论文笔记: FSA-Net
论文笔记: FSA-Net:Learning Fine-Grained Structure Aggregation for Head Pose Estimation from a Single Image
简介
这篇工作目前看下来,给我的总体感觉就是hopenet的后续版,introduction和related work和hopenet论文里写的差不多。但由于改进了网络的结构,
原文《FSA-NET》。
原代码 https://github.com/shamangary/FSA-Net。
Attention机制
由于自己一开始做头部姿态的初衷就是出于人类注意力分析的工程目的,而且attention detection这一头部姿态的目的也在前面的introduction中出现过,因此在文中看到Attention下意识以为指的是头部姿态,细读才发现attention是作为一个CV的学术名词出现的。
由于自己读过的论文太少,Attention这个概念还是我第一次读到。
大体来说,是为了实现提取有用信息,除去无用信息的目的,类似于机器学习中的主成分分析。
叫做attention机制,正是因为它的思想就是模拟了人类注意力的生物特性。
注意力机制是人类视觉所特有的大脑信号处理机制。人类眼睛快速扫描全局图像的同时,会下意识地获得需要重点关注的目标区域,而后对这一区域投入更多注意力资源,以获取更多所需要关注目标的细节信息,而抑制其他无用信息。
因此当用神经网络来处理大量的输入信息时,也可以借鉴人脑的注意力机制,只选择一些关键的信息输入进行处理,来提高神经网络的效率。实际上这种方法在深度学习中也经常会使用,比如池化、卷积的局部连接,我觉得也算是一定程度上在实现注意力机制。
SSR-NET的结构
SSR本身指的是Soft Stagewise regression。SSR-NET是原文的作者在过去做的工作[2],做的是年龄估算的工作。受到DEX[3]的启发,SSR-NET把回归问题也把年龄估算看作是一个分类问题来处理。DEX是将一个年龄分成几个不同的阶段(bins),再把每一个阶段都当作是一个类别来看待,输出的概率即为年龄分布的概率,再将该阶段取代表性年龄μ。对于一个 s 类的分类模型,取其每一类的概率与当前类的代表年龄的加和作为最终的预测值:
![{%asset_img 2.png [func1]%}](http://img.e-com-net.com/image/info8/ae4d122dda634bb1b4cb2b0a905ec376.jpg)
而SSR-NET与DEX不同的是,SSR-NET选择分阶段执行DEX的预测操作,再对不同阶段的值进行融合。
简单来就是第一阶段(0,30)(30,60)(60,90),那么第二阶段就是(0,10)(10,20)(20,30)。
SSR-NET给出的预测结果的公式如下所示:
![{%asset_img 3.png [func2]%}](http://img.e-com-net.com/image/info8/6b6fa5bfb0304a6bb9fd26c9356aa68f.jpg)
作者除了多阶段预测以外,在这里还使用了一个trick,年龄是连续的,而且有一定的不确定性,将年龄段划分为无交集的区域并不合适,因此引入了shift vector η和scale factor Δ,对预测结果进行调整。
a shift vector η(k) adjusts the center for each bin and a scale factor ∆ scales the widths of all bins at the k-th stage, thus modifying the representative ages μ(k).
同时scale factor、shift vector以及分布p都是可学习的,最终映射到连续结果,最终SSR-NET的结果在年龄预测这一问题的效果有提升。
虽然FSA-NET与SSR-NET有巨大的关联。但这里和年龄估算不同的是,FSA-Net是对姿态进行估算,他有3个数值,是一个矢量,而非一个像年龄一样的标量。作者将用SSR-NET预测多维结果的形式称为SSR-NET—MD,后续并将其结构略做修改。
尽管SSR-NET—MD已经能够取得不错的效果,但在特征融合方面依然有提升空间,也就是可以利用attention机制学习到更好的表达。
最终修改部分结构的SSR-NET以及添加了特征融合的网络也就是FSA-NET。

除了多段预测以外,SSR-NET还有一个特点,那就是使用了互补的Two Stream的结构。这部分是受到了参考文献[3]的启发,据说通过这种方式,可以探索不同的特征,他们的融合也可以提高性能。以后有空的话去专门了解一下。
FSA-NET的结构
下面就是本篇文章的重头戏了。论文看了很久,这部分也没能感觉特别清晰。但还是尽量把自己理解的东西记录下来吧。
首先,下图是FSA-NET的结构:
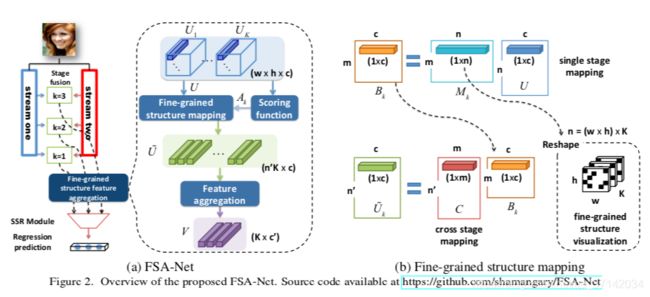
流程简单来说,Two Stream会先进行element-wise multiplication,再使用11卷积,后面再接池化,类似于SSR-NET,最终得到wh*c大小的特征图。特征图的每个网格都是c维度的空间向量,代表了一定的空间局部信息。然后把Uk送入到映射模块中,最终产生k个c’维度的特征向量,这k个c’维度的特征向量的向量用于姿态的预测。也就是利用他们去获得SSR所需要的p、η、μ和Δ等参数。
Two Stream
首先就是类似SSR-NET的Two Stream和多个stage的数据,但具体的网络结构相较于SSR-NET发生了变动,每条stream具体Building Block安排得不太一样。
Feature Aggregation
除此之外,就是Fine-grained structure feature aggregation的部分,也就是将Uk送入,最终产生k个c’维度的特征向量的模块。也就是这部分较为难懂,我觉得这部分的工作也是这篇文章能够被CVPR录用的原因,毕竟SSR-NET是过去的工作,换个皮的话,不会被别人认可的(其实我觉得hopenet就是resnet换了个皮…)。
aggregation 模型的的任务就是对前面得到的Uk进行提炼,也就是上图的右侧部分。
类似于pooling的操作,最终从Uk中提炼到更加有用的信息,最终获得更小的,K*c‘维度的向量。
目前存在的Aggregation的方法,主要有capsule和NetVLAD两种。但正如introduction讲到的,两种方法都忽略了特征图中的空间信息。因此在执行aggregation前,作者对特征进行了空间分组。作为aggression输入的带有空间信息的特征,相比于像素级特征,会更有效果。
为了有效地对Uk进行空间分组,作者使用了注意力机制。即后面介绍的scoring function。先通过scoring function先计算得到一个Ak,下一步把Ak和Uk一起送入到fine-grained structure mapping module中,从而得到最终K*c‘维度,从而对向量进行SSR的计算。
Scoring function
为了更好地对特征进行空间分组,需要去测量像素级特征的重要性,也就是前面提到的注意力机制。作者设计了一个评分的函数Φ(u)来评估特征的重要性从而更好地进行空间分组。每一个特征图Uk都有一个对应的Ak,Ak(i,j)=Φ(Uk(i,j))。
至于我们要采用什么作为Scoring function,此处作者提到了三种方法。
1)1*1卷积。Φ(u) = σ(w · u),σ是sigmoid函数。w是可学习的参数。
2)方差。 Φ ( u ) = ∑ i = 1 c ( u i − μ ) 2 , 其 中 μ = 1 c ∑ i = 1 c u i \Phi(u)=\sum_{i=1}^{c}(u_i-\mu)^2,其中 \mu=\frac{1}{c}\sum_{i=1}^{c}u_i Φ(u)=i=1∑c(ui−μ)2,其中μ=c1i=1∑cui,方差作为Scoring function的话并不能被学习。
3)全置为常数1。这种方法就相当于放弃使用Scoring function。
以上三种方法可以捕捉不同层面的信息,起到互补的作用,融合使用可增加模型的鲁棒性。
最后的实验结果显示,1)2)效果比3)好,而平均地融合三个Scoring function最终的效果是最好的。
这部分的比较结果如下:

这个地方关于Score的结果能够代表注意力的理解并没有特别清晰。目前的理解是1*1卷积再通过sigmoid方程,通过网络的学习,那些重要信息的Score会被提高,不重要的会被忽视,因此可代表注意力。
Fine-grained structure mapping
得到了特征图Uk和注意力图Ak以后,下一步就是进行fine-grained structure mapping了。最终会得到一组具有代表性的特征Ũ。
U到Ũ的映射关系满足 U ~ = S k U Ũ=S_kU U~=SkU,这里的U = [U1,U2…Uk],shape为(K,w,h,c) 然后reshape为(n,c),这里n = w * h * K,U是包含了所有阶段的所有特征映射中的c-d像素级特征的2D矩阵。而Sk的shape为(n’,n),Ũk的Shape为(n‘,c)。
在第k阶段,我们希望找到一个映射Sk,该映射Sk将U中的特征选择并分组成n‘个代表性特征Ũk,这个n‘个特征向量Ũk是由n个像素级别的特征转变而成的。Sk是一种线性变换,它通过对所有像素级特征进行加权平均来进行线性降维。
Sk被分解为两个矩阵参数去学习。 S k = C M k , C ∈ R n ′ × m , M k ∈ R m × n S_k=CM_k,C\in R^{n'\times m},M_k\in R^{m\times n} Sk=CMk,C∈Rn′×m,Mk∈Rm×nC参数对于所有K折处的特征都是共享的,但是对于Mk并非是共享的,也就是对于每个折处的特征向量,都有对应的一个Mk。这部分并不好理解。
![{%asset_img 7.png [function]%}](http://img.e-com-net.com/image/info8/6f7f4752d982445a940e0dcd1b79eaf2.jpg)
fm和fc都是全连层,A=[A1,A2,…Ak]。这个公式可以看出这个工作确实是利用了注意力机制,下图为Mk经过可视化而形成的热力图。
文中也讲到了:把Sk分解成fM和fc这种方式,不仅减少了参数,还使训练更加的稳定。

每个Mk图都能折叠成K个w*h大小的特征图,Mk图的每一行都装载了代表性信息,因此Mk可以看作是突出头部姿态估计的细粒度结构。
最后链接来自Uk的所有特征形成Ũ作为最终进行计算的feature,后面和SSR-NET一样,进入fusion module得出计算最终角度的三个值p,Δ和η,最后产生最终的预测结果。
实验结果
作者进行的实验做的很细致,也很客观,不仅指出了自己在RGB-based数据集训练的各种方法中取得了SOTA(用300W-LP训练,用AFLW2000和BIWI测试),如下图所示,
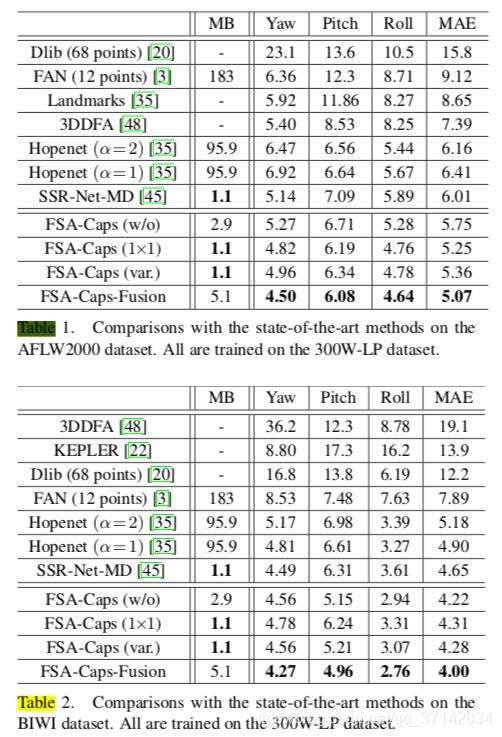
而且还在BIWI数据集上做了测试(70%用于训练,30%用于测试),效果不如带有深度信息和带有时序信息的方法,但也没偏差太多。虽然带Depth或者Time相对来说准确一些,但数据要求苛刻,鲁棒性也不行,它们的学术和工程价值都有限。

后面还做了消融学习,证明它们使用的各种trick,比如aggregation、Scoring function在不同的数据集上也是能够经受住考验的。
总结
这个工作总体网络结构就是套用了SSR-Net,在最后进入Fusion Block之前,利用了注意力机制,映射出了更加有效的特征,再进行后面的SSR计算工作。
1.贡献
这篇工作使用极小的模型(最大的FSA-Caps-Fusion也只有5.1m)实现了现有头部姿态估计工作的SOTA,虽然相比于hopenet来说,模型小了很多,但只能说明hopenet的工作还是比较粗糙,直接套resnet来进行预测。头部姿态估计还有很多东西可以去做。
2.性能
虽然暂时并未复现这篇工作中记录的网络,但简单地用它的模型测试了一下我们的数据集。
配置:i7+1080ti,同一个数据集,1K画质,单帧平均20个人脸。
使用MTCNN+hopenet,单帧1.4秒左右,占用显存2g;使
使用MTCNN+FSANET,单帧0.9s,占用显存9g左右,暂时未统计准确率。
resnet作为15年的工作,FSA-NET虽然拥有了很小的模型(毕竟原创模型),但在运行的时间、显存性能上却并没有太大的改进,是否可以在这方面入手进行改进?我觉得值得调研一下。
3.创新点
创新点也就是用attention机制重新表征特征,在本任务中的精度取得了提升。
也就是先定义score function来评估feature的注意力得分,再用评估的attention map来学习一种变换,对原来的feature进行变换,能够获得更好的特征从而达到更好的效果。
我对于attention机制并不了解,但通过简单的资料查找,主观感觉大多数attention机制应该会比本文中叙述的复杂,或者会更有效果。或许可以采用更加优秀的Score function加强headpose estimation的效果,但毕竟注意力机制是本文中率先提出的,在这方面花功夫或许并不足以作为一个值得发论文的创新点,工作价值有限。而且也不知道是否有其他类似的创新点或者说是trick可以加强效果,后面可以深入调研一下。
参考资料
[1]Tsun-Yi Yang,Yi-Ting Chen,Yen-Yu Lin, et al. FSA-Net: Learning Fine-Grained Structure Aggregation for Head Pose Estimation From a Single Image[C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2019. 《FSA-NET》。
[2]Tsun-Yi Yang, Yi-Hsuan Huang, Yen-Yu Lin, Pi-Cheng Hsiu, and Yung-Yu Chuang. SSR-Net: A compact soft stage- wise regression network for age estimation. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), 2018.SSR-NET。
[3][Yang et al., 2017] Tsun-Yi Yang, Jo-Han Hsu, Yen-Yu Lin, and Yung-Yu Chuang. DeepCD: Learning deep complementary descriptors for patch representations. In Proceedings of the IEEE Conference on International Conference on Computer Vision (ICCV), pages 3314–3322, 2017.