跟着官方文档学习Kotlin协程,官方文档还是香啊!

/ 今日科技快讯 /
近日,核桃编程宣布完成新一轮融资,C轮系列融资额约 2亿美元。这是迄今为止少儿编程行业金额最高的一笔融资,同时创造中国在线教育C轮融资额高点。本轮融资由高瓴创投、KKR、元璟资本领投,源码资本、华兴新经济基金等机构继续跟投,凡卓资本担任本轮融资独家财务顾问。
/ 作者简介 /
看到本篇,意味着明天就是愉快地周末啦!
本篇文章来自信波波同学投稿,根据官方文档讲解了coroutines,原汁原味,相信会对大家有所帮助!同时也感谢作者贡献的精彩文章!
信波波的博客地址:
https://blog.csdn.net/panqf86?type=blog
/ 前言 /
使用Kotlin做Android开发也有一段时间了,Kotlin 协程 Coroutines 也一直在用。
但是那时只知其然,不知其所以然,用起来就跟模板代码一样,只知道复制黏贴,虽然功能实现了,但是总觉得理解得很肤浅,用起来不顺手,心里也没那么踏实。
所以前段时间静下心来,重新学习了一遍,有了一些深入的了解,甚至有一种拨云见日的感觉。
现在把自己的学习过程做个记录,希望能帮到那些像我之前一样,想对 Kotlin 协程加深了解的人。
/ 都有哪些坑? /
1. 定义的坑
对于如何了解一个新名词,我的习惯做法是先去找这个词的定义。
协程的定义是什么?
协程(英语:coroutine)是计算机程序的一类组件,推广了协作式多任务的子程序,允许执行被挂起与被恢复。相对子例程而言,协程更为一般和灵活,但在实践中使用没有子例程那样广泛。协程更适合于用来实现彼此熟悉的程序组件,如协作式多任务、异常处理、事件循环、迭代器、无限列表和管道。
Coroutines are computer program components that generalize subroutines for non-preemptive multitasking, by allowing execution to be suspended and resumed. Coroutines are well-suited for implementing familiar program components such as cooperative tasks, exceptions, event loops, iterators, infinite lists and pipes.
以上是维基百科(Wikipedia)对于协程的定义。概括得很精确,也列出了协程的应用场合。
但是,我刚看完后脑子是有点懵的。里面概念实在是太多了,比如什么是“协作式多任务(cooperative tasks)”?协程怎么个适合实现“异常处理(exceptions)”,“无限列表(infinite lists)”?
再往下看维基百科(Wikipedia)上的协程(Coroutine)词条,后面还讲解了不同语言的协程实现,以及把协程同子例程(subroutines)、线程(threads)、生成器(generators),尾调用互递归(mutual recursion)进行比较。
我发现自己的脑袋处于一种越来越懵逼的状态。
眼睛说我懂了,但是脑子说:不 ~ 你!不!懂!
这都是些啥玩意?我不就是想打个酱油(加深理解Android开发用的kotlin协程)吗?我为什么要看这些?
这些内容太过繁杂,需要延伸阅读的知识点也太多,况且就算我全搞懂了,好像跟我的初衷(加深理解Android开发用的kotlin协程)也已经背道而驰。主战场并不在这里,我不能消耗太多的弹药(精力)。
那我换个方向,看看大家是怎么理解Kotlin 协程的吧?
2. 中文文章的坑
在国内各大技术网站/论坛逛了一圈。花了几天的时间把高赞的文章基本看过一遍。
然后发现不知道是我的理解能力出问题了还是怎么地滴。理论上他们应该都在讲Kotlin协程吧,但是好像说的又不是同一个东西。
看完之后似乎更疑惑了。关注点稍微不注意就被带偏。
有些博主为了说明得形象生动,做了很多比喻。对于不同的人来说,徒增了理解的难度。
有些文章讲得太过精炼,这些自己原来都懂了,不懂的地方好像也没讲到,或者没有详细说明。
有些文章又很长,分为好几篇,完全读下来,有时候又很容易顾前不顾后。知识点铺得很广,关注点稍微不注意就容易被带偏。而且有些点可能是作者笔误的原因,无形中又增加了理解的难度。
有些文章是分析源码的,这个看起来更加吃力。我一边对着文章,一边打开Android Studio对着源码看,发现有些源码版本还不太一样,最后也是落得个一知半解。
最终前后花了大概一个星期的时间,读了很多文章。似乎获取了很多知识,但是细细一想,还是对Kotlin协程不甚了解。脑子里的概念很多,却是零散的一堆。
到底是哪里出问题了?
/ 官方文档 /
1. 英文阅读恐惧症
不知道有没有人跟我以前一样,看到大段大段的英文就头疼。
我称之为“英文阅读恐惧症”。这也是为什么一上来我没有选择直接看官方文档的原因。
其实在这之间我是有看过官方的文档,但是看的还是翻译后的中文版。
当我硬着头皮、完完整整地把官方的英文文档认真看过几遍(其实也就两遍)以后,发现官方英文文档 真香。
有句说句,Android开发者官网的英文文档不一定是精品,但是绝对是 错误最少的文档。
要克服“英文阅读恐惧症”,并没有什么捷径,就是 硬杠。
不过话说回来,英文技术文档,用的都是浅显易懂的单词,我在看的时候把词典打开,遇到不懂的单词就查一下。最后我发现,来来回回就那几个关键词。然后就越读越顺了。
2. 官方文档也有坑?
打开Android开发者官网,找到 GET STARTED 的Kotlin coroutines小节(https://developer.android.com/kotlin/coroutines)。我在下面截了个图。
这个GET STARTED 的Kotlin coroutines小节,其实总共就只有四个章节,每个章节也不太长,一字一句地读完,其实也不花多少时间。
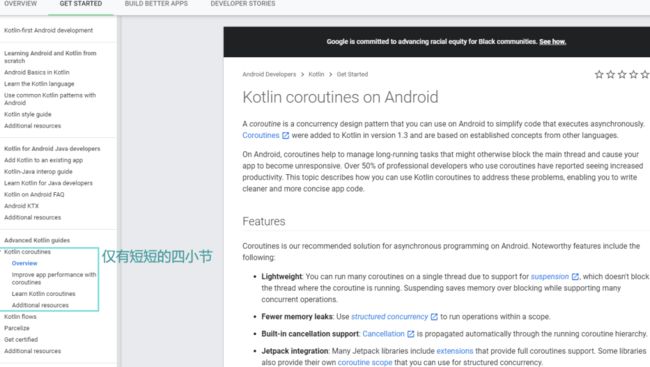
最前面两段话是一个概括说明:
A coroutine is a concurrency design pattern that you can use on Android to simplify code that executes asynchronously.
On Android, coroutines help to manage long-running tasks that might otherwise block the main thread and cause your app to become unresponsive.
关键字:
concurrency design pattern(并发设计模式)
asynchronously(异步的)
long-running tasks(耗时任务)
block the main thread(阻塞主线程)
我现在回过头来看的时候,发现这四个关键词挺重要的。
这就像一个人的自我介绍,你要用最简短,最直接的方式告诉别人,你的特点/特长是什么。
比如你说:我有钞能力!
然后大家都记住了,当遇到你的时候就会说:哦,他就是那个有钞能力的人!
同理,当你下次看到协程的时候,你就会说:哦,他就是用来处理异步、耗时任务的技术!
对于Android开发者来说,处理用户界面(UI)的主线程(Main Thread)是不能被阻塞的,否则反应到使用者(用户)那里的结果就是:这个APP怎么那么卡,点了半天都没反应!下场可想而知:卸了!
在Android开发里,所谓的异步、耗时任务我理解的就是下面这三种场景:
网络请求(也称网络I/O操作)
读写硬盘
CPU计算/耗时操作(列表排序,JSON解析,图片处理等)
所以当你碰到以上这些耗时任务 (long-running tasks)的时候,能够第一时间想到用Kotlin Coroutines来解决,那么说明你已经摸到一点门道了。
这里说句题外话:在Android中处理异步、耗时任务的技术,以前常用的应该是RxJava,或者Java提供的线程池Executors,以及Android的 AsyncTask。
既然已经有了好几种解决方案了,为什么还要整出这么一个Kotlin Coroutines的新东东呢?
这个问题个人认为没有那么复杂,至少不像当年教员想了十天十夜都想不通的那个问题。
Kotlin作为谷歌强力推荐的Android开发语言,Kotlin Coroutines是其语言生态系统里很重要的一环。
而且作为新语言,其后发优势也很明显:Kotlin Coroutines 协程处理异步任务,有效避开了前面几种方式里的很多坑(例如回调地狱(callback hell)),同时增加了很多新的功能/支持(Jetpack 支持,Retrofit(2.6.0以后) 支持)。
目的就是让Android开发者使用起来比较方便,提高开发效率(工资也…)。
既然Kotlin协程听起来那么厉害,为什么好像用的人不多呢?
个人觉得有两点原因:
原来使用Java开发Android的人还没习惯使用Kotlin来开发Android,更不用说进阶用法Kotlin Coroutines了。不过这点相信过个一年半载将有很大改观。
萌新Android开发者项目经验少,很多都没有经历过老Java Android开发前辈的苦难历程,自然很难对“回调地狱”这样的开发痛点感同身受,结果也基本上是左耳进右耳出。并且关于Kotlin协程的很多中文文章,写得异常繁琐。空有概念却串不到一起,不能融入到自己的知识体系里 。说白了,没有真正入门。
扯得有点远了,回到我的学习历程上来。
前面两段话概括介绍了kotlin协程后,接下来说的是它的四个特点(Features):
Lightweight(轻量(级))
Fewer memory leaks(更少的内存泄漏(风险))
Built-in cancellation support(内置取消支持)
Jetpack integration(jetpack框架集成(支持))
我看第一遍的时候也不甚了解,不过不要紧,脑子里有个粗略的概念就可以。
接下来就是官方文档的一个“坑”了,这里举的例子,是基于Jetpack的app架构的,也就是下面这个MVVM的app架构图:
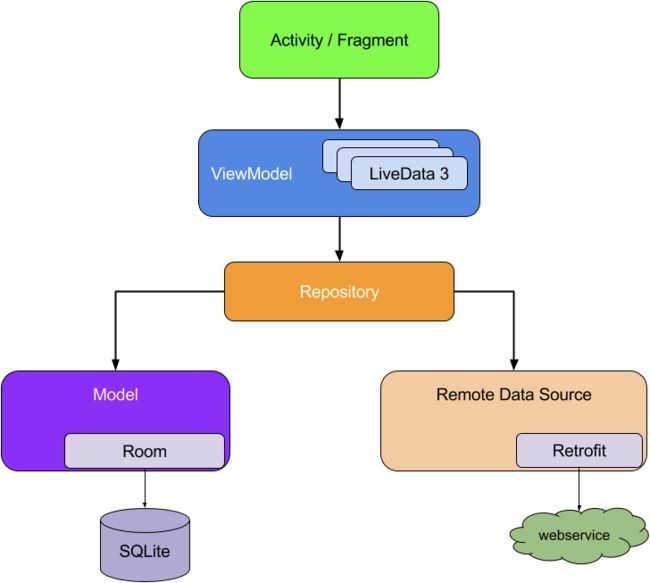
对于熟悉jetpack的MVVM 架构的人来说,并没有什么问题。但是对于那些不了解/不熟悉的人呢?真是要了老命了,又是一堆新的背景知识需要去了解。
对于官方文档这种“夹带私货”的“坑”,其实并不只是kotlin协程这一章节,在其他需要代码举例的地方,都有它的影子。
最刚开始的时候,对于这我也有点不爽,不过用了一段时间之后,还是逃不了“真香定律”——这个“坑”是值得一填的。
不过,就算现在不了解/不熟悉的人,这个“坑”也是可以暂时绕开的。这个例子里并没有太多涉及MVVM架构的东西,本质上来说,无非就是多嵌套几个类而已。
3. 我是这么阅读官方文档的
小节标题隐藏的秘密
其实,个人认为重点并不在代码的本身实现上,而是在这个文档要怎么用代码来表达kotlin协程的特点(Features)上,简单来说,重点在文章的那些小节标题上:
Dependency info(依赖信息)
Executing in a background thread(运行在后台线程上)
Use coroutines for main-safety(使用协程来(保证)主线程安全)
Handling exceptions(处理异常)
Dependency info
这个添加依赖的方法,就不多讲了。在build.gradle里添加相应的依赖就可以。
Executing in a background thread
还记得之前说的协程的作用吗——哦,他就是用来处理异步、耗时任务的技术!
而网络请求(也称网络I/O操作)就是最常碰到的异步、耗时任务。
这里用的例子,就是模拟一个网络请求(network request)的应用场景,实现的方法是LoginRepository类里面的makeLoginRequest()方法——用来处理一个登陆的网络请求。
既然是耗时任务,那么怎么放到后台线程运行呢?或者说,怎么用协程的方式,把这个makeLoginRequest()的网络请求方法,放到后台运行呢?
请看下面的代码:
class LoginViewModel(
private val loginRepository: LoginRepository
): ViewModel() {
fun login(username: String, token: String) {
// 启动一个新的 协程 ,并把这个协程放到 后台线程 运行
viewModelScope.launch(Dispatchers.IO) {
val jsonBody = "{ username: \"$username\", token: \"$token\"}"
loginRepository.makeLoginRequest(jsonBody)
}
}
}
文档里也说到,启动一个协程,用的就是 launch()这个方法:
launch is a function that creates a coroutine and dispatches the execution of its function body to the corresponding dispatcher.
launch(Dispatchers.IO)方法启动了一个协程,并且有一个Dispatchers.IO的参数。这个参数用来告诉系统(准确来说应该是协程框架在处理,不过为了避免多处使用“协程”这个关键词导致理解困难,我就用“系统”这个上帝视角来概括表达),新建立的这个协程(也就是launch()方法后面花括号里那一个代码块),交给Dispatchers.IO这个dispatcher(分发器)来执行。
其实在这里,Dispatchers.IO这个参数的本质意义,就是把跟在它后面的花括号里的协程代码块,放到“后台线程”(IO线程)去执行,这也就应验了这一小节的标题:Executing in a background thread。
文档里还讲了其他一些知识点,不过最重要的还是上面这些:怎么启动一个协程(launch()方法),并且如何告诉系统让这个协程在后台线程上执行(launch()方法加上Dispatchers.IO参数——launch(Dispatchers.IO))。
至于viewModelScope,ViewModel()等其他内容,暂且可以看成是标准用法,不用深究。
Use coroutines for main-safety
前面已经把耗时任务——网络请求方法makeLoginRequest()放到协程里(用launch()方法启动一个新协程),并且告诉系统让这个协程(花括号里的代码块)在后台线程上执行。似乎已经解决问题了?
One issue with the previous example is that anything calling makeLoginRequest needs to remember to explicitly move the execution off the main thread. Let’s see how we can modify the Repository to solve this problem for us.
这是上一小节Executing in a background thread的最后一段话,刚开始看我是有点懵的,不知道它要表达什么意思。后来才知道,它要表达的意思其实有两点:
1. 这里的耗时任务,也就是makeLoginRequest()方法,调用这个函数的程序员,一定要明确地把makeLoginRequest()方法放到后台线程里执行(off the main thread(远离主线程))。那么问题来了,如果不是我自己写的函数/方法,鬼知道makeLoginRequest()这个方法是不是耗时的啊?它又没有写在脸上,说:我是耗时函数/方法。
2. 第二点是比较隐晦的,既然是网络请求,那么肯定希望得到什么结果(返回值)吧,比如这个登录请求makeLoginRequest(),应该是希望拿到/返回用户信息吧?但是有没有发现,上面的示例代码里,在协程里的loginRepository.makeLoginRequest(jsonBody)这一行代码,是没有把它的返回值赋值给任何变量的。这一点也是我当时比较疑惑的地方,后面我才明白,示例代码这样的写法是拿不到返回值的。也就是说,系统把这个协程交给后台线程以后,并不关心后台线程那边发生了什么,这个协程在后台线程运行结束就没有然后了,它根本不能跟调用它的方法(这里就是login()方法)有任何后续的交互。说白了,就是launch()这个方法启动的协程,是称作“fire and forget”的一种模式。也就是刚才我们说的那样,系统把这个协程代码块交给了指定的线程,然后就没有然后了(forget)。所以似乎launch()这种启动协程的方法有点鸡肋?当然不是了,比如可以打印log啊(哈哈)。(这里先卖个关子,launch()方法启动协程是有它的应用场景的)。
而在这一小节Use coroutines for main-safety的目的,就是要解决上一小节提出的两个问题:
问题1:如何给一个耗时函数/方法的“脸上”写上“耗时”的标记;
问题2:怎么拿到网络请求的结果(返回值)。
先上完整的代码:
class LoginRepository(...) {
...
suspend fun makeLoginRequest(
jsonBody: String
): Result {
// Move the execution of the coroutine to the I/O dispatcher
return withContext(Dispatchers.IO) {
// Blocking network request code
}
}
}
class LoginViewModel(
private val loginRepository: LoginRepository
): ViewModel() {
fun login(username: String, token: String) {
// Create a new coroutine on the UI thread
viewModelScope.launch {
val jsonBody = "{ username: \"$username\", token: \"$token\"}"
// Make the network call and suspend execution until it finishes
val result = loginRepository.makeLoginRequest(jsonBody)
// Display result of the network request to the user
when (result) {
is Result.Success -> // Happy path
else -> // Show error in UI
}
}
}
}
上面贴出了这一小节的代码,但是为了能看得更清楚,我把makeLoginRequest()方法前后的变化截图方便对比:

在makeLoginRequest()方法的前面,多了个suspend关键字。
这个suspend关键字,解决了我们前面说的问题1:如何给一个耗时函数/方法的“脸上”写上“耗时”的标记;
凡是耗时函数/方法,就应该标上suspend关键字前缀,让别人知道它是个耗时函数/方法。并且它只能在协程里,或者另外一个同样标记了suspend关键字的函数/方法里调用(后面我们统称suspend标记的函数为“挂起函数”)。
那我怎么知道什么函数/方法才是标记了suspend关键字呢?
这一点,Android Studio已经帮你在编译的时候做好了,只要你不按照这个规则使用有suspend关键字的挂起函数,编译分分钟不给你过。就像下面这张截图的一样:

问题1:如何给一个耗时函数/方法的“脸上”写上“耗时”的标记问题,已经圆满解决了。接下来就要解决问题2:怎么拿到网络请求的结果(返回值)。

相比上一小节的loginRepository.makeLoginRequest(jsonBody),变成了现在的val result = loginRepository.makeLoginRequest(jsonBody)。拿到了这个网络请求makeLoginRequest()的返回值——赋值给result变量。问题似乎解决了?但是这是怎么解决的呢?
我们的目的是把耗时任务放在后台线程执行的哦!那系统怎么知道要把这个函数放在后台线程执行呢?
关键就在于withContext(Dispatchers.IO)这个函数。其实,withContext()也是一个挂起函数(还记得挂起函数的限制条件吗:要放到协程里,或者另外一个挂起函数里。),它的参数Dispatchers.IO跟在launch()方法里的Dispatchers.IO参数的作用本质上是一样的:就是告诉系统,我要把我身后大括号里的代码块,放到后台线程里执行。
到此,问题2似乎也已经圆满解决了——拿到网络请求的返回值,并且这个网络请求是在后台线程执行的。
读到这里的时候我也是有疑惑的,虽然这里把网络请求的结果赋值给了result变量,但是鬼知道,网络请求什么时候开始,又是什么时候结束呢?我又什么时候才能去使用这个result里的值呢?
后来我才意识到,协程的精髓就是这个问题的答案:协程的 挂起 和 恢复 。
协程(英语:coroutine)是计算机程序的一类组件,推广了协作式多任务的子程序,允许执行被挂起与被恢复。相对子例程而言,协程更为一般和灵活,但在实践中使用没有子例程那样广泛。协程更适合于用来实现彼此熟悉的程序组件,如协作式多任务、异常处理、事件循环、迭代器、无限列表和管道。
为了方便对比,我把前后的代码截图放在一起观察:

挂起函数之所以一定要在另外一个挂起函数里,或者在一个协程里执行,就是因为我们需要把这个挂起函数所在的协程挂起(suspend)(注意,被挂起的是协程,是协程!),以此来等待那些耗时操作结束,拿到返回值后,然后其所在的协程才会被恢复(resume),并且该协程剩余的代码块被继续执行。
如果在继续执行的过程中,再次执行到某个挂起函数,则重复上面的操作——
协程被挂起
–> 等待挂起函数在后台线程执行完毕
–> 获取返回值(如果有的话)
–> 协程被恢复
–> 协程剩余的代码块被当前线程(该例子就是主线程)继续执行。
看到这里,我才恍然大悟,困扰我很久的零散知识点,似乎被我第一次完整地串联到一起了。
我再尝试总结一下:
1. 挂起函数(suspend)之所以要在另外一个挂起函数里,或者在一个协程里执行,目的就是给它所在的协程提供一个“挂起点”,让系统知道在什么时候把这个协程挂起!(如果这个挂起函数在另外一个挂起函数里被调用,那么层层递归之后,最外面那个挂起函数,一定也是在某个协程里被调用的,对不?);这里再啰嗦一句,为什么一定要把协程挂起呢?为了不卡主线程(主线程不会干等着这个协程结束,而是把这个协程挂起以后,去继续执行其他代码)!
2. 既然协程会被挂起(suspend),那么它一定也会被恢复(resume)。什么时候会被恢复?——就是导致它被挂起的那个挂起函数执行完毕后(一般这个挂起函数会在另外一个线程里被执行,极有可能是一个后台线程),该协程将会从挂起点被恢复,继续往下执行该协程剩下的代码块(如果调用它的是主线程,则恢复后仍然在主线程执行剩下的协程代码块,所以在上面的例子代码里面,可以在这个协程里操作UI)。
when (result) {
is Result.Success -> // Happy path
else -> // Show error in UI(把错误信息显示在屏幕上)
}
3.协程不被挂起行不行?当然可以。示例代码里最早那个协程viewModelScope.launch(Dispatchers.IO) {...}的花括号里面,不就没有挂起函数么?那么这个协程在后台线程(Dispatchers.IO)执行完毕之后,就结束了,不会跟调用它的主线程有任何交互了。
4. 协程被“挂起”到底是什么意思?其实协程被挂起,就是说执行这个协程的线程是要从当前协程跳出去的。跳出去做什么?当然是继续去执行该协程外面的代码了。那如果跟这个例子一样,协程外面/后面似乎已经没有其他代码了,主线程干什么去了呢?当然还可以去刷新屏幕啊(Android主线程16.67ms左右刷新一次屏幕)。
到这里,我又产生了一个疑惑:这一小节的标题是Use coroutines for main-safety,也就是“使用协程保证主线程安全”,但是到现在,似乎没有多大的关联?
Once the withContext block finishes, the coroutine in login() resumes execution on the main thread with the result of the network request.
其实这个小节的最后一句话提到了。不过第一次读的时候我没有理解它的意思。
“主线程安全”的意思,说白了就是不要把耗时函数/方法放在主线程里执行,不能卡主线程,这个我们已经烂熟于胸了。
等等,这时候我似乎有点开窍了:“resumes execution on the main thread”(恢复到主线程继续执行),其实在这里系统(协程框架)已经默默地帮我做了一件事:切线程!从耗时函数所在的后台线程,切换到了主线程。

就类似于以前用回调函数写异步代码时,使用runOnUiThread()方法切换到主线程来更新UI一样。
在这里,根本不用显式地使用类似runOnUiThread()的方法来切线程,原来的协程在哪个线程执行的,从挂起点恢复之后,就自动切回到调用它的那个线程上!
妙啊!原来这就是所谓的“主线程安全”的意思——虽然看似耗时函数在主线程里被调用,但是实际上运行耗时函数的地方是后台线程!
Handling exceptions
最后一个小节是讲处理异常的,其实就是用try-catch的方式来处理。
class LoginViewModel(
private val loginRepository: LoginRepository
): ViewModel() {
fun makeLoginRequest(username: String, token: String) {
viewModelScope.launch {
val jsonBody = "{ username: \"$username\", token: \"$token\"}"
val result = try {
loginRepository.makeLoginRequest(jsonBody)
} catch(e: Exception) {
Result.Error(Exception("Network request failed"))
}
when (result) {
is Result.Success -> // Happy path
else -> // Show error in UI
}
}
}
}
比如网络请求失败,抛一个Result.Error(Exception("Network request failed")),然后在UI上把“Network request failed”这句话显示出来。用户就知道网络请求失败了。
try-catch处理异常也算中规中矩,也比较好理解。这里就不再展开,以后有机会再单独写一篇关于协程异常处理的文章。
Overview小节的总结
如果不考虑协程更进阶一点的用法,其实在Overview这一小节所讲到的知识点,已经把协程的基本用法讲明白了。
当然,jetpack框架的MVVM架构这个坑,也是需要花点时间去填的。这应该是大势所趋,作为Android开发者,个人觉得这个坑值得花时间去填。
我粗略地统计了一下,本小节中提到次数较多的关键字有:thread(32次),scope (13次), suspend(7次),blocking&block(15次),launch(9次),Dispatchers(6次), withContext(5次)。
既然thread(32次)是提到最多的关键字,那么我们其实可以猜测:Kotlin Coroutines协程肯定和线程thread有关系。大胆点甚至可以说,Android 里的Kotlin Coroutines协程,是建立在线程thread基础上的(一个框架)。
虽然很多文章都会把用线程和协程作为对比来说明,但是至少目前的kotlin协程,协程和线程不是同一个维度的,协程是建立在线程基础上的一个线程框架。也就是说,kotlin协程的运行/执行,是离不开线程的,所以我们前面才会有协程“切线程”这样的操作说法。
英文关键词
其实scope这个关键词也出现了13次,从字面上理解,scope-范围?就是协程的作用范围。示例程序中就用viewModelScope.launch() {...}的方式来启动一个新的协程。其实在下个章节的文章Improve app performance with Kotlin coroutines(https://developer.android.com/kotlin/coroutines/coroutines-adv)中会详细介绍关于scope的 CoroutineScope接口。在这里我们可以先不用深究它,只要记住每个协程都会对应一个scope即可。
不知道大家有没有注意到,英文文章在表达的时候,使用的关键字都很单一直接,基本不会变。所以你看这个小节里,重要的关键字,出现的频率都很高!
不像翻译过来的中文译文,同一个英文单词,可能会翻译成两个中文词,例如Context,有些地方翻译成环境,有些地方翻译成上下文。对于读者来说,经常会搞不清到底是不是一个意思。结果可能就是越看越懵逼。
我发现,在阅读的时候用笔随意记一些自己认为重要的内容,并且用红笔勾画出一些关键词,对加深理解和记忆有意想不到的帮助。
虽然可能当时不甚理解,但是当过了几天再回过头来复习的时候,这张笔记真是让我爱不释手。

其他小节的开始
其实入门是最难的,一旦入门了,后面的知识点学习都是水到渠成的事情。
比如后面的小节——Improve app performance with Kotlin coroutines里面会提到除了Dispatchers.IO以外,还有Dispatchers.Main和Dispatchers.Default两种Dispatchers(其实还有一个Dispatchers.Unconfined)。
在前面我们理解了Dispatchers.IO是把协程或者挂起函数放到后台线程上执行,那么其他相应的Dispatchers肯定也是放到对应的线程上执行的嘛。
Inside the body of get, call withContext(Dispatchers.IO) to create a block that runs on the IO thread pool.
– Improve app performance with Kotlin coroutines
这是在 Improve app performance with Kotlin coroutines小节里关于Dispatchers.IO的一段说明,很明确地说了,对于Dispatchers.IO这个Dispatcher,协程框架使用的就是IO线程池(IO thread pool)来实现的。这也从侧面说明了——kotlin 协程是建立在线程上的一个框架。
还有提到的CoroutineScope接口,有这么一句话:
A CoroutineScope keeps track of any coroutine it creates using launch or async.
其实也很好理解,Android一个很重要的概念就是生命周期。同理,协程的建立和销毁,肯定需要某种方式来进行/约束,而CoroutineScope就提供了这个操作的空间/方法,所以上面那句话才会说“keeps track of any coroutine”(CoroutineScope用来追踪任何/所有的协程)。
除此之外,还提到了Job和CoroutineContext。这些也都是为了更灵活地使用协程提供的工具/方法。
以及后面一个小节Learn how to use Kotlin coroutines,将会提供一些学习路径(Pathway)。里面会有一些实际的工程例子(Use Kotlin Coroutines in your Android App)。

这些官方的工程例程都一直在更新,不用担心技术陈旧学了就被淘汰。
这个例子是让你把一个原来使用Java Executors线程池实现的网路请求,并用回调函数的方式更新数据,改造成使用Kotlin协程的方式来实现。
该例程代码量不多,但是涉及的知识面还挺广,值得一看。
//回调函数的方式实现数据更新
repository.refreshTitleWithCallbacks(object : TitleRefreshCallback {
override fun onCompleted() {
_spinner.postValue(false)
}
override fun onError(cause: Throwable) {
_snackBar.postValue(cause.message)
_spinner.postValue(false)
}
})
// 协程的方式实现数据更新,并且可以做到异常处理
fun refreshTitle() {
launchDataLoad {
repository.refreshTitle()
}
}
private fun launchDataLoad(block: suspend () -> Unit) {
viewModelScope.launch {
try {
_spinner.value = true
block()
} catch (error: TitleRefreshError) {
_snackBar.value = error.message
} finally {
_spinner.value = false
}
}
}
而且这个例程里还会有些值得借鉴的技巧,比如Use Kotlin Coroutines in your Android App这个codelab里面,就有如何通过Retrofit使用local json file的方式来模拟网络测试交互,这样就省了搭建一个网络交互环境的工作量,开发起来也很高效。
以及如何给协程写单元测试等技巧,这些都会在学习路径(Pathway)里有提及,个人认为还是值得深入发掘的。
/ 总结 /
kotlin 协程与 jetpack框架的WorkManager、Room,以及Retrofit(2.6.0以后)一起使用,可以实现代码清晰,易于维护的工程项目。当然,这些都是kotlin 协程的进阶用法了,本文就不再展开。
不过万变不离其宗,无论kotlin协程有多少使用技巧,它的本质还是那些:
1. Kotlin 协程在Android开发里,就是一个建立在线程thread上的一个线程框架,它的执行需要依赖线程;
2. suspend 标注的挂起函数,是Kotlin 协程的灵魂所在,协程的挂起和恢复都与他直接相关。没用到挂起函数的协程,是没有灵魂的协程;
Kotlin’s concept of suspending function provides a safer and less error-prone abstraction for asynchronous operations than futures and promises.
– Kotlin Coroutines Guide
Builders.common.kt 源码就三个函数——launch, async, withContext,他们都跟协程的创建(Builder)相关,值得仔细阅读。
从本质来说,程序是人类和计算机之间交互的桥梁。所以无论是现在的用协程写异步程序,还是之前回调方式写异步程序,计算机(或者说编译器)根本就不在意,反正最终它都能看得懂。在意的其实还是人类(程序员),所以我觉得Kotlin Coroutines Guide上面那句话用得很好——safer and less error-prone——使用kotlin协程,让程序员不会那么容易犯错(BUG)。
真正了解Kotlin协程的本质后,我发现自己才算真正入门。其他相关的知识点学起来也比较顺畅了。
目前来说,日常的Android开发,Kotlin协程已经可以用得很顺手了,达到了自己最开始设立的目标。如果以后有机会,再深入源码进行学习,也不失为一种乐趣。
推荐阅读:
我的新书,《第一行代码 第3版》已出版!
Jetpack新成员,Paging3从吐槽到真香
Android 11新特性,Scoped Storage又有了新花样
欢迎关注我的公众号
学习技术或投稿
![]()

长按上图,识别图中二维码即可关注