监控系统-Prometheus(普罗米修斯)(四)存储机制(Long-Term Storage)
文章目录
- 监控系统-Prometheus(普罗米修斯)(四)存储机制(Long-Term Storage)
-
- 背景
- Long-Term Storage
- 什么是时序数据?
- 存储配置
- 远程存储方案主要有哪些?
-
- Prometheus Long-Term Storage 远程存储方案对比
- 参考
- Prometheus 使用 Victoria Metrics远程存储
- 基于VictoriaMetrics的prometheus 集群监控报警方案
监控系统-Prometheus(普罗米修斯)(四)存储机制(Long-Term Storage)
官方文档:https://prometheus.io/docs/prometheus/latest/storage/
背景
Prometheus提供了两种数据持久化方式:一种是本地存储,通过Prometheus自带的TSDB(时序数据库),将数据保存到本地磁盘。
Prometheus本地数据存储能力一直为大家诟病,但Prometheus本地存储设计的初衷就是为了监控数据的查询,Facebook发现85%的查询是针对26小时内的数据。所以Prometheus本地时序数据库的设计更多考虑的是高性能而非分布式大容量。
另一种是远端存储,适用于大量历史监控数据的存储和查询。
Prometheus提供了本地存储,即tsdb时序数据库,本地存储给Prometheus带来了简单高效的使用体验,prometheus2.0以后压缩数据能力也得到了很大的提升。可以在单节点的情况下满足大部分用户的监控需求。
Prometheus默认是自己带有存储的,保存的时间为15天。但本地存储也意味着Prometheus无法持久化数据,无法存储大量历史数据,同时也无法灵活扩展。
prometheus提供了本地存储,即tsdb时序数据库。本地存储的优势就是运维简单,缺点就是无法海量的metrics持久化和数据存在丢失的风险
本地存储也限制了Prometheus的可扩展性,带来了数据持久化等一系列的问题。为了解决单节点存储的限制,prometheus没有自己实现集群存储,而是提供了远程读写的接口,让用户自己选择合适的时序数据库来实现prometheus的扩展性。
为了保证Prometheus的简单性,Prometheus并没有从自身集群的维度来解决这些问题,而是定义了两种接口,remote_write/remote_read,将数据抛出去,你自己处理。
Prometheus 2017 年加入了 remote read/write API,成了 Prometheus 社区创新的起点。
官网有一句话:Again, Prometheus’s local storage is not meant as durable long-term storage.或许使用Prometheus的本地存储作为平台持久化存储的数据库不是明智的选择。
Long-Term Storage
参考URL: https://www.oreilly.com/library/view/prometheus-up/9781492034131/ch01.html
Since Prometheus stores data only on the local machine, you are limited by how much disk space you can fit on that machine.8 While you usually care only about the most recent day or so worth of data, for long-term capacity planning a longer retention period is desirable.
Prometheus does not offer a clustered storage solution to store data across multiple machines, but there are remote read and write APIs that allow other systems to hook in and take on this role. These allow PromQL queries to be transparently run against both local and remote data.
什么是时序数据?
在数据库领域有一种数据库叫做时序数据库,那么相比于传统的关系数据库这种数据库有什么特点呢?
时序数据库中存储的时序数据就是带着时间戳的数据,采集时序数据的目的是监测数据的前后差异,然后做出响应。
时序数据库出现的时间较晚,目前较成熟的时序数据库都仅有2、3年的历史。
InfluxDB(单机版免费,集群版收费)最成熟,Kairosdb(底层使用Cassandra),OpenTsdb(底层使用HBase),beringei(Facebook开源),TimeScaleDB(底层基于PostgreSQL),TSDB(百度开源),HiTSDB(阿里开源,底层是PostgreSQL)。
在万物互联(IoT)兴起的推动下,时间序列数据(衡量事物随时间变化的数据)的应用和场景激增,是增长最快的数据类型之一,例如监控指标数据、传感器数据、日志等等。
时序数据的主要来源有以下三个方面:
- IOT
主要来源是传感器,比如某点的温度、湿度、压力、电流、电压等 - 金融和科学数据
比如交易时段的证券价格,地震监控数据等 - IT 基础架构
这里的主要来源是软硬件的监控数据
存储配置
对于本地存储,prometheus提供了一些配置项,主要包括
–storage.tsdb.path: 存储数据的目录,默认为data/,如果要挂外部存储,可以指定该目录
–storage.tsdb.retention.time: 数据过期清理时间,默认保存15天
–storage.tsdb.retention.size: 实验性质,声明数据块的最大值,不包括wal文件,如512MB
–storage.tsdb.retention: 已被废弃,改为使用storage.tsdb.retention.time
远程存储方案主要有哪些?
来自官方文档: https://prometheus.io/docs/operating/integrations/#remote-endpoints-and-storage
TiDB 默认使用的是 Prometheus 进行的监控采集,但有时候在监控数据量太大的时候,Promethues 也会遇到一些性能问题
- AppOptics: write
- AWS Timestream: read and write
- Azure Data Explorer: read and write
- Azure Event Hubs: write
- Chronix: write
- Cortex: read and write
- CrateDB: read and write
- Elasticsearch: write
- Gnocchi: write
- Google BigQuery: read and write
- Google Cloud Spanner: read and write
- Grafana Mimir: read and write
- Graphite: write
- InfluxDB: read and write
- Instana: write
- IRONdb: read and write
- Kafka: write
- M3DB: read and write
- New Relic: write
- OpenTSDB: write
- PostgreSQL/TimescaleDB: read and write
- QuasarDB: read and write
- SignalFx: write
- Splunk: read and write
- Sysdig Monitor: write
- TiKV: read and write
- Thanos: read and write
- VictoriaMetrics: write
- Wavefront: write
重点关注:
❏ M3DB
M3DB是Uber开源的一款分布式时序数据库,已在Uber内部使用多年。
❏ VictoriaMetrics
维多利亚度量 VictoriaMetrics是一个快速,经济高效且可扩展的监视解决方案和时间序列数据库。
VictoriaMetrics 是一个不错的prometheus 集群方案,同时也提供了比较全的周边工具,同时社区也很活跃。
❏ Thanos
英国游戏技术公司 Improbable 开源了他们的Prometheus 高可用解决方案。Thanos 方案本身对于Prometheus 没有任何强势侵入,并增强了Prometheus的短板。最后Thanos 依赖于对象存储系统
Thanos很重要的一个功能,就是降采样
Victoria Metrics 目前只在商业版本上线了降采样功能,开源版本并未透出。
❏ Cortex
由 Grafana 开源,是 Loki, Tempo, Grafana Cloud 等产品的基础
❏ Grafana Mimir
数据持久化到硬盘选择 VictoriaMetrics 是更好的选择。数据持久化到对象存储的方案Thanos更受欢迎!
可以使用读写完整的 InfluxDB,我们使用了多prometheus server同时远程读+写,验证了速度还是可以的。并且InfluxDB生态完整,自带了很多管理工具。
Prometheus Long-Term Storage 远程存储方案对比
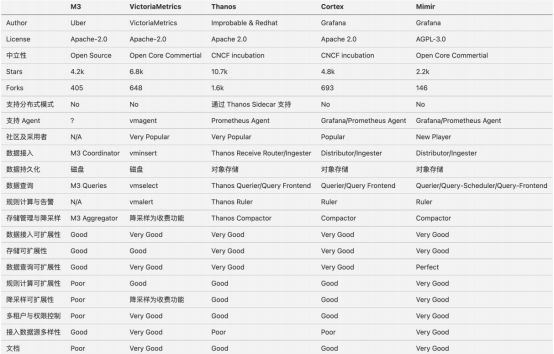
参考
Thanos 与 VictoriaMetrics,谁才是打造大型 Prometheus 监控系统的王者?
参考URL: https://blog.csdn.net/alex_yangchuansheng/article/details/108271368
CSDN云原生系列Meetup·北京站
参考URL: https://t.csdnimg.cn/CFuj
Prometheus 使用 Victoria Metrics远程存储
参考URL: https://blog.csdn.net/qq_37362891/article/details/119577204
基于VictoriaMetrics的prometheus 集群监控报警方案
基于VictoriaMetrics的prometheus 集群监控报警方案
参考URL: https://www.cnblogs.com/rongfengliang/p/12882955.html