pytorch、tensorflow对比学习—功能组件(激活函数、模型层、损失函数)
功能组件(激活函数、模型层、损失函数)
前言
本文是《pytorch-tensorflow-Comparative study》,pytorch和tensorflow对比学习专栏,第三章——功能组件。(其中的激活函数、模型层、损失函数部分)
虽然说这两个框架在语法和接口的命名上有很多地方是不同的,但是深度学习的建模过程确实基本上都是一个套路的。
所以该笔记的笔记方式是:在使用相同的处理功能模块上,对比记录pytorch和tensorflow两者的API接口,和语法。

1,有利于深入理解深度学习建模过程流程。
2,有利于理解pytorch,和tensorflow设计上的不同,更加灵活的使用在自己的项目中。
3,有利于深入理解各个功能模块的使用。
本章节主要对比学习pytorch 和tensorflow有关功能组件。(其中的激活函数、模型层、损失函数部分)

前面我们介绍了Pytorch的张量的结构操作和数学运算中的一些常用API。
利用这些张量的API我们可以构建出神经网络相关的组件(如激活函数,模型层,损失函数,优化器)。
Pytorch中:和神经网络相关的功能组件大多都封装在 torch.nn模块下。这些功能组件的绝大部分既有函数形式实现,也有类形式实现。
1,nn.functional(一般引入后改名为F)有各种功能组件的函数实现。
2,便于对参数进行管理,通过继承 nn.Module 转换成为类的实现形式,并直接封装在 nn 模块下。(建议)
tensorflow中:和神经网络相关的功能组件大多通过继承tf.keras子模块实现。所以tensorflow实现的功能组件大多数是类的形式实现的。

激活函数
激活函数在深度学习中扮演着非常重要的角色,它给网络赋予了非线性,从而使得神经网络能够拟合任意复杂的函数。
如果没有激活函数,无论多复杂的网络,都等价于单一的线性变换,无法对非线性函数进行拟合。
目前,深度学习中最流行的激活函数为 relu, 但也有些新推出的激活函数,例如 swish、GELU 据称效果优于relu激活函数。

常用激活函数
**sigmoid:**将实数压缩到0到1之间,一般只在二分类的最后输出层使用。主要缺陷为存在梯度消失问题,计算复杂度高,输出不以0为中心。

softmax:sigmoid的多分类扩展,一般只在多分类问题的最后输出层使用。

**tanh:**将实数压缩到-1到1之间,输出期望为0。主要缺陷为存在梯度消失问题,计算复杂度高。

**relu:**修正线性单元,最流行的激活函数。一般隐藏层使用。主要缺陷是:输出不以0为中心,输入小于0时存在梯度消失问题(死亡relu)。

**leaky_relu:**对修正线性单元的改进,解决了死亡relu问题。

**elu:**指数线性单元。对relu的改进,能够缓解死亡relu问题。

**selu:**扩展型指数线性单元。在权重用tf.keras.initializers.lecun_normal初始化前提下能够对神经网络进行自归一化。不可能出现梯度爆炸或者梯度消失问题。需要和Dropout的变种AlphaDropout一起使用。

**swish:**自门控激活函数。谷歌出品,相关研究指出用swish替代relu将获得轻微效果提升。
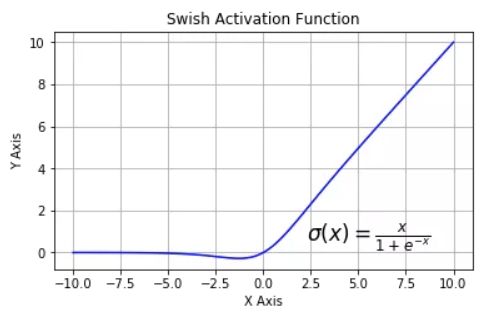
**gelu:**高斯误差线性单元激活函数。在Transformer中表现最好。tf.nn模块尚没有实现该函数。

激活函数实现

pytorch
激活函数的使用方法有两种,分别是:
import torch.nn.functional as F
"""
F.relu
F.sigmoid
F.tanh
F.softmax
"""
out = F.relu(input)
import torch.nn as nn
"""
nn.ReLU
nn.Sigmoid
nn.Tanh
nn.Softmax
"""
nn.ReLU()
其实这两种方法都是使用relu激活,只是使用的场景不一样,F.relu()是函数调用,一般使用在foreward函数里。而nn.ReLU()是模块调用,一般在定义网络层的时候使用。(nn.ReLU(),通过继承 nn.Module 转换成为类的实现形式,并直接封装在 nn 模块下。)
当用print(net)输出时,会有nn.ReLU()层,而F.ReLU()是没有输出的。
import torch.nn as nn
import torch.nn.functional as F
class NET1(nn.Module):
def __init__(self):
super(NET1, self).__init__()
self.conv = nn.Conv2d(3, 16, 3, 1, 1)
self.bn = nn.BatchNorm2d(16)
self.relu = nn.ReLU() # 模块的激活函数
def forward(self, x):
out = self.conv(x)
x = self.bn(x)
out = self.relu()
return out
class NET2(nn.Module):
def __init__(self):
super(NET2, self).__init__()
self.conv = nn.Conv2d(3, 16, 3, 1, 1)
self.bn = nn.BatchNorm2d(16)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
out = F.relu(x) # 函数的激活函数
return out
net1 = NET1()
net2 = NET2()
print(net1)
print(net2)
tensorflow
在keras模型中使用激活函数一般有两种方式,一种是作为某些层的activation参数指定,另一种是显式添加layers.Activation激活层。
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow.keras import layers,models
tf.keras.backend.clear_session()
model = models.Sequential()
model.add(layers.Dense(32,input_shape = (None,16),activation = tf.nn.relu)) #通过activation参数指定
model.add(layers.Dense(10))
"""
tf.nn.sigmoid
tf.nn.softmax
tf.nn.tanh
tf.nn.relu
tf.nn.leaky_relu
tf.nn.elu
tf.nn.selu
tf.nn.swish
gelu
"""
model.add(layers.Activation(tf.nn.softmax)) # 显式添加layers.Activation激活层
model.summary()
模型层layers
深度学习模型一般由各种模型层组合而成。
**pytroch中:**torch.nn中内置了非常丰富的各种模型层。它们都属于nn.Module的子类,具备参数管理功能。
例如:
- nn.Linear, nn.Flatten, nn.Dropout, nn.BatchNorm2d
- nn.Conv2d,nn.AvgPool2d,nn.Conv1d,nn.ConvTranspose2d
- nn.Embedding,nn.GRU,nn.LSTM
- nn.Transformer
如果这些内置模型层不能够满足需求,我们也可以通过继承nn.Module基类构建自定义的模型层。
实际上,pytorch不区分模型和模型层,都是通过继承nn.Module进行构建。
因此,我们只要继承nn.Module基类并实现forward方法即可自定义模型层。
**tensorflow中:**tf.keras.layers内置了非常丰富的各种功能的模型层。例如,
layers.Dense,layers.Flatten,layers.Input,layers.DenseFeature,layers.Dropout
layers.Conv2D,layers.MaxPooling2D,layers.Conv1D
layers.Embedding,layers.GRU,layers.LSTM,layers.Bidirectional等等。
如果这些内置模型层不能够满足需求,我们也可以通过编写tf.keras.Lambda匿名模型层或继承tf.keras.layers.Layer基类构建自定义的模型层。
其中tf.keras.Lambda匿名模型层只适用于构造没有学习参数的模型层。

内置模型层
一些常用的内置模型层简单介绍如下。
基础层
| 名称 | pytorch | tensorflow |
|---|---|---|
| 输入层 | Input | |
| 全连接层/密集连接层 | nn.Linear | Dense |
| 特征列接入层 | DenseFeature | |
| 压平层 | nn.Flatten | Flatten |
| 随机置零层 | nn.Dropout | Dropout |
| nn.Dropout2d | SpatialDropout2D | |
| nn.Dropout3d | ||
| 批标准化层 | nn.BatchNorm1d | BatchNormalization |
| nn.BatchNorm2d | ||
| nn.BatchNorm3d | ||
| 限幅层 | nn.Threshold | |
| 常数填充层 | nn.ConstantPad2d | |
| 复制填充层 | nn.ReplicationPad1d | |
| 零值填充层 | nn.ZeroPad2d | |
| 加法层 | Add | |
| 减法层 | Subtract | |
| 取最大值层 | Maximum | |
| 取最小值层 | Minimum | |
| 形状重塑层 | Reshape | |
| 拼接层 | Concatenate | |
| 组归一化 | nn.GroupNorm | |
| 层归一化 | nn.LayerNorm | |
| 样本归一化 | nn.InstanceNorm2d |
相关名词解释:
pytorch
- nn.Linear:全连接层。参数个数 = 输入层特征数× 输出层特征数(weight)+ 输出层特征数(bias)
- nn.Flatten:压平层,用于将多维张量样本压成一维张量样本。
- nn.BatchNorm1d:一维批标准化层。通过线性变换将输入批次缩放平移到稳定的均值和标准差。可以增强模型对输入不同分布的适应性,加快模型训练速度,有轻微正则化效果。一般在激活函数之前使用。可以用afine参数设置该层是否含有可以训练的参数。
- nn.BatchNorm2d:二维批标准化层。
- nn.BatchNorm3d:三维批标准化层。
- nn.Dropout:一维随机丢弃层。一种正则化手段。
- nn.Dropout2d:二维随机丢弃层。
- nn.Dropout3d:三维随机丢弃层。
- nn.Threshold:限幅层。当输入大于或小于阈值范围时,截断之。
- nn.ConstantPad2d: 二维常数填充层。对二维张量样本填充常数扩展长度。
- nn.ReplicationPad1d: 一维复制填充层。对一维张量样本通过复制边缘值填充扩展长度。
- nn.ZeroPad2d:二维零值填充层。对二维张量样本在边缘填充0值.
- nn.GroupNorm:组归一化。一种替代批归一化的方法,将通道分成若干组进行归一。不受batch大小限制,据称性能和效果都优于BatchNorm。
- nn.LayerNorm:层归一化。较少使用。
- nn.InstanceNorm2d: 样本归一化。较少使用。
tensorflow
- Dense:密集连接层。参数个数 = 输入层特征数× 输出层特征数(weight)+ 输出层特征数(bias)
- Activation:激活函数层。一般放在Dense层后面,等价于在Dense层中指定activation。
- Dropout:随机置零层。训练期间以一定几率将输入置0,一种正则化手段。
- BatchNormalization:批标准化层。通过线性变换将输入批次缩放平移到稳定的均值和标准差。可以增强模型对输入不同分布的适应性,加快模型训练速度,有轻微正则化效果。一般在激活函数之前使用。
- SpatialDropout2D:空间随机置零层。训练期间以一定几率将整个特征图置0,一种正则化手段,有利于避免特征图之间过高的相关性。
- Input:输入层。通常使用Functional API方式构建模型时作为第一层。
- DenseFeature:特征列接入层,用于接收一个特征列列表并产生一个密集连接层。
- Flatten:压平层,用于将多维张量压成一维。
- Reshape:形状重塑层,改变输入张量的形状。
- Concatenate:拼接层,将多个张量在某个维度上拼接。
- Add:加法层。
- Subtract: 减法层。
- Maximum:取最大值层。
- Minimum:取最小值层。
卷积网络相关层
| 名称 | pytorch | tensorflow |
|---|---|---|
| 普通一维卷积 | nn.Conv1d | Conv1D |
| 普通二维卷积 | nn.Conv2d | Conv2D |
| 普通三维卷积 | nn.Conv3d | Conv3D |
| 二维深度可分离卷积层 | SeparableConv2D | |
| 二维深度卷积层 | DepthwiseConv2D | |
| 二维卷积转置层 | nn.ConvTranspose2d | Conv2DTranspose |
| 二维局部连接层 | LocallyConnected2D | |
| 一维最大池化 | nn.MaxPool1d | MaxPool1D |
| 二维最大池化 | nn.MaxPool2d | MaxPool2D |
| 三维最大池化 | nn.MaxPool3d | MaxPool3D |
| 二维平均池化层 | nn.AvgPool2d | AveragePooling2D |
| 二维自适应最大池化 | nn.AdaptiveMaxPool2d | |
| 二维分数最大池化 | nn.FractionalMaxPool2d | |
| 全局最大池化层 | GlobalMaxPool2D | |
| 全局平均池化层 | GlobalAvgPool2D | |
| 二维自适应平均池化 | nn.AdaptiveAvgPool2d | |
| 上采样层 | nn.Upsample | |
| 滑动窗口提取层 | nn.Unfold | |
| 逆滑动窗口提取层 | nn.Fold | |
相关名词解释:
pytorch
- nn.Conv1d:普通一维卷积,常用于文本。参数个数 = 输入通道数×卷积核尺寸(如3)×卷积核个数 + 卷积核尺寸(如3)
- nn.Conv2d:普通二维卷积,常用于图像。参数个数 = 输入通道数×卷积核尺寸(如3乘3)×卷积核个数 + 卷积核尺寸(如3乘3) 通过调整dilation参数大于1,可以变成空洞卷积,增大卷积核感受野。 通过调整groups参数不为1,可以变成分组卷积。分组卷积中不同分组使用相同的卷积核,显著减少参数数量。 当groups参数等于通道数时,相当于tensorflow中的二维深度卷积层tf.keras.layers.DepthwiseConv2D。 利用分组卷积和1乘1卷积的组合操作,可以构造相当于Keras中的二维深度可分离卷积层tf.keras.layers.SeparableConv2D。
- nn.Conv3d:普通三维卷积,常用于视频。参数个数 = 输入通道数×卷积核尺寸(如3乘3乘3)×卷积核个数 + 卷积核尺寸(如3乘3乘3) 。
- nn.MaxPool1d: 一维最大池化。
- nn.MaxPool2d:二维最大池化。一种下采样方式。没有需要训练的参数。
- nn.MaxPool3d:三维最大池化。
- nn.AdaptiveMaxPool2d:二维自适应最大池化。无论输入图像的尺寸如何变化,输出的图像尺寸是固定的。 该函数的实现原理,大概是通过输入图像的尺寸和要得到的输出图像的尺寸来反向推算池化算子的padding,stride等参数。
- nn.FractionalMaxPool2d:二维分数最大池化。普通最大池化通常输入尺寸是输出的整数倍。而分数最大池化则可以不必是整数。分数最大池化使用了一些随机采样策略,有一定的正则效果,可以用它来代替普通最大池化和Dropout层。
- nn.AvgPool2d:二维平均池化。
- nn.AdaptiveAvgPool2d:二维自适应平均池化。无论输入的维度如何变化,输出的维度是固定的。
- nn.ConvTranspose2d:二维卷积转置层,俗称反卷积层。并非卷积的逆操作,但在卷积核相同的情况下,当其输入尺寸是卷积操作输出尺寸的情况下,卷积转置的输出尺寸恰好是卷积操作的输入尺寸。在语义分割中可用于上采样。
- nn.Upsample:上采样层,操作效果和池化相反。可以通过mode参数控制上采样策略为"nearest"最邻近策略或"linear"线性插值策略。
- nn.Unfold:滑动窗口提取层。其参数和卷积操作nn.Conv2d相同。实际上,卷积操作可以等价于nn.Unfold和nn.Linear以及nn.Fold的一个组合。 其中nn.Unfold操作可以从输入中提取各个滑动窗口的数值矩阵,并将其压平成一维。利用nn.Linear将nn.Unfold的输出和卷积核做乘法后,再使用 nn.Fold操作将结果转换成输出图片形状。
- nn.Fold:逆滑动窗口提取层。
tensorflow
- Conv1D:普通一维卷积,常用于文本。参数个数 = 输入通道数×卷积核尺寸(如3)×卷积核个数
- Conv2D:普通二维卷积,常用于图像。参数个数 = 输入通道数×卷积核尺寸(如3乘3)×卷积核个数
- Conv3D:普通三维卷积,常用于视频。参数个数 = 输入通道数×卷积核尺寸(如3乘3乘3)×卷积核个数
- SeparableConv2D:二维深度可分离卷积层。不同于普通卷积同时对区域和通道操作,深度可分离卷积先操作区域,再操作通道。即先对每个通道做独立卷积操作区域,再用1乘1卷积跨通道组合操作通道。参数个数 = 输入通道数×卷积核尺寸 + 输入通道数×1×1×输出通道数。深度可分离卷积的参数数量一般远小于普通卷积,效果一般也更好。
- DepthwiseConv2D:二维深度卷积层。仅有SeparableConv2D前半部分操作,即只操作区域,不操作通道,一般输出通道数和输入通道数相同,但也可以通过设置depth_multiplier让输出通道为输入通道的若干倍数。输出通道数 = 输入通道数 × depth_multiplier。参数个数 = 输入通道数×卷积核尺寸× depth_multiplier。
- Conv2DTranspose:二维卷积转置层,俗称反卷积层。并非卷积的逆操作,但在卷积核相同的情况下,当其输入尺寸是卷积操作输出尺寸的情况下,卷积转置的输出尺寸恰好是卷积操作的输入尺寸。
- LocallyConnected2D: 二维局部连接层。类似Conv2D,唯一的差别是没有空间上的权值共享,所以其参数个数远高于二维卷积。
- MaxPool2D: 二维最大池化层。也称作下采样层。池化层无可训练参数,主要作用是降维。
- AveragePooling2D: 二维平均池化层。
- GlobalMaxPool2D: 全局最大池化层。每个通道仅保留一个值。一般从卷积层过渡到全连接层时使用,是Flatten的替代方案。
- GlobalAvgPool2D: 全局平均池化层。每个通道仅保留一个值。
循环网络相关层
| 名称 | pytroch | tensorflow |
|---|---|---|
| 嵌入层 | nn.Embedding | Embedding |
| 长短记忆循环网络层 | nn.LSTM | LSTM |
| 门控循环网络层 | nn.GRU | GRU |
| 简单循环网络层 | nn.RNN | SimpleRNN |
| 卷积长短记忆循环网络层 | ConvLSTM2D | |
| 双向循环网络包装器 | Bidirectional | |
| RNN基本层 | RNN | |
| 长短记忆循环网络单元 | nn.LSTMCell | LSTMCell |
| 门控循环网络单元 | nn.GRUCell | GRUCell |
| 简单循环网络单元 | nn.RNNCell | SimpleRNNCell |
| 抽象RNN单元 | AbstractRNNCell |
相关名词解释:
pytorch
- nn.Embedding:嵌入层。一种比Onehot更加有效的对离散特征进行编码的方法。一般用于将输入中的单词映射为稠密向量。嵌入层的参数需要学习。
- nn.LSTM:长短记忆循环网络层【支持多层】。最普遍使用的循环网络层。具有携带轨道,遗忘门,更新门,输出门。可以较为有效地缓解梯度消失问题,从而能够适用长期依赖问题。设置bidirectional = True时可以得到双向LSTM。需要注意的时,默认的输入和输出形状是(seq,batch,feature), 如果需要将batch维度放在第0维,则要设置batch_first参数设置为True。
- nn.GRU:门控循环网络层【支持多层】。LSTM的低配版,不具有携带轨道,参数数量少于LSTM,训练速度更快。
- nn.RNN:简单循环网络层【支持多层】。容易存在梯度消失,不能够适用长期依赖问题。一般较少使用。
- nn.LSTMCell:长短记忆循环网络单元。和nn.LSTM在整个序列上迭代相比,它仅在序列上迭代一步。一般较少使用。
- nn.GRUCell:门控循环网络单元。和nn.GRU在整个序列上迭代相比,它仅在序列上迭代一步。一般较少使用。
- nn.RNNCell:简单循环网络单元。和nn.RNN在整个序列上迭代相比,它仅在序列上迭代一步。一般较少使用。
tensorflow
- Embedding:嵌入层。一种比Onehot更加有效的对离散特征进行编码的方法。一般用于将输入中的单词映射为稠密向量。嵌入层的参数需要学习。
- LSTM:长短记忆循环网络层。最普遍使用的循环网络层。具有携带轨道,遗忘门,更新门,输出门。可以较为有效地缓解梯度消失问题,从而能够适用长期依赖问题。设置return_sequences = True时可以返回各个中间步骤输出,否则只返回最终输出。
- GRU:门控循环网络层。LSTM的低配版,不具有携带轨道,参数数量少于LSTM,训练速度更快。
- SimpleRNN:简单循环网络层。容易存在梯度消失,不能够适用长期依赖问题。一般较少使用。
- ConvLSTM2D:卷积长短记忆循环网络层。结构上类似LSTM,但对输入的转换操作和对状态的转换操作都是卷积运算。
- Bidirectional:双向循环网络包装器。可以将LSTM,GRU等层包装成双向循环网络。从而增强特征提取能力。
- RNN:RNN基本层。接受一个循环网络单元或一个循环单元列表,通过调用tf.keras.backend.rnn函数在序列上进行迭代从而转换成循环网络层。
- LSTMCell:LSTM单元。和LSTM在整个序列上迭代相比,它仅在序列上迭代一步。可以简单理解LSTM即RNN基本层包裹LSTMCell。
- GRUCell:GRU单元。和GRU在整个序列上迭代相比,它仅在序列上迭代一步。
- SimpleRNNCell:SimpleRNN单元。和SimpleRNN在整个序列上迭代相比,它仅在序列上迭代一步。
- AbstractRNNCell:抽象RNN单元。通过对它的子类化用户可以自定义RNN单元,再通过RNN基本层的包裹实现用户自定义循环网络层。
Transformer相关层
| 名称 | pytorch | tensorflow |
|---|---|---|
| Dot-product类型注意力机制层 | Attention | |
| Additive类型注意力机制层 | AdditiveAttention | |
| 时间分布包装器 | TimeDistributed | |
| Transformer网络结构 | nn.Transformer | |
| Transformer编码器结构 | nn.TransformerEncoder | |
| Transformer解码器结构 | nn.TransformerDecoder | |
| Transformer的编码器层 | nn.TransformerEncoderLayer | |
| Transformer的解码器层 | nn.TransformerDecoderLayer | |
| 多头注意力层 | nn.MultiheadAttention |
相关名词解释:
pytorch
- nn.Transformer:Transformer网络结构。Transformer网络结构是替代循环网络的一种结构,解决了循环网络难以并行,难以捕捉长期依赖的缺陷。它是目前NLP任务的主流模型的主要构成部分。Transformer网络结构由TransformerEncoder编码器和TransformerDecoder解码器组成。编码器和解码器的核心是MultiheadAttention多头注意力层。
- nn.TransformerEncoder:Transformer编码器结构。由多个 nn.TransformerEncoderLayer编码器层组成。
- nn.TransformerDecoder:Transformer解码器结构。由多个 nn.TransformerDecoderLayer解码器层组成。
- nn.TransformerEncoderLayer:Transformer的编码器层。
- nn.TransformerDecoderLayer:Transformer的解码器层。
- nn.MultiheadAttention:多头注意力层。
tensorflow
- Attention:Dot-product类型注意力机制层。可以用于构建注意力模型。
- AdditiveAttention:Additive类型注意力机制层。可以用于构建注意力模型。
- TimeDistributed:时间分布包装器。包装后可以将Dense、Conv2D等作用到每一个时间片段上。
自定义模型层
如果内置模型层不能够满足需求,我们也可以通过继承nn.Module(pytorch)或者keras.layers(tensorflow)基类构建自定义的模型层。
pytorch
实际上,pytorch不区分模型和模型层,都是通过继承nn.Module进行构建。
因此,我们只要继承nn.Module基类并实现forward方法即可自定义模型层。
下面是Pytorch的nn.Linear层的源码,我们可以仿照它来自定义模型层。
import torch
from torch import nn
import torch.nn.functional as F
class Linear(nn.Module):
__constants__ = ['in_features', 'out_features']
def __init__(self, in_features, out_features, bias=True):
super(Linear, self).__init__()
self.in_features = in_features
self.out_features = out_features
self.weight = nn.Parameter(torch.Tensor(out_features, in_features))
if bias:
self.bias = nn.Parameter(torch.Tensor(out_features))
else:
self.register_parameter('bias', None)
self.reset_parameters()
def reset_parameters(self):
nn.init.kaiming_uniform_(self.weight, a=math.sqrt(5))
if self.bias is not None:
fan_in, _ = nn.init._calculate_fan_in_and_fan_out(self.weight)
bound = 1 / math.sqrt(fan_in)
nn.init.uniform_(self.bias, -bound, bound)
def forward(self, input):
return F.linear(input, self.weight, self.bias)
def extra_repr(self):
return 'in_features={}, out_features={}, bias={}'.format(
self.in_features, self.out_features, self.bias is not None
)
linear = nn.Linear(20, 30)
inputs = torch.randn(128, 20)
output = linear(inputs)
print(output.size())
# torch.Size([128, 30])
tensorflow
如果自定义模型层没有需要被训练的参数,一般推荐使用Lamda层实现。
如果自定义模型层有需要被训练的参数,则可以通过对Layer基类子类化实现。
Lambda层由于没有需要被训练的参数,只需要定义正向传播逻辑即可,使用比Layer基类子类化更加简单。
Lambda层的正向逻辑可以使用Python的lambda函数来表达,也可以用def关键字定义函数来表达。
import tensorflow as tf
from tensorflow.keras import layers,models,regularizers
mypower = layers.Lambda(lambda x:tf.math.pow(x,2))
mypower(tf.range(5))
# Layer的子类化一般需要重新实现初始化方法,Build方法和Call方法。下面是一个简化的线性层的范例,类似Dense.
class Linear(layers.Layer):
def __init__(self, units=32, **kwargs):
super(Linear, self).__init__(**kwargs)
self.units = units
#build方法一般定义Layer需要被训练的参数。
def build(self, input_shape):
self.w = self.add_weight("w",shape=(input_shape[-1], self.units),
initializer='random_normal',
trainable=True) #注意必须要有参数名称"w",否则会报错
self.b = self.add_weight("b",shape=(self.units,),
initializer='random_normal',
trainable=True)
super(Linear,self).build(input_shape) # 相当于设置self.built = True
#call方法一般定义正向传播运算逻辑,__call__方法调用了它。
@tf.function
def call(self, inputs):
return tf.matmul(inputs, self.w) + self.b
#如果要让自定义的Layer通过Functional API 组合成模型时可以被保存成h5模型,需要自定义get_config方法。
def get_config(self):
config = super(Linear, self).get_config()
config.update({'units': self.units})
return config
linear = Linear(units = 8)
print(linear.built)
#指定input_shape,显式调用build方法,第0维代表样本数量,用None填充
linear.build(input_shape = (None,16))
print(linear.built)
# False
# True
linear = Linear(units = 8)
print(linear.built)
linear.build(input_shape = (None,16))
print(linear.compute_output_shape(input_shape = (None,16)))
# False
# (None, 8)
linear = Linear(units = 16)
print(linear.built)
#如果built = False,调用__call__时会先调用build方法, 再调用call方法。
linear(tf.random.uniform((100,64)))
print(linear.built)
config = linear.get_config()
print(config)
# False
# True
# {'name': 'linear_3', 'trainable': True, 'dtype': 'float32', 'units': 16}
tf.keras.backend.clear_session()
model = models.Sequential()
#注意该处的input_shape会被模型加工,无需使用None代表样本数量维
model.add(Linear(units = 1,input_shape = (2,)))
print("model.input_shape: ",model.input_shape)
print("model.output_shape: ",model.output_shape)
model.summary()
model.input_shape: (None, 2)
model.output_shape: (None, 1)
'''
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
linear (Linear) (None, 1) 3
=================================================================
Total params: 3
Trainable params: 3
Non-trainable params: 0
_________________________________________________________________
'''
model.compile(optimizer = "sgd",loss = "mse",metrics=["mae"])
print(model.predict(tf.constant([[3.0,2.0],[4.0,5.0]])))
# [[-0.04092304]
# [-0.06150477]]
# 保存成 h5模型
model.save("./data/linear_model.h5",save_format = "h5")
model_loaded_keras = tf.keras.models.load_model(
"./data/linear_model.h5",custom_objects={"Linear":Linear})
print(model_loaded_keras.predict(tf.constant([[3.0,2.0],[4.0,5.0]])))
# [[-0.04092304]
# [-0.06150477]]
# 保存成 tf模型
model.save("./data/linear_model",save_format = "tf")
model_loaded_tf = tf.keras.models.load_model("./data/linear_model")
print(model_loaded_tf.predict(tf.constant([[3.0,2.0],[4.0,5.0]])))
# INFO:tensorflow:Assets written to: ./data/linear_model/assets
# [[-0.04092304]
# [-0.06150477]]

损失函数loss

一般来说,监督学习的目标函数由损失函数和正则化项组成。(Objective = Loss + Regularization)
**pytorch中:**Pytorch中的损失函数一般在训练模型时候指定。
注意Pytorch中内置的损失函数的参数和tensorflow不同,是y_pred在前,y_true在后,而Tensorflow是y_true在前,y_pred在后。
对于回归模型,通常使用的内置损失函数是均方损失函数nn.MSELoss 。
对于二分类模型,通常使用的是二元交叉熵损失函数nn.BCELoss (输入已经是sigmoid激活函数之后的结果) 或者 nn.BCEWithLogitsLoss (输入尚未经过nn.Sigmoid激活函数) 。
对于多分类模型,一般推荐使用交叉熵损失函数 nn.CrossEntropyLoss。 (y_true需要是一维的,是类别编码。y_pred未经过nn.Softmax激活。)
此外,如果多分类的y_pred经过了nn.LogSoftmax激活,可以使用nn.NLLLoss损失函数(The negative log likelihood loss)。 这种方法和直接使用nn.CrossEntropyLoss等价。
如果有需要,也可以自定义损失函数,自定义损失函数需要接收两个张量y_pred,y_true作为输入参数,并输出一个标量作为损失函数值。
Pytorch中的正则化项一般通过自定义的方式和损失函数一起添加作为目标函数。
如果仅仅使用L2正则化,也可以利用优化器的weight_decay参数来实现相同的效果。
tensorflow中:
对于keras模型,目标函数中的正则化项一般在各层中指定,例如使用Dense的 kernel_regularizer 和 bias_regularizer等参数指定权重使用l1或者l2正则化项,此外还可以用kernel_constraint 和 bias_constraint等参数约束权重的取值范围,这也是一种正则化手段。
损失函数在模型编译时候指定。对于回归模型,通常使用的损失函数是均方损失函数 mean_squared_error。
对于二分类模型,通常使用的是二元交叉熵损失函数 binary_crossentropy。
对于多分类模型,如果label是one-hot编码的,则使用类别交叉熵损失函数 categorical_crossentropy。如果label是类别序号编码的,则需要使用稀疏类别交叉熵损失函数 sparse_categorical_crossentropy。
如果有需要,也可以自定义损失函数,自定义损失函数需要接收两个张量y_true,y_pred作为输入参数,并输出一个标量作为损失函数值。
内置损失函数
内置的损失函数一般有类的实现和函数的实现两种形式。
**pytorhc中:**如:nn.BCE 和 F.binary_cross_entropy 都是二元交叉熵损失函数,前者是类的实现形式,后者是函数的实现形式。
实际上类的实现形式通常是调用函数的实现形式并用nn.Module封装后得到的。
一般我们常用的是类的实现形式。它们封装在torch.nn模块下,并且类名以Loss结尾。
import numpy as np
import pandas as pd
import torch
from torch import nn
import torch.nn.functional as F
y_pred = torch.tensor([[10.0,0.0,-10.0],[8.0,8.0,8.0]])
y_true = torch.tensor([0,2])
# 直接调用交叉熵损失
ce = nn.CrossEntropyLoss()(y_pred,y_true)
print(ce)
# 等价于先计算nn.LogSoftmax激活,再调用NLLLoss
y_pred_logsoftmax = nn.LogSoftmax(dim = 1)(y_pred)
nll = nn.NLLLoss()(y_pred_logsoftmax,y_true)
print(nll)
# tensor(0.5493)
# tensor(0.5493)
**tensorflow中:**如:CategoricalCrossentropy 和 categorical_crossentropy 都是类别交叉熵损失函数,前者是类的实现形式,后者是函数的实现形式。
常用的一些内置损失函数说明如下。
| 损失函数类型 | pytorch | tensorflow |
|---|---|---|
| 均方误差损失 | nn.MSELoss | mean_squared_error |
| 绝对值误差损失 | nn.L1Loss | mean_absolute_error |
| 平滑L1损失 | nn.SmoothL1Loss | |
| 平均百分比误差损失 | mean_absolute_percentage_error | |
| Huber损失 | Huber | |
| 二元交叉熵 | nn.BCELoss/nn.BCEWithLogitsLoss | binary_crossentropy |
| 类别交叉熵 | nn.CrossEntropyLoss | categorical_crossentropy |
| 稀疏类别交叉熵 | sparse_categorical_crossentropy | |
| 合页损失函数 | sparse_categorical_crossentropy | |
| 负对数似然损失 | nn.NLLLoss | |
| 余弦相似度 | nn.CosineSimilarity | cosine_similarity |
| 分布很不均衡的损失函数 | nn.AdaptiveLogSoftmaxWithLoss | |
| 相对熵损失 | kld |
名词解释:
pytorch
- nn.MSELoss(均方误差损失,也叫做L2损失,用于回归)
- nn.L1Loss (L1损失,也叫做绝对值误差损失,用于回归)
- nn.SmoothL1Loss (平滑L1损失,当输入在-1到1之间时,平滑为L2损失,用于回归)
- nn.BCELoss (二元交叉熵,用于二分类,输入已经过nn.Sigmoid激活,对不平衡数据集可以用weigths参数调整类别权重)
- nn.BCEWithLogitsLoss (二元交叉熵,用于二分类,输入未经过nn.Sigmoid激活)
- nn.CrossEntropyLoss (交叉熵,用于多分类,要求label为稀疏编码,输入未经过nn.Softmax激活,对不平衡数据集可以用weigths参数调整类别权重)
- nn.NLLLoss (负对数似然损失,用于多分类,要求label为稀疏编码,输入经过nn.LogSoftmax激活)
- nn.CosineSimilarity(余弦相似度,可用于多分类)
- nn.AdaptiveLogSoftmaxWithLoss (一种适合非常多类别且类别分布很不均衡的损失函数,会自适应地将多个小类别合成一个cluster)
更多损失函数的介绍参考如下知乎文章:
《PyTorch的十八个损失函数》https://zhuanlan.zhihu.com/p/61379965
tensorflow
- mean_squared_error(均方误差损失,用于回归,简写为 mse, 类与函数实现形式分别为 MeanSquaredError 和 MSE)
- mean_absolute_error (平均绝对值误差损失,用于回归,简写为 mae, 类与函数实现形式分别为 MeanAbsoluteError 和 MAE)
- mean_absolute_percentage_error (平均百分比误差损失,用于回归,简写为 mape, 类与函数实现形式分别为 MeanAbsolutePercentageError 和 MAPE)
- Huber(Huber损失,只有类实现形式,用于回归,介于mse和mae之间,对异常值比较鲁棒,相对mse有一定的优势)
- binary_crossentropy(二元交叉熵,用于二分类,类实现形式为 BinaryCrossentropy)
- categorical_crossentropy(类别交叉熵,用于多分类,要求label为onehot编码,类实现形式为 CategoricalCrossentropy)
- sparse_categorical_crossentropy(稀疏类别交叉熵,用于多分类,要求label为序号编码形式,类实现形式为 SparseCategoricalCrossentropy)
- hinge(合页损失函数,用于二分类,最著名的应用是作为支持向量机SVM的损失函数,类实现形式为 Hinge)
- kld(相对熵损失,也叫KL散度,常用于最大期望算法EM的损失函数,两个概率分布差异的一种信息度量。类与函数实现形式分别为 KLDivergence 或 KLD)
- cosine_similarity(余弦相似度,可用于多分类,类实现形式为 CosineSimilarity)
自定义损失函数
自定义损失函数接收两个张量y_pred,y_true(tensorflow为y_true,y_pred)作为输入参数,并输出一个标量作为损失函数值。
pytorch中:也可以对nn.Module进行子类化,重写forward方法实现损失的计算逻辑,从而得到损失函数的类的实现。
tensorflow中:也可以对tf.keras.losses.Loss进行子类化,重写call方法实现损失的计算逻辑,从而得到损失函数的类的实现。
下面是一个Focal Loss的自定义实现示范。Focal Loss是一种对binary_crossentropy的改进损失函数形式。
它在样本不均衡和存在较多易分类的样本时相比binary_crossentropy具有明显的优势。
它有两个可调参数,alpha参数和gamma参数。其中alpha参数主要用于衰减负样本的权重,gamma参数主要用于衰减容易训练样本的权重。
从而让模型更加聚焦在正样本和困难样本上。这就是为什么这个损失函数叫做Focal Loss。
详见《5分钟理解Focal Loss与GHM——解决样本不平衡利器》
https://zhuanlan.zhihu.com/p/80594704
pytorch
class FocalLoss(nn.Module):
def __init__(self,gamma=2.0,alpha=0.75):
super().__init__()
self.gamma = gamma
self.alpha = alpha
def forward(self,y_pred,y_true):
bce = torch.nn.BCELoss(reduction = "none")(y_pred,y_true)
p_t = (y_true * y_pred) + ((1 - y_true) * (1 - y_pred))
alpha_factor = y_true * self.alpha + (1 - y_true) * (1 - self.alpha)
modulating_factor = torch.pow(1.0 - p_t, self.gamma)
loss = torch.mean(alpha_factor * modulating_factor * bce)
return loss
#困难样本
y_pred_hard = torch.tensor([[0.5],[0.5]])
y_true_hard = torch.tensor([[1.0],[0.0]])
#容易样本
y_pred_easy = torch.tensor([[0.9],[0.1]])
y_true_easy = torch.tensor([[1.0],[0.0]])
focal_loss = FocalLoss()
bce_loss = nn.BCELoss()
print("focal_loss(hard samples):", focal_loss(y_pred_hard,y_true_hard))
print("bce_loss(hard samples):", bce_loss(y_pred_hard,y_true_hard))
print("focal_loss(easy samples):", focal_loss(y_pred_easy,y_true_easy))
print("bce_loss(easy samples):", bce_loss(y_pred_easy,y_true_easy))
#可见 focal_loss让容易样本的权重衰减到原来的 0.0005/0.1054 = 0.00474
#而让困难样本的权重只衰减到原来的 0.0866/0.6931=0.12496
# 因此相对而言,focal_loss可以衰减容易样本的权重。
# focal_loss(hard samples): tensor(0.0866)
# bce_loss(hard samples): tensor(0.6931)
# focal_loss(easy samples): tensor(0.0005)
# bce_loss(easy samples): tensor(0.1054)
tensorflow
def focal_loss(gamma=2., alpha=0.75):
def focal_loss_fixed(y_true, y_pred):
bce = tf.losses.binary_crossentropy(y_true, y_pred)
p_t = (y_true * y_pred) + ((1 - y_true) * (1 - y_pred))
alpha_factor = y_true * alpha + (1 - y_true) * (1 - alpha)
modulating_factor = tf.pow(1.0 - p_t, gamma)
loss = tf.reduce_sum(alpha_factor * modulating_factor * bce,axis = -1 )
return loss
return focal_loss_fixed
class FocalLoss(tf.keras.losses.Loss):
def __init__(self,gamma=2.0,alpha=0.75,name = "focal_loss"):
self.gamma = gamma
self.alpha = alpha
def call(self,y_true,y_pred):
bce = tf.losses.binary_crossentropy(y_true, y_pred)
p_t = (y_true * y_pred) + ((1 - y_true) * (1 - y_pred))
alpha_factor = y_true * self.alpha + (1 - y_true) * (1 - self.alpha)
modulating_factor = tf.pow(1.0 - p_t, self.gamma)
loss = tf.reduce_sum(alpha_factor * modulating_factor * bce,axis = -1 )
return loss
正则化项(L1,L2)
pytorch
通常认为L1 正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择。
而L2 正则化可以防止模型过拟合(overfitting)。一定程度上,L1也可以防止过拟合。
下面以一个二分类问题为例,演示给模型的目标函数添加自定义L1和L2正则化项的方法。
这个范例同时演示了上一个部分的FocalLoss的使用。
# 定义模型
class DNNModel(torchkeras.Model):
def __init__(self):
super(DNNModel, self).__init__()
self.fc1 = nn.Linear(2,4)
self.fc2 = nn.Linear(4,8)
self.fc3 = nn.Linear(8,1)
def forward(self,x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
y = nn.Sigmoid()(self.fc3(x))
return y
model = DNNModel()
model.summary(input_shape =(2,))
"""
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Linear-1 [-1, 4] 12
Linear-2 [-1, 8] 40
Linear-3 [-1, 1] 9
================================================================
Total params: 61
Trainable params: 61
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.000008
Forward/backward pass size (MB): 0.000099
Params size (MB): 0.000233
Estimated Total Size (MB): 0.000340
----------------------------------------------------------------
"""
# 准确率
def accuracy(y_pred,y_true):
y_pred = torch.where(y_pred>0.5,torch.ones_like(y_pred,dtype = torch.float32),
torch.zeros_like(y_pred,dtype = torch.float32))
acc = torch.mean(1-torch.abs(y_true-y_pred))
return acc
# L2正则化
def L2Loss(model,alpha):
l2_loss = torch.tensor(0.0, requires_grad=True)
for name, param in model.named_parameters():
if 'bias' not in name: #一般不对偏置项使用正则
l2_loss = l2_loss + (0.5 * alpha * torch.sum(torch.pow(param, 2)))
return l2_loss
# L1正则化
def L1Loss(model,beta):
l1_loss = torch.tensor(0.0, requires_grad=True)
for name, param in model.named_parameters():
if 'bias' not in name:
l1_loss = l1_loss + beta * torch.sum(torch.abs(param))
return l1_loss
# 将L2正则和L1正则添加到FocalLoss损失,一起作为目标函数
def focal_loss_with_regularization(y_pred,y_true):
focal = FocalLoss()(y_pred,y_true)
l2_loss = L2Loss(model,0.001) #注意设置正则化项系数
l1_loss = L1Loss(model,0.001)
total_loss = focal + l2_loss + l1_loss
return total_loss
# 编译模型的时候使用定义的损失函数即可
model.compile(loss_func =focal_loss_with_regularization,
optimizer= torch.optim.Adam(model.parameters(),lr = 0.01),
metrics_dict={"accuracy":accuracy})
dfhistory = model.fit(30,dl_train = dl_train,dl_val = dl_valid,log_step_freq = 30)
tensorflow
tf.keras.backend.clear_session()
model = models.Sequential()
model.add(layers.Dense(64, input_dim=64,
kernel_regularizer=regularizers.l2(0.01),
activity_regularizer=regularizers.l1(0.01),
kernel_constraint = constraints.MaxNorm(max_value=2, axis=0)))
# 正则化项作为添加层(最后一层)的参数kernel_regularizer添加即可。
model.add(layers.Dense(10,
kernel_regularizer=regularizers.l1_l2(0.01,0.01),activation = "sigmoid"))
model.compile(optimizer = "rmsprop",
loss = "binary_crossentropy",metrics = ["AUC"])
model.summary()
"""
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 64) 4160
_________________________________________________________________
dense_1 (Dense) (None, 10) 650
=================================================================
Total params: 4,810
Trainable params: 4,810
Non-trainable params: 0
_________________________________________________________________
"""

说明
笔记中很多代码案例来自于:
《20天吃掉那只Pytorch》
- github项目地址: https://github.com/lyhue1991/eat_pytorch_in_20_days
《30天吃掉那只TensorFlow2》
- github项目地址: https://github.com/lyhue1991/eat_tensorflow2_in_30_days
感兴趣的同学可以进入学习。
===========================================================================
我的笔记一部分是将这两项目中内容整理归纳,一部分是相应功能的内容自己找资料整理归纳。
笔记以MD格式存入我的git仓库,另外代码案例所需要数据集文件也在其中:可以clone下来学习使用。
《pytorch-tensorflow对比学习笔记》
github项目地址: https://github.com/Boris-2021/pytorch-tensorflow-Comparative-study
===========================================================================
笔记中增加了很多趣味性的图片,增加阅读乐趣。
===========================================================================
感觉对你的学习有帮助,就点个星,点个赞,点个关注再走把,整理不易,拒绝白嫖从我做起!
