bp神经网络实现人脸识别,bp神经网络模式识别
求基于BP神经网络实现汽车牌照识别的matlab代码或者是汽车牌照识别系统(用matlab写的,有用到BP神经网络
matlab中BP神经网络OCR识别?
单看错误率分析不出来什么,可能是样本量太少,也可能是别的原因AI爱发猫 www.aifamao.com。可以把错误识别的样本拿出来,看看是哪些地方导致的错误,再有针对性的改进。
还可能是特征工程不到位,特征选取的不好,不满足尺度不变性、旋转不变性、仿射不变性三个要素,说白了就是,大小变了,旋转的角度变了,拍照的时候站的位置不同导致对车牌的透视发生变化了,然后可能就识别不出来了。
所以可以考虑找一个更好的描述特征的方法,比如HoG(方向梯度直方图)。
HoG,简单说就是,相邻的两个像素值做个减法,就可以表示颜色的变化,那么一个像素周围,上下、左右各有两个像素,就可以分别做两个减法,得到两个值,就像力学里两个力可以合并一样,这两个值也可以合并,得到方向,和大小(就是梯度),这样就有了一个像素的特征。
但是特征太多计算量太大,就用统计的方法减少下特征,首先把图片划分成网格的形式,就像是在图像上画围棋线一样,然后每个方格内单独统计一下,方向在0-20角度内的像素的梯度的和是多少,依次类推,就得到了直方图,如果以20度为一个直方的话,那么180度就可以划分成9个直方,也就是9个特征,这样一个方格内的特征数量就与像素的数量无关了,而是固定了的。
然后就是关于HoG的其他手段了,比如为了消除光照变化,可以对特征向量做归一化等。
另外还可以对HoG可视化,在每个方格内,用线的方向和长度代替特征的方向和梯度,最后呈现的效果是,有若干个方格,每个方格内都好像有一个沿原点对称的星星,这样做对分析算法效果有一定帮助。
HoG是比较常见的特征描述子了,在行人检测上用的比较多。除了HoG,还有SIFT、SURF等特征描述子,这些都是计算机视觉中的内容了,属于特征检测的范畴。
计算机视觉主要包括二值化、滤波器、特征检测、特征匹配等一些基础的手段,然后就是图像滤镜、图像分割、图像识别、图像生成等具体的应用算法。
由于近年来计算成本降低导致神经网络的再度崛起,计算机视觉的研究热点已经转为深度神经网络的各种改进和性能优化上了,像HoG已经是05年的事情了。
关于车牌识别(LPR),如果环境不复杂,是可以做到接近100%的准确率的,如果环境较为复杂,95%以上准确率应该是可以做到的。总的来说,基本已经实现应用落地和商用了。
现在的方法基本都是深度学习,端到端一气呵成,无需专门提取特征,传统的模式识别方法已经GG。说的比较细。
如果只是关心结果的话,Github上可以找到关于车牌识别的一些开源项目,比如openalpr之类的,当然也是采用深度学习的办法,炼丹嘛,就是这么直接。
如何在 MATLAB 中实现车牌号图片的识别
您好,请问您有基于BP神经网络算法的车牌识别的程序代码吗?用matlab可以运行的那种。
急求用BP神经网络实现车牌识别的MATLAB程序代码
车牌识别技术(VehicleLicensePlateRecognition,VLPR)是计算机视频图像识别技术在车辆牌照识别中的一种应用。
车牌识别技术要求能够将运动中的汽车牌照从复杂背景中提取并识别出来,通过车牌提取、图像预处理、特征提取、车牌字符识别等技术,识别车辆牌号,目前的技术水平为字母和数字的识别率可达到96%,汉字的识别率可达到95%。
附件为基于matlab的车牌识别的源程序(可以实现),其中包括车牌定位,车牌矫正,字符分割,字符识别4部分。还有已训练好的BP神经网络用于字符识别。
车牌识别系统的识别原理
车辆检测可以采用埋地线圈检测、红外检测、雷达检测技术、视频检测等多种方式。采用视频检测可以避免破坏路面、不必附加外部检测设备、不需矫正触发位置、节省开支,而且更适合移动式、便携式应用的要求。
系统进行视频车辆检测,需要具备很高的处理速度并采用优秀的算法,在基本不丢帧的情况下实现图像采集、处理。
若处理速度慢,则导致丢帧,使系统无法检测到行驶速度较快的车辆,同时也难以保证在有利于识别的位置开始识别处理,影响系统识别率。因此,将视频车辆检测与牌照自动识别相结合具备一定的技术难度。
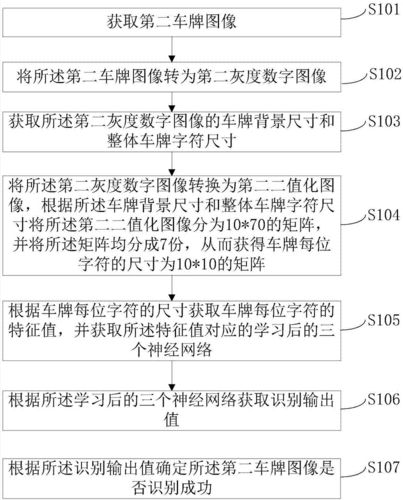
为了进行车牌识别,需要以下几个基本的步骤:1)牌照定位,定位图片中的牌照位置;2)牌照字符分割,把牌照中的字符分割出来;3)牌照字符识别,把分割好的字符进行识别,最终组成牌照号码。
车牌识别过程中,牌照颜色的识别依据算法不同,可能在上述不同步骤实现,通常与车牌识别互相配合、互相验证。
1)牌照定位自然环境下,汽车图像背景复杂、光照不均匀,如何在自然背景中准确地确定牌照区域是整个识别过程的关键。
首先对采集到的视频图像进行大范围相关搜索,找到符合汽车牌照特征的若干区域作为候选区,然后对这些侯选区域做进一步分析、评判,最后选定一个最佳的区域作为牌照区域,并将其从图像中分离出来。
2)牌照字符分割完成牌照区域的定位后,再将牌照区域分割成单个字符,然后进行识别。字符分割一般采用垂直投影法。
由于字符在垂直方向上的投影必然在字符间或字符内的间隙处取得局部最小值的附近,并且这个位置应满足牌照的字符书写格式、字符、尺寸限制和一些其他条件。
利用垂直投影法对复杂环境下的汽车图像中的字符分割有较好的效果。3)牌照字符识别方法主要有基于模板匹配算法和基于人工神经网络算法。
基于模板匹配算法首先将分割后的字符二值化并将其尺寸大小缩放为字符数据库中模板的大小,然后与所有的模板进行匹配,选择最佳匹配作为结果。
基于人工神经网络的算法有两种:一种是先对字符进行特征提取,然后用所获得特征来训练神经网络分配器;另一种方法是直接把图像输入网络,由网络自动实现特征提取直至识别出结果。
实际应用中,车牌识别系统的识别率还与牌照质量和拍摄质量密切相关。
牌照质量会受到各种因素的影响,如生锈、污损、油漆剥落、字体褪色、牌照被遮挡、牌照倾斜、高亮反光、多牌照、假牌照等等;实际拍摄过程也会受到环境亮度、拍摄方式、车辆速度等等因素的影响。
这些影响因素不同程度上降低了车牌识别的识别率,也正是车牌识别系统的困难和挑战所在。为了提高识别率,除了不断地完善识别算法还应该想办法克服各种光照条件,使采集到的图像最利于识别。
基于matlab的车牌识别系统