网络传输中的编码与解码
一、字符集与编码
字符编码的由来
电脑是由电路板组成,电路板里面集成了无数的电阻和电容, 交流电经过电容的时候,电压比较低 记为低电平用0表示;交流电流过电阻的时候,电压比较高,记为高电平,用1来表示。 所以每一个1和0在计算机中被称为位,也就是bit位。
然而,如果使用一个位来表示计算机中的最小存储单元, 那么这个存储单元只能存储0或者1,存储的范围太小了,所以我们规定用用8个bit位为一组来表示计算机的最小存储单元。 8个位每个位上能存储0或者1,则byte的存储范围则是 00000000-11111111(换算成整数即0-255)。 这个最小存储单元,就是byte字节。
一个字节可以表示256个数字,两个字节可以表示65536个数字:

计算机的底层只能存储0和1,如果是日常生活中遇到的数字比如127,这个可以通过10进制和二进制的转换从而让计算机存储01111111,但是如果计算机存储类似于汉字、英文字符、符号字符等内容,是如何存储的呢?
一堆二进制的0和1,怎么也算不出字母A吧。不能直接表示,那就通过数字中转一下。只要给它指定一个数值编号,要存储字符时,就存储这个数值。要读取时,按照映射关系找到这个字符。
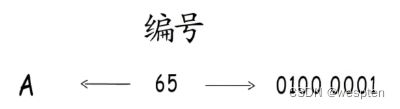
像这样收录许多字符然后给它们一一编号,得到一个字符编号对照表,这就是“字符集”。
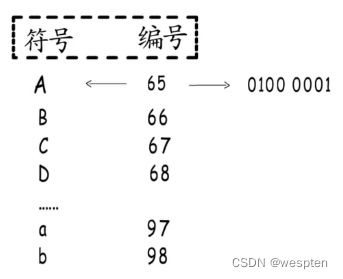
例如下图,计算机提供了很多的编码表记录了字符和数字的一一对应关系,编码就是把字符对应编码表中的码值存储在电脑中,而解码则是把码值在编码表中的对应的字符展现出来。

字符集和字符编码以及编码转换
最先出现的编码格式是ASCII码,这种编码规则是美国人制定的,大致的规则是用一个字节(8个bit)去表示出现的字符,其实由于在老美的世界里中总共出现的字符也不超过128个,而一个字节能够表示256种字符,所以当时这种编码的方式是没有问题的。
后来计算机在全世界普及起来,不同国家的语言都面临着如何在计算机中表示的问题,比如我们的汉字常用的就有几千个,显然最开始一个字节的ASIIC码表示就不够用了,这个时候就出现了Unicode编码,确切的说它只是一种表示规则,并不对应具体的实现形式。
针对汉字,最先设计了GB2312字符集、但是GB2312不包含繁体字,所以又设计了BIG5字符集,但是依然有很多字符没有被收录,其它国家的字体也不在其中
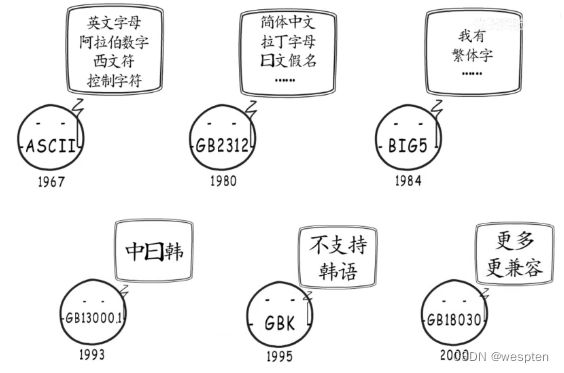
与其不断推出收录更多字符的字符集,还不如本着全球化统一标准的目的,制作一个通用字符集,Unicode学术学会就是这样做的,这个字符集就是Unicode,它于1990年开始研发并于1994年正式公布,实现了跨语言跨平台的文本转换与处理,字符集促成了字符与二进制的合作。
Uni-这个前缀在英文中表示的是统一的含义,它试图把全世界的语言用一种统一的编码表示,但是Unicode只规定了字符对应的二进制数据,但是没有规定这种二进制数据在内存中具体用几个字节存储,然后就乱套了,各国在实现Unicode时都发挥了自己的聪明才智,出现了类似utf-16,utf-32等等的形式,在这种情况下,Unicode的理想并没有实现,直到互联网的普及,utf-8的出现,utf-8的出现真正实现了大一统,它在实现Unicode规范的同时,又扩展了自己的规则,utf-8规定了任意一种字符编码后的机器码都是占用6个字节。
UTF-8以8位单元对Unicode进行编码:

UTF-8 的编码规则:如果只有一个字节,那么最高的比特位为 0;如果有多个字节,那么第一个字节从最高位开始,连续有几个比特位的值为 1,就使用几个字节编码,剩下的字节均以 10 开头。
具体的表现形式为:
0xxxxxxx:单字节编码形式,这和 ASCII 编码完全一样,因此 UTF-8 是兼容 ASCII 的;
110xxxxx 10xxxxxx:双字节编码形式;
1110xxxx 10xxxxxx 10xxxxxx:三字节编码形式;
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx:四字节编码形式。
xxx 就用来存储 Unicode 中的字符编号。
例如汉子的“汉”字,Unicode的编码是6C49,6C49在0800-FFFF之间,因此使用3个字节模板来存储。将6C49写成二进制是0100110001001001,用这个比特流一次代替模板中的x,得到11100110 10110001 10001001,即E6 B1 89。
对于常用的字符,它的 Unicode 编号范围是 0 ~ FFFF,用 1~3 个字节足以存储,只有及其罕见,或者只有少数地区使用的字符才需要 4~6个字节存储。
UTF-8编码具体是怎么存储(eggo世界)这个内容呢?
直接的想法是,找到每个字符对应的编号,存成二进制,如果使用unicode字符集,拿到他们的编号,直接组合会得到这样一大串二进制位:

问题出现了,该怎么知道这一长串内容是要按照下面的方式划分的呢?

也可以按照下面的方式划分呀:

所以,照搬编号的方式,行不通!!!
那现在我们可以知道了,编码完成之后还需要解决的一个问题是如何划分字符边界。
其中一个方法可以这样,不管编号多大多小,统一按照最长的编码的来,位数不够的高位补0。

这就是定长编码,这样就可以解决字符边界的问题,但是可以发现,这样就太浪费内存了,而且字符集收录的符号越多,编号跨度就越大,定长编码造成的浪费就越显著,还得再想办法,定长编码不行,那就“变长编码”,小编号少占字节,大编号多占字节。
但是怎么划分字符边界呢?来看一种解决方案,如果编号属于[0,127],就占用一个字节,且最高位固定标识为0。如果属于[128,2047],就占用两个字节,且有固定标识位110和10,三个以及更多字节的编码也遵循这样的规则:

以二进制数字01100101,这个字节最高位是零,就表示这个字符只占一个字节,除去标识位,剩下的7位就是该字符的二进制编号,转换成十进制就是101,对应字符e,“世”字同理。
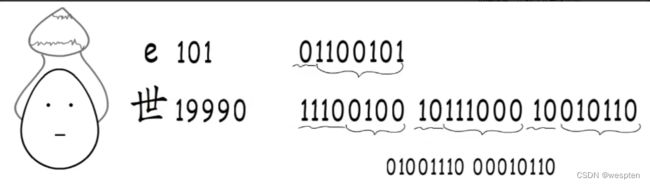
这样划分字符就不成问题了。刚刚我们做的是解码,现在来编码试试,世界的“界”字在Unicode字符集中编号为30028,符合区间[2048,65535],所以要占用三字节,使用下面这个模板。
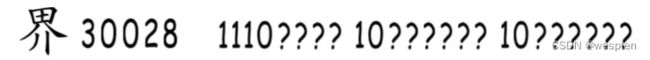
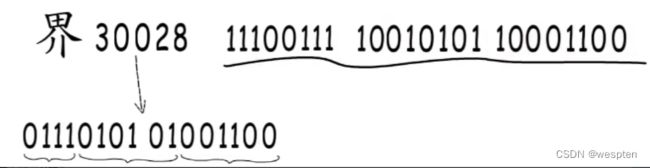
然后将编号30028转换成二进制01110101 01001100,再对应填到模板中:
常见编码格式与编码表
计算机中存储一个数是用二进制来表示的,比如存储127,那么计算机的底层是 0111 1111,人看这些二进制的数通常都是眼花缭乱的,如何方便而规整的表示这些二进制数呢,不妨引入十六进制。
二进制换算成十六进制,则是每四位为一组转换为16进制数即可, 比如0111 1111 这个数前4位 0111 转换为 7 ,后4位转换为F, 则最终的16进制数是7F,一般我繁琐的二进制数使用十六进制数来表示会比较方便规整,所以人们习惯用十六进制数来表示码值。
1、HEX格式
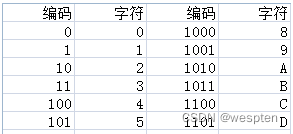
hex编码也称之为Base16 编码,就是把一个字节,用十六进制来表示, 表示的结果得是字符形式的。
Hex的编码原理是:把一长串二进制数每4个分一组,如果位数不够就在高位补0。4位数字一共只有16种情况,分别用0-9,A-F表示这16种情况。
比如说字符的 ‘a’,在计算机底层存储的是 0110 0001 ,对应的16进制就是61 ,它对应的字符 是'61'。也就是说 ‘a’ 经过HEX编码转化成了 '61' ,从计算存储二进制的角度是从0110 0001经过HEX编码成了 0011011000110001,占用的存储扩大了一倍。
其他任意二进制数据(字节为单位)都可以转化。
HEX编码
hex编码就是16进制编码,是字符的ascii码值的16进制表示:
string = input("请输入一个字符: ") #接收一个字符
number=ord(string) #得到该字符的ASCII值
print(string+" 的16进制表示为:",hex(number)) #将字符的ASCII值转换为16进制形式
string2 = input("请输入16进制表示: ") #接收一个16进制格式的ascii值
number2=int(string2,16) #将该16进制的数据转为10进制的数据ascii值
print(string+" 的16进制表示为:",chr(number2)) #将该10进制的ascii转为字符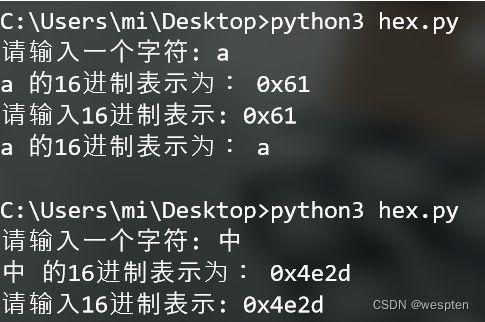
HEX编码的特点是:解码编码速度快但是体积变大了一倍。
代码演示:
byte[] src = "a".getBytes(StandardCharsets.UTF_8);
byte[] encoded = Hex.encode(src);
System.out.printf("字符串'%s'编码后的字符结果:'%s'%n",new String(src,StandardCharsets.UTF_8),new String(encoded,StandardCharsets.UTF_8));
System.out.printf("原长度:%d,编码后的长度:%d, 编码后是原来的%.2f%n",src.length,encoded.length,(double)(encoded.length)/src.length);
输出结果为61:
字符串'a'编码后的字符结果:'61'
原长度:1,编码后的长度:2, 编码后是原来的2.002、Base64编码
Base64是网络上最常见的用于传输8Bit字节码的编码方式之一,Base64就是一种基于64个可打印字符来表示二进制数据的方法。
Base64编码是从二进制到字符的过程,可用于在HTTP环境下传递较长的标识信息。采用Base64编码具有不可读性,需要解码后才能阅读。
base64其实不是安全领域下的加密解密算法。虽然有时候经常看到所谓的base64加密解密。其实base64只能算是一个编码算法,对数据内容进行编码来适合传输。虽然base64编码过后原文也变成不能看到的字符格式,但是这种方式很初级,很简单。
base64 产生背景:不想被人获取到明文后,直接得知内容,必须解密之后才能阅读。
Base64就是在这种背景下产生的加密方法。它的特点是:1、速度非常快。2、能够将字符串A转换成字符串B,而且如果你光看字符串B,是绝对猜不出字符串A的内容来的。
例如:
转换前 aaaaaabb ccccdddd eeffffff
转换后 00aaaaaa 00bbcccc 00ddddee 00ffffff
Base64的算法规则:把数据按照字节分为三个字节一组,也就是24bit,如果最后存在不够三个字节为一组,也就是不够24bit的话,就使用0补位。
Base64就是说选出64个字符,包括小写字母a-z、大写字母A-Z、数字0-9、符号”+”、”/”作为基本基础集的编码方式。
①将每三个字节作为一组,一共是24个二进制位。
②将这24个二进制位分为四小组,每个小组有6个二进制位。
③在每小组前面加两个00,扩展成32个二进制位,即四个字节。
④根据base64基础表,得到扩展后的每个字节的对应的base64符号。
1)最后一组三个字节,不用补位
'abc'字符串 底层的二进制为 011000010110001001100011,这是24个bit为一组,以6bit分为四部分为 011000 010110 001001 100011 编码成对应上表的字符 ’ YWJj' 。
byte[] src = "abc".getBytes(StandardCharsets.UTF_8);
byte[] encoded = Base64.encode(src);
System.out.printf("字符串'%s'编码后的字符结果:'%s'%n",new String(src,StandardCharsets.UTF_8),new String(encoded,StandardCharsets.UTF_8));
System.out.printf("原长度:%d,编码后的长度:%d, 编码后是原来的%.2f%n",src.length,encoded.length,(double)(encoded.length)/src.length);
字符串'abc'编码后的字符结果:'YWJj'
原长度:3,编码后的长度:4, 编码后是原来的1.33
2)最后一组只有两个字节,补2bit 0
'ab'字符串 底层的二进制为 0110000101100010,补位成 011000010110001000,以6bit分为三部分为 011000 010110 001000 编码成对应上表的字符 ’ YWI' ,因为比一般的少一个编码单位,所以在后面加上一个=字符,最终的结果就是 ’ YWI=' 。
byte[] src = "ab".getBytes(StandardCharsets.UTF_8);
byte[] encoded = Base64.encode(src);
System.out.printf("字符串'%s'编码后的字符结果:'%s'%n",new String(src,StandardCharsets.UTF_8),new String(encoded,StandardCharsets.UTF_8));
System.out.printf("原长度:%d,编码后的长度:%d, 编码后是原来的%.2f%n",src.length,encoded.length,(double)(encoded.length)/src.length);
字符串'ab'编码后的字符结果:'YWI='
原长度:2,编码后的长度:4, 编码后是原来的2.00
3)最后一组只有一个字节 补4bit0
'a'字符串 底层的二进制为 01100001,补位成 011000010000这是24个bit为一组,以6bit分为四部分为 011000 010000 编码成对应上表的字符 ’ YQ' ,因为比一般的少两个编码单位,所以后面加上两个=字符,最终的结果就是 ’ YQ==' 。
byte[] src = "a".getBytes(StandardCharsets.UTF_8);
byte[] encoded = Base64.encode(src);
System.out.printf("字符串'%s'编码后的字符结果:'%s'%n",new String(src,StandardCharsets.UTF_8),new String(encoded,StandardCharsets.UTF_8));
System.out.printf("原长度:%d,编码后的长度:%d, 编码后是原来的%.2f%n",src.length,encoded.length,(double)(encoded.length)/src.length);字符串'a'编码后的字符结果:'YQ=='
原长度:1,编码后的长度:4, 编码后是原来的4.00
由于在编码的过程中只有最后一组才有可能存在补位情况,所以我们可以认为 使用base64编码后数据的体积是原来的1.33倍。
Base64编码:
import base64
string = input("请输入一个字符: ")
print(string+" 的Base64编码为:",base64.b64encode(string.encode('utf-8')).decode("utf-8")) #字符转为base64编码
string2 = input("请输入一个base64编码: ")
print(string2+" 对应的字符为:",base64.b64decode(string2.encode('utf-8')).decode("utf-8")) #base64编码转为字符
经过Base64 转码后数据长度的变化:
UTF-8编码下的中/日/韩文占了3/4个字节,若中文占四个字节是最长的情况:则base64 转换后长度比是 1 : 8。
1个中文字符 –》 4个字节 –》 每三个字节分为一组,则分成两组,共6个字节 –》 扩展,得到8个字节 –》 将8个字节转换成8个base64字符。
毕竟四个字节占少数,三个字节情况下:则base64 转换后长度比是1 : 4。
1个中文字符 –》 3个字节 –》 每三个字节分为一组,则分成一组,共3个字节 –》 扩展,得到4个字节 –》 将4个字节转换成4个base64字符。
因此加密后的字符长度为原长度的4~8倍。
Base64编码的特点: 体积小,但是由于算法相对复杂所以解码编码速度比较慢。
3、url编码
当 URL 路径,或者查询参数中带有中文、特殊字符的时候,就需要对 URL 进行编码(采用十六进制编码格式)。URL 编码的原则是使用安全字符(即没有特殊用途或者特殊意义的字符)去表示那些不安全的字符。
为什么需要URL编码
URL 之所以需要编码,是因为 URL 中的某些字符会引起歧义,比如若 URL 查询参数中包含”&”或者”%”就会造成服务器解析错误,再比如,URL 的编码格式采用的是 ASCII 码而非 Unicode,这表明 URL 中不允许包含任何非 ASCII 字符(比如中文),否则就会造成 URL 解析错误。
URL基本组成
一个 URL 的基本组件包括协议、域名、端口号、路径和查询字符串,其中路径和查询字符串之间使用问号?隔离,示例如下:
http://www.biancheng.net/index?param=10其中域名为 http://www.biancheng.net,路径为 index,查询字符串为 param=1。
URL 中规定了一些字符(:/ ? # [ ] @)用来分隔不同的 URL 组件,这些字符被称为保留字符。例如:
- 冒号:用于分隔协议和主机组件,斜杠用于分隔主机和路径
- 问号:用于分隔路径和查询参数等。
还有一些保留字符(! $ & * + , ; =)起到分割 URL 不同组件的作用,比如:
=用于表示查询参数中的键值对&符号用于分隔查询多个键值对。
哪些字符需要编码
URL 编码协议规定(即 RFC3986 协议):URL 中只允许包含英文字母、数字、以及这 4 个 - _ . ~ 特殊字符和所有的保留字符。
协议中规定了以下保留字符:
! * ’ ( ) ; : @ & = + $ , / ? # [ ]非保留字符:
![]()
如果一个保留字符在特定上下文中具有特殊含义 , 且URI中必须使用该字符用于其它目的, 那么该字符必须百分号编码:

使用:
1. url中的PathInfo
2. url中的QueryString
当组件中的普通数据包含这些特殊字符时,它们就变成了不安全字符,此时就需要对其进行编码处理。
比如查询字符串中包含了特殊字符:
http://www.biancheng.net/index?param=10*¶m1=20*3. get请求或post 请求Content-Type的值是:application/x-www-form-urlencoded
表单提交时,参数中中文的编码则根据HTML代码中指定的字符编码来决定(也就是html代码中标签指定的字符编码)。当然这是在form中没有指定accept-charset的情况下,如果form中加了accept-charset="GBK”属性,则表单参数则由accept-charset指定编码进行编码。
下表列出了一些 URL特殊字符及其编码:
为了让您思路更清晰,下面简单总结一下,哪些字符需要编码。主要分为以下六种情况:
- ASCII 表中没有对应可显示字符的,例如汉字。
- 不安全字符,包括:# ”% <> [] {} | \ ^ ` ~ 。
- 不当做保留字符来使用的保留字符,即& / : ; = ? @ 。
- 字母不需要进行URL编码
- 特殊字符的URL编码是其ASCII值的16进制表示,前面加个%
- 中文的URL编码是其UTF-8编码前面加个 %
from urllib.parse import quote
from urllib.parse import unquote
string = input("请输入一个字符: ")
print(string+" 的URL编码为:",quote(string,"utf-8")) #将字符进行URL编码
string2 = input("请输入一个URL编码: ")
print(string2+" 对应的字符为:",unquote(string2,"utf-8")) #将URL编码转换为字符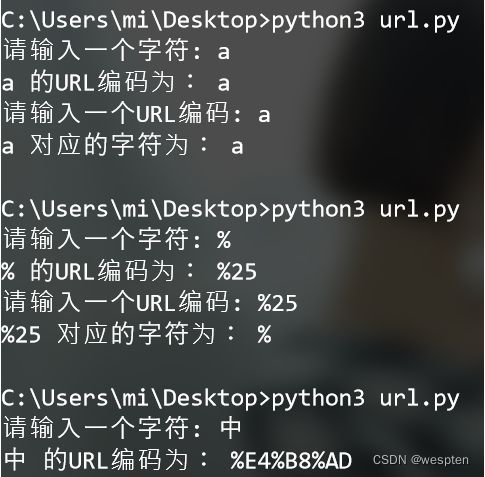
URL在线编码解码
通过浏览器可以搜索到许多在线 URL 编码解码工具,这些工具能够很方便的实现 URL 的编码与解码:
编码转换工具
在线url网址编码、解码器-BeJSON.com
示例如下:
编码前: http://www.biancheng.net/s?ie=utf-8&f=8&tn=baidu&wd=hell 编程帮
编码后: http://www.biancheng.net/s?ie=utf-8&f=8&tn=baidu&wd=hell%20%B1%E0%B3%CC%B0
4、拉丁字符集
ASCII编码
世界上虽然有各种各样的字符,但计算机发明之初没有考虑那么多,基本上只考虑了美国的需求,美国大概只需要128个字符,美国就规定了这128个字符的二进制表示方法,这个方法是一个标准,称为ASCII编码,全称是American Standard Code for Information Interchange,美国信息互换标准代码。128个字符用7个位刚好可以表示,计算机存储的最小单位是byte,即8位,ASCII码中最高位设置为0,用剩下的7位表示字符。这7位可以看做数字0到127,ASCII码规定了从0到127个,每个数字代表什么含义。除了中文之外,我们平常用的字符基本都涵盖了,键盘上的字符大部分也都涵盖了。
ASCII第一次以规范标准的型态发表是在1967年,最后一次更新则是在1986年,至今为止共定义了128个字符,其中33个字符无法显示(这是以现今操作系统为依归,但在DOS模式下可显示出一些诸如笑脸、扑克牌花式等8-bit符号),且这33个字符多数都已是陈废的控制字符,控制字符的用途主要是用来操控已经处理过的文字,在33个字符之外的是95个可显示的字符,包含用键盘敲下空白键所产生的空白字符也算1个可显示字符(显示为空白)。

扩展 ASCII 打印字符:扩展的 ASCII 字符满足了对更多字符的需求。扩展的 ASCII 包含 ASCII 中已有的 128 个字符(数字 0–32 显示在下图中),又增加了 128 个字符,总共是 256 个。即使有了这些更多的字符,许多语言还是包含无法压缩到 256 个字符中的符号。因此,出现了一些 ASCII 的变体来囊括地区性字符和符号.

ASCII编码:
字符的ascii编码可以对照ASCII编码表;
中文的ASCII编码是对照unicode编码表;
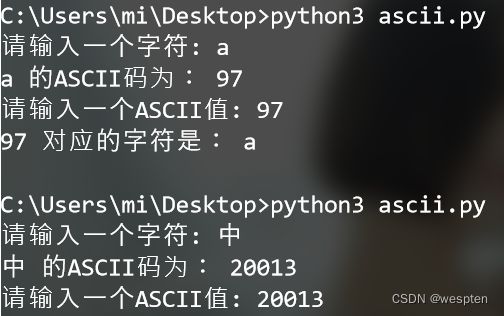
string = input("请输入一个字符: ")
print(string+" 的ASCII码为:",ord(string)) #将字符转换为ascii码值
number = input("请输入一个ASCII值: ")
number = int(number) #将接收到的字符数字转换int格式
print(number," 对应的字符是:",chr(number)) #将ascii码值转换为字符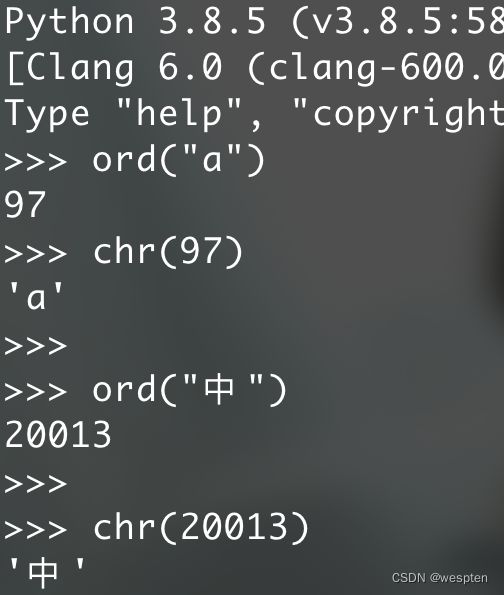
ISO-8859-1
ISO 8859-1又称Latin-1,它也是使用一个字节表示一个字符,因为西欧的文字也都是字母拼接,只不过不是26个英文字母罢了,其中0到127与Ascii一样,128到255规定了不同的含义。在128到255中,128到159表示一些控制字符,这些字符也不常用,就不介绍了。
160到255表示一些西欧字符,如下图所示:
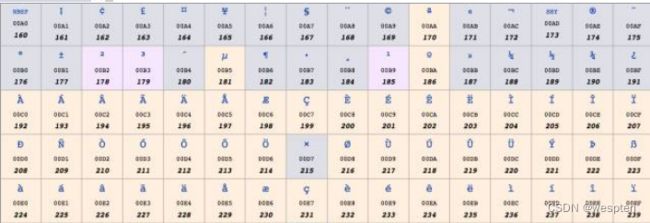
windows-1252
ISO 8859-1虽然号称是标准,用于西欧国家,但它连欧元(€) 这个符号都没有,因为欧元比较晚,而标准比较早。
实际使用中更为广泛的是Windows-1252编码,这个编码与ISO8859-1基本是一样的,区别 只在于数字128到159,Windows-1252使用其中的一些数字表示可打印字符,这些数字表示的含义,如下图所示:

这个编码中加入了欧元符号以及一些其他常用的字符。基本上可以认为,ISO 8859-1已被Windows-1252取代,在很多应用程序中,即使文件声明它采用的是ISO 8859-1编码,解析的时候依然被当做Windows-1252编码。
HTML5 甚至明确规定,如果文件声明的是ISO 8859-1编码,它应该被看做Windows-1252编码。为什么要这样呢?因为大部分人搞不清楚ISO 8859-1和Windows-1252的区别,当他说ISO 8859-1的时候,其实他实际指的是Windows-1252,所以标准干脆就这么强制了。
5、中文字符集
GB2312
美国和西欧字符用一个字节就够了,但中文显然是不够的。中文第一个标准是GB2312。GB2312标准主要针对的是简体中文常见字符,包括约7000个汉字,不包括一些罕见词,不包括繁体字。GB2312固定使用两个字节表示汉字,在这两个字节中,最高位都是1,如果是0,就认为是Ascii字符。在这两个字节中,其中第一个字节范围是1010 0001(十进制161) - 1111 0111(十进制247),第二个字节范围是1010 0001(十进制161) - 1111 1110(十进制254)。
为了方便的查看二进制 和 十进制 和 十六进制的转换 ,可以使用下面的两个方法:
/** 格式化打印:0b1111 -> 二进制: 1111 十进制: 15 十六进制: F */
private static void printFormatFromBinary(int binary) {
System.out.println("二进制: "+Integer.toBinaryString(binary)+" 十进制: "+binary+" 十六进制: "+Integer.toHexString(binary).toUpperCase());
}
/** 格式化打印:0xFF -> 二进制: 11111111 十进制: 255 十六进制: F */
private static void printFormatFromHex(int hex){
System.out.println("二进制: "+Integer.toBinaryString(hex)+" 十进制: "+hex+" 十六进 制: "+Integer.toHexString(hex).toUpperCase());
}GBK
GBK建立在GB2312的基础上,向下兼容GB2312,也就是说,GB2312编码的字符的二进制表示,在GBK编码里是完全一样的。GBK增加了一万四千多个汉字,共计约21000汉字,其中包括繁体字。GBK同样使用固定的两个字节表示,其中第一个字节范围是1000 0001(十进制129) - 1111 1110(十进制254),第二个字节范围是0100 0000(十进制64) - 0111 1110(十进制126)和1000 0000(十进制128) - 1111 1110(十进制254)。
需要注意的是,第二个字节是从64开始的(64属于byte正数范围,和ASCII的编码重合了),也就是说,第二个字节最高位可能为0。那怎么知道它是汉字的一部分,还是一个ASCII字符呢? 其实很简单,因为汉字是用固定两个字节表示的,在解析二进制流的时候,如果第一个字节的最高位为1,那么就将下一个字节读进来一起解析为一个汉字,而不用考虑它的最高位,解析完后,跳到第三个字节继续解析。
GB18030
GB18030向下兼容GBK,增加了五万五千多个字符,共七万六千多个字符。包括了很多少数民族字符,以及中日韩统一字符。用两个字节已经表示不了GB18030中的所有字符,GB18030使用变长编码,有的字符是两个字节,有的是四个字节。
在两字节编码中,字节表示范围与GBK一样。在四字节编码中,第一个字节的值从1000 0001(十进制129) 到11111110(十进制254),第二个字节的值从0011 0000(十进制48)到0011 1001(十进制57),第三个字节的值从1000 0001(十进制129) 到11111110(十进制254),第四个字节的值从0011 0000(十进制48)到0011 1001(十进制57)。
解析二进制时,如何知道是两个字节还是四个字节表示一个字符呢?很简单,看第二个字节的范围,如果是48到57就是四个字节表示,因为两个字节编码中第二字节都比这个大。所以这样综合说明GB18030兼容GBK,兼容GB2312,兼容ASCII,但是GB18030,GBK,GB2312这三个编码和ISO8859-1是不兼容的哦。
Big5
Big5是针对繁体中文的,广泛用于台湾香港等地。Big5包括1万3千多个繁体字,和GB2312类似,一个字符同样固定使用两个字节表示。在这两个字节中,第一个字节范围是10000001(十进制129) 到1111 1110(十进制254),第二个字节范围是0100 0000(十进制64) - 0111 1110(十进制126) 和1010 0001(十进制161) - 1111 1110(十进制254)。Big5和GB18030,GBK,GB2312不兼容哈,如果已经理解了上文,其实你就能理解为什么Big5和GB的三个编码为什么不兼容了。
6、乱码与兼容
ASCII码是基础,一个字节表示,最高位设为0,其他7位表示128个字符。其他编码都是兼容Ascii的,最高位使用1来进行区分。西欧主要使用Windows-1252,使用一个字节,增加了额外128个字符。
中文大陆地区的三个主要编码GB2312,GBK,GB18030,有时间先后关系,表示的字符数越来越多,且后面的兼容前面的,GB2312和GBK都是用两个字节表示,而GB18030则使用两个或四个字节表示。香港台湾地区的主要编码是Big5。
如果文本里的字符都是Ascii码字符,那么采用以上所说的任一编码方式都是一样的,不会乱码。但如果有高位为1的字符,除了GB2312/GBK/GB18030外,其他编码都是不兼容的,比如,Windows-1252和中文的各种编码是不兼容的,即使Big5和GB18030都能表示繁体字,其表示方式也是不一样的,而这就会出现所谓的乱码。
兼容:GB2312/GBK/GB18030 ASCII是兼容的 比如我们文本里面 a字符,使用这四种码表任何一种都是可以正常显示的。
windows-1252和ISO-8859-1和ASCII是兼容的,Big5和ASCII是兼容的,但西欧编码和 Big5 以及 GB系列的编码他们相互之间是不兼容的,也就是同样的码值在三种编码表中显示的内容是不一样的。
乱码:如果编码的时候同一种编码表,而解码的时候通过的却是一种不兼容的编码表,则就就会出现乱码现象。
7、Unicode编码
以上我们介绍了中文和西欧的字符与编码,但世界上还有很多的国家的字符,每个国家的各种计算机厂商都对自己常用的字符进行编码,在编码的时候基本忽略了别的国家的字符和编码,甚至忽略了同一国家的其他计算机厂商,这样造成的结果就是,出现了太多的编码,且互相不兼容。
世界上所有的字符能不能统一编码呢?可以,这就是Unicode。
Unicode 做了一件事,就是给世界上所有字符都分配了一个唯一的数字编号,这个编号范围从0x000000到0x10FFFF,包括110多万。但大部分常用字符都 在0x0000到0xFFFF之间,即65536个数字之内。每个字符都有一个Unicode编号,这个编号一般写成16进制,在前面加U+,大部分中文的编号范围在U+4E00到U+9FA5。
Unicode就做了这么一件事,就是给所有字符分配了唯一数字编号。它并没有规定这个编号怎么对应到二进制表示,这是与上面介绍的其他编码不同的,其他编码都既规定了能表示哪些 字符,又规定了每个字符对应的二进制是什么,而Unicode本身只规定了每个字符的数字编号是多少。
Unicode从1990年开始研发,1994年正式公布。随着计算机工作能力的增强,Unicode也在面世以来的十多年里得到普及。 Unicode6.3版已发布(2013年11月),在Unicode联盟网站上可以查看完整的6.3的核心规范。
Unicode定义了大到足以代表人类所有可读字符的字符集,Unicode其实应该是一个码值表。
Unicode的功用是为每一个字符提供一个唯一的数字码,而对数字码的存储规则的定义则需要依靠UTF-8/UTF-16/UTF-32 UTF-8/UTF-16/UTF-32是通过对Unicode码值进行对应规则转换后,编码保持到内存/文件中,UTF-8/UTF-16都是可变长度的编码方式。
Unicode编码:
字符的unicode编码是其ascii值前加上 &#
中文的unicode编码是其hex编码的 0x 换成 \u
string = input("请输入一个字符: ")
print(string+" 的unicode编码为:",string.encode('unicode_escape').decode('utf-8')) #将字符转换为ascii码值
print("\u4e2d") #将unicode编码转为字符,直接打印即可
那编号怎么对应到二进制表示呢?有多种方案,主要有UTF-32, UTF-16和UTF-8。
UTF-32
这个最简单,就是字符编号的整数二进制形式,四个字节。
但有个细节,就是字节的排列顺序,如果第一个字节是整数二进制中的最高位,最后一个字节是整数二进制中的最低位,那这种字节序就叫“大端”(Big Endian, BE),否则,正好相反的情况,就叫“小端”(Little Endian, LE)。
对应的编码方式分别是UTF-32BE和UTF-32LE。比如:

注意:之所以有大端和小端两种方式,是因为硬件读写顺序的不同。 大端:数据的高字节保存在内存的低地址中,低字节保存到内存的高地址中,和我们的阅读习惯一致;小端则相反,常 用的X86结构是小端模式。采用大端方式进行数据存放符合人类的正常思维,而采用小端方式进行数据存放利于计算机处理。
可以看出,每个字符都用四个字节表示,非常浪费空间,实际采用的也比较少。
注意:UTF-32是因为UTF-16编码方式不能表示全部的字符而扩充的编码方式。
UTF-16
在上面的介绍中,提到了 Unicode 是一本很厚的字典,她将全世界所有的字符定义在一个集合里。这么多的字符不是一次性定义的,而是分区定义。每个区可以存放 65536 个( 2^16 )字符,称为一个平面(plane)。目前,一共有 17 个( 2^5 )平面(65536*17 = 1,114,112 也就是110万),也就是说,整个 Unicode 字符集的大小现在是 2^21 。
最前面的 65536 个字符位,称为基本平面(简称 BMP ),它的码点范围是从 0 到 2^16-1 ,写成 16 进制就是从U+0000 到 U+FFFF。所有最常见的字符都放在这个平面,这是 Unicode 最先定义和公布的一个平面。剩下的字符都放在辅助平面(简称 SMP ),码点范围从U+010000 到 U+10FFFF。基本了解了平面的概念后,再说回到 UTF-16。UTF-16 编码介于 UTF-32 与 UTF-8 之间,同时结合了定长和变长两种编码方法的特点。它的编码规则很简单:基本平面的字符占用 2 个字节,辅助平面的字符占用 4 个字节。也就是说,UTF-16 的编码长度要么是 2 个字节(U+0000 到 U+FFFF,也就是),要么是 4 个字节(U+010000 到U+10FFFF)。
那么问题来了,当我们遇到两个字节时,到底是把这两个字节当作一个字符还是与后面的两个字节一起当作一个字符呢?
为了将两个字节的UTF-16编码与四个字节的UTF-16编码区分开来,Unicode编码的设计者将0xD800-0xDFFF保留下来,并称为代理区(Surrogate):辅助平面的字符位共有 2^20 个,因此表示这些字符至少需要 20 个二进制位。UTF-16 将这 20 个二进制位分成两半,前 10 位映射在 U+D800 到 U+DBFF,称为高代理位(H),后 10 位映射在 U+DC00 到 U+DFFF,称为低代理位(L)。这意味着,一个辅助平面的字符,被拆成两个基本平面的字符表示。

如果U≥0x10000,我们先计算U’=U-0x10000,然后将U’写成二进制形式:yyyy yyyy yyxx xxxx xxxx,U的UTF-16编码(二进制)就是110110yyyyyyyyyy110111xxxxxxxxxx。
按照上述规则,Unicode编码0x10000-0x10FFFF的UTF-16编码有四个字节,前两个字节的高6位是110110,后两个字节的高6位是110111。可见,前两个字节的取值范围(二进制)是11011000 00000000到1101101111111111,即0xD800-0xDBFF。后两个字节取值范围(二进制)是11011100 00000000到11011111 11111111,即0xDC00-0xDFFF。
因此,当我们遇到两个字节,发现它的码点在 U+D800 到 U+DBFF 之间,就可以断定,紧跟在后面的两个字节的码点,应该在 U+DC00 到 U+DFFF 之间,这四个字节必须放在一起解读。
接下来,以汉字""为例,说明 UTF-16 编码方式是如何工作的。
汉字""的 Unicode 码点为 0x20BB7 ,该码点显然超出了基本平面的范围(0x0000 - 0xFFFF),因此需要使用四个字节表示。首先用 0x20BB7 - 0x10000 计算出超出的部分,然后将其用 20 个二进制位表示(不足前面补 0),结果为 0001000010 1110110111 。接着,将前 10 位映射到 U+D800 到 U+DBFF 之间,后 10 位映射到U+DC00 到 U+DFFF 即可。 U+D800 对应的二进制数为 1101100000000000 ,直接填充后面的 10 个二进制位即可,得到 1101100001000010 ,转成 16 进制数则为 0xD842 。同理可得,低位为 0xDFB7 。因此得出汉字""的 UTF-16 编码为 0xD842 0xDFB7 。 和UTF-32一样,UTF-16也有UTF-16LE和UTF-16BE之分,例如:

注意:UTF-16常用于系统内部编码,我们平常说的 “Unicode编码是2个字节” 这句话,其实认的Unicode编码就是UTF-16,在常用基本字符上2个字节的编码方式已经够用导致的误解,其有特殊说明的情况下,常说的Unicode编码可以理解为UTF-16编码,而且是UTF-16BE编码。
UTF-16比UTF-32节省了很多空间,但是任何一个字符都至少需要两个字节表示,对于美国和西欧国家而言,还是很浪费的。
UTF-8
UTF-8就是使用变长字节表示,每个字符使用的字节个数与其Unicode编号的大小有关,编号小的使用的字节就少,编号大的使用的字节就多,使用的字节个数从1到4个不等。
具体来说,各个Unicode编号范围对应的二进制格式如下表所示:

图中的x表示可以用的二进制位,而每个字节开头的1或0是固定的。
小于128的(即0x00-0x7F之间的字符),编码与Ascii码一样,最高位为0。其他编号的第一个字节有特殊含义,最高位有几个连续的1表示一共用几个字节表示,而其他字节都以10开头。4字节模板有21个x,即可以容纳21位二进制数字。Unicode的最大码位0x10FFFF也只有21位。
对于一个Unicode编号,具体怎么编码呢?首先将其看做整数,转化为二进制形式(去掉高位的0),然后将二进制位从右向左依次填入到对应的二进制格式x中,填完后,如果对应的二进制格式还有没填的x,则设为0。
例如 “汉”字的Unicode编码是0x6C49。0x6C49在0x0800-0xFFFF之间,使用3字节模板:1110xxxx 10xxxxxx10xxxxxx。将0x6C49写成二进制是:0110 1100 0100 1001, 用这个比特流依次代替模板中的x,得到:11100110 10110001 10001001,即E6 B1 89。
例如Unicode编码0x20C30在0x010000-0x10FFFF之间,使用4字节模板:11110xxx 10xxxxxx 10xxxxxx 10xxxxxx。将0x20C30写成21位二进制数字(不足21位就在前面补0):0 0010 0000 1100 0011 0000,用这个比特流依次代替模板中的x,得到:11110000 10100000 10110000 10110000,即F0 A0 B0 B0。
注意:UTF-8和UTF-32/UTF-16不同的地方是UTF-8是兼容Ascii的,对大部分中文而言,一个中文字符需要用三个 字节表示。UTF-8的优势是网络上数据传输英文字符只需要1个字节,可以节省带宽资源。所以当前大部分的网络应用都 使用UTF-8编码,因为网络应用的代码编写全部都是使用的英文编写,占据空间小,网络传输速度快。
BOM
我们通常会看到这样的编码 UTF-8和UTF-8+BOM ,那么什么是BOM呢?
比如一个文本软件,在打开一个文件的时候,如何判断这个文件是使用的什么编码呢,该用什么编码进行解码呢?
那么就需要通过BOM(Byte Order Mark)来指明了。
Unicode标准建议用BOM(Byte Order Mark)来区分字节序,即在传输字节流前,先传输被作为BOM的字符“零宽无中断空格”。这个字符的编码是FEFF,而反过来的FFFE(UTF-16)和FFFE0000(UTF-32)在Unicode中都是未定义的码位,不应该出现在实际传输中。
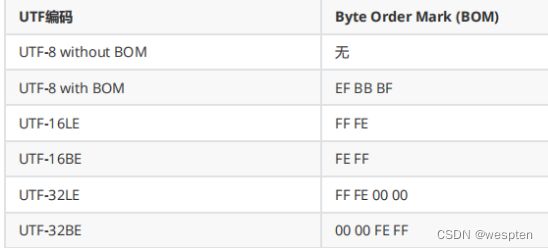
注意:UTF-8不需要BOM来表明字节顺序,但可以用BOM来表明文件是UTF-8的编码方式。根据BOM的规则,在一段字节 流开始时,如果接收到以下字节,则分别表明了该文本文件的编码。而如果不是以BOM开头,那程序则会以ANSI,也就是系统默认编码读取。
总结:
1. 为何要Base64 转码?
不希望一些敏感信息被人直接看见,如秘钥。但是感觉如果进行Base64 解码还是能看见,不明白为啥这么设计。
2. 为何 UTF-8转GB2312?
网络中传输的都是国际标准编码UTF-8格式,而公司底层数据库存的是GB2312编码格式。
3. UTF-8转为 Base64 长度变化?
长度变为 4-8 倍不等:若 1个中文字符是用4字节UTF-8 存储,则Base64 转码后变为8字节;经Base64 转码后 长度变大。
4. UTF-8转为GB2312长度变化?
一个中文字符,4(或3)字节UTF-8,2字节GB2312;UTF-8 转GB2312长度会变短;反之变长。
二、通信中的编码与解码
1、网络数据传输格式
Bytes(字节)才是计算机里真正的数据类型,也是网络数据传输中唯一的数据格式,不要把Bytes(字节)和编程语言里的其它数据类型混淆。
Json、Xml这些格式的字符串最后想传输也都得转成Bytes的数据类型才能通过socket进行传输,而Bytes的数据与字符串类型数据的转换就是编码与解码的转换,utf-8是编解码时指定的格式。
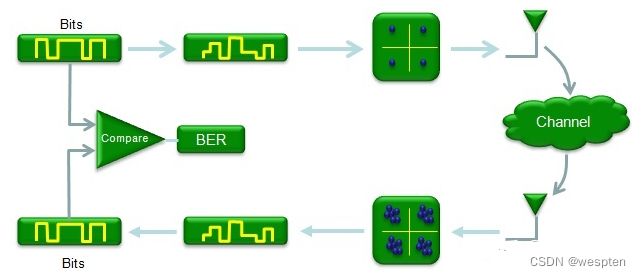
通信系统中,信息在传播之前需要进行编码,通过信道传播后,在接收端再进行解码,如图:
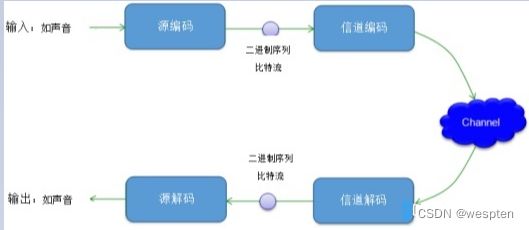
由于无线通信系统中,频谱资源越来越稀缺,所以必须保证整个通信系统高效、稳定的进行交互。
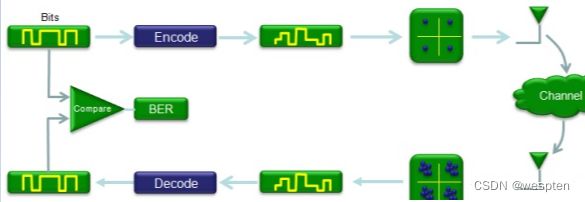
首先看下源编码,这个过程是将原始数据转换成二进制序列的过程,如图:
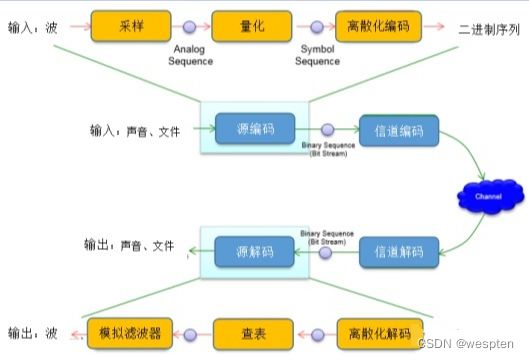
信源编码的另一种定义是将信源数据转换成能够最小化传输数据所需的带宽的形式。简单地说,就是“数据压缩”。
信道编码呢?
信道编码是一种将“原始数据位”替换为“一些其他位(通常比原始位长)”的方法。例如,最简单的编码如下:
0 --> 0000 :将原始数据中的所有“1”替换为“0000‘
1 --> 1111 : 将原始数据中的所有“1”替换为“1111‘
编码的另一个例子是在通信中添加奇偶校验位,原始七位数据-->原始七位数据+一个奇偶校验位。
在通信系统中,通常把“原始数据”称为“消息(message)”,把编码后的数据称为“码字(Codeword)”。在所有的编码过程中,“码字”的长度大于“消息”的长度,这意味着在编码过程中,在原始数据(消息)中增加了一些额外的位,这些额外的位被称为“冗余位”。
这不是降低了效率吗?为什么需要编码呢?
答案是在“信道”上有“噪声”。接收端不能准确的接收到正确的原始数据。
为了解决这个问题,可以考虑两种可能的选择。
- 使信道无噪音。(以无噪音的方式建造信道)
- 使用某种方法检测并纠正错误
第一种选择几乎是不可能的,尤其是在无线通信中。如果是有线通信,至少你可以尝试降低信道中的噪声,但在无线通信中,几乎不可能直接从信道中去除噪声。
这意味着唯一的选择是开发一些方法(算法)来检测和纠正由噪声信道引起的错误。这是“编码”的主要动机。
编码的主要思想是以一种非常特殊的方式(不是以随机/任意的方式)向原始数据中添加一些额外的位(称之为冗余位),以便它们可以用来检测错误的确切位置并进行纠正。
通常编码/解码块的位置如下图所示。编码接收比特流并产生编码比特流。
那编码/解码的增益是多少?是不是可以使接收到的数据很少或几乎没有错误?
以下是编码/解码过程引起的主要问题。
1. ·数据传输开销(由于冗余位)
2. ·使数据传输和接收过程复杂化(由于编码/解码算法)
如前所述,编码是在原始数据中添加一些冗余位,这些冗余位将用于检测和纠正解码过程中的错误。编解码算法有很多种,各有优缺点。因此,在实现编码/解码块时,总是会遇到以下问题。
1. ·必须添加多少位冗余位以最小化冗余位的数量并最大化错误纠正?
2. ·哪种编码/解码算法是最好的。比如5G中的Polar码和LDPC编码
一般来说,添加的冗余位越多,错误检测/纠正能力就越高。但是,添加的冗余位越多,获得的吞吐量就越低,因为传输的位的较大部分应该分配给冗余位,而不是要发送的信息。
3GPP规范规定了编码/解码过程的所有细节,我们只需要执行和学习就够了。
例如,在LTE情况下,3GPP 36.212指定如下所示的编码算法和相关参数。

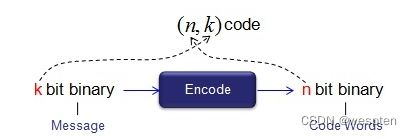
在4、5G网络中,使用了Block Code编码方法,它把整个输入数据流分成小块,用另一小块(码字Codeword)代替小块(消息Message)。
这个过程可以如下图所示。进入编码功能的小块称为“消息”,离开编码功能的小块称为“码字”。也用符号(n,k)来表示这个过程。n是码字(输出)的位数,k是消息(输入)的位数。n总是大于k,这意味着输出(码字)的长度总是大于输入(消息)的长度。
Block Code的一个示例如下图所示。将输入数据流拆分为4位块,并用7位块替换每个块。每个可能的4位块(输入=消息)和7位块(输出=码字)之间的映射表如下图所示。

“线性编码”是指一组代码,其中两个代码在该集合中的任何线性组合产生一个也属于原始集合的代码。假设有一组代码,如下图所示。从集合中取出任意两个代码,取它们的模2求和,结果也是集合的一个成员。

“循环”是一组代码,其中一个代码可以通过该代码集中另一个代码的循环移位来生成。换言之,该集合中一个码的任意数量的循环移位也属于该集合。例如,假设有一个由以下四个代码组成的代码集。如果只查看这些代码中的每一个,这些代码中的任何一个都可以通过另一个代码的循环移位来创建,如下图所示。
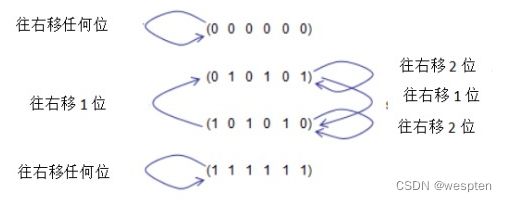
将编码(0110101)循环右移1,得到(10101010),它也是集合的一个成员。
将编码(0110101),循环右移2,得到(0110101),它也是集合的一个成员。
简言之,在这一组不管你用什么代码,不管你做了多少次循环移位,结果总是在原来的集合中。
用一个叫“生成功能”来产生这些编码集,如下图所示。
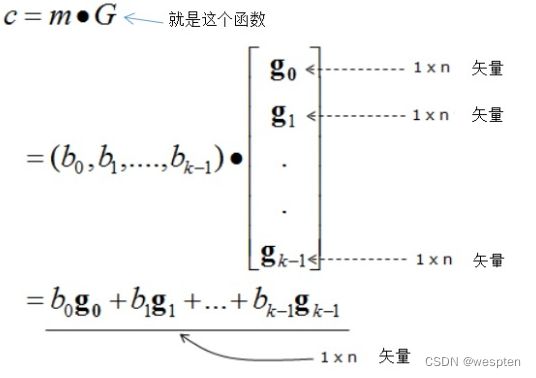
理解上述等式真正含义的最佳方法是举例说明。假设有四个生成函数:
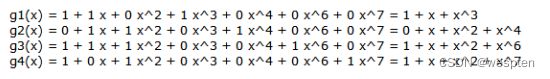
可以将这些方程打包成一个矩阵,如下所示。(注意最低的顺序是最左边的)。
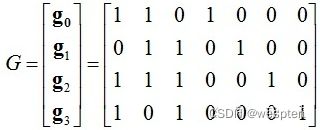
假设有一个m = (1 1 0 1)的消息。
现在,计算出该消息的码字(计算出该消息通过编码器块时的输出位流)。使用生成器函数计算码字的过程如图所示:

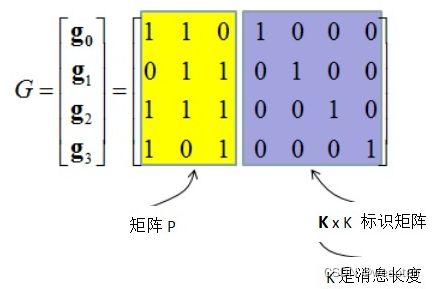
现在看一下生成器函数(生成器矩阵)的高级视图,看看是否有任何可识别的模式。
1. 行数与消息长度相同(消息中的位数)。
2. 矩阵包含k x k单位矩阵,其中k是消息的长度。
如下图所示:
我怎么知道使用哪些生成器函数?
正常情况下,这些功能/矩阵将根据通信系统提供规范。每个无线通信系统都会提供码本以供使用。

2、http请求流程
整体流程图如下图所示:
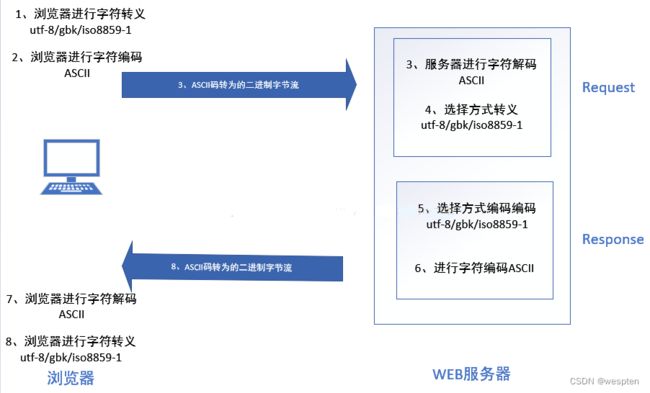
流程说明:
1、字符转义:浏览器对汉字的通过某种编码方式进行url编码转义,转译成为ascii以便下一步。这里就是get post请求涉及到的地方,get肯定url编码转义,post中的urlencode与之类似,formdata猜测应该未转义,json猜测应该url编码;
2、字符编码:浏览器将上一步骤转义的字符按照ascii编码为字节;
3、字符解码:服务器将传输过来的字节按照ascii解码为字符,此步骤web server内部已经帮我们实现;
4、字符反转义:服务器将字符按照utf-8或某种编码方式进行url编码反转义为汉字,此过程中开发常用到request可以自定义字符转义解码方式;
5、字符转义:服务器将响应头字符按照某种编码方式url编码转义,此过程中开发常用response定义url编码,框架中一般默认会自动选择utf-8进行url编码,请求体见步骤6;
6、字符编码:服务器对url编码转义后的响应头,与响应体进行二进制编码,webserver内部实现;
7、字符解码:浏览器对响应头与响应体按照ascii解码为字符;
8、字符反转义:浏览器响应头进行url编码反转义,对响应体查看content-type来进行html解析或者图片解析;3、序列化与反序列化
序列化可以分为本地和网络,对于本地序列化,往往就是将内存中的对象持久化到本地的硬盘,此时序列化做的工作就是将对象和一些对象的相关信息序列化成字符串,然后字符串以某种格式(比如utf-8)进行编码变成bytes类型,存储到硬盘。反序列化就是先将硬盘中的bytes类型中的数据读到内存经过解码变成字符串,然后对字符串进行反序列化解析生成对象。
网络中传输的数据一般为Json和Xml,此时序列化是指将对象变成Json类型的字符串,传输时同样需要将序列化后的字符串变成Bytes类型,反序列化是先将拿到的Bytes类型的数据变成Json类型的字符串(这一步框架往往会帮我们做),然后真正的反序列化是指将Json类型的字符串变成Json类型的对象。(这里注意区分Json类型的字符串和Json类型的对象)
三、C语言实现编码与解码
1、中文字符编码
字符编码有好多种,如果一段文本中有非ASCII字符,就必须得用某一种字符编码来表示,将其保存到文件中也是如此。
现在要打开一个文本文件,文件编辑器(记事本,EditPlus等)必须要知道这个文件采用了何种编码,不然没法解析。如果文件是UTF-8编码存储,却被当作GBK编码来解读,最后展示出来肯定会是乱码。
我们先说Windows操作系统下面的情况,GBK是中文版Windows默认的兼容ASCII码的存储格式,所以GBK编码不用特殊标识。只不过这样的文件放到台湾版或是日本版的系统下面打开会是乱码。UTF-8编码的文件就需要特殊处理一下,Windows会在UTF-8编码的文件前增加3个字节的特殊字符 "EF BB BF” ,这就是常说的BOM,全称叫做"Byte Order Mard”。
只是,BOM是为其他编码准备的,UTF-8带BOM并不合标准,只在Windows阵营下才这么用。由于Windows的影响范围太广,很多文本编辑器都是支持带BOM的UTF-8文本。在Mac和Linux下就不吃这一套,很有可能会出现乱码。大部分编译器也不认,遇到问题会直接编译错误。
我们可以用Windows自带的记事本来存储不同格式的文本并进行比较。打开记事本,输入一段文本,比如就三个字“中国人”,保存时可以指定编码,如下图:

其中ANSI默认就是GBK编码,Unicode和UTF-8分别是相应的编码。而出现的big endian 还有默认的little endian指的存储格式,接下来会再做简单的介绍。弄不明白也没关系,这属于编码中比较边缘的知识,不用急于一时全部搞懂。
保存完后我们来看分别选择ANSI 、 Unicode 和 UTF-8 这三种情况下文件的具体内容,可以用UltraEdit打开看文件看其16进制表示,也可以用Linux下面的xxd工具。
用GBK 编码保存后的文件内容如下:
0000000: d6d0 b9fa c8cb ……可以看到“中国人”三个字的GBK编码分别是“d6 d0”, “b9 fa”, “c8 cb”
用UTF-8编码保存后的文件内容如下:
0000000: efbb bfe4 b8ad e59b bde4 baba …………可以看到“中国人”三个字的UTF-8编码分别是“e4 b8 ad” “e5 9b bd” “e4 ba ba”, 前面多出来的3个字节是BOM。
如果在Mac下面重新保存一个文件,里面的内容是这样的,没有BOM,“0a”是最后多了一个换行符
0000000: e4b8 ade5 9bbd e4ba ba0a ……….用Unicode编码保存后的文件内容如下:
0000000: fffe 2d4e fd56 ba4e ..-N.V.N“中国人”三个字的Unicode编码分别是 “0x4E2D” “0x56FD”, “0x4EBA”
其中fffe代表该文件是little endian存储的,如果是feff,说明是big endian 存储的。
看到这里大家可能又奇怪了,怎么GBK 跟UTF-8的编码跟展示那么对应,Unicode展示出来就高低位互换了呢?
这里要格外注意,GBK和UTF-8的基本单位是byte,是一个字节,编辑器对其解析时是顺序的。我们看到的从左到右在地址空间里面是由低位到高位。“中”的GBK编码就就是0xd6和0xd0两个字节拼起来表示。但Unicode的基本单位是short,也就是两个字节,“中”的Unicode表示是”0x4E2D”, 2D在低位,用little endian存储当然是在左边了。
Mac 下面默认是big endian存储,用Unicode编码保存后的文件内容如下:
0000000: 4e2d 56fd 4eba 000a N-V.N…可以看到2D跑到右边去了。这里最后面的“000a” 是Unicode表示的换行符,其在正常ASCII码的前面增加了8位的0。
再说一下HTML页面,也就是我们平常说的网页。在文件开头有meta标签可以设置charset,这是设置本页面编码的地方,它的值可以为"utf-8”,”gb2312”等。charset一定要在文件开头,在任何非ASCII码出现之前设置好,否则很有可能出现乱码。另外,如果是UTF-8格式存储,BOM是不需要的。有些浏览器碰到带BOM的页面会解析出错。
比如下面这个HTML页面的代码:
标题,请写在charset设置之后
Hello HTML! 这里是Body内容,肯定在charset设置之后!
网络上还有一种XML文件使用的很频繁,其编码的设置跟HTML文件差不多,也是在开头设置encoding。不过对于web开发工程师来说,如果是利用xml实现ajax请求,后台返回给前端的xml数据可以不必太纠结编码,统一用unicode的转义字符来表示就可以了。浏览器自己可以正常解析,这部分内容我们后续再详细介绍。
比如下面这个xml文件,不论encoding设置成gb2312还是utf-8,浏览器都可以正常显示:
只是这种情况如果是程序员写代码来解析的话,最好还是将所使用的编码格式跟charset声明的保持一致。
再说一下内存中的编码。先看一下下面这段C代码:
#include
#include
int main(){
int i=0;
char str[100] = "中国人";
int len = strlen(str);
printf("the length of str is %d\n", len);
for (i=0; i 编译后执行,看看输出结果是啥。当然结果是未知的,因为常见的会有以下两种情况:
第一种:
the length of str is 6
D6 D0 B9 FA C8 CB第二种:
the length of str is 9
E4 B8 AD E5 9B BD E4 BA BA之所以会出现这两种情况,就是因为str所指向的字符串其内容受源代码文件的编码格式影响,如果是以gbk编码保存,则执行结果是第一种情况,如果是用utf-8编码保存,就是第2种情况。
为了使编码固定,可以在定义时明确编码,比如我就是想定义一个utf8格式的编码,可以这么定义:
char str[100] = "\xe4\xb8\xad\xe5\x9b\xbd\xe4\xba\xba”; 这种方式跟第二种方式是一模一样的,除了阅读不方便之外,编译之后对于计算机而言没有任何区别。
2、Unicode与UTF-8转换
Unicode和UTF-8之间的转换关系表:

以上表格摘自维基百科,该表格记录了UCS-4 与UTF-8的对应关系。上面的x表示我们可以编码的位。这个表记录的内容太多,我们平常使用只需要前三行,也就是UCS-2的表示范围。这基本可以表示我们国际上通用的所有文字和特殊符号了。
再来解释一下UTF-8编码字节含义:
对于UTF-8编码中的任意字节B,如果B的第一位为0,则B为ASCII码,并且B独立的表示一个字符;
如果B的第一位为1,第二位为0,则B为一个非ASCII字符(该字符由多个字节表示)中的一个字节,并且不为字符的第一个字节编码;
如果B的前两位为1,第三位为0,则B为一个非ASCII字符(该字符由多个字节表示)中的第一个字节,并且该字符由两个字节表示;
如果B的前三位为1,第四位为0,则B为一个非ASCII字符(该字符由多个字节表示)中的第一个字节,并且该字符由三个字节表示;
有了这层对应关系,Unicode到utf-8的转化代码就不难实现了,以下是我用c实现的,经多年线上验证没有问题。
typedef char T_GB;
typedef unsigned short T_UC;
typedef unsigned char T_UTF8;
/*!
* \brief UCS-2编码文本转换为UTF-8编码文本
* \param[in] puc: UCS-2字符串的地址
* \param[in] nuclen: UCS-2字符串的长度
* \param[out] putf8: 输出的UTF-8字符串的地址
* \param[in] nutf8len: 最大可以允许的UTF-8字符串的长度,如果nutf8len>6) | 0xC0;
*utf8bpos++ = (*ucbpos++ & 0x3F) | 0x80;
}
else
{
if (utf8epos-utf8bpos < 3)
{
break;
}
*utf8bpos++ = ((*ucbpos&0xF000)>>12) | 0xE0;
*utf8bpos++ = ((*ucbpos&0x0FC0)>>6) | 0x80;
*utf8bpos++ = ((*ucbpos++&0x3F)) | 0x80;
}
}
return (utf8bpos-putf8);
}
/*!
* \brief UTF-8编码文本转换为UCS-2编码文本
* \param[in] putf8: UTF-8字符串的地址
* \param[in] nutf8len: UTF-8字符串的长度
* \param[out] puc: 输出的UCS-2字符串的地址
* \param[in] nuclen: 最大可以允许的UCS-2字符串的长度,如果nuclen 那么Unicode和GBK编码之间如何转换呢?因为Unicode和GBK之间没有算法上面的对应关系,只能通过查表来转换。在Linux下面有iconv族函数,可以辅助完成这一操作。以下是c++的实现代码。
template
static int csconv(iconv_t tID, const _CS1* pcs1, size_t nlen1, _CS2* pcs2, size_t nlen2)
{
size_t nleft1 = nlen1*sizeof(_CS1);
size_t nleft2 = nlen2*sizeof(_CS2);
char* cpcs1 = (char*)pcs1;
char* cpcs2 = (char*)pcs2;
size_t nConv = iconv(tID, &cpcs1, &nleft1, &cpcs2, &nleft2);
if (nConv==(size_t)-1)
{
return -1;
}
return (nlen2-nleft2/sizeof(_CS2));
}
int uc2gb(const T_UC* puc, size_t nuclen, T_GB* pgb, size_t ngblen){
iconv_t tID = iconv_open("GBK", "UCS-2");
int len = csconv(m_tID, puc, nuclen, pgb, ngblen);
iconv_close(tID);
return len;
}
int gb2uc(const T_GB* pgb, size_t ngblen, T_UC* puc, size_t nuclen){
iconv_t tID = iconv_open("UCS-2", "GBK");
int len = csconv(m_tID, pgb, ngblen, puc, nuclen)
iconv_close(tID);
return len;
} 因为Unicode与GBK表示的字符集不一样大,所以有很多Unicode字符没有办法转化成GBK编码。反过来就好多了,绝大多数GBK字符都可以正常转换为Unicode字符。这里没有说全部的GBK字符,是因为又有特殊情况,不过这个情况不用太关注,可以简单的认为所有的GBK字符都能正常转换。
至于其他平台的转换方法,php有类似的iconv函数,Java中就更简单了:
String gbk = new String(unicode.getBytes("GBK")); 当然,我们还可以用最原始的方法,就是自己实现查表的功能。不过查表法费力不讨好,建议不用。
有了Unicode和UTF-8的转换,加上Unicode与GBK之间的转换,那么UTF-8和GBK之间的转换只需要用Unicode做一层中转就好了。
3、转义
1. 为什么要转义
以C语言做例子,我想声明一个char字符,该字符表示一个换行。但ASCII码中没有表示换行的文字符号,所以必须用转义字符来表示。于是我们可以这样定义:
char c1=‘\n’;其中’\n’ 用两个ASCII码字符表示了一个换行符。编译器在遇到反斜杠时,会将其与后面的字符合在一起当作一个字符来处理。
再一种情况,这次我想声明的char字符表示一个单引号(‘)。但是在C语言中单引号是有特殊含义的,两个单引号之间是一个字符。如果中间再加一个单引号,那么编译器就没法正确理解这几个单引号的含义。所以,我们需要如下定义:
char c2=‘\’’;编译器遇到的第一个单引号是C语法字符,遇到的第二个单引号因为是在反斜杠之后,会被编译器认定是真正的单引号,遇到的第三个单引号同第一个一样,是C语法字符。
第三种情况,因为ASCII码只能表示0-127的字符,那大于128的字符如何表示呢?比如大小为255的字符我么可以这么表示:
char c3=‘\xff’;现在我们来总结使用转义字符的原因,主要是有两个:
1,有些字符没有文字字符表示,比如ASCII中的空字符、换行符等,还有些字符超出了ASCII码的范围,即那些大于128的字符,这些字符需要用转义字符来表示。
2,某些特定字符在编程语言中有特殊用途,在这些编程语言中就失去了字符原有的含义。如C语言中的引号,HTML中的<等。
2. 何时转义
转义的目的有两个:
1) 通过转义字符来表示无法表示的内容。
2) 通过转义将原本的字符意义改变。在实际使用中处于安全考虑会做。如在执行SQL语句时,若某些数据是外来输入,则需要将这些数据进行转义,以防止注入攻击。
转义操作发生在输入时。为了让输入内容本义改变而做转义操作。实际使用中很多需要在输出时做转义,但这些输出也只是为了成为别人的输入。
3. 如何转义
这里我拿web中最常用的三个转义方法来做例子,分别是escape,encodeURI,encodeURIComponent。在此我们用C语言来实现这几个方法,达到对其完全理解的目的。
这三个方法是在web开发中最常用的对字符串编码的函数,均是将特殊字符转换成为%xx格式的编码(xx等于该字符的16进制编码),但还是有些不太一样。
encodeURI,encodeURIComponent:将非ASCII码转为UTF-8格式,然后特殊字符用16进制表示。特殊字符是非ASCII码以及ASCII码中需要转义的字符。两者的区别是字符集的不同。前者比后者要少一点。
escape:先将ASCII码转为UCS-2格式,然后特殊字符用16进制表示。
非ASCII码肯定是需要转义的字符,ASCII码中的待转义字符可以利用Javascript来辅助找到。在Shell中通过以下命令可以得到判断128个ASCII码是否为待转义字符的Javascript代码:
awk 'BEGIN{for(i=0;i<8;i++){for(j=0;j<16;j++){printf("%X\n", i*16+j)}}}' | awk '{p="";if(NR<=16)p="0";printf("console.log(\"%s\",escape(\"\\x%s%s\")==\"\\x%s%s\");\n",$1, p, $1, p, $1)}'可以得到128行代码:
console.log("0",escape("\x00")=="\x00");
console.log("1",escape("\x01")=="\x01");
console.log("2",escape("\x02")=="\x02");
console.log("3",escape("\x03")=="\x03");
console.log("4",escape("\x04")=="\x04");
console.log("5",escape("\x05")=="\x05");
console.log("6",escape("\x06")=="\x06");
console.log("7",escape("\x07")=="\x07");
console.log("8",escape("\x08")=="\x08");
console.log("9",escape("\x09")=="\x09");
console.log("A",escape("\x0A")=="\x0A");
console.log("B",escape("\x0B")=="\x0B");
console.log("C",escape("\x0C")=="\x0C");
console.log("D",escape("\x0D")=="\x0D");
console.log("E",escape("\x0E")=="\x0E");
console.log("F",escape("\x0F")=="\x0F");
…在Chrome下面打开控制台,执行以上代码,可以得到如下:
0 false
1 false
2 false
3 false
4 false
5 false
…其中false代表需要转义的字符,true代表无需转义的字符,这样我就可以得到128个字符中转义成%XX的字符数了。当然为了保险起见,这些被转义的字符是否真的变成%XX,还可以通过这条命令的结果在Javascript中验证一下:
awk 'BEGIN{for(i=0;i<8;i++){for(j=0;j<16;j++){printf("%X\n", i*16+j)}}}' | awk '{p="";if(NR<=16)p="0";printf("if(escape(\"\\x%s%s\")!=\"\\x%s%s\")console.log(\"%s\", escape(\"\\x%s%s\")==\"%%%s%s\");\n", p, $1, p, $1, $1, p, $1, p, $1)}’经检验,与我们开始的判断完全吻合,大家可以自己试一下。现在,我们用CPP代码来实现escape:
/*!
* \brief 将UCS-2编码文本转义
* \param[in] sUCValue: sUCValue UCS2格式字符串
* \return string 转换后的字符串
*/
std::string escape(const std::string& sUCValue)
{
const static bool s_esc[256] =
{
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 0,
1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1
};
const T_UC* bpos = (T_UC*)&sUCValue[0];
const T_UC* epos = bpos + (sUCValue.size()/sizeof(T_UC));
std::string sValue = __encodeBase(s_esc, bpos, epos, "%", "%u", "");
return sValue;
}其中__encodeBase的实现如下:
char* ITOX2(int x, char vx[2])
{
static char MAPX[16] = { '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'A', 'B', 'C', 'D', 'E', 'F' };
vx[0] = MAPX[(unsigned char)x>>4];
vx[1] = MAPX[x&0x0F];
return vx;
}
char* ITOX4(int x, char vx[4])
{
ITOX2((unsigned short)(x&0xFF00)>>8, vx);
ITOX2(x&0xFF, vx+2);
return vx;
}
std::string __encodeBase(const bool esc[256], const T_UC* bpos, const T_UC* epos, const char* prefix2, const char* prefix4, const char* subfix)
{
int bSize2 = strlen(prefix2);
int bSize4 = strlen(prefix4);
int eSize = strlen(subfix);
char v2[16] = {0};
char v4[16] = {0};
char* p2 = v2+bSize2;
char* p4 = v4+bSize4;
memcpy(v2, prefix2, bSize2);
memcpy(v4, prefix4, bSize4);
memcpy(p2+2, subfix, eSize);
memcpy(p4+4, subfix, eSize);
int s2 = bSize2+2+eSize;
int s4 = bSize4+4+eSize;
std::string sValue((bSize4+eSize+4)*(epos-bpos), 0);
char* tpos = &sValue[0];
while (bpos < epos)
{
if (*bpos & 0xff00)
{
ITOX4(*bpos, p4);
memcpy(tpos, v4, s4);
tpos += s4;
++bpos;
}
else if (esc[*bpos & 0xff])
{
ITOX2(*bpos, p2);
memcpy(tpos, v2, s2);
tpos += s2;
++bpos;
}
else
{
*tpos++ = *bpos++;
}
}
sValue.resize(tpos - &sValue[0]);
return sValue;
}同理我们来实现encodeURIComponent。先得到表示256个字符是否需要转义的状态map,通过以下结果得到Javascript代码:
awk 'BEGIN{for(i=0;i<8;i++){for(j=0;j<16;j++){printf("%X\n", i*16+j)}}}' | awk '{p="";if(NR<=16)p="0";printf("console.log(\"%s\",encodeURIComponent(\"\\x%s%s\")==\"\\x%s%s\");\n",$1, p, $1, p, $1)}'CPP代码实现:
/*!
* \brief 将UTF-8编码文本转义
* \param[in] sData: utf-8格式字符串
* \return string 转换后的字符串
*/
std::string encodeURIComponent(const std::string& sData)
{
const static bool s_esc[256] =
{
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 0, 1, 1, 1, 1, 1, 0, 0, 0, 0, 1, 1, 0, 0, 1,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1,
1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 0,
1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1
};
std::string sValue;
sValue.reserve(sData.size() * 4);
T_UTF8 *bpos = (T_UTF8*)&sData[0];
T_UTF8 *epos = bpos + sData.size();
while (bpos两者对应的decode函数分别如下:
/*!
* \brief 将文本解码成utf-8
* \param[in] sData, URIComponent之后的字符串
* \return string 转换后的字符串,utf-8格式
*/
std::string decodeURIComponent(const std::string& sData)
{
std::string sResult = sData;
int x, y;
for (x = 0, y = 0; sData[y]; x++, y++)
{
if((sResult[x] = sData[y]) == '%')
{
sResult[x] = x2c(&sData[y+1]);
y += 2;
}
}
return sResult.substr(0, x);
}
/*!
* \brief 将文本解码成unicode
* \param[in] sData, escape之后的字符串
* \return string 转换后的字符串,unicode格式
*/
std::string unescape(const std::string& sData)
{
struct HEX
{
static bool isHex(T_UC ch)
{
return (ch>='0' && ch<='9' || ch>='A' && ch<='F' || ch>='a' && ch<='f');
}
};
std::string sUCValue = UCS2(sData);
std::string sValue(sUCValue.size(), 0);
T_UC *ucbpos = (T_UC *)&sUCValue[0];
T_UC *ucepos = ucbpos + sUCValue.size()/sizeof(T_UC);
T_UC *ucbResult = (T_UC *)&sValue[0];
#define HEXUCTOI(uc) ((uc >= 'a')? (uc - 'a' + 10) : (uc >= 'A') ? (uc - 'A' + 10) : (uc - '0'))
while (ucbpos < ucepos)
{
if (*ucbpos != 0x25) // %
{
*ucbResult++ = *ucbpos++;
}
else if((*(ucbpos+1)=='u' || *(ucbpos+1)=='U') && (ucepos>ucbpos+5) && HEX::isHex(*(ucbpos+2)) && HEX::isHex(*(ucbpos+3)) && HEX::isHex(*(ucbpos+4)) && HEX::isHex(*(ucbpos+5)))
{
*ucbResult++ = (HEXUCTOI(*(ucbpos+2))<<12) | (HEXUCTOI(*(ucbpos+3))<<8) | (HEXUCTOI(*(ucbpos+4))<<4) | (HEXUCTOI(*(ucbpos+5)));
ucbpos=ucbpos+6;
}
else if ((ucepos>ucbpos+2) && HEX::isHex(*(ucbpos+1)) && HEX::isHex(*(ucbpos+2)) )
{
*ucbResult++ = (HEXUCTOI(*(ucbpos+1))<<4) | (HEXUCTOI(*(ucbpos+2)));
ucbpos=ucbpos+3;
}
else
{
*ucbResult++ = *ucbpos++;
}
}
sValue.resize((ucbResult-(T_UC *)&sValue[0])*sizeof(T_UC));
return sValue;
}4、JSON字符转义
在Javascript中的字符有多种表达形式:
1,ASCII码的8进制转义,16进制转义,比如换行符可以用”\x0A” 和 “\12” 表示 。
2,ASCII码里面特殊字符的转义,比如换行符还可以用”\n” 表示。
3,从开发者角度来看,Javascript中的所有字符都是Unicode字符,所以换行符还可以用”\u0012”来表示,其中0012是换行符的Unicode编码。
如果涉及到中文的处理,会发现如果统一采用第3种方式来对字符编码,会消除非ASCII码对编码环境的要求。
Javascript中有个方法JSON.stringify可以起到一定的辅助作用,帮助我们找到需要编码的字符。首先用shell命令得到JavaScript代码:
awk 'BEGIN{for(i=0;i<8;i++){for(j=0;j<16;j++){printf("%X\n", i*16+j)}}}' | awk '{p="";if(NR<=16)p="0";printf("console.log(\"%s\",\"\\x%s%s\", JSON.stringify(\"\\x%s%s\"));\n",$1, p, $1, p, $1)}’得到结果,我们发现有些字符被转化为“\uxxxx”的格式,有些没有。我们的实现也按照这一规则。当然那些没有变成这样格式的字符我们也可以如此表示,但为了可读性以及节省输出字符的长度,我们还是用其他方式来表示。
其中,退格键(0x08,\b),制表符(0x09,\t),换行符(0x0a,\n),回车(0x0d,\r),换页符(0x0c,\f),双引号(0x22,“),反斜杠(0x5c,\)这7个符号需要特殊处理,其他的都不做处理。这几个字符处理完之后在我们的map中相对应的位置设置为0或是1都没有影响。其他字符在0x00-0x1F内的转为\uxxxx格式,在0x20-0x7F内的字符不做处理。在0x80-0x7F内的字符原则上可以不做处理,这里为了防止在其他平台上解析出问题,统一转为\uxxxx格式。
代码实现如下:
std::string CXCode::encodeJSONComponent(const std::string& sData)
{
std::string sUCValue = UCS2(sData);
T_UC* bpos = (T_UC*)&sUCValue[0];
const T_UC* epos = bpos + (sUCValue.size()/sizeof(T_UC));
T_UC * tUC = new T_UC[sData.size() * 4];
T_UC * ptUC = tUC;
while (bpos < epos)
{
if (*bpos == '\\' || *bpos== '\"' )
{
*ptUC++ = '\\';
*ptUC++ = *bpos;
}
else if (*bpos == '\n')
{
*ptUC++ = '\\';
*ptUC++ = 'n';
}
else if (*bpos == '\r')
{
*ptUC++ = '\\';
*ptUC++ = 'r';
}
else if (*bpos == '\b')
{
*ptUC++ = '\\';
*ptUC++ = 'b';
}
else if (*bpos == '\f')
{
*ptUC++ = '\\';
*ptUC++ = 'f';
}
else if (*bpos == '\t')
{
*ptUC++ = '\\';
*ptUC++ = 't';
}
else
{
*ptUC++ = *bpos;
}
++bpos;
}
bpos = tUC;
epos = ptUC;
const static bool s_esc[256] =
{
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1
};
std::string sValue = __encodeBase(s_esc, bpos, epos, "\\u00", "\\u", "");
if (tUC != NULL)
{
delete[] tUC;
}
if (CXCode::GetCharSet()==CXCode::CHARSET_UCS2)
{
CXCode x2(CXCode::CHARSET_UTF8);
return UCS2(sValue);
}
return sValue;
}再来看xml和html,他们两者都有表示转义字符的方法:实体名字和实体编号。比如“<”,用实体名字表示就是“<”用实体编号表示是“<”。当然实体编号还可以用16进制表示为“<”
用实体(Entity)名字的好处是比较好理解,但是其劣势在于并不是所有的浏览器都支持最新的Entity名字。而实体(Entity)编号,各种浏览器都能处理。
我们这里为了兼容性,统一用实体编号来进行转义。
xml中有几个字符必须要转义,他们是 & < > " ' ,在HTML中还有个空格。他们的实体名字和16进制编码分别为:
& & 0x26
< < 0x3C
> > 0x3E
“ " 0x22
‘ ' 0x27
0x20除了这几个符号之外,其他的符号理论上来说不需要做特殊处理。但是有些不可见字符,还有回车换行符等,最好还是转义一下,反正转义多了不会出错,只会带来人眼识别上的困难。所以最终我们的代码实现如下:
std::string encodeXMLComponent(const std::string& sData)
{
const static bool s_esc[256] =
{
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 0,
1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1
};
std::string sUCValue = UCS2(sData);
T_UC* bpos = (T_UC*)&sUCValue[0];
const T_UC* epos = bpos + (sUCValue.size()/sizeof(T_UC));
while (bpos < epos)
{
if (*bpos < 32 && *bpos!=13 && *bpos!=10)
{
*bpos = T_UC('?');
}
++bpos;
}
bpos = (T_UC*)&sUCValue[0];
std::string sValue = __encodeBase(s_esc, bpos, epos, "&#x", "&#x", ";");
return sValue;
}四、Java实现编码与解码
1、Jsp/Servlet编码
在jsp/servlet中主要有以下几个地方可以设置编码:
-
pageEncoding="UTF-8"
- 设置jsp编译成servlet时使用的编码
- 例如:jsp文件保存为gbk格式,pageEncoding="UTF-8"时servlet会出现乱码
- JSP中不指定contentType参数,不使用response.setCharacterEncoding方法时,指定对服务器响应进行重新编码的编码
-
response
需要设置转换成传输流的编码方式及浏览器的解码方式。
服务器发给浏览器的数据默认是按照ISO-8859-1编码,浏览器接收到数据后按照默认的字符集进行解码后显示,如果浏览器的默认解码字符集不是ISO-8859-1,就出现乱码。ISO-8859-1不支持中文即传输中文必须采用其他传输方式,否则为乱码。
-
response.setCharacterEncoding("utf-8”);
设置服务器端的编码,默认是ISO-8859-1;该方法必须在response.getWriter()之前进行设置,如果设置了Content-Type字段,response.setCharacterEncoding方法设置的字符集编码会出现在Http消息的响应头中,会要求浏览器使用utf-8进行解码response.setHeader("Content-Type", "text/html; ");或response.setHeader("Content-Type", "text/html;");
通知浏览器服务器发送的数据格式是text/html,并要求浏览器使用utf-8进行解码。 -
response.setContentType("text/html;charset=utf-8”);或response.setHeader("Content-Type", "text/html; charset=utf-8”);
它其实会覆盖response.setCharacterEncoding("utf-8”) ,在开发中只需要设置response.setContentType("text/html;charset=utf-8”)就可以了。意思是通知浏览器服务器发送的数据格式是text/html,服务器采用utf-8编码,并要求浏览器使用utf-8进行解码。 -
response.setCharacterEncoding("utf-8”);
设置服务器端的编码为utf-8response.getWriter().println("”);
要求浏览器使用utf-8进行解码,按照整个html格式编写,写在head中。
可以看出,第二种方式是最简便的,这也是我们在开发中最常使用的方式。setCharacterEncoding优先权比setContentType及setLocale()节点要高
-
-
request
会涉及到URL编程,参考url编码
在服务器端,通过request.setCharacterEncoding("utf-8”)即可设置服务器的解码为utf-8(默认是ISO-8859-1),但是它只对请求体里面的参数有效;如果参数跟在请求行中的uri后边,它就无能为力了。因此请求方式不同,解决乱码的方案也不同。
-
在地址栏直接输入URL访问
编码方式由浏览器决定,RFC 3986协议强制要求转换为UTF-8,为了方便处理,通过超链接和表单的访问也规定必须是utf-8格式,即显示当前页面的编码也要使用utf-8,这样浏览器将统一使用utf-8对参数进行编码
-
点击页面中的超链接访问
将参数按照当前页面的显示编码进行编码,RFC 3986协议强制要求转换为UTF-8。
-
提交表单访问
将参数按照当前页面的显示编码进行编码。
-
解决方案:
1)post请求
post方式属于表单提交,参数存在于请求体中,通过request.setCharacterEncoding("utf-8”)即可解决乱码。
2)get方式
get方式提交的参数会跟在请求行中的uri后边,服务器按照默认的iso-8859-1进行解码,这时候解决乱码有两种办法:
1、修改服务器端对uri参数的默认编码
在tomcat的server.xml中,设置
注意:
1)设置
2)通过修改server.xml指定服务器对get和post统一按照utf-8解码,要求tomcat管理下的所有web应用都要使用utf-8编码,即所有的jsp、html页面都使用utf-8编码。比如 JSP页面的头信息是这样的:
<%@ page language="java" contentType="text/html; charset=utf-8" pageEncoding="utf-8"%>2、参数从浏览器到服务器,经过客户端utf-8编码,服务器端iso-8859-1解码,最终成为乱码。那我们将乱码进行相反的编解码,即可得到正常的参数值。
例如:
String name = request.getParameter("name”);//得到乱码
name = new String(name.getBytes("iso-8859-1"),"utf-8”);//得到正常的name值注意:name.getBytes();如果不指定编码,默认按照gb2312进行编码。
2、Java编码器
编码器操作出站数据,而解码器处理入站数据。编码器是将消息转换为适合于传输的格式,而对应的解码器则是将网络字节流转换回应用程序的消息格式。
解码器
1)将字节解码为消息:ByteToMessageDecoder、ReplayingDecoder
2)将一种消息类型解码为另外一种:MessageToMessageDecoder
因为解码器是负责将入站数据从一种格式转换到另外一种格式,所以Netty的解码器实现了ChannelInboundHandler。每当需要为ChannelPipeline中的下一个ChannelInboundHandler转换入站数据是会用到,此外可以将多个解码器连接在一起,以实现复杂的转换逻辑。
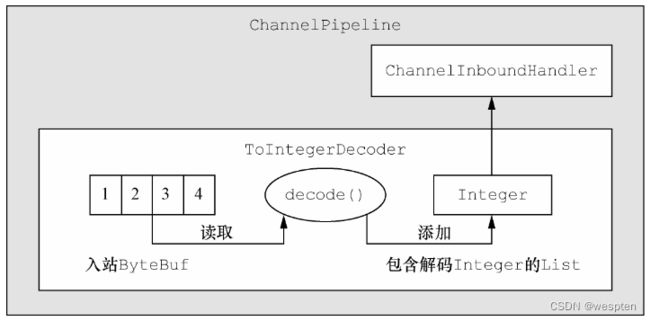
// 扩展ByteToMessageDecoder类,以将字节解码为特定格式
public class ToIntegerDecoder extends ByteToMessageDecoder{
@override
public void decode(ChannelHandlerContext ctx, ByteBuf in, List编码器
1)MessageToByteEncoder
2)MessageToMessageEncoder+encode(ChannelHandlerContext ctx, I msg, ByteBuf out)
encode()方法是你需要实现的唯一抽象方法。它被调用时将会传入要被该类编码为 ByteBuf 的(类型为 I 的)出站消息。该 ByteBuf 随后将会被转发给 ChannelPipeline中的下一个ChannelOutboundHandler。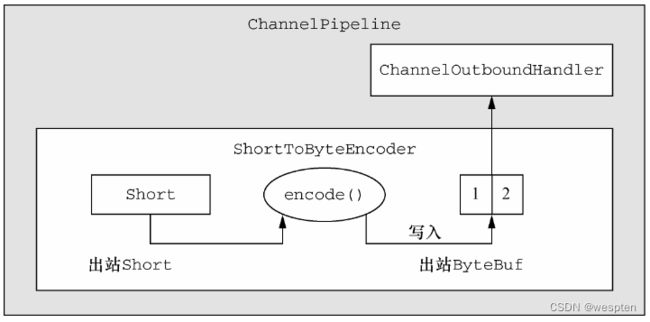
public class ShortToByteEncoder extends MessageToByteEncoder{
@override
public void encode(ChannelHandlerContext ctx, Short msg, ByteBUf out) throws Exception{
// 将Short写入ByteBuf中
out.writeShort(msg);
}
} 预置的ChannelHandler和编解码器
1. Http编解码器
Http请求的组成部分:
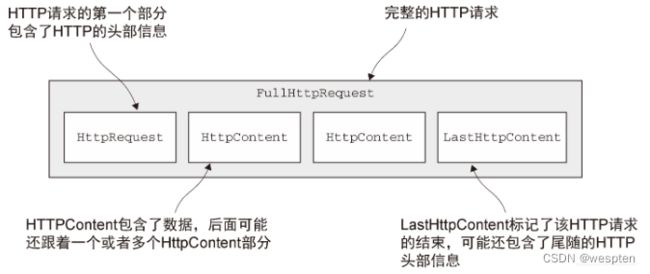
Http响应的组成部分:
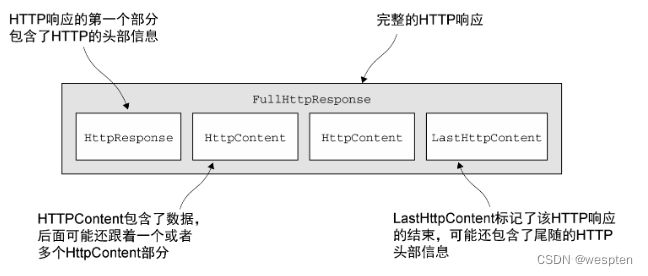
一个 HTTP 请求/响应可能由多个数据部分组成,并且它总是以一个 LastHttpContent 部分作为结束。 FullHttpRequest 和 FullHttpResponse 消息是特殊的子类型,分别代表了完整的请求和响应。所有类型的 HTTP 消息( FullHttpRequest、LastHttpContent )都实现了 HttpObject 接口。

import io.netty.channel.Channel;
import io.netty.channel.ChannelInitializer;
import io.netty.channel.ChannelPipeline;
import io.netty.handler.codec.http.*;
public class HttpPiplineInitialize extends ChannelInitializer {
private final boolean client;
public HttpPiplineInitialize(boolean client){
this.client = client;
}
@Override
protected void initChannel(Channel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
if (client){
// 如果是客户端,则添加HttpResponseDecoder 以处理来自服务器的响应
pipeline.addLast("decoder", new HttpResponseDecoder());
// 如果是客户端,则添加 HttpRequestEncoder 以向服务器发送请求
pipeline.addLast("encoder", new HttpRequestEncoder());
// 一种聚合器写法:
/*pipeline.addLast("codec", new HttpClientCodec());*/
} else {
// 如果是服务器,则添加 HttpResponseEncoder 以向客户端发送响应
pipeline.addLast("decoder", new HttpRequestDecoder());
// 如果是服务器,则添加 HttpRequestDecoder 以接收来自客户端的请求
pipeline.addLast("encoder", new HttpResponseEncoder());
// 一种聚合器写法
/* pipeline.addLast("codec", new HttpServerCodec());*/
}
}
} 2. WebSocket
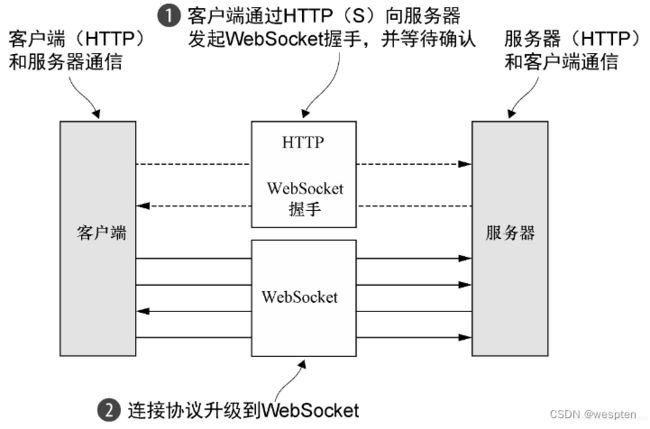
WebSocket解决了一个长期存在的问题:既然底层的协议( HTTP) 是一个请求/响应模式的交互序列,那么如何实时地发布信息呢? AJAX提供了一定程度上的改善,但是数据流仍然是由客户端所发送的请求驱动的。
WebSocket提供了“在一个单个的TCP连接上提供双向的通信……结合WebSocket API……它为网页和远程服务器之间的双向通信提供了一种替代HTTP轮询的方案。”WebSocket 现在可以用于传输任意类型的数据, 很像普通的套接字。
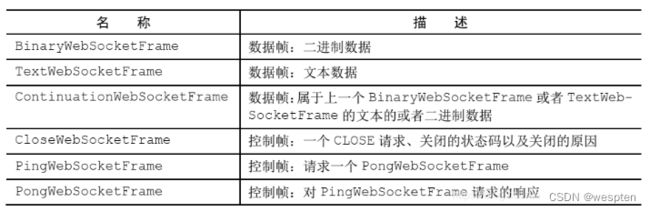
展示了一个使用WebSocketServerProtocolHandler的简单示例,这个类处理协议升级握手,以及 3 种控制帧——Close、 Ping和Pong。 Text和Binary数据帧将会被传递给下一个(由你实现的) ChannelHandler进行处理。
import io.netty.channel.Channel;
import io.netty.channel.ChannelHandlerContext;
import io.netty.channel.ChannelInitializer;
import io.netty.channel.SimpleChannelInboundHandler;
import io.netty.handler.codec.http.HttpObjectAggregator;
import io.netty.handler.codec.http.HttpServerCodec;
import io.netty.handler.codec.http.websocketx.BinaryWebSocketFrame;
import io.netty.handler.codec.http.websocketx.ContinuationWebSocketFrame;
import io.netty.handler.codec.http.websocketx.TextWebSocketFrame;
import io.netty.handler.codec.http.websocketx.WebSocketServerProtocolHandler;
public class WebSocketServerInitializer extends ChannelInitializer {
@Override
protected void initChannel(Channel channel) throws Exception {
channel.pipeline().addLast(
// 为握手提供聚合的HttpRequest
new HttpServerCodec(),
new HttpObjectAggregator(65535),
// 如果被请求的端点是“/webSocket"则处理该升级握手
new WebSocketServerProtocolHandler("/websocket"),
// 处理TextWebSocketFrame
new TextFrameHandler(),
// 处理BinaryWebSocketFrame
new BinaryFrameHandler(),
// 处理ContinuationWebSocketFrame
new ContinuationFrameHandler()
);
}
public static final class TextFrameHandler extends SimpleChannelInboundHandler{
@Override
protected void channelRead0(ChannelHandlerContext channelHandlerContext, TextWebSocketFrame textWebSocketFrame) throws Exception {
// 处理TextWebSocketFrame
}
}
public static final class BinaryFrameHandler extends SimpleChannelInboundHandler{
@Override
protected void channelRead0(ChannelHandlerContext channelHandlerContext, BinaryWebSocketFrame textWebSocketFrame) throws Exception {
// 处理BinaryWebSocketFrame
}
}
public static final class ContinuationFrameHandler extends SimpleChannelInboundHandler{
@Override
protected void channelRead0(ChannelHandlerContext channelHandlerContext, ContinuationWebSocketFrame textWebSocketFrame) throws Exception {
// 处理ContinuationWebSocketFrame
}
}
} 3、Java中文编码
1. charAt 与 codePonitAt
我们知道 Java 内部使用的是 utf-16 作为它的 char、String 的字符编码方式,这里我们叫它内部字符集。而 utf-16 是变长编码,一个字符的编码被称为一个 code point,它可能是 16 位 —— 一个 code unit,也可能是 32 位 —— 两个 code unit。
Java 的 char 类型长度为二字节,它对应的是 code unit。换句话说,一个字符的编码,可能需要用两个 char 来存储。
作为一个输入法爱好者,我偶尔会编程处理一些生僻字。其中有些生僻字大概是后来才加入 unicode 字符集里的,直接用 charAt 方法读取它们,会得到一堆问号。原因很清楚 —— 因为这些字符(eg. "")是用两个 code unit,也就是两个 char 表示的。charAt 找不到对应的编码,就会将这些 char 输出成「?」。
//示例
public class Test {
public static void main(String[] args){
String s = "";
System.out.println(s.length()); //输出:2
System.out.println(s.charAt(0)); //输出:?
System.out.println(s.charAt(1)); //输出:?
}
}
因此,涉及到中文,一定要使用 String 而不是 char,并且使用 codePoint 相关方法来处理它。否则的话,如果用户使用了生僻字,很可能就会得到不想要的结果。
下面是一个使用 codePoint 遍历一个字符串的示例,需要注意的是,codePoint 是 int 类型的(因为 char 不足以保存一个 codepoint),因此需要做些额外的转换:
public class Test {
public static void main(String[] args){
String s = "赵孟孟";
for (int i = 0; i < s.codePointCount(0,s.length()); i++) {
System.out.println(
new String(Character.toChars(s.codePointAt(i))));
// 这里的轨迹是:类型为 int 的 codepoint -> char数组 -> String
}
}
}
/* 结果:
赵
孟
?
*/
问题来了,「」这个字是正常地输出了,可最后的「孟」却变成了黑人问号。。
原因就在于 codepointAt(i) 是以 char 偏移量索引的。。所以只是这样输出也是不行的。。
正确的遍历姿势是这样的:
final int length = s.length();
for (int offset = 0; offset < length; ) {
final int codepoint = s.codePointAt(offset);
System.out.println(new String(Character.toChars(codepoint)));
offset += Character.charCount(codepoint);
}
这个代码保持了一个变量offset, 来指示下一个 codepoint 的偏移量。最后那一句在处理完毕后,更新这个偏移量
而 Java 8 添加了 CharSequence#codePoints, 该方法返回一个 IntStream,该流包含所有的 codepoint。可以直接通过 forEach 方法来遍历他。
string.codePoints().forEach(
c -> System.out.println(new String(Character.toChars(c)));
);或者用循环:
for(int c : string.codePoints().toArray()){
System.out.println(new String(Character.toChars(c)));
}2. 内部字符集与输出字符集(内码与外码)
现在我们知道了中文字符在 java 内部可能会保存成两个 char,可还有个问题:如果我把一个字符输出到某个流,它还会是两个 char,也就是 4 字节么?
回想一下,Java io 有字符流,字符流使用 jvm 默认的字符集输出,而若要指定字符集,可使用转换流。
因此,一个中文字符,在内部是使用 utf-16 表示,可输出就不一定了。
来看个示例:
import java.io.UnsupportedEncodingException;
public class Test {
public static void main(String[] args)
throws UnsupportedEncodingException {
String s = "中"; //
System.out.println(s + ": chars: " + s.length());
System.out.println(s + ": utf-8 bytes:" + s.getBytes("utf-8").length);
System.out.println(s + ": unicode bytes: " + s.getBytes("unicode").length);
System.out.println(s + ": utf-16 bytes: " + s.getBytes("utf-16").length);
}
}
输出为:
中: chars: 1 // 2 bytes
中: utf-8 bytes:3
中: unicode bytes: 4
中: utf-16 bytes: 4
: chars: 2 // 4 bytes
: utf-8 bytes:4
: unicode bytes: 6
: utf-16 bytes: 6
一个「中」字,内部存储只用了一个 char,也就是 2 个字节。可转换成 utf-8 编码后,却用了 3 个字节。怎么会不一样呢,是不是程序出了问题?
当然不是程序的问题,这是内码(utf-16)转换成外码(utf-8),字符集发生了改变,所使用的字节数自然也可能会改变。(尤其这俩字符集还都是变长编码)
3. utf-16、utf-16le、utf-16be、bom
不知道在刚刚的示例中,你有没有发现问题:同是 utf-16,为何「中」和「」的 s.getBytes("utf-16").length 比s.length 要多个 2?开头就说了 String 也是 utf-16 编码的,这两个数应该相等才对不是吗?
原因在于,utf-16 以 16 位为单位表示数据,而计算机是以字节为基本单位来存储/读取数据的。因此一个 utf-16 的 code unit 会被存储为两个字节,需要明确指明这两个字节的先后顺序,计算机才能正确地找出它对应的字符。而 utf-16 本身并没有指定这些,所以它会在字符串开头插入一个两字节的数据,来存储这些信息(大端还是小端)。这两个字节被称为BOM(Byte Order Mark)。刚刚发现的多出的两字节就是这么来的。
如果你指定编码为 utf-16le 或 utf-16be,就不会有这个 BOM 的存在了。这时就需要你自己记住该文件的大小端。。
4. utf-8 unicode
windows 中,utf-8 格式的文件也可能会带有 BOM,但 utf-8 的基本单位本来就是一个字节,因此它不需要 BOM 来表示 所谓大小端。这个 BOM 一般是用来表示该文件是一个 utf-8 文件。不过 linux 系统则对这种带 BOM 的文件不太友好。不般不建议加。。(虽如此说,上面的测试中,utf-8 的数据应该是没加 bom 的结果)
unicode字符集UCS(Unicode Character Set) 就是一张包含全世界所有文字的一个编码表,但是 UCS 太占内存了,所以实际使用基本都是使用它的其他变体。一般来说,指定字符集时使用的 unicode 基本等同于 utf-16.(所以你会发现第二节演示的小程序里,utf-16 和 unicode 得出的结果是一样的。)
4、base64编码不唯一
测试 JWT,发现修改 JWT 的最后一个字符(其实不是我发现的。。),居然有可能不影响 JWT 的正确性。比如如下这个使用 HS256 算法的 JWT:
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiaWF0IjoxNTE2MjM5MDIyfQ.SflKxwRJSMeKKF2QT4fwpMeJf36POk6yJV_adQssw5c把它的最后一个字符改成 d e或者 f,都能成功通过 http://jwt.io 的验证。
这让我觉得很奇怪(难道我发现了一个 Bug?),在QQ群里一问,就有大佬找到根本原因:这是 base64 编码的特性。并且通过 python 进行了实际演示:
In [1]: import base64
# 使用 jwt 的 signature 进行验证
In [2]: base64.b64decode("SflKxwRJSMeKKF2QT4fwpMeJf36POk6yJV_adQssw5c==")
Out[2]: b'I\xf9J\xc7\x04IH\xc7\x8a(]\x90O\x87\xf0\xa4\xc7\x89\x7f~\x8f:N\xb2%V\x9dB\xcb0\xe5'
In [3]: base64.b64decode("SflKxwRJSMeKKF2QT4fwpMeJf36POk6yJV_adQssw5d==")
Out[3]: b'I\xf9J\xc7\x04IH\xc7\x8a(]\x90O\x87\xf0\xa4\xc7\x89\x7f~\x8f:N\xb2%V\x9dB\xcb0\xe5'
In [4]: base64.b64decode("SflKxwRJSMeKKF2QT4fwpMeJf36POk6yJV_adQssw5e==")
Out[4]: b'I\xf9J\xc7\x04IH\xc7\x8a(]\x90O\x87\xf0\xa4\xc7\x89\x7f~\x8f:N\xb2%V\x9dB\xcb0\xe5'
In [5]: base64.b64decode("SflKxwRJSMeKKF2QT4fwpMeJf36POk6yJV_adQssw5f==")
Out[5]: b'I\xf9J\xc7\x04IH\xc7\x8a(]\x90O\x87\xf0\xa4\xc7\x89\x7f~\x8f:N\xb2%V\x9dB\xcb0\xe5'
# 两个等于号之后的任何内容,都会被直接丢弃。这个是实现相关的,有的 base64 处理库对这种情况会报错。
In [6]: base64.b64decode("SflKxwRJSMeKKF2QT4fwpMeJf36POk6yJV_adQssw5f==fdf=df==dfd=fderwe=r")
Out[6]: b'I\xf9J\xc7\x04IH\xc7\x8a(]\x90O\x87\xf0\xa4\xc7\x89\x7f~\x8f:N\xb2%V\x9dB\xcb0\xe5'可以看到将最后一个字符(不考虑 ==)改成 d e f,解码出来的都是同样的内容。
原因分析
base64 编码将二进制内容(bytes)从左往右每 6 bits 分为一组,每一组编码为一个可打印字符。
bas64 从 ASCII 字符集中选出了 64 个字符(=号除外)进行编码。因为 26=6426=64,使用 64 个字符才能保证上述编码的唯一性。
但是被编码的二进制内容(bytes)的 bits 数不一定是 6 的倍数,无法被编码为 6 bits 一组。
为了解决这个问题,就需要在这些二进制内容的末尾填充上 2 或 4 个 bit 位,这样才能使用 base64 进行编码。
关于这些被填充的 bits,在 RFC4648 中定义了规范行为:全部补 0.
但是这并不是一个强制的行为,因此实际上你可以随便补,在进行 base64 解析时,被填补的 bits 会被直接忽略掉。
这就导致了上面描述的行为:修改 JWT 的最后一个字符(6 bits,其中可能包含 2 或 4 个填充比特位)可能并不影响被编码的实际内容!
RFC4684 中对这个 bits 填充的描述如下:
3.5. Canonical Encoding
The padding step in base 64 and base 32 encoding can, if improperly
implemented, lead to non-significant alterations of the encoded data.
For example, if the input is only one octet for a base 64 encoding,
then all six bits of the first symbol are used, but only the first
two bits of the next symbol are used. These pad bits MUST be set to
zero by conforming encoders, which is described in the descriptions
on padding below. If this property do not hold, there is no
canonical representation of base-encoded data, and multiple base-
encoded strings can be decoded to the same binary data. If this
property (and others discussed in this document) holds, a canonical
encoding is guaranteed.
In some environments, the alteration is critical and therefore
decoders MAY chose to reject an encoding if the pad bits have not
been set to zero. The specification referring to this may mandate a
specific behaviour.它讲到在某些环境下,base64 解析器可能会严格检查被填充的这几个 bits,要求它们全部为 0.
但是我测试发现,Python 标准库和 https://jwt.io 都没有做这样的限制。因此我认为绝大部分环境下,被填充的 bits 都是会被忽略的。
问题一:为什么只需要填充 2 或 4 个 bit 位?
这是看到「填充上 2 或 4 个 bit 位」时的第一想法——如果要补足到 6 的倍数,不应该是要填充 1-5 个 bit 位么?
要解答这个问题,我们得看 base64 的定义。在 RFC4648 的 base64 定义中,有如下这样一段话:
The Base 64 encoding is designed to represent arbitrary sequences of
octets in a form that allows the use of both upper- and lowercase
letters but that need not be human readable.注意重点:octets—— 和 bytes 同义,表示 8 bits 一组的位序列。这表示 base64 只支持编码 bits 数为 8 的倍数的二进制内容,而 8xmod68xmod6 的结果只可能是 0/2/4 三种情况。
因此只需要填充 2 或 4 个 bit 位。
这样的假设也并没有什么问题,因为现代计算机都是统一使用 8 bits(byte) 为最小的可读单位的。即使是 c 语言的「位域」也是如此。
因为 Byte(8 bits) 现代 CPU 数据读写操作的基本单位,学过汇编的对这个应该都有些印象。
你仔细想想,所有文件的最小计量单位,是不是都是 byte?
问题二:为什么用 python 测试时可能需要在 JWT signature 的末尾添加多个 =,而 JWT 中不需要?
前面已经讲过,base64 的编码步骤是是将字节(byte, 8 bits)序列,从左往右每 6 个 bits 转换成一个可打印字符。
查阅 RFC4648 第 4 小节中 baae64 的定义,能看到它实际上是每次处理 24 bits,因为这是 6 和 8 的最小公倍数,可以刚好用 4 个字符表示。
在被处理的字节序列的比特(bits)数不是 24 的整数时,就需要在序列末尾填充 0 使末尾的 bits 数是 6 的倍数(6-bit groups)。有可能会出现三种情况:
- 被处理的字节序列 S 的比特数刚好是 24 的倍数:不需要补比特位,末尾也就不需要加
= - S 的比特数是 24x+824x+8: 末尾需要补 4 个 bits,这样末尾剩余的 bits 才是 6-bit groups,才能编码成 base64。然后添加两个
==使编码后的字符数为 4 的倍数。 - S 的比特数为 24x+1624x+16:末尾需要添加 2 个 bits 才能编码成 base64。然后添加一个
=使编码后的字符数为 4 的倍数。
其实可以看到,添加 = 的目的只是为了使编码后的字符数为 4 的倍数而已,= 这个 padding 其实是冗余信息,完全可以去掉。
在解码完成后,应用程序会自动去除掉末尾这不足 1 byte 的 2 或 4 个填充位。
因此 JWT 就去掉了它以减少传输的数据量。
可以用前面讲到的 JWT signature 进行验证:
In [1]: import base64
In [2]: s = base64.b64decode("SflKxwRJSMeKKF2QT4fwpMeJf36POk6yJV_adQssw5c==")
# len(s) * 8 得到 bits 数
In [3]: len(s) * 8 % 24
Out[3]: 8可以看到这里的被编码内容比特数为 24x+824x+8,所以末尾需要添加两个 == 号才符合 RFC4648 的定义。
Java 与 Python 对比:
python3 在字符串表示上,做了大刀阔斧的改革,python3 的 len(str) 得到的就是 unicode 字符数,因此程序员完全不需要去考虑字符的底层表示的问题。(实际上其内部表示也可能随着更新而变化)带 BOM 的 utf-8 也可通过指定字符集为 utf-8-sig 解决。若需要做字符集层面处理,需要 encode 为特定字符集的 byte 类型。
python2 存在和 Java 相同的问题。