吴恩达深度学习笔记-单层神经网络(第2课)
深度学习笔记
- 1、 神经网络概览
- 2、神经网络表示
- 3、计算神经网络的输出
- 4、多个样本的向量化
- 5、向量化实现的解释
- 6、激活函数
- 7、为什么需要非线性激活函数?
- 8、激活函数的导数
- 9、神经网络的梯度下降法
- 10、直观理解反向传播
- 11、随机初始化
1、 神经网络概览
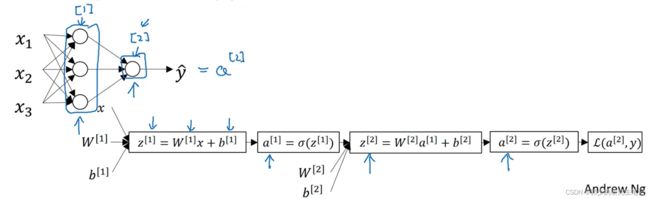
z[i]表示第i层的输入,a[i]表示第i层的输出
2、神经网络表示
单层神经网络:
【一般不把输入层看作一个标准层】
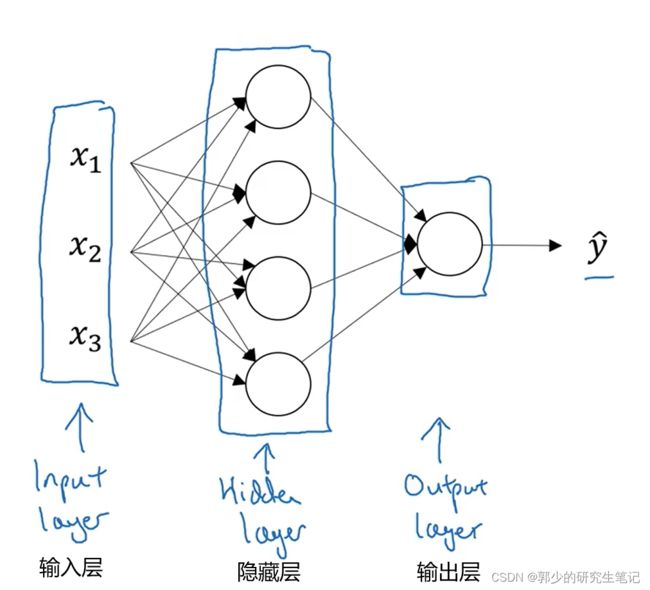
隐藏层的含义是在训练集中,这些中间节点的真正数值我们是不知道的。在训练集我们只能看到输入值X和输出值Y。
对于输入层的X,可以使用a[0]表示
.
a[i]j表示第i层的第j个输入feature值
3、计算神经网络的输出
下图是逻辑回归的输出计算过程:

神经网络其实就是重复了逻辑回归的计算过程。以下图的神经网络为例子:
先省略其他节点,只看第一个节点:

接下来只看隐藏层的第二个节点:
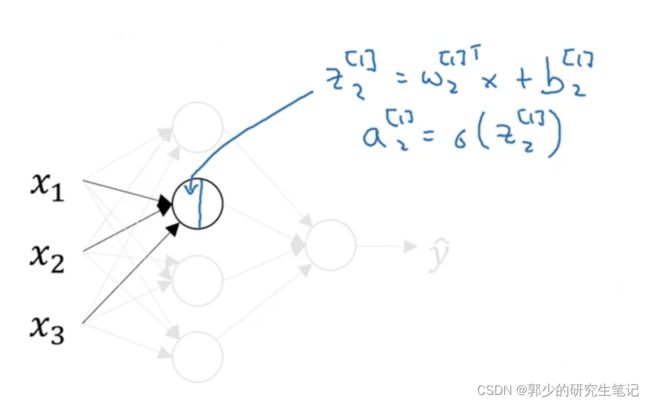
神经网络中的各节点与左边的Logistic回归单元类似
将上述隐藏层各节点进行整理:
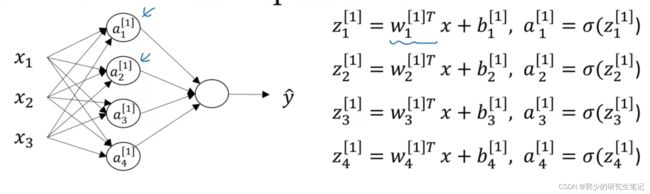
使用for循环计算z[i]j计算量很大,所以需要向量化:
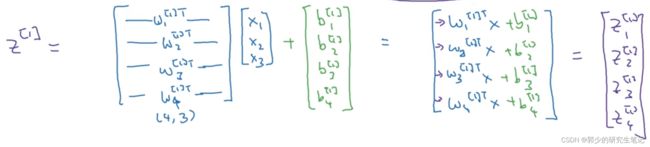
所以计算包含4个隐藏节点的神经网络,只需要下图中的4个式子:

大写的W[i]表示第i层的权重矩阵:
W[i] = [ w[i]1 w[i]2 w[i]3 w[i]4].T
4、多个样本的向量化
对于图中描述的神经网络,当存在多个训练样本时需要重复的计算4个式子:
对m个样本使用for循环重复的计算输出值,这表明没有进行向量化的实现。
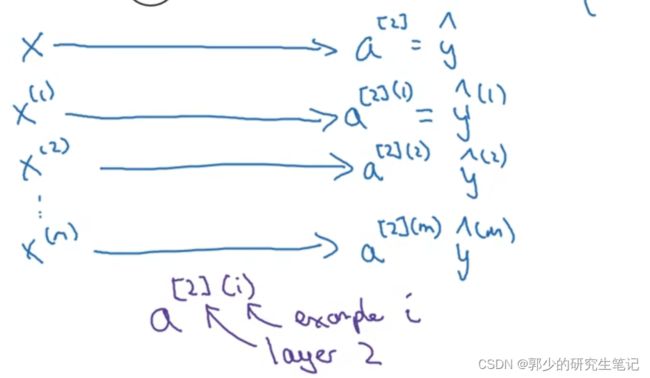
接下来进行向量化:
向量化目标是,使用矩阵一次性计算下述的4个式子。

将m个样本的输入进行向量化:

隐藏层输入和输出向量化:
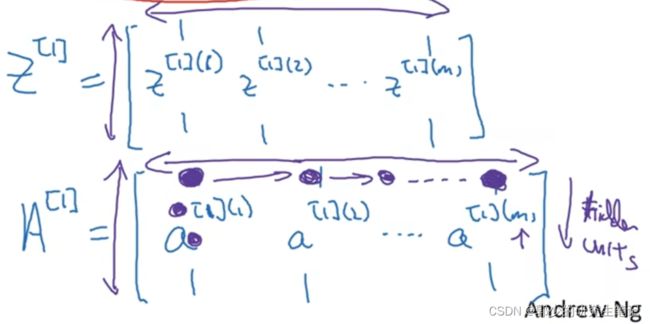
各矩阵的横坐标代表第几个训练样本,纵坐标代表隐藏层的第几个节点
5、向量化实现的解释
假设有3个样本,为了简化理解过程,将所有b设置为0。
对于第一层隐藏层,我们需要计算下述式子: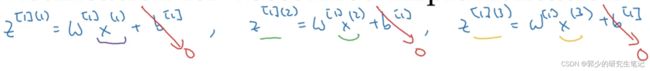
先进行分别对当个样本进行计算:
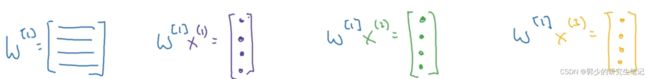
将样本输入向量化后进行计算:

最后得到的结果是不同样本的z叠起来,放在不同的列里
6、激活函数
要搭建一个神经网络,可以选择的是隐藏层使用的哪一个激活函数和输出单元使用什么激活函数。
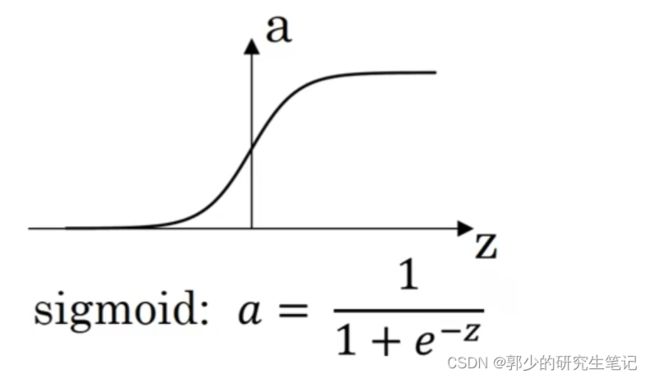
目前我们仅使用了sigmoid函数作为激活函数:
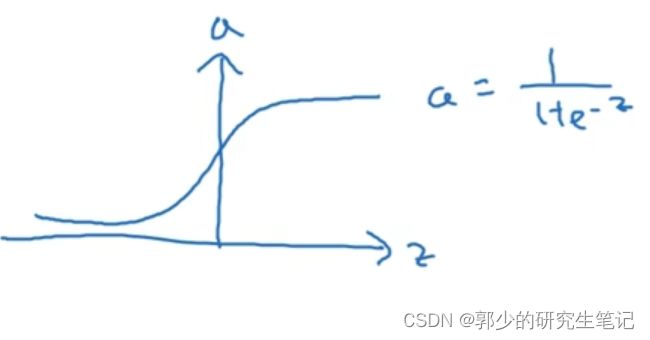
在一般情况下,我们可以使用不同的激活函数g(x),g(x)可以实非线性函数,不一定是sigmoid函数。
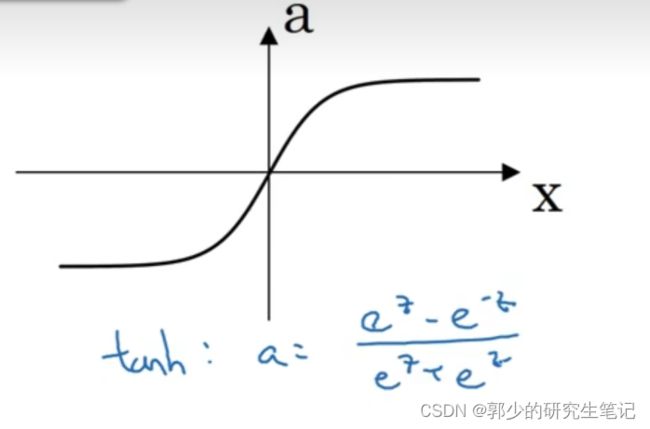
比如说sigmoid函数介于0~1之间,有个激活函数几乎总比sigmoid表现更好,就是tanh函数(双曲正切函数)。函数图像及表达式如下图:
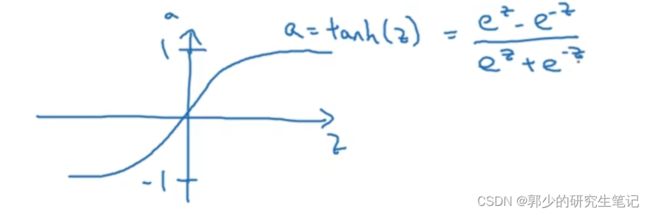
数学上tanh其实是sigmoid函数平移后的版本。tanh几乎效果会比sigmoid要好,因为函数输出介于-1到1之间,激活函数的平均值就更接近0。训练时可能需要平移所有数据,让数据平均值为0,使用tanh而不是sigmoid函数有类似数据中心化的效果。
现在很少使用sigmoid函数,除了在二元分类和输出层(希望输出的概率在0~1之间)中使用sigmoid函数
.
sigmoid和tanh的缺点:
当z特别大或者特别小时,函数的斜率可能就会很小,接近于0,这样会拖慢梯度下降算法
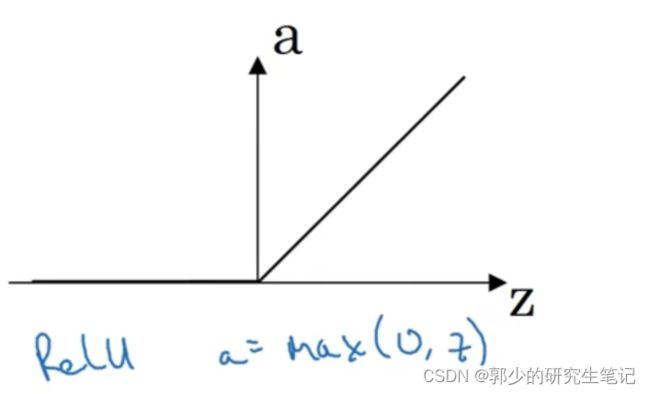
在机器学习中,最受欢迎的激活函数是修正线性单元(ReLU):
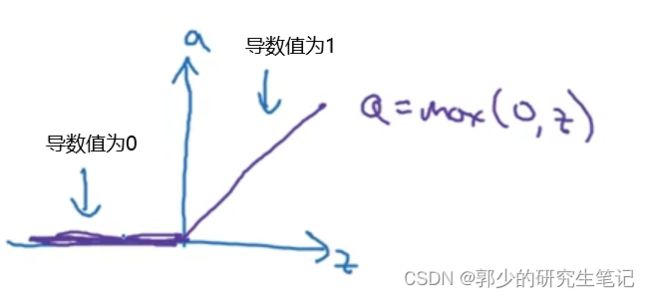
总结:
(1)sigmoid函数:
除非用在二元分类的输出层,不然绝对不要用
(2)tanh函数:
几乎所有场合都比sigmoid函数要优
(3)ReLU函数:
最常用的激活函数
(4)leaky ReLU:
不想让z为负数时函数斜率为0,所以当z<0,函数斜率较小
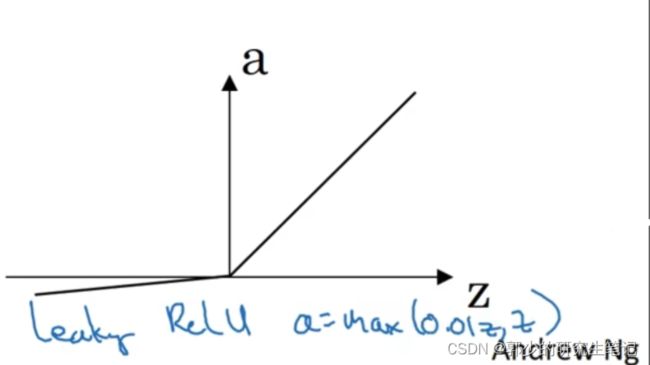
7、为什么需要非线性激活函数?
当不使用激活函数a(z) =z(也叫恒等激活函数)时,模型的输出y不过是输入特征x的线性组合。 如下图:
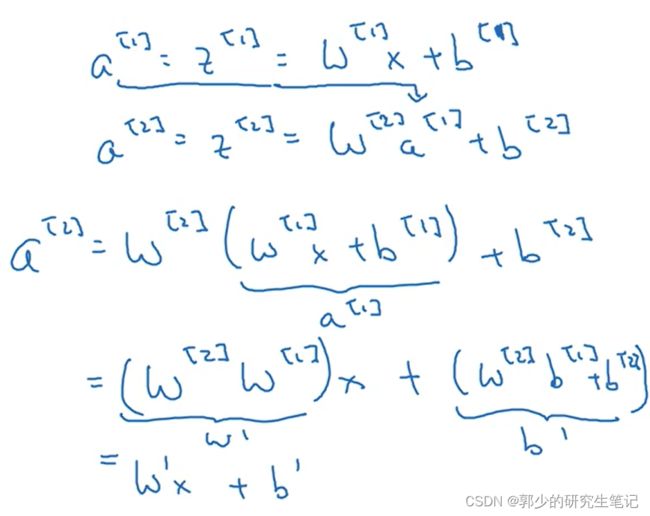
可以看到,不使用激活函数,神经网络只是把输入线性组合再输出
例如:
当隐藏层使用恒等激活函数,输出层使用sigmoid激活函数时,该神经网络的复杂度和没有任何隐藏层的标准逻辑回归是一样的。就算隐藏层再多,最后的输出也是输入的线性组合。
8、激活函数的导数
-
sigmoid函数的导数:
g’(z) = g(z)(1-g(z)) -
tanh函数的导数:
g’(z) = 1- ( g(z) )2 -
ReLU函数的导数:

当x=0时不可导,在神经网络的反向传播中令z=0时,导数等于0或者1 -
Leaky ReLU
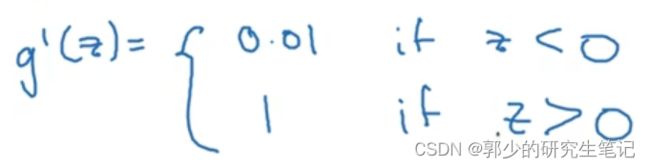
同理z=0时不可导,可以令z=0时,导数为0.01或者1
9、神经网络的梯度下降法

这里直接给出前向传播和后向传播具体实现:

10、直观理解反向传播
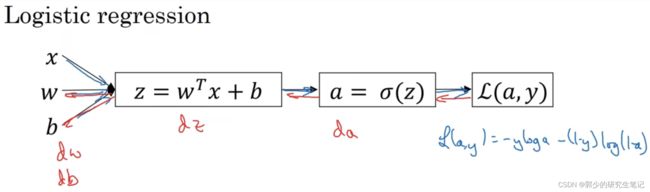
在逻辑回归中,需要损失函数L对w和b进行求导。而L是包含a的式子,a是包含z的式子,z是包含w和b的式子。
根据链式求导法则,应该先求L对a求导,再求a对z求导,再最z对w和b求偏导。即下图中从右到左的反向传播过程,先求da,后求dz,再求dw和db。
同理,对于单层神经网络,如下图:
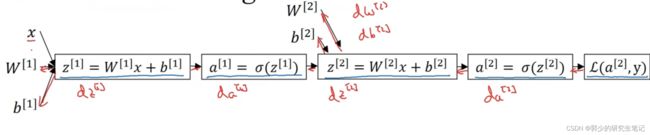
因此,需要先计算L对a[2]求导,再计算a[2]对z[2]求导,再算z[2]对W[2]和b[2]求导。
再计算z[2]对a[1]求导,再机端a[1]对z[1]求导,再计算算z[1]对W[1]和b[1]求导。
下图为反向求导结果:

11、随机初始化
如果将神经网络的各参数数组全部初始化为0,再使用梯度下降算法,那会完全无效。
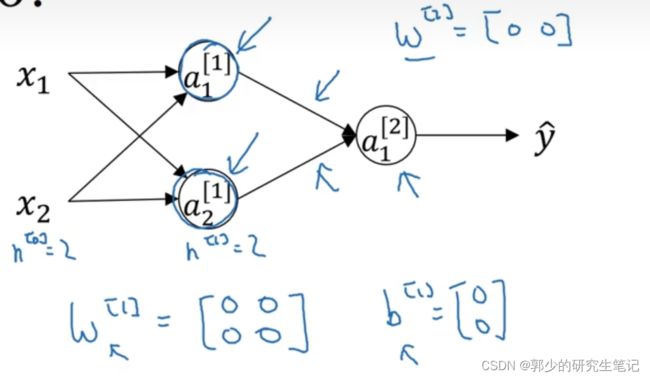
以上图的神经网络为例子,当w[1]和w[2]都设置为0时。第1层的两个神经其实是一样的,他们的输出完全一样,在反向传播时dz[1]1=dz[1]2,最好得到的W[1]每一行都是一样的数,即该层都是一样的函数。
因此应该将W[1]随机初始化为一个很小的数。b[1]因为不具有对称性,因此可以初始化为0;W[2]和b[2]同理。

随机初始化为一个很小的数是因为tanh和sigmoid函数在接近0的时候函数梯度较大;若初始化的过大或过小,函数斜率非常的小,随机梯度下降就会很慢。