pytorch学习(二)-全连接网络之Mnist数据集数字识别
在学习本文之前可以参考(里面含有损失函数和交叉熵的基本概念)
https://blog.csdn.net/qq_41821067/article/details/115358983
目录
- 在学习本文之前可以参考(里面含有损失函数和交叉熵的基本概念)
- 神经网络
- 网络训练
-
- 输入
- 输出
- 网络结构
-
- 损失函数
- 求解极小值
- 神经元串联
- 模型工作
-
- 损失函数
- 线性和非线性
- 处理线性不可分
- 分类器类别
- 预处理
- 全连接网络
-
- 手写数字识别
- 网络模型
- 代码
- epoch
- 训练规则
- 训练结果
一个神经元中包括线性模型和激励函数部分。
神经网络
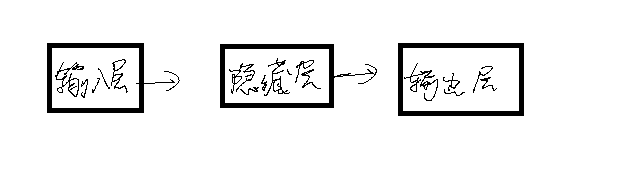
输入层不对数据做任何处理,不计入层数,隐藏层可以有一层,也可以有多层,输出层是最后一层。根据不同的需求,输出层的格式也是不同的。
网络训练
网络训练中用到了数学,统计学,最优化等众多学科。
输入

这里我们提到了量化处理,那么什么是量化处理,就是根据一定的规则进行编码,例如归一化,白化,灰度化,嵌入等。
输出

网络结构

每个网络都相当于一个函数g(x|Θ),为了区别不同的网络层,用下标表示,如g1(x|Θ1),g2(x|Θ2.)…
要解决的问题就是f(x|Θ)中的Θ取什么值,每层中的gi(x|Θi)取什么值,这些值确定下来,就可以进行训练
损失函数
损失函数是训练者自己定义的,表示模型误差的大小,

求解极小值
求解损失函数极小值的过程就是训练的过程,

神经元串联
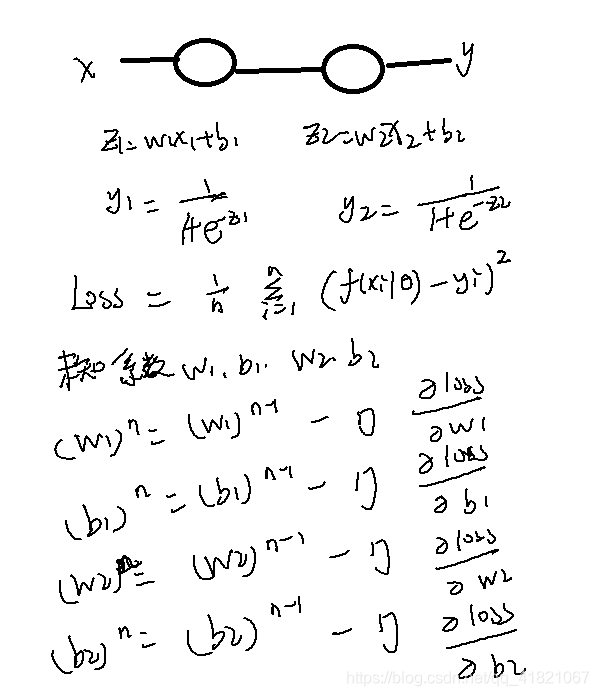
模型工作
模型训练之后,模型就开始工作了。就是将输入值代入到训练好的模型函数中,得到一个输出值。这个过程是非常简单的,因为只是一个简单的加减乘除运算。
这也得到很多模型都是训练的时候时间很长,是反向传播的过程,工作是一个样本正向传播的过程。
损失函数
我们平常接触到的损失函数含有很多的项

线性和非线性
在没有非线性函数之前,我们使用贝叶斯,决策树,支持向量机等传统机器分类模型进行机器学习,提取特征是其中一个重要的环节,
处理线性不可分
使用多层线性分类器模拟的堆叠
SVM用升维来处理线性不可分的问题,神经网络的每一个神经元都是一个线性分类器,
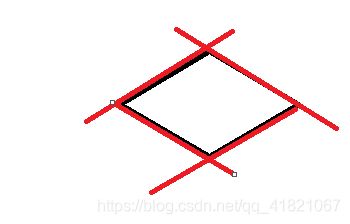
对于上面的一个四边形,怎么对他进行分类,一边是四边形内的点,一边是四边形外面的点,我们用四条直线(红线),也就是4个线性分类器对其进行分类。
因为神经网络中有很多层,每一层有很多神经元,一个神经元可以看成一个线性分类器,这样线性不可分模型就可以被分类。
随着维度和深度的增加,分类器也会越来越复杂,可以用与,或,非,这些进行线性分类器叠加。
分类器类别

预处理
1、宽度归一化
全连接网络
手写数字识别
我们只要输入数据样本,机器就会学习这个样本,通过输入图片的向量的特征,与f(x|Θ)中的Θ进行计算。
1、输入格式
28*28像素的手写数字图片,归一化处理的灰度值,0代表黑色,1代表白色,小数就是灰度值
2、输出标签
10维的独热向量
[0,0,1,0,0,0,0,0,0,0]
代表的就是2,具有含义唯一性,无法用这向量表示其他数字
网络模型
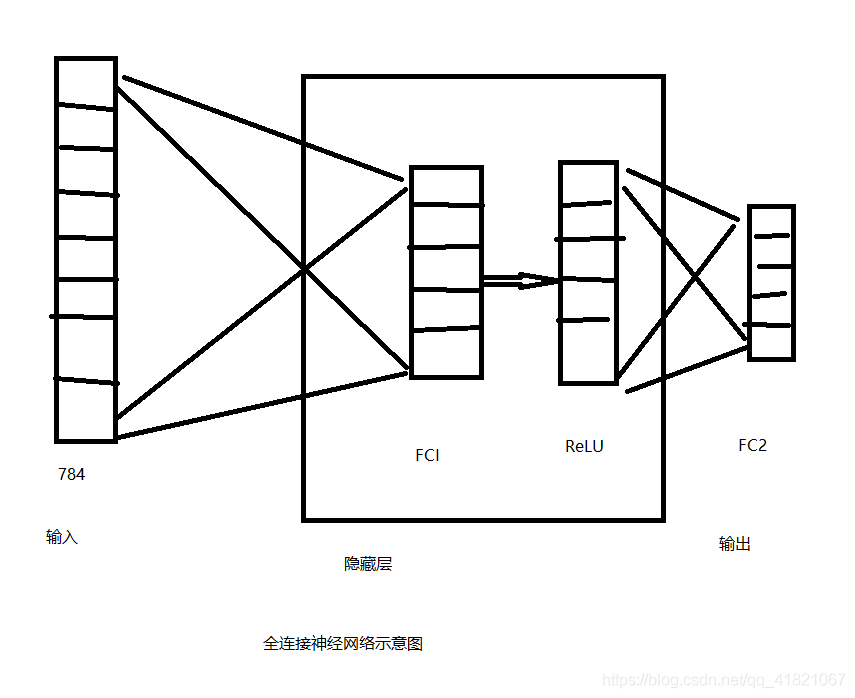
输入是一个1784的矩阵,FCI 是一个全连接层,其中有500个神经元,,其实是一个784500的矩阵,ReLU 是激活函数,对FCI输出的1500的矩阵的每一个维度进行处理,FC2也是一个全连接层,是一个50010的矩阵,其中FCI和RelU是一个2层的隐藏层。
代码
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
# Device configuration
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# Hyper-parameters
input_size = 784
hidden_size = 500
num_classes = 10
num_epochs = 5
batch_size = 100
learning_rate = 0.001
# MNIST dataset
train_dataset = torchvision.datasets.MNIST(root='../../data',
train=True,
transform=transforms.ToTensor(),
download=True)
test_dataset = torchvision.datasets.MNIST(root='../../data',
train=False,
transform=transforms.ToTensor())
# Data loader
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False)
# Fully connected neural network with one hidden layer
class NeuralNet(nn.Module):
def __init__(self, input_size, hidden_size, num_classes):
super(NeuralNet, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, num_classes)
def forward(self, x):
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
return out
model = NeuralNet(input_size, hidden_size, num_classes).to(device)
# Loss and optimizer
#使用交叉熵损失,损失函数的值就是在一个epoch中在每个样本上的平均误差值。
criterion = nn.CrossEntropyLoss()
#优化方法为Adam,类似随机梯度下降,使得整个网络中的待定系数朝着减小整个误差值的方向进行
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# Train the model
#总步长是加载数据的长度total_step
total_step = len(train_loader)
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
# Move tensors to the configured device
#正向传播一幅图片并得到一个拟合值
images = images.reshape(-1, 28*28).to(device)
labels = labels.to(device)
# Forward pass
outputs = model(images)
# 计算损失函数的值
loss = criterion(outputs, labels)
# 反向传播并进行优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i+1) % 100 == 0:
print ('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'
.format(epoch+1, num_epochs, i+1, total_step, loss.item()))
# Test the model
# In test phase, we don't need to compute gradients (for memory efficiency)
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
images = images.reshape(-1, 28*28).to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: {} %'.format(100 * correct / total))
# Save the model checkpoint
torch.save(model.state_dict(), 'model.ckpt')
epoch
机器学习中用来衡量样本量的一个词,如在机器学习中准备了50000个样本,当全部样本通过网络进行了一次正向传播的时候就叫做一个epoch,在上面代码中batch-size=100,也就是随机挑选100个样本进行训练,再进行一次梯度下降,每处理一批(batch)样本就叫做一个step,要让50000个样本通过网络完成一个epoch就要500个step
1次epoch完成的样本=step*batch_size
注意!batch从样本中抽取就不能放回。
训练规则
可以由我们自己确定,让每个样本都能等权重地在训练中发挥作用,让每个样本都有同等的机会进行正向传播并产生相应的损失值。
训练结果

我们只需要把数据找到,把网络搭好,把损失函数定义好,其他就可以交给计算机了,不用手动进行分类。