Future&ForkJoin源码解析
任务性质类型
CPU密集型(CPU-bound)
CPU密集型也叫计算密集型,指的是系统的硬盘、内存性能相对CPU要好很多,此时,系统运作大部分的状况是CPU Loading 100%,CPU要读/写I/O(硬盘/内存),I/O在很短的时间就可以完成,而CPU还有许多运算要处理,CPU Loading很高。
在多重程序系统中,大部份时间用来做计算、逻辑判断等CPU动作的程序称之CPU bound。例如一个计算圆周率至小数点一千位以下的程序,在执行的过程当中绝大部份时间用在三角函数和开根号的计算,便是属于CPU bound的程序。
CPU bound的程序一般而言CPU占用率相当高。这可能是因为任务本身不太需要访问I/O设备,也可能是因为程序是多线程实现因此屏蔽掉了等待I/O的时间。
线程数一般设置为:
线程数 = CPU核数+1 (现代CPU支持超线程)
IO密集型(I/O bound)
IO密集型指的是系统的CPU性能相对硬盘、内存要好很多,此时,系统运作,大部分的状况是CPU在等I/O (硬盘/内存) 的读/写操作,此时CPU Loading并不高。
I/O bound的程序一般在达到性能极限时,CPU占用率仍然较低。这可能是因为任务本身需要大量I/O操作,而pipeline做得不是很好,没有充分利用处理器能力。
线程数一般设置为:
线程数 = ((线程等待时间+线程CPU时间)/线程CPU时间 )* CPU数目
CPU密集型 vs IO密集型
我们可以把任务分为计算密集型和IO密集型。
计算密集型任务的特点是要进行大量的计算,消耗CPU资源,比如计算圆周率、对视频进行高清解码等等,全靠CPU的运算能力。这种计算密集型任务虽然也可以用多任务完成,但是任务越多,花在任务切换的时间就越多,CPU执行任务的效率就越低,所以,要最高效地利用CPU,计算密集型任务同时进行的数量应当等于CPU的核心数。
计算密集型任务由于主要消耗CPU资源,因此,代码运行效率至关重要。Python这样的脚本语言运行效率很低,完全不适合计算密集型任务。对于计算密集型任务,最好用C语言编写。
第二种任务的类型是IO密集型,涉及到网络、磁盘IO的任务都是IO密集型任务,这类任务的特点是CPU消耗很少,任务的大部分时间都在等待IO操作完成(因为IO的速度远远低于CPU和内存的速度)。对于IO密集型任务,任务越多,CPU效率越高,但也有一个限度。常见的大部分任务都是IO密集型任务,比如Web应用。
IO密集型任务执行期间,99%的时间都花在IO上,花在CPU上的时间很少,因此,用运行速度极快的C语言替换用Python这样运行速度极低的脚本语言,完全无法提升运行效率。对于IO密集型任务,最合适的语言就是开发效率最高(代码量最少)的语言,脚本语言是首选,C语言最差。
一、什么是 Fork/Join 框架?
Fork/Join 框架是 Java7 提供了的一个用于并行执行任务的框架, 是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架。
Fork 就是把一个大任务切分为若干子任务并行的执行,Join 就是合并这些子任务的执行结果,最后得到这个大任务的结果。比如计算1+2+…+10000,可以分割成 10 个子任务,每个子任务分别对 1000 个数进行求和,最终汇总这 10 个子任务的结果。如下图所示:

Fork/Jion特性:
- ForkJoinPool 不是为了替代 ExecutorService,而是它的补充,在某些应用场景下性能比 ExecutorService 更好。(见 Java Tip: When to use ForkJoinPool vs ExecutorService )
- ForkJoinPool 主要用于实现“分而治之”的算法,特别是分治之后递归调用的函数,例如 quick sort 等。
- ForkJoinPool 最适合的是计算密集型的任务,如果存在 I/O,线程间同步,sleep() 等会造成线程长时间阻塞的情况时,最好配合使用 ManagedBlocker。
二、工作窃取算法
工作窃取(work-stealing)算法是指某个线程从其他队列里窃取任务来执行。
我们需要做一个比较大的任务,我们可以把这个任务分割为若干互不依赖的子任务,为了减少线程间的竞争,于是把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应,比如A线程负责处理A队列里的任务。但是有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务等待处理。干完活的线程与其等着,不如去帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。而在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。
工作窃取算法的优点是充分利用线程进行并行计算,并减少了线程间的竞争,其缺点是在某些情况下还是存在竞争,比如双端队列里只有一个任务时。并且消耗了更多的系统资源,比如创建多个线程和多个双端队列。
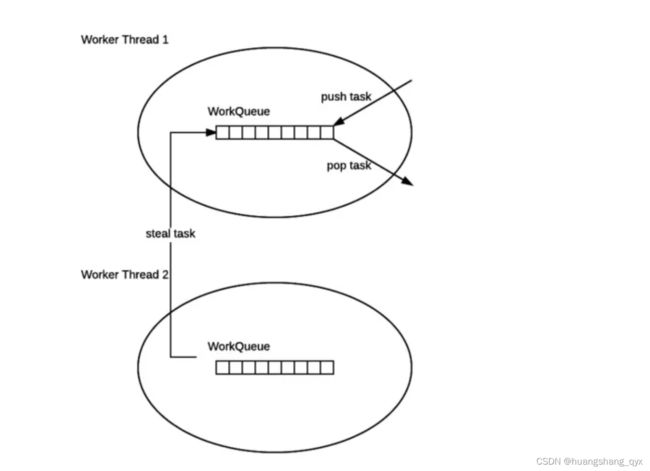
- ForkJoinPool 的每个工作线程都维护着一个工作队列(WorkQueue),这是一个双端队列(Deque),里面存放的对象是任务 (ForkJoinTask)。
- 每个工作线程在运行中产生新的任务(通常是因为调用了 fork())时,会放入工作队列的队尾,并且工作线程在处理自己的工作 队列时,使用的是 LIFO 方式,也就是说每次从队尾取出任务来执行。
- 每个工作线程在处理自己的工作队列同时,会尝试窃取一个任务(或是来自于刚刚提交到 pool 的任务,或是来自于其他工作线 程的工作队列),窃取的任务位于其他线程的工作队列的队首,也就是说工作线程在窃取其他工作线程的任务时,使用的是 FIFO 方式。
- 在遇到 join() 时,如果需要 join 的任务尚未完成,则会先处理其他任务,并等待其完成。
- 在既没有自己的任务,也没有可以窃取的任务时,进入休眠。
三、fork/join的使用
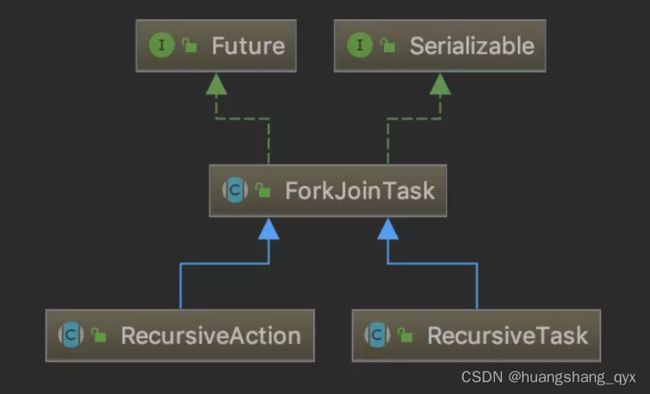
ForkJoinTask:我们要使用 ForkJoin 框架,必须首先创建一个 ForkJoin 任务。它提供在任务中执行 fork() 和 join() 操作的机制,通常情况下我们不需要直接继承 ForkJoinTask 类,而只需要继承它的子类,Fork/Join 框架提供了以下两个子类:
RecursiveAction:用于没有返回结果的任务。(比如写数据到磁盘,然后就退出了。 一个RecursiveAction可以把自己的工作分割成更小的几块, 这样它们可以由独立的线程或者CPU执行。 我们可以通过继承来实现一个RecursiveAction)
RecursiveTask :用于有返回结果的任务。(可以将自己的工作分割为若干更小任务,并将这些子任务的执行合并到一个集体结果。 可以有几个水平的分割和合并)
CountedCompleter: 在任务完成执行后会触发执行一个自定义的钩子函数
ForkJoinPool :ForkJoinTask 需要通过 ForkJoinPool 来执行,任务分割出的子任务会添加到当前工作线程所维护的双端队列中,进入队列的头部。当一个工作线程的队列里暂时没有任务时,它会随机从其他工作线程的队列的尾部获取一个任务。
使用场景示例:
定义fork/join任务,如下示例,生成一个数组,然后求和。
public class LongSum extends RecursiveTask{ //获取逻辑处理器数量 static final int NCPU = Runtime.getRuntime().availableProcessors(); //任务拆分的最小阀值 static final int SEQUENTIAL_THRESHOLD = 10; int low; int high; int[] array; LongSum(int[] arr, int lo, int hi) { array = arr; low = lo; high = hi; } protected Long compute() { //任务被拆分到足够小时,则开始求和 if (high - low <= SEQUENTIAL_THRESHOLD) { long sum = 0; for (int i = low; i < high; ++i) { sum += array[i]; } return sum; } else {//如果任务任然过大,则继续拆分任务,本质就是递归拆分 int mid = low + (high - low) / 2; LongSum left = new LongSum(array, low, mid); LongSum right = new LongSum(array, mid, high); left.fork(); right.fork(); long rightAns = right.join(); long leftAns = left.join(); return leftAns + rightAns; } } public static void main(String[] args) throws Exception { int[] array = new int[1000]; for (int i = 0; i < 1000; i++) { array[i] = i; } System.out.println("cpu-num:" + NCPU); //采用fork/join方式将数组求和任务进行拆分执行,最后合并结果 LongSum ls = new LongSum(array, 0, array.length); ForkJoinPool fjp = new ForkJoinPool(4); //使用的线程数 ForkJoinTask result = fjp.submit(ls); System.out.println("forkjoin sum=" + result.get()); fjp.shutdown(); } }
结果输出 :
cpu-num:8
forkjoin sum=499500
先来看一下ForkJoinPool的结构

1、简介
ForkJoinPool 是用于并行执行任务的框架, 是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架。Fork就是把一个大任务切分为若干子任务并行的执行,Join就是合并这些子任务的执行结果,最后得到这个大任务的结果。
JDK 7加入的一个线程池类。Fork/Join 技术是分治算法(Divide-and-Conquer)的并行实现,它是一项可以获得良好的并行性能的简单且高效的设计技术。目的是为了帮助我们更好地利用多处理器带来的好处,使用所有可用的运算能力来提升应用的性能。我们常用的数组工具类 Arrays 在JDK 8之后新增的并行排序方法(parallelSort)就运用了 ForkJoinPool 的特性,还有 ConcurrentHashMap 在JDK 8之后添加的函数式方法(如forEach等)也有运用。在整个JUC框架中,ForkJoinPool 相对其他类会复杂很多。

Fork/Join 框架主要由 ForkJoinPool、ForkJoinWorkerThread 和 ForkJoinTask 来实现
,它们之间有着很复杂的联系。ForkJoinPool 中只可以运行 ForkJoinTask 类型的任务(在实际使用中,也可以接收 Runnable/Callable 任务,但在真正运行时,也会把这些任务封装成 ForkJoinTask 类型的任务);而 ForkJoinWorkerThread 是运行 ForkJoinTask 任务的工作线程。
ForkJoinPool 的另一个特性是它使用了work-stealing(工作窃取)算法:线程池内的所有工作线程都尝试找到并执行已经提交的任务,或者是被其他活动任务创建的子任务(如果不存在就阻塞等待)。这种特性使得 ForkJoinPool 在运行多个可以产生子任务的任务,或者是提交的许多小任务时效率更高。尤其是构建异步模型的 ForkJoinPool 时,对不需要合并(join)的事件类型任务也非常适用。
在 ForkJoinPool 中,线程池中每个工作线程(ForkJoinWorkerThread)都对应一个任务队列(WorkQueue),
工作线程优先处理来自自身队列的任务(LIFO或FIFO顺序,参数 mode 决定),然后以FIFO的顺序随机窃取其他队列中的任务。

任务的分类与分布情况
ForkJoinPool 中的任务分为两种:一种是本地提交的任务(Submission task,如 execute、submit 提交的任务);另外一种是 fork 出的子任务(Worker task)。两种任务都会存放在 WorkQueue 数组中,但是这两种任务并不会混合在同一个队列里,ForkJoinPool 内部使用了一种随机哈希算法(有点类似 ConcurrentHashMap 的桶随机算法)将工作队列与对应的工作线程关联起来,Submission 任务存放在 WorkQueue 数组的偶数索引位置,Worker 任务存放在奇数索引位。实质上,Submission 与 Worker 一样,只不过他它们被限制只能执行它们提交的本地任务,在后面的源码解析中,我们统一称之为“Worker”。
任务的分布情况如下图:

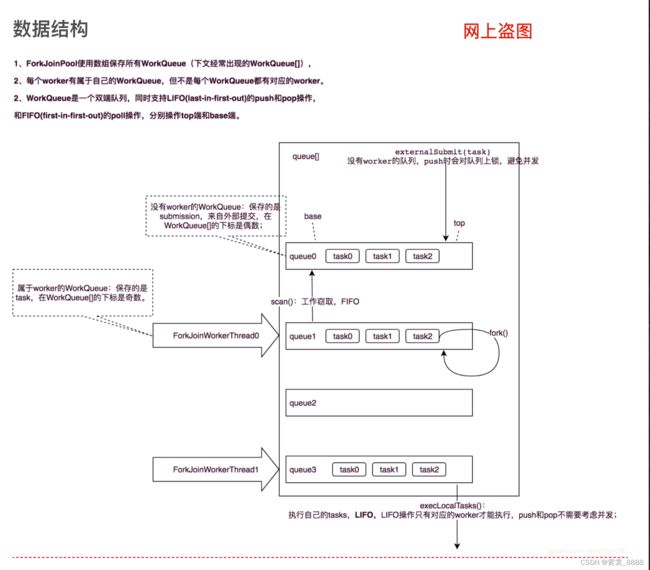
这个图贯穿 ForkJoin 整个源码
public class ForkJoinPool extends AbstractExecutorService {
// 线程工厂
public static final ForkJoinWorkerThreadFactory defaultForkJoinWorkerThreadFactory;
// 启动或杀死线程的方法调用者的权限
private static final RuntimePermission modifyThreadPermission;
private static final AtomicInteger poolNumberGenerator;
static final Random workerSeedGenerator;
ForkJoinWorkerThread[] workers;
private static final int INITIAL_QUEUE_CAPACITY = 8;
private static final int MAXIMUM_QUEUE_CAPACITY = 1 << 24; // 16M
private ForkJoinTask[] submissionQueue;
private final ReentrantLock submissionLock;
private final Condition termination;
// 创建新线程的工厂( the factory for creating new threads)。默认情况下使用
// ForkJoinWorkerThreadFactory defaultForkJoinWorkerThreadFactory。
private final ForkJoinWorkerThreadFactory factory;
// 线程异常情况下的处理器(Thread.UncaughtExceptionHandler handler),该处理器在线程执行任务时由于某
// 些无法预料 到的错误而导致任务线程中断时进行一些处理,默认情况为null。
final Thread.UncaughtExceptionHandler ueh;
// 用于创建工作线程的名称
private final String workerNamePrefix;
private volatile long stealCount;
volatile long ctl;
// 活跃线程数
private static final int AC_SHIFT = 48;
// 工作线程数
private static final int TC_SHIFT = 32;
private static final int ST_SHIFT = 31;
private static final int EC_SHIFT = 16;
// 低位掩码,也是最大索引位
private static final int MAX_ID = 0x7fff;
// 工程最大线程容量
private static final int SMASK = 0xffff;
private static final int SHORT_SIGN = 1 << 15;
private static final int INT_SIGN = 1 << 31;
private static final long STOP_BIT = 0x0001L << ST_SHIFT;
// 活跃线程掩码
private static final long AC_MASK = ((long)SMASK) << AC_SHIFT;
// 掩码
private static final long TC_MASK = ((long)SMASK) << TC_SHIFT;
// units for incrementing and decrementing
private static final long TC_UNIT = 1L << TC_SHIFT;
// 活跃线程增量
private static final long AC_UNIT = 1L << AC_SHIFT;
private static final int UAC_SHIFT = AC_SHIFT - 32;
private static final int UTC_SHIFT = TC_SHIFT - 32;
private static final int UAC_MASK = SMASK << UAC_SHIFT;
private static final int UTC_MASK = SMASK << UTC_SHIFT;
private static final int UAC_UNIT = 1 << UAC_SHIFT;
private static final int UTC_UNIT = 1 << UTC_SHIFT;
private static final int E_MASK = 0x7fffffff; // no STOP_BIT
private static final int EC_UNIT = 1 << EC_SHIFT;
// 并行度( the parallelism level),默认情况下跟我们机器的cpu个数保持一致,使用
// Runtime.getRuntime().availableProcessors()可以得到我们机器运行时可用的CPU个数。
final int parallelism;
volatile int queueBase;
int queueTop;
volatile boolean shutdown;
// 这个参数要注意,在ForkJoinPool中,每一个工作线程都有一个独立的任务队列,
// asyncMode表示工作线程肉摊任务队列是采用何种方式进行调试,可以是先进先出FIFO,也可以是后进先出LIFO
// 如果为true,则线程池中的工作线程则使用先进先出的方式进行任务调试,默认情况下是false
final boolean locallyFifo;
volatile int quiescerCount;
volatile int blockedCount;
private volatile int nextWorkerNumber;
private int nextWorkerIndex;
volatile int scanGuard;
private static final int SG_UNIT = 1 << 16;
private static final long SHRINK_RATE =
4L * 1000L * 1000L * 1000L;
public static final ForkJoinWorkerThreadFactory defaultForkJoinWorkerThreadFactory;
private static final RuntimePermission modifyThreadPermission;
static final ForkJoinPool common;
// 并行度,对应内部common池
static final int commonParallelism;
// 备用线程数,在tryCompensate中使用
private static int commonMaxSpares;
//
private static int poolNumberSequence;
//
private static final synchronized int nextPoolId() {
return ++poolNumberSequence;
}
// 线程阻塞等待新的任务的超时值(以纳秒为单位),默认2秒
private static final long IDLE_TIMEOUT = 2000L * 1000L * 1000L; // 2sec
// 空闲超时时间,防止timer未命中
private static final long TIMEOUT_SLOP = 20L * 1000L * 1000L; // 20ms
// 默认备用线程数
private static final int DEFAULT_COMMON_MAX_SPARES = 256;
// 阻塞前自旋的次数,用在在awaitRunStateLock和awaitWork中
private static final int SPINS = 0;
// indexSeed的增量
private static final int SEED_INCREMENT = 0x9e3779b9;
// 低位和高位掩码
private static final long SP_MASK = 0xffffffffL;
private static final long UC_MASK = ~SP_MASK;
// 活动线程数
private static final int AC_SHIFT = 48;
private static final long AC_UNIT = 0x0001L << AC_SHIFT;
private static final long AC_MASK = 0xffffL << AC_SHIFT;
// 工作线程数
private static final int TC_SHIFT = 32;
// 工作线程数增量
private static final long TC_UNIT = 0x0001L << TC_SHIFT;
// 掩码
private static final long TC_MASK = 0xffffL << TC_SHIFT;
// 创建工作线程标志
private static final long ADD_WORKER = 0x0001L << (TC_SHIFT + 15); // sign
// 池状态
private static final int RSLOCK = 1; // 线程池被锁定
private static final int RSIGNAL = 1 << 1; // 线程池有线程需要唤醒
private static final int STARTED = 1 << 2;// 线程池已经初始化
private static final int STOP = 1 << 29;// 线程池停止
private static final int TERMINATED = 1 << 30; // 线程池终止
private static final int SHUTDOWN = 1 << 31; //线程池关闭
// 主控制参数,最高 16 位存储 active 线程数信息; 后面 16 位存储当前总线程数信息;低 32 位存储最后一个 inactive 的队列的
// scanState,而队列在 inactive 之前都会把上一个 inactive 的队列的 scanState 存储到自己的 stackPred 成员变量,
// 所以所有的 inactive 队列会形成一条链,当然,因为最后 inactive 的在最上面,所以实际上是一个栈。
volatile long ctl;
// 运行状态锁
// 第 1 位的 1 表示 RSLOCK 状态,runState 变量被锁,其它线程暂时不可以修改;
// 第 2 位的 1 表示 RSIGNAL 状态,线程阻塞等其它线程释放 RSLOCK;
// 其它状态同 ThreadPoolExecutor。
volatile int runState;
// 并行度 | 模式
final int config;
// 用于生成工作线程索引,indexSeed的增量
int indexSeed;
// 主对象注册信息,workQueue
volatile WorkQueue[] workQueues;
// 线程工厂
final ForkJoinWorkerThreadFactory factory;
// 每个工作线程的异常信息
final UncaughtExceptionHandler ueh;
// 用于创建工作线程的名称
final String workerNamePrefix;
// 偷取任务总数,也可以作为同步监视器
volatile AtomicLong stealCounter;
// 低位掩码,也是最大索引位
static final int SMASK = 0xffff;
// 工作线程最大容量
static final int MAX_CAP = 0x7fff;
// 偶数低位掩码
static final int EVENMASK = 0xfffe;
// workQueues 数组最多64个槽位
static final int SQMASK = 0x007e;
// ctl 子域和WorkQueue.scanState 的掩码和标志位
static final int SCANNING = 1;
// 失活状态,负数
static final int INACTIVE = 1 << 31;
// 版本戳,防止ABA问题
static final int SS_SEQ = 1 << 16;
// 模式掩码
static final int MODE_MASK = 0xffff << 16;
// LIFO 队列
static final int LIFO_QUEUE = 0;
// FIFO 队列
static final int FIFO_QUEUE = 1 << 16;
// 共享模式队列,负数
static final int SHARED_QUEUE = 1 << 31;
}
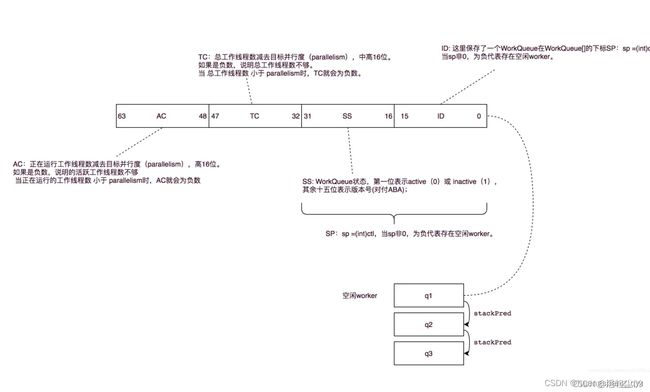
ForkJoinPool 的内部状态都是通过一个64位的 long 型 变量ctl来存储,它由四个16位的子域组成: AC: 正在运行工作线程数减去目标并行度,高16位
- AC:正在运行工作线程数减去目标并行度,高16位
- TC: 总工作线程数减去目标并行度,中高16位
- SS: 栈顶等待线程的版本计数和状态,中低16位
- ID: 栈顶 WorkQueue 在池中的索引(poolIndex),低16位
在后面的源码解析中,某些地方也提取了ctl的低32位(sp=(int)ctl)来检查工作线程状态,例如,当sp不为0时说明当前还有空闲工作线程。
invoke/submit/execute
向 ForkJoinPool 提交任务有三种方法,它们之间的区别:
- invoke:提交任务,并等待返回执行结果
- submit:提交并立刻返回任务,ForkJoinTask实现了Future,可以充分利用 Future 的特性
- execute:只提交任务
static final class WorkQueue {
// 初始化队列容量 ,2 的幂
static final int INITIAL_QUEUE_CAPACITY = 1 << 13;
// 最大队列容量
static final int MAXIMUM_QUEUE_CAPACITY = 1 << 26; // 64M
// 实例字段
// 最高位(符号位)的 1 表示 inactive,所以负数肯定是 inactive 状态;
// 接下来 15 位无符号数表示版本号,线程每次从 inactive 状态被重新激活都会加 1;
// 低 16 位存储了当前 WorkQueue 在 ForkJoinPool 的 WorkQueue[] 中的索引值;
// 最低位的 1 同时还表示 SCANNING 状态,尽管如此,SCANNING 状态在 1 和 0 之间的变更并不会影响对索引值的获取产生影响,因为有自己
// 工作线程的队列索引值一定是奇数,反之为偶数,所以在获取索引值的时候,其实不需要最低位。
volatile int scanState;
// 记录前一个栈顶的ctl
int stackPred;
// 偷取任务数
int nsteals;
// 记录偷取者索引,初始化随机索引
int hint;
// 池索引和模式
int config;
//1: locked, < 0: terminate; else 0
volatile int qlock;
// 下一个poll操作的索引(栈底/队列头)
volatile int base;
// 下一个push操作的索引(栈顶/队列尾)
int top;
// 任务数组
ForkJoinTask[] array;
// the containing pool (may be null )
final ForkJoinPool pool;
// 当前工作队列的工作线程,共享模式下为null
final ForkJoinWorkerThread owner;
// 调用park阻塞期间的owner ,其他情况为null
volatile Thread parker;
// 记录被join过来的任务
volatile ForkJoinTask currentJoin;
// 记录从其他工作队列偷取过来的任务
volatile ForkJoinTask currentSteal;
}
1、异常处理
ForkJoinTask 在执行的时候可能会抛出异常,但是我们没办法在主线程里直接捕获异常,所以 ForkJoinTask 提供了 isCompletedAbnormally() 方法来检查任务是否已经抛出异常或已经被取消了,并且可以通过 ForkJoinTask 的 getException 方法获取 异常。示例如下
if(task.isCompletedAbnormally()){
System.out.println(task.getException());
}
getException 方法返回 Throwable 对象,如果任务被取消了则返回CancellationException。如果任务没有完成或者没有抛出异常 则返回 null。
上面这些笔记来源于 并发编程之Future&ForkJoin框架原理分析 ,也是杨过老师的笔记。有兴趣去看原笔记 。
关于ForkJoin框架的资料都在这里了,但光看这些注释,一点用都没有。如果想真正的了解ForkJoin框架的原理,作者的巧妙构思,我们还是要深入源码,不入虎穴,焉得虎子。
在看源码之前,我们先来看一个例子。这个例子的目的就是计算0-1000所有整数之和,但是我们不是一个简单的for循环就计算出来,而是通过ForkJoin来实现,请看下面代码 。
WorkQueue 是一个双端队列,线程池有 runState,WorkQueue 有 scanState
- 小于零:inactive (未激活状态)
- 奇数:scanning (扫描状态)
- 偶数:running (运行状态)
操作线程池需要锁,操作队列也是需要锁的,qlock 就派上用场了
- 1: 锁定
- 0:未锁定
- 小于零:终止状态
public class ForkJoinLongSum extends RecursiveTask{ //获取逻辑处理器数量 static final int NCPU = Runtime.getRuntime().availableProcessors(); //任务拆分的最小阀值 static final int SEQUENTIAL_THRESHOLD = 10; int low; int high; int[] array; ForkJoinLongSum(int[] arr, int lo, int hi) { array = arr; low = lo; high = hi; } protected Long compute() { //任务被拆分到足够小时,则开始求和 if (high - low <= SEQUENTIAL_THRESHOLD) { long sum = 0; for (int i = low; i < high; ++i) { sum += array[i]; } return sum; } else {//如果任务任然过大,则继续拆分任务,本质就是递归拆分 int mid = low + (high - low) / 2; ForkJoinLongSum left = new ForkJoinLongSum(array, low, mid); ForkJoinLongSum right = new ForkJoinLongSum(array, mid, high); left.fork(); right.fork(); long rightAns = right.join(); long leftAns = left.join(); return leftAns + rightAns; } } public static void main(String[] args) throws Exception { int[] array = new int[1000]; for (int i = 0; i < 1000; i++) { array[i] = i; } System.out.println("cpu-num:" + NCPU); //采用fork/join方式将数组求和任务进行拆分执行,最后合并结果 ForkJoinLongSum ls = new ForkJoinLongSum(array, 0, array.length); ForkJoinPool fjp = new ForkJoinPool(4); //使用的线程数 ForkJoinTask result = fjp.submit(ls); System.out.println("forkjoin sum=" + result.get()); fjp.shutdown(); } }
我们先进入构造函数中 。
public ForkJoinPool(int parallelism) {
//defaultForkJoinWorkerThreadFactory 默认为DefaultForkJoinWorkerThreadFactory
this(parallelism, defaultForkJoinWorkerThreadFactory, null, false);
}
public ForkJoinPool(int parallelism,
ForkJoinWorkerThreadFactory factory,
UncaughtExceptionHandler handler,
boolean asyncMode) {
// 线程池的最大并行度不能超过0000 0000 0000 0000 0111 1111 1111 1111 = 32767
this(checkParallelism(parallelism),
// factory不能为空,如果为空,则抛出NullPointerException
checkFactory(factory),
// 内部工作线程处理程序,由于在执行任务时遇到不可恢复的错误而终止。默认值为null
handler,
// FIFO_QUEUE 先进先出模式 ,LIFO_QUEUE 后进先出模式,栈模式
asyncMode ? FIFO_QUEUE : LIFO_QUEUE,
"ForkJoinPool-" + nextPoolId() + "-worker-");
// 较验线程可修改权限
checkPermission();
}
private ForkJoinPool(int parallelism,
ForkJoinWorkerThreadFactory factory,
UncaughtExceptionHandler handler,
int mode,
String workerNamePrefix) {
this.workerNamePrefix = workerNamePrefix;
this.factory = factory;
this.ueh = handler;
// 在本例中 parallelism = 4 = 0000 0000 0000 0000 0000 0000 0000 0100
// SMASK = 0000 0000 0000 0000 1111 1111 1111 1111
// mode 默认情况下是 LIFO_QUEUE = 0000 0000 0000 0000 0000 0000 0000 0000 所以
// 从上面例子中分析得出
// 0000 0000 0000 0000 0000 0000 0000 0100 &
// 0000 0000 0000 0000 1111 1111 1111 1111 |
// 0000 0000 0000 0000 0000 0000 0000 0000 =
// 0000 0000 0000 0000 0000 0000 0000 0100 = 4
this.config = (parallelism & SMASK) | mode;
// 如果parallelism = 4 ,则np = -4
long np = (long)(-parallelism); // offset ctl counts
// np = 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1100
// AC_SHIFT = 48
// AC_MASK = 1111 1111 1111 1111 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000
// TC_SHIFT = 32
// TC_MASK = 0000 0000 0000 0000 1111 1111 1111 1111 0000 0000 0000 0000 0000 0000 0000 0000
// (np << AC_SHIFT) & AC_MASK) =
// 1111 1111 1111 1100 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000
// (np << TC_SHIFT) & TC_MASK =
// 0000 0000 0000 0000 1111 1111 1111 1100 0000 0000 0000 0000 0000 0000 0000 0000
// 并行度4的ctl最终值为:
// 1111 1111 1111 1100 1111 1111 1111 1100 0000 0000 0000 0000 0000 0000 0000 0000
// ,看到没有,发现 AC_MASK 为64位中高32位中的高16位掩码,而TC_MASK为高32位中的低16位掩码,
// 最高16 位存储当前激活工作线程数 - 并行度; 高32位中低16 位存储当前总线程数 - 并行度 , 低 32 位中,高16位
// 存储栈顶队列的激活信息+ 版本号, 低16位存储 等待栈顶队列在池workQueues的索引 ,而每个等待队列的stackPred
// 记录着前一个等待队列在workQueues的索引
this.ctl = ((np << AC_SHIFT) & AC_MASK) | ((np << TC_SHIFT) & TC_MASK);
}
public static interface ForkJoinWorkerThreadFactory {
public ForkJoinWorkerThread newThread(ForkJoinPool pool);
}
static final class DefaultForkJoinWorkerThreadFactory implements ForkJoinWorkerThreadFactory {
public final ForkJoinWorkerThread newThread(ForkJoinPool pool) {
return new ForkJoinWorkerThread(pool);
}
}
CTL
发现构造函数中做了一些初始化值和较验的功能,但这些初始化值有什么用呢?我们后面来分析 。接下来先看submit()方法的实现。
ForkJoinPool 自身拥有工作队列,这些工作队列的作用是用来接收由外部线程(非 线程)提交过来的任务,而这些工作 队列被称为 submitting queue 。submit() 和 fork() 其实没有本质区别,只是提交对象变成了 submitting queue 而已(还有一些同步,初始化的操作)。submitting queue 和其他 work queue 一样,是工作线程”窃取“的对象,因此当其中的任务被一个工作线程成功窃取时,就意味着提交的任务真正 开始进入执行阶段。
publicForkJoinTask submit(ForkJoinTask task) { // 任务不能为空,否则抛出空指针 if (task == null) throw new NullPointerException(); externalPush(task); return task; }
externalPush
前面说过,task 会细分成 submission task 和 worker task,worker task 是 fork 出来的,那从这个入口进入的,自然也就是 submission task 了,也就是说:
- 通过invoke() | submit() | execute() 等方法提交的 task, 是 submission task,会放到 WorkQueue 数组的偶数索引位置
- 调用 fork() 方法生成出的任务,叫 worker task,会放到 WorkQueue 数组的奇数索引位置
final void externalPush(ForkJoinTask task) {
WorkQueue[] ws; WorkQueue q; int m;
// 一般情况下,每个线程每次调用生成的值一样,一个线程的probe探针值,是一个非零hash值,它不会
// 和其他线程重复(一定情况下, 有可能也会重复)
// 感兴趣可以查看ThreadLocalRandom#getProbe #advanceProbe浅析
int r = ThreadLocalRandom.getProbe();
int rs = runState;
// 如果队列不为空 ,且队列长度大于0,m为队列数组长度-1,读过HashMap
// 源码的小伙伴应该知道,HashMap计算桶的位置时用到了 【o.hashCode() & (n - 1 ) 】 ,这里的原理其实一样
if ((ws = workQueues) != null && (m = (ws.length - 1)) >= 0 &&
// SQMASK = 0000 0000 0000 0000 0000 0000 0111 1110 保证 index = m & r & SQMASK
// index 在 0 ~ ws.length -1 之间的偶数,因为 & SQMASK 的最低位为0,那么 & SQMASK 结果肯定是一个偶数
// 这里作者意图就是将submit()方法提交的这些任务放到工作队列的偶数槽位
(q = ws[m & r & SQMASK]) != null && r != 0 && rs > 0 &&
// CAS 对 q = ws[index] 队列加锁
U.compareAndSwapInt(q, QLOCK, 0, 1)) {
ForkJoinTask[] a; int am, n, s;
// 如果ws[index]的数组不为空,top - base 表示q.array中实际已经存储任务的个数
// 当am > top - base 时,数组不需要扩容
if ((a = q.array) != null &&
(am = a.length - 1) > (n = (s = q.top) - q.base)) {
// Class ak = ForkJoinTask[].class;
// ABASE = U.arrayBaseOffset(ak);
// int scale = U.arrayIndexScale(ak);
// ASHIFT = 31 - Integer.numberOfLeadingZeros(scale); ,numberOfLeadingZeros函数的作用
// 将scale转化为二进制后,从左向右数0的个数, scale 为ForkJoinTask数组每一个元素占内存的大小
// ABASE 可以看作是数组的起始内存地址 ,为什么要使用 << ASHIFT 来实现呢? 因为 << 符号的性能更快
// 例:如果 scale = 4 ,ASHIFT = 31 - (numberOfLeadingZeros(4) =
// numberOfLeadingZeros(0000 0000 0000 0000 0000 0000 0000 0100) ) = 31 - 29 = 2
// 其实j的整个计算过程就是将本来的乘法运算转化为位移运算来实现, 乘4 其实和 左移2位结果一样
// 如 1 * 4 = 1 << 2 = 4
// 2 * 4 = 2 << 2 = 8
// 3 * 4 = 3 << 2 = 12 ,因此下面两行代码其实就是为了实现 a[s] = task
int j = ((am & s) << ASHIFT) + ABASE;
U.putOrderedObject(a, j, task);
U.putOrderedInt(q, QTOP, s + 1);
// 解锁操作
U.putIntVolatile(q, QLOCK, 0);
// 当n <= 1 时,则需要通知Worker来执行任务,不知道大家知道作者的用意没有
// n = top - base ,如果n <= 1 ,则当前队列中有 小于等于 1 个任务
// 如果当前队列中只有一个任务,则当前队列的Worker可能进入阻塞,因此需要唤醒
// 如果当前队列中没有任务,可能当前队列已经进入等待状态
// 因此此处执行signalWork() 唤醒阻塞的任务
if (n <= 1)
// 唤醒工作者来执行任务
signalWork(ws, q);
return;
}
U.compareAndSwapInt(q, QLOCK, 1, 0);
}
// 如果队列为空或并发情况下,对ws[index]队列加锁失败,则通过externalSubmit()方法将任务添加到队列中
externalSubmit(task);
}
private static final sun.misc.Unsafe U;
private static final int ABASE;
private static final int ASHIFT;
static {
try {
U = sun.misc.Unsafe.getUnsafe();
Class ak = ForkJoinTask[].class;
//数组元素定位:
// Unsafe类中有很多以BASE_OFFSET结尾的常量,比如ARRAY_INT_BASE_OFFSET,ARRAY_BYTE_BASE_OFFSET等,
// 这些常量值是通过arrayBaseOffset方法得到的。arrayBaseOffset方法是一个本地方法,可以获取数组第一个元素的偏移地址。
// Unsafe类中还有很多以INDEX_SCALE结尾的常量,比如 ARRAY_INT_INDEX_SCALE , ARRAY_BYTE_INDEX_SCALE等,这些常量值是
// 通过arrayIndexScale方法得到的。arrayIndexScale方法也是一个本地方法,可以获取数组的转换因子,也就是数组中元素的增
// 量地址。将arrayBaseOffset与arrayIndexScale配合使用,可以定位数组中每个元素在内存中的位置。
// Arrays和Java别的对象一样,都有一个对象头,它是存储在实际的数据前面的。
// 这个头的长度可以通过unsafe.arrayBaseOffset(T[].class)方法来获取到,这里T是数组元素的类型。数组元素的大小可以通过
// unsafe.arrayIndexScale(T[].class)
// 方法获取到。这也就是说要访问类型为T的第N个元素的话,你的偏移量offset应该是arrayOffset+N*arrayScale。
ABASE = U.arrayBaseOffset(ak);
int scale = U.arrayIndexScale(ak);
if ((scale & (scale - 1)) != 0)
throw new Error("data type scale not a power of two");
// int numberOfLeadingZeros(int i) 给定一个int类型数据,返回这个数据的二进制串中从最左边算起连续的“0”的总数量。
// 因为int类型的数据长度为32所以高位不足的地方会以“0”填充。如果scale = 4 ,则numberOfLeadingZeros(4) = 29
// 所以ASHIFT = 2
ASHIFT = 31 - Integer.numberOfLeadingZeros(scale);
} catch (Exception e) {
throw new Error(e);
}
}
externalPush()方法的实现原理还是很简单的,如果当前task分配到的队列不为空,则将当前task加入到队列数组中,如果队列中的任务超过一个,唤醒队列的线程来执行任务 。
private void externalSubmit(ForkJoinTask task) {
int r; // initialize caller's probe
// getProbe()实际上是获取threadLocalRandomProbe变量的值,threadLocalRandomProbe 是线程中的一个变量,
// 用来表示ThreadLocalRandom 是否进行了初始化,如果是非0,表示已经初始化,等于0表示还未进行初始化,如果等于0 ,
// 则需要执行localInit方法,ThreadLocalRandom.getProbe();返回一个和线程相关的随机数,只要没有调用
// ThreadLocalRandom.advanceProbe(r);方法,线程每次调用getProbe()方法返回的值一定是相等的,但有一点需要注意
// 不同的线程调用getProbe()方法生成的随机数可能相等,即使可能性很小,但是还是有可能
if ((r = ThreadLocalRandom.getProbe()) == 0) {
ThreadLocalRandom.localInit();
r = ThreadLocalRandom.getProbe();
}
for (;;) {
WorkQueue[] ws; WorkQueue q; int rs, m, k;
boolean move = false;
// 如果ForkJoinPool池的状态为SHUTDOWN,则终止ForkJoin执行
if ((rs = runState) < 0) {
tryTerminate(false, false);
throw new RejectedExecutionException();
}
// 如果池还没有初始化 或 workQueues为空或工作队列的length 为0,则对workQueues进行初始化队列
else if ((rs & STARTED) == 0 ||
((ws = workQueues) == null || (m = ws.length - 1) < 0)) {
int ns = 0;
// 为了避免并发,对整个池加锁
rs = lockRunState();
try {
if ((rs & STARTED) == 0) {
U.compareAndSwapObject(this, STEALCOUNTER, null, new AtomicLong());
//SMASK = 0000 0000 0000 0000 1111 1111 1111 1111
int p = config & SMASK;
// 研究过HashMap源码的小伙伴应该熟悉下面代码,如我们定义HashMap的容量为11
// 实际上初始化HashMap数组的长度是16,下面也是一样,保证n 是2 ^ n 次方
int n = (p > 1) ? p - 1 : 1;
n |= n >>> 1; n |= n >>> 2; n |= n >>> 4;
n |= n >>> 8; n |= n >>> 16; n = (n + 1) << 1;
// 初始化workQueues数组
workQueues = new WorkQueue[n];
ns = STARTED;
}
} finally {
// 解锁runState,并且将runState设置拥有STARTED状态
unlockRunState(rs, (rs & ~RSLOCK) | ns);
}
}
// SQMASK= 0000 0000 0000 0000 0000 0000 0111 1110
// 那么 k 一定是一个偶数
else if ((q = ws[k = r & m & SQMASK]) != null) {
// 将ws[index]锁住
if (q.qlock == 0 && U.compareAndSwapInt(q, QLOCK, 0, 1)) {
// 拿到ws[index]的ForkJoinTask
ForkJoinTask[] a = q.array;
int s = q.top;
boolean submitted = false;
try {
// 如果ws[index].array 不为空,并且加一个新的task后,数组没有越界
if ((a != null && a.length > s + 1 - q.base) ||
// 如果ws[index]的array为空,或者数组越界,扩容array数组
(a = q.growArray()) != null) {
// a[s] = task
int j = (((a.length - 1) & s) << ASHIFT) + ABASE;
U.putOrderedObject(a, j, task);
U.putOrderedInt(q, QTOP, s + 1);
submitted = true;
}
} finally {
U.compareAndSwapInt(q, QLOCK, 1, 0);
}
// 如果提交成功,当前Worker可能处于阻塞状态,通知Worker来执行任务
if (submitted) {
signalWork(ws, q);
return;
}
}
// 如果存在碰撞,则调用ThreadLocalRandom.advanceProbe(r);方法,重新计算k的值
move = true;
}
// 程序执行到此,肯定runState状态已经启动,并且ws[k] == null,则创建一个新队列放到ws[k]中
else if (((rs = runState) & RSLOCK) == 0) {
q = new WorkQueue(this, null);
// q.hint 记录随机因子
q.hint = r;
// SQMASK = 0000 0000 0000 0000 0000 0000 0111 1110
//SHARED_QUEUE= 1000 0000 0000 0000 0000 0000 0000 0000
// q.config = r & m & SQMASK | SHARED_QUEUE
// 从上述计算中可以得到,config 一定是一个 [-126,0] 之间的偶数,这样做的目的是什么,限制 最多64个(偶数)插槽
q.config = k | SHARED_QUEUE;
// scanState = INACTIVE = 1 << 31 = 1000 0000 0000 0000 0000 0000 0000 0000 非激活状态
q.scanState = INACTIVE;
// 加锁
rs = lockRunState();
if (rs > 0 && (ws = workQueues) != null &&
k < ws.length && ws[k] == null)
// 如果 workQueues 队列不为空,并且ws[k] == null,将新创建的q 赋值给ws[k]
ws[k] = q;
//解锁
unlockRunState(rs, rs & ~RSLOCK);
}
else
move = true;
// 如果发生了碰撞,则重置随机数
if (move)
r = ThreadLocalRandom.advanceProbe(r);
}
}
private int lockRunState() {
int rs;
// 如果runState为RSLOCK状态,则调用awaitRunStateLock()方法等待解锁
return ((((rs = runState) & RSLOCK) != 0 ||
// 如果存在多线程加锁操作,并且当前线程加锁失败,调用awaitRunStateLock()方法进入等待
!U.compareAndSwapInt(this, RUNSTATE, rs, rs |= RSLOCK)) ?
// 如果加锁成功,则直接返回
awaitRunStateLock() : rs);
}
// 等待获取锁操作
private int awaitRunStateLock() {
Object lock;
boolean wasInterrupted = false;
// SPINS 自旋次数 ,一般默认为0
for (int spins = SPINS, r = 0, rs, ns;;) {
// 只要ForkJoin池不处于被锁定状态,则进入下面代码块
if (((rs = runState) & RSLOCK) == 0) {
// 当前线程再次抢锁 ,其实runState的最低位为1,表示ForkJoin池被锁定状态 在源码中,我们经常看到
// rs | RSLOCK 的写法,作者就是想保证runState的其他位不变,而RSLOCK所在的位变成1,也就是已锁定状态
if (U.compareAndSwapInt(this, RUNSTATE, rs, ns = rs | RSLOCK)) {
// 如果在等待过程中被中断过,则恢复中断标志位
if (wasInterrupted) {
try {
Thread.currentThread().interrupt();
} catch (SecurityException ignore) {
}
}
return ns;
}
}
// 生成线程随机数r
else if (r == 0)
r = ThreadLocalRandom.nextSecondarySeed();
// 开始自旋
else if (spins > 0) {
// 大家可能不太明白下面的代码,作者为什么这么写?
// 不知道大家看过JDK7中HashMap的hash函数,
// 其中是hash方法这样写的
// final int hash(Object k) {
// int h = hashSeed;
// if (0 != h && k instanceof String) {
// return sun.misc.Hashing.stringHash32((String) k);
// }
// h ^= k.hashCode();
// h ^= (h >>> 20) ^ (h >>> 12);
// return h ^ (h >>> 7) ^ (h >>> 4);
// }
// hash方法的目的是使得hashCode更加散列
// 那么下面代码的用途是什么呢? 我自己也测试了一下,r 是一个随机数,每次对这个随机数散列,
// 得到的r可能大于0,也可能小于0 ,因此有些线程的spins的值减少,但是有些并不会减少,这样就造成了
// 每个线程自旋的次数不一致,从而避免后面代码锁的竞争
r ^= r << 6; r ^= r >>> 21; r ^= r << 7;
if (r >= 0)
--spins;
}
//workQueues初始化时会将runState设置为STARTED,并且stealCounter置为 new AtomicLong()
// 因此,如果workQueues还没有初始化完,当前线程需要释放CPU时间片,等待workQueues初始化完
else if ((rs & STARTED) == 0 || (lock = stealCounter) == null)
Thread.yield();
// 将ForkJoin池的 runState 设置拥有RSIGNAL状态,也就是等待状态
else if (U.compareAndSwapInt(this, RUNSTATE, rs, rs | RSIGNAL)) {
synchronized (lock) {
// 如果获取锁成功,并且runState拥有RSIGNAL状态,则进入等待
if ((runState & RSIGNAL) != 0) {
try {
lock.wait();
} catch (InterruptedException ie) {
if (!(Thread.currentThread() instanceof
ForkJoinWorkerThread))
wasInterrupted = true;
}
}
else
// 如果当前runState中没有RSIGNAL,则通知所有在等待中的线程
lock.notifyAll();
}
}
}
}
private void unlockRunState(int oldRunState, int newRunState) {
// 将runState由oldRunState设置为newRunState ,这个过程中可能出现失败
// 因为在多线程操作的情况下,如之前的oldRunState是没有RSIGNAL状态的,但在awaitRunStateLock()
// 方法中将runState状态中设置了RSIGNAL状态(等待状态),其他线程将处于wait()中
// 因此下面的代码需要将runState设置为newRunState,并且调用notifyAll()唤醒所有在等待中的线程
if (!U.compareAndSwapInt(this, RUNSTATE, oldRunState, newRunState)) {
Object lock = stealCounter;
runState = newRunState;
if (lock != null)
// 当线程从lockRunState() 的 wait()方法中唤醒后,会再次调用unlockRunState() 设置runState的状态
// 为newRunState ,最终runState的状态会被设置为~RSLOCK 状态
synchronized (lock) { lock.notifyAll(); }
}
}
externalSubmit()方法的实现原理还是很简单的,如果workQueues没有初始化好,先初始化workQueues,如果通过随机运算得到workQueues[k]处的队列没有初始化,则先对workQueues[k]进行初始化,再将任务放到workQueues[k]中,如果workQueues[k]放入成功,创建线程来执行新加入的任务,下面我们就来看如何创建Worker来执行任务 。
final void signalWork(WorkQueue[] ws, WorkQueue q) {
// 如果活动的工作进程太少,则尝试创建或激活工作进程。
long c; int sp, i; WorkQueue v; Thread p;
// 如果 active 线程数已经达到 parallelism size,不创建线程
while ((c = ctl) < 0L) {
// 即使 active 线程数不够,如果有空闲线程,也不会创建线程
if ((sp = (int)c) == 0) {
//ADD_WORKER = 0000 0000 0000 0000 1000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000
// 最后判断线程总数,确实不够才会创建线程
if ((c & ADD_WORKER) != 0L)
tryAddWorker(c);
break;
}
// 如果workQueues为空,说明还没有初始化,则退出循环
if (ws == null)
break;
if (ws.length <= (i = sp & SMASK))
break;
//SMASK =0000 0000 0000 0000 0000 1111 1111 1111 1111
// 如果非激活栈顶队列为空,则退出循环
if ((v = ws[i]) == null)
break;
// SS_SEQ = 0000 0000 0000 0001 0000 0000 0000 0000
// ~INACTIVE= 0111 1111 1111 1111 1111 1111 1111 1111
// 计算next 的 scanState , scanState 的高16位和ctl一样,32位表示激活或非激活状态, 16 ~ 31 位,用于保存版本号
// 程序执行到这里,说明有空闲线程,计算下一个scanState,增加了版本号,并且调整为 active 状态
int vs = (sp + SS_SEQ) & ~INACTIVE;
int d = sp - v.scanState;
// UC_MASK = 1111 1111 1111 1111 1111 1111 1111 1111 0000 0000 0000 0000 0000 0000 0000 0000
// AC_UNIT = 0000 0000 0000 0001 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000
// SP_MASK = 0000 0000 0000 0000 0000 0000 0000 0000 1111 1111 1111 1111 1111 1111 1111 1111
// 计算前驱队列的ctl值,因为当前ws[i] 的线程需要被唤醒,因此激活工作线程数+ 1
long nc = (UC_MASK & (c + AC_UNIT)) | (SP_MASK & v.stackPred);
if (d == 0 && U.compareAndSwapLong(this, CTL, c, nc)) {
v.scanState = vs;
//如果有线程阻塞,则调用unpark唤醒即可
if ((p = v.parker) != null)
U.unpark(p);
break;
}
// 如果q 的任务已经被执行完毕,则直接退出
if (q != null && q.base == q.top)
break;
}
}
假设程序刚开始执行,那么活动线程数以及总线程数肯定都没达到并行度要求,这时就会调用 tryAddWorker 方法,增加工作线程数
private void tryAddWorker(long c) {
boolean add = false;
do {
// AC_MASK= 1111 1111 1111 1111 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000
// AC_UNIT= 0000 0000 0000 0001 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000
// TC_MASK= 0000 0000 0000 0000 1111 1111 1111 1111 0000 0000 0000 0000 0000 0000 0000 0000
// TC_UNIT= 0000 0000 0000 0000 0000 0000 0000 0001 0000 0000 0000 0000 0000 0000 0000 0000
// ctl 的48~64位用于存储激活Worker数,32~48位,表示总Worker数 ,如果需要添加Worker,
// 则激活Worker和总Worker都需要加 1
long nc = ((AC_MASK & (c + AC_UNIT)) |
(TC_MASK & (c + TC_UNIT)));
// 在并发情况下,ctl !=c ,则重新进行while循环判断
if (ctl == c) {
int rs, stop;
// 添加Worker需要对整个ForkJoin池加锁
if ((stop = (rs = lockRunState()) & STOP) == 0)
// 如果 runState != STOP状态,增加当前ForkJoin池的总Worker数,和激活Worker数
// 细心的小伙伴肯定发现了,ctl 的48~64位用于存储激活Worker数 - 并行度
// 32~48位,表示总Worker数 - 并行度
add = U.compareAndSwapLong(this, CTL, c, nc);
// 解锁
unlockRunState(rs, rs & ~RSLOCK);
// 如果ForkJoin池被STOP了,则直接退出循环
if (stop != 0)
break;
if (add) {
//如果CAS 添加Worker成功,则创建Worker
createWorker();
break;
}
}
//ADD_WORKER= 0000 0000 0000 0000 1000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000
} while (((c = ctl) & ADD_WORKER) != 0L && (int)c == 0);
}
tryAddWorker()方法的原理还是很简单的,就是将当前Worker数和激活Worker数分别都加1 ,如果池状态为STOP,则直接终止,如果Worker数量增加成功,则建新Worker ,接下来,我们看新Worker的创建逻辑 。
private boolean createWorker() {
ForkJoinWorkerThreadFactory fac = factory;
Throwable ex = null;
ForkJoinWorkerThread wt = null;
try {
// 调用线程工厂创建新的Worker
if (fac != null && (wt = fac.newThread(this)) != null) {
wt.start();
return true;
}
} catch (Throwable rex) {
ex = rex;
}
// 如果创建新Worker失败,则需要取消注册Worker
deregisterWorker(wt, ex);
return false;
}
createWorker()这个方法的实现逻辑还是很简单的,调用ForkJoinWorkerThreadFactory创建新的Worker并且注册到ForkJoin池中,但如果创建失败,则调用deregisterWorker()做一些回滚操作。我们先看newThread()方法,如何注册新的Worker 。
protected ForkJoinWorkerThread(ForkJoinPool pool) {
super("aForkJoinWorkerThread");
this.pool = pool;
this.workQueue = pool.registerWorker(this);
}
ForkJoinWorkerThread的构造函数并没有太多的实现逻辑,我们接下来看如何注册Worker 。
final WorkQueue registerWorker(ForkJoinWorkerThread wt) {
UncaughtExceptionHandler handler;
// 设置wt为守护线程
wt.setDaemon(true);
// 初始化异常处理器,默认handler为null
if ((handler = ueh) != null)
wt.setUncaughtExceptionHandler(handler);
// 创建新的WorkQueue
WorkQueue w = new WorkQueue(this, wt);
int i = 0;
// 设置当前队列的模式 MODE_MASK = 1111 1111 1111 1111 0000 0000 0000 0000
int mode = config & MODE_MASK;
int rs = lockRunState();
try {
WorkQueue[] ws; int n;
if ((ws = workQueues) != null && (n = ws.length) > 0) {
// 随机数,下面随机数加入,主要是用来计算s用的,为什么要加入随机数呢?
// 如多个线程同时调用 registerWorker()方法添加WorkQueue,在遍历ws 的奇数索引时
// 尽量让不同的线程查找奇数位索引不一样,从而引入了indexSeed随机索引
int s = indexSeed += SEED_INCREMENT;
int m = n - 1;
// i 为一个 1 ~ ws.length -1 之内的奇数
i = ((s << 1) | 1) & m;
// 如果碰撞上了ws[i]有值
if (ws[i] != null) {
int probes = 0;
// EVENMASK = 0000 0000 0000 0000 1111 1111 1111 1110
// n = 32 ,则step = (16 & EVENMASK ) + 2 = 16 + 2= 18
int step = (n <= 4) ? 2 : ((n >>> 1) & EVENMASK) + 2;
// 遍历 ws 所有奇数位索引,直接ws[i] == null ,退出循环
while (ws[i = (i + step) & m] != null) {
// 如果所有ws的所有奇数位都遍历完,依然没有找到ws[i] == null ,则对workQueues 扩容
// ,容量为原来的两倍
if (++probes >= n) {
workQueues = ws = Arrays.copyOf(ws, n <<= 1);
m = n - 1;
probes = 0;
}
}
}
// 如果ws[i] = w 为空
w.hint = s;
// 记录索引与模式
w.config = i | mode;
// 记录当前q 在ws的索引
w.scanState = i;
ws[i] = w;
}
} finally {
unlockRunState(rs, rs & ~RSLOCK);
}
wt.setName(workerNamePrefix.concat(Integer.toString(i >>> 1)));
return w;
}
如果创建的线程执行完毕,则取消当前注册的工作线程。
final void deregisterWorker(ForkJoinWorkerThread wt, Throwable ex) {
WorkQueue w = null;
if (wt != null && (w = wt.workQueue) != null) {
WorkQueue[] ws;
// SMASK = 0000 0000 0000 0000 1111 1111 1111 1111
// 我们知道,config中记录了当前w所在的Queue在ws中的索引与模式,而模式分为两种,
// LIFO_QUEUE = 0000 0000 0000 0000 0000 0000 0000 0000 和
// FIFO_QUEUE = 0000 0000 0000 0001 0000 0000 0000 0000
// config = index | model ,model 只可能是0或 1<<16 ,因此index = config & SMASK
// 清空ws[idx] 队列
int idx = w.config & SMASK;
int rs = lockRunState();
if ((ws = workQueues) != null && ws.length > idx && ws[idx] == w)
// 将wt所在的队列从workQueues移除掉
ws[idx] = null;
unlockRunState(rs, rs & ~RSLOCK);
}
long c;
// 循环CAS,将总工作线程数和激活工作线程数减少1,直到成功为止
do {} while (!U.compareAndSwapLong
(this, CTL, c = ctl, ((AC_MASK & (c - AC_UNIT)) |
(TC_MASK & (c - TC_UNIT)) |
(SP_MASK & c))));
if (w != null) {
// 将队列锁状态置为-1
w.qlock = -1;
// 将偷取计数添加到池偷取计数器(如果存在),并重置。
w.transferStealCount(this);
// 将 join的, 偷取的,以及自身队列的任务的状态都设置为取消状态
w.cancelAll();
}
for (;;) {
WorkQueue[] ws; int m, sp;
// 如果终止成功,或w被清除掉了,或runState 为停止状态 或 workQueues 为空或 workQueues的长度小于0
if (tryTerminate(false, false) || w == null || w.array == null ||
(runState & STOP) != 0 || (ws = workQueues) == null ||
(m = ws.length - 1) < 0)
break;
// 只要ctl != 0 ,则唤醒栈顶工作线程来替代
if ((sp = (int)(c = ctl)) != 0) {
if (tryRelease(c, ws[sp & m], AC_UNIT))
break;
}
// 如果没空闲线程,并且还没有达到满足并行度的条件,那就得再次尝试创建一个线程,弥补刚刚
else if (ex != null && (c & ADD_WORKER) != 0L) {
tryAddWorker(c);
break;
}
else
break;
}
if (ex == null)
ForkJoinTask.helpExpungeStaleExceptions();
else
// 抛出异常
ForkJoinTask.rethrow(ex);
}
其实deregisterWorker()方法的意图通过方法名就能看出来,取消之前注册的队列及工作线程,但是有条件的,如果ForkJoin池的状态是正常状态,如果当前有等待的工作线程,则唤醒它,如果没有等待的工作队列,则偿试创建一个新的工作队列 。
总之 deregisterWorker 方法从线程池里注销工作队列,清空WorkQueue,同时更新ctl,最后做可能的替换,根据线程池的状态决定是否找一个自己的替代者:
- 有空闲线程,则唤醒一个
- 没有空闲线程,再次尝试创建一个新的工作线程
private boolean tryRelease(long c, WorkQueue v, long inc) {
// SS_SEQ = 0000 0000 0000 0001 0000 0000 0000 0000
// ~INACTIVE = 0111 1111 1111 1111 1111 1111 1111 1111
int sp = (int)c, vs = (sp + SS_SEQ) & ~INACTIVE; Thread p;
// 如果当前v位于栈顶
if (v != null && v.scanState == sp) {
// UC_MASK = 1111 1111 1111 1111 1111 1111 1111 1111 0000 0000 0000 0000 0000 0000 0000 0000
// SP_MASK = 0000 0000 0000 0000 0000 0000 0000 0000 1111 1111 1111 1111 1111 1111 1111 1111
// 计算下一个ctl的值,活动线程数 AC + 1,通过stackPred取得前一个WorkQueue的索引,重新设置回sp,计算得最终的ctl值
long nc = (UC_MASK & (c + inc)) | (SP_MASK & v.stackPred);
if (U.compareAndSwapLong(this, CTL, c, nc)) {
// vs 的版本号加1,v.scanState记录 激活状态 + 当前版本号 + v 位于 ws 队列的索引
v.scanState = vs;
if ((p = v.parker) != null)
// 唤醒v线程
U.unpark(p);
return true;
}
}
return false;
}
final void transferStealCount(ForkJoinPool p) {
AtomicLong sc;
if (p != null && (sc = p.stealCounter) != null) {
int s = nsteals;
nsteals = 0;
// 偷取计数添加到池偷取计数器(如果存在),并重置。
sc.getAndAdd((long)(s < 0 ? Integer.MAX_VALUE : s));
}
}
final void cancelAll() {
ForkJoinTask t;
if ((t = currentJoin) != null) {
currentJoin = null;
// 将join过来的任务 ,取消掉
ForkJoinTask.cancelIgnoringExceptions(t);
}
if ((t = currentSteal) != null) {
currentSteal = null;
// 将偷取过来的任务取消掉
ForkJoinTask.cancelIgnoringExceptions(t);
}
while ((t = poll()) != null)
// 将当前队列中所有的任务取消掉
ForkJoinTask.cancelIgnoringExceptions(t);
}
static final void cancelIgnoringExceptions(ForkJoinTask t) {
if (t != null && t.status >= 0) {
try {
t.cancel(false);
} catch (Throwable ignore) {
}
}
}
public boolean cancel(boolean mayInterruptIfRunning) {
// DONE_MASK = 1111 0000 0000 0000 0000 0000 0000 0000
// 在setCompletion()方法中,如果status < 0 ,可能当前status 包含
// SIGNAL = 0000 0000 0000 0001 0000 0000 0000 0000 状态,因此
// 需要将status 的0~28位剔除掉,再与CANCELLED比较,如果相等,则一定是取消成功了
return (setCompletion(CANCELLED) & DONE_MASK) == CANCELLED;
}
private int setCompletion(int completion) {
for (int s;;) {
// 如果任务状态已经是 NORMAL,CANCELLED,EXCEPTIONAL ,则直接返回
if ((s = status) < 0)
return s;
if (U.compareAndSwapInt(this, STATUS, s, s | completion)) {
// 如果当前状态是SIGNAL = 0000 0000 0000 0001 0000 0000 0000 0000 状态
// 则需要通知其他所有等待中的线程
if ((s >>> 16) != 0)
synchronized (this) { notifyAll(); }
return completion;
}
}
}
// 如果now == true ,则立即终止ForkJoin池,在shutdownNow()方法调用时使用
// 如果enable ==true,则将runState变为SHUTDOWN ,等有机会再关闭ForkJoin池,这个和线程池源码一样,在shutdown()方法调用时使用
private boolean tryTerminate(boolean now, boolean enable) {
int rs;
// 如果是公共池,则直接返回false ,
if (this == common)
return false;
// 如果runState 不为SHUTDOWN 状态
if ((rs = runState) >= 0) {
// 如果 enable 为false 直接返回false,如果enable 为true ,则将当前runState设置为SHUTDOWN
if (!enable)
return false;
// 将池状态设置为SHUTDOWN
rs = lockRunState();
unlockRunState(rs, (rs & ~RSLOCK) | SHUTDOWN);
}
// 程序执行到这里 runState的状态至少为SHUTDOWN,如果runState不为STOP状态
if ((rs & STOP) == 0) {
if (!now) {
for (long oldSum = 0L;;) {
WorkQueue[] ws; WorkQueue w; int m, b; long c;
long checkSum = ctl;
// 如果当前激活工作线程数大于 0 ,则 直接返回false
if ((int)(checkSum >> AC_SHIFT) + (config & SMASK) > 0)
return false;
// 如果工作队列为空或其长度小于等于0,则直接退出循环
if ((ws = workQueues) == null || (m = ws.length - 1) <= 0)
break;
// 遍历所有的工作队列
for (int i = 0; i <= m; ++i) {
if ((w = ws[i]) != null) {
// 如果工作队列的扫描状态为激活状态,或者工作队列有任务,或者从其他队列中偷来的任务不为空
// 则激活并唤醒栈顶工作队列,并返回false
if ((b = w.base) != w.top || w.scanState >= 0 ||
w.currentSteal != null) {
tryRelease(c = ctl, ws[m & (int)c], AC_UNIT);
return false;
}
// 将所有偶数索引设置为终止状态
checkSum += b;
if ((i & 1) == 0)
w.qlock = -1;
}
}
// 如果遍历两圈,base == top ,并且w.scanState < 0 并且w.currentSteal == null,则退出循环
if (oldSum == (oldSum = checkSum))
break;
}
}
// 如果ForkJoin池的状态仍然不为STOP,则将ForkJoin池的状态设置为STOP
if ((runState & STOP) == 0) {
rs = lockRunState();
unlockRunState(rs, (rs & ~RSLOCK) | STOP);
}
}
int pass = 0;
for (long oldSum = 0L;;) {
WorkQueue[] ws; WorkQueue w; ForkJoinWorkerThread wt; int m;
long checkSum = ctl;
// 如果总工作线程数<= 0 或 workQueues 为空或 ws.length - 1 <= 0
if ((short)(checkSum >>> TC_SHIFT) + (config & SMASK) <= 0 ||
(ws = workQueues) == null || (m = ws.length - 1) <= 0) {
// 如果runState 不为TERMINATED ,则将runState 设置为TERMINATED
if ((runState & TERMINATED) == 0) {
rs = lockRunState();
unlockRunState(rs, (rs & ~RSLOCK) | TERMINATED);
synchronized (this) { notifyAll(); }
}
break;
}
// 如果workQueues !=null && ws.length > 0 ,并且总线程数> 0,下面代码要整体结合起来看,才看得明白
// 下面代码至少经历3次循环
// 第一次循环 oldSum == all(w.base) 之和
// 第二次循环,w.cancelAll(); 取消掉所有队列,并且 tryRelease(c, ws[sp & m], AC_UNIT);所有的队列
// 第三次循环 调用wt.interrupt(); 为所有工作线程设置中断标识,并且唤醒所有 U.unpark(wt); 工作线程
for (int i = 0; i <= m; ++i) {
if ((w = ws[i]) != null) {
checkSum += w.base;
w.qlock = -1;
if (pass > 0) {
// 将所有的任务设置为取消状态
w.cancelAll();
if (pass > 1 && (wt = w.owner) != null) {
if (!wt.isInterrupted()) {
try {
// 工作线程设置中断标识
wt.interrupt();
} catch (Throwable ignore) {
}
}
// 如果工作队列为非激活状态,则唤醒其工作线程
if (w.scanState < 0)
U.unpark(wt);
}
}
}
}
// 如果出现不稳定的因素,如 队列新加入任务,则之前的努力白费了,都重新再来
if (checkSum != oldSum) {
oldSum = checkSum;
pass = 0;
}
// 这里需要注意,为什么pass > 3 ,同时还设置pass > m
// 因为当前工作队列的长度可能只有2 ,因此需要加上 pass > 3 的判断,
// 为什么要加上pass > m 的判断呢?因为tryRelease()方法每次去激活工作队列,存在并发情况 。
// 即使每次执行下面代码块只唤醒了一个工作队列,经过m 次循环调用,最终还是能唤醒所有的工作队列的,这也就是需要判断 pass > m 的原因。
// while (j++ <= m && (sp = (int)(c = ctl)) != 0)
// tryRelease(c, ws[sp & m], AC_UNIT);
else if (pass > 3 && pass > m) // can't further help
break;
else if (++pass > 1) { // try to dequeue
long c; int j = 0, sp; // bound attempts
while (j++ <= m && (sp = (int)(c = ctl)) != 0)
tryRelease(c, ws[sp & m], AC_UNIT);
}
}
return true;
}
tryTerminate()方法的实现原理和线程池很像,使用也和线程池很像,如shutdown() 和shutdownNow()方法,其目的就是为了将池从SHUTDOWN ->STOP ->TERMINATED的状态转变,最终当总线程数小于等于0或workQueues为空或ws的长度为0时,则将线程池状态设置为TERMINATED 。
如果线程已经启动,我们来看线程启动代码。
public void run() {
if (workQueue.array == null) { // only run once
Throwable exception = null;
try {
// 留给子类实现
onStart();
pool.runWorker(workQueue);
} catch (Throwable ex) {
exception = ex;
} finally {
try {
//留给子类实现
onTermination(exception);
} catch (Throwable ex) {
if (exception == null)
exception = ex;
} finally {
pool.deregisterWorker(this, exception);
}
}
}
}
runWorker 是很常规的三部曲操作:
- scan: 通过扫描获取任务
- runTask:执行扫描到的任务
- awaitWork:没任务进入等待
final void runWorker(WorkQueue w) {
// 判断task是否需要扩容,如果需要扩容为原理两倍
w.growArray();
int seed = w.hint;
int r = (seed == 0) ? 1 : seed;
for (ForkJoinTask t;;) {
// 扫描任务
if ((t = scan(w, r)) != null)
// 执行任务
w.runTask(t);
else if (!awaitWork(w, r))
break;
r ^= r << 13; r ^= r >>> 17; r ^= r << 5; // xorshift
}
}
final ForkJoinTask[] growArray() {
ForkJoinTask[] oldA = array;
// 当数组容量小于 1 << 13时,则数组容量扩容为原来两倍
int size = oldA != null ? oldA.length << 1 : INITIAL_QUEUE_CAPACITY;
// 如果任务数组长度大于 1 << 26 时,抛出异常
if (size > MAXIMUM_QUEUE_CAPACITY)
throw new RejectedExecutionException("Queue capacity exceeded");
// 进行任务数组扩容
int oldMask, t, b;
// 遍历整个旧的数组,从base开始,一个一个的移到到新数组中
ForkJoinTask[] a = array = new ForkJoinTask[size];
if (oldA != null && (oldMask = oldA.length - 1) >= 0 &&
(t = top) - (b = base) > 0) {
int mask = size - 1;
do {
ForkJoinTask x;
int oldj = ((b & oldMask) << ASHIFT) + ABASE;
int j = ((b & mask) << ASHIFT) + ABASE;
x = (ForkJoinTask)U.getObjectVolatile(oldA, oldj);
if (x != null &&
// 将旧数组中的元素设置为空,有利于jvm回收
U.compareAndSwapObject(oldA, oldj, x, null))
// 将旧数组中的元素转移到新的数组中
U.putObjectVolatile(a, j, x);
} while (++b != t);
}
// 返回新数组
return a;
}
growArray()方法的实现逻辑还是很简单的,先判断新数组容量是否超限,如果没有超限,则将旧任务数组中的元素一个一个的转移到新任务数组中。接下来,我们来看scan()方法的实现。
private ForkJoinTask scan(WorkQueue w, int r) {
WorkQueue[] ws; int m;
if ((ws = workQueues) != null && (m = ws.length - 1) > 0 && w != null) {
// 记录扫描状态
int ss = w.scanState;
// origin 记录最初r的值
for (int origin = r & m, k = origin, oldSum = 0, checkSum = 0;;) {
WorkQueue q; ForkJoinTask[] a; ForkJoinTask t;
int b, n; long c;
// 如果k槽位不为空
if ((q = ws[k]) != null) {
// 如果q不为空,且q中有任务
if ((n = (b = q.base) - q.top) < 0 &&
(a = q.array) != null) {
// 从base ~ top 找任务
long i = (((a.length - 1) & b) << ASHIFT) + ABASE;
// 取出任务t
if ((t = ((ForkJoinTask)
U.getObjectVolatile(a, i))) != null &&
// 较验此时 base的任务有没有被其他线程取走,如果没有取走
q.base == b) {
// 如果工作队列scanState状态大于等于 0,表示当前任务为激活状态 ,从base端偷取
if (ss >= 0) {
// 将a[base] 置为空
if (U.compareAndSwapObject(a, i, t, null)) {
// base = base + 1
q.base = b + 1;
// 如果base - top < -1 ,即使取走一个任务,当前队列中至少还有一个任务没有消费掉,唤醒其他线程来执行任务
if (n < -1)
signalWork(ws, q);
return t;
}
}
// 如果oldSum == 0,表示此时线程的非激活状态不是由于遍历了一圈之后,线程由激活状态转化为非激活状态导致的
// w.scanState < 0 , 表示非激活状态
else if (oldSum == 0 &&
w.scanState < 0)
// 激活栈顶队列
tryRelease(c = ctl, ws[m & (int)c], AC_UNIT);
}
// 如果当前队列中有任务,但当前队列没有被激活状态 或 当前队列是激活状态,但任务被其他线程抢走
// 为了避免不必要的竞争,重置随机索引,换位置扫描,当前线程到其他队列中找任务
if (ss < 0)
ss = w.scanState;
r ^= r << 1; r ^= r >>> 3; r ^= r << 10;
origin = k = r & m;
// 一般查找两圈都没有找到任务,当前队列将进入非激活状态,凡是重置了随机索引,之前的努力都白费了,
// 重新来两圈
oldSum = checkSum = 0;
continue;
}
// 计数器
checkSum += b;
}
// 如果找了一圈都没有找到可执行任务,则进入下面代码块
if ((k = (k + 1) & m) == origin) {
// 如果队列是激活状态或遍历了一圈之后,当前队列的激活状态没有改变
if ((ss >= 0 || (ss == (ss = w.scanState))) &&
// 第一圈遍历,如果所有的队列都为空,则oldSum = 0 ,checkSum = all(base) 之和,因此不满足于进入下面代码块
// 此时将oldSum = checkSum = all(base ),并且重置checkSum = 0
// 第二圈遍历,仍然所有队列中的任务依然为空,此时 已经 oldSum = checkSum = all(base) ,
// 有资格进入下面代码
oldSum == (oldSum = checkSum)) {
// 如果当前队列已经是非激活状态,则直接退出
if (ss < 0 || w.qlock < 0)
break;
// INACTIVE = 1000 0000 0000 0000 0000 0000 0000 0000
// 将当前队列置为非激活状态
int ns = ss | INACTIVE;
// SP_MASK = 0000 0000 0000 0000 0000 0000 0000 0000 1111 1111 1111 1111 1111 1111 1111 1111
// UC_MASK = 1111 1111 1111 1111 1111 1111 1111 1111 0000 0000 0000 0000 0000 0000 0000 0000
// AC_UNIT = 0000 0000 0000 0001 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000
// 非激活状态队列个数加1 , sp = 当前队列的 (激活状态 + 索引位置)
long nc = ((SP_MASK & ns) |
(UC_MASK & ((c = ctl) - AC_UNIT)));
// stackPred 指向之前的非激活队列的索引
w.stackPred = (int)c;
// 设置w的scanState = ns
U.putInt(w, QSCANSTATE, ns);
// 设置ctl = 新的nc
if (U.compareAndSwapLong(this, CTL, c, nc))
// 如果设置成功,则再进行一次遍历,看其他队列中是否有任务,如果已经没有任务了,则退出循环
ss = ns;
else
// 如果nc 设置失败,则再进行一次遍历,如果所有的队列中没有任务了,则将当前队列scanState状态设置为非
// 激活状态,再进行一次遍历,如果所有的任务中没有任务了,才退出循环
w.scanState = ss;
}
checkSum = 0;
}
}
}
return null;
}
上面的代码有很多种情况,我这里列出几种情况让大家理解
- 如果队列的扫描状态为非激活状态,如果扫描所有的队列中的任务都为空,此时需要再扫描一圈,仍然没有扫描到任务 ,如果当前队列的扫描状态为非激活状态或者当前队列已经被终止,则直接退出循环,返回null。
- 如果当前的扫描状态为激活状态,如果扫描所有的队列中的任务都为空,则此时需要再扫描一圈,仍然没有扫描到任务,此时将当前队列的扫描状态设置为非激活状态,并且ws的ctl 中记录激活队列个数减1,ws的ctl 的低32位 记录当前队列的(激活状态 + scanState ) ,CAS操作设置ws的ctl值,如果设置成功,则再进行一次循环,此时ss < 0 ,退出循环,如果设置失败,先进行一轮循环,将当前队列的scanState设置为非激活状态,再进行一轮循环,如果仍然没有发现任务,此时ss < 0 ,则退出循环。
- 当前队列的scanState 为激活状态,并且在循环队列过程中,找到可执行任务,则直接返回任务。
- 如果当前队列的状态为非激活状态,但有队列有任务不为空,则激活int (ctl) 栈顶任务,之前的扫描全部作废,重新进行循环,但这里需要注意的是,激活的是栈顶任务,而不是当前队列的任务。
- 当前在2的情况中,如果当前队列的激活状态变成了非激活状态,此时再进行一轮循环时,发现队列中有任务了,此时会重置所有状态,相当于重新进入scan()方法,只是此时的队列的scanState为非激活状态。
希望这些例子,对你理解scan方法有所帮助 。
inal void runTask(ForkJoinTask task) {
if (task != null) {
// ~SCANNING = 1111 1111 1111 1111 1111 1111 1111 1110
// 运行到这里,当前队列的状态肯定是激活状态,那么最高位肯定为0
// 因此 scanState 一定是一个偶数,因此得出结论,scanState 为偶数时,是运行时状态
scanState &= ~SCANNING; // mark as busy
// task为从其他任务中偷来的任务,因此,currentSteal = stask ,并调用doExec()方法执行
(currentSteal = task).doExec();
// 将当前队列中偷来的任务置空
U.putOrderedObject(this, QCURRENTSTEAL, null);
// 执行剩余的本地任务
execLocalTasks();
ForkJoinWorkerThread thread = owner;
// 当前偷来的任务 + 1
if (++nsteals < 0)
// ws中偷取的任务数 + 1
transferStealCount(pool);
// SCANNING = 1 ,重置当前的scanState 状态为激活状态,因此可以得出结论,scanState 为奇数时
// 当前队列为激活状态
scanState |= SCANNING;
if (thread != null)
// 留给子类实现
thread.afterTopLevelExec();
}
}
接下来,我们来看执行本地任务
final void execLocalTasks() {
int b = base, m, s;
ForkJoinTask[] a = array;
if (b - (s = top - 1) <= 0 && a != null &&
(m = a.length - 1) >= 0) {
// 如果模式是LIFO_QUEUE 类型的,则从上往下取数据
if ((config & FIFO_QUEUE) == 0) {
for (ForkJoinTask t;;) {
// 如果取到为空,则直接退出
if ((t = (ForkJoinTask)U.getAndSetObject
(a, ((m & s) << ASHIFT) + ABASE, null)) == null)
break;
// 每次top --
U.putOrderedInt(this, QTOP, s);
// 执行任务
t.doExec();
// 如果top == base ,则退出
if (base - (s = top - 1) > 0)
break;
}
}
else
pollAndExecAll();
}
}
// 从下往上取数据
final void pollAndExecAll() {
for (ForkJoinTask t; (t = poll()) != null;)
// 执行任务
t.doExec();
}
final ForkJoinTask poll() {
ForkJoinTask[] a; int b; ForkJoinTask t;
while ((b = base) - top < 0 && (a = array) != null) {
int j = (((a.length - 1) & b) << ASHIFT) + ABASE;
t = (ForkJoinTask)U.getObjectVolatile(a, j);
if (base == b) {
if (t != null) {
if (U.compareAndSwapObject(a, j, t, null)) {
base = b + 1;
return t;
}
}
else if (b + 1 == top) // now empty
break;
}
}
return null;
}
执行本地任务的代码还是很简单的,如果模式为FIFO_QUEUE,则先进先出。那么从数组由下往上取数据,如果是LIFO_QUEUE模式,则先进后出,则从数组的由上往下取数据 。

接下来看doExec()的执行过程 。
final int doExec() {
int s; boolean completed;
if ((s = status) >= 0) {
try {
// 执行具体的任务
completed = exec();
} catch (Throwable rex) {
return setExceptionalCompletion(rex);
}
if (completed)
// 任务执行完毕,将当前任务的状态设置为NORMAL
s = setCompletion(NORMAL);
}
return s;
}
public abstract class RecursiveTask extends ForkJoinTask {
private static final long serialVersionUID = 5232453952276485270L;
V result;
protected abstract V compute();
public final V getRawResult() {
return result;
}
protected final void setRawResult(V value) {
result = value;
}
protected final boolean exec() {
// 调用我们自己写的compute 方法,并将执行结果保存到result中
result = compute();
return true;
}
}
我相信任务的执行逻辑还是简单的,最终调用我们自定义的compute方法,将执行结果存储到result中。
当找不到可执行任务时则会进入awaitWork(),我们继续看awaitWork()方法 。
private boolean awaitWork(WorkQueue w, int r) {
// 如果队列为空或已经终止了,结束外层循环
if (w == null || w.qlock < 0)
return false;
for (int pred = w.stackPred, spins = SPINS, ss;;) {
// 如果w工作队列为激活状态,则退出当前循环,继续外层循环
if ((ss = w.scanState) >= 0)
break;
// spins 自旋次数
else if (spins > 0) {
r ^= r << 6; r ^= r >>> 21; r ^= r << 7;
// r 可能是正数,也可能是负数,那么-- spins == 0 的次数也变成了一个随机数,
// 也就是每个线程的自旋次数是一个0 ~ spins之间的一个随机数。
if (r >= 0 && --spins == 0) {
WorkQueue v; WorkQueue[] ws; int s, j; AtomicLong sc;
// 前驱队列不为空
if (pred != 0 && (ws = workQueues) != null &&
(j = pred & SMASK) < ws.length &&
(v = ws[j]) != null &&
// 前驱队列的工作线程为空或扫描状态是激活状态,说明有任务来了
(v.parker == null || v.scanState >= 0))
// 重置自旋次数,再次等待,希望能分配到任务
spins = SPINS;
}
}
// 现次较验是w 否被终止了,如果被终止了,则退出外层循环
else if (w.qlock < 0)
return false;
else if (!Thread.interrupted()) {
long c, prevctl, parkTime, deadline;
// 我们知道,config 的 0 ~ 16 位记录了工作队列的并行度, 而 ctl 的 48 ~ 64 位记录的是当前工作线程 - 并行度
// 因此ac 的值就是当前激活的工作线程数
int ac = (int)((c = ctl) >> AC_SHIFT) + (config & SMASK);
// 如果工作线程数小于等于0 ,并且池终止成功 或 当前runState 为STOP状态 ,则直接退出外层循环
if ((ac <= 0 && tryTerminate(false, false)) ||
(runState & STOP) != 0)
return false;
// 如果当前线程是最后一个 inactive 的,不能永远阻塞,否则没有线程能唤醒, 所以需要计算阻塞时间
if (ac <= 0 && ss == (int)c) {
// 计算当前w的前一个等待者的ctl
prevctl = (UC_MASK & (c + AC_UNIT)) | (SP_MASK & pred);
//TC_SHIFT = 32 , t 为当前总的工作线程数 - 并行度
int t = (short)(c >>> TC_SHIFT);
// 如果总工作线程数减并行度 大于2 ,并且 ctl 设置成功,直接退出外层循环,立即销毁
if (t > 2 && U.compareAndSwapLong(this, CTL, c, prevctl))
return false;
// 如果t < 2 ,IDLE_TIMEOUT = 2 秒,TIMEOUT_SLOP = 20毫秒
//
parkTime = IDLE_TIMEOUT * ((t >= 0) ? 1 : 1 - t);
deadline = System.nanoTime() + parkTime - TIMEOUT_SLOP;
}
else
// 如果当前激活工作线程数大于 0 或 当前w 不是最后一个等待队列
prevctl = parkTime = deadline = 0L;
Thread wt = Thread.currentThread();
// 将wt 的 parkBlocker 设置为pool
U.putObject(wt, PARKBLOCKER, this);
// w 的线程设置为当前线程
w.parker = wt;
// 如果w的扫描状态为非激活状态 并且 ctl 没有发生过改变
if (w.scanState < 0 && ctl == c)
// 阻塞住当前线程
U.park(false, parkTime);
// 设置 w 的parker 为空, wt 的parkBlocker为空
U.putOrderedObject(w, QPARKER, null);
U.putObject(wt, PARKBLOCKER, null);
// 如果工作队列的扫描状态为激活状态,则工作线程继续开始工作
if (w.scanState >= 0)
break;
// 当激活线程数小于等待0 ,总线程数- 并行度 <= 2 时,并且当前工作线程为最后一个等待者,
// 也就是最顶部的等待者,并且在阻塞 parkTime之后自动唤醒,并且ctl 更新成功。则退出外层循环
// 我相信此时此刻大家对deadline = System.nanoTime() + parkTime - TIMEOUT_SLOP 这一行代码理解了
// TIMEOUT_SLOP = 20 ms ,假如 parkTime = 2000 毫秒,可能在1990毫秒时,CPU就分配给了
// 线程时间片,此时 2000 - 1990 - 20 < 0 ,此时就可以终止外层循环了,如果有些CPU的偏差比较大
// 可以调大 TIMEOUT_SLOP 的值
if (parkTime != 0L && ctl == c &&
deadline - System.nanoTime() <= 0L &&
U.compareAndSwapLong(this, CTL, c, prevctl))
return false;
}
}
return true;
}
我们来总结一下awaitWork()方法的主要意图。 大家需要注意,凡是awaitWork()方法返回false, ForkJoinWorkerThread线程将运行结束。
- 如果w的扫描状态为激活状态,则不等待
- 如果w是终止状态,终止线程
- 如果w的前驱队列为激活状态并且不为空,则再自旋一会,说不定就有任务了。
- 如果当前池的激活线程数小于0 ,并且tryTerminate()方法调用成功,或者runState = STOP,则直接终止线程
- 如果当前池的激活线程数小于0 ,并且当前w是最后一个等待队列,并且总线程数 - 并行度 >2 ,则直接终止当前线程,如果总线程数- 并行度 < 2 ,则阻塞一定时间 ,在阻塞过程中被唤醒或阻塞一段时间自动唤醒,如果线程所属队列的扫描状态为激活状态,则继续外层循环(主要是扫描任务的操作),如果在阻塞中自动唤醒的线程,并且ctl没有被修改过,则线程终止掉。
接下来,我们来看fork()方法,fork() 做的工作只有一件事,既是把任务推入当前工作线程的工作队列里。可以参看以下的源代码:
public final ForkJoinTaskfork() { Thread t; if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread) // 如果当前线程是ForkJoinWorkerThread的子类,则直接push到ForkJoinWorkerThread所在队列即可 ((ForkJoinWorkerThread)t).workQueue.push(this); else // 否则调用externalPush()方法将当前任务添加到工作队列中 ForkJoinPool.common.externalPush(this); return this; } final void push(ForkJoinTask task) { ForkJoinTask[] a; ForkJoinPool p; int b = base, s = top, n; if ((a = array) != null) { int m = a.length - 1; U.putOrderedObject(a, ((m & s) << ASHIFT) + ABASE, task); U.putOrderedInt(this, QTOP, s + 1); if ((n = s - b) <= 1) { if ((p = pool) != null) p.signalWork(p.workQueues, this); } else if (n >= m) growArray(); } }
push()方法的原理很简单,直接将task添加到数组中即可,如果top - base <= 1,则可能 w被阻塞,需要唤醒工作队列 。
如果top - base >= m ,则达到了数组的容量,需要对数组进行扩容 。
join() 的工作则复杂得多,也是 join() 可以使得线程免于被阻塞的原因——不像同名的 Thread.join()。
- 检查调用 join() 的线程是否是 ForkJoinThread 线程。如果不是(例如 main 线程),则阻塞当前线程,等待任务完成。如果 是,则不阻塞。
- 查看任务的完成状态,如果已经完成,直接返回结果。
- 如果任务尚未完成,但处于自己的工作队列内,则完成它。
- 如果任务已经被其他的工作线程偷走,则窃取这个小偷的工作队列内的任务(以 方式),执行,以期帮助它早日完成欲 join 的任务。
- 如果偷走任务的小偷也已经把自己的任务全部做完,正在等待需要 join 的任务时,则找到小偷的小偷,帮助它完成它的任务。 6. 递归地执行第5步。
将上述流程画成序列图的话就是这个样子:

接下来,我们再来看看join()方法的实现。
public final V join() {
int s;
if ((s = doJoin() & DONE_MASK) != NORMAL)
reportException(s);
return getRawResult();
}
private int doJoin() {
int s;
Thread t;
ForkJoinWorkerThread wt;
ForkJoinPool.WorkQueue w;
// 有结果,直接返回
if((s = status) < 0) {
return s;
}else {
// 如果是 ForkJoinWorkerThread Worker
if((t = Thread.currentThread()) instanceof ForkJoinWorkerThread) {
// 类似上面提到的 scan,但是是专项尝试从本工作队列里取出等待的任务
if((w = (wt = (ForkJoinWorkerThread) t).workQueue).tryUnpush(this)
// 取出了任务,就去执行它,并返回结果
&& (s = doExec()) < 0) {
return s;
}else {
// 也有可能别的线程把这个任务偷走了或者有新的任务join到当前队列,那就执行内部等待方法
return wt.pool.awaitJoin(w, this, 0L);
}
}else {
// 如果不是 ForkJoinWorkerThread,执行外部等待方法
return externalAwaitDone();
}
}
}
final boolean tryUnpush(ForkJoinTask t) {
ForkJoinTask[] a; int s;
if ((a = array) != null && (s = top) != base &&
// 如果array的顶部依然是t,则置空,并取出
U.compareAndSwapObject
(a, (((a.length - 1) & --s) << ASHIFT) + ABASE, t, null)) {
U.putOrderedInt(this, QTOP, s);
return true;
}
return false;
}
如果线程被别的任务偷走了。 我们来看awaitJoin()方法的内部实现。
final int awaitJoin(WorkQueue w, ForkJoinTask task, long deadline) {
int s = 0;
if (task != null && w != null) {
ForkJoinTask prevJoin = w.currentJoin;
U.putOrderedObject(w, QCURRENTJOIN, task);
CountedCompleter cc = (task instanceof CountedCompleter) ?
(CountedCompleter)task : null;
for (;;) {
// 如果任务状态小于0,则直接退出
if ((s = task.status) < 0)
break;
if (cc != null)
// 如果task 是CountedCompleter的子类
helpComplete(w, cc, 0);
//如果当前队列任务为空,为空说明当前任务被其他工作线程给窃取了
//tryRemoveAndExec是用于尝试执行存到队列中的当前任务,应为这个任务可能不在栈顶
//如果队列中没有找到当前join的这个任务,那很明显被其他工作线程给偷走了
else if (w.base == w.top || w.tryRemoveAndExec(task))
helpStealer(w, task);
if ((s = task.status) < 0)
break;
long ms, ns;
// 任务等待时间
if (deadline == 0L)
ms = 0L;
// 超时退出
else if ((ns = deadline - System.nanoTime()) <= 0L)
break;
else if ((ms = TimeUnit.NANOSECONDS.toMillis(ns)) <= 0L)
ms = 1L;
// 尝试补偿策略(找一个替代者执行任务,自己在这儿等)
if (tryCompensate(w)) {
// 补偿成功,指定阻塞时间 ,将当前任务的状态设置为SIGNAL状态
task.internalWait(ms);
// 活跃线程加1
U.getAndAddLong(this, CTL, AC_UNIT);
}
}
// 设置回前一个join的任务
U.putOrderedObject(w, QCURRENTJOIN, prevJoin);
}
return s;
}
final boolean tryRemoveAndExec(ForkJoinTask task) {
ForkJoinTask[] a; int m, s, b, n;
// 如果当前队列中的任务为空,则直接返回true,需要去其他队列中偷取任务
if ((a = array) != null && (m = a.length - 1) >= 0 &&
task != null) {
while ((n = (s = top) - (b = base)) > 0) {
for (ForkJoinTask t;;) { // traverse from s to b
long j = ((--s & m) << ASHIFT) + ABASE;
// 如果当前a[top-1]的任务被其他线程偷取
if ((t = (ForkJoinTask)U.getObject(a, j)) == null)
// 如果发生了任务的窃取,那么说明此时的s已经执行到了栈底
return s + 1 == top;
// 如果当前a[top-1]的任务等于当前任务,证明task没有被其他工作线程偷取
else if (t == task) {
boolean removed = false;
// 从数组的顶部弹出任务,如果此时没有其他任务加到当前队列中
if (s + 1 == top) {
// 当前join任务在栈顶,尝试将其弹出
// 如果cas失败,任务被其他线程偷走,此时的队列已经空了
if (U.compareAndSwapObject(a, j, task, null)) {
// 将当前任务从数组顶部移除 ,top = top - 1
U.putOrderedInt(this, QTOP, s);
removed = true;
}
}
// 如果s + 1 != top ,则表明有其他任务添加到当前队列中.
// 为什么不是 top 任务被其他工作线程消费了呢? 细心的读者发现无论是scan()方法还是helpStealer()方法,都是
// 从数组底部取任务的,而不会从数组顶部取任务,而base = b 的情况,s + 1 != top ,只可能是s + 1 = top + 1
else if (base == b)
// 因为有其他任务加到了当前数组的顶部,而task不能等到其他任务执行完之后再执行吧
// 而当前任务所在数组位置的任务又不能空着,很多地方都是以null作为并发判断,其他工作线程取到null时会认
// 为任务被其他线程抢先了,这样就永远获取不到任务了
// 因此插入一个空任务替换到掉当前任务,当前任务的执行也没有后顾之忧了
removed = U.compareAndSwapObject(
a, j, task, new EmptyTask());
if (removed)
// 执行当前任务
task.doExec();
break;
}
// 如果t已经被执行完或取消,并且t没有从队列中移除,将t从队列中移除
// 通常我们的任务都是先取,然后cas将对应坑位置空,再去执行的,为什么这里会出现任务还在
// 队列中,任务却已执行完成的情况呢?前面我们看到如果当前join的任务不是在栈顶,那么这个会被EmptyTask
// 占位替换,这个EmptyTask的任务状态直接就是NORMAL(正常完成状态)
else if (t.status < 0 && s + 1 == top) {
if (U.compareAndSwapObject(a, j, t, null))
U.putOrderedInt(this, QTOP, s);
break;
}
// 如果之前只有一个任务,但有新任务增加,或当前任务还处于等待状态,返回false
if (--n == 0)
return false;
}
// 如果任务已经完成
if (task.status < 0)
return false;
}
}
return true;
}
队列为空且任务未知,则帮助偷取当前工作线程的任务的工作线程执行任务 。
helpStealer 偷取
private void helpStealer(WorkQueue w, ForkJoinTask task) {
WorkQueue[] ws = workQueues;
int oldSum = 0, checkSum, m;
if (ws != null && (m = ws.length - 1) >= 0 && w != null &&
task != null) {
do {
checkSum = 0;
ForkJoinTask subtask;
// v 是任务的偷取者
WorkQueue j = w, v;
descent: for (subtask = task; subtask.status >= 0; ) {
// 遍历 ws 中所有的奇数索引工作队列
// 其实就是遍历,不过是跳着遍历,因为所有工作线程的队列都在奇数位
for (int h = j.hint | 1, k = 0, i; ; k += 2) {
// 没有发现偷取者,直接跳转到descent
if (k > m)
break descent;
// 如果找到了偷取者
if ((v = ws[i = (h + k) & m]) != null) {
if (v.currentSteal == subtask) {
// 定位到偷取者,更新hint为偷取者索引,方便下次定位
j.hint = i;
break;
}
checkSum += v.base;
}
}
for (;;) {
ForkJoinTask[] a; int b;
checkSum += (b = v.base);
// 记录偷取者join的任务
ForkJoinTask next = v.currentJoin;
// 如果子任务被执行完毕或 加入的任务不等于子任务或当前偷取者偷取的任务不等于子任务
// 1.任务已经被偷取者执行完毕
// 2. j又有新的子任务加入进来
// 3. v偷取的任务不再是之前的 j 的子任务,则重新再来
if (subtask.status < 0 || j.currentJoin != subtask ||
v.currentSteal != subtask)
break descent;
// 如果偷取者没有任何可执行的任务
if (b - v.top >= 0 || (a = v.array) == null) {
// 如果偷取者没有子任务添加,则退出循环
if ((subtask = next) == null)
break descent;
// 如果偷取者的任务已经执行完,但偷取者有子任务添加,且被其他工作线程偷取了
// 则当前工作线程要帮助偷取了 v 的任务工作队列执行任务,此时subtask= v.currentJoin
// 以此循环往复,也就是帮助偷取者的偷取者执行任务...
j = v;
break;
}
// 从偷取者的base中取任务
int i = (((a.length - 1) & b) << ASHIFT) + ABASE;
ForkJoinTask t = ((ForkJoinTask)
U.getObjectVolatile(a, i));
// 如果没有其他来线程来偷取任务
if (v.base == b) {
// 如果任务被取走,重新递归
if (t == null)
break descent;
// 将任务取出
if (U.compareAndSwapObject(a, i, t, null)) {
// base ++
v.base = b + 1;
// 记录调用者之前偷取的任务
ForkJoinTask ps = w.currentSteal;
int top = w.top;
do {
// 更新currentSteal 为刚刚偷来的任务
U.putOrderedObject(w, QCURRENTSTEAL, t);
t.doExec();
// 如果task没有被执行并且有新的任务加到了w,并且从w中弹出任务不为空
// 先执行w自己的任务
} while (task.status >= 0 &&
w.top != top &&
(t = w.pop()) != null);
// 恢复w 之前的currentSteal偷来的任务
U.putOrderedObject(w, QCURRENTSTEAL, ps);
// 如果 w 自己有任务需要执行了,则直接退出,否则继续帮助偷取者执行任务
if (w.base != w.top)
return;
}
}
}
}
//退出 helpStealer 的条件有两个,满足其一即可:
//1.自己 join 的任务已经执行完了,还是自己的工作优先;
//2.虽然自己 join 的任务还没有执行完,但是也找不到任务可以窃取了,
// 继续循环也只是空跑,浪费 cpu 资源,所以退出去后面阻塞当前线程
} while (task.status >= 0 && oldSum != (oldSum = checkSum));
}
}
-
每次跳2个槽位,遍历奇数位索引,直到定位到偷取者,并记录偷取者的索引(hint = i),方便下次定位。
-
获取偷取者的任务列表,帮助其执行任务,如果执行过程中发现自己任务列表里有任务,则依次弹出执行。
-
如果偷取者任务队列为空,则帮助其执行Join任务,寻找偷取者的偷取者,如此往复,加快任务执行。
-
如果最后发现自己任务队列不为空(base != top),则退出帮助。
-
最后判断任务task是否结束,如果未结束,且工作队列base和在变动中,说明偷取任务一直在进行,则重复以上操作,加快任务执行
-
currentSteal:当前线程窃取过来的任务;
-
currentJoin:导致当前线程阻塞的任务。
helpStealer 方法与 scan 方法之后的 runTask 方法是呼应的,runTask 方法中执行窃取的任务时会先给 currentSteal 变量赋值。
helpStealer 方法其实不仅仅是 help stealer,还会 help stealer’s stealer,help stealer’s stealer’s … stealer’s stealer,比如:
- thread1 在 task1 上 join;
- 通过遍历比较发现 task1 == thread2.currentSteal;
- thread1 从 thread2 队列底部窃取一个任务;
- thread1 再从 thread2 队列底部窃取一个任务;
- 继续从底部窃取…
- thread2 队列没有任务了,thread1 继续寻找窃取了 thread2.currentJoin 的线程;
- 通过遍历比较发现 thread2.currentJoin == thread3.currentSteal;
- thread1 从 thread3 队列底部窃取一个任务;
- 继续从底部窃取…
- thread3 队列没有任务了,thread1 继续寻找窃取了 thread3.currentJoin 的线程;
- 不断循环…
所以,currentJoin 和 currentSteal 其实记录了一条链路:thread1.currentJoin -> thread2.currentSteal -> thread2.currentJoin -> thread3.currentSteal -> thread3.currentJoin -> …
当然,一些情况会导致这条链路断开:
- 任何一个线程的 currentJoin 或 currentSteal 为 null;
- 任何一个线程的 currentJoin 或 currentSteal 已经执行完成;
- 自己 join 的任务已被执行完成。
需要注意的是:
- help stealer 只会发生在工作线程的队列之间,所以在上一节的 submit 子任务的示例中,help stealer 不会起作用;
- help stealer 虽然也会执行子任务,但它在功能上不是必须的,而是一个性能优化,优化点在于减少线程因为 join 而阻塞,join 期间帮其它线程执行一个任务,可能 join 的任务就执行完了。
private boolean tryCompensate(WorkQueue w) {
boolean canBlock;
WorkQueue[] ws; long c; int m, pc, sp;
// 如果ForkJoin池被中止了 ,不需要进入阻塞
if (w == null || w.qlock < 0 ||
(ws = workQueues) == null || (m = ws.length - 1) <= 0 ||
(pc = config & SMASK) == 0)
canBlock = false;
// sp != 0 ,则表明有空闲线程
else if ((sp = (int)(c = ctl)) != 0)
// 去释放空闲的工作线程,这里的第三个参数为0 ,因为如果为canBlock为true
// 执行tryCompensate()方法后,会将激活线程数加1 ,因此这里传0 即可
canBlock = tryRelease(c, ws[sp & m], 0L);
else {
// 当前激活工作线程数
int ac = (int)(c >> AC_SHIFT) + pc;
// 当前总工作线程数
int tc = (short)(c >> TC_SHIFT) + pc;
int nbusy = 0;
for (int i = 0; i <= m; ++i) {
WorkQueue v;
// 遍历所有的奇数索引
if ((v = ws[((i << 1) | 1) & m]) != null) {
// 统计正在running的工作线程,直到找到
if ((v.scanState & SCANNING) != 0)
break;
++nbusy;
}
}
// 如果正在运行的线程数 不等于总工作线程数的2倍 或 ctl 的值发生改变,直接非阻塞
// 在争用、检测到过时、不稳定或终止时返回false
if (nbusy != (tc << 1) || ctl != c)
canBlock = false;
// 如果总线程数大于 并行 度,并且激活线程数大于 1 (如果所有的工作线程都睡眠了
// 就没有工作线程来唤醒睡眠的工作线程了),并且当前工作线程的队列已经是空
// 则更新ctl 的值
else if (tc >= pc && ac > 1 && w.isEmpty()) {
// 激活线程数 -1
long nc = ((AC_MASK & (c - AC_UNIT)) |
(~AC_MASK & c));
canBlock = U.compareAndSwapLong(this, CTL, c, nc);
}
// 如果总工作线程数 大于 2 ^ 16 次 -1 ,或者当前ForkJoin池是公共池,
// 则 总线程数大于 并行度+ 256 ,则抛出RejectedExecutionException异常
else if (tc >= MAX_CAP ||
(this == common && tc >= pc + commonMaxSpares))
throw new RejectedExecutionException(
"Thread limit exceeded replacing blocked worker");
else {
boolean add = false; int rs;
// 总工作线程数 + 1
long nc = ((AC_MASK & c) |
(TC_MASK & (c + TC_UNIT)));
if (((rs = lockRunState()) & STOP) == 0)
add = U.compareAndSwapLong(this, CTL, c, nc);
unlockRunState(rs, rs & ~RSLOCK);
canBlock = add && createWorker();
}
}
return canBlock;
}
这段代码的思想就是尝试减少活动计数(有时是隐式的),并可能释放或创建一个补偿工作进程,为阻塞做准备,如果ForkJoin池属于终止状态,则当前线程不阻塞,如果有空闲工作线程,则唤醒空闲工作线程,如果总工作线程大于并行度,并且激活线程数大于1,并且当前队列为空,则减少工作线程数,当前工作线程进入阻塞。 如果既没有空闲的工作线程,当前总线程数也并没有大于并行度,只能通过createWorker()的方式来增加工作线程了。当前线程进入阻塞 。
final void internalWait(long timeout) {
int s;
if ((s = status) >= 0 && // force completer to issue notify
U.compareAndSwapInt(this, STATUS, s, s | SIGNAL)) {
synchronized (this) {
if (status >= 0)
try { wait(timeout); } catch (InterruptedException ie) { }
else
notifyAll();
}
}
}
这是网上其他小伙伴的总结
对于一个 new ForkJoinPool(),执行任务全流程如下:
ForkJoinPool 初始化 parallelism size = cpu 逻辑核心数,没有队列,没有线程;
向 ForkJoinPool 提交一个任务;
初始化队列数组,容量为 2 * Max { parallelism size, 2 ^ n };
创建一个没有线程的队列,容量为 2 ^ 13,随机放在队列数组的某一个偶数索引处;
任务存入这个队列索引值为 2 ^ 12 处;
再创建一个有线程的队列,容量为 2 ^ 13,随机放在队列数组的某一个奇数索引处;
线程启动;
线程从随机一个队列开始,遍历所有队列,最终扫描找到前面提交的任务,并从其所在队列取出;
线程执行任务,拆分出两个子任务;
如果用 invokeAll 提交,则一个进入线程所在队列,另一个直接在线程里执行;
如果用 fork 提交,则两个都进入线程所在队列;
提交的子任务触发创建新的线程,及与其对应的队列,还是在奇数索引处;
提交的子任务可能仍然被当前线程执行,可能被其它线程窃取;
线程在子任务处 join,join 期间会尝试从窃取自己任务的线程那里窃取任务执行;
优先窃取队列底部;
队列没有任务则窃取其正在 join 的任务;
还没有则阻塞自己等待被唤醒,在阻塞之前会补偿一个活跃线程;
提交的子任务不管被哪个线程执行,仍会重复上述拆分、提交、窃取、阻塞流程;
当任务被拆分的足够细,则会真正开始计算;
计算完成从递归一层一层返回;
最终所有子任务都完成,得到结果;
如果不再提交任务,所有线程扫描不到任务进入 inactive 状态;
最终,所有线程销毁,所有奇数索引位的队列回收,ForkJoinPool 中只剩下一个最初创建的在偶数索引位的队列。
参考文章
JUC源码分析-线程池篇(四):ForkJoinPool - 1
线程池:ForkJoinPool 源码解析
forkJoin源码解读