大数据编程技术——期末复习
1、补充提纲要仔细理解,大题必考的。
2、DataFrame查询大题也要考,SQL或者DataFrame算子都行。要会常用的聚合函数sum、count、distinct、avg之类的,where条件查询,还有group查询(SQL中的group by查询,不是RDD算子中的group)
(以下标注重点的项目有可能出现在主观题中)
哥哥姐姐!!!我都这么用心为你的考试总结了大纲考点,点赞收藏加关注的你,稳过哦!这锦鲤你能不信?
一 Scala
1、Scala语言特点
- 由java开发,基于JVM运行,计算速度快(比Python快近10倍),可无缝调用Java API,完美兼容Hadoop生态组件(由java开发)
- 类型系统较复杂,语法简洁,支持函数式编程
2、Lambda演算的概念
- 函数可视为一种数据类型
- 函数的参数和返回值均可为函数类型,即函数可以参数形式传入另一个函数,也可以返回值形式作为一个函数的运算结果。
3、类(静态类和动态类)、方法和函数的声明
类
1)动态类声明:class
动态类可有多个实例/对象
2)静态类声明:object
静态类只有一个实例/对象
- 首次使用静态类时自动创建实例/对象
- 调用时用类名即可
方法和函数
1)函数和方法类似,都是可重复调用的独立语句块,方法就是对象的函数。
2)函数与方法的声明
- 使用类中的def语句定义方法
- 使用=>运算符(lambda运算符)定义函数
3)方法声明
- 多行定义
//[args]形参列表,[return type]返回值类型
def methodname([ags]):[return type]{
method body
return [expr] //[expr]表达式
}
- 单行定义
def methodName([args]):[return type] = [expr]
4)函数声明(函数声明时,参数表类型不能省略)
- 值函数(多行)定义,值参数,参数不能用推断类型,必须注明参数类型。
val funcName = ([args]) =>{ //[args]形参列表
function body
[expr] //[expr]表达式
}
val add = (x:Int,y:Int) => {//传入的参数默认是val类型常量,在函数体内部不能被修改
var temp = x+1
temp+y
}
- 值函数(单行)定义
val funcName = ([args]) => [expr] //省去函数体的大括号
val add = (x:Int) => x+3 //单参数
val add = (x:Int,y:Int) => x+y //多参数
- 参数函数
//注意:函数参数传入后,需要在函数体内执行,也可以将其返回
val add = (x:Int,y:Int => Int) => x+y(2)
//参数为多参数函数
val add=(x:Int,y:(Int,Int) => Int) => x+y(2+5)
- 匿名函数(多行)定义
([args]) =>{
function body
[expr]
}
- 匿名函数(单行)定义
([args]) => [expr] //如(x,y) => x*y
理解:用=>创建匿名函数对象,并赋值给常量(或变量)funcName
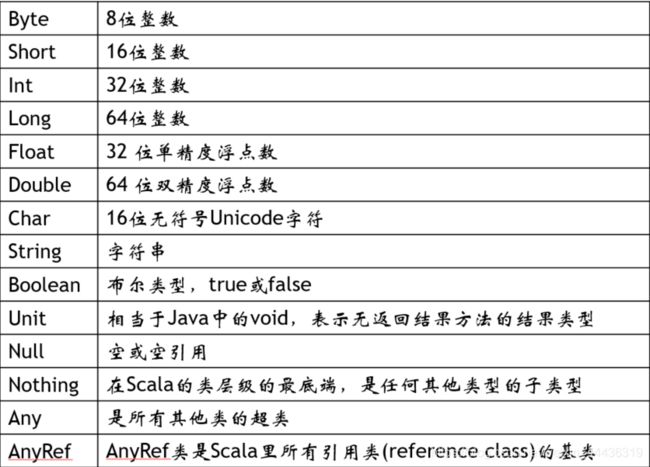
4、数据类型,Int、String、Double、Boolean、Array、List、Map、Tuple
5、常量和变量的声明
使用var声明变量
var myStr : String = "Foo"
var myInt : Int = 123
var MyVar : Float
使用val声明常量,常量声明后为只读
val myVal : String = "Foo"
使用推断类型创建变量/常量
- 声明时疏忽类型(但必须赋值), Scala根据初始值类型确定变量/常量类型
var myStr = "Foo" //使用推断类型声明变量
val myVal = 15.6 //使用推断类型声明常量
6、运算符,特别注意Lambda运算符
大致与java相同
Lambda表达式:
=> 符号又称为lambda运算符,意为创建函数对象实例。
基于Lambda运算符定义匿名函数
1)定义方法
- 多行定义
(参数表)=>{
函数体
返回值表达式
}
或(参数表)=>{函数体;返回值表达式}
- 单行定义
(参数表) => 返回值表达式
7、选择语句
if-else语句和java类似
8、for循环语句(能看懂即可)
遍历数值范围(x to y,包含y)、(x until y 不包含y)
9、Array、List、Tuple的声明和使用
1)数组Array
- 创建数组
var z:Array[String] = new Array[String](3)
var z = new Array[String](3)
var z:Array[String] = Array("Runoob","Baidu","Google")
var z = Array("Runoob","Baidu","Google")
- 访问数组
arrayName(下标值)
-合并数组
var newArray = concat(a1, a2) //将两个数组合并成一个
2)列表List
- List列表
val datas: List[String] = List()
3)元组Tuple
- 只读的属性集合,各属性数据类型可不一样;可看成是一个具备少量属性的简单对象。
- 支持的类型从Tuple1~Tuple22,其对应的属性数量也在1~22个。
val obj:Tuple2[String,Int] = Tuple2("年",2020)
10、函数与方法的区别(重点)
- 方法是对象的一部分
- 函数是一个完整的对象,可作为参数(函数类型参数)传值给任何其他的函数或方法——函数式编程的基本设定
- 函数不支持return,直接返回函数体最后一行表达式的运算结果;故函数的返回值可应用推断类型(根据最后一行表达式运算结果的类型进行推断)
11、高阶函数的lambda表达式调用方法(重点,在程序题中大量使用)
高阶函数:函数的参数或返回值类型为函数对象类型
12、容器方法:map、flatmap、filter、sortBy、groupBy、foreach、print
Scala为所有类型的序列/集合都提供了一系列Lambda风格的处理方法,涵盖了常见的序列/集合处理操作,称之为容器方法。
这些容器方法Scala均做过多线程优化。
1)foreach:遍历操作
- 只遍历操作序列中所有元素,无返回值。
var list = (0 to 9)
//四种等价写法,打印数组中所有元素
list.foreach(print(_))//1
list.foreach(x=>print(x))//2
list.foreach(item => print(item))//3
val printFunc = (x:Int) => print(x)//4
list.foreach(printFunc)
2)map:将集合中每个元素经过计算后映射到一个新集合的元素中去
3)flatMap:执行映射时,若各元素也是序列,则将各元素序列相接映射至一个新的序列中。
4)filter:遍历容器元素取出所有符合条件的元素并构成一个新的容器。
5)reduce、reduceLeft:从左至右计算,reduceRight:从右至左计算
6)fold
7)sortBy:将计算结果进行升序
var arr = Array("program","in","Spark","by","Scala")
arr.sortBy(x => x(0))//按首字母升序排列
arr.sortBy(_(0))//不建议省略参数来写,可读性差!
arr.sortBy(x => x.length).reverse //按词汇长度降序排列
8)partition
9)groupBy:按表达式结果将容器分为多个容器,相同结果的数据以键值对格式被分到map容器,键为表达式结果,值为原容器元素。
二 Spark基础
1、Spark生态环境(伯克利技术栈)
Spark生态系统被称为伯克利数据分析栈(BDAS,Berkeley Data Analytics Stack)
该技术栈亦融合了一些通用第三方平台
- Spark Core:提供Spark核心功能,实现了Spark的底层机制并提供基本数据抽象格式。
- Spark SQL:提供Spark SQL语言的解析和执行
- Spark Streaming:流式计算框架,提供了数据流的接入、抽象、计算等规范。
- MLlib:机器学习框架,常用机器学习的分布式实现。
- GraphX:分布式图计算框架,常用于图算法的分布式实现。
- Tachyon:分布式文件存储系统。

Spark环境搭建
- Spark的标准运行环境
Linux+JVM+Scala+(HadoopYARN/Mesos) - 操作系统
Redhat/Centos - 编译环境
JDK+Scala - 集群环境
第三方集群管理:Hadoop YARN或Mesos
若使用自带的集群管理器则不需要安装第三方集群管理器。
2、Spark是由什么语言开发的
Scala语言编写,spark基于scala提供了交互式的编程体验。
3、Spark支持的语言
java、Python、Scala、R(通过SparkR)
4、 Spark主从架构
1)主从架构
主节点:Master,负责管理Worker
从节点:Worker,负责与Master通信,并管理Executor和Driver进程。
注意:这里的Master和Worker不是指守护进程,在不同提交模式中,主从架构由不同的技术实现。
2)Cilent
用户客户端,提交程序或执行spark-shell命令的主机,用于在本地代理用户的操作。

5、Spark运行架构(Driver、Application、SparkSession、SparkContext、RDD、Executor、Job、Stage、Task)
- Driver
Spark的任务管理进程,执行用户提交的应用程序的main()方法,启动Application。 - Application
用户编写的Spark应用程序或启动SparkShell会创建Application,其中包含了一个SparkSession。 - SparkSession
Spark与用户的交互结构,集成了SparkContext。 - SparkContext
Application上下文,包含RDD,SparkConf和任务划分组件。 - RDD(Resilient Distributed Dataset,弹性分布式数据集,是Spark最底层的数据抽象)
Spark的基本数据结构,基于内存的分布式存储序列,分区(Partition)存储在Worker中。 - Executor
运行在Worker上,用于执行Stage中的Task。 - Job
包含了RDD的每次Action操作。 - Stage
job的基本调度单位,一个job会分为多个Stage(阶段,job在时间段上的划分),每个Stage包含多个Task,故也称为任务集。 - Task
Task是Job中每个阶段(Stage)具有执行的任务,最终以Stage为单位被分配到各Worker节点中的Executor中执行。
RDD中的每个Task操作一个Partition,最终RDD的并行度取决于RDD的Partition情况。
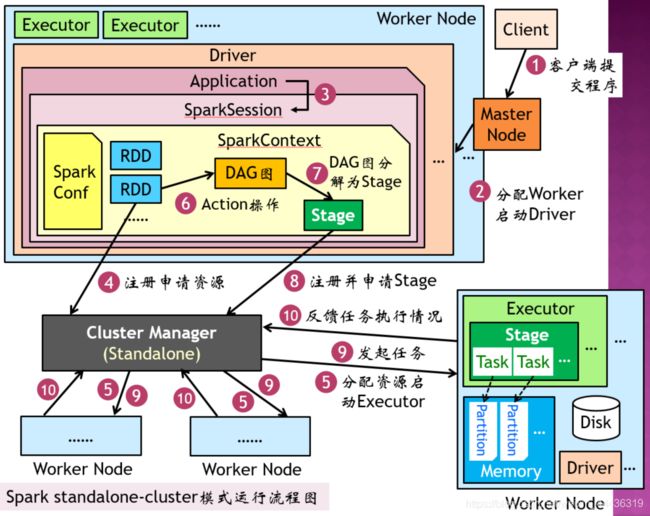
6、Spark Standalone-Cluster和Spark Standalone-Client执行流程(重点)
Spark Standalone-Cluster执行流程
1)用户操作Client向Master节点提交Spark程序
2)Master节点分配Worker启动Driver,由Worker中的Driver执行用户代码创建Application
3)执行Application时生成SparkSession保存用户与Spark的会话状态,包括SparkConf、SparkContext和SQLContext等。
4)创建RDD,向集群管理器(Cluster Manager)注册并请求RDD资源
5)Cluster Manager分配资源并在Worker上启动Executor
6)执行RDD的Action操作,解析为DAG图(有向无环图)
7)由DAG调度器将DAG图分为多个Stage及Stage中的Task
8)SparkContext向Cluster Manager提交任务申请
9)Cluster Manager分配完任务后,由SparkContext将任务发送给Worker中的Executor执行
10)Executor向Cluster Manager反馈资源使用情况,执行完毕后向其注销资源。
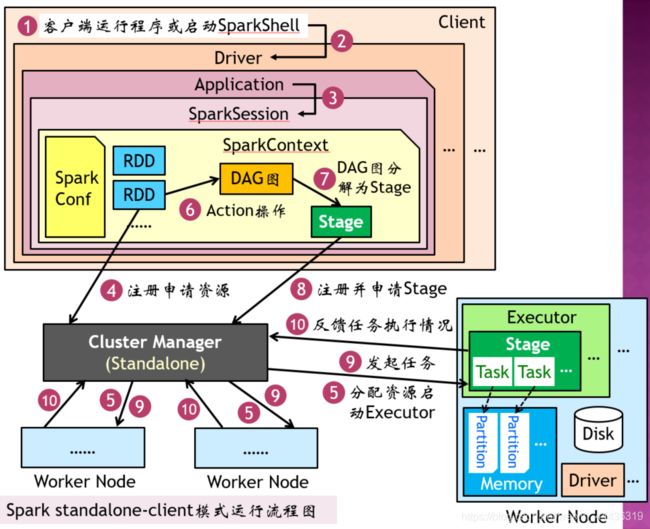
Spark Standalone-Client执行流程
1)用户在Client中执行Spark程序
2)Client启动Driver执行用户代码创建Application
3)执行Application时生成SparkSession保存用户与Spark的会话状态,包括SparkContext、SparkConf和SQLContext等。
4)创建RDD,向集群管理器(Cluster Manager)注册并请求RDD资源
5)Cluster Manager分配资源并在Worker上启动Executor
6)执行RDD的Action操作,解析为DAG图(有向无环图)
7)由DAG调度器将DAG图分为多个Stage及Stage中的Task。
8)SparkContext向Cluster Manager提交任务申请
9)Cluster Manager分配完任务后,由SparkContext将任务发送给Worker中的Executor执行。
10)Executor向Cluster Manager反馈资源使用情况,执行完毕后向其注销资源。
Spark其他模式执行流程
- local模式
- yarn-client模式
- yarn-cluster模式
- mesos-client模式或mesos-cluster模式
7、Spark提交模式
1)Local
主从架构(Worker和Master)在本地进程中实现,常用于开发测试。
在Client上安装配置Spark,不用启动Spark守护进程。
local:单线程模式,只有一个Worker线程。
local[n]:多线程模式,使用n个Worker线程。
local[*]:多线程模式,Worker线程数=CPU核心数
2)Spark on Standalone
使用Spark的Standalone提供资源调度;任务由Client提交至Spark集群,主从架构在Spark的Master和Worker守护进程中实现。
安装配置Spark集群并事先启动Spark守护进程
standalone-client:Driver运行在Client
standalone-cluster:Driver运行在Worker守护进程。

3)Spark on YARN
使用Hadoop YARN提供资源调度;任务由Client直接提交至YARN,主从架构由YARN中的ResourceManager和NodeManager实现。
须安装配置Hadoop集群并启动YARN;在Client上安装配置Spark即可,不用启动Spark守护进程。
yarn-client:Driver在Client中运行
yarn-cluster:Driver在YARN的NodeManager中运行。

Spark on Mesos
使用Mesos提供资源调度,主从架构由Mesos实现
Spark on Kurbernetes(k8s)
主从架构中的Worker和Master均运行在由k8s调度管理的Docker容器集群(PaaS云平台)中。
8、spark-shell命令及常见参数
spark-shell:以命令行的方式执行程序,系统每执行完一条命令,等待用户输入下一条命令(Scala和Python均支持命令行运行方式)
- spark-shell用master参数设定提交模式
master参数:
local:local模式
local[*](缺省):local[*]模式
local[n]:local[n]模式
spark://MasterIP:7077:standalone-client模式
yarn:yarn-client模式
1.MasterIP为Spark的Master守护进程节点IP或主机名
2.Cluster模式不支持SparkShell
9、spark-submit命令及常见参数
spark-submit:一次性运行指定程序
- 安装部署Spark后,输入spark-shell命令即启动SparkShell
1)SparkShell启动成功后,系统界面进入Shell命令行模式
2)启动Driver创建SparkSession并启动SparkContext
3)Shell可通过命令访问该SparkContext,默认变量名为sc - 将Spark程序打包为jar包后,可在client上输入命令spark-submit将jar提交至Client执行
1)程序成功提交后,Spark开始执行程序
2)启动Driver创建SparkSession,通过程序中的显式代码创建SparkContext - spark-submit用master参数设定提交模式,用deploy-mode参数(缺省为client)设定集群模式
1)local、local[*]、local[n]、Standalone-client和yarn-client模式的参数设置与spark-shell的master参数设置相同。
2)cluster模式须显式指定depoly-mode参数

常用参数:
name:应用程序的名称
class:jar包中主类包名和类名
master:设定提交模式
deploy-mode:设定集群模式
driver-memory:driver内存(缺省时默认为1G)
driver-cores:driver核心数(缺省时默认为1),YARN和Standalone模式下可用
executor-memory:executor内存(缺省时默认1G)
executor-core:各executor的核心数,YARN或Standalone模式下可用
num-executors:启动executor的数量(缺省时默认为2),YARN模式下可用
spark-shell和spark-submit的运行参数基本可通用。
以上参数在命令执行后会加载到新创建的SparkConf
也可事先配置到文件spark-env.sh中,由Spark默认加载到SparkConf
也可在Spark程序中显式写入SparkConf对象,程序执行后加载到SparkConf
5 Spark编程框架
package cn.edu.swpu.scs
import org.apache.spark.{SparkConf, SparkContext}
object App{
def main(args:Array[String]):Unit{
val conf = new SparkConf()
conf.setAppName("Test")
val sc = new SparkContext(conf)
val records = sc.textFile("~/test_file.txt")
records.filter(x => ...).map(x => ...)...
.saveAsTextFile("~/result.txt")
}
}
三 Spark Core
1、惰性计算基本概念
- RDD创建
只定义数据的读取方式并返回RDD,不会真正执行读取。 - 转换(Transformation)操作:定义计算操作返回一个新的RDD
只定义计算操作不执行计算,若连续执行转换操作,所有的操作会累积到返回的RDD中。 - 行动(Action)操作:执行RDD中所有操作并返回结果
一次性执行RDD中累积的所有数据读取、转换操作和自身操作,并返回最终结果。 - 惰性计算:一次性执行大量计算步骤,有助于调度器优化资源调度,提升计算效率和存储效率。

2、RDD数据读取(wholeTextFiles、textFile、makeRDD、parallelize)
- wholeTextFiles:按文件读取文本文件至RDD.用于多个文件的载入,将整个文件载入到RDD的一个元素,载入后的数据以键值对形式存储,文件名为key,文件内容为value,RDD中的键值对是以二元组的形式存在:(key, value)
- textFile:按行读取文本文件至RDD
//若为目录路径则加载该目录中所有文件
//file://代表本地文件协议
val rdd01 = sc.textFile("file://root/tempFiles")
val rdd02 = sc.textFile("/root/tempFiles/1.txt")
//hdfs://代表HDFS文件协议
val rdd03 = sc.textFile("hdfs://node1:9000/tmps")
- makeRDD:从内存读取数据并按最佳分区创建RDD
- parallelize:从内存读取数据并按 指定分区创建RDD
3、makeRDD和parallelize注意分区参数的意义
- parallelize方法
//使用指定数量的分片创建RDD
val rdd1 = sc.parallelize(List(1,2,3,4,5,6),2)
val rdd2 = sc.parallelize(List(1,2,3,4,5,6),3)
- makeRDD方法
//使用最佳分片创建RDD,基于parallelize方法构建
val rdd3 = sc.makeRDD(List(1,2,3,4,5,6))
val rdd4 = sc.makeRDD(List(1,2,3,4,5,6))
makeRDD可以最佳数量分区,也可以指定数量分区,parallelize只能指定数量分区
4、RDD算子(map、flatMap、groupBy、groupByKey、filter、foreach、reduce、reduceByKey、sum、count、collect、sortBy)(重点)
非Shuffle类算子:foreach、map、flatMap、filter、mapPartitions
1)元素映射类算子
- Action算子:foreach
- Transformation算子:
map:将RDD各元素依次映射到新的RDD。执行映射时可以改变元素类型、
filter:对RDD元素进行过滤操作,将符合要求(表达式结果为true)的元素映射到新的RDD、
flatMap:将RDD中的序列元素相接后映射到新的RDD、
mapValues、
union:合并两个RDD,若有重复数据不会去除
2)分区映射类算子
- Action算子:
foreachPartition(遍历每个partition,无返回值) - Transformation算子:
mapPartitions(将各parttion映射至序列,执行计算并返回),
glom(将各partition中的元素映射至对应序列)
Shuffle类算子
输入分区和输出分区不一致或会产生交叉,即宽依赖算子,有shuffle过程,shuffle数据量会影响算子效率。
元素映射类算子,对各元素执行计算
1)提取操作:提取RDD中的元素到driver或新RDD中
- Action算子:
collect(提取RDD所有元素到driver)、
take:从RDD中返回前num个元素(不排序)、
top:从RDD中先排序(降序)再返回前num个元素、
Transformation算子:
sample:对RDD按指定方式和比例随机采样、
takeSample
注意:谨慎将大量数据提取到driver,这将增加数据传输开销且增大driver负担。
2)规约操作:遍历RDD元素并迭代执行,最终将规约到一个结果
Action算子:
reduce:将RDD中的元素两两规约到一个值上、
reduceByKey:RDD元素为键值或Tuple2,将相同key中的值两两规约到一个键值对上、
fold:以初始值和一个元素开始,将元素两两规约到一个值上、
foldByKey、
3)聚合操作:将RDD元素以共同特性(key或计算结果)为key聚合到键值对序列中。
Transformation算子:
groupBy:按表达式结果进行聚合操作,将表达式结果作为key,value为元素的序列、
GroupByKey:基于PairRDD元素的key执行聚合。对键值对或Tuple2元素中的key进行聚合操作,将相同key的value合并到一个key中、
cogroup、
//将3以上和3以下的数聚合到两个键值对中
//结果类型:RDD[List((Boolean,List[Int]))]
//结果内容:Array((true,List(4,5,6)), (false,List(1,2,3)))
sc.makeRDD(1 to 6).groupBy(x => x>3)
//聚合各词汇的出现次数
//结果类型:RDD[List((String,List[Int]))]
//结果内容:List(("hello",List(2,1)), ("world",List(1)))
val rdd = sc.makeRDD(List(("hello",2),("world",1),("hello",1)))
rdd.groupByKey()
4)统计类操作:执行计数、极值、求和等操作
Action算子:
count(统计RDD中使表达式结果为true的元素数量)、
sc.makeRDD(List(1,2,2,3,1,4,2)).count//结果为7
sc.makeRDD(List(1,2,2,3,1,4,2)).count()//等价语句
countByValue:统计各元素在RDD中的个数,返回值是一个Map序列,key为值,value为该值出现次数、
sc.makeRDD(List(1,2,2,3,1,4,2)).countByValue//结果Map(4 -> 1, 1 -> 2, 3 -> 1, 2 -> 3)
countByKey:统计各元素key在RDD中的个数,返回值是一个Map序列,key为值,value为该值出现次数、
sc.makeRDD(List((3, "Gnu"), (3, "Yak"), (5, "Mouse"), (3, "Dog"))
).countByKey//结果为Map(3 -> 3, 5 -> 1)
max:返回RDD中的最大元素多元组按第一个属性返回最大元素、
val rdd=sc.makeRDD(List((3,1),(2,2),(1,3)))
//求第2元素最大的二元组,计算结果为(1,3)
rdd.reduce((x,y) => if(x._2>y._2)x else y)
min、sum、
5)排序操作:执行排序操作
Transformation算子:
sortBy、
sortByKey:按RDD中元素的key进行升序排序,若元素为元组,将元组的第一个属性作为key、
val rdd = sc.makeRDD(List(("stu1",60),("stu2",78),("stu1",70)))
rdd.sortByKey() //按学生(key)升序排列
rdd.sortByKey(false) //按学生(key)降序排列
rdd.sortBy(x => x._2) //按分数(value)升序排列
rdd.sortBy(x => x._2,false) //按分数(value)降序排列
//按学生升序排列,同一个学生按分数升序排列
rdd.sortBy(x => (x._1,x._2))
//按分数降序排列,同一个分数按学生降序排列
rdd.sortBy(x => (x._2,x._1), false)
5、RDD持久化算子(saveAsTextFile)(重点)
- rdd.saveAsTextFile:将rdd中的序列存储至文本文件,每个序列元素保存一行文本。先执行Action操作再写文件。
//存储文本文件至hdfs的/files/output目录
rdd.saveAsTextFile("hdfs://files/output")
//存储文本文件至本地目录
rdd.saveAsTextFile("/root/files/ouput")
- rdd.saveAsObjectFile:将rdd中的序列对象序列化(kryo)后存储至Object文件
//存储Object文件至hdfs的/output目录
rdd.saveAsObjectFile("hdfs:///output")
//存储Object文件至本地目录
rdd.saveAsObjectFile("/root/files/output")
6、RDD重分区算子(repartition)
reparation:对RDD进行重分区。基于随机数计算HashCode
val list=List(("a",1),("b",1),("a",5),("a",2),("a",3),("a",4))
val rdd =sc.makeRDD(list)
//基于随机数的HashCode重分区
//分区1: (a,1), (a,5), (a,3);分区2: (b,1), (a,2), (a,4)
rdd.repartition(2).glom.collect
//基于Key的HashCode重分区,相同key总是在相同分区
//分区1: (b,1);分区2: (a,1), (a,5), (a,2), (a,3), (a,4)
rdd.partitionBy(new HashPartitioner(2)).glom.collect//无法正常执行,报错找不到类型
7、两个内置分区器(HashPartitioner和RangePartitioner)
- coalesce算子:使用HashPartitioner对RDD重分区。
计算各元素的HashCode并取模后得到新分区id。基于随机数计算HashCode,相同元素不会总是分到相同分区。
方法定义:
def coalesce(numPartitions:Int,shuffle:Boolean = false)
numPartitions参数:重分区后的分区数目
shuffle:执行重分区时是否shuffle;shuffle为false时,父RDD分区只会被划分到本地分区,子RDD分区只能变得更多,设置更少的numPartitions值将不执行重分区。
SparkCore提供了两个分区器用于对RDD进行分区。
- HashPartitioner(哈希分区器)
计算RDD各元素的HashCode并取模以求得元素对应的新分区id;缺省的分区器,Spark大多API使用此方式分区(参见coalesce和reparation算子中的分区逻辑) - RangePartitioner(范围分区器)
按RDD元素或元素key的取值范围分区。
要求RDD元素或元素的key是可排序的序列。
8、搞清楚哪些是转换操作算子,哪些是行动操作算子
转换(Transformation)操作、行动(Action)操作
看算子是转换操作还是行动操作唯一的判断方法就是:看算子的返回值是RDD类型还是其他类型,如果是RDD类型就是转换算子,否则就是行动算子。
所谓的转换操作就是将一个RDD转换为另一个RDD,所以转换操作算子输入和输出都应该是RDD
在IDEA中用语法感知就能看到,最右边的就是方法的返回值
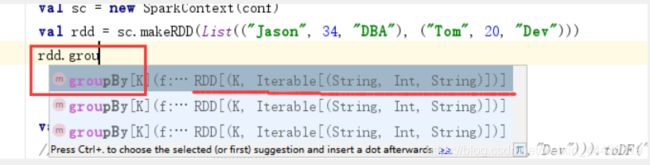
这个group算子返回值就是RDD[…],是转换操作
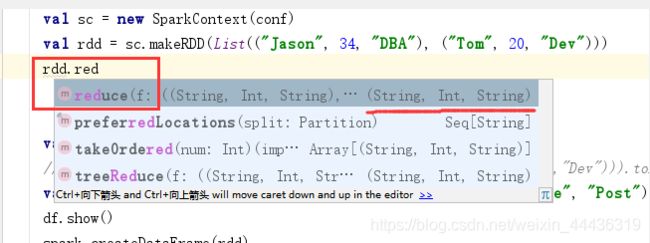
reduce算子返回值是一个元组,是行动操作

count算子返回值是long,是行动操作
9、RDD编程wordCount、统计平均数、分组统计数量(重点)
- wordCount
val rdd = sc.textFile("文章文件路径")//读取文章
rdd.flatMap(x => new JiebaSegmenter().sentenceProcess(x).toArray())//对每篇文章执行分词
.map(x => (x.toString(),1))//转化为词汇列表
.reduceByKey((x,y)=> x+y)//计算wordCount
- 计算平均数
val rdd = sc.makeRDD(1 to 100)
//将rdd元素转为二元组,属性1计算和,属性2计数
val sum =rdd.map(x =>(x,1))
//对元素执行两两累加,并规约到一个二元组上
.reduce((x,y) =>(x._1+y._1, x._2+y._2))
//计算平均数并输出
print(sum._1/sum._2)
10、写出RDD算子的输出结果,类似作业2(重点)
1.统计1~5内所有奇数的和
(1)val rdd=sc.makeRDD(1 to 5)
(2)rdd.filter(x=>x%2==1)
(3) .sum
写出各行语句生成的RDD的类型和中间结果
我的答案:
(1)类型:RDD[Int]
内容:List(1,2,3,4,5)
(2)类型:RDD[Int]
内容:List(1,3,5)
(3)类型:Double
内容:9.0
2.计算1~5内所有偶数和奇数之差
(1)val rdd=sc.makeRDD(1 to 5)
(2)rdd.groupBy(x=>x%2)
(3) .map(x=>x._2.sum)
(4) .reduce((x,y)=>x-y)
写出各行语句生成的RDD的类型和中间结果
我的答案:
(1)类型:RDD[Int]
内容:List(1,2,3,4,5)
(2)类型:RDD[(Int, List[Int])]
内容:List((0, (1,3,5)), (1, (2,4)) )
(3)类型:RDD[Int]
内容:6, 9
(4)类型:RDD[Int]
内容: -3
3.统计各学生的及格课程数
(1)val rdd=sc.makeRDD(List((“stu1”,50),(“stu1”,70),(“stu1”,67),(“stu2”,80)))
(2)rdd.filter(x=>x._2>=60)
(3) .groupBy(x=>x._1)
(4) .map(x=>(x._1,x._2.count(y=>true)))
(5) .foreach(x=>println(x._1+":"+x._2))
写出各行语句生成的RDD的类型和中间结果
我的答案:
(1)类型:RDD[(String,Int)]
内容:List("stu1",50),("stu1",70),("stu1",67),("stu2",80)
(2)类型:RDD[(String,Int)]
内容:List("stu1",70),("stu1",67),("stu2",80)
(3)类型:RDD[(String,Iterable[(String,Int)])]
内容:List( (stu1,((stu1,67))), (stu2, ((stu2,70), (stu2, 80)))
(4)类型:RDD[(String, Int)]
内容:List(stu2, 2), (stu1,1))
(5)类型:Unit
内容:
stu2:2
stu1:1
4.统计各学生的平均分:
(1)val rdd=sc.makeRDD(List((“stu1”,50),(“stu1”,70),(“stu1”,67), (“stu2”,80)))
(2)rdd.map(x=>(x._1,(x._2,1)))
(3) .reduceByKey((x,y)=>(x._1+y._1,x._2+y._2))
(4) .map(x=>(x._1,x._2._1/x._2._2))
(5) .foreach(x=>println(x._1+":"+x._2))
写出各行语句生成的RDD的类型和中间结果
我的答案:
(1)类型:RDD[(String,Int)]
内容:List(("stu1", 50), ("stu1", 70), ("stu1", 67), ("stu2", 80))
(2)RDD[(String, (Int, Int))],
内容:List((stu1, (50,1)), (stu2, (70, 1)), (stu1, (67, 1)), (stu2, (80, 1)))
(3)类型:RDD[(String, (Int, Int))]
内容:List((stu2, (150, 2)), (stu1, (117, 2)))
(4)类型RDD[(String, Int)]
内容List((stu2, 75), (stu1,58))
(5)类型:Unit
内容:
stu2:75
stu1:58
11、RDD计算优化方法(重点)
RDD计算优化不考编程,只需罗列优化方案,具体方案书上和PPT上都有
1)避免重复计算
- 缓存需要重复使用的转换操作结果。
- 计算完毕后释放缓存
- 算法设计上尽量复用RDD
2)减少RDD分区(Partition)间的数据传输(Shuffle)
- 避免使用Shuffle类算子
- Shuffle前先对各分区数据做聚合、规约、过滤等减少元素数量的操作
3)合理进行RDD分区,避免数据倾斜
- 数据倾斜:RDD中数据分布不均衡甚至相差巨大
4)提升对象序列化性能
- 使用Kryo优化序列化性能
分区优化
wordCount优化前算法
val r = List("hello","hello","world","spark","math","math","world")
val rdd = sc.makeRDD(r,2)
rdd.map(x =>(x,1)).groupByKey()
.map(x => (x._1,x._2.count(x => true))).foreach(println)
wordCount优化后的算法
val r=List("hello","hello","world","spark","math","math","world")
val rdd = sc.makeRDD(r,2)
rdd.map(x=>(x,1))
.mapPartitions(x => x.toList.groupBy(_._1)
.map(y => (y._1,y._2.count(z => true)))
.toIterator)
.reduceByKey(_+_).foreach(println)
//.groupByKey().map(x => (x._1, x._2.sum)).foreach(println)//与reduceByKey语句执行效果相同
1.5 ObjectFile
基于SequenceFile封装的对象文件格式,用于存放RDD对象数据。
方法调用
//读取保存了RDD[Int]对象的ObjectFile
val rdd = sc.objectFile[Int]("文件路径")
//读取保存了RDD[(String,Int)]对象的ObjectFile
val rdd =sc.objectFile[(String,Int)]("文件路径")
对象类型不匹配会报异常!
四 Spark SQL
1、DataFrame转换操作算子(select、selectExpr、where/filter、distinct、groupBy、sort)或等价的SQL语句 (重点)
- DataFrame:基于RDD[Row]构建,以面向列的方式存储表格数据,包含了表格的元数据Schema,且DataFrame与RDD[Row]可相互转换。
- Schema:DataFrame中的数据结构信息,包含:列名、列数据类型、列注释、是否可为空等。
- DataFrame转换操作:将一个DataFrame转换成另一个DataFrame,该操作只进行DataFrame转换,不会触发计算,由后序的Action操作触发计算(惰性计算,通RDD)
转化操作——select
- DataFrame查询
select(“列名”,…)
val conf = new SparkConf()
conf.setAppName("Test")
val sc = new SparkContext(conf)
val saprk = SparkSession.active
val score = sc.makeRDD(List(("s1",60),("s2",80),("s3",75)))
val df = spark.createDataFrame(score).toDF("name","score")
//查询name列数据,并打印。
df.select("name").show
//查询name列和score列数据
df.select("name","score").show
//查询df中所有列数据
df.select("*").show
转化操作——selectExpr
- DataFrame复杂查询
selectExpr(“表达式”,…)
val spark = SparkSession.active
val score = sc.makeRDD(List(("s1",60),("s2",80),("s3",75)))
val df = spark.createDataFrame(score).toDF("name","score")
//使用聚合函数查询总行数、平均分数和总分数
df.selectExpr("count(name)","avg(score)","sum(score)").show
//去除重复查询的所有姓名
df.selectExpr("distinct(name)").show
df.select("name").distinct.show //两句的结果一样,等价。
//查询所有姓名的首字母,并将结果列命名为first。
df.selectExpr("substring(name,0,1) as first").show
//查询所有姓名和成绩并将分数成绩转为及格和不及格.
df.selectExpr("name","if(score>60,'及格','不及格') as grade").show
只要是SQL语句中支持的聚合函数在selectExpr中都可用
转换操作——列新增
- 添加列
withColumn
//添加列newCol1填充常量1
df.withColumn("newCol1",lit(1))
//添加列newCol2填充布尔值,score>60为true,否则为false
df.withColumn("newCol2",expr("score>60"))
//将score列复制为newCol3列
df.withColumn("newCol3",col("score"))
//将score列复制为newCol4列,并加1
df.withColumn("newCol4",col("score")+1)
//将score列复制为newCol列,并将数据类型转换为字符串型
df.withColumn("newCol",col("score").cast("string"))
只要是SQL语句中支持的聚合函数在withColumn中都可用
- 删除列
drop(“列名”,…)
//删除name列
df.drop("name")
//删除name列和newCol列
df.drop("name","newCol")
- 重命名列
withColumnRenamed
//将列newCol重命名为year
df.withColumnRenamed("newCol","year")
转换操作——行过滤
- 过滤掉不符合条件的行,通过设定表达式,仅返回表达式结果为true的行;相当于SQL中的where
where/filter(两个方法通用)
//返回score大于60的行
df.where(col("score")>60)
.show//打印
//返回score大于等于80且小于90的行
df.where(col("score")>=80).where(col("score")<90)
.show//打印
df.where(sol("score")>=80 && col("score")<90)
.show//打印
//返回score小于60或为null(无成绩)的行
df.where(col("score")<60 || col("score") == null)
//查询无成绩的学生姓名,去重并返回,代码有误!
df.select("name").where(col("score")== "").distinct
转换操作——追加行
- 合并(union)两个相同Schema的DataFrame,相当于向DataFrame中追加行
DataFrame.Union(DataFrame)
val spark = SparkSession.active
//创建df
val score = sc.makeRDD(List(("s1",60),("s2",80),("s3",75)))
val df = spark.createDataFrame(score).toDF("name","score")
//创建df2
val score2 = sc.makeRDD(List(("s4",80),("s5",70),("s5",90)))
val df2 = spark.createDataFrame(score).toDF("name","score")
//将df2合并至df1(相当于向df追加行)
df.union(df2).show
转换操作——行排序
- 对DataFrame中的值进行排序
sort/orderBy(两个方法通用)
//以score进行升序排序
df.sort("score")
//以score进行一次升序排序,再以name进行二次升序排序
df.orderBy("score","name")
df.orderBy(asc("score"),asc("name"))
//以score进行一次降序排序,再以name进行二次升序排序
df.orderBy(desc("score"),asc("name"))
- 截取DataFrame中的值
limity提取前n条记录
//返回前10名成绩
df.select("name","score").sort(desc("score")).limit(10)
转换操作——分组操作
- 分组操作通SQL中的GroupBy
groupBy
RelationalGroupedDataset对象支持统计方法,对各分组进行统计操作,并将结果以DataFrame返回。
max min mean sum count
//按name列进行分组并转为RelationalGroupedDataset对象
val groups = df.groupBy("name")
//返回所有数字类型列在各分组的最大值
groups.max()
//返回score列赫尔age列各分组的平均值(各分组的平均分和平均年龄)
groups.mean("score","age")
//返回各分组的数量,此方法不支持参数
groups.count()
2、DataFrame行动操作算子(show、printSchema)
* 编程题中,用转换算子查询或SQL语句的执行查询均可
show方法:以表格方式打印DataFrame中的数据和列名(数据超过20条时,只打印前20条)

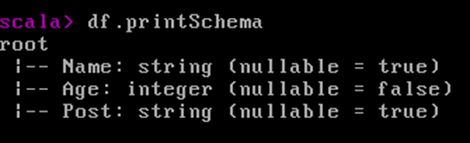
printSchema方法:以树形目录打印DataFrame的Schema
行的操作——列信息
- 获取指定列描述信息
describe(“列名”,…)
3、DataFrame中的SQL查询
-SQL查询例
val spark = SparkSession.active
val score = sc.makeRDD(List(("s1",50),("s2",80),("s3",75)))
val df = spark.createDataFrame(score).toDF("name","score")
//1.使用df方法查询
df.selectExpr("avg(score)","sum(score)").show
//2.使用SQL查询(与1等效)
df.createTempView("Stu")
df.sqlContext.sql("select avg(score),sum(score) from Stu").show
//3、使用df方法查询(以下三行代码等效)
df.select("score").where("score>60").show
df.select("score").where(expr("score>60")).show
df.where(col("score")>60).select("score").show
//4.使用SQL查询(与3等效)
df.sqlContext.sql("select score from Stu where score>60").show
行动操作——提取操作
schema:返回Schema对象(StructType对象)
columns:返回DataFrame列名数组Array[String]
collect:内存序列Array[Row]提取DataFrame多有数据至Driver
- first:提取第一行记录的Row对象至Driver
- head/take:提取前n条记录并以Array[Row]的方式至Driver
//以对象Row提取第1条记录(与first相同)
df.head
//以对象Array[Row]提取第1条记录
df.head(1)
df.take(1)
//以对象Array[Row]提取前十条记录
df.head(10)
df.take(10)
- takeAsList:提取前n条记录并以List[Row]的方式至Driver
df.takeAsList(10)
行动操纵——持久化
执行DataFrame计算并按要求输出到文件,属于Action操作。

五 Spark Streaming
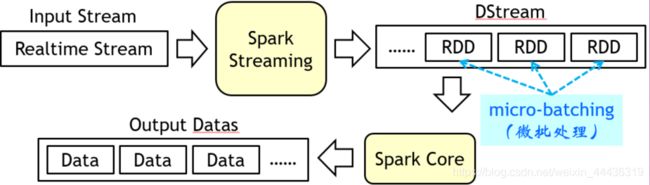
1、微批处理逻辑和DStream概念
微批处理(macro-batching)
间隔一定时间(如1秒钟)将输入流的数据组成微小批次,分批次处理数据。
有一定延迟
Spark Stream将输入数据流按时间切分为小批次,将每个批次的数据封装为RDD交由Spark Core处理,支持所有RDD算子。
- 原生流(naive stream)
输入流的数据到达即处理
低延迟

Dstream(Discretized Stream,离散化数据流)
StreamingContext会根据设置的批处理的时间间隔将产生的rdd归为一批,这一批rdd就是一个DStream,DStream可以通过算子操作转化为另一个DStream
概念参考博文
接收器接收的流数据被划分为微批量数据(RDD)后抽象为Dstream;对批量数据的所有操作都定义在Dstream中。
Spark Streaming中的数据流抽象,其中包含了若干RDD(微批量数据)。
对Dstream的操作包含:转换操作和行动操作;
Dstream中定义的所有操作会被应用到源源不断的RDD中。

2、DStream转换操作算子(map、flatMap),使用算子做简单计算 (重点)
无状态转换操作:每个批次(RDD)的处理只局限于当前批次的数据。
无状态转换操作算子
1)map
将一个Dstream元素映射到新的Dstream中,映射过程可改变Dstream类型。
//创建batch间隔(duration)为1秒的Dstream
val scc = new StreamingContext(sc, Seconds(1))
//读取文本文件至Dstream
val ds=ssc.textFileStream("文件路径")
//ds类型:DStream[String]
//ds数据:List("1","2","3","4","5")
//ds1类型:DStream[Int],DStream[Int]中的RDD为RDD[Int]
//ds1数据:List(1,2,3,4,5)
val ds1=ds.map(x => Integer.parseInt(x))
2)flatmap
将一个DStream元素扁平化映射到新的DStream中,映射过程中可改变DStream类型
val ssc = new StreamingContext(sc,Seconds(1))
val ds = ssc.textFileStream("文件路径")
//ds类型:DStream[String]
//ds数据:List("Hello World", "Spark Scala", "Spark")
//ds1类型:DStream[String],DStream[String]中的RDD为RDD[String]
//ds1数据:List("Hello", "World", "Spark", "Scala", "Spark")
val ds1 = ds.flatMap(x => x.split(" "))
3)filter
过滤DStream中所有元素,不可改变DStream类型。
注意该算子中判断条件为真才留下,为假的就会被过滤掉!
val ssc = new StreamingContext(sc,Seconds(1))
val ds = ssc.textFileStream("文件路径")
//ds类型:DStream[String]
//ds数据:List("Hello World", "Spark Scala", "Spark")
//ds1类型:DStream[String]
//ds1数据:List("Spark", "Scala", "Spark")
val ds1 = ds.flatMap(x => x.split(" ")).filter(x => x(0) == 'S')
4)reduce
对DStream中的每个RDD指定reduce聚合到一个类型为T的值中,并装入DStream[T]中
val ssc = new StreamingContext(sc, Seconds(1))
val ds = ssc.receiverStream(myReceiver)
//ds类型:DStream[Int]
//ds数据:List(1, 2, 3, 4, 5, 6, 7, 8, 9)
//ds1类型:DStream[Int]
//ds1数据:List(55)
val ds1 = ds.reduce((x,y) => x+y)
- count
统计DStream中各RDD元素数量,返回DStream[Long]
val ssc = new StreamingContext(sc,Seconds(1))
val ds = textFileStream("文件路径")
//ds类型:DStream[String]
//ds数据:List("Hello World", "Spark Scala", "Spark")
//ds1类型:DStream[Long]
//ds1数据:List(5)
val ds1 = ds.flatMap(s => x.split(" ")).count
- countByValue
统计DStream[T]中各RDD元素在本RDD的出现次数,
返回PairDStream[(T, Long)](key为元素,value为次数)
val ssc = new StreamingContext(sc,Seconds(1))
val ds = ssc.textFileStream("文件路径")
//ds类型:DStream[String]
//ds数据:List("Hello World", "Spark Scala", "Spark")
//ds1类型:DStream[(String, Int)]
//ds1数据:List(("Hello", 1), ("World", 1), ("Spark", 2), ("Scala", 1))
val ds1 = ds.flatMap(x => x.split(" ")).countByValue
7) reduceByKey
对PairDStream中的RDD使用reduceByKey聚合为一个类型为T的值,并装入DStream[T]中
val ssc = new StreamingContext(sc, Seconds(1))
val ds = ssc.textFileStream("文件路径")
//ds类型:DStream[String]
//ds数据:List("Hello World", "Spark Scala", "Spark")
//ds1类型:DStream[(String, Int)]
//ds1数据:List(("Hello", 1), ("World", 1), ("Spark", 2), ("Scala", 1))
val ds1 = ds.flatMap(x => x.split(" "))
.map(x => (x,1))
.reduceByKey
- join
将两个PairDStream中的RDD使用join合并为一个RDD,并装入新的DStream中
val ssc = new StreamingContext(sc, Seconds(1))
val ds1 = ssc.receiverStream(myReceiver1)
val ds2 = ssc.receiverStream(myReveiver2)
//ds1类型:DStream[(String, Int)]
//ds1数据:List(("stu1", 80), ("stu2", 70), ("stu3", 75))
//ds2类型:DStream[(String, String)]
//ds2数据:List(("stu1", "F"), ("stu2", "M"), ("stu3", "F"))
//ds3类型:DStream[(String, (Int, String))]
//ds3数据:List(("stu1", (80, "F")), ("stu2", (70, "M")), ("stu3", (75, "F")))
val ds3 = ds1.join(ds2)
9)reparation
10) union
有状态转换操作
基于滑动窗口(window)的操作:可一次性处理一个窗口中的数据,一个窗口中包含了多个批次。
- 滑动窗口转换操作
将Stream数据按1个时间间隔(duration)提取batch数据,装入RDD(RDD,duration和batch一一对应)
windowDuration(窗口时间长度):每次对多少个时间间隔(duration)的数据执行转换操作
slideDuration(滑动时间长度):间隔多少个时间间隔(duration)执行一次转换操作 - Window算子
将源DStream按指定参数设置为窗口化的DStream
方法定义
window(windowDuration, slideDuration)
windowDuration和slideDuration须为duration的整数倍
//创建batch间隔(duration)为1秒的DStream
val ssc = new StreamingContext(sc, Seconds(1))
//读取文本文件至DStream
val ds = ssc.textFileStream("文件路径")
//将ssc设置为窗口长度为3秒,每次移动为1秒
.window(second(3),second(1))
- countByWindow算子
将源DStream按指定参数的窗口统计每个窗口中元素的数量
方法定义:
countByWindow(windowDuration,slideDuration)
所有计算将被映射到同窗口内的所有RDD中,相当于将同窗口内的RDD合并后再执行count
reduceByWindow算子
将源DStream按指定参数的窗口计算Reduce聚合操作。
方法定义
reduceByWindow(reduceFunc,windowDuration,slideDuration)
redeuceFunc参数为聚合函数
所有计算将被映射到同窗口内的所有RDD中,相当于将同窗口内的RDD合并后再执行reduce。
- 基于状态(state)更新的操作
可将前面批次的运算结果(状态)保存下来,供后续批次访问和更新。
state翻译为状态,实指在程序运行过程中:
1)描述某个实体情况的数据(如:用户状态、时间、token等)
2)程序运行情况的数据(如:中间结果数据,过程数据)
3、使用foreachRDD算子保存DStream数据,参考实验5代码 (重点)
输出至文件
将DStrea中的数据存储至文件
一个batch即一个RDD,一个RDD中的partition对应存储一个文件
常见的存储格式文本文件和Object文件
saveAsTextFiles(prefix,suffix)
saveAsObjectFiles(prefix,suffix)
输出到其他外部系统
- foreachRDD
DStream的foreachRDD用于遍历所有RDD;遍历速度与数据批次的处理速度一致,计算一批数据,这里就遍历到一批数据。
在foreachRDD中可允许调用访问其他外部系统,如:关系数据库、NoSQL数据库、REST API等。
计算完毕后的DStream数据可在这里遍历后传入其他外部系统。
foreachRDD保存策略
一般先遍历DStream中的RDD,然后用foreachPartition算子遍历RDD的partition,再在partition中执行保存。

实验五部分代码
//遍历DStream的所有RDD
lines.foreachRDD(x => {
if(x.count() > 0) {
//使用RDD的saveAsTextFile存储RDD数据,存储目录以时间戳命名
x.saveAsTextFile("hdfs://node1:9000/rdds/rec" + new Date().getTime.toString)
}
})
//存储计算后的流数据
ds.foreachRDD(x => {
if(x.count() > 0) {
//使用RDD的saveAsTextFile存储RDD数据,存储目录以时间戳命名
x.saveAsTextFile("hdfs://node1:9000/result/rec" + new Date().getTime.toString)
}
})
3.1 输入源
- 文本文件源:Receiver每隔一定时间检查一次目录中的新增文件,将新增文件读入DStream的RDD中。
方法定义
StreamingContext.textFileStream("文件目录")
- socket文件源:Receiver向TCP Socket服务器发起连接请求,每隔一定时间接收一次数据。
方法定义
StreamingContext.socketTextStream("IP地址",port)
receiverStream:使用自定义receiver接收流数据,需继承Receiver类创建自定义Recerver
方法定义
receiverStream(myReceiver)
3.3Spark Streaming编程步骤
val sc = new SparkContext(new SparkConf())
//创建StreamingContext,按1秒为间隔将输入流拆分成微批(RDD)
//间隔时间最少1秒,无法实现毫秒级响应
val ssc = new StreamingContext(sc, Seconds(1))
//检查点,spark streaming故障恢复用,最好是稳定性好的HDFS
ssc.checkpoint("hdfs:///checkpoint")
//Receiver每隔1秒(StreamContext中定义)读取目录中的新增文件
//将新增文件按行读取到文件流中,并返回为DStream[String]
//DStream[String]中的RDD为RDD[String]
val ds = ssc.textFileStream("file:///root/newtexts/")
//转换操作,将DStream[String]扁平化映射到新的DStream[String]
//该操作会应用到DStream所有的RDD中
ds.flatMap(x => x.split(" "))
//将DStream输出至文本文件,文件名前缀为words,后缀为txt
//每个RDD中的各Partition对应一个文件
//参数1为prefix(目录前缀),参数2为suffix(目录名后缀)
.saveAsTextFiles("file:///root/words/w","")
//每次执行微批操作时打印运行信息
ds.print
//开始执行
ssc.start
//支持运行,直到人为干预再停止
ssc.awaitTermination
//参数1:停止SparkContext,停止2:是否优雅的停止
ssc.stop(false, true)
六 Spark MLlib
1、什么是MLlib?
MLlib是Spark高级数据分析工具包。它提供各种API接口用于收集和清理数据、特征工程、特征选择、训练和微调大型机器学习模型。
2、MLlib包含了一些什么类型的算法?
mllib包内的算法:

图片来源
分类(分类器Classification)
目前MLlib支持10多种分类器算法。
- 逻辑回归分类器(Logistic regression)
二项式逻辑回归(Binomial logistic regression)
多项式逻辑回归(Multinomial logistic regression) - 决策树分类器(Decision tree classifier)
- 随机森林分类器(Random forest classifier)
- 梯度提升树分类器(Gradient-boosted tree)
- 多层感知机(Multilayer perceptron classifier)
MLPC:多层神经网络中的一种,MLlib中采用BP算法。 - 线性支持向量机(Linear Support Vector Machine)
SVM,一种二分类器,利用维度提升实现在复杂数据中的线性分类。 - 二分类扩展到多分类(One-vs-Rest classifier)
一个基于二分类模型的多分类机器学习模型。利用二分类模型如SVM或逻辑回归循环分类,以最终解决多分类问题。 - 朴素贝叶斯分类器(Naive Bayes)
一种基于概率的二分类器 - 因子分解机分类器(Factorization Machine)
FM,一种基于矩阵分解的有监督学习算法,可用于超稀疏的矩阵计算,在海量超稀疏矩阵的分类算法中,效果比传统分类器好。
回归(回归算法Regression)
目前MLlib支持8种回归算法。
- 线性回归
- 广义线性回归(Generalized linear regression)
是线性回归的扩展模型 - 决策树回归(Decision tree regression)
- 随机森林回归(Random forest regression)
- 梯度提升树回归(Gradient-boosted tree regression)
- 生存分析(Survival regression)
- 利用统计生存模型对特定事件或发生事件的时间进行预测。
- 保序回归(Isotonic regression)
根据数据的增长现象进行回归预测,计算在何种模型下,能够得到增长的数据;如:每年投入多少广告和研发经费可以使得产品营收实现正增长 - 因式分解机回归(Factorization machine regression)
聚类
评估
特征工程(特征提取、特征转换、特征选择)
特征提取(Feature Extractors)
从一些杂乱的、非特征化的数据中抽取特征数据。
- TF-IDF:从文章词汇数据中计算TF-IDF值,广泛用于搜索引擎和NPL等领域。
- word2Vec(Word to Vector):Goole的一个开源算法,用于将词汇转换为实数值向量特征,且考虑到每个词汇的上下文环境,可用于NPL。
- CountVectorizer:对各文档的词汇进行计数并转为文档词频向量,向量中包含了每个文档中每个词汇的出现次数,是一个稀疏向量,可替代字典用于词频提取,或传递给LDA算法。
特征转换(Feature Transformers)
- Tokenizer:将字符串(如句子)划分为更小的子项(如词汇),可按空格划分,也可按正则表达式。
中文句子词汇划分,更适合用中文分词器。 - StopWordsRemover:停用词去除,指定停用词并去除。
中文词汇可直接使用中文分词器的停用词去除功能。 - n-gram:又称n元模型,是一种基于统计语言模型的算法,对文档中的文本按固定字节长度(字数)为窗口(window/mask)进行频度统计,形成一个描述性文档的特征向量空间;广泛应用在NPL领域,用于文档评估、文档查重等。
- Binarizer:设定一个阀值,对特征进行二值化处理。二值化结果为0.0或1.0
- PCA:主成分分析(Principal Component Analysis),找出一组特征值中的相关特征并进行合并,是数据特征转换、降维的常用方法。
- PolynomialExpansion:多项式扩展,将原有向量空间映射到更高纬度的空间中,用于回归模型中,可使模型的拟合特性更好。
- DCT:离散余弦变换(Discrete Cosine Transform),主要用于离散信号处理(一维信号如音频信号,压力变换和温度变换信号,二维信号如图像信号和视频信号等。);将信号的空间域表达转换到频率域上。类似的算法有傅里叶变换(DFT)和小波变换(DWT)等
- StringIndexer:将各行的字符串按distinct后的下标编码。
- OneHotEncoder:独热编码(或一位有效码)在有监督学习分类算法中对标签进行编码,将分类看成是状态,一个状态用一位二进制数表达,每个分类下只有一个状态待激活(1),其他都是非激活(0)。
- Interaction:笛卡尔特征交互,输入两个特征向量,将两个特征向量的多有可能组合的乘积组成一个新的特征向量。
- Normalizer:正则化,使每一个行向量的范数(norm)变换为一个单位范数。
- StandardScaler:数据标准化(或中心化),将每一列的数据标准化为单位标准差或0均值,使得数据符合正态分布;消除各特征之间的差异性,提升算法收敛速度。
- MinMaxScaler:归一化,将每一列的数据线性的映射到[0,1]空间中去。
关联规则
优化
推荐算法
- 协同过滤Collaboration Filtering
利用用户的行为推荐商品,使用基于统计的机器学习来实现较好的推荐效果。
统计

- ml包内的算法:组件、分类、优化、回归、调优、
说明:名为ml包内算法,实则并非ml包与mllib包区别十分明显,部分甚至多数ml包内算法已经在mllib包算法内提到并叙述。ml包内算法仅为对算法提供一个基于DataFrame类型的补充说明,已解释过的算法不再赘述。
参考博文
3、MLib各组件基本作用(转换器、估计器、评估器、流水线)(不用考虑编码)
转换器(transformer):定义了原始数据的数据转换,用于预处理和特征工程
估计器(estimater):用于训练模型
评估器(evaluater):用于估计模型
流水线(pipeline):用于定义数据分析的过程步骤,其中包含了上述组件。
补充:
*wordCount
val words = sc.makeRDD(List(“a”, “b”, “d”, “a”, “d”))
方法1:words.map(x => (x, 1)).reduceByKey((x, y) => x + y)
方法2:words.map(x => (x, 1)).groupByKey.map(x => (x._1, x._2.sum))
方法3:words.groupBy(x => x).map(x => (x._1, x._2.count))
*统计平均数
见PPT第3章6.6 规约操作例题
*分组统计数量
val rdd = sc.makeRDD(List((“stu1”,“高数”, 60),(“stu2”, “高数”, 80),(“stu2”, “英语”, 80),(“stu1”, “C语言”, 70)))
统计各学生的总分
方法1:rdd.map(x => (x._1, x._3)).reduceByKey((x, y) => x + y)
方法2:rdd.map(x => (x._1, x._3)).groupByKey.map(x => (x._1, x._2.sum))
统计各门课的参考人数(与WordCount类似)
方法1:rdd.map(x => (x._2, 1)).reduceByKey((x, y) => x + y)
方法2:rdd.map(x => (x._2, 1)).groupByKey.map(x => (x._1, x._2.sum))
方法3:rdd.map(x => x._2).groupBy(x => x).map(x => (x._1, x._2.count))