pytorch 图像分割的交并比_pytorch知识点总结
清理库存4~
PyTorch 中文手册(pytorch handbook):
https://pytorch-cn.readthedocs.io/zh/latest/(官方中文版)
zergtant/pytorch-handbookgithub.com
英文版:
Deep Learning with PyTorch: A 60 Minute Blitzpytorch.org
PyTorch是一个Python包,提供两个高级功能:
具有强大的GPU加速的张量计算(如NumPy)
包含自动求导系统的的深度神经网络
基于Python的科学计算包,服务于以下两种场景:
- 作为NumPy的替代品,可以使用GPU的强大计算能力
- 提供最大的灵活性和高速的深度学习研究平台
Tensors(张量)
Tensors与Numpy中的 ndarrays类似,但是在PyTorch中 Tensors 可以使用GPU进行计算.
PyTorch支持各种类型的张量。
PyTorch入门教程www.jianshu.com
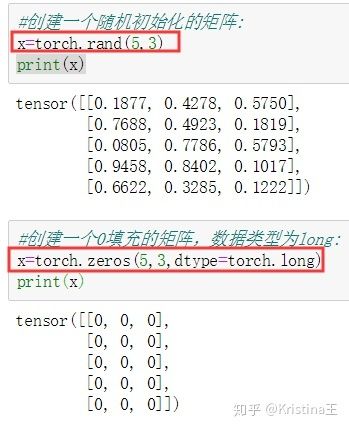
根据现有的张量创建张量,使用size方法与Numpy的shape属性返回的相同,张量也支持shape属性.

【注意】`torch.Size` 返回值是 tuple类型, 所以它支持tuple类型的所有操作.
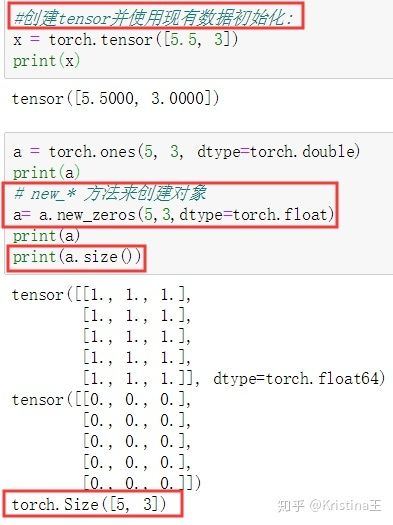

【注意】:
torch.Tensor默认的是torch.float数据类型。

输出的四种结果都一样:

【重点理解】:Pytorch 张量维度
可参考:
https://blog.csdn.net/weicao1990/article/details/93204452blog.csdn.net函数dim()可以返回张量的维度,shape属性与成员函数size()返回张量的具体维度分量。
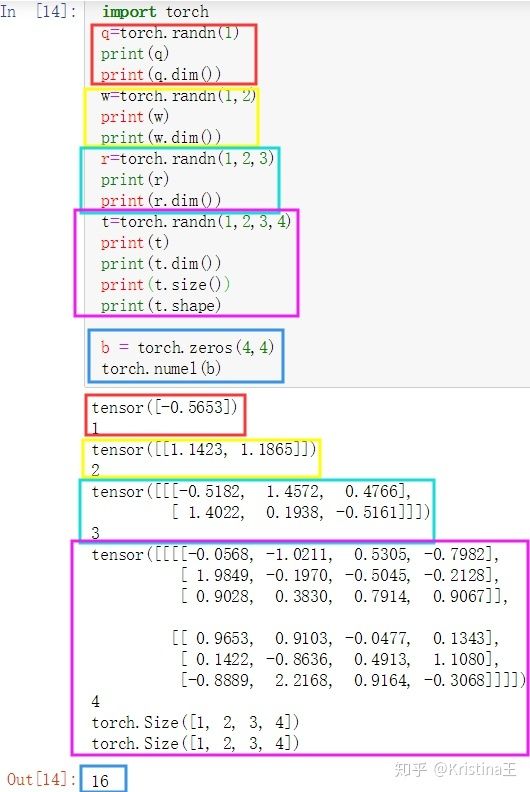
dim=0的标量
维度为0的Tensor为标量,标量一般用在Loss这种地方。如下代码定义了一个标量:
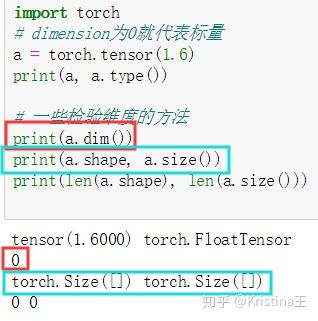
定义标量的方式很简单,只要在tensor函数中传入一个标量初始化的值即可,注意是具体的数据。
dim=1的张量
dim=1的Tensor一般用在Bais这种地方,或者神经网络线性层的输入Linear Input,例如MINST数据集的一张图片用shape=[784]的Tensor来表示。
dim=1相当于只有一个维度,但是这个维度上可以有多个分量(就像一维数组一样),一维的张量实现方法有很多,下面是三种实现:
注意:维度为1时,shape和size返回的是元素个数。

dim=2的张量
dim=2的张量一般用在带有batch的Linear Input,例如MNIST数据集的k张图片如果放再一个Tensor里,那么shape=[k,784]。
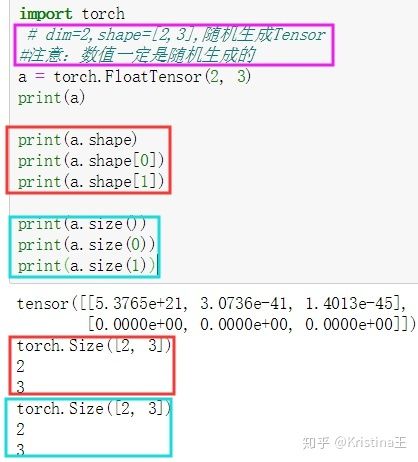
从上面可以看出,可以取到Tensor每一维度的分量 。
dim=3的张量
dim=3的张量很适合用于RNN和NLP,如20句话,每句话10个单词,每个单词用100个分量的向量表示,得到的Tensor就是shape=[20,10,100]。
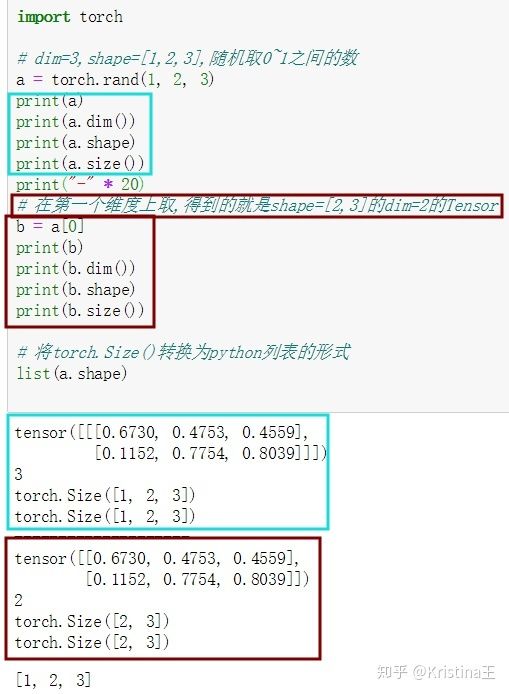
dim=4的张量
dim=4的张量适合用于CNN表示图像,例如100张MNIST手写数据集的灰度图(通道数为1,如果是RGB图像通道数就是3),每张图高=28像素,宽=28像素,所以这个Tensor的shape=[100,1,28,28],也就是一个batch的数据维度:[batch_size,channel,height,width] 。
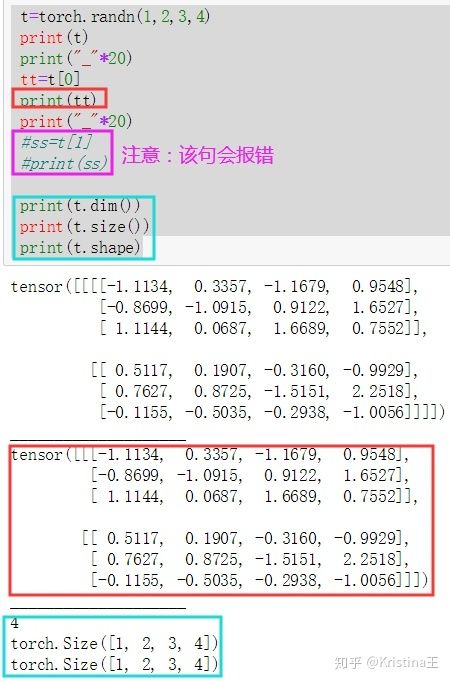
注意:在维度上取值:

输出:

总结:
在同构的意义下,第零阶张量 (r = 0) 为标量 (Scalar),第一阶张量 (r = 1) 为向量 (Vector), 第二阶张量 (r = 2) 则成为矩阵 (Matrix),第三阶以上的统称为多维张量。
对于标量,我们可以直接使用 .item() 从中取出其对应的python对象的数值。
特别的:如果张量中只有一个元素的tensor也可以调用tensor.item方法。

基本类型
Tensor的基本数据类型有五种:
- 32位浮点型:torch.FloatTensor。 (默认)
- 64位整型:torch.LongTensor。
- 32位整型:torch.IntTensor。
- 16位整型:torch.ShortTensor。
- 64位浮点型:torch.DoubleTensor。
除以上数字类型外,还有 byte和chart型.
设备间转换
一般情况下可以使用.cuda方法将tensor移动到gpu,这步操作需要cuda设备支持。
使用.cpu方法将tensor移动到cpu。

如果我们有多GPU的情况,可以使用to方法来确定使用那个设备。

常用方法:


【PyTorch】Tensor和tensor的区别
可参考:
https://blog.csdn.net/tfcy694/article/details/85338745

torch.Tensor()是python类,更明确地说,是默认张量类型torch.FloatTensor()的别名,torch.Tensor([1,2])会调用Tensor类的构造函数__init__,生成单精度浮点类型的张量。
而torch.tensor()仅仅是python函数,函数原型是:
torch.tensor(data, dtype=None, device=None, requires_grad=False)
其中data可以是:list, tuple, NumPy ndarray, scalar和其他类型。
主要区别有以下两点:
- torch.tensor会从data中的数据部分做拷贝(而不是直接引用),根据原始数据类型生成相应的torch.LongTensor、torch.FloatTensor和torch.DoubleTensor。而torch.Tensor()只能指定数据类型为torch.float。
- torch.tensor()参数接收的是具体的数据,而torch.Tensor()参数既可以接收数据也可以接收维度分量也就是shape。
Pytorch中tensor常用语法:
https://blog.csdn.net/weixin_44538273/article/details/88400805
torch.numel 返回input 张量中的元素个数。
torch.numel(input)->int
计算Tensor中元素的数目:
torch.sum(input, dim, keepdim=False, out=None) → Tensor
返回新的张量,其中包括输入张量input中指定维度dim中每行的和。其中,sum默认为每列的和。torch.sum(input) : 返回所有元素的之和。

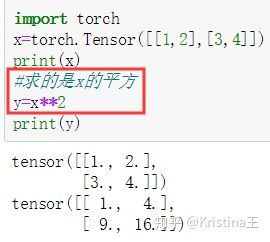
torch.linspace
torch.linspace(start, end, steps=100, out=None) → Tensor
返回一个1维张量,包含在区间start 和 end 上均匀间隔的steps个点。 输出1维张量的长度为steps。
参数:
- start (float) – 序列的起始点
- end (float) – 序列的最终值
- steps (int) – 在
start和end间生成的样本数 - out (Tensor, optional) – 结果张量

torch.logspace
torch.logspace(start, end, steps=100, out=None) → Tensor
返回一个1维张量,包含在区间 10start10start 和 10end10end上以对数刻度均匀间隔的steps个点。 输出1维张量的长度为steps。
参数:
- start (float) – 序列的起始点
- end (float) – 序列的最终值
- steps (int) – 在
start和end间生成的样本数 - out (Tensor, optional) – 结果张量

torch.rand
torch.rand(*sizes, out=None) → Tensor
返回一个张量,包含了从区间[0,1)的均匀分布中抽取的一组随机数,形状由可变参数sizes 定义。
torch.randn
torch.randn(*sizes, out=None) → Tensor
返回一个张量,包含了从标准正态分布(均值为0,方差为 1,即高斯白噪声)中抽取一组随机数,形状由可变参数sizes定义。
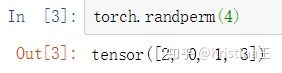
torch.randperm
torch.randperm(n, out=None) → LongTensor
给定参数n,返回一个从0 到n -1 的随机整数排列。
torch.arange
torch.arange(start, end, step=1, out=None) → Tensor
返回一个1维张量,长度为 floor((end−start)/step)floor((end−start)/step)。包含从start到end,以step为步长的一组序列值(默认步长为1)。
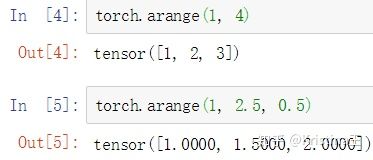
torch.range
torch.range(start, end, step=1, out=None) → Tensor
返回一个1维张量,有 floor((end−start)/step)+1floor((end−start)/step)+1 个元素。包含在半开区间[start, end)从start开始,以step为步长的一组值。 step 是两个值之间的间隔,即
警告:建议使用函数 torch.arange()
索引,切片,连接,换位Indexing, Slicing, Joining, Mutating Ops
torch.cat
torch.cat(inputs, dimension=0) → Tensor
在给定维度上对输入的张量序列seq 进行连接操作。
torch.cat()可以看做 torch.split() 和 torch.chunk()的反操作。 cat() 函数可以通过下面例子更好的理解。
参数:
- inputs (sequence of Tensors) – 可以是任意相同Tensor 类型的python 序列
- dimension (int, optional) – 沿着此维连接张量序列。

torch.chunk
torch.chunk(tensor, chunks, dim=0)
在给定维度(轴)上将输入张量进行分块儿。
参数:
- tensor (Tensor) – 待分块的输入张量
- chunks (int) – 分块的个数
- dim (int) – 沿着此维度进行分块
torch.gather(注意:维度的取值?????理解的不到位)
torch.gather(input, dim, index, out=None) → Tensor
沿给定轴dim,将输入索引张量index指定位置的值进行聚合。
注意:该函数不太容易理解。
https://blog.csdn.net/edogawachia/article/details/80515038blog.csdn.nettorch.index_select(简言之,dim=0按行取值,dim=1按列取值)
torch.index_select(input, dim, index, out=None) → Tensor
沿着指定维度对输入进行切片,取index中指定的相应项(index为一个LongTensor),然后返回到一个新的张量, 返回的张量与原始张量_Tensor_有相同的维度(在指定轴上)。
注意: 返回的张量不与原始张量共享内存空间。
参数:
- input (Tensor) – 输入张量
- dim (int) – 索引的轴
- index (LongTensor) – 包含索引下标的一维张量
- out (Tensor, optional) – 目标张量

torch.masked_select
torch.masked_select(input, mask, out=None) → Tensor
根据掩码张量mask中的二元值,取输入张量中的指定项( mask为一个 ByteTensor),将取值返回到一个新的1D张量,
张量 mask须跟input张量有相同数量的元素数目,但形状或维度不需要相同。 注意: 返回的张量不与原始张量共享内存空间。
参数:
- input (Tensor) – 输入张量
- mask (ByteTensor) – 掩码张量,包含了二元索引值
- out (Tensor, optional) – 目标张量
torch.nonzero
torch.nonzero(input, out=None) → LongTensor
返回一个包含输入input中非零元素索引的张量。输出张量中的每行包含输入中非零元素的索引。
如果输入input有n维,则输出的索引张量output的形状为 z x n, 这里 z 是输入张量input中所有非零元素的个数。
参数:
- input (Tensor) – 源张量
- out (LongTensor, optional) – 包含索引值的结果张量
##################################
torch.nn
网络教程代码解析可参考:
https://blog.csdn.net/weixin_41070748/article/details/89890330blog.csdn.net视频教程可参考:
https://blog.csdn.net/fendouaini/article/details/89944199
自动微分
在pytorch中,神经网络的核心是自动微分,在本节中我们会初探这个部分,也会训练一个小型的神经网络。自动微分包会提供自动微分的操作,它是一个取决于每一轮的运行的库,你的下一次的结果会和你上一轮运行的代码有关,因此,每一轮的结果,有可能都不一样。接下来,让我们来看一些例子。
PyTorch常用函数摘抄:
PyTorch常用函数摘抄www.jianshu.com
可以使用与NumPy索引方式相同的操作来进行对张量的操作:
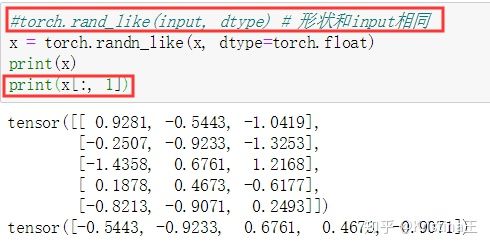
torch.view: 可以改变张量的维度和大小。torch.view 与Numpy的reshape类似。

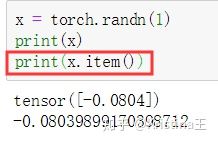
如果你有只有一个元素的张量,使用.item()来得到Python数据类型的数值:
多维的张量:
http://tech.ifeng.com/a/20180411/44945275_0.shtmltech.ifeng.comNumPy 转换
将一个Torch Tensor转换为NumPy数组是一件轻松的事,反之亦然。
Torch Tensor与NumPy数组共享底层内存地址,修改一个会导致另一个的变化。
将一个Torch Tensor转换为NumPy数组:

NumPy Array 转化成 Torch Tensor:使用from_numpy自动转化。
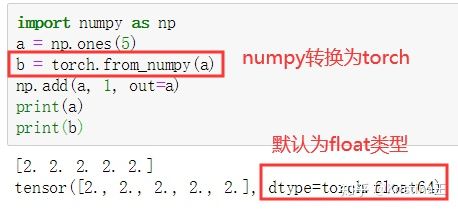
【注意】CharTensor 类型不支持到 NumPy 的转换.
CUDA 张量
所有的 Tensor 类型默认都是基于CPU,使用.to 方法 可以将Tensor移动到任何设备中。
is_available 函数判断是否有cuda可以使用。`torch.device`将张量移动到指定的设备中。

Autograd: 自动求导机制
PyTorch 中所有神经网络的核心是 autograd 包。 我们先简单介绍一下这个包,然后训练第一个简单的神经网络。
autograd包为张量上的所有操作提供了自动求导。 它是一个在运行时定义的框架,这意味着反向传播是根据你的代码来确定如何运行,并且每次迭代可以是不同的。
torch.Tensor是这个包的核心类。
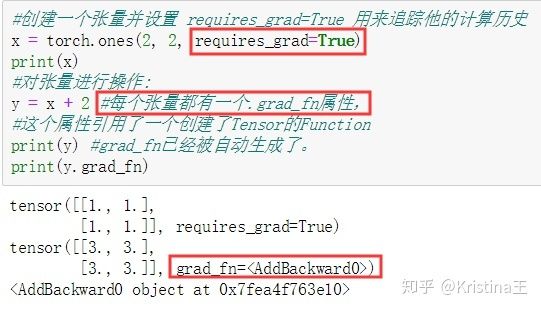
如果设置.requires_grad为True,那么将会追踪所有对于该张量的操作。 当完成计算后通过调用.backward(),自动计算所有的梯度, 这个张量的所有梯度将会自动积累到.grad属性。
要阻止张量跟踪历史记录,可以调用.detach()方法将其与计算历史记录分离,并禁止跟踪它将来的计算记录。
为了防止跟踪历史记录(和使用内存),可以将代码块包装在with torch.no_grad():中。 在评估模型时特别有用,因为模型可能具有requires_grad = True的可训练参数,但是我们不需要梯度计算。
在自动梯度计算中还有另外一个重要的类Function.
Tensor 和 Function互相连接并生成一个非循环图,它表示和存储了完整的计算历史。 每个张量都有一个.grad_fn属性,这个属性引用了一个创建了Tensor的Function(除非这个张量是用户手动创建的,即,这个张量的 grad_fn 是 None)。
如果需要计算导数,你可以在Tensor上调用.backward()。 如果Tensor是一个标量(即它包含一个元素数据)则不需要为backward()指定任何参数, 但是如果它有更多的元素,你需要指定一个gradient 参数来匹配张量的形状。
译者注:在其他的文章中你可能会看到说将Tensor包裹到Variable中提供自动梯度计算,Variable 这个在0.41版中已经被标注为过期了,现在可以直接使用Tensor。
梯度
反向传播 因为 out是一个纯量(scalar),out.backward() 等于out.backward(torch.tensor(1))。
##############未完待续################