
outputs = layers.Dense(name="output", units=1,
activation='linear')(inputs)
model = models.Model(inputs=inputs, outputs=outputs,
name="Perceptron")
# 深层神经网络
# 输入层
inputs = layers.Input(name="input", shape=(n_features,))
# 隐层1
h1 = layers.Dense(name="h1", units=int(round((n_features+1)/2)), activation='relu')(inputs)
h1 = layers.Dropout(name="drop1", rate=0.2)(h1)
# 隐层2
h2 = layers.Dense(name="h2", units=int(round((n_features+1)/4)), activation='relu')(h1)
h2 = layers.Dropout(name="drop2", rate=0.2)(h2)
# 输出层
outputs = layers.Dense(name="output", units=1, activation='sigmoid')(h2)
# 完整的模型
model = models.Model(inputs=inputs, outputs=outputs, name="DeepNN")
神经网络结构可视化
这个部分是工具部分,我们希望通过一段代码把多层的神经网络的大致结构绘制出来。当然,这里的结构只是一个简单的信息呈现,如果大家要深入理解神经网络的权重和激活函数等绘制,可以看ShowMeAI 后续的深入教程。
完整的代码如下:
'''
抽取tensorflow.keras模型中的每层信息
'''
def utils_nn_config(model):
lst_layers = []
if "Sequential" in str(model): #-> Sequential不显示输入层
layer = model.layers[0]
lst_layers.append({"name":"input", "in":int(layer.input.shape[-1]), "neurons":0,
"out":int(layer.input.shape[-1]), "activation":None,
"params":0, "bias":0})
for layer in model.layers:
try:
dic_layer = {"name":layer.name, "in":int(layer.input.shape[-1]), "neurons":layer.units,
"out":int(layer.output.shape[-1]), "activation":layer.get_config()["activation"],
"params":layer.get_weights()[0], "bias":layer.get_weights()[1]}
except:
dic_layer = {"name":layer.name, "in":int(layer.input.shape[-1]), "neurons":0,
"out":int(layer.output.shape[-1]), "activation":None,
"params":0, "bias":0}
lst_layers.append(dic_layer)
return lst_layers
'''
绘制神经网络的草图
'''
def visualize_nn(model, description=False, figsize=(10,8)):
# 获取层次信息
lst_layers = utils_nn_config(model)
layer_sizes = [layer["out"] for layer in lst_layers]
# 绘图设置
fig = plt.figure(figsize=figsize)
ax = fig.gca()
ax.set(title=model.name)
ax.axis('off')
left, right, bottom, top = 0.1, 0.9, 0.1, 0.9
x_space = (right-left) / float(len(layer_sizes)-1)
y_space = (top-bottom) / float(max(layer_sizes))
p = 0.025
# 中间节点
for i,n in enumerate(layer_sizes):
top_on_layer = y_space*(n-1)/2.0 + (top+bottom)/2.0
layer = lst_layers[i]
color = "green" if i in [0, len(layer_sizes)-1] else "blue"
color = "red" if (layer['neurons'] == 0) and (i > 0) else color
## 添加信息说明
if (description is True):
d = i if i == 0 else i-0.5
if layer['activation'] is None:
plt.text(x=left+d*x_space, y=top, fontsize=10, color=color, s=layer["name"].upper())
else:
plt.text(x=left+d*x_space, y=top, fontsize=10, color=color, s=layer["name"].upper())
plt.text(x=left+d*x_space, y=top-p, fontsize=10, color=color, s=layer['activation']+" (")
plt.text(x=left+d*x_space, y=top-2*p, fontsize=10, color=color, s="Σ"+str(layer['in'])+"[X*w]+b")
out = " Y" if i == len(layer_sizes)-1 else " out"
plt.text(x=left+d*x_space, y=top-3*p, fontsize=10, color=color, s=") = "+str(layer['neurons'])+out)
## 遍历
for m in range(n):
color = "limegreen" if color == "green" else color
circle = plt.Circle(xy=(left+i*x_space, top_on_layer-m*y_space-4*p), radius=y_space/4.0, color=color, ec='k', zorder=4)
ax.add_artist(circle)
## 添加文本说明
if i == 0:
plt.text(x=left-4*p, y=top_on_layer-m*y_space-4*p, fontsize=10, s=r'$X_{'+str(m+1)+'}$')
elif i == len(layer_sizes)-1:
plt.text(x=right+4*p, y=top_on_layer-m*y_space-4*p, fontsize=10, s=r'$y_{'+str(m+1)+'}$')
else:
plt.text(x=left+i*x_space+p, y=top_on_layer-m*y_space+(y_space/8.+0.01*y_space)-4*p, fontsize=10, s=r'$H_{'+str(m+1)+'}$')
# 添加链接箭头等
for i, (n_a, n_b) in enumerate(zip(layer_sizes[:-1], layer_sizes[1:])):
layer = lst_layers[i+1]
color = "green" if i == len(layer_sizes)-2 else "blue"
color = "red" if layer['neurons'] == 0 else color
layer_top_a = y_space*(n_a-1)/2. + (top+bottom)/2. -4*p
layer_top_b = y_space*(n_b-1)/2. + (top+bottom)/2. -4*p
for m in range(n_a):
for o in range(n_b):
line = plt.Line2D([i*x_space+left, (i+1)*x_space+left],
[layer_top_a-m*y_space, layer_top_b-o*y_space],
c=color, alpha=0.5)
if layer['activation'] is None:
if o == m:
ax.add_artist(line)
else:
ax.add_artist(line)
plt.show()
我们在之前的 2 个模型上尝试一下,首先是感知器:
visualize_nn(model, description=True, figsize=(10,8))

然后是深度神经网络:
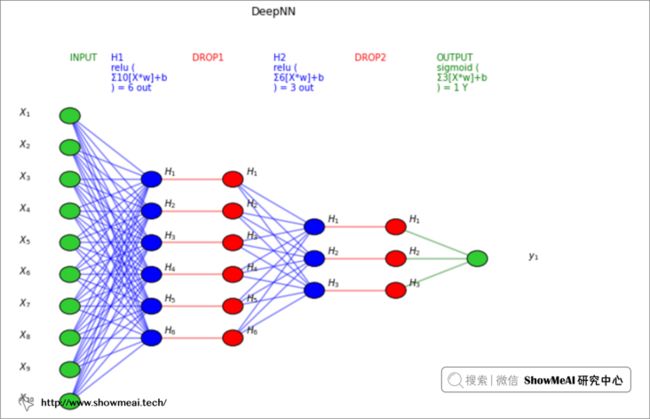
当然,TensorFlow 本身也提供了一个绘制模型结构的方法,它不是像上述示例图一样的简单形式呈现,而是输出更多的模型层次信息,下面是我们对深度模型调用 plot_model 的结果。
utils.plot_model(model, to_file='model.png', show_shapes=True, show_layer_names=True)
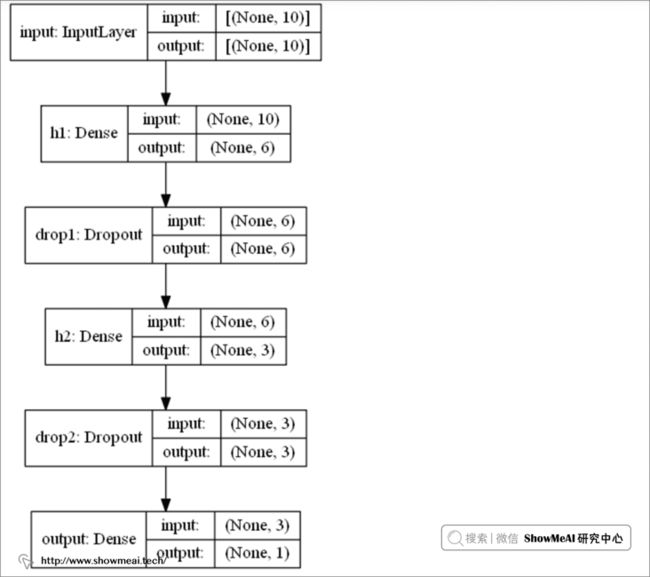
同时也会生成名为model.png的图片保存在你本地笔记本电脑上。
训练和测试评估
下一步是训练我们前面构建的深度学习模型。在 tensorflow.keras 中,我们需要先对模型『编译』,或者换句话说,我们需要定义训练过程中的一些细节,比如优化器Optimizer、损失函数Loss和评估准则Metrics。其中:
详细的编译代码如下:
# 定义评估准则
def Recall(y_true, y_pred):
true_positives = K.sum(K.round(K.clip(y_true * y_pred, 0, 1)))
possible_positives = K.sum(K.round(K.clip(y_true, 0, 1)))
recall = true_positives / (possible_positives + K.epsilon())
return recall
def Precision(y_true, y_pred):
true_positives = K.sum(K.round(K.clip(y_true * y_pred, 0, 1)))
predicted_positives = K.sum(K.round(K.clip(y_pred, 0, 1)))
precision = true_positives / (predicted_positives + K.epsilon())
return precision
def F1(y_true, y_pred):
precision = Precision(y_true, y_pred)
recall = Recall(y_true, y_pred)
return 2*((precision*recall)/(precision+recall+K.epsilon()))
# 编译神经网络
model.compile(optimizer='adam', loss='binary_crossentropy',
metrics=['accuracy',F1])
我们当前是分类问题,如果是回归问题,我们可以选用 MAE 为损失,将 R方 作为度量。参考代码如下:
# 定义R方评估准则
def R2(y, y_hat):
ss_res = K.sum(K.square(y - y_hat))
ss_tot = K.sum(K.square(y - K.mean(y)))
return ( 1 - ss_res/(ss_tot + K.epsilon()) )
# 编译神经网络
model.compile(optimizer='adam', loss='mean_absolute_error',
metrics=[R2])
神经网络的训练,大部分时候,不是一次性把数据都送入模型学习的(因为数据量非常大,通常GPU不足以容纳这种规模的数据,同时全量数据也容易陷入局部最低点)
关于评估准则,大家可以阅读ShowMeAI的文章 深度学习教程 | 神经网络优化算法
我们通常会采用一个批次一个批次数据训练的方式,因此在开始训练之前,我们还需要确定 Epochs 和 Batches:其中Epochs代表全量数据迭代的次数,Batches代表单个批次数据样本的数量。
总的数据会拆分为若干批次(每个batch的样本数量越大,您需要的内存空间越多),反向传播和参数更在每批数据上都会进行。一个Epoch是对整个训练集的一次遍历。
如果我们手头有 100 个样本且batch大小为 20,则需要 5 个batch才能完成 1 个 epoch。batch大小尽量选择为2的倍数(常见:32、64、128、256),因为计算机通常以 2 的幂来组织内存。
在训练过程中,理想的状态是随着一轮一轮的数据迭代,评估指标在不断改进,损失在逐步减少。不过这个结果只表明在训练集数据上我们在学习,但在新数据上是否有同样的效果并不好确定。因此我们会保留一部分数据(20%左右)用于验证评估。
我们用代码来做说明,我们在这里简单地生成随机数据构建特征数据X和标签数据y,例如
import numpy as np
X = np.random.rand(1000,10)
y = np.random.choice([1,0], size=1000)
那我们可以基于下述方式对数据进行训练和评估
# 训练和评估
training = model.fit(x=X, y=y, batch_size=32, epochs=100, shuffle=True, verbose=0, validation_split=0.2)
# 绘制评估指标
metrics = [k for k in training.history.keys() if ("loss" not in k) and ("val" not in k)]
fig, ax = plt.subplots(nrows=1, ncols=2, sharey=True, figsize=(15,3))
# 训练阶段
ax[0].set(title="Training")
ax11 = ax[0].twinx()
ax[0].plot(training.history['loss'], color='black') ax[0].set_xlabel('Epochs')
ax[0].set_ylabel('Loss', color='black')
for metric in metrics:
ax11.plot(training.history[metric], label=metric) ax11.set_ylabel("Score", color='steelblue')
ax11.legend()
# 验证集评估阶段
ax[1].set(title="Validation")
ax22 = ax[1].twinx()
ax[1].plot(training.history['val_loss'], color='black') ax[1].set_xlabel('Epochs')
ax[1].set_ylabel('Loss', color='black')
for metric in metrics:
ax22.plot(training.history['val_'+metric], label=metric) ax22.set_ylabel("Score", color="steelblue")
plt.show()
得到的结果图如下所示(下2幅图分别为分类和回归场景下的训练集与验证集的loss和评估准则指标):

模型可解释性
实际生产过程中,神经网络效果可能很好,但我们实际是不太方向直接把它当做一个黑盒来用的,我们希望对模型做一些可解释性分析,能部分地理解我们的模型。
我们在这里会用到一个模型可解释性工具 Shap ,用它和神经网络搭配对模型做一些解释。
具体说来,对于每个样本的预测,我们结合shap都能够估计每个特征对模型预测结果的贡献,进而部分解释问模型的问题『为什么预测这是 1 而不是 0?』(二分类场景)。
参考代码如下:
'''
使用shap构建解释器
:parameter
:param model: model instance (after fitting)
:param X_names: list
:param X_instance: array of size n x 1 (n,)
:param X_train: array - if None the model is simple machine learning, if not None then it's a deep learning model
:param task: string - "classification", "regression"
:param top: num - top features to display
:return
dtf with explanations
'''
def explainer_shap(model, X_names, X_instance, X_train=None, task="classification", top=10):
# 构建解释器
# 机器学习(树模型)
if X_train is None:
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X_instance)
# 深度学习(神经网络)
else:
explainer = shap.DeepExplainer(model, data=X_train[:100])
shap_values = explainer.shap_values(X_instance.reshape(1,-1))[0].reshape(-1)
# 绘图
# 分类场景
if task == "classification":
shap.decision_plot(explainer.expected_value, shap_values, link='logit', feature_order='importance',
features=X_instance, feature_names=X_names, feature_display_range=slice(-1,-top-1,-1))
# 回归场景
else:
shap.waterfall_plot(explainer.expected_value[0], shap_values,
features=X_instance, feature_names=X_names, max_display=top)
shap实际上是一个很有效的工具,大家在上述代码也可以看到,实际它可以应用在机器学习模型(如线性回归、随机森林)上,也可以应用在神经网络上。从代码中可以看出,如果 X_train 参数为 None,会选择机器学习模型进行解释,否则使用深度学习进行解释分析。
我们在Titanic分类问题和房价预估回归问题上进行测试:(对应的这两个案例大家可以在ShowMeAI后续的文章中找到)
i = 1explainer_shap(model,
X_names=list_feature_names,
X_instance=X[i],
X_train=X,
task="classification", # 分类任务
top=10)
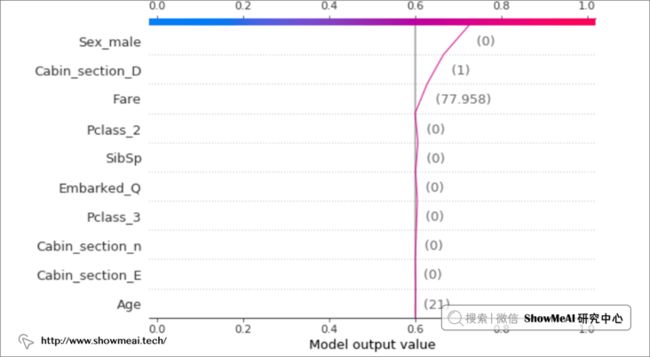
上图中,Titanic问题中,预测为『Survived』主要因素是变量 Sex_male = 0,即乘客是女性。
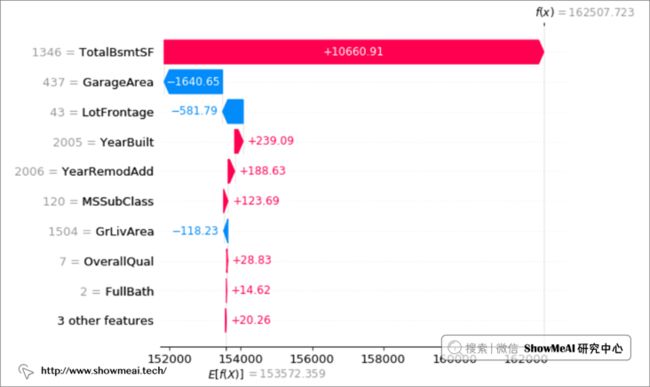
上图中,在房价预估的回归问题中,影响最大的因素是房屋的面积。
参考资料

������������������������������������������������������������������������������������������������������������������������������������