MySQL进阶
目录
高级函数
条件判断
数学函数
字符串函数
日期函数
加密函数
系统函数
其他函数
窗口函数 MySQL8 开始支持
LAG()、LEAD() 函数
row_number()
rank() 与 dense_rank()
first_value() 与 last_value()
nth_value(expr,n) 与 ntile(n)
关键字
ANY
ALL
使用JSON
查找
JSON 函数
修改
删除
其他函数
JSON使用索引
公用表表达式(CTE)
WITH子句用法
非递归CTE
递归CTE
高级函数
条件判断
| 函数 |
用法 |
| IF(value,T,F) |
相当于java的三元运算符,value为真返回T,否则返回F |
| IFNULL(value,value2) |
判断value是否为空,为空返回vlaue2 |
| ISNULL(expression) |
判断表达式是否为 NULL,为NULL返回1,不为NULL返回0 |
| NULLIF(expr1, expr2) |
比较两个字符串,如果字符串 expr1 与 expr2 相等 返回 NULL,否则返回 expr1 |
| CASE WHEN 条件1 THEN 结果1 WHEN 条件2 THEN 结果2 WHEN 条件N THEN 结果N ELSE 都不能满足的结果 END |
流程控制语句,相当于java的if...else if |
| CASE 条件 WHEN 常量值1 THEN 结果1 WHEN 常量值2 THEN 结果2 WHEN 常量值N THEN 结果N ELSE 结果N END |
流程控制语句,相当于jav a的switch...case |
数学函数
| 函数 |
用法 |
| ABS(X) |
返回X的绝对值 |
| SQRT(X) |
返回X的平方根 |
| POW(X) |
返回X的Y次方根 |
| CEIL(X) |
返回大于X的最小整数,即向上取整 |
| FLOOR(X) |
返回大于X的最大整数,即向下取整 |
| MOD(X,Y) |
返回X/Y的值 |
| RAND(X) |
返回0-1的随机数 |
| ROUND(X,Y) |
返回X的四舍五入,Y为保留几位小数 |
| TRUNCATE(X,Y) |
不考虑四舍五入,截断X,Y为截断的小数点位数 |
| FORMAT(X,Y) |
强制保留Y位,考虑四舍五入,和ROUND(X,Y)区别是整数超过三位会以逗号分隔,返回文本 |
SELECT CEIL(2.1) #3 向上取整
SELECT FLOOR(2.1) #2 向下取整
SELECT RAND() #返回0-1之间的随机数 0.6553991843530901
SELECT ROUND(2.5686,3) #四舍五入保留三位 2.569
SELECT TRUNCATE(2.5686,3) #截断小数点后三位 2.568
SELECT FORMAT(123859.5686,3) #四舍五入,整数超过三位逗号分隔 123,859.569 字符串函数
| 函数 |
用法 |
| CONCAT(S1,S2,...Sn) |
拼接字符串; |
| CONCAT_WS(6,S1,S2...Sn) |
拼接字符串。但每个以字符串都会加6 |
| LENGTH(S) |
返回字符串S的字符串的字节,和字符集有关,一个字符占3个字节 |
| LEFT(S,N) RIGHT(S,N) |
返回字符串左边/右边的第N个字符 |
| TRIM(S) |
去除S开始和结束的空格 |
| SUBSTRING(s,index,len) |
返回字符串S的index位置截取len字符 |
| LCASE(s)、LOWER(s) |
将字符串 s 的所有字母变成小写字母 |
| UCASE(s)、UPPER(s) |
将字符串 s 的所有字母变成大写字母 |
| CAST(x AS type) |
转换数据类型 |
| ELT(N,str1,str2,str3,…) |
返回对应位置的字符串 |
SELECT CONCAT('Hello','World') #HelloWorld
SELECT CONCAT_WS('6','1','1','1') #16161
SELECT LENGTH('hello world') #11字节
SELECT LEFT('helloworld',5),RIGHT('helloworld',5) #helloworld
SELECT TRIM(' YYYY-MM-dd') #YYYY-MM-dd
SELECT SUBSTRING('helloworld',1,5) #hello
SELECT CAST("2017-08-29" AS DATE)#字符串转Date
SELECT CAST("2" AS signed);#字符串转数字
select elt(2,'02','03') #02日期函数
| 函数 |
用法 |
| CURDATE() |
返回当前系统日期 |
| CURTIME() |
返回当前系统时间 |
| NOW()、SYSDATE()、LOCALTIME()、LOCALTIMESTAMP() |
返回当前系统日期时间 |
| YEAR(date)、MONTH(date)、DAY(date)、HOUR(time)、MINUTE(time)、SECOND(time) |
返回具体的年月日时分秒 |
| DATEDIFF(DATE1,DATE2) |
返回两个日期的日期间隔 |
| DATE_FORMAT(datetime,fmt) |
按照字符串fmt格式化日期datetime值 |
| DATE_ADD(date,INTERVAL expr type) |
函数向日期添加指定的时间间隔。 |
| DATE_SUB(date,INTERVAL expr type) |
函数向日期减少指定的时间间隔。 |
SELECT CURDATE() #2022-08-08
SELECT CURTIME() #14:43:47
SELECT NOW() #2022-08-08 14:44:27
SELECT SYSDATE()# 2022-08-08 14:44:44
SELECT LOCALTIME() #2022-08-08 14:45:12
SELECT LOCALTIMESTAMP() #2022-08-08 14:45:29
SELECT YEAR(NOW()) AS '年',MONTH(NOW()) AS '月',DAY(NOW()) AS '日',HOUR(NOW()) AS '时',MINUTE(NOW()) AS '分',SECOND(NOW()) AS '秒' #2022年8月8日14时45分53秒
SELECT DATEDIFF('2022-07-04','2022-07-01') #相差天数3
SELECT DATE_FORMAT(CURDATE(),'%y%m%d') #格式化后220705
SELECT DATE_ADD('2022-08-08',INTERVAL 1 DAY) #2022-08-09 8月8加一天8月9
SELECT DATE_SUB('2022-08-08',INTERVAL 2 DAY) #2022-08-09 8月8减二天8月6DATE_SUB() 、DATE_ADD()的type参数可以是下列值:
| Type 值 |
说明 |
| MICROSECOND |
毫秒 |
| SECOND |
秒 |
| MINUTE |
分 |
| HOUR |
小时 |
| DAY |
天 |
| WEEK |
周 |
| MONTH |
月 |
| QUARTER |
季度 |
| YEAR |
年 |
| SECOND_MICROSECOND |
复合型,间隔单位:秒、毫秒,expr可以用两个值来分别指定秒和毫秒 |
| MINUTE_MICROSECOND |
复合型,间隔单位:分、毫秒 |
| MINUTE_SECOND |
复合型,间隔单位:分、秒 |
| HOUR_MICROSECOND |
复合型,间隔单位:小时、毫秒 |
| HOUR_SECOND |
复合型,间隔单位:小时、秒 |
| HOUR_MINUTE |
复合型,间隔单位:小时分 |
| DAY_MICROSECOND |
复合型,间隔单位:天、毫秒 |
| DAY_SECOND |
复合型,间隔单位:天、秒 |
| DAY_MINUTE |
复合型,间隔单位:天、分 |
| DAY_HOUR |
复合型,间隔单位:天、小时 |
| YEAR_MONTH |
复合型,间隔单位:年、月 |
加密函数
| 函数 |
用法 |
| password(str) |
返回字符串str的加密版本,41位长的字符串(mysql8不再支持) |
| md5(str) |
返回字符串str的md5值,一种加密方式 |
| SHA(str) |
返回字符串str的sha算法加密字符串,40位十六进制值的密码字符串 |
| SHA2(str,sash_length) |
返回字符串str的sha算法加密字符串,密码字符串的长度是hash_length/4。hash_length可以是224、256、384、512、0其中0等同于256。 |
SELECT MD5('123456') #e10adc3949ba59abbe56e057f20f883e
SELECT SHA('123456') #7c4a8d09ca3762af61e59520943dc26494f8941b系统函数
| 函数 |
用法 |
| VERSION() |
返回数据库版本信息 |
| USER() |
查询当前登录用户 |
| DATABASE() |
查询当前使用哪个数据库 |
SELECT VERSION() #5.7.37-log
SELECT USER() #用户名@连接地址
SELECT DATABASE() #数据库名其他函数
| 函数 |
用法 |
| COALESCE(expr1, expr2, …, expr_n) |
返回参数中的第一个非空表达式(从左向右) |
| NULLIF(expr1, expr2) |
比较两个字符串,如果字符串 expr1 与 expr2 相等 返回 NULL,否则返回 expr1 |
| group_count() |
将group by产生的同一个分组中的值连接起来,返回一个字符串结果。 |
SELECT COALESCE(NULL, NULL, NULL, 'baidu.com', NULL, 'google.com') #baidu.com
SELECT NULLIF('cao', 'cao1') #cao窗口函数 MySQL8 开始支持
语法:
funcation(args) over([PARTITION BY expression] [ORDER BY expression[ASC|DESC]][frame])解释:
- funcation:换成对应的函数例如LAG 、LEAD、SUM..
- PARTITION BY:分组的列
- ORDER By: 排序的列,默认升序
- frame: 判定分组的方式
-
- rows模式: 按照物理行进行区分
SELECT
year_month,
sales,
sum(sales) over(order by year_month rows unbounded PRECEDING) as sum_by_sub_cate
from tmp
- sales=3594 ; sum_by_sub_cate=3594
- sales=865 ; sum_by_sub_cate=4459 #相当于3594 +865
- sales=603 ; sum_by_sub_cate=5062 #相当于4459 +603
-
- range模式:按照数值进行逻辑区分
SELECT
year_month,
sales,
sum(sales) over(order by year_month range unbounded PRECEDING) as sum_by_sub_cate
from tmp
- 根据year_month排序,它是分组算的
- year_month=2022-01;sales=3594; sum_by_sub_cate=4459
- year_month=2022-01;sales=865; sum_by_sub_cate=4459
- year_month=2022-02;sales=603; sum_by_sub_cate=7920
- year_month=2022-02;sales=2858; sum_by_sub_cate=7920
- 第一组进行组内累加 sum_by_sub_cate是累加结果 即3594+865=4459;
- 第二组进行组内累加 603+2858=3461;在加上,上一组的结果3461+4459=7920
LAG()、LEAD() 函数
- lead(expression,n):返回当前行的后n行,理解为取未来的数据,今天取明天的数据
- lag(expression,n): 返回当前行的前n行, 理解为取之前的数据,今天取昨天的数据
语法:
LAG(要取的列,取偏移后的第几行数据,没有符合条件的默认值默认为null) OVER()
LEAD(要取的列,取偏移后的第几行数据,没有符合条件的默认值默认为null) OVER()案例1:查询每个月和上月的销售数、没有为0
表结构&数据:
SELECT
product '产品名',
DATE_FORMAT(`year_month`,'%Y-%d-%m') '月份',
gmv '销量',
LAG(gmv,1,0)over() '上月销售'
FROM
`xiaoliang`
如果要取这个月和下个月的 使用LAED()
案例2:取连续登录5天的活跃用户,用户同一天可能重复登录

分析:

看上图站在第二条数据角度看,lag_num是上一条数据的结果,lead_num是下一条数据的结果,所有只有 number、lag_num、lead_num相等即可找出连续出现的数据row——
SELECT DISTINCT num AS Consecutivenums
FROM(
SELECT
id,num,
lag(num,1) orve(ORDER BY id) lag_num,
lead(num,1) orve(ORDER BY id) lead_num
FROM Logs
WHERE num=lag_num AND num=lead_num
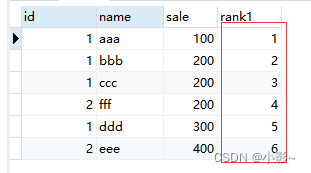
)row_number()
作用:加上序号
SELECT
t.*,
row_number() over ( PARTITION BY id ORDER BY sale ) AS rank1
FROM
test AS t;
不加分组PARTITION BY id
rank() 与 dense_rank()
rank() over(partition by col1 order by col2)
- rank函数根据字段col1进行分组,在分组内部根据字段col2进行跳跃排序,有相同的排名时,相同排名的数据有相同的序号,排序序号不连续;
#对id进行分组,分组后根据sale排序
#可以发现sale相同时有相同的序号,并且由于id=1的分组中没有排名第3的序号造成排序不连续
bbb、ccc成绩一样共同排名第二,去除排序,fff也是排第二

dense_rank() over(partition by col1 order by col2)
- dense_rank函数根据字段col1进行分组,在分组内部根据字段col2进行连续排序,有相同的排名时,相同排名的数据有相同的序号,但是排序序号连续
#对id进行分组,分组后根据sale排序
#可以发现sale相同时有相同的序号,但是整个排序序号是连续的

first_value() 与 last_value()
first_value():
first_value( EXPR ) over( partition by col1 order by col2 )其中EXPR通常是直接是列名,也可以是从其他行返回的表达式,根据字段col1进行分组,在分组内部根据字段col2进行排序;
first_value函数返回一组排序值后的第一个值
last_value返回一组排序值后的最后一个值
#first_value函数查看每一个分组的第一个值
SELECT
t.*,
first_value( sale ) over ( PARTITION BY id ) AS rank1
FROM
test AS t;如下图:查到这个组最大的id的第一个值,如果要这个组内最小的值在PARTITION BY id 后面加Order By sale Desc即可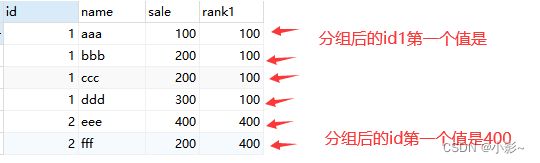
验证:
SELECT
t.*
FROM
test AS t;
GROUP BY id分组后的第一个值

last_value():
last_value( EXPR ) over( partition by col1 order by col2 )其中EXPR通常是直接是列名,也可以是从其他行返回的表达式,根据字段col1进行分组,在分组内部根据字段col2进行排序;
first_value函数返回一组排序值后的第一个值
last_value返回一组排序值后的最后一个值
#last_value函数查看每一个分组的最后一个值
SELECT
t.*,
last_value( sale ) over ( PARTITION BY id ) AS rank1
FROM
test AS t;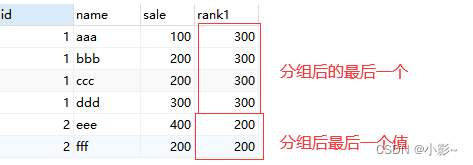
验证:
SELECT
t.*
FROM
test AS t;
GROUP BY id
nth_value(expr,n) 与 ntile(n)
nth_value():
其中NTH_VALUE(expr, n)中的第二个参数是指这个函数取排名第几的记录,返回窗口中第n个expr的值。expr可以是表达式,也可以是列名。
SELECT
order_id,
username,
create_date,
cost,
NTH_VALUE( cost, 3 ) OVER ( ORDER BY username ASC ) nth_cost
FROM
tb_customer_shopping;如下图:取出排名第三的成绩46

SELECT
order_id,
username,
create_date,
cost,
NTH_VALUE( cost, 3 ) OVER ( PARTITION BY username ORDER BY create_date ASC ) nth_cost
FROM
tb_customer_shopping;
SELECT
order_id,
username,
create_date,
cost,
NTH_VALUE( cost, 2 ) OVER ( PARTITION BY username ORDER BY create_date ASC rows BETWEEN unbounded preceding AND unbounded following ) nth_cost
FROM
tb_customer_shopping;
ntile():
ntile(ntile_num) OVER ( partition by col1 order by col2 )NTILE函数对一个数据分区中的有序结果集进行划分,举一个生活中的例子,我们想要把一些鸡蛋放入若干个篮子中,每个篮子可以看成一个组,然后为每个篮子分配一个唯一的组编号,这个组里面就有一些鸡蛋。我们假设篮子的编号可以反映放在内部鸡蛋的体积大小,例如编号较大的篮子里面放着一些体积较大的鸡蛋,编号较小的篮子则放着体积较小的鸡蛋,现在,因为体积特别大的鸡蛋和特别小的鸡蛋不适合放入规定范围包装盒内进行出售,所以要进行筛选,在进行分组之后,我们只需要拎出合适范围的带有编号的篮子就能拿到我们想要的鸡蛋
NTILE函数在统计分析中是很有用的。例如,如果想移除异常值,我们可以将它们分组到顶部或底部的“桶”中,然后在统计分析的时候将这些值排除。在统计信息收集可以使用NTILE函数来计算直方图信息边界。在统计学术语中,NTILE函数创建等宽直方图信息。
ntile_num是一个整数,用于创建“桶”的数量,即分组的数量,不能小于等于0。其次需要注意的是,在over函数内,尽量要有排序ORDER BY子句
SELECT
t.*,
ntile( 4 ) over ( PARTITION BY id ORDER BY sale ) AS rank1 #声明了4个篮子
FROM
test AS t;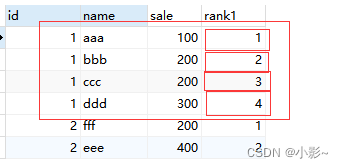
关键字
ANY
关键字ANY表示满足其中任意一个条件。只要满足内层查询语句返回的结果中的任意一个,就可以通过条件执行外层语句。
=ANY等价于IN
SELECT *
FROM tableName
WHERE id =ANY(SELECT id FROM tableName WHERE name='张三' || ename='李四');ALL
关键字ALL表示满足所有条件。使用关键字ALL时,只有满足内层查询语句的所以返回结果,才可以执行外层查询语句。
查询薪资比“张三”,“李四”,“王五”三个人的薪资都要高的员工姓名和薪资
SELECT ename,salary
FROM t_employee
WHERE salary >ALL(SELECT salary FROM t_employee WHERE ename IN('张三','李四','王五'));小结:关键字ANY和ALL的使用方法是一样的,但两者存在着很大的区别,使用ANY关键字时,只要满足内层查询语句结果中的任意一个,就可以通过该条件来执行外层查询语句;而关键字ALL则需要满足内层查询语句返回的所有结果,才可以执行外层查询语句。
使用JSON
MySQL5.7开始,支持了JavaScript对象表示(javaScript Object Notation, JSON)数据类型。之前这类数据不是单独的数据类型,会被存储为字符串。
新的JSON数据类型提供了自动验证的JSON文档以及优化的存储格式。
JSON文档以二进制格式存储,它提供以下功能:
- 对文档元素的快速读取访问
- 当服务器再次读取JSON文档时,不需要重新解析文本获取该值
- 通过键或数组索引直接查找子对象或嵌套值,而不需要读取文档的所有值。
创建表:
CREATE TABLE `emp_details` (
`emp_no` int NOT NULL,
`details` json DEFAULT NULL,
PRIMARY KEY (`emp_no`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;插入数据:
INSERT into emp_details(emp_no,details) values('1',
'{
"location":"IN",
"phone":"11999999911",
"email":"[email protected]",
"address":{
"line1":"abc",
"line2":"cde",
"city":"huj",
"pin":"41242"
}
}')查找
- 查询详情信息的address对象的pin字段内容
SELECT emp_no,details ->'$.address.pin' pin FROM emp_details # "41242"结果有引号,如果不用引号,可以使用->>运算符
SELECT emp_no,details ->>'$.address.pin' pin FROM emp_details #41242- 可以在where 子句中使用 col->>path 运算符来引用JSON的某一列
SELECT emp_no FROM emp_details WHERE details->>'$.address.pin'='41242'JSON 函数
MySQL提供了许多处理JSON数据的函数,下面举例几种常用的函数
- 也可以使用JSON_CONTAINS函数查询数据。如果找到了数据,则返回1,否则返回0
SELECT JSON_CONTAINS(details->>'$.address.pin',"41242") FROM emp_details- 查询一个key是否存在 address.pin这个key是否存在使用JSON_CONTAINS_PATH,存在返回1,否则返回0
SELECT JSON_CONTAINS_PATH(details,'one','$.address.pin') FROM emp_detailsone表示至少应该存在一个键
- 检查 address.line1或者address.line2是否存在
SELECT JSON_CONTAINS_PATH(details,'one','$.address.line1','$.address.line2') FROM emp_details- 如果要检查address.line1和 address.line2 是否同时存在,可以使用all,而不是one,使用了all只要有一个不存在就是返回0,都存在返回1
SELECT JSON_CONTAINS_PATH(details,'all','$.address.line1','$.address.line2') FROM emp_details修改
可以使用三种不同的函数来修改数据:JSON_SET()、JSON_INSERT()和JSON_PEPLACE()。在MySQL8 之前的版本,我们还需要对整个列进行完整的更新,这并不是最佳的方法。
- JSON_SET():替换现有值并添加不存在的值
替换员工的pin码,并添加昵称的详细信息
UPDATE emp_details SET details=JSON_SET(details, '$.address.pin', '666','$.nickName','小明')- JSON_INSERT():插入值,但不替换现有值
假设希望添加新列而不更新现有值
UPDATE emp_details SET details = JSON_INSERT( details, '$.address.pin', '555', '$.address.line4', 'wocao' ) WHERE emp_no =1这种情况,pin不会被更新,只会添加一个新字段address.line4
- JSON_REPLACE():仅替换现有值
假设只需要替换现有字段,不需要添加新字段
UPDATE emp_details SET details = JSON_REPLACE( details, '$.address.pin', '222', '$.address.line5', 'wocao' ) WHERE emp_no =1这种情况下,line5不会被添加,只有pin会被更新
删除
JSON_REMOVE能从JSON文档中删除数据
假设不在需要地址中的line4字段
UPDATE emp_details SET details = JSON_REMOVE( details, '$.address.line4') WHERE emp_no =1其他函数
- JSON_KEYS():获取JSON文档中的所有键
SELECT JSON_KEYS(details) FROM emp_details #["email", "phone", "address", "location", "nickName"]- JSON_LENGTH():给出JSON文档中的元素数。
SELECT JSON_LENGTH(details) FROM emp_details #5- JSON_PRETTY():优雅浏览
想要优雅的格式显示JSON值,使用JSON_PRETTY()函数:
SELECT emp_no,JSON_PRETTY(details) FROM emp_details结果:
{
"email": "[email protected]",
"phone": "11999999911",
"address": {
"pin": "41242",
"city": "huj",
"line1": "abc",
"line2": "cde"
},
"location": "IN"
}如果不适用函数是这样的结果
{"email": "[email protected]", "phone": "11999999911", "address": {"pin": "41242", "city": "huj", "line1": "abc", "line2": "cde"}, "location": "IN"}更多函数可以看官网的函数列表:MySQL :: MySQL 8.0 Reference Manual :: 12.18.1 JSON Function Reference
JSON使用索引
在JSON列上不能直接建立索引,如果要在JSON列上使用索引,可以使用虚拟列和在虚拟列上创建索引来提取信息。
插入虚拟数据:
INSERT IGNORE INTO emp_details(emp_no , details) VALUES
( '1','{"location":"IN","phone":"+1180000000","email":"[email protected]","address": { "line1":"abc","line2":"xyzstreet","city": "Bangalore","pin":"560101" }}' ) ,
( '2','{"location":"IN","phone":"+1180000000","email":"[email protected]","address": { "line1":"abc","line2":"xyzstreet","city": "quanzhou","pin":"560102" }}' ) ,
( '3','{"location":"IN","phone":"+1180000000","email":"[email protected]","address": { "line1":"abc","line2":"xyzstreet","city": "xiamen","pin":"560103" }}' ) ,
( '4','{"location":"IN","phone":"+1180000000","email":"[email protected]","address": { "line1":"abc","line2":"xyzstreet","city": "zhangzhou","pin":"560104" }}' ) ,
( '5','{"location":"IN","phone":"+1180000000","email":"[email protected]","address": { "line1":"abc","line2":"xyzstreet","city": "yongcun","pin":"560105" }}' ) 查询城市quanzhou的员工编号emp_no
EXPLAIN SELECT emp_no FROM emp_details WHERE details->>'$.address.city'='quanzhou'如果下图:无法使用索引,也全表扫描
![]()
解决办法:可以将城市作为虚拟列进行检索,并在这个虚拟列添加索引
ALTER TABLE emp_details ADD COLUMN city VARCHAR(20) AS (details->>'$.address.city'),ADD INDEX(city);如下图,使用了索引,也只扫描了一行
![]()
也可以在创建表的时候添加索引
CREATE TABLE emp_details(
emp_no int(11) NOT NULL,
details json DEFAULT NULL,
city VARCHAR(20) GENERATED ALWAYS AS(json_unquote(json_extract(details,_utf8'$.address.city')))
VIRTUAL,
PRIMARY KEY(emp_no),
KEY city (city)
ENGINE=INNODB DEFAULT CHARSET=utf8mb4
)
公用表表达式(CTE)
MySQL 8支持公用表达式 ,包括非递归和递归两种。
公用表表达式允许使用命名的临时结果集,这是通过允许在SELECT语句和某些其他语句前面使用WITH子句来实现的
为什么需要CTE?
不能在同一查询中引用两次派生表,因为那样的话,查询会根据派生表的引用次数计算两次或多次,这样会引发严重的性能问题,使用CTE后,子查询只会计算一次。
基础语法:
WITH cte_name (column_list) AS (
query
)
SELECT * FROM cte_name;注意,查询中的列数必须与column_list中的列数相同。 如果省略column_list,CTE将使用定义CTE的查询的列列表。
简单示例:
WITH customers_in_usa AS (
SELECT customerName, state
FROM customers
WHERE country = 'USA'
)
SELECT customerName FROM customers_in_usa
WHERE state = 'CA' ORDER BY customerName;更高级的示例:
WITH salesrep AS (
SELECT
employeeNumber,
CONCAT(firstName, ' ', lastName) AS salesrepName
FROM
employees
WHERE
jobTitle = 'Sales Rep'
),
customer_salesrep AS (
SELECT
customerName, salesrepName
FROM
customers
INNER JOIN
salesrep ON employeeNumber = salesrepEmployeeNumber
)
SELECT
*
FROM
customer_salesrep
ORDER BY customerName;WITH子句用法
在SELECT,UPDATE和DELETE语句的开头可以使用WITH子句:
WITH ... SELECT ...
WITH ... UPDATE ...
WITH ... DELETE ...可以在子查询或派生表子查询的开头使用WITH子句
SELECT ... WHERE id IN (WITH ... SELECT ...);
SELECT * FROM (WITH ... SELECT ...) AS derived_table;可以在SELECT语句之前立即使用WITH子句,包括SELECT子句
CREATE TABLE ... WITH ... SELECT ...
CREATE VIEW ... WITH ... SELECT ...
INSERT ... WITH ... SELECT ...
REPLACE ... WITH ... SELECT ...
DECLARE CURSOR ... WITH ... SELECT ...
EXPLAIN ... WITH ... SELECT ...非递归CTE
公用表表达式(CTE) 与派生表类似,但它的声明会放在子查询块之前,而不是FROM 子句中。
派生类:
SELECT... FROM (subquery) AS derived,t1 ...CTE:
SELECT... WITH derived AS (subquery) SELECT ... FROM derived,t1...CTE 可能在SELECT/UPDATE/DELETE之前,包括WITH derived AS (subquery)
案例:想了解每年工资比较前一年的增长百分比,如果没有CTE,你需要编写两个子查询,这两个子查询本质上是相同的,但MySQL并不能识别出它们是相同的,这就会导致子查询被执行两次
SELECT
q1.YEAR,
q2.YEAR AS next_year,
q1.sum,
q2,
sum AS next_sum,
100 *(q2.sum - q1.sum )/ q1.sum AS pct
FROM
(SELECT year(from_date) as year,sum(salary) as sum FROM salaries GROUP BY year) AS q1,
(SELECT year(from_date) as year,sum(salary) as sum FROM salaries GROUP BY year) AS q2
WHERE q1.year=q2.year-1;如果使用非递归 CTE,派生查询只执行一次并重用:
WITH CTE AS (SELECT year(from_date) AS year,SUM(salary) AS sum FROM salaries GROUP BY year)
SELECT
q1.YEAR,
q2.YEAR AS next_year,
q1.sum,
q2.sum AS next_sum,
100 *(q2.sum - q1.sum )/ q1.sum AS pct
FROM
CTE AS q1,
CTE AS q2
WHERE
q1.YEAR = q2.yuar - 1;结果发现使用CTE后,结果与之前相同,查询时间缩短了50%,可读性变好,而且可以被多次引用
优缺点:
- 派生查询不能引用其他派生查询
- CTE可以引用其他CTE
递归CTE
递归CTE是一种特殊的CTE,其子查询会引用自己的名字,WITH子句必须以WITH RECURSIVE开头。递归CTE子查询包括两部分:seed查询 和recursive查询,有UNION[ALL]或UNION DISTINCT分隔
- seed SELECT被执行一次以创建初始数据子集;
- recursive SELECT被重复执行以返回数据的子集,直到获得完整的结果集。
当迭代不会生成任何新行时,递归会停止。这对挖掘层次结构(父/子或部分子部分)非常有用
WITH RECURSIVE cte AS
(SELECT ... FROM table_name /* seed SELECT*/
UNION ALL
SELECT ... FROM cte ,table_name) /* recursive SELECT*/
SELECT ... FROM cte;
)案例:假设要执行分层数据遍历,以便为每个员工生成一个组织结构图(即从 CEO 到每个员工的路径),也可以使用递归CTE!
创建表:
CREATE TABLE employees_mgr (
id INT PRIMARY KEY NOT NULL,
NAME VARCHAR ( 100 ) NOT NULL,
manager_id INT NULL,
INDEX(manager_id),
FOREIGN KEY ( manager_id ) REFERENCES employees_mgr(id)
);插入示例数据:
INSERT INTO employees_mgr
VALUES
( 333, 'Yasm na', NULL ), #Yasmina is the CEO (manager id is NULL)
( 198, 'John', 333 ),# John has ID 198 and reports to 333 (Yasm na)
( 692, 'Tarek', 333 ),
( 29, 'Pedro', 198 ),
( 4610, 'Sarah', 29 ),
( 72, 're', 29 ),
(123,'Adil',692 );执行递归CTE:
WITH RECURSIVE employee_paths (id,`name`,path) AS
(
SELECT id,`name` , CAST(id AS CHAR(200)) #转int类型
FROM employees_mgr
WHERE manager_id IS NULL
UNION ALL
SELECT e.id, e.name , CONCAT(ep.path ,',', e.id)
FROM employee_paths AS ep JOIN employees_mgr AS e
ON ep.id = e.manager_id
)
SELECT * FROM employee_paths ORDER BY path ;
-- SQL分析:
WITH RECURSIVE employee_paths (id,`name`,path) AS -- 是CTE的名称,列是(id,`name`,path)
SELECT id,`name` , CAST(id AS CHAR(200))
FROM employees_mgr
WHERE manager_id IS NULL -- 查询CEO的seed查询(没有在CEO智商的管理者))
SELECT e.id, e.name , CONCAT(ep.path ,',', e.id)
FROM employee_paths AS ep JOIN employees_mgr AS e
ON ep.id = e.manager_id -- 是递归查询
-- 递归查询生成的每一行,会查找直接向前一行生成的员工汇报所有员工,对于每个员工,改行的信息包括员工ID、姓名、员工管理链,该链是咋最后添加了员工ID的管理链这是小编在开发学习使用和总结的小Demo, 这中间或许也存在着不足,希望可以得到大家的理解和建议。如有侵权联系小编!