吴恩达机器学习课后作业——KMeans和PCA
1.写在前面
吴恩达机器学习的课后作业及数据可以在coursera平台上进行下载,只要注册一下就可以添加课程了。所以这里就不写题目和数据了,有需要的小伙伴自行去下载就可以了。
作业及数据下载网址:吴恩达机器学习课程
2.KMeans作业1
作业一中主要是实现聚类算法,通过迭代不断更新聚类中心,并绘制聚类中心的变化轨迹。
下面附上代码,有详细的注释,这里就不一一解释了。
# author:FLC
# time:2021/7/5
import numpy as np
import scipy.io as scio
import sys
import matplotlib.pyplot as plt
import random
# 用于导入数据的函数
def input_data():
# 导入训练集的路径
data_file = 'machine-learning-ex7\\machine-learning-ex7\\ex7\\ex7data2.mat'
# 导入训练集
data = scio.loadmat(data_file)
X = data['X']
return X
# 用于打印原始数据的函数
def plot_origin_data(X):
fig, ax = plt.subplots(1, 1)
ax.scatter(X[:, 0], X[:, 1])
plt.show()
# 用于寻找距离最近的聚类中心
def find_closest_centroids(X, centroids):
idx = [] # 初始化一个存放中心的列表
for i in range(0, X.shape[0]): # 遍历每一个样本
dis = sys.maxsize # 初始化一个最大值距离
k = -1 # 初始化当前样本中心
for j in range(0, centroids.shape[0]): # 遍历每一个聚类中心
if np.sum(np.power(X[i, :] - centroids[j, :], 2)) < dis: # 如果距离这个聚类中心更近
k = j # 更新中心
dis = np.sum(np.power(X[i, :] - centroids[j, :], 2)) # 修改最小距离
idx.append(k + 1) # 列表添加每一个样本的中心
return idx
# 更新聚类中心
def compute_centroids(X, centroids, idx):
for i in range(0, centroids.shape[0]): # 遍历每一个聚类中心
idxx = [k for k in range(0, len(idx)) if idx[k] == (i + 1)] # 提取属于当前聚类中心的样本位置
cen_temp = np.zeros((1, centroids.shape[1])) # 初始化一个临时变量用来进行向量求和
for j in idxx:
cen_temp += X[j] # 属于当前聚类中心的样本向量求和
centroids[i] = cen_temp / len(idxx) # 得到新的聚类中心
return centroids
# 随机初始化聚类中心
def Kmeans_init_centroids(X, K):
random_int = [] # 定义一个随机数数组
for i in range(0, K):
random_int.append(random.randint(1, X.shape[0] + 1)) # 生成K个随机数
random_centroids = np.array([], dtype=float) # 创建聚类中心
random_centroids = random_centroids.reshape(0, X.shape[1])
# 根据随机数选择对应的样本作为聚类中心
for k in random_int:
random_centroids = np.insert(random_centroids, random_centroids.shape[0], values=X[k], axis=0)
return random_centroids
# 运行Kmeans算法
def runKmeans(X, centroids, iter, K):
iter_centroids = np.array([], dtype=float) # 记录聚类中心变化的数组
iter_centroids = iter_centroids.reshape(K, 0)
idx = None # 记录样本的所属聚类中心
for i in range(0, iter):
idx = find_closest_centroids(X, centroids) # 为每一个样本寻找最近的聚类中心
centroids = compute_centroids(X, centroids, idx) # 更新聚类中心
# 记录聚类中心的变化
iter_centroids = np.insert(iter_centroids, iter_centroids.shape[1], values=centroids[:, 0], axis=1)
iter_centroids = np.insert(iter_centroids, iter_centroids.shape[1], values=centroids[:, 1], axis=1)
fig, ax = plt.subplots(1, 1)
# 绘制原始数据的散点图
for i in range(0, len(idx)):
c = idx[i]
if c == 1:
ax.scatter(X[i, 0], X[i, 1], c='r')
elif c == 2:
ax.scatter(X[i, 0], X[i, 1], c='b')
elif c == 3:
ax.scatter(X[i, 0], X[i, 1], c='g')
# 绘制三个聚类中心的变化
ax.plot(iter_centroids[0, 0:iter_centroids.shape[1]:2], iter_centroids[0, 1:iter_centroids.shape[1]:2], c='black',
marker='o')
ax.plot(iter_centroids[1, 0:iter_centroids.shape[1]:2], iter_centroids[1, 1:iter_centroids.shape[1]:2], c='black',
marker='o')
ax.plot(iter_centroids[2, 0:iter_centroids.shape[1]:2], iter_centroids[2, 1:iter_centroids.shape[1]:2], c='black',
marker='o')
plt.show()
K = 3 # 定义聚类中心的个数
X = input_data() # 导入数据
centroids = Kmeans_init_centroids(X, K) # 随机初始化聚类中心
runKmeans(X, centroids, 10, K) # 运行KMeans
结果展示:
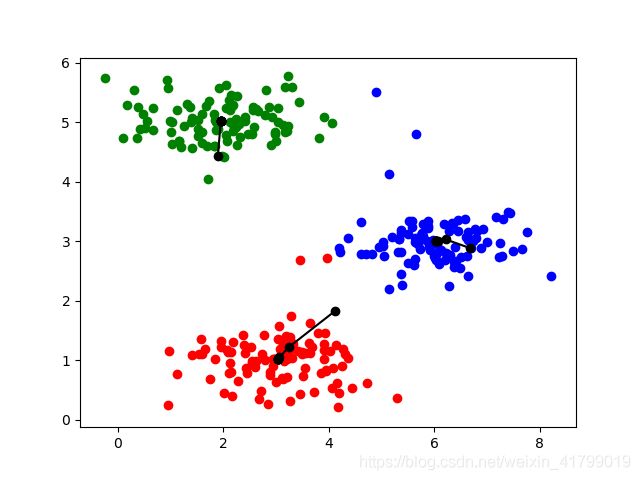
3.KMeans作业2
作业二中主要是实现颜色的降维,将原本的上万种颜色变为16种颜色(相当于形成16个聚类中心)。
下面附上代码,有详细的注释,这里就不一一解释了。
# author:FLC
# time:2021/7/6
import cv2
import numpy as np
import sys
import random
import matplotlib.pyplot as plt
# 导入数据的函数
def input_data():
# 导入训练集的路径
data_file = 'machine-learning-ex7\\machine-learning-ex7\\ex7\\bird_small.png'
img = cv2.imread(data_file)
# 对原始数据进行可视化
# fig, ax = plt.subplots(1, 1)
# ax.imshow(img)
# plt.show()
return img
# 用于寻找距离最近的聚类中心
def find_closest_centroids(X, centroids):
idx = [] # 初始化一个存放中心的列表
for i in range(0, X.shape[0]): # 遍历每一个样本
dis = sys.maxsize # 初始化一个最大值距离
k = -1 # 初始化当前样本中心
for j in range(0, centroids.shape[0]): # 遍历每一个聚类中心
if np.sum(np.power(X[i, :] - centroids[j, :], 2)) < dis: # 如果距离这个聚类中心更近
k = j # 更新中心
dis = np.sum(np.power(X[i, :] - centroids[j, :], 2)) # 修改最小距离
idx.append(k + 1) # 列表添加每一个样本的中心
return idx
# 更新聚类中心
def compute_centroids(X, centroids, idx):
for i in range(0, centroids.shape[0]): # 遍历每一个聚类中心
idxx = [k for k in range(0, len(idx)) if idx[k] == (i + 1)] # 提取属于当前聚类中心的样本位置
cen_temp = np.zeros((1, centroids.shape[1])) # 初始化一个临时变量用来进行向量求和
for j in idxx:
cen_temp += X[j] # 属于当前聚类中心的样本向量求和
centroids[i] = cen_temp / len(idxx) # 得到新的聚类中心
return centroids
# 随机初始化聚类中心
def Kmeans_init_centroids(X, K):
random_int = [] # 定义一个随机数数组
for i in range(0, K):
random_int.append(random.randint(1, X.shape[0] + 1)) # 生成K个随机数
random_centroids = np.array([], dtype=float) # 创建聚类中心
random_centroids = random_centroids.reshape(0, X.shape[1])
# 根据随机数选择对应的样本作为聚类中心
for k in random_int:
random_centroids = np.insert(random_centroids, random_centroids.shape[0], values=X[k], axis=0)
return random_centroids
# 运行Kmeans算法
def runKmeans(X, centroids, iter, K):
iter_centroids = np.array([], dtype=float) # 记录聚类中心变化的数组
iter_centroids = iter_centroids.reshape(K, 0)
idx = None # 记录样本的所属聚类中心
for i in range(0, iter):
idx = find_closest_centroids(X, centroids) # 为每一个样本寻找最近的聚类中心
centroids = compute_centroids(X, centroids, idx) # 更新聚类中心
# 记录聚类中心的变化
iter_centroids = np.insert(iter_centroids, iter_centroids.shape[1], values=centroids[:, 0], axis=1)
iter_centroids = np.insert(iter_centroids, iter_centroids.shape[1], values=centroids[:, 1], axis=1)
return idx, centroids
# 绘制图像的函数
def plot_img(raw_img, idx, centroids):
raw_shape0 = raw_img.shape[0] # 记录原始数据的第一个维度
raw_shape1 = raw_img.shape[1] # 记录原始数据的第二个维度
raw_shape2 = raw_img.shape[2] # 记录原始数据的第三个维度
fig, ax = plt.subplots(1, 2)
ax[0].imshow(raw_img) # 原始数据的绘制
raw_img = raw_img.reshape(raw_shape0 * raw_shape1, 3)
for i in range(0, len(idx)):
raw_img[i] = centroids[idx[i] - 1] # 将一些像素点替换成所属聚类中心的像素点
proceed_img = raw_img.reshape(raw_shape0, raw_shape1, raw_shape2)
ax[1].imshow(proceed_img) # 压缩后的数据绘制
plt.show()
K = 16 # 定义聚类中心的个数
iter = 10 # 定义迭代次数
raw_img = input_data() # 导入原始数据
p_img = raw_img.reshape(raw_img.shape[0] * raw_img.shape[1], 3) # 修改维度
centroids = Kmeans_init_centroids(p_img, K) # 初始化聚类中心
idx, centroids = runKmeans(p_img, centroids, iter, K) # 运行KMeans算法
plot_img(raw_img, idx, centroids) # 打印数据
结果展示:

4.PCA作业1
作业一中主要是实现二维数据降至一维度数据,然后再对降维后的数据进行还原,可视化降维后的误差。
下面附上代码,有详细的注释,这里就不一一解释了。
# author:FLC
# time:2021/7/6
import numpy as np
import scipy.io as scio
import sys
import matplotlib.pyplot as plt
import random
# 用于导入数据的函数
def input_data():
# 导入训练集的路径
data_file = 'machine-learning-ex7\\machine-learning-ex7\\ex7\\ex7data1.mat'
# 导入训练集
data = scio.loadmat(data_file)
X = data['X']
# 可视化原始数据
# fig,ax = plt.subplots(1,1)
# ax.scatter(X[:,0],X[:,1])
# plt.show()
return X
# 用于计算协方差的函数
def compute_sigma(X):
# 根据公式计算协方差
m = X.shape[0]
sum = np.zeros((X.shape[1], X.shape[1])) # 初始化累加矩阵
for i in range(0, X.shape[0]):
x = X[i, :]
x = x.reshape(1, X.shape[1])
sum += x.T @ x # 得到一个n*n的矩阵
return sum / m # 得到协方差
# 用于进行特征缩放的函数(均值归一化)
def featureNormalize(data, b):
for i in range(0, b):
dataMean = np.mean(data[:, i]) # 获取第i列的平均值
dataStd = np.std(data[:, i]) # 获取第i列的标准差
for j in range(0, data.shape[0]): # 遍历第i列中每一个数值
data[j, i] = (data[j, i] - dataMean) / dataStd # 利用吴恩达老师的公式进行归一化
return data
# 用于打印数据的函数
def plot_data(X,X_approx):
fig, ax = plt.subplots(1, 1)
ax.scatter(X[:, 0], X[:, 1], color='b') # 打印原始数据
ax.scatter(X_approx[:, 0], X_approx[:, 1], color='r') # 打印还原后
plt.show()
X = input_data() # 导入原始数据
X = featureNormalize(X, X.shape[1]) # 进行归一化
sigma = compute_sigma(X) # 计算协方差
U, S, V = np.linalg.svd(sigma) # 调用svd进行奇异值分解
U_reduce = U[:, [0]] # 选择要降至的维度,也就是选择对应列数的向量
z = X @ U_reduce # 得到降维后的数据
X_approx = z @ U_reduce.T # 还原数据
plot_data(X,X_approx)
结果展示:
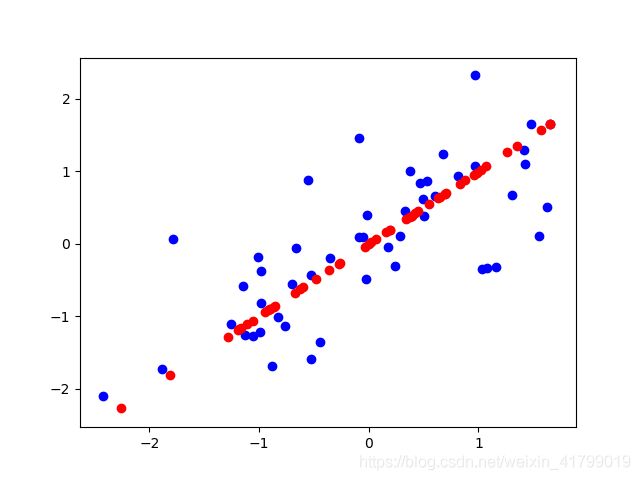
5.PCA作业2
作业二中主要是实现数据的降维与还原的对比
下面附上代码,有详细的注释,这里就不一一解释了。
# author:FLC
# time:2021/7/6
import numpy as np
import scipy.io as scio
import sys
import matplotlib.pyplot as plt
import random
# 用于导入数据的函数
def input_data():
# 导入训练集的路径
data_file = 'machine-learning-ex7\\machine-learning-ex7\\ex7\\ex7faces.mat'
# 导入训练集
data = scio.loadmat(data_file)
X = data['X']
# 绘制原始数据
# fig,ax = plt.subplots(10,10,figsize=(10,10))
# n = 0
# for i in range(0,10):
# for j in range(0,10):
# temp = X[n]
# temp = temp.reshape(32, 32).T
# n = n+1
# ax[i][j].imshow(temp, cmap='Greys_r')
# # 消除坐标轴,主要为了美观
# ax[i][j].set_xticks([])
# ax[i][j].set_yticks([])
# plt.show()
return X
# 用于进行特征缩放的函数(均值归一化)
def featureNormalize(data, b):
for i in range(0, b):
dataMean = np.mean(data[:, i]) # 获取第i列的平均值
dataStd = np.std(data[:, i]) # 获取第i列的标准差
for j in range(0, data.shape[0]): # 遍历第i列中每一个数值
data[j, i] = (data[j, i] - dataMean) / dataStd # 利用吴恩达老师的公式进行归一化
return data
# 用于计算协方差的函数
def compute_sigma(X):
# 根据公式计算协方差
m = X.shape[0]
sum = np.zeros((X.shape[1], X.shape[1])) # 初始化累加矩阵
for i in range(0, X.shape[0]):
x = X[i, :]
x = x.reshape(1, X.shape[1])
sum += x.T @ x # 得到一个n*n的矩阵
return sum / m # 得到协方差
# 打印图像
def plot_imag(X):
fig, ax = plt.subplots(10, 10, figsize=(10, 10)) # 定义一个10*10的画布
n = 0 # 记录第几个
for i in range(0, 10): # 遍历行
for j in range(0, 10): # 遍历列
temp = X[n]
temp = temp.reshape(32, 32).T # 重构维度
n = n + 1
ax[i][j].imshow(temp, cmap='Greys_r') # 打印图片
# 消除坐标轴,主要为了美观
ax[i][j].set_xticks([])
ax[i][j].set_yticks([])
plt.show()
X = input_data() # 导入数据
X = featureNormalize(X, X.shape[1]) # 对数据进行归一化
sigma = compute_sigma(X) # 计算协方差
U, S, V = np.linalg.svd(sigma) # 调用svd进行奇异值分解
U_reduce = U[:, 0:36] # 选择要降至的维度,也就是选择对应列数的向量
z = X @ U_reduce # 得到降维后的数据
X_approx = z @ U_reduce.T # 还原数据
plot_imag(X) # 打印原始数据
plot_imag(X_approx) # 打印还原后的数据
结果展示:

