核酸检测识别系统——总章
目录
核酸检测结果识别系统
源代码(FOR FREE)
产品介绍
产品功能
技术栈
使用说明
技术算法讲解
组成部分
easyocr
opencv
excel表和数据库
Pyecharts可视化界面
运行控制
网站部分
前端
后端
总结
异常处理
核酸检测结果识别系统
HELLO,大家好。现在是2022年8月9日20:14:44。
在老师和伙伴的帮助下,我完成了核酸检测结果识别系统1.0。相信这套简单方便的系统,能够为大家提供便利。
源代码(FOR FREE)
abcdefg-png/-system (github.com)
产品介绍
产品功能
由于高校频繁的核酸检测,导致每次结果统计非常麻烦。这套系统可以极大减轻负责人(例如辅导员)的工作压力。同学们把检测后的图片上传到网站入口,在下方输入框内填上学号即可。
后台会自动识别图片的检测结果、时间并写入数据库汇总,实时反馈提交情况并制作图标,反馈信息。
技术栈
开发工具:VSCode,PyCharm,sqlyog
前端技术:HTML+CSS+JS,jquery,echarts,bootstrap
后端技术:Python,OCR,opencv,SQL,numpy,pyecharts
使用说明
需要提供给网站管理员一份本班的学号+姓名表格作为数据库,生成的数据表格(result.xlsx)。
可视化数据界面实时更新提交和识别情况,属于私有界面,不会对外公开,只对班级的管理员开放,因此可以很大程度上保证使用者的信息安全。
识别出的情况分类:
时间识别:
| 识别结果 | 原因 |
|---|---|
| 识别成功(年月日和当日时间) | 报告符合规范 |
| 时间匹配失败 | 图片损坏、图片不是核酸检测结果、图片字体过于艺术等等 |
结果识别:
| 识别结果 | 原因 |
|---|---|
| 阴/阳性 | 识别出了图片为绿/红色的主色调 |
| 结果匹配失败 | 图片损坏、图片的主色调不是红或绿 |
特别说明:如果有人传错了图(不是核酸检测结果报告),会识别出阴性阳性,但时间匹配必然失败。所以遇到时间匹配失败+阳性,请勿惊慌,要联系学生重新提交。
技术算法讲解
组成部分
easyocr图像文字提取+opencv颜色识别+正则表达式结果匹配+Python写入Excel和数据库+pyecharts可视化界面 + schedule控制挂载运行;
HTML+CSS+JS+jquery+bootstrap(前端)+ PHP(后端)+ Nginx反向代理 + pm2(项目部署)
easyocr
easyocr是python 2021年推出的第三方包,可以非常精准的识别、提取图片文字(亲测有效)。这项功能主要被用来提取学生的核酸检测时间。下面是easyocr的具体使用:
f = open('result.txt', 'w')
for filename in os.listdir(directory_name):
reader = easyocr.Reader(['ch_sim', 'en'], gpu=False) # GPU or CPU
result = reader.readtext(directory_name + r'/' + filename, detail=0)
result = str.join(result)
f.write(result)
f.write("\n")这里要注意两点,['ch_sim', 'en']是识别语言的列表(中、英文),如果需要其他语言可以去搜它对应的代码。gpu=false 表示我的电脑配置没有gpu,设置成用cpu跑深度学习的代码。
另外,reader.readtext() 是不支持中文路径的,读取的路径一定要注意!
读取完图片文字后,我们把他写入一个txt中,下面要从杂乱的文字中提取出学生的核酸检测时间:
try:
timeresult = re.search('采集时间[\d,\-,:,.]*', result) # 获取采集时间
timeres.append(timeresult.group()[4:]) # 去掉前四个字“采集时间”
except Exception as err:
timeres.append("时间匹配失败")这里我们一定要加入异常处理,防止因为匹配失败而直接报错中断运行。
opencv
本身是打算用easyocr直接提取“阴性”这两个字,但是发现这两个字实在不好提取。所以决定用opencv的颜色识别解决结果的判断问题。首先我们列出一个颜色清单,命名为colorList.py。为了识别更加准确,我们只留下红绿两种颜色。
def getColorList():
dict = collections.defaultdict(list)
# 红色
lower_red = np.array([156, 43, 46])
upper_red = np.array([180, 255, 255])
color_list = []
color_list.append(lower_red)
color_list.append(upper_red)
dict[r'colorList/red'] = color_list
# 绿色
lower_green = np.array([35, 43, 46])
upper_green = np.array([77, 255, 255])
color_list = []
color_list.append(lower_green)
color_list.append(upper_green)
dict[r'coloList/green'] = color_list
return dict
之后用opencv函数进行颜色判断;但cv2.imwrite函数只支持jpg图片,所以我们在网站收集图片时,可以将目标图片进行.jpg文件转换。之后import刚刚的colorList,使用opencv识别图片的颜色。
def get_color(frame):
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
maxsum = -100
color = None
color_dict = colorList.getColorList()
for d in color_dict:
mask = cv2.inRange(hsv, color_dict[d][0], color_dict[d][1])
cv2.imwrite(d + '.jpg', mask) # 这里一定要保证,读取的图片是jpg
binary = cv2.threshold(mask, 127, 255, cv2.THRESH_BINARY)[1]
binary = cv2.dilate(binary, None, iterations=2)
cnts, hiera = cv2.findContours(binary.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
sum = 0
for c in cnts:
sum += cv2.contourArea(c)
if sum > maxsum:
maxsum = sum
color = d
return colorexcel表和数据库
为了方便管理者导出,我们用python将结果写入了excel表格;为了做出可视化界面,我们也需要将结果写入database。数据库的建立比较简单,分为四个字段:
| 字段 | 数据类型 |
|---|---|
| sno(学号) | varchar |
| sname(姓名) | varchar |
| time_result(时间检测结果) | varchar |
| test_result(检测结果) | varchar |
python写入excel表格的操作比较简单,另外,如果直接在浏览器输入.xlsx的文件地址,可以直接下载获取,也是十分方便。
在写入之前,我们需要先清理干净excel表格,我选择直接删除Sheet1,然后新建一张。做数据库也是一样,每次清理一次数据库,防止旧数据干扰新一次的检测。刷新后,写入本次的结果。
db = pymysql.connect(host='localhost', user='root', passwd='root', port=3306, db='hesuan_result_collection')
cursor = db.cursor()
bg = op.load_workbook(r"result.xlsx") # 应先将excel文件放入到工作目录下
bg.remove(bg["Sheet1"])
bg.create_sheet("Sheet1", index=0)
sheet = bg["Sheet1"]
sheet.cell(1, 1, "学号")
sheet.cell(1, 2, "姓名")
sheet.cell(1, 3, "检测时间")
sheet.cell(1, 4, "检测结果") # 刷新excel表格的数据
sql_delete = "Update xinan set time_result = '' , test_result = '' "
cursor.execute(sql_delete)
db.commit() # 刷新数据库的数据
if len(timeres) == len(testres):
for i in range(1, len(timeres) + 1):
sql_fetch_name = "select sname from xinan where sno = '%s' " % student_sno[i - 1] # 获取学号对应的姓名
cursor.execute(sql_fetch_name)
sheet.cell(i + 1, 1, student_sno[i - 1])
try:
sheet.cell(i + 1, 1, student_sno[i - 1])
except Exception as err:
sheet.cell(i + 1, 1, "找不到姓名")
sheet.cell(i + 1, 3, timeres[i - 1])
sheet.cell(i + 1, 4, testres[i - 1]) # 分别写入学号、姓名、检测时间、检测结果
bg.save(r"result.xlsx") # 对文件进行保存
sql_update = "UPDATE `xinan` " \
"SET `time_result` ='%s' , `test_result` = '%s' " \
"WHERE sno = '%s'; " % (timeres[i - 1], testres[i - 1], student_sno[i - 1])
try:
sql_update_result = cursor.execute(sql_update)
db.commit() # 提交数据并保存
except Exception as err:
print("数据库写入失败:", err) # 这里同样也要加入异常处理
else:
print("长度不匹配")
print("finished")Pyecharts可视化界面
做好了算法部分,我们也要能够展示实时提交的情况。这样可以更方便班委管理,及时催促指定同学提交核酸检测报告。首先我们连接数据库,写好相关的sql语句:
import pymysql
import main
db = pymysql.connect(host='localhost', user='root', passwd='root', port=3306, db='hesuan_result_collection')
cursor = db.cursor() # 数据库连接
sql_find_failed = "SELECT DISTINCT sname,sno,time_result,test_result FROM xinan WHERE time_result = '时间匹配失败' or test_result = '结果存疑'" # 查找检测失败的同学名单
sql_readyto_submit = "SELECT DISTINCT sname,sno,time_result,test_result FROM xinan " \
"WHERE time_result = '时间匹配失败' or test_result = '结果存疑'" \
"or time_result = '' or test_result = ''" # 查找需要重新提交的同学名单,包括结果为空和结果错误的总和
main.student_failed = cursor.execute(sql_find_failed)
main.student_left = main.student_num - main.student_checked - main.student_failed之后使用sql查找的结果,制作饼图和表格
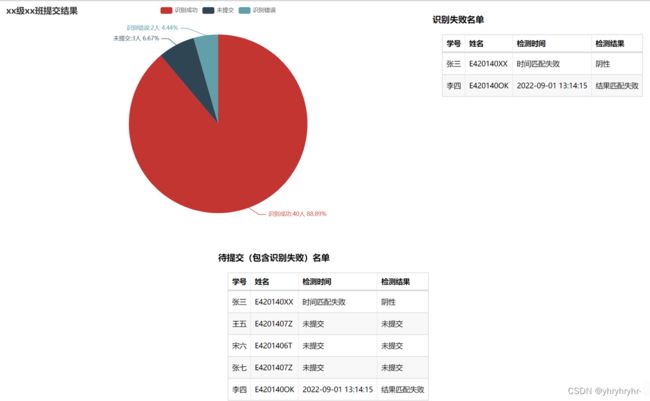
def pie_base():
label = ['识别成功', '未提交', '识别错误']
values = [main.student_checked, main.student_left, main.student_failed] # 计算的三个变量制作饼图,识别成功+未提交+识别错误 == 所有学生
c = (
Pie()
.add("", [list(z) for z in zip(label, values)])
.set_global_opts(title_opts=opts.TitleOpts(title="20信安提交结果"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{c}人 {d}%")) # 值得一提的是,{d}%为百分比
)
return c
def table_base():
cursor.execute(sql_find_failed)
temp = cursor.fetchall() # 获取全部的结果
failed_match = []
for i in temp:
x = list(i)
failed_match.append(x) # 这里fetchall()函数返回的是元组,需要将元组转成列表进行表格制作
table = Table()
headers = ["学号", "姓名", "检测时间", "检测结果"]
rows = failed_match
table.add(headers, rows).set_global_opts(
title_opts=opts.ComponentTitleOpts(title="识别失败名单")
)
return table
def page_simple_layout():
page = Page(layout=Page.SimplePageLayout) # 简单布局
page.add(
pie_base(), # 展示饼图
table_base(), # 展示识别失败名单
table_base2(), # 展示
)
page.render("./result.html")
if __name__ == "__main__":
page_simple_layout()运行控制
使用python的schedule进行运行控制,我们可以有很多控制方法,将这个文件设置成run.py,之后将他用pm2或者nohup挂载运行即可。
import schedule
import os
def run():
os.system("python view.py")
schedule.every().day.at("10:30").do(run) # 每天的10:30执行一次任务
# schedule.every().monday.do(run) # 每周一的这个时候执行一次任务
# schedule.every().hour.do(run) # 每隔一小时执行一次任务
while True:
schedule.run_pending() # run_pending:运行所有可以运行的任务网站部分
前端
前端部分使用传统三件套+jquery+bootstrap,可以展示项目开发人员列表和提交要求,上传图片时实现图片预览,并且检测用户输入的是否为空,是否为学号。
首先我们引入jquery和bootstrap的核心css,js文件
首先,设置一个简单的空白抬头,使页面可以在中间显示:
style>
#main-form
{
margin-top: 30px;
}
之后在body下面套一层div和form表单:
我们用textarea展示文本内容,例如开发者、鸣谢者名单和提交要求之类的信息。class="form-control" 是bootstrap专有样式,使用rows = 7 可以对宽度进行调整。这里还要说明一下,textarea真的是textarea,回车空行都是会显示的,比较方面。
选择图片后的界面是这样的:

使用这段网上写好的js(现在真的找不到原作者了,大海捞针)来实现图片的预览,我本人也不是什么JavaScript高手,有些代码还是喜欢搬运一下哈哈哈
这里很多设置也都加入了注释,允许同时上传文件个数我们设置成1。
之后再用这段代码,判断一下用户输入的是不是学号。
后端
后端使用简单的php,实现将上传图片移动到服务器某目录的功能。多余的一项功能是将上传的图片命名成学号,下面是PHP的后端代码
0){
// echo "错误:".$file["error"];
if($upload_file["error"]==4){
echo "";
}
}// 链接改!!!!!!
if($upload_name==null)
{
echo "";
}
else{
$arr = ".jpg";
$new_name ="{$upload_name}{$arr}";
$upload_file["name"] = $new_name;
$name = iconv('utf-8','gbk',"hesuan/Xinan/".$upload_file["name"]); // 改!!!!!
if(move_uploaded_file($upload_file['tmp_name'],$name)){
move_uploaded_file($upload_file['tmp_name'],$store_dir.$new_name);
echo "";
}
else{
echo "";
}
}
?>总结
到这里,我们终于完成了逻辑闭环。
Step1:同学们将核酸检测的截图提交到网页(并输入合规的学号)
Step2:服务器将文件统一收到某个文件夹下,进行智能识别匹配,将结果写入对应班级的数据库。
Step3:从数据库调出目前的提交情况,反馈到可视化界面和Excel表格(管理员可查看\下载)
Step4:Python实现定时工作并定期删除全部的报告,数据实现阶段更新的大循环。
异常处理
-
首先,我们能够保证学生提交的图片:命名为学号,格式为.jpg。这样一来,python的路径中将不含有中文路径,opencv读取的图片也一定是jpg格式。
-
不论是图片损坏,图片时间识别失败,图片结果识别失败,都有对应的异常处理,可以反馈识别失败和结果存疑这类的异常。
-
项目部署没有问题,可以长期挂载运行python的执行脚本,根据需求安排进程,保证服务器的负载均衡和服务稳定。