李沐动手学深度学习V2-目标检测SSD
一. 目标检测SSD(单发多框检测)
1. 介绍
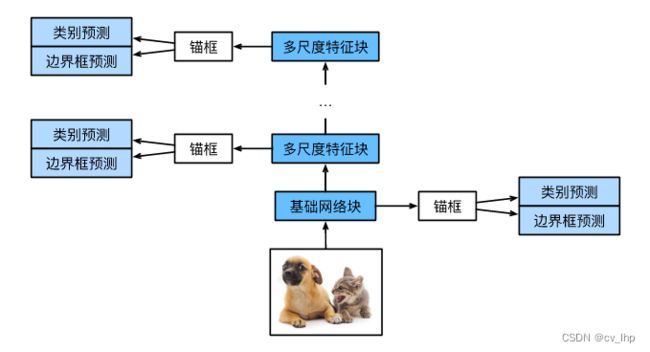
SSD模型主要由基础网络组成,其后是几个多尺度特征块。 基本网络用于从输入图像中提取特征,因此它可以使用深度卷积神经网络。 单发多框检测论文中选用了在分类层之前截断的VGG,现在也常用ResNet替代。 我们可以设计基础网络,使它输出的高和宽较大,从而基于该特征图生成的锚框数量较多,可以用来检测尺寸较小的目标,接下来的每个多尺度特征块将上一层提供的特征图的高和宽缩小(如减半),并使特征图中每个单元在输入图像上的感受野变得更广阔。由于接近顶部(输出层)的多尺度特征图较小,但具有较大的感受野,它们适合检测较少但较大的物体。 简而言之,通过多尺度特征块,单发多框检测生成不同大小的锚框,并通过预测边界框的类别和偏移量来检测大小不同的目标,因此这是一个多尺度目标检测模型,如下图所示。
2. 类别预测层
设目标类别的数量为 ,因此锚框有 +1 个类别,其中0类是背景。 在某个尺度下,设特征图的高和宽分别为 ℎ 和 ,如果以其中每个单元为中心生成 个锚框,那么需要对 ℎ 个锚框进行分类。 如果使用全连接层作为输出,很容易导致模型参数过多。由前面NIN网络介绍的使用卷积层的通道来输出类别预测的方法, 单发多框检测采用同样的方法来降低模型复杂度。
具体来说,类别预测层使用一个保持输入高和宽的卷积层,这样一来,输出和输入在特征图宽和高上的空间坐标一一对应。 考虑输出和输入同一空间坐标( 、 ):输出特征图上( 、 )坐标的通道里包含了以输入特征图( 、 )坐标为中心生成的所有锚框的类别预测,因此输出通道数为 (+1) ,其中索引为 (+1)+ ( 0≤≤ )的通道代表了索引为 的锚框有关类别索引为 的预测。
下面定义了一个类别预测层,通过参数num_anchors和num_classes分别指定了 和 ,该图层使用填充为1的 3×3 的卷积层,此卷积层的输入和输出的宽度和高度保持不变。
import torch
import d2l
from torch import nn
import d2l.torch
import torchvision
def class_predictor(num_inputs,num_anchors_per_pixel,num_class):
return nn.Conv2d(in_channels=num_inputs,out_channels=num_anchors_per_pixel*(num_class+1),kernel_size=3,padding=1)
3. 边界框预测层
边界框预测层的设计与类别预测层的设计类似,唯一不同的是,这里需要为每个锚框预测4个偏移量,而不是 +1 个类别。
def bbox_offset_predictor(num_inputs,num_anchors_per_pixel):
return nn.Conv2d(in_channels=num_inputs,out_channels=num_anchors_per_pixel*4,kernel_size=3,padding=1)
4. 连接多尺度预测
单发多框检测使用多尺度特征图来生成锚框并预测其类别和偏移量,在不同的尺度下,特征图的形状或以同一单元为中心的锚框的数量可能会有所不同,因此,不同尺度下预测输出的形状可能会有所不同。
下面为同一个小批量构建两个不同比例(Y1和Y2)的特征图,其中Y2的高度和宽度是Y1的一半。 以类别预测为例,假设Y1和Y2的每个单元分别生成了 5 个和 3 个锚框。 进一步假设目标类别的数量为 10 ,对于特征图Y1和Y2,类别预测输出中的通道数分别为 5×(10+1)=55 和 3×(10+1)=33 ,其中任一输出的形状是(批量大小,通道数,高度,宽度)。
def forward(x,block):
return block(x)
Y1 = forward(torch.zeros(size=(2,8,20,20)),class_predictor(8,5,10))
Y2 = forward(torch.zeros(size=(2,16,10,10)),class_predictor(16,3,10))
Y1.shape,Y2.shape
'''
输出结果:
(torch.Size([2, 55, 20, 20]), torch.Size([2, 33, 10, 10]))
'''
由输出结果看出,除了批量大小这一维度外,其他三个维度都具有不同的尺寸, 为了将这两个预测输出链接起来以提高计算效率,需要把这些张量转换为更一致的格式。
通道维包含中心相同的锚框的预测结果。我们首先将通道维移到最后一维。 因为不同尺度下批量大小仍保持不变,我们可以将预测结果转成二维的(批量大小,高 × 宽 × 通道数)的格式,以方便之后在维度 1 上的连结。尽管Y1和Y2在通道数、高度和宽度方面具有不同的大小,仍然可以在同一个小批量的两个不同尺度上连接这两个预测输出。
def flatten_pred(pred):
return torch.flatten(pred.permute(0,2,3,1),start_dim=1)
def concat_preds(preds):
return torch.cat([flatten_pred(pred) for pred in preds],dim=1)
concat_preds([Y1,Y2]).shape
'''
输出结果:
torch.Size([2, 25300])
'''
5. 高和宽减半块
为了在多个尺度下检测目标,定义高和宽减半块down_sample_blk(),该模块将输入特征图的高度和宽度减半。 事实上,该块应用了前面VGG模块设计。 更具体地说,每个高和宽减半块由两个填充为 1 的 3×3 的卷积层、以及步幅为 2 的 2×2 最大汇聚层组成。 填充为 1 的 3×3 卷积层不改变特征图的形状,后面的 2×2 的最大汇聚层将输入特征图的高度和宽度减少了一半。 **对于此高和宽减半块的输入和输出特征图,因为 1×2+(3−1)+(3−1)=6 ,所以输出中的每个单元在输入上都有一个 6×6 的感受野,如下图所示。**因此,高和宽减半块会扩大每个单元在其输入特征图中的感受野。

#构建的高和宽减半块会更改输入通道的数量,并将输入特征图的高度和宽度减半
def down_sample_block(in_channels,out_channels):
blk = []
for _ in range(2):
blk.append(nn.Conv2d(in_channels=in_channels,out_channels=out_channels,kernel_size=3,padding=1))
blk.append(nn.BatchNorm2d(num_features=out_channels))
blk.append(nn.ReLU())
in_channels = out_channels
blk.append(nn.MaxPool2d(kernel_size=2,stride=2))
return nn.Sequential(*blk)
Y3 = forward(torch.zeros(size=(2,10,20,20)),down_sample_block(10,50))
Y3.shape
#输出结果:torch.Size([2, 10, 10, 10])
6. 基本网络块
基本网络块用于从输入图像中抽取特征。 为了计算简洁,构造了一个小的基础网络,该网络串联3个高和宽减半块,并逐步将通道数翻倍。 给定输入图像的形状为 256×256 ,此基本网络块输出的特征图形状为 32 × 32 32 \times 32 32×32( 256 / 2 3 = 32 256/2^3=32 256/23=32)。
def base_net():
blk = []
num_filters = [3,16,32,64]
for i in range(len(num_filters)-1):
blk.append(down_sample_block(in_channels=num_filters[i],out_channels=num_filters[i+1]))
return nn.Sequential(*blk)
Y4 = forward(torch.zeros(size=(2,3,256,256)),base_net())
Y4.shape
#输出结果:torch.Size([2, 64, 32, 32])
7. 完整模型
完整的单发多框检测模型由五个模块组成,每个块生成的特征图既用于生成锚框,又用于预测这些锚框的类别和偏移量。在这五个模块中,第一个是基本网络块,第二个到第四个是高和宽减半块,最后一个模块使用全局最大池将高度和宽度都降到1,从技术上讲,第二到第五个区块都是多尺度特征块。
def get_block(i):
if i == 0:
block = base_net()
elif i ==1 :
block = down_sample_block(in_channels=64,out_channels=128)
elif i == 4:
block = nn.AdaptiveAvgPool2d(output_size=(1,1))
else:
block = down_sample_block(in_channels=128,out_channels=128)
return block
为每个块定义前向传播,与图像分类任务不同,此处的前向传播输出包括:CNN特征图Y;在当前尺度下根据Y生成的锚框;预测的这些锚框的类别和偏移量(基于Y)。
def block_forward(X,block,size,ratio,block_class_predictor,block_bbox_offset_predictor):
Y = block(X)
anchors = d2l.torch.multibox_prior(data=Y,sizes=size,ratios=ratio)
class_predictor = block_class_predictor(Y)
bbox_offset_predictor = block_bbox_offset_predictor(Y)
return (Y,anchors,class_predictor,bbox_offset_predictor)
一个较接近顶部的多尺度特征块是用于检测较大目标的,因此需要生成更大的锚框。前向传播中,在每个多尺度特征块上,通过调用的multibox_prior()函数的sizes参数传递两个比例值的列表。在下面,0.2和1.05之间的区间被均匀分成五个部分,以确定五个模块的在不同尺度下的较小值:0.2、0.37、0.54、0.71和0.88。之后,他们较大的值由 0.2 × 0.37 = 0.272 \sqrt{0.2 \times 0.37} = 0.272 0.2×0.37=0.272、 0.37 × 0.54 = 0.447 \sqrt{0.37 \times 0.54} = 0.447 0.37×0.54=0.447等给出。
sizes = [[0.2, 0.272], [0.37, 0.447], [0.54, 0.619], [0.71, 0.79],
[0.88, 0.961]]
ratios = [[1, 2, 0.5]] * 5
num_anchors_per_pixel = len(sizes[0])+len(ratios[0])-1
定义完整的模型TinySSD:
class TinySSD(nn.Module):
def __init__(self,num_classes):
super(TinySSD,self).__init__()
self.num_classes = num_classes
idx_to_in_channels = [64,128,128,128,128]
for i in range(5):
# 即赋值语句self.blk_i=get_blk(i)
setattr(self,f'block_{i}',get_block(i))
setattr(self,f'block_class_predictor_{i}',class_predictor(num_inputs=idx_to_in_channels[i],num_anchors_per_pixel=num_anchors_per_pixel,num_class=num_classes))
setattr(self,f'block_bbox_offset_predictor_{i}',bbox_offset_predictor(num_inputs=idx_to_in_channels[i],num_anchors_per_pixel=num_anchors_per_pixel))
def forward(self,X):
anchors,class_predictors,bbox_offset_predictors=[None]*5,[None]*5,[None]*5
for i in range(5):
# getattr(self,'blk_%d'%i)即访问self.blk_i
X,anchors[i],class_predictors[i],bbox_offset_predictors[i] = block_forward(X,getattr(self,f'block_{i}'),sizes[i],ratios[i],getattr(self,f'block_class_predictor_{i}'),getattr(self,f'block_bbox_offset_predictor_{i}'))
anchors = torch.cat(anchors,dim=1)
class_predictors = concat_preds(class_predictors)
class_predictors = class_predictors.reshape(class_predictors.shape[0],-1,self.num_classes+1)
bbox_offset_predictors = concat_preds(bbox_offset_predictors)
return anchors,class_predictors,bbox_offset_predictors
创建一个模型实例,然后使用它对一个 256 × 256 256 \times 256 256×256像素的小批量图像X执行前向传播:第一个模块输出特征图的形状为 32 × 32 32 \times 32 32×32,第二到第四个模块为高和宽减半块,第五个模块为全局汇聚层。由于以特征图的每个单元为中心有 4 4 4个锚框生成,因此在所有五个尺度下,每个图像总共生成 ( 3 2 2 + 1 6 2 + 8 2 + 4 2 + 1 ) × 4 = 5444 (32^2 + 16^2 + 8^2 + 4^2 + 1)\times 4 = 5444 (322+162+82+42+1)×4=5444个锚框。
net = TinySSD(num_classes=1)
X = torch.zeros(size=(32,3,256,256))
anchors,class_predictors,bbox_offset_predictors = net(X)
anchors.shape,class_predictors.shape,bbox_offset_predictors.shape
'''
输出结果:
output anchors: torch.Size([1, 5444, 4])
output class preds: torch.Size([32, 5444, 2])
output bbox preds: torch.Size([32, 21776])
'''
8. 读取数据集和初始化
batch_size = 32
train_iter,_ = d2l.torch.load_data_bananas(batch_size)
#香蕉检测数据集中,目标的类别数为1,定义好模型后,需要初始化其参数并定义优化算法。
device,net = d2l.torch.try_gpu(0),TinySSD(num_classes=1)
optim = torch.optim.SGD(params=net.parameters(),lr=0.2,weight_decay=5e-4)
9 定义损失函数和评价函数
目标检测有两种类型的损失。 第一种有关锚框类别的损失:使用之前图像分类问题里一直使用的交叉熵损失函数来计算; 第二种有关正类锚框偏移量的损失:预测偏移量是一个回归问题,使用 1 范数损失,即预测值和真实值之差的绝对值,不使用平方损失,防止预测的偏移量与真实labels的偏移量相差过大时,造成平方损失过大。 掩码变量bbox_masks令负类锚框和填充锚框不参与损失的计算,最后,将锚框类别和偏移量的损失相加,以获得模型的最终损失函数。
class_loss = nn.CrossEntropyLoss(reduction='none')
bbox_offset_loss = nn.L1Loss(reduction='none')
def calculate_loss(class_preds,class_labels,bbox_offset_preds,bbox_offset_labels,bbox_mask):
batch_sizes,num_classes = class_preds.shape[0],class_preds.shape[2]
cla_ls = class_loss(class_preds.reshape(-1,num_classes),class_labels.reshape(-1)).reshape(batch_sizes,-1).mean(dim=1)
bbox_offset_ls = bbox_offset_loss(bbox_offset_preds*bbox_mask,bbox_offset_labels*bbox_mask).mean(dim=1)
return cla_ls+bbox_offset_ls
评价函数沿用图像分类准确率评价分类函数, 由于偏移量使用了 1 范数损失,因此使用平均绝对误差来评价边界框的预测结果,这些预测结果是从生成的锚框及其预测偏移量中获得的。
def class_eval(class_preds,class_labels):
# 由于类别预测结果放在最后一维,argmax需要指定最后一维。
return float((torch.argmax(class_preds,dim=-1).type(class_labels.dtype) == class_labels).sum())
def offset_eval(bbox_offset_preds,bbox_offset_labels,bbox_mask):
return float((torch.abs((bbox_offset_labels-bbox_offset_preds)*bbox_mask)).sum())
10. 模型训练
在训练模型时,需要在模型的前向传播过程中生成多尺度锚框(anchors),并预测其类别(cls_preds)和偏移量(bbox_preds),然后根据标签信息Y为生成的锚框标记类别(cls_labels)和偏移量(bbox_labels), 最后我们根据类别和偏移量的预测和标注值分别计算损失函数,然后对类别和偏移量的损失求和。
num_epochs,timer = 20,d2l.torch.Timer()
animator = d2l.torch.Animator(xlabel='epoch',xlim=[1,num_epochs],legend=['class error','bbox mae'])
net = net.to(device)
for epoch in range(num_epochs):
# 批量类别损失和,批量样本数
# 批量偏移损失和,批量样本数
accumulator = d2l.torch.Accumulator(4)
net.train()
for X,Y in train_iter:
timer.start()
X,Y = X.to(device),Y.to(device)
optim.zero_grad()
# 生成多尺度的锚框,为每个锚框预测类别和偏移量
anchors,class_preds,bbox_offset_preds = net(X)
# 为每个锚框标注类别和偏移量
bboxes_offset_labels, bboxes_masks, bboxes_class_labels = d2l.torch.multibox_target(anchors,Y)
# 根据类别和偏移量的预测和标注值计算损失函数
loss = calculate_loss(class_preds,bboxes_class_labels,bbox_offset_preds,bboxes_offset_labels,bboxes_masks)
loss.mean().backward()
optim.step()
accumulator.add(class_eval(class_preds,bboxes_class_labels),bboxes_class_labels.numel(),offset_eval(bbox_offset_preds,bboxes_offset_labels,bboxes_masks),bboxes_offset_labels.numel())
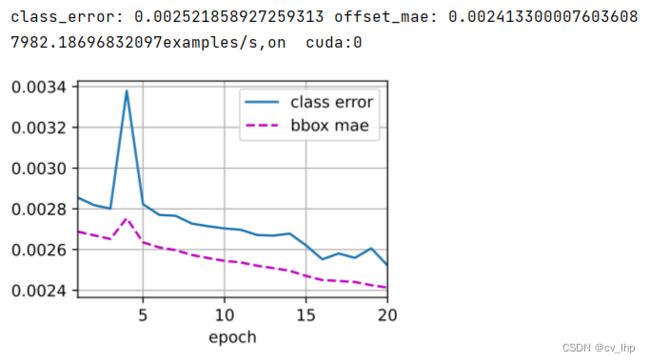
class_error,offset_mae = 1-accumulator[0]/accumulator[1],accumulator[2]/accumulator[3]
animator.add(epoch+1,[class_error,offset_mae])
print('class_error:',class_error,'offset_mae:',offset_mae)
print(f'{len(train_iter.dataset)/timer.stop()}examples/s,on ',str(device))
模型训练结果如下图所示:
11 模型预测
在预测阶段,希望能把图像里面所有我们感兴趣的目标检测出来。下面读取并调整测试图像的大小,然后将其转成卷积层需要的四维格式。
X = torchvision.io.read_image(path='../images/banana.jpg').unsqueeze(0).float()
print('x.shape1',X.shape)
transform = torchvision.transforms.Resize(size=(256,256))
X = transform(X)
img = X.squeeze(0).permute(1,2,0).long()
print('x.shape2',X.shape)
使用下面的multibox_detection()函数,可以根据锚框及其预测偏移量得到预测边界框,然后通过非极大值抑制来移除相似的预测边界框。
def predict(X):
net.eval()
anchors,cls_preds,offset_preds=net(X.to(device))
print('cls_preds.shape',cls_preds.shape)
cls_probs = torch.softmax(cls_preds,dim=2).permute(0,2,1)
output = d2l.torch.multibox_detection(cls_probs,offset_preds,anchors)
print('output==',output[0])
idx = [i for i,row in enumerate(output[0]) if row[0] != -1]
print(idx)
return output[0,idx]
output = predict(X)
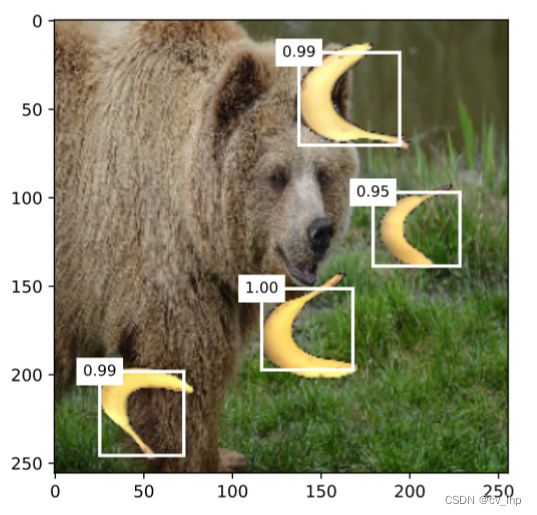
最后筛选所有预测类别置信度不低于0.9的边界框,做为最终输出。
def display(img,output,threshold):
d2l.torch.set_figsize((5,5))
fig = d2l.torch.plt.imshow(img)
for row in output:
score = float(row[1])
if score<threshold:
continue
h,w = img.shape[0:2]
box_scale = torch.tensor([w,h,w,h],device=row.device)
#print('预测框坐标:',row[2:6]*box_scale)
d2l.torch.show_bboxes(fig.axes,[row[2:6]*box_scale],'%.2f'%score,'w')
display(img,output.cpu(),0.9)
预测结果如下图所示:
11 改进
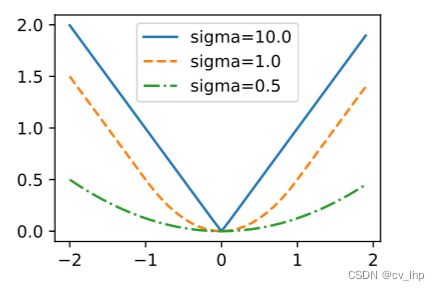
- 通过改进损失函数来改进单发多框检测,例如将预测偏移量用到的 L 1 L_1 L1范数损失替换为平滑 L 1 L_1 L1范数损失。它在零点附近使用平方函数从而更加平滑,这是通过一个超参数 σ \sigma σ来控制平滑区域的:
f ( x ) = { ( σ x ) 2 / 2 , if ∣ x ∣ < 1 / σ 2 ∣ x ∣ − 0.5 / σ 2 , otherwise f(x) = \begin{cases} (\sigma x)^2/2,& \text{if }|x| < 1/\sigma^2\\ |x|-0.5/\sigma^2,& \text{otherwise} \end{cases} f(x)={(σx)2/2,∣x∣−0.5/σ2,if ∣x∣<1/σ2otherwise
当 σ \sigma σ非常大时,这种损失类似于 L 1 L_1 L1范数损失。当它的值较小时,损失函数较平滑。
def smooth_l1(data, scalar):
out = []
for i in data:
if abs(i) < 1 / (scalar ** 2):
out.append(((scalar * i) ** 2) / 2)
else:
out.append(abs(i) - 0.5 / (scalar ** 2))
return torch.tensor(out)
sigmas = [10, 1, 0.5]
lines = ['-', '--', '-.']
x = torch.arange(-2, 2, 0.1)
d2l.torch.set_figsize()
for l, s in zip(lines, sigmas):
y = smooth_l1(x, scalar=s)
d2l.torch.plt.plot(x, y, l, label='sigma=%.1f' % s)
d2l.torch.plt.legend();
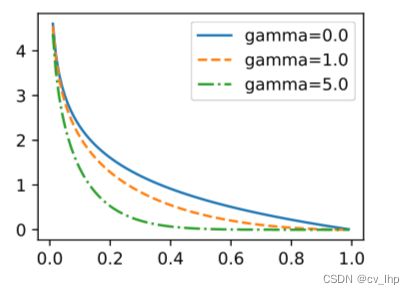
- 在类别预测时,实验中使用了交叉熵损失:设真实类别 j j j的预测概率是 p j p_j pj,交叉熵损失为 − log p j -\log p_j −logpj,还可以使用焦点损失如下所示,给定超参数 γ > 0 \gamma > 0 γ>0和 α > 0 \alpha > 0 α>0,此损失的定义为:
− α ( 1 − p j ) γ log p j . - \alpha (1-p_j)^{\gamma} \log p_j. −α(1−pj)γlogpj.
可以看到增大 γ \gamma γ可以有效地减少正类预测概率较大时(例如 p j > 0.5 p_j > 0.5 pj>0.5)的相对损失,因此训练可以更集中在那些错误分类的困难示例上。
def focal_loss(gamma, x):
return -(1 - x) ** gamma * torch.log(x)
x = torch.arange(0.01, 1, 0.01)
for l, gamma in zip(lines, [0, 1, 5]):
y = d2l.torch.plt.plot(x, focal_loss(gamma, x), l, label='gamma=%.1f' % gamma)
d2l.torch.plt.legend();
输出结果如下所示:
12 小结
- 单发多框检测是一种多尺度目标检测模型。基于基础网络块和各个多尺度特征块,单发多框检测生成不同数量和不同大小的锚框,并通过预测这些锚框的类别和偏移量检测不同大小的目标。
- 在训练单发多框检测模型时,损失函数是根据锚框的类别和偏移量的预测及标注值分别计算loss,然后求和得出的。
13. 全部代码
import torch
import d2l
from torch import nn
import d2l.torch
import torchvision
def class_predictor(num_inputs, num_anchors_per_pixel, num_class):
return nn.Conv2d(in_channels=num_inputs, out_channels=num_anchors_per_pixel * (num_class + 1), kernel_size=3,
padding=1)
def bbox_offset_predictor(num_inputs, num_anchors_per_pixel):
return nn.Conv2d(in_channels=num_inputs, out_channels=num_anchors_per_pixel * 4, kernel_size=3, padding=1)
def forward(x, block):
return block(x)
Y1 = forward(torch.zeros(size=(2, 8, 20, 20)), class_predictor(8, 5, 10))
Y2 = forward(torch.zeros(size=(2, 16, 10, 10)), class_predictor(16, 3, 10))
Y1.shape, Y2.shape
def flatten_pred(pred):
return torch.flatten(pred.permute(0, 2, 3, 1), start_dim=1)
def concat_preds(preds):
return torch.cat([flatten_pred(pred) for pred in preds], dim=1)
concat_preds([Y1, Y2]).shape
def down_sample_block(in_channels, out_channels):
blk = []
for _ in range(2):
blk.append(nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=3, padding=1))
blk.append(nn.BatchNorm2d(num_features=out_channels))
blk.append(nn.ReLU())
in_channels = out_channels
blk.append(nn.MaxPool2d(kernel_size=2, stride=2))
return nn.Sequential(*blk)
Y3 = forward(torch.zeros(size=(2, 10, 20, 20)), down_sample_block(10, 50))
Y3.shape
def base_net():
blk = []
num_filters = [3, 16, 32, 64]
for i in range(len(num_filters) - 1):
blk.append(down_sample_block(in_channels=num_filters[i], out_channels=num_filters[i + 1]))
return nn.Sequential(*blk)
Y4 = forward(torch.zeros(size=(2, 3, 256, 256)), base_net())
Y4.shape
def get_block(i):
if i == 0:
block = base_net()
elif i == 1:
block = down_sample_block(in_channels=64, out_channels=128)
elif i == 4:
block = nn.AdaptiveAvgPool2d(output_size=(1, 1))
else:
block = down_sample_block(in_channels=128, out_channels=128)
return block
def block_forward(X, block, size, ratio, block_class_predictor, block_bbox_offset_predictor):
Y = block(X)
anchors = d2l.torch.multibox_prior(data=Y, sizes=size, ratios=ratio)
class_predictor = block_class_predictor(Y)
bbox_offset_predictor = block_bbox_offset_predictor(Y)
return (Y, anchors, class_predictor, bbox_offset_predictor)
sizes = [[0.2, 0.272], [0.37, 0.447], [0.54, 0.619], [0.71, 0.79],
[0.88, 0.961]]
ratios = [[1, 2, 0.5]] * 5
num_anchors_per_pixel = len(sizes[0]) + len(ratios[0]) - 1
class TinySSD(nn.Module):
def __init__(self, num_classes):
super(TinySSD, self).__init__()
self.num_classes = num_classes
idx_to_in_channels = [64, 128, 128, 128, 128]
for i in range(5):
# 即赋值语句self.blk_i=get_blk(i)
setattr(self, f'block_{i}', get_block(i))
setattr(self, f'block_class_predictor_{i}',
class_predictor(num_inputs=idx_to_in_channels[i], num_anchors_per_pixel=num_anchors_per_pixel,
num_class=num_classes))
setattr(self, f'block_bbox_offset_predictor_{i}', bbox_offset_predictor(num_inputs=idx_to_in_channels[i],
num_anchors_per_pixel=num_anchors_per_pixel))
def forward(self, X):
anchors, class_predictors, bbox_offset_predictors = [None] * 5, [None] * 5, [None] * 5
for i in range(5):
# getattr(self,'blk_%d'%i)即访问self.blk_i
X, anchors[i], class_predictors[i], bbox_offset_predictors[i] = block_forward(X,
getattr(self, f'block_{i}'),
sizes[i], ratios[i],
getattr(self,
f'block_class_predictor_{i}'),
getattr(self,
f'block_bbox_offset_predictor_{i}'))
anchors = torch.cat(anchors, dim=1)
class_predictors = concat_preds(class_predictors)
class_predictors = class_predictors.reshape(class_predictors.shape[0], -1, self.num_classes + 1)
bbox_offset_predictors = concat_preds(bbox_offset_predictors)
return anchors, class_predictors, bbox_offset_predictors
net = TinySSD(num_classes=1)
X = torch.zeros(size=(32, 3, 256, 256))
anchors, class_predictors, bbox_offset_predictors = net(X)
anchors.shape, class_predictors.shape, bbox_offset_predictors.shape
batch_size = 32
train_iter, _ = d2l.torch.load_data_bananas(batch_size)
#香蕉检测数据集中,目标的类别数为1,定义好模型后,需要初始化其参数并定义优化算法。
device, net = d2l.torch.try_gpu(0), TinySSD(num_classes=1)
optim = torch.optim.SGD(params=net.parameters(), lr=0.2, weight_decay=5e-4)
class_loss = nn.CrossEntropyLoss(reduction='none')
bbox_offset_loss = nn.L1Loss(reduction='none')
def calculate_loss(class_preds, class_labels, bbox_offset_preds, bbox_offset_labels, bbox_mask):
batch_sizes, num_classes = class_preds.shape[0], class_preds.shape[2]
cla_ls = class_loss(class_preds.reshape(-1, num_classes), class_labels.reshape(-1)).reshape(batch_sizes, -1).mean(
dim=1)
bbox_offset_ls = bbox_offset_loss(bbox_offset_preds * bbox_mask, bbox_offset_labels * bbox_mask).mean(dim=1)
return cla_ls + bbox_offset_ls
def class_eval(class_preds, class_labels):
# 由于类别预测结果放在最后一维,argmax需要指定最后一维。
return float((torch.argmax(class_preds, dim=-1).type(class_labels.dtype) == class_labels).sum())
def offset_eval(bbox_offset_preds, bbox_offset_labels, bbox_mask):
return float((torch.abs((bbox_offset_labels - bbox_offset_preds) * bbox_mask)).sum())
num_epochs, timer = 20, d2l.torch.Timer()
animator = d2l.torch.Animator(xlabel='epoch', xlim=[1, num_epochs], legend=['class error', 'bbox mae'])
net = net.to(device)
for epoch in range(num_epochs):
# 批量类别损失和,批量样本数
# 批量偏移损失和,批量样本数
accumulator = d2l.torch.Accumulator(4)
net.train()
for X, Y in train_iter:
timer.start()
X, Y = X.to(device), Y.to(device)
optim.zero_grad()
# 生成多尺度的锚框,为每个锚框预测类别和偏移量
anchors, class_preds, bbox_offset_preds = net(X)
# 为每个锚框标注类别和偏移量
bboxes_offset_labels, bboxes_masks, bboxes_class_labels = d2l.torch.multibox_target(anchors, Y)
# 根据类别和偏移量的预测和标注值计算损失函数
loss = calculate_loss(class_preds, bboxes_class_labels, bbox_offset_preds, bboxes_offset_labels, bboxes_masks)
loss.mean().backward()
optim.step()
accumulator.add(class_eval(class_preds, bboxes_class_labels), bboxes_class_labels.numel(),
offset_eval(bbox_offset_preds, bboxes_offset_labels, bboxes_masks),
bboxes_offset_labels.numel())
class_error, offset_mae = 1 - accumulator[0] / accumulator[1], accumulator[2] / accumulator[3]
animator.add(epoch + 1, [class_error, offset_mae])
print('class_error:', class_error, 'offset_mae:', offset_mae)
print(f'{len(train_iter.dataset) / timer.stop()}examples/s,on ', str(device))
X = torchvision.io.read_image(path='../images/banana.jpg').unsqueeze(0).float()
print('x.shape1', X.shape)
transform = torchvision.transforms.Resize(size=(256, 256))
X = transform(X)
img = X.squeeze(0).permute(1, 2, 0).long()
print('x.shape2', X.shape)
def predict(X):
net.eval()
anchors, cls_preds, offset_preds = net(X.to(device))
print('cls_preds.shape', cls_preds.shape)
cls_probs = torch.softmax(cls_preds, dim=2).permute(0, 2, 1)
output = d2l.torch.multibox_detection(cls_probs, offset_preds, anchors)
print('output==', output[0])
idx = [i for i, row in enumerate(output[0]) if row[0] != -1]
print(idx)
return output[0, idx]
output = predict(X)
def display(img, output, threshold):
d2l.torch.set_figsize((5, 5))
fig = d2l.torch.plt.imshow(img)
for row in output:
score = float(row[1])
if score < threshold:
continue
h, w = img.shape[0:2]
box_scale = torch.tensor([w, h, w, h], device=row.device)
#print('预测框坐标:',row[2:6]*box_scale)
d2l.torch.show_bboxes(fig.axes, [row[2:6] * box_scale], '%.2f' % score, 'w')
display(img, output.cpu(), 0.9)
def smooth_l1(data, scalar):
out = []
for i in data:
if abs(i) < 1 / (scalar ** 2):
out.append(((scalar * i) ** 2) / 2)
else:
out.append(abs(i) - 0.5 / (scalar ** 2))
return torch.tensor(out)
sigmas = [10, 1, 0.5]
lines = ['-', '--', '-.']
x = torch.arange(-2, 2, 0.1)
d2l.torch.set_figsize()
for l, s in zip(lines, sigmas):
y = smooth_l1(x, scalar=s)
d2l.torch.plt.plot(x, y, l, label='sigma=%.1f' % s)
d2l.torch.plt.legend();
def focal_loss(gamma, x):
return -(1 - x) ** gamma * torch.log(x)
x = torch.arange(0.01, 1, 0.01)
for l, gamma in zip(lines, [0, 1, 5]):
y = d2l.torch.plt.plot(x, focal_loss(gamma, x), l, label='gamma=%.1f' % gamma)
d2l.torch.plt.legend();
14 思考
1. 思考1为什么在预测锚框的类别,预测锚框的偏移量的过程中,不需要用到锚框本身而是使用特征图?特征图怎么和锚框联系起来的,根据特征图预测类别和偏移量为什么能够表示这个根据特征图生成的锚框的类别和真实边界框?或者说特征图预测的锚框的类别,以及偏移量,在什么地方来优化锚框?,参考理解如下图问题以及回答所示:

我的理解(仅供参考):
在模型的前向传播中生成多尺度锚框,在模型训练时为生成的锚框标注类别和到真实边缘框的偏移量,然后与在前向传播过程生成的预测类别和偏移量计算损失,注意前向传播预测时并没有用到生成的锚框的信息,因为在训练阶段中将锚框的大小(类别和偏移量)传入到loss函数中,从而导致在前向传播预测时强迫卷积核(3x3的卷积核)查看它所对应感受野的区域里面查看我们需要有用的信息区域(这个信息区域只是感受野的一部分,比如这个信息区域可能包含狗,猫等物体,根据loss函数反向传播强迫卷积核查看这个信息区域,由于强迫看的信息区域不同,可能查看的信息区域有大有小,有长有宽的,因此强迫看的信息区域大小对应着象征着表示模拟这个以同一个像素为中心生成的锚框的大小。同样预测的偏移量根据loss函数中锚框标注的与真实边界框偏移量的label标签的损失,loss函数反向传播会强迫卷积核(3x3)查看它的感受野中对自己需要的部分信息区域,比如需要这个信息区域包含狗,猫等物体,然后去计算当前这个锚框的预测偏移量,由于这个预测的偏移量的不同,因此强迫卷积核查看这个感受野里面的信息区域野不同,从而体现了这个锚框的不同,由于强迫查看的这个感受野里面的信息区域,即代表象征着这个真实边界框圈住的区域,由于偏移量代表预测的真实边界框,因此偏移量计算出来的预测的真实边界框代表这个强迫看到的信息区域,而物体类别识别也是强迫看这个信息区域,因此对这个信息区域识别的物体和预测的偏移量代表的预测真实边界框就能一一对应起来。锚框的作用只是相当于给标签进行存储,相当于用来对这个识别的类别和偏移量label的一个编号,预测的类别并不是对这个锚框所在区域里面的信息进行识别,只是相当于感官模拟这个锚框而已,并不是对这个锚框所圈住的区域进行识别,因为预测识别的类别区域并不是这个锚框所在的区域,而是相当于这个预测偏移量所框住的区域。由于loss反向传播强迫卷积核识别的是这部分信息区域里面的信息,同时也强迫偏移量预测的也是这部分区域,虽然预测物体和预测偏移量是同时进行的,而不是有先后顺序进行预测,但是预测物体和预测偏移量都是针对这部分信息区域的,因此这个预测物体的值和预测偏移量(对应预测的真实边界框:结合当前编号对应的锚框大小和预测的偏移量计算出这个预测的真实边界框)是一一对应的,都是针对这部分信息区域进行预测的)。
一句话总结:loss函数反向梯度传播强迫3x3的卷积核所对应的感受野(注意:一般这个感受野是足够大了,能够包含所有锚框大小,比如:示例中第一个进行类别和偏移量预测是在经过第一个stage(经过四个卷积层和两个池化层后的base_block)后才开始预测的,因此此时卷积核看到的输入图像的感受野范围很大,包含了本示例中第一个stage使用到的锚框大小)查看里面感兴趣的信息区域,对这个信息区域预测的类别和结合loss函数传入的锚框信息从而对这个信息区域预测出来的偏移量(这个信息区域由这个偏移量结合锚框计算出来的预测的真实边界框来表示(框住),强迫查看的信息区域的大小也就象征着模拟这个以同一像素为中心的多个锚框大小。因此使用预测的偏移量结合对应锚框编号计算出来的预测真实边界框用来表示loss函数反向梯度传播强迫卷积核要查看的这个信息区域,预测识别出来的物体用来表示这个信息区域里面的物体是什么)。
2. 思考2

3. 思考3