自动驾驶 2D 单目\双目\多目视觉方法 一(Pseudo-LiDAR,Mono3D,FCOS3D,PSMNet)
文章目录
- 概述
-
- 单目3D感知
-
- 3D目标检测
- 单目深度估计
- 双目3D感知
-
- 双目3D目标检测
- 双目深度估计
- Pseudo-LiDAR
-
- 1. 核心思路总结
- 2. 要点分析
- Mono3D
- FCOS3D
- PSMNet
概述
自动驾驶中必不可少的3D场景感知。因为深度信息、目标三维尺寸等在2D感知中是无法获得的,而这些信息才是自动驾驶系统对周围环境作出正确判断的关键。想得到3D信息,最直接的方法就是采用激光雷达(LiDAR)。但是,LiDAR也有其缺点,比如成本较高,车规级产品量产困难,受天气影响较大等等。因此,单纯基于摄像头的3D感知仍然是一个非常有意义和价值的研究方向,接下来我们梳理了一些基于单目和双目的3D感知算法。
单目3D感知
基于单摄像头图像来感知3D环境是一个不适定问题,但是可以通过几何假设(比如像素位于地面)、先验知识或者一些额外信息(比如深度估计)来辅助解决。本次将从实现自动驾驶的两个基本任务(3D目标检测和深度估计)出发进行相关算法介绍。
3D目标检测
表示转换(伪激光雷达):视觉传感器对周围其他车辆等的检测通常会遇到遮挡、无法度量距离等问题,可以将透视图转换成鸟瞰图表示。这里介绍两种变换方法。一是逆透视图映射(IPM),它假定所有像素都在地面上,并且相机外参准确,此时可以采用Homography变换将图像转换到BEV,后续再采用基于YOLO网络的方法检测目标的接地框。二是正交特征变换(OFT),利用ResNet-18提取透视图图像特征。然后,通过在投影的体素区域上累积基于图像的特征来生成基于体素的特征。然后将体素特征沿垂直方向折叠以产生正交的地平面特征。最后,用另一个类似于ResNet的自上而下的网络进行3D目标检测。这些方法只适应于车辆、行人这类贴地的目标。对于交通标志牌、红绿灯这类非贴地目标来说,可以通过深度估计来生成伪点云,进而进行3D检测。Pseudo-LiDAR先利用深度估计的结果生成点云,再直接应用基于激光雷达的3D目标检测器生成3D目标框,其算法流程如下图所示,

关键点和3D模型:待检测目标如车辆、行人等其大小和形状相对固定且已知,这些可以被用作估计目标3D信息的先验知识。DeepMANTA是这个方向的开创性工作之一。首先,采用一些目标检测算法比如Faster RNN来得到2D目标框,同时也检测目标的关键点。然后,将这些2D目标框和关键点与数据库中的多种3D车辆CAD模型分别进行匹配,选择相似度最高的模型作为3D目标检测的输出。MonoGRNet则提出将单目3D目标检测分成四个步骤:2D目标检测、实例级深度估计、投影3D中心估计和局部角点回归,算法流程如下图所示。这类方法都假设目标有相对固定的形状模型,对于车辆来说一般是满足的,对于行人来说就相对困难一些。

2D/3D几何约束:对3D中心和粗略实例深度的投影进行回归,并使用这二者估算粗略的3D位置。开创性的工作是Deep3DBox,首先用2D目标框内的图像特征来估计目标大小和朝向。然后,通过一个2D/3D的几何约束来求解中心点3D位置。这个约束就是3D目标框在图像上的投影是被2D目标框紧密包围的,即2D目标框的每条边上都至少能找到一个3D目标框的角点。通过之前已经预测的大小和朝向,再配合上相机的标定参数,可以求解出中心点的3D位置。2D和3D目标框之间的几何约束如下图所示。Shift R-CNN在Deep3DBox的基础上将之前得到的2D目标框、3D目标框以及相机参数合并起来作为输入,采用全连接网络预测更为精确的3D位置。
直接生成3DBox:这类方法从稠密的3D目标候选框出发,通过2D图像上的特征对所有的候选框进行评分,评分高的候选框即是最终的输出。有些类似目标检测中传统的滑动窗口方法。代表性的Mono3D算法首先基于目标先验位置(z坐标位于地面)和大小来生成稠密的3D候选框。这些3D候选框投影到图像坐标后,通过综合2D图像上的特征对其进行评分,再通过CNN再进行二轮评分得到最终的3D目标框。M3D-RPN是一种基于Anchor的方法,定义了2D和3D的Anchor。2D Anchor通过图像上稠密采样得到,3D Anchor是通过训练集数据的先验知识(如目标实际大小的均值)确定的。M3D-RPN还同时采用了标准卷积和Depth-Aware卷积。前者具有空间不变性,后者将图像的行(Y坐标)分成多个组,每个组对应不同的场景深度,采用不同的卷积核来处理。上述这些稠密采样方法计算量非常大。SS3D则采用更为高效的单阶段检测,包括用于输出图像中每个相关目标的冗余表示以及相应的不确定性估计的CNN,以及3D边框优化器。FCOS3D也是一个单阶段的检测方法,回归目标额外增加了一个由3D目标框中心投影到2D图像得到的2.5D中心(X,Y,Depth)。
单目深度估计
不管是上述的3D目标检测还是自动驾驶感知的另一项重要任务——语义分割,从2D扩展到3D,都或多或少得应用到了稀疏或稠密的深度信息。单目深度估计的重要性不言而喻,其输入是一张图像,输出是相同大小的一张由每个像素对应的场景深度值组成的图像。输入也可以是视频序列,利用相机或者物体运动带来的额外信息来提高深度估计的准确度。
相比于监督学习,单目深度估计的无监督方法无需构建极具挑战性的真值数据集,实现难度更小。单目深度估计的无监督方法可分为基于单目视频序列和基于同步立体图像对两种。前者是建立在运动相机和静止场景的假设之上的。在后者的方法中,Garg等人首次尝试使用同一时刻立体校正后的双目图像对进行图像重建,左右视图的位姿关系通过双目标定得到,获得了较为理想的效果。在此基础上,Godard等人用左右一致性约束进一步地提升了精度,但是,在逐层下采样提取高级特征来增大感受野的同时,特征分辨率也在不断下降,粒度不断丢失,影响了深度的细节处理效果和边界清晰度。为缓解这一问题,Godard等人引入了全分辨率多尺度的损失,有效减少了低纹理区域的黑洞和纹理复制带来的伪影。但是,这对精度的提升效果仍是有限的。
最近,一些基于Transformer的模型层出不穷,旨于获得全阶段的全局感受野,这也非常适用于密集的深度估计任务。有监督的DPT中就提出采用Transformer和多尺度结构来同时保证预测的局部精确性和全局一致性,下图是网络结构图。
双目3D感知
双目视觉可以解决透视变换带来的歧义性,因此从理论上来说可以提高3D感知的准确度。但是双目系统在硬件和软件上要求都比较高。硬件上来说需要两个精确配准的摄像头,而且需要保证在车辆运行过程中始终保持配准的正确性。软件上来说算法需要同时处理来自两个摄像头的数据,计算复杂度较高,算法的实时性难以保证。与单目相比,双目的工作相对较少。接下来也同样从3D目标检测和深度估计两方面进行简单介绍。
双目3D目标检测
3DOP是一个两阶段的检测方法,是Fast R-CNN方法在3D领域的拓展。首先利用双目图像生成深度图,将深度图转化为点云后再将其量化为网格数据结构,再以此为输入来生成3D目标的候选框。与之前介绍的Pseudo-LiDAR类似,都是将稠密的深度图(来自单目、双目甚至低线数LiDAR)转换为点云,然后再应用点云目标检测领域的算法。DSGN利用立体匹配构建平面扫描体,并将其转换成3D几何体,以便编码3D几何形状和语义信息,是一个端到端的框架,可提取用于立体匹配的像素级特征和用于目标识别的高级特征,并且能同时估计场景深度和检测3D目标。Stereo R-CNN扩展了 Faster R-CNN 用于立体输入,以同时检测和关联左右视图中的目标。在RPN之后增加额外的分支来预测稀疏的关键点、视点和目标尺寸,并结合左右视图中的2D边界框来计算粗略的3D目标边界框。然后,通过使用左右感兴趣区域的基于区域的光度对齐来恢复准确的3D边界框,下图是它的网络结构。
双目深度估计
双目深度估计的原理很简单,就是根据左右视图上同一个3D点之间的像素距离d(假设两个相机保持同一高度,因此只考虑水平方向的距离)即视差,相机的焦距f,以及两个相机之间的距离B(基线长度),来估计3D点的深度,公式如下,估计出视差就可以计算出深度。那么,需要做的就是为每个像素点在另一张图像上找出与之匹配的点。
对于每一个可能的d,都可以计算每个像素点处的匹配误差,因此就得到了一个三维的误差数据Cost Volume。通过Cost Volume,我们可以很容易得到每个像素处的视差(对应最小匹配误差的d),从而得到深度值。MC-CNN用一个卷积神经网络来预测两个图像块的匹配程度,并用它来计算立体匹配成本。通过基于交叉的成本汇总和半全局匹配来细化成本,然后进行左右一致性检查以消除被遮挡区域中的错误。PSMNet提出了一个不需要任何后处理的立体匹配的端到端学习框架,引入金字塔池模块,将全局上下文信息纳入图像特征,并提供了一个堆叠沙漏3D CNN进一步强化全局信息。下图是其网络结构。

Pseudo-LiDAR
1. 核心思路总结
首先利用DRON或PSMNET从单目 (Monocular)或双目 (Stereo)图像获取对应的深度图像(depth map),然后将原图像结合深度信息得到伪雷达点云 (pseudo-LiDAR),最后用pseudo-LiDAR代替原始雷达点云,以3D point cloud和bird’s eye view的形式,分别在LiDAR-based的F-PointNet以及AVOD上与图像的front view表示进行了比较,并对比了Image-based的Mono3D, 3DOP, MLF这三类方案。(好像就是一个深度估计+一个三维重建+一堆对比实验?)
图一:The Pipeline of Pseudo-LiDAR
Pseudo-LiDAR一堆对比实验如表一所示。其中蓝色字体为利用图像的pseudo-LiDAR表示,灰色字体为利用原始雷达点云,黑色字体为利用图像的前视图表示 (原始表示)。从表中可以看到,将图像转换为pseudo-LiDAR表示后,确实是bridged the gap between Image-based 3D Perception and LiDAR-based 3D Perception.

表一:Comparison with Other Methods
2. 要点分析
- The Inferior Performance of Image-based 3D Perception
众所周知,从2D图像进行3D感知本身就是一个ill-posed问题,因为图像缺少3D感知最为关键的深度信息。虽然通过单目或双目深度估计可以得到深度图像,但是其不准确的深度信息会严重影响网络对三维空间的理解。这也是为什么目前主流的3D感知算法都会采用LiDAR的原因,即为什么LiDAR-based 3D Perception要远远优于Image-based 3D Perception, 因为LiDAR提供的深度信息是完全无误的。
但是,真正的原因好像不仅仅局限于此。
让我们先分析一下目前的Image-based 3D Perception方案具体是怎么做的:一种方式是通过深度估计将深度信息作为additional channel加到原始图像后;另一种方式也是以叠加的方式,加入ground, class semantic, instance semantic, shape, context, location等hand-crafted features, 见图二,以尽可能提供多方位的空间信息。那么,神经网络能够有效地从这些“无脑”叠加的多类特征图中感知到三维物体的真实属性吗?

图二:Hand-crafted Features in Mono3D
接下来,我们可以看一个实验结果,如图三。其中,左上是由原始图像 (front view)估计的深度信息,左下是对应得到的pseudo-Lidar (BEV形式),右上是原始深度图通过二维卷积得到的结果,右下是将经过2D卷积处理后的深度图像变换到三维空间的点云。我们可以看到,原图像的深度信息经过2D卷积后发生了剧烈的畸变扭曲,原始的车辆形状也发生了巨大的改变。

图三:The Result of 2D Convolution to the Frontal View Depth Map
因此,2D卷积在以front view形式的Image-based 3D Perception中并不work. 以下给出理论分析:
(1) Physically Incoherent
在2D图像中,不同深度的物体均呈现在同一个平面上,因此在卷积核的某一感受野之内,不同物体实际上是physically incoherent, 但相邻的像素点之间并没有显式表示这种关系。比如图四的bounding box中,按深度从小到大排序有手、球拍、人脸等物体,这些物体以front view的形式是连贯在一起的,而网络并不能感知到实际的physically incoherent关系。Focal Loss的提出也是为了解决类似的前景、背景不平衡的问题,但是个人认为更重要的原因是2D图像的front view表示形式,严重限制了神经网络的2D和3D Perception.

图四:Physically Incoherent Example of a 2D Image
(2) Different Scales
在front view后简单叠加depth map, 虽然能够提供重要的深度信息,但是仍然没有直观地展示真实三维空间的分布属性。除此之外,越远的物体在front view中是越小的,而检测小物体本身就是一个比较难的任务。因此,深度图中不同尺度的物体也增加了Image-based 3D Perception的难度。

图五:Different Scales Example of a Depth Map
综上,目前的Image-based 3D Perception方案较差的性能主要是由于front view这种2D图形表示,而不是之前一直纠结的不准确的depth map. 表二给出了实验论证,使用相同方法估计的depth map, 以BEV形式 (pseudo-Lidar投影得到)的3D Perception要远优于FV+depth map的形式。

表二:Comparison between FV and BEV
2. The Promising Performance of LiDAR-based 3D Perception
经过上面的分析,LiDAR-based 3D Perception的优越性便显而易见了。首先,在三维点云中(或BEV), 卷积和池化操作的区域都是physical nearby, 不同位置的不同物体并不会混为一谈;其次,物体的尺度具备深度不变性,保持了三维空间中最原始的尺度。
总之,虽然本文没有任何技术层面的创新与改进,但是重新审视了Image-based 3D Perception的致命点,能够给目前的三维感知一些重要的启示。正如作者所说的:“Sometimes, it is the simple discoveries that make the biggest differences”.
四、一些思考
- Inspiration from 3D Perception to 2D Perception
我们知道,目前几乎所有的3D Detector都是继承了2D Detector的结构以及设计思路 (除了PointNet),其改进的主要思想也都是来自2D Detector. 但是,从pseudo-Lidar对3D Detection的探讨中,我们也可以得到有益于2D Detection的启发,即主要限制复杂场景物体检测的原因是2D图像的front view表示。因此,对于这种场景,通过depth estimation-point cloud-3D detection-2D projection可能会比在FV上用focal loss更有效。
- Fusion of LiDAR and pseudo-LiDAR
这也是作者在future work中提到的,因为雷达点云虽然精确并有反射强度信息,但是非常稀疏,而且线数不同分辨率也不同。相比之下,pseudo-LiDAR虽然不是特别精确,但是比雷达点云要密集的多,且具备RGB颜色信息。因此,将两者进行融合 (互补),会是一个比较有意思的工作。这样比传统的RGB image & LiDAR point cloud fusion方式,比如MV3D, AVOD等,更加易于神经网络感知。
此外,可以尝试在pseudo-LiDAR和LiDAR之间架一个GAN,以生成更高精度的pseudo-LiDAR,使得Image-based 3D Perception性能进一步接近LiDAR-based 3D Perception,即在自动驾驶中,使相机完全代替雷达成为可能。
Mono3D

假设目标位于地面之上,以及目标的先验的大小,根绝目标的平均大小设置,根据这两个信息,稠密的生成3D物体候选框。在KITTI,车辆生成4w候选框,行人生成7w的候选框。根据最远距离和采样间隔决定的。对于每一幅图像,就可以生成稠密的3D物体候选。有了候选之后,我们将他们投影到2D图像,得到2D的候选框,2D候选框和视觉特征,根据评分,过滤到背景的候选框,以及NMS除去高度重叠的候选框,和2D视觉RPN是非常小相似的。因为2D的候选框和3D的候选框是一一对应的,我们就就知道了3D的候选框,再对3D候选框大小进行修正回归(之前是平均值)。
FCOS3D

FCOS3D是FCOS在3D的扩展,实际上FCOS3D和FOCS在网络结构非常的相似,从pipeline可以看粗,backbone和neck和FCOS是完全一样的 ,FCOS3D在多个特征图上进行了预测。FCOS3D的不同在于:


b是2D的中心,c是3D中心点在2D的投影,所以b和c是不同的。最终我们还要得到物体在3D的中心点,无论是通过图像还是其他信息,我们关心是在3D的中心点,而不是2D的bb的几何中心。
这里借助反变换,因为知道了c的深度,我们可以计算。
物体的长宽高LWH,直接在2d的图像上进行回归。
目标的朝向,理论上也应该是3D的变量,但是车辆俯仰角和左右的倾斜,在一般的应用中,值比较小,实际应用作用不大。最重要的角,就是相对于z轴的旋转,对应的车身的一个朝向,正前方,还是45度,还是90度。FOCS3D只回归这个角度。

centerness在3d和2d不同。以3D中心点在2D的投影为原点的高斯分布(上面提了),利用高斯分布,来定义centerness。alpha是高斯的参数,deltax和deltay。
FCOS3D网络结构比较常见,速度也比较快。
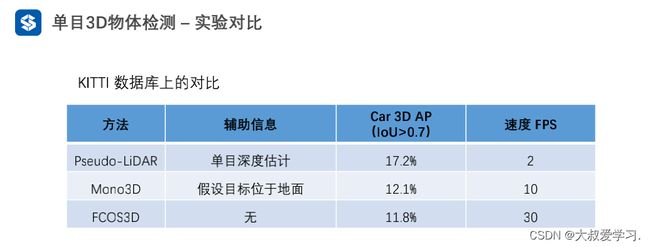
在3D的情况下IOU>0.7已经是比较苛刻的条件了。在L2纯视觉,L3和L4都有激光雷达,不需要图像来做3D的信息了。尤其是单目的。这里3D单目的物体检测,主要是以辅助。
PSMNet

双目系统不需要先验知识、几何约束、以及大量的数据。而是通过视差的概念来恢复当前目标点的深度信息。双目感知不依赖物体检测的结果,不需要知道当前物体的形状和信息,只需要知道是我们想要的目标点,两个相机都可以看到目标点。可以对场景任意一点,进行深度估计。

xl左边成像位置点,xr右边成像位置点。xl和xr的差值d就是视差。所以深度估计的关键就是估计视差。

将场景的深度估计转为视差估计。深度估计是以米为单位,视差的单位是像素。比如深度估计的范围是90-1.7m,视差的范围可能对应是1-10个像素。
可以利用深度学习对周围的区域,进行特征的提取,来帮助引入有用的特征计算视差。


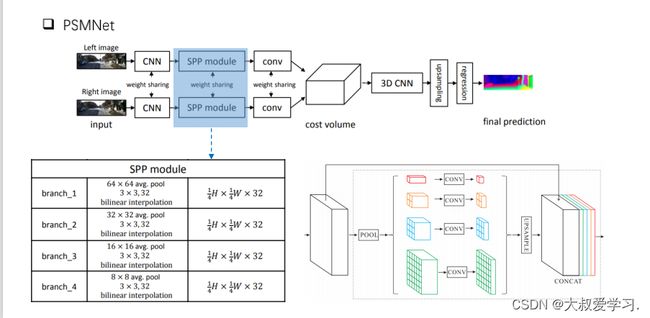
average pooling的尺寸越大,说明越是全局的特征,尺寸越小,越是局部的特征。SPP就是要找到不同层次的特征进行融合。

H‘和W’是原图像的1/4. D个可能的视差值,左侧和右侧的特征图,进行不同像素的移动。将移动后的特征图再进行拼接,多余的部分cut掉。每一个视差值得到的H‘和W’的特征图,channel是2C,原来的2倍。个数是D个。
H‘*W’D2C。


找到D中最小值,就是每个像素点的视差值,再通过视差去计算深度。


基线长度就是2个摄像头之间的距离。
