实现MySQL同步数据到ES构建宽表
作者介绍
Ceven,德勤乐融(北京)科技有限公司 邮箱:[email protected]
前言
CloudCanal 近期提供了自定义代码构建宽表能力,我们第一时间参与了该特性内测,效果不错。开发流程详见官方文档 《CloudCanal自定义代码实时加工》
能力特点包括:
- 灵活,支持反查打宽表,特定逻辑数据清洗,对账,告警等场景
- 调试方便,通过任务参数配置自动打开 debug 端口,对接 IDE 调试
- SDK 接口清晰,提供丰富的上下文信息,方便数据逻辑开发
本文基于我们业务中的实际需求(MySQL -> ElasticSearch 宽表构建),梳理一下具体的开发调试流程,希望对大家有所帮助。
场景描述
MySQL 擅长关系型数据操作,我们在其中存储了 product, tag, product_tag_mapping 表数据,用以表示产品和标签之间多对多关系。精简的数据结构如下:
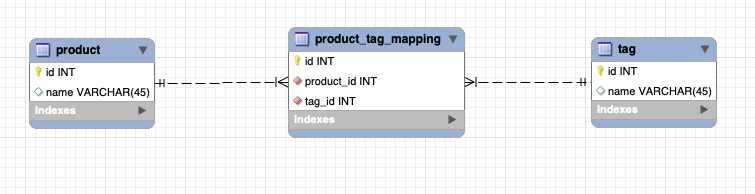
ElasticSearch 擅长搜索,但是并不支持不同索引间的联合查询, 所以构造宽表是业界刚需。我们存储其上的产品索引结构如下:
PUT es_product
{
"mappings" : {
"properties" : {
"id" : {
"type" : "integer"
},
"name" : {
"type" : "text"
},
"tags" : {
"type" : "nested",
"properties" : {
"id" : {
"type" : "integer"
},
"name" : {
"type" : "text"
}
}
}
}
}
}同步策略
CloudCanal 在 同步 MySQL -> ElasticSearch 数据过程中,会兼顾全量和增量两种情况,我们可以创建两个独立的任务,分别同步产品的基础信息和附加信息(即标签信息)。
- 基础信息任务
- 使用基本的映射关系,将 MySQL 中的 product 数据表,映射到 es_product 索引中,即可保证全量和增量的数据同步。
- 附加信息任务
- 创建 CloudCanal 任务将 MySQL 中的 product_tag_mapping 数据表映射到 es_product 索引中,同步过程中反查源数据库中的 tag 信息,构造宽表数据,填充进 es_product 索引,实现附加信息全量和增量的数据同步。
实现步骤
1. MySQL 表结构初始化
# 创建产品信息表
CREATE TABLE `product` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(64) COLLATE utf8_unicode_ci NOT NULL DEFAULT '' COMMENT '名称',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci COMMENT='产品信息记录表';
# 创建标签信息表
CREATE TABLE `tag` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(64) COLLATE utf8_unicode_ci NOT NULL DEFAULT '' COMMENT '名称',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci COMMENT='标签信息记录表';
# 创建产品标签关系表
CREATE TABLE `product_tag_mapping` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`product_id` bigint(20) unsigned NOT NULL DEFAULT '0' COMMENT '产品ID',
`tag_id` bigint(20) unsigned NOT NULL DEFAULT '0' COMMENT '标签ID',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci COMMENT='产品标签关系表';2. MySQL 填充测试数据
# 填充产品信息
INSERT INTO `product` (`name`)
VALUES
('product_1');
# 填充标签信息
INSERT INTO `tag` (`name`)
VALUES
('tag_1'),
('tag_2');
# 填充产品标签关系信息
INSERT INTO `product_tag_mapping` (`product_id`, `tag_id`)
VALUES
(1, 1);3. ElasticSearch 索引创建(也可以使用 CloudCanal 结构迁移)
PUT es_product
{
"mappings" : {
"properties" : {
"id" : {
"type" : "integer"
},
"name" : {
"type" : "text"
},
"tags" : {
"type" : "nested",
"properties" : {
"id" : {
"type" : "integer"
},
"name" : {
"type" : "text"
}
}
}
}
}
}4. 编写自定义代码
自定义代码的项目基于 maven 构建,可以参考 示例项目 cloudcanal-sdk-demos
4.1 修改 MAVEN 配置
初始化的项目需要手工配置一下 pom.xml 文件,将 sdk 指向本地目录文件,代码片段如下
com.clougence.cloudcanal
cloudcanal-sdk
1.0.0-SNAPSHOT
system
/path/to/your/project/src/main/resources/lib/cloudcanal-sdk-2.0.0.9-SNAPSHOT.jar
4.2 实现 TAG 类
public class Tag {
private int id;
private String name;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}4.3 实现 PROCESSOR 处理逻辑
@Override
public List process(List list, CustomProcessorContext context) {
DataSource dataSource = (DataSource) context.getProcessorContextMap().get(RdbContextKey.SOURCE_DATASOURCE);
String stage = context.getProcessorContextMap().get("currentTaskStage").toString();
for (CustomRecord record : list) {
try (Connection connection = dataSource.getConnection(); Statement statement = connection.createStatement()) {
// 由于 ES 的嵌套结构会被认为是独立的文档,故需要填充旧的数据
ResultSet rs = statement.executeQuery("SELECT `tag`.`id`, `tag`.`name`" +
" FROM `product`.`product_tag_mapping` AS `mapping`" +
" LEFT JOIN `product`.`tag` AS `tag` ON `tag`.`id` = `mapping`.`tag_id`" +
" WHERE `mapping`.`product_id` = " + record.getFieldMapAfter().get("product_id").getValue()
);
List tags = buildTags(rs);
if ("INCREMENT".equals(stage)) {
// 增量创建的 product_tag_mapping 处于内存中,无法通过 SQL 语句查询得到,故需要单独处理
rs = statement.executeQuery("SELECT `id`, `name` FROM `product`.`tag` WHERE `id` = " + record.getFieldMapAfter().get("tag_id").getValue().toString());
List newTags = buildTags(rs);
tags.add(newTags.get(0));
}
ObjectMapper mapper = new ObjectMapper();
String json = mapper.writeValueAsString(tags);
Map tagField = new LinkedHashMap<>();
tagField.put("tags", json);
RecordBuilder.modifyRecordBuilder(record)
.addField(tagField)
.build();
} catch (SQLException | JsonProcessingException e) {
e.printStackTrace();
}
}
return list;
}
private List buildTags(ResultSet rs) throws SQLException {
List tags = new ArrayList<>();
while (rs.next()) {
Tag tag = new Tag();
tag.setId(rs.getInt("id"));
tag.setName(rs.getString("name"));
tags.add(tag);
}
return tags;
} 4.4 编译自定义代码包
执行如下命令编译生成自定义代码包, 之后会在 target 目录中生成 jar 文件
mvn clean package -Dmaven.test.skip=true -Dmaven.compile.fork=true5. 创建 CloudCanal 任务
5.1 同步 PRODUCT 基础数据
全量增量同步 product 信息到 es_product 索引,在此就不做具体描述,详情请参考 CloudCanal 文档。
此时查询产品数据,得到结果

5.2 扩展 PRODUCT TAG 数据
5.2.1 配置数据源和目标

5.2.2 配置规格
可去掉自动启动任务选项,以便于单步追踪调试 
5.2.3 配置索引映射
Tips: 只配置增加操作,不要配置编辑和删除,否则可能造成对数据的误删;
编辑和删除操作,只最好使用 ES 调用的方式进行处理;
增加操作最好不要使用 ES 调用的方式处理,会引起高并发问题。5.2.4 上传自定义代码

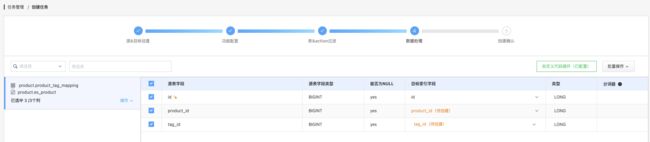
Tips: 创建任务时如果不上传自定义代码包,之后将无法上传,除非重建任务。
上传自定义代码,意味着创建特殊类型的任务,然后才会出现特殊的选项进行字段映射。5.2.5 配置字段映射
将 id 和 tag_id 调整为 “只订阅不同步”(老版本此处会显示为仅供自定义代码使用),实现只订阅这两个字段,而不会真正写入到 ES 索引,而将 product_id 映射到对端的 id。 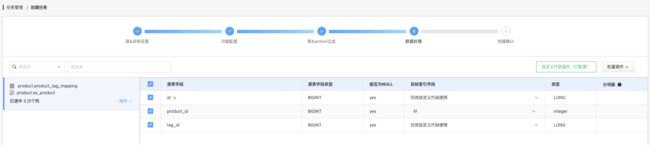
设置映射 _id,以指定目标 ES 索引中的 id 为 product_id
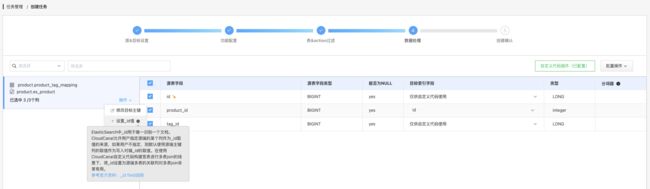

Tips: product_id 字段必须做映射,否则即使配置了 _id 信息,依旧无法正常执行,会忽略 product_id 字段的值。6. 同步结果

调试自定义代码
自定义代码在开发阶段最麻烦的事情是如何高效进行调试,CloudCanal 能够比较友好的让开发在本地直接调试代码逻辑。
修改任务参数
任务详情->参数修改


Tips:每次修改完参数信息之后,必须点击生效配置和重启任务;
在任务详情配置中,也可以上传新的代码包,激活和重启任务后可以使用。配置 IntelliJ IDEA Debug 模式

Tips: 设置好断点以后,需要先启动 CloudCanal 任务,再点击 debug 按钮,才能 Attach 到远程的 8787 端口;
CloudCanal 会一直 pending,直到有 Attachment,才会继续执行,所以不需要单步跟踪调试时,一定记得关闭调试模式,否则任务无法执行。总结
CloudCanal 自定义代码能够拓展的能力具有不错的想象空间,我们甚至能加入一些在线业务逻辑的处理,让业务需求能够更好的满足,同时配合社区版调试也很方便。希望未来这块能力在便利功能,性能等层面有更好的表现。
参与内测
CloudCanal 会不断提供一些预览的能力,包括新数据链路, 优化能力,功能插件。本文所描述的自定义代码能力目前也处于内测阶段。如需体验,可添加我们小助手(微信号:suhuayue001)进行了解和试用。
加入CloudCanal粉丝群掌握一手消息和获取更多福利,请添加我们小助手微信:suhuayue001
CloudCanal-免费好用的企业级数据同步工具,欢迎品鉴。 了解更多产品可以查看官方网站: http://www.clougence.com CloudCanal社区:https://www.askcug.com/