【论文粗读】(NeurIPS 2020) SwAV:对比聚类结果的无监督视觉特征学习
题目
《Unsupervised Learning of Visual Features by Contrasting Cluster Assignments》
第一作者:Mathilde Caron,Inria & Facebook AI Research
会议:NeurIPS 2020
SwAV 全称:Swapping Assignments between multiple Views of the same image
摘要
无监督图像表示(Unsupervised image representation)显著地缩小了和有监督预训练的差距,特别是对比学习方法的最新成果。这些对比学习方法通常在线工作,依赖于大量显式的成对特征比较,计算量比较大。
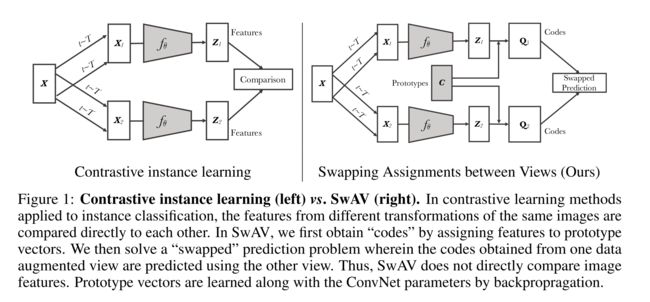
本文提出的在线算法SwAV不需要成对比较,它比较不同 view 下的聚类结果(clustering assignment)而不是直接对比特征。具体来说,SwAV 对数据进行聚类的同时,加强对同一图像的不同增强(或“视图”)产生的聚类结果之间的一致性,而不是像对比学习中那样直接比较特征。简单地说,使用了 交叉(swapped)预测机制,同一图片通过数据增强后得到两个 views,然后 SwAV 通过 view A 的 code(就是 cluster assignment)预测 view B 的representation,通过 view B 的 code 预测 view A 的representation。
方法可以通过大批量和小批量进行训练,并可以扩展到无限数量的数据。在此之前也有 Deep Cluster 这样基于聚类的深度无监督学习方法,但是要求对整个数据集计算 cluster assignment 作为模型训练的label, 计算开销很大, 而 SwAV 则是在线计算 code,然后保持同一批图片不同视角下的 code 一致。与以往的对比方法相比,此方法由于不需要较大的存储库和特殊的动量网络而具有更高的存储效率。
除了引入聚类以外,还提出了一种新的数据扩充策略: 多裁剪(multi-crop),以往论文证实了更多的 views 可以提高自监督学习模型的效果,multi-crop 用 smaller-size 的图像提高 views 的数量而不增加内存和计算需求,直接对缩放尺寸的图像操作可能会给特征带来 bias,但这种 bias 可以通过不同尺寸的混合来避免。
通过使用ResNet-50在ImageNet上实现75.3%的top-1准确率,以及在所有考虑的转移任务上超过有监督预训练,验证了我们的发现。
方法
Online clustering
SwAV 首先通过把特征 assign 到 prototype 来得到 codes,然后交叉预测不同 views 的 codes。
损失函数的定义是:
![]()
这里的 l ( z , q ) l(z,q) l(z,q) 衡量特征 z 和 code q 之间的关系,具体来说使用 code 和 softmax 后的z, c 之间的交叉熵来计算,公式表示为:

Multi-crop: Augmenting views with smaller images
如图所示,Multi-crop 策略包括了:
- 两个标准的
RandomResizedCrop; - V个额外的小views。
损失函数为:
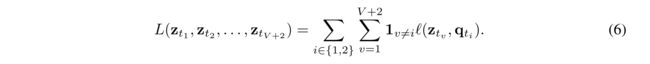
例如对于ImageNet数据集,如下的代码中:nmb_crops = [2, 6] 表示两个标准随机裁剪和六个小views;size_crops = [224, 96]表示标准 RandomResizedCrop 后得到的尺寸为224224,小views经过 RandomResizedCrop 后得到的尺寸为9696;min_scale_crops = [0.14, 0.05], max_scale_crops = [1.00, 0.14] 表示标准 RandomResizedCrop 时的尺度为(0.14, 1.00),小views在RandomResizedCrop时的尺度为(0.05, 0.14)。
实验
Evaluating the unsupervised features on ImageNet
如图是自监督模型预训练后在线性分类器测试的结果,SwAV 进一步拉近了自监督学习方法和有监督学习的距离,和有监督学习的准确率只差了1.2%,这里SwAV在大的batch(4096)上训练了 800 epochs。
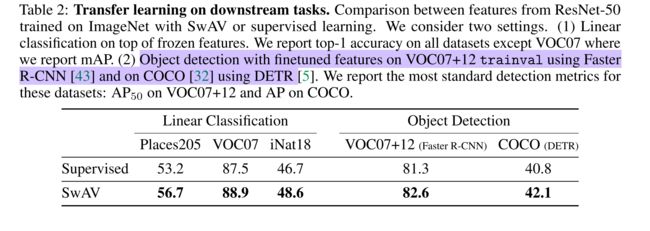
Transferring unsupervised features to downstream tasks
如图是SwAV用 ResNet50 在ImageNet 上预训练的模型迁移到分类和目标检测问题上。在分类问题上只训练顶部的线性分类器,在目标检测问题上用预训练模型初始化再 fine-tune。在这些问题上都取得了超过有监督训练的效果。
Training with small batches
比较不同自监督学习方法在 batch size为256时的表现,SwAV 仍然是 SOTA 的。
……
小结
SwAV 使用了聚类带来的额外先验信息,并增加了 Multi-crop 的数据增强策略,所以效果一定是好的。
Reference:
项目源码:GitHub源码指路
知乎:知乎解析
A u t h o r : C h i e r Author: Chier Author:Chier