聚类算法-KMeans&DBSCAN
K-Means与DBSCAN都是常见的聚类算法。
K-means
1、从n个数据对象中任意选出k个对象作为初始的聚类中心;
2、计算剩余的各个对象到聚类中心的距离,将它划分给最近的簇;
3、重新计算每一簇的平均值(中心对象);
4、循环多次直到每个聚类不再发生变化为止。
K-Means需要确定参数要分成的簇数K。
DBSCAN
1、 核心点:这些点在基于密度的簇内部。点的邻域由距离函数和用户指定的距离参数Eps决定。核心点的定义是,如果该点的给定邻域的点的个数超过给定的阈值MinPts,其中MinPts也是一个用户指定的参数。
2、边界点:边界点不是核心点,但它落在某个核心点的邻域内。
3、噪声点:噪声点是既非核心点也非边界点的任何点。
1、任选一个未被访问的点开始,找出与其距离在eps之内(包括eps)的所有附近点;
2、如果附近点的数量 ≥ minPts,则当前点与其附近点形成一个簇,并且出发点被标记为已访问。然后递归,以相同的方法处理该簇内所有未被标记为已访问的点,从而对簇进行扩展。
3、如果附近点的数量 < minPts,则该点暂时被标记作为噪声点。
4、如果簇充分地被扩展,即簇内的所有点被标记为已访问,然后用同样的算法去处理未被访问的点。
DBSCAN需要二个参数:扫描半径 (eps)和最小包含点数(minPts)。
聚类评估算法-轮廓系数
轮廓系数(Silhouette Coefficient),是聚类效果好坏的一种评价方式。
方法如下:
1、计算样本i到同簇其他样本的平均距离ai。ai 越小,说明样本i越应该被聚类到该簇。将ai 称为样本i的簇内不相似度。 簇C中所有样本的a i 均值称为簇C的簇不相似度。
2、计算样本i到其他某簇Cj 的所有样本的平均距离bij,称为样本i与簇Cj 的不相似度。定义为样本i的簇间不相似度:bi =min{bi1, bi2, …, bik}。bi越大,说明样本i越不属于其他簇。
3、根据样本i的簇内不相似度a i 和簇间不相似度b i ,定义样本i的轮廓系数:
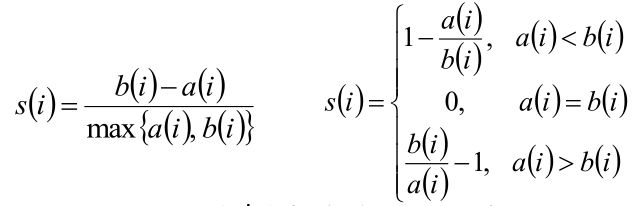
4、判断:
si接近1,则说明样本i聚类合理;
si接近-1,则说明样本i更应该分类到另外的簇;
si 接近为0,则说明样本i在两个簇的边界上。
案例
import pandas as pd
beer=pd.read_excel('路径/beer.xlsx')#一个关于beer的聚类。
X=beer[["calories","sodium","alcohol","cost"]] #取出四列数据
进行聚类
from sklearn.cluster import KMeans
km = KMeans(n_clusters=3).fit(X)#n_clusters=3意思是聚成三堆
km2 = KMeans(n_clusters=2).fit(X)#聚成2堆。为了比较一下聚成3堆和2堆的效果
km.labels_#会告诉你哪种数据属于哪种类别
array([1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 1, 2, 1, 1, 1, 0, 1, 1, 0, 2])
beer['cluster'] = km.labels_ #将每行分类加入啤酒这个表格
beer['cluster2'] = km2.labels_ #将每行分类加入啤酒这个表格
beer.sort_values('cluster') #按照分类排序
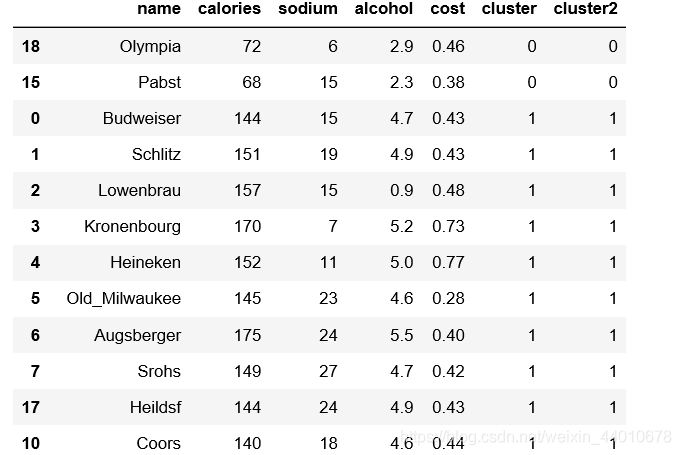
可以看一下每类之间的一些平均值的差异
beer.groupby("cluster").mean() #看一下分成三类的情况下每一类的均值
beer.groupby("cluster2").mean()#看一下分成两类的情况下每一类的均值
之后,进行可视化展示
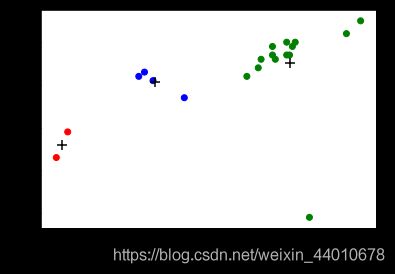
先来看在Alcohol和Calories两个维度上的关系
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams['font.size']=14
centers = beer.groupby("cluster").mean().reset_index()
colors=np.array(['red','green','blue','yellow'])
plt.scatter(beer["calories"], beer["alcohol"],c=colors[beer["cluster"]])
plt.scatter(centers.calories,centers.alcohol,linewidths=3,marker='+',s=100,c='black')
plt.xlabel("Calories")
plt.ylabel("Alcohol")
plt.show()
一幅图是不能满足我们所有的需求的,我们选择将其余的关系图加入
from pandas.tools.plotting import scatter_matrix
scatter_matrix(beer[["calories","sodium","alcohol","cost"]],s=200, alpha=1, c=colors[beer["cluster"]], figsize=(10,10))
plt.suptitle("With 3 centrois initialized")
plt.show()
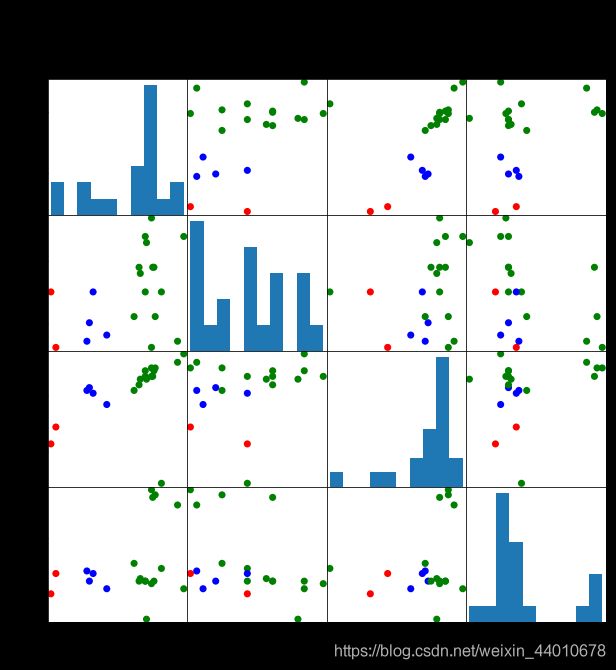
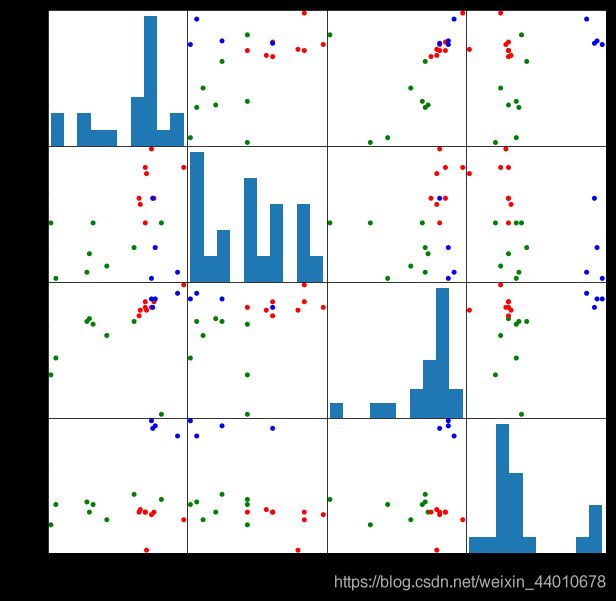
可以从图中看出来,大多数的还是被分开了,但是有些效果不是特别好。
在用轮廓系数评价之前我们先来对数据进行归一化处理,然后再比较数据进行归一化和不进行归一化的轮廓系数:
上面是没有进行归一化处理的数据,机器会自动认为数据越大就越重要,接下来进行归一化处理
from sklearn.preprocessing import StandardScaler
scaled=StandardScaler()
X_scaled=scaled.fit_transform(X)
km=KMeans(n_clusters=3).fit(X_scaled)
beer["scaled_cluster"]=km.labels_
beer.sort_values('scaled_cluster')
pd.scatter_matrix(X,c=colors[beer.scaled_cluster],alpha=1,figsize=(10,10),s=100)
plt.show()
接下来比较两者的轮廓系数
from sklearn import metrics
score_scaled = metrics.silhouette_score(X,beer.scaled_cluster) # 标准化后数据
score = metrics.silhouette_score(X,beer.cluster) #不做标准化的数据
print(score_scaled,score)
0.179780680894 0.673177504646
是不是有些震惊,做归一化的数据竟然结果更差一些。
通常情况下,归一化之后的效果比较好。但是有时也不一定(比如这个数据)因为有些特征潜在就是比较重要的。
我们可以做一次KMean调参过程的轮廓系数遍历(常用)
scores=[]
for k in range(2,20):
labels=KMeans(n_clusters=k).fit(X).labels_
print(labels)
score=metrics.silhouette_score(X,labels)
scores.append(score)
print(scores)
#print(max(scores))
[0.69176560340794857, 0.67317750464557957, 0.58570407211277953, 0.42254873351720201, 0.4559182167013377, 0.43776116697963124, 0.38946337473125997, 0.39746405172426014, 0.3915697409245163, 0.34131096180393328, 0.29095767011004892, 0.31221439248428434, 0.30707782144770296, 0.31834561839139497, 0.28495140011748982, 0.23498077333071996, 0.15880910174962809, 0.084230513801511767]
可以看出K=2时效果是最好的
接下来用DBSCAN来做一下
from sklearn.cluster import DBSCAN
db=DBSCAN(eps=10,min_samples=2).fit(X)#eps为半径,min_samples为最小密度
labels=db.labels_
beer['cluster_db']=labels
beer.sort_values('cluster_db')
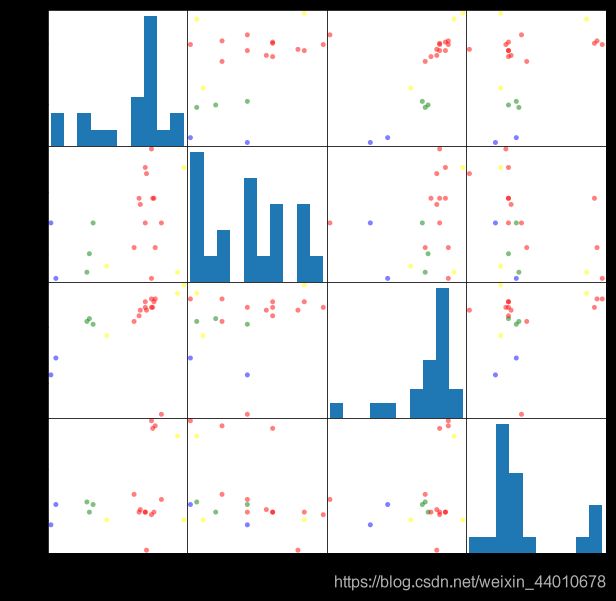
pd.scatter_matrix(X,c=colors[beer.cluster_db],figsize=(10,10),s=100)
plt.show()
计算轮廓系数
score = metrics.silhouette_score(X,beer.cluster_db)
print(score)
0.495309552968
依然可以做一个遍历(常用):
scores1=[]
for i in range(5,20):
for j in range(0,3):
db=DBSCAN(eps=i,min_samples=j).fit(X).labels_#注意这里min_samples=j只能取0,1,2,3,因为最多分为4类
score1=metrics.silhouette_score(X,db)
scores1.append(score1)
print(scores1)
#print(max(scores1))
[0.28495140011748982, 0.28495140011748982, -0.067816095663587483, 0.34597752371272478, 0.34597752371272478, 0.16260848891286961, 0.27956882753455314, 0.27956882753455314, 0.12626205982196476, 0.26115847430369743, 0.26115847430369743, 0.16564759416041527, 0.38787917075277784, 0.38787917075277784, 0.42951251219183106, 0.45472811033880489, 0.45472811033880489, 0.49530955296776086, 0.45472811033880489, 0.45472811033880489, 0.49530955296776086, 0.45472811033880489, 0.45472811033880489, 0.49530955296776086, 0.45472811033880489, 0.45472811033880489, 0.49530955296776086, 0.52388285107209265, 0.52388285107209265, 0.58570407211277953, 0.52388285107209265, 0.52388285107209265, 0.58570407211277953, 0.52387817106138013, 0.52387817106138013, 0.52387817106138013, 0.52387817106138013, 0.52387817106138013, 0.52387817106138013, 0.67317750464557957, 0.67317750464557957, 0.67317750464557957, 0.67317750464557957, 0.67317750464557957, 0.67317750464557957]
可以看出有时DBSCAN不如KMeans效果好,但是大多数时候效果还是要好的。
总结
1、K-means使用簇的基于原型的概念,而DBSCAN使用基于密度的概念。
2、K-means只能用于具有明确定义的质心(如均值)的数据。DBSCAN要求密度定义(基于传统的欧几里得密度概念)对于数据是有意义的。
3、K-means需要指定簇的个数作为参数,DBSCAN不需要事先知道要形成的簇类的数量,DBSCAN自动确定簇个数。
4、与K-means方法相比,DBSCAN可以发现任意形状的簇类。DBSCAN可以处理不同大小和不同形状的簇,K-means很难处理非球形的簇和不同形状的簇。
5、K-means可以用于稀疏的高纬数据,如文档数据。DBSCAN则不能很好反映高维数据。
6、K-means可以发现不是明显分离的簇,即便簇有重叠也可以发现,但是DBSCAN会合并有重叠的簇。
总之,DBSCAN在机器学习中大多数时候要强于K-Means。