k8s-8_-rook介绍与使用
k8s-8_Kubernetes-rook介绍与使用
1.rook简介
一、容器的持久化存储
1. 容器的持久化存储是保存容器存储状态的重要手段,存储插件会在容器里挂载一个基于网络或者其他机制的远程数据卷,使得在容器里创建的文件,实际上是保存在远程存储服务器上,或者以分布式的方式保存在多个节点上,而与当前宿主机没有任何绑定关系。这样,无论你在其他哪个宿主机上启动新的容器,都可以请求挂载指定的持久化存储卷,从而访问到数据卷里保存的内容。
2. 由于 Kubernetes 本身的松耦合设计,绝大多数存储项目,比如 Ceph、GlusterFS、NFS 等,都可以为 Kubernetes 提供持久化存储能力。
二、Rook
1. 简介
● Rook 是一个开源的cloud-native storage编排, 提供平台和框架;为各种存储解决方案提供平台、框架和支持,以便与云原生环境本地集成。
● Rook 将存储软件转变为自我管理、自我扩展和自我修复的存储服务,它通过自动化部署、引导、配置、置备、扩展、升级、迁移、灾难恢复、监控和资源管理来实现此目的。
● Rook 使用底层云本机容器管理、调度和编排平台提供的工具来实现它自身的功能。
● Rook 目前支持Ceph、NFS、Minio、EdgeFS等
2. 架构
- Rook使用Kubernetes原语使Ceph存储系统能够在Kubernetes上运行。

● 随着Rook在Kubernetes集群中运行,Kubernetes应用程序可以挂载由Rook管理的块设备和文件系统,或者可以使用S3 / Swift API提供对象存储。Rook oprerator自动配置存储组件并监控群集,以确保存储处于可用和健康状态。
● Rook oprerator是一个简单的容器,具有引导和监视存储集群所需的全部功能。oprerator将启动并监控ceph monitor pods和OSDs的守护进程,它提供基本的RADOS存储。oprerator通过初始化运行服务所需的pod和其他组件来管理池,对象存储(S3 / Swift)和文件系统的CRD。
● oprerator将监视存储后台驻留程序以确保群集正常运行。Ceph mons将在必要时启动或故障转移,并在群集增长或缩小时进行其他调整。oprerator还将监视api服务请求的所需状态更改并应用更改。
● Rook oprerator还创建了Rook agent。这些agent是在每个Kubernetes节点上部署的pod。每个agent都配置一个Flexvolume插件,该插件与Kubernetes的volume controller集成在一起。处理节点上所需的所有存储操作,例如附加网络存储设备,安装卷和格式化文件系统。

一、ceph基本概念
1. 功能
Ceph是一个可靠、自动重均衡、自动恢复的分布式存储系统,根据场景划分可以将Ceph分为三大块,分别是对象存储、块设备和文件系统服务。
2. 优点
● 高性能:摒弃了传统的集中式存储元数据寻址的方案,采用CRUSH算法,数据分布均衡,并行度高,能够实现各类负载的副本放置规则,能够支持上千个存储节点的规模,支持TB到PB级的数据。
● 高可用性:副本数可以灵活控制。支持故障域分隔,数据强一致性。多种故障场景自动进行修复自愈。没有单点故障,自动管理,自动扩充副本数。
● 高可扩展性:去中心化。扩展灵活。随着节点增加而线性增长。
● 特性丰富:支持三种存储接口:块存储(得到的是硬盘)、文件存储(目录)、对象存储(对接的是一个挂载的目录,后端会把数据打散,采用键值对形式存储)。支持自定义接口,支持多种语言驱动。
3. Ceph核心组件

● Monitors(管理服务):监视器,维护集群状态的多种映射,同时提供认证和日志记录服务,包括有关monitor 节点端到端的信息,其中包括 Ceph 集群ID,监控主机名和IP以及端口。并且存储当前版本信息以及最新更改信息,通过 "ceph mon dump"查看 monitor map。
● MDS(Metadata Server):Ceph 元数据,主要保存的是Ceph文件系统的元数据。注意:ceph的块存储和ceph对象存储都不需要MDS。
● OSD:即对象存储守护程序,但是它并非针对对象存储。是物理磁盘驱动器,将数据以对象的形式存储到集群中的每个节点的物理磁盘上。OSD负责存储数据、处理数据复制、恢复、回(Backfilling)、再平衡。完成存储数据的工作绝大多数是由 OSD daemon 进程实现。在构建 Ceph OSD的时候,建议采用SSD 磁盘以及xfs文件系统来格式化分区。此外OSD还对其它OSD进行心跳检测,检测结果汇报给Monitor
● RADOS:Reliable Autonomic Distributed Object Store。RADOS是ceph存储集群的基础。在ceph中,所有数据都以对象的形式存储,并且无论什么数据类型,RADOS对象存储都将负责保存这些对象。RADOS层可以确保数据始终保持一致。
● librados:librados库,为应用程度提供访问接口。同时也为块存储、对象存储、文件系统提供原生的接口。
● RADOSGW:网关接口,提供对象存储服务。它使用librgw和librados来实现允许应用程序与Ceph对象存储建立连接。并且提供S3 和 Swift 兼容的RESTful API接口。
● RBD:块设备,它能够自动精简配置并可调整大小,而且将数据分散存储在多个OSD上。
● CephFS:Ceph文件系统,与POSIX兼容的文件系统,基于librados封装原生接口。
4. Ceph 数据存储过程
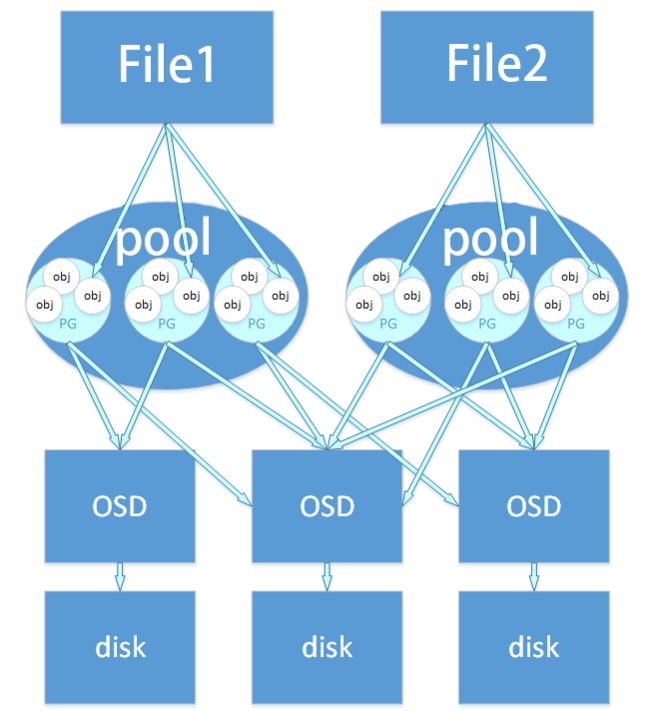
● File : 用户需要存储或者访问的文件。当上层应用向RADOS存入size很大的file时,需要将file切分成统一大小的一系列object(最后一个的大小可以不同)进行存储。
● Object : 无论使用哪种存储方式(对象、块、文件系统),存储的数据都会被切分成Objects。每个对象都会有一个唯一的OID,由ino(文件的File ID,在全局唯一标识每一个文件)与ono(分片的编号,比如:一个文件FileID为A,它被切成了两个对象,那么这两个文件的oid则为A0与A1)生成。
● pool是ceph存储数据时的逻辑分区,它起到namespace的作用。其他分布式存储系统。每个pool包含一定数量的PG,PG里的对象被映射到不同的OSD上,因此pool是分布到整个集群的。除了隔离数据,我们也可以分别对不同的POOL设置不同的优化策略,比如副本数、数据清洗次数、数据块及对象大小等。
● PG(Placement Group):对object的存储进行组织和位置映射。PG和object之间是“一对多”映射关系。PG和OSD之间是“多对多”映射关系。
● OSD: 即object storage device,OSD的数量事实上也关系到系统的数据分布均匀性,因此其数量不应太少
5. Ceph中的寻址映射过程
● File -> object映射
● Object -> PG映射,hash(oid) & mask -> pgid(哈希算法)
● PG -> OSD映射,CRUSH算法
6. RADOS分布式存储相较于传统分布式存储的优势
● 将文件映射到object后,利用Cluster Map 通过CRUSH 计算而不是查找表方式定位文件数据存储到存储设备的具体位置。优化了传统文件到块的映射和Block MAp的管理。
● RADOS充分利用OSD的智能特点,将部分任务授权给OSD,最大程度地实现可扩展
7. cephfs与ceph rbd对比
| CephFS 文件存储 | Ceph RBD块存储 | |
|---|---|---|
| 优点: | 读取延迟低,I/O带宽表现良好,尤其是block size较大一些的文件灵活度高,支持k8s的所有接入模式 | 1. 读取延迟低,I/O带宽表现良好,尤其是block size较大一些的文件 1. I/O带宽表现良好2. 灵活度高,支持k8s的所有接入模式 2. 读写延迟都很低3. 支持镜像快照,镜像转储4. 支持k8s动态供给 |
| 缺点: | 写入延迟相对较高且延迟时间不稳定,不支持动态供给 | 不支持多节点挂载 |
| 适用场景: | 适用于要求灵活度高(支持k8s多节点挂载特性),对I/O延迟不甚敏感的文件读写操作,以及非海量的小文件存储支持.例如作为常用的应用/中间件挂载存储后端. | 对I/O带宽和延迟要求都较高,且无多个节点同时读写数据需求的应用,例如数据库 |
二、部署ceph集群
github地址,一键部署集群
https://github.com/luckman666/deploy_ceph_cluster_luminous_docker
环境准备
| 主机名 | IP | 配置 | 磁盘空间 |
|---|---|---|---|
| ceph1 | 192.168.10.131 | 4C4G | sda(50G,安装系统)sdb(50G,不格式化) sdc(50G,不格式化) |
| ceph2 | 192.168.10.132 | 4C4G | sda(50G,安装系统) sdb(50G,不格式化) sdc(50G,不格式化) |
| ceph3 | 192.168.10.132 | 4C4G | sda(50G,安装系统) sdb(50G,不格式化) sdc(50G,不格式化) |

1、主机名
#三个节点分别配置主机名
[root@localhost ~]# hostnamectl set-hostname ceph1
[root@localhost ~]# hostnamectl set-hostname ceph2
[root@localhost ~]# hostnamectl set-hostname ceph3
2、关闭防火墙、核心防护
[root@ceph01 ~]# systemctl stop firewalld
[root@ceph01 ~]# systemctl disable firewalld
[root@ceph01 ~]# setenforce 0
[root@ceph01 ~]# sed -i '7s/enforcing/disabled/' /etc/selinux/config
3、配置hosts
[root@ceph01 ~]# vim /etc/hosts
192.168.0.68 ceph1
192.168.0.71 ceph2
192.168.0.189 ceph3

2. clone项目脚本,赋予执行权限
# git clone https://github.com/luckman666/deploy_ceph_cluster_luminous_docker.git && chmod -R 755 deploy_ceph_cluster_luminous_docker

3. 配置base.config基本信息

4. 执行安装脚本
# ./ceph_luminous.sh
脚本内容

执行完成一个阶段,他会自动执行第二个节点


ceph节点信息

安装完毕

5. 查看安装日志信息
`# tail -f setup.log`
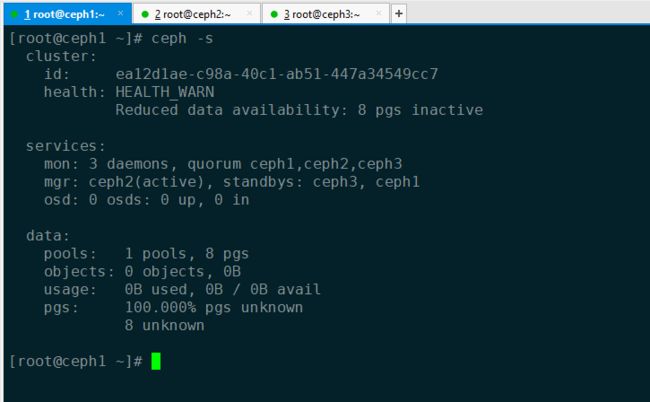
6. 验证
`# ceph -s`
三、k8s连接ceph
1. k8s所有节点安装ceph客户端
-
添加阿里云repo源
# vim /etc/yum.repos.d/ceph.repo [ceph-nautilus] name=ceph-luminous baseurl=https://mirrors.aliyun.com/ceph/rpm-nautilus/el7/x86_64/ gpgcheck=0 [ceph-noarch] name=cephnoarch baseurl=https://mirrors.aliyun.com/ceph/rpm-nautilus/el7/noarch/ gpgcheck=0

2. 查看可用版本,与ceph服务端版本保持一致
yum list ceph --showduplicates | sort -r`
3. 安装指定版本ceph
`# yum install -y ceph-common-14.2.6`
4. 添加配置文件,验证连接
- ceph进入到/data/ceph/etc目录将 ceph.client.admin.keyring和ceph.conf两个配置文件传送到ceph客户端服务器的/etc/ceph目录下

`# scp /data/ceph/etc/ceph.client.admin.keyring 192.168.10.101:/etc/ceph`
`# scp /data/ceph/etc/ceph.conf 192.168.10.101:/etc/ceph`
- k8s查看ceph信息
`# ceph -s`
3.rook部署
官方文档链接
https://www.rook.io/docs/rook/v1.2/ceph-quickstart.html
1. clone项目到本地
# git clone --single-branch --branch release-1.2 https://github.com/rook/rook.git
# cd cluster/examples/kubernetes/ceph

2. 创建rook-ceph名称空间
kubectl create namespace rook-ceph
3. apply资源清单文件
# kubectl apply -f common.yaml
# kubectl apply -f operator.yaml
# kubectl apply -f cluster.yaml(cluster至少需要三个work节点)


4. 创建ceph客户端连接工具
kubectl apply -f toolbox.yaml
- 进入容器bash环境
kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l "app=rook-ceph-tools" -o jsonpath='{.items[0].metadata.name}') bash
- 查看集群状态
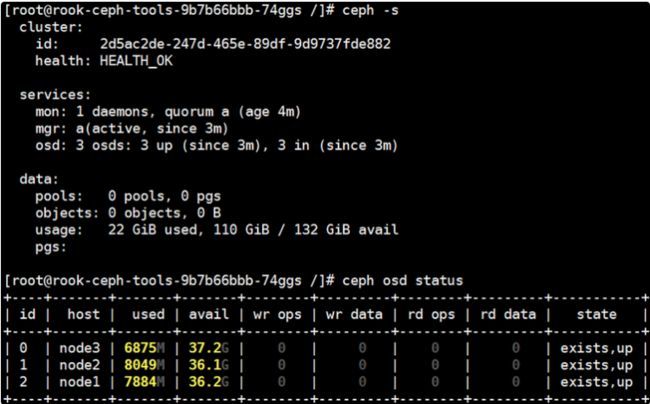

- 使用完成后删除部署
`kubectl -n rook-ceph delete deployment rook-ceph-tools`
5. dashboard部署
- 查看svc信息,默认使用clusterip

- 创建nodeport模式https代理
kubectl apply -f dashboard-external-https.yaml

- 访问测试

- 获取默认密码
kubectl -n rook-ceph get secret rook-ceph-dashboard-password -o jsonpath="{['data']['password']}" | base64 --decode && echo
6. 使用Prometheus监控
相关文档
https://www.rook.io/docs/rook/v1.2/ceph-monitoring.html
[外链图片转存中...(img-63wVv0KF-1660039217649)]
- 访问测试
[外链图片转存中...(img-ed146VXj-1660039217649)]
- 获取默认密码
```shell
kubectl -n rook-ceph get secret rook-ceph-dashboard-password -o jsonpath="{['data']['password']}" | base64 --decode && echo
6. 使用Prometheus监控
相关文档
https://www.rook.io/docs/rook/v1.2/ceph-monitoring.html