Logstash从mysql同步数据到es
Logstash同步数据到es
简介
Logstash 是免费且开放的服务器端数据处理管道,能够从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的“存储库”中。
Logstash 是一个功能强大的工具,可与各种部署集成。 它提供了大量插件,可帮助你解析,丰富,转换和缓冲来自各种来源的数据。 如果你的数据需要 Beats 中没有的其他处理,则需要将 Logstash 添加到部署中。
应用场景
- 日志搜索器: logstash采集、处理、转发到elasticsearch存储,在kibana进行展示
- Elk日志分析(elasticsearch+logstash+kibana)
- logstash同步mysql数据库数据到es
logstash安装部署
1 . 拉取logstash镜像 (需要与es版本对应)
docker pull logstash:7.12.1
2 . 构建logstash容器
#创建一个用于存储logstash配置以及插件的目录
mkdir /docker/logstash
#构建容器
docker run -p 9900:9900 -d --name logstash \
-v /docker/logstash:/etc/logstash/pipeline \
--privileged=true logstash:7.12.1
3 . 进入logstash容器内部安装 jdbc 和 elasticsearch 插件
#进入logstash容器内部
docker exec -it logstash bash
#使用logstash-plugin安装器安装logstash-input-jdbc插件,改安装器在bin目录下
#此插件镜像新版本已自带
logstash-plugin install logstash-input-jdbc
#安装数据输出到es的插件
logstash-plugin install logstash-output-elasticsearch

4 . 下载jdbc的mysql-connection.jar包
创建并进入文件夹:mkdir -p /docker/logstash/package
https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.24/mysql-connector-java-8.0.24.jar
5 . 修改容器内部配置
#更改logstash.yml文件
vi config/logstash.yml
#内容如下:
http.host: "0.0.0.0"
xpack.monitoring.elasticsearch.hosts: [ "http://172.17.0.7:9200" ]
#更改pipelines.yml文件
vi config/pipelines.yml
#内容如下:
- pipeline.id: table1
path.config: "/etc/logstash/pipeline/conf/logstash.conf"
注:需要注意的是这个目录,是不是存在这些文件,不要找错地方了,一般进入容器就会是logstash的安装目录,ls查看就能够看到config目录的
创建es的文档:
PUT /products/
{
"mappings": {
"properties": {
"name":{
"type": "text",
"analyzer": "ik_smart"
},
"long_name":{
"type": "text",
"analyzer": "ik_smart"
},
"brand_id":{
"type": "integer"
},
"category_id":{
"type":"integer"
},
"category":{
"type": "keyword"
},
"category_path":{
"type": "keyword"
},
"shop_id":{
"type":"integer"
},
"price":{
"type":"scaled_float",
"scaling_factor":100
},
"sold_count":{
"type":"integer"
},
"review_count":{
"type":"integer"
},
"status":{
"type":"integer"
},
"create_time" : {
"type" : "date"
},
"last_time" : {
"type" : "date"
}
}
}
}
6 . 退出容器,配置文件创建与编辑 (此处属于全量的配置文件)
创建mysql文件:(注:这里是容器里面的真实文件路径,本地创建需要小心)
vim /etc/logstash/pipeline/sql/products.sql
SELECT
a.`name`,
a.long_name,
a.brand_id,
a.three_category_id AS category_id,
a.shop_id,
a.price,
a.STATUS,
a.sold_count,
a.review_count,
a.create_time,
a.last_time,
b.`name` AS category,
b.path
FROM
lmrs_products AS a
LEFT JOIN lmrs_product_categorys AS b ON a.three_category_id = b.id
创建缓存存储脚本文件夹
mkdir /docker/logstash/cache
注意:需要给 : /docker/logstash 赋予权限
chmod -R 777 /docker/logstash
基本案例:
注:复制全部数据
创建脚本(注意:这个文件需要跟 pipelines.yml 定义的文件路径一致)
touch /docker/logstash/conf/logstash.conf
input {
stdin { }
jdbc {
#注意mysql连接地址一定要用ip,不能使用localhost等
jdbc_connection_string => "jdbc:mysql://172.17.0.4:3306/lmrs"
jdbc_user => "root"
jdbc_password => "root"
#数据库重连尝试
connection_retry_attempts => "3"
#数据库连接可用校验超时时间,默认为3600s
jdbc_validation_timeout => "3600"
#这个jar包的地址是容器内的地址
jdbc_driver_library => "/etc/logstash/pipeline/package/mysql-connector-java-8.0.24.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
#开启分页查询(默认是false)
jdbc_paging_enabled => "true"
#单次分页查询条数(默认100000,字段较多的话,可以适当调整这个数值)
jdbc_page_size => "50000"
#执行的sql语句
statement_filepath => "/etc/logstash/pipeline/sql/products.sql"
#需要记录查询结果某字段的值时,此字段为true,否则默认tracking_colum为timestamp的值
use_column_value => true
#是否将字段名转为小写,默认为true(如果具备序列化或者反序列化,建议设置为false)
lowercase_column_names => false
#需要记录的字段,同于增量同步,需要是数据库字段
tracking_column => id
#记录字段的数据类型
tracking_column_type => numeric
#上次数据存放位置
record_last_run => true
#上一个sql_last_value的存放路径,必须在文件中指定字段的初始值
last_run_metadata_path => "/etc/logstash/pipeline/cache/products.txt"
#是否清除last_run_metadata_path的记录,需要增量同步这个字段的值必须为false
clean_run => false
#同步的频率(分 时 天 月 年)默认为每分钟同步一次
schedule => "* * * * *"
}
}
output {
elasticsearch {
# 要导入到的Elasticsearch所在的主机
hosts => "172.17.0.7:9200"
# 要导入到的Elasticsearch的索引的名称
index => "products"
# 类型名称(类似数据库表名)
document_type => "_doc"
# 主键名称(类似数据库主键)
document_id => "%{id}"
}
stdout {
# JSON格式输出
codec => json_lines
}
}
注意:
last_run_metadata_path => “/etc/logstash/pipeline/cache/products.txt” : 因为需要记录下上次同步的数据id,所以这里会有一个文件进行存储这个id,需要在logstash目录下去创建一个txt文件,用于存储这个id,同时需要给予权限。不给会出现权限异常问题.
启动
docker start logstash
7 . 完整案例:
注:
1 . 同时同步多张表的数据
2 . 根据修改时间进行增量同步
创建es文档:
PUT /products/
{
"mappings": {
"properties": {
"name":{
"type": "text",
"analyzer": "ik_smart"
},
"long_name":{
"type": "text",
"analyzer": "ik_smart"
},
"brand_id":{
"type": "integer"
},
"category_id":{
"type":"integer"
},
"category":{
"type": "keyword"
},
"category_path":{
"type": "keyword"
},
"shop_id":{
"type":"integer"
},
"price":{
"type":"scaled_float",
"scaling_factor":100
},
"sold_count":{
"type":"integer"
},
"review_count":{
"type":"integer"
},
"status":{
"type":"integer"
},
"create_time" : {
"type" : "date"
},
"last_time" : {
"type" : "date"
},
"skus":{
"type": "nested",
"properties": {
"name":{
"type":"text",
"analyzer": "ik_smart"
},
"price":{
"type":"scaled_float",
"scaling_factor":100
}
}
},
"attributes":{
"type": "nested",
"properties": {
"name": { "type": "keyword" },
"value": { "type": "keyword"}
}
}
}
}
}
创建同步的sql脚本
商品脚本
vim /etc/logstash/pipeline/sql/products.sql
SELECT
a.id,
a.`name`,
a.long_name,
a.brand_id,
a.three_category_id AS category_id,
a.shop_id,
a.price,
a.sold_count,
a.review_count,
a.`status`,
a.create_time,
a.last_time,
b.`name` AS category,
b.path
FROM
lmrs_products AS a
LEFT JOIN lmrs_product_categorys AS b ON a.three_category_id = b.id
WHERE
a.last_time > :sql_last_value
商品规格属性脚本
vim /etc/logstash/pipeline/sql/attributes.sql
SELECT
c.*,
d.`name` AS category,
d.path AS category_path
FROM
(
SELECT
b.id,
b.`name` AS `value`,
b.`last_time`,
b.sort AS attribute_value_sort,
a.`name`,
a.sort AS attribute_sort,
a.category_id
FROM
lmrs_attributes AS a
LEFT JOIN lmrs_attribute_values AS b ON a.id = b.attribute_id
) AS c
LEFT JOIN lmrs_product_categorys AS d ON c.category_id = d.id
WHERE
c.last_time > :sql_last_value
创建匹配过滤器
属性与规格脚本
vim /etc/logstash/pipeline/sql/filter_attr_sku.sql
SELECT
c.`name`,
f.`name` AS `value`
FROM
(
SELECT
b.`name`,
b.id
FROM
lmrs_product_attribute_values AS a
LEFT JOIN lmrs_attributes AS b ON a.attribute_id = b.id
WHERE
a.product_id = :sensor_identifiers
) AS c
LEFT JOIN (
SELECT
d.attribute_id,
d.`name`
FROM
lmrs_attribute_values AS d
LEFT JOIN lmrs_product_attribute_values AS e ON d.id = e.attribute_value_id
WHERE
product_id = :sensor_identifiers
) AS f ON c.id = f.attribute_id
GROUP BY
f.`name`
规格值脚本
vim /etc/logstash/pipeline/sql/filter_sku.sql
SELECT
`name`,
price
FROM
lmrs_product_skus
WHERE
product_id = :sensor_identifier
创建logstash.conf脚本
vim /etc/logstash/pipeline/conf/logstash.conf
input {
stdin {}
jdbc {
#注意mysql连接地址一定要用ip,不能使用localhost等
jdbc_connection_string => "jdbc:mysql://172.17.0.4:3306/lmrs"
jdbc_user => "root"
jdbc_password => "root"
#数据库重连尝试
connection_retry_attempts => "3"
#数据库连接可用校验超时时间,默认为3600s
jdbc_validation_timeout => "3600"
#这个jar包的地址是容器内的地址
jdbc_driver_library => "/etc/logstash/pipeline/package/mysql-connector-java-8.0.24.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
#开启分页查询(默认是false)
jdbc_paging_enabled => "true"
#单次分页查询条数(默认100000,字段较多的话,可以适当调整这个数值)
jdbc_page_size => "5000"
#执行的sql语句
statement_filepath => "/etc/logstash/pipeline/sql/products.sql"
#需要记录查询结果某字段的值时,此字段为true,否则默认tracking_colum为timestamp的值
use_column_value => true
#是否将字段名转为小写,默认为true(如果具备序列化或者反序列化,建议设置为false)
lowercase_column_names => false
#需要记录的字段,同于增量同步,需要是数据库字段
tracking_column => last_time
#记录字段的数据类型
tracking_column_type => timestamp
#上次数据存放位置
record_last_run => true
#上一个sql_last_value的存放路径,必须在文件中指定字段的初始值
last_run_metadata_path => "/etc/logstash/pipeline/cache/products.txt"
#是否清除last_run_metadata_path的记录,需要增量同步这个字段的值必须为false
clean_run => false
#同步的频率(分 时 天 月 年)默认为每分钟同步一次
schedule => "* * * * *"
#给当前的jdbc命名
type => "products"
}
jdbc {
#注意mysql连接地址一定要用ip,不能使用localhost等
jdbc_connection_string => "jdbc:mysql://172.17.0.4:3306/lmrs"
jdbc_user => "root"
jdbc_password => "root"
#数据库重连尝试
connection_retry_attempts => "3"
#数据库连接可用校验超时时间,默认为3600s
jdbc_validation_timeout => "3600"
#这个jar包的地址是容器内的地址
jdbc_driver_library => "/etc/logstash/pipeline/package/mysql-connector-java-8.0.24.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
#开启分页查询(默认是false)
jdbc_paging_enabled => "true"
#单次分页查询条数(默认100000,字段较多的话,可以适当调整这个数值)
jdbc_page_size => "5000"
#执行的sql语句
statement_filepath => "/etc/logstash/pipeline/sql/attributes.sql"
#需要记录查询结果某字段的值时,此字段为true,否则默认tracking_colum为timestamp的值
use_column_value => true
#是否将字段名转为小写,默认为true(如果具备序列化或者反序列化,建议设置为false)
lowercase_column_names => false
#需要记录的字段,同于增量同步,需要是数据库字段
tracking_column => last_time
#记录字段的数据类型
tracking_column_type => timestamp
#上次数据存放位置
record_last_run => true
#上一个sql_last_value的存放路径,必须在文件中指定字段的初始值
last_run_metadata_path => "/etc/logstash/pipeline/cache/attributes.txt"
#是否清除last_run_metadata_path的记录,需要增量同步这个字段的值必须为false
clean_run => false
#同步的频率(分 时 天 月 年)默认为每分钟同步一次
schedule => "* * * * *"
#给当前的jdbc命名
type => "attributes"
}
}
filter {
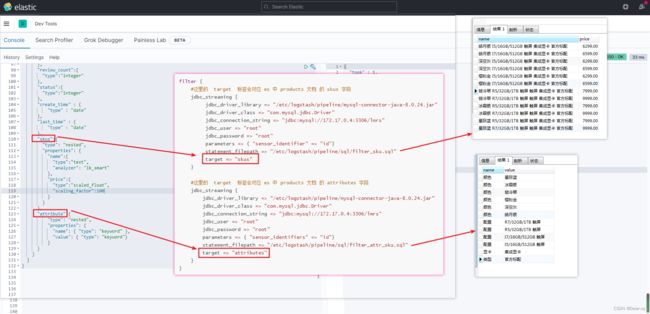
#这里的 target 标签会对应 es 中 products 文档 的 skus 字段
jdbc_streaming {
jdbc_driver_library => "/etc/logstash/pipeline/package/mysql-connector-java-8.0.24.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://172.17.0.4:3306/lmrs"
jdbc_user => "root"
jdbc_password => "root"
parameters => { "sensor_identifier" => "id"}
#这里不能使用statement_filepath的方式引入sql文件,会报错
#statement_filepath => "/etc/logstash/pipeline/sql/filter_sku.sql"
statement => "select `name`,price from lmrs_product_skus where product_id= :sensor_identifier"
#这个skus对应 es 索引中的 skus字段
target => "skus"
}
#这里的 target 标签会对应 es 中 products 文档 的 attributes 字段
jdbc_streaming {
jdbc_driver_library => "/etc/logstash/pipeline/package/mysql-connector-java-8.0.24.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://172.17.0.4:3306/lmrs"
jdbc_user => "root"
jdbc_password => "root"
parameters => { "sensor_identifiers" => "id"}
#这里不能使用statement_filepath的方式引入sql文件,会报错
#statement_filepath => "/etc/logstash/pipeline/sql/filter_attr_sku.sql"
statement => "select c.`name`,f.`name` as `value` from (select b.`name`,b.id FROM lmrs_product_attribute_values as a LEFT JOIN lmrs_attributes as b on a.attribute_id= b.id where a.product_id = :sensor_identifiers) as c LEFT JOIN(select d.attribute_id,d.`name` from lmrs_attribute_values as d LEFT JOIN lmrs_product_attribute_values as e on d.id = e.attribute_value_id where product_id = :sensor_identifiers) as f on c.id = f.attribute_id GROUP BY f.`name`"
#这个skus对应 es 索引中的 attributes
target => "attributes"
}
}
output {
if [type] == "products"
{
elasticsearch
{
# 要导入到的Elasticsearch所在的主机
hosts => "172.17.0.2:9200"
# 要导入到的Elasticsearch的索引的名称
index => "products"
# 类型名称(类似数据库表名)
document_type => "_doc"
# 主键名称(类似数据库主键)
document_id => "%{id}"
}
}
if [type] == "attributes"
{
elasticsearch
{
# 要导入到的Elasticsearch所在的主机
hosts => "172.17.0.2:9200"
# 要导入到的Elasticsearch的索引的名称
index => "attributes"
# 类型名称(类似数据库表名)
document_type => "_doc"
# 主键名称(类似数据库主键)
document_id => "%{id}"
}
}
stdout
{
# JSON格式输出
codec => json_lines
}
}
注意:

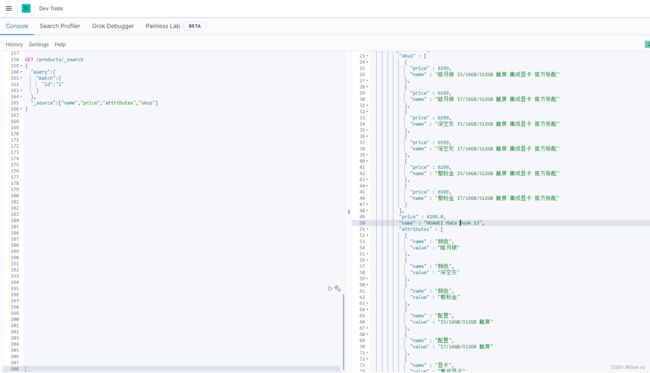
测试结果