卷积神经网络的训练过程,卷积神经网络如何训练
深度神经网络是如何训练的?
Coursera的Ng机器学习,UFLDL都看过。没记错的话Ng的机器学习里是直接给出公式了,虽然你可能知道如何求解,但是即使不知道完成作业也不是问题,只要照着公式写就行。
反正我当时看的时候心里并没能比较清楚的明白。我觉得想了解深度学习UFLDL教程-Ufldl是不错的。有习题,做完的话确实会对深度学习有更加深刻的理解,但是总还不是很清晰。
后来看了LiFeiFei的StanfordUniversityCS231n:ConvolutionalNeuralNetworksforVisualRecognition,我的感觉是对CNN的理解有了很大的提升。
沉下心来推推公式,多思考,明白了反向传播本质上是链式法则(虽然之前也知道,但是当时还是理解的迷迷糊糊的)。所有的梯度其实都是对最终的loss进行求导得到的,也就是标量对矩阵or向量的求导。
当然同时也学到了许多其他的关于cnn的。并且建议你不仅要完成练习,最好能自己也写一个cnn,这个过程可能会让你学习到许多更加细节和可能忽略的东西。
这样的网络可以使用中间层构建出多层的抽象,正如我们在布尔线路中做的那样。
例如,如果我们在进行视觉模式识别,那么在第一层的神经元可能学会识别边,在第二层的神经元可以在边的基础上学会识别出更加复杂的形状,例如三角形或者矩形。第三层将能够识别更加复杂的形状。依此类推。
这些多层的抽象看起来能够赋予深度网络一种学习解决复杂模式识别问题的能力。然后,正如线路的示例中看到的那样,存在着理论上的研究结果告诉我们深度网络在本质上比浅层网络更加强大。
谷歌人工智能写作项目:小发猫

卷积神经网络cnn究竟是怎样一步一步工作的
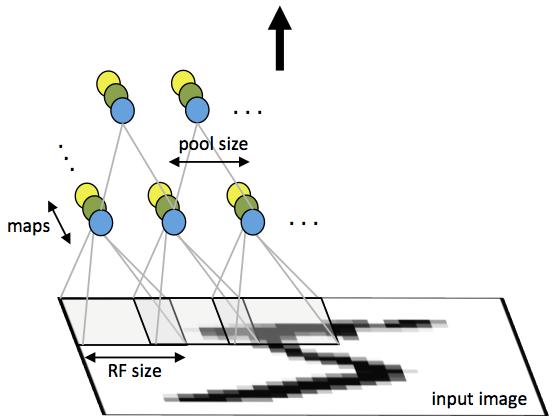
用一个卷积核滑动图片来提取某种特征(比如某个方向的边),然后激活函数用ReLU来压制梯度弥散rbsci。
对得到的结果用另一个卷积核继续提取+reLU,然后池化(保留区域最大或者用区域平均来替换整个局部区域的值,保证平移不变性和一定程度上对过拟合的压制)之后“深度”的话,就会需要对池化后的结果继续用不同的卷积核进行“卷积+relu”再池化的工作。
最后得到的实质是一个图片的深度特征,然后实际分类需要另外加一层,一般是softmax。
(也就是说如果对一个现成的已经训练完毕的卷积神经网络模型,只保留除了最后一层之外的部分,然后输入训练图片,把网络的输出重新送入一个多类的SVM再训练,最后也能得到差不多的结果,取决于svm的参数。)
卷积神经网络训练的参数是什么
卷积神经网络 有哪些改进的地方
卷积神经网络的研究的最新进展引发了人们完善立体匹配重建热情。从概念看,基于学习算法能够捕获全局的语义信息,比如基于高光和反射的先验条件,便于得到更加稳健的匹配。
目前已经探求一些两视图立体匹配,用神经网络替换手工设计的相似性度量或正则化方法。这些方法展现出更好的结果,并且逐步超过立体匹配领域的传统方法。
事实上,立体匹配任务完全适合使用CNN,因为图像对是已经过修正过的,因此立体匹配问题转化为水平方向上逐像素的视差估计。
与双目立体匹配不同的是,MVS的输入是任意数目的视图,这是深度学习方法需要解决的一个棘手的问题。
而且只有很少的工作意识到该问题,比如SurfaceNet事先重建彩色体素立方体,将所有像素的颜色信息和相机参数构成一个3D代价体,所构成的3D代价体即为网络的输入。
然而受限于3D代价体巨大的内存消耗,SurfaceNet网络的规模很难增大:SurfaceNet运用了一个启发式的“分而治之”的策略,对于大规模重建场景则需要花费很长的时间。
怎样用python构建一个卷积神经网络
用keras框架较为方便首先安装anaconda,然后通过pip安装keras以下转自wphh的博客。
#coding:utf-8''' GPU run command: THEANO_FLAGS=mode=FAST_RUN,device=gpu,floatX=float32 python CPU run command: python 2016.06.06更新:这份代码是keras开发初期写的,当时keras还没有现在这么流行,文档也还没那么丰富,所以我当时写了一些简单的教程。
现在keras的API也发生了一些的变化,建议及推荐直接上看更加详细的教程。
'''#导入各种用到的模块组件from __future__ import absolute_importfrom __future__ import print_functionfrom keras.preprocessing.image import ImageDataGeneratorfrom keras.models import Sequentialfrom import Dense, Dropout, Activation, Flattenfrom keras.layers.advanced_activations import PReLUfrom keras.layers.convolutional import Convolution2D, MaxPooling2Dfrom keras.optimizers import SGD, Adadelta, Adagradfrom keras.utils import np_utils, generic_utilsfrom six.moves import rangefrom data import load_dataimport randomimport numpy as np(1024) # for reproducibility#加载数据data, label = load_data()#打乱数据index = [i for i in range(len(data))]random.shuffle(index)data = data[index]label = label[index]print(data.shape[0], ' samples')#label为0~9共10个类别,keras要求格式为binary class matrices,转化一下,直接调用keras提供的这个函数label = np_utils.to_categorical(label, 10)################开始建立CNN模型################生成一个modelmodel = Sequential()#第一个卷积层,4个卷积核,每个卷积核大小5*5。
1表示输入的图片的通道,灰度图为1通道。
#border_mode可以是valid或者full,具体看这里说明:.conv2d#激活函数用tanh#你还可以在(Activation('tanh'))后加上dropout的技巧: (Dropout(0.5))(Convolution2D(4, 5, 5, border_mode='valid',input_shape=(1,28,28))) (Activation('tanh'))#第二个卷积层,8个卷积核,每个卷积核大小3*3。
4表示输入的特征图个数,等于上一层的卷积核个数#激活函数用tanh#采用maxpooling,poolsize为(2,2)(Convolution2D(8, 3, 3, border_mode='valid'))(Activation('tanh'))(MaxPooling2D(pool_size=(2, 2)))#第三个卷积层,16个卷积核,每个卷积核大小3*3#激活函数用tanh#采用maxpooling,poolsize为(2,2)(Convolution2D(16, 3, 3, border_mode='valid')) (Activation('relu'))(MaxPooling2D(pool_size=(2, 2)))#全连接层,先将前一层输出的二维特征图flatten为一维的。
#Dense就是隐藏层。16就是上一层输出的特征图个数。
4是根据每个卷积层计算出来的:(28-5+1)得到24,(24-3+1)/2得到11,(11-3+1)/2得到4#全连接有128个神经元节点,初始化方式为normal(Flatten())(Dense(128, init='normal'))(Activation('tanh'))#Softmax分类,输出是10类别(Dense(10, init='normal'))(Activation('softmax'))##############开始训练模型###############使用SGD + momentum#model.compile里的参数loss就是损失函数(目标函数)sgd = SGD(lr=0.05, decay=1e-6, momentum=0.9, nesterov=True)model.compile(loss='categorical_crossentropy', optimizer=sgd,metrics=["accuracy"])#调用fit方法,就是一个训练过程. 训练的epoch数设为10,batch_size为100.#数据经过随机打乱shuffle=True。
verbose=1,训练过程中输出的信息,0、1、2三种方式都可以,无关紧要。show_accuracy=True,训练时每一个epoch都输出accuracy。
#validation_split=0.2,将20%的数据作为验证集。
(data, label, batch_size=100, nb_epoch=10,shuffle=True,verbose=1,validation_split=0.2)"""#使用data augmentation的方法#一些参数和调用的方法,请看文档datagen = ImageDataGenerator( featurewise_center=True, # set input mean to 0 over the dataset samplewise_center=False, # set each sample mean to 0 featurewise_std_normalization=True, # divide inputs by std of the dataset samplewise_std_normalization=False, # divide each input by its std zca_whitening=False, # apply ZCA whitening rotation_range=20, # randomly rotate images in the range (degrees, 0 to 180) width_shift_range=0.2, # randomly shift images horizontally (fraction of total width) height_shift_range=0.2, # randomly shift images vertically (fraction of total height) horizontal_flip=True, # randomly flip images vertical_flip=False) # randomly flip images# compute quantities required for featurewise normalization # (std, mean, and principal components if ZCA whitening is applied)(data)for e in range(nb_epoch): print('-'*40) print('Epoch', e) print('-'*40) print("Training...") # batch train with realtime data augmentation progbar = generic_utils.Progbar(data.shape[0]) for X_batch, Y_batch in (data, label): loss,accuracy = model.train(X_batch, Y_batch,accuracy=True) (X_batch.shape[0], values=[("train loss", loss),("accuracy:", accuracy)] )"""。
卷积神经网络是不是按顺序一张一张来训练的
卷积神经网络(ConvolutionalNeuralNetwork,CNN)是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现。
[1] 它包括卷积层(alternatingconvolutionallayer)和池层(poolinglayer)。卷积神经网络是近年发展起来,并引起广泛重视的一种高效识别方法。
20世纪60年代,Hubel和Wiesel在研究猫脑皮层中用于局部敏感和方向选择的神经元时发现其独特的网络结构可以有效地降低反馈神经网络的复杂性,继而提出了卷积神经网络(ConvolutionalNeuralNetworks-简称CNN)。
现在,CNN已经成为众多科学领域的研究热点之一,特别是在模式分类领域,由于该网络避免了对图像的复杂前期预处理,可以直接输入原始图像,因而得到了更为广泛的应用。
K.Fukushima在1980年提出的新识别机是卷积神经网络的第一个实现网络。随后,更多的科研工作者对该网络进行了改进。
其中,具有代表性的研究成果是Alexander和Taylor提出的“改进认知机”,该方法综合了各种改进方法的优点并避免了耗时的误差反向传播。
卷积神经网络用全连接层的参数是怎么确定的?
卷积神经网络用全连接层的参数确定:卷积神经网络与传统的人脸检测方法不同,它是通过直接作用于输入样本,用样本来训练网络并最终实现检测任务的。
它是非参数型的人脸检测方法,可以省去传统方法中建模、参数估计以及参数检验、重建模型等的一系列复杂过程。本文针对图像中任意大小、位置、姿势、方向、肤色、面部表情和光照条件的人脸。
输入层卷积神经网络的输入层可以处理多维数据,常见地,一维卷积神经网络的输入层接收一维或二维数组,其中一维数组通常为时间或频谱采样;二维数组可能包含多个通道;二维卷积神经网络的输入层接收二维或三维数组;三维卷积神经网络的输入层接收四维数组。
由于卷积神经网络在计算机视觉领域应用较广,因此许多研究在介绍其结构时预先假设了三维输入数据,即平面上的二维像素点和RGB通道。