Pytorch常见报错、踩坑点总结(持续更新)
在利用PyTorch进行深度学习的路上踩坑点实在是太多了,因此打算总结一些,以便日后查阅使用。
一、transforms.ToTensor()
在运行下面一段程序的时候,发现报错提醒:
D:\Anaconda3\envs\py36\lib\site-packages\torchvision\datasets\mnist.py:498: UserWarning: The given NumPy array is not writeable, and PyTorch does not support non-writeable tensors. This means you can write to the underlying (supposedly non-writeable) NumPy array using the tensor. You may want to copy the array to protect its data or make it writeable before converting it to a tensor. This type of warning will be suppressed for the rest of this program. (Triggered internally at …\torch\csrc\utils\tensor_numpy.cpp:180.)
return torch.from_numpy(parsed.astype(m[2], copy=False)).view(*s)
import torch
import torchvision
from torchvision import transforms
#读取数据集
#transforms.ToTensor()将尺寸为 (H x W x C)
# 且数据位于[0, 255]的PIL图片或者数据类型为np.uint8的NumPy数组转换为尺寸为(C x H x W)且数据类型为torch.float32且位于[0.0, 1.0]的Tensor
trans = transforms.ToTensor()
mnist_train = torchvision.datasets.FashionMNIST(root="../data", train=True,
transform=trans,
download=True)
mnist_test = torchvision.datasets.FashionMNIST(root="../data", train=False,
transform=trans, download=True)
print(type(mnist_train))
print(len(mnist_train), len(mnist_test))
翻译一下,大概意思就是:
给定的NumPy数组不可写,PyTorch不支持不可写张量。这意味着您可以使用张量写入底层(假定不可写)NumPy数组。在将数组转换为张量之前,可能需要复制数组以保护其数据或使其可写。
网上查找原因,在这个帖子中发现:
transform=torchvision.transforms.ToTensor()起到的作用是把PIL.Image或者numpy.narray数据类型转变为torch.FloatTensor类型,shape是CHW,数值范围缩小为[0.0, 1.0]。
在用数据读取的时候无需换成PIL的数据格式了,直接numpy格式就可以,无需转来转去,多此一举,transform可以直接处理numpy数据!
但是基于ToTensor()源码就是会将numpy转换为Tensor格式,下载的最新PyTorch也不是很了解,故暂且忽略这个用法警告,以后懂了回来填坑。同时也请有幸看到此贴的大佬指正(毕竟我还是个刚开始学习的小辣鸡)
二、torch.utils.data.DataLoader()的num_workers值的问题
若指定进程数为除0以外的其他数,如为4,运行下面一段代码:
import time
import torch
import torchvision
from torchvision import transforms
#读取数据集
#transforms.ToTensor()将尺寸为 (H x W x C)
# 且数据位于[0, 255]的PIL图片或者数据类型为np.uint8的NumPy数组转换为尺寸为(C x H x W)且数据类型为torch.float32且位于[0.0, 1.0]的Tensor
trans = transforms.ToTensor()
mnist_train = torchvision.datasets.FashionMNIST(root="../data", train=True,
transform=trans,
download=True)
mnist_test = torchvision.datasets.FashionMNIST(root="../data", train=False,
transform=trans, download=True)
#读取小批量
batch_size = 256
num_workers = 4 #指定进程数为4
train_iter = torch.utils.data.DataLoader(mnist_train, batch_size=batch_size, shuffle=True, num_workers=num_workers)
test_iter = torch.utils.data.DataLoader(mnist_test, batch_size=batch_size, shuffle=False, num_workers=num_workers) #打乱测试集
#查看读取一遍训练数据所花时间
start = time.time()
for X, y in train_iter:
continue
print('%.2f sec' % (time.time() - start))
报错一大堆:
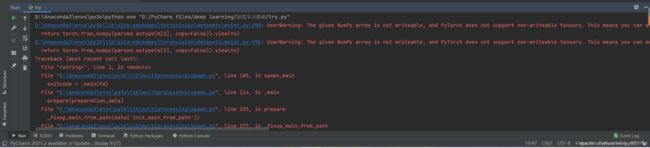
RuntimeError:
An attempt has been made to start a new process before the
current process has finished its bootstrapping phase.
This probably means that you are not using fork to start your
child processes and you have forgotten to use the proper idiom
in the main module:
if __name__ == '__main__':
freeze_support()
...
The "freeze_support()" line can be omitted if the program
is not going to be frozen to produce an executable.
RuntimeError: DataLoader worker (pid(s) 15464, 27252, 8356, 12452) exited unexpectedly
查找原因:在linux系统中可以使用多个子进程加载数据,而在windows系统中不能。所以在windows中要将DataLoader中的num_workers设置为0或者采用默认为0的设置。
参考链接1
参考链接2
抑或是,按照报错信息,将要运行的部分放进__main()__函数里面。
参考链接
修改程序如下:
import time
import torch
import torchvision
from torchvision import transforms
#读取数据集
#transforms.ToTensor()将尺寸为 (H x W x C)
# 且数据位于[0, 255]的PIL图片或者数据类型为np.uint8的NumPy数组转换为尺寸为(C x H x W)且数据类型为torch.float32且位于[0.0, 1.0]的Tensor
trans = transforms.ToTensor()
mnist_train = torchvision.datasets.FashionMNIST(root="../data", train=True,
transform=trans,
download=True)
mnist_test = torchvision.datasets.FashionMNIST(root="../data", train=False,
transform=trans, download=True)
def main():
# 读取小批量
batch_size = 256
num_workers = 4 # 指定进程数为4
train_iter = torch.utils.data.DataLoader(mnist_train, batch_size=batch_size, shuffle=True, num_workers=num_workers)
test_iter = torch.utils.data.DataLoader(mnist_test, batch_size=batch_size, shuffle=False,
num_workers=num_workers) # 打乱测试集
# 查看读取一遍训练数据所花时间
start = time.time()
for X, y in train_iter:
continue
print('%.2f sec' % (time.time() - start))
if __name__ == "__main__":
main()
再看输出结果:

发现仅报第一类错误了,成功输出时间。且比num_workers为0时所花的时间(4.73 sec)减少一半。
三、batch_size过大,报错
在学习到稠密连接网络(DenseNet)时,运行程序,发现报错如下:
Traceback (most recent call last):
File "D:/PyCharm files/deep learning/卷积神经网络/DenseNet.py", line 89, in <module>
d2l.train_ch5(net, train_iter, test_iter, batch_size, optimizer, device, num_epochs)
File "D:\Anaconda3\envs\pytorch\lib\d2lzh_pytorch\utils.py", line 238, in train_ch5
y_hat = net(X)
File "D:\Anaconda3\envs\pytorch\lib\site-packages\torch\nn\modules\module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "D:\Anaconda3\envs\pytorch\lib\site-packages\torch\nn\modules\container.py", line 117, in forward
input = module(input)
File "D:\Anaconda3\envs\pytorch\lib\site-packages\torch\nn\modules\module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "D:\Anaconda3\envs\pytorch\lib\site-packages\torch\nn\modules\container.py", line 117, in forward
input = module(input)
File "D:\Anaconda3\envs\pytorch\lib\site-packages\torch\nn\modules\module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "D:\Anaconda3\envs\pytorch\lib\site-packages\torch\nn\modules\linear.py", line 93, in forward
return F.linear(input, self.weight, self.bias)
File "D:\Anaconda3\envs\pytorch\lib\site-packages\torch\nn\functional.py", line 1690, in linear
ret = torch.addmm(bias, input, weight.t())
RuntimeError: CUDA error: CUBLAS_STATUS_NOT_INITIALIZED when calling `cublasCreate(handle)`
通过百度发现,是由于设置的batch_size设置过大导致的。
原来的为256,修改为128,点击运行,成功运行!
training on cuda
epoch 1, loss 0.4221, train acc 0.848, test acc 0.885, time 69.5 sec
epoch 2, loss 0.2658, train acc 0.902, test acc 0.909, time 67.6 sec
epoch 3, loss 0.2284, train acc 0.917, test acc 0.883, time 67.6 sec
epoch 4, loss 0.2072, train acc 0.924, test acc 0.921, time 67.7 sec
epoch 5, loss 0.1887, train acc 0.930, test acc 0.905, time 67.9 sec
参考链接