深入Golang内存管理(三) 内存对齐篇
Go struct 内存对齐
举个例子
type S struct {
a bool
b int32
c int8
d int64
e byte
}
上面的struct S,占用多大的内存?
首先我们按照每个成员来算算,S这一个结构体的占用内存大小为 1+4+1+8+1 = 15 个字节。相信有的小伙伴是这么算的,看上去也没什么问题.
但真实情况是怎么样的呢?我们实际调用看看,如下:
fmt.Printf("part1 size: %d",unsafe.Sizeof(S))
最终输出为占用 32 个字节。这与前面所预期的结果完全不一样。这充分地说明了先前的计算方式是错误的。这就要提到我们今天的主角,内存对齐.
为什么要关心对齐
- 你正在编写的代码在性能(CPU、Memory)方面有一定的要求
- 你正在处理向量方面的指令
- 某些硬件平台(ARM)体系不支持未对齐的内存访问
为什么要做内存对齐
-
平台(移植性)原因:不是所有的硬件平台都能够访问任意地址上的任意数据。例如:特定的硬件平台只允许在特定地址获取特定类型的数据,否则会导致异常情况
-
性能原因:操作系统并非一个字节一个字节访问内存,而是按2, 4, 8这样的字长来访问。因此,当CPU从存储器读数据到寄存器,或者从寄存器写数据到存储器,IO的数据长度通常是字长。
-
若访问未对齐的内存,将会导致 CPU 进行两次内存访问,并且要花费额外的时钟周期来处理对齐及运算。而本身就对齐的内存仅需要一次访问就可以完成读取动作
举个例子
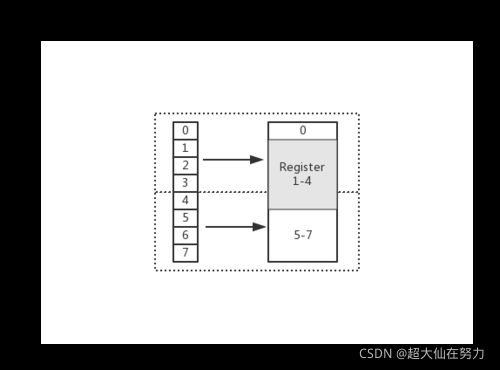
在上图中,假设从 Index 1 开始读取,将会出现很崩溃的问题。因为它的内存访问边界是不对齐的。因此 CPU 会做一些额外的处理工作。如下: -
CPU 首次读取未对齐地址的第一个内存块,读取 0-3 字节。并移除不需要的字节 0
-
CPU 再次读取未对齐地址的第二个内存块,读取 4-7 字节。并移除不需要的字节 5、6、7 字节
-
合并 1-4 字节的数据
-
合并后放入寄存器
从上述流程可得出,不做 “内存对齐” 是一件有点 “麻烦” 的事。因为它会增加许多耗费时间的动作
而假设做了内存对齐,从 Index 0 开始读取 4 个字节,只需要读取一次,也不需要额外的运算。这显然高效很多,是标准的空间换时间做法.
原理
术语
在介绍如何内存对齐之前,我们有必要先了解一些前置知识.
- 字
是用于表示其自然的数据单位,也叫machine word。字是电脑用来一次性处理事务的一个固定长度。 - 字长
一个字的位数,现代电脑的字长通常为 16、32、64 位。(一般 N 位系统的字长是 N/8 字节。)
数据结构对齐
大小保证
在Go中,如果两个值的类型为同一种类的类型,并且它们的类型的种类不为接口、数组和结构体,则这两个值的尺寸总是相等的。
目前(Go 1.14),至少对于官方标准编译器来说,任何一个特定类型的所有值的尺寸都是相同的。所以我们也常说一个值的尺寸为此值的类型的尺寸。
下表列出了各种种类的类型的尺寸(对标准编译器1.14来说):
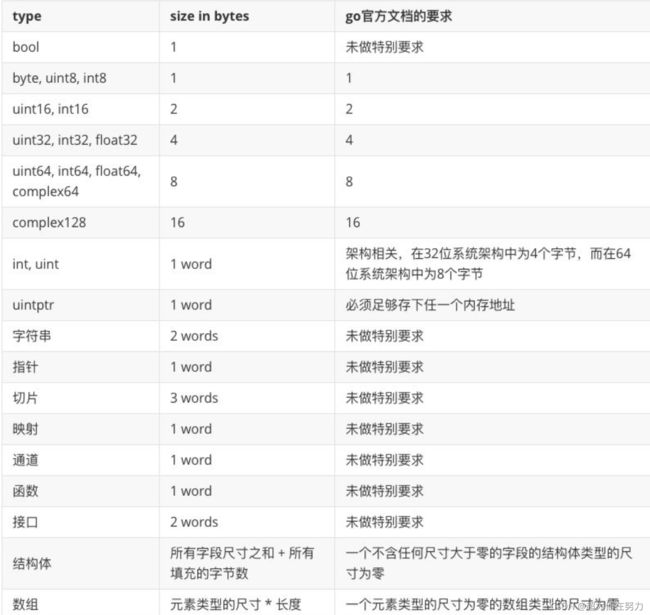
一个结构体类型的尺寸取决于它的各个字段的类型尺寸和这些字段的排列顺序。
为了程序执行性能,编译器需要保证某些类型的值在内存中存放时必须满足特定的内存地址对齐要求。
地址对齐可能会造成相邻的两个字段之间在内存中被插入填充一些多余的字节。 所以,一个结构体类型的尺寸必定不小于(常常会大于)此结构体类型的各个字段的类型尺寸之和。
一个数组类型的尺寸取决于它的元素类型的尺寸和它的长度。它的尺寸为它的元素类型的尺寸和它的长度的乘积。
struct{} 和[0]T{} 的大小为 0; 不同的大小为 0 的变量可能指向同一块地址。
对齐系数
在了解如何对齐之前,我们需要了解"对齐系数"这个概念,unsafe 标准库提供了 Alignof 方法,可以返回一个类型的对齐系数一般来说,对齐系数在我们常用的平台的系数如下:
- 32 位:4
- 64 位:8
在go官方文档中对齐系数的要求只有如下解释:
- 对于任何类型的变量x,对齐系数的结果最小为1。
- 对于一个结构体类型的变量x,对齐系数为x的所有字段的对齐系数中的最大值(但是最小为1)。
- 对于一个数组类型的变量x,对齐系数和此数组的元素类型的一个变量的对齐系数相等。

如果一个类型T的对齐系数为N(一个正整数),则在运行时刻T类型的每个(可寻址的)值的地址都是N的倍数。 我们也可以说类型T的值的地址保证为N字节对齐的。
事实上,每个类型有两个对齐系数。当它被用做结构体类型的字段类型时的对齐系数称为此类型的字段对齐系数,其它情形的对齐系数称为此类型的一般对齐系数。
对于一个类型T,我们可以调用unsafe.Alignof(t)来获得它的一般对齐系数,其中t为一个T类型的非字段值, 也可以调用unsafe.Alignof(x.t)来获得T的字段对齐系数,其中x为一个结构体值并且t为一个类型为T的结构体字段值。
在运行时刻,对于类型为T的一个值t,我们可以调用reflect.TypeOf(t).Align()来获得类型T的一般对齐系数, 也可以调用reflect.TypeOf(t).FieldAlign()来获得T的字段对齐系数。
对于当前的官方Go编译器(1.14版本),一个类型的一般对齐系数和字段对齐系数总是相等的。
对齐规则
在了解完大小和对齐系数以后,我们就可以利用对齐规则对结构体进行内存对齐:
- 结构体的成员变量,第一个成员变量的偏移量为 0。往后的每个成员变量的对齐值必须为编译器默认对齐长度(#pragma pack(n))或当前成员变量类型的长度(unsafe.Sizeof),取最小值作为当前类型的对齐值。其偏移量必须为对齐值的整数倍
- 结构体本身,对齐值必须为编译器默认对齐长度(#pragma pack(n))或结构体的所有成员变量类型中的最大长度,取最大数的最小整数倍作为对齐值
- 结合以上两点,可得知若编译器默认对齐长度(#pragma pack(n))超过结构体内成员变量的类型最大长度时,默认对齐长度是没有任何意义的.
其中#pragma pack(n)的取值就是我们前面介绍的操作系统一般情况下的取值,即32位为4,64位为8.
实践
那么我们重新回到一开始的结构体上:
type S struct {
a bool
b int32
c int8
d int64
e byte
}
让我们一个一个成员来看: (x为padding)
- 成员a:
- 类型为 bool
- 大小/对齐值为 1 字节
- 初始地址,偏移量为 0。占用了第 1 位
- 成员 b
- 类型为 int32
- 大小/对齐值为 4 字节
- 根据规则 1,其偏移量必须为 4 的整数倍。确定偏移量为 4,因此 2-4 位为 Padding。而当前数值从第 5 位开始填充,到第 8 位。如下:axxx|bbbb
- 成员 c
- 类型为 int8
- 大小/对齐值为 1 字节
- 根据规则1,其偏移量必须为 1 的整数倍。当前偏移量为 8。不需要额外对齐,填充 1 个字节到第 9 位。如下:axxx|bbbb|c…
- 成员 d
- 类型为 int64
- 大小/对齐值为 8 字节
- 根据规则 1,其偏移量必须为 8 的整数倍。确定偏移量为 16,因此
9-16 位为 Padding。而当前数值从第 17 位开始写入,到第 24 位。如下:axxx|bbbb|cxxx|xxxx|dddd|dddd
- 成员 e
- 类型为 byte
- 大小/对齐值为 1 字节
- 根据规则 1,其偏移量必须为 1 的整数倍。当前偏移量为 24。不需要额外对齐,填充 1 个字节到第 25 位。如下:axxx|bbbb|cxxx|xxxx|dddd|dddd|e…
最后由于规则2,,整个结构体本身也要进行字节对齐,因为可发现它可能并不是 2^n,不是偶数倍。显然不符合对齐的规则.
根据规则 2,可得出对齐值为 8。现在的偏移量为 25,不是 8 的整倍数。因此确定偏移量为 32。对结构体进行对齐.
所以最后的内存布局为:
struct S : axxx|bbbb|cxxx|xxxx|dddd|dddd|exxx|xxxx
特例
下面是一道腾讯的面试题:
type S struct {
A uint32
B uint64
C uint64
D uint64
E struct{}
}
首先,我们可以明确S的是8字节对齐的,所以第一感觉E没有占用空间,所以答案是32.
但当我们调用fmt.Println(unsafe.Sizeof(S{})).会发现答案是40. 很明显在最后面存在一个大小为8的padding.
针对于这种情况,在github上有相关的issue:
结构体尾部size为0的变量(字段)会被分配内存空间进行填充,原因是如果不给它分配内存,该变量(字段)指针将指向一个非法的内存空间(类似C/C++的野指针)。
就比如说我连续分配了两个S结构体,那么如果不存在这个padding那么S.E的位置实际上是等于下一个S的位置的,导致了非法内存访问.
总结
- 内存对齐是为了让 cpu 更高效访问内存中数据
- struct 的对齐是:如果类型 t 的对齐保证是 n,那么类型 t 的每个值的地址在运行时必须是 n 的倍数。
- struct 内字段如果填充过多,可以尝试重排,使字段排列更紧密,减少内存浪费
- 零大小字段要避免作为 struct 最后一个字段,会有内存浪费.
- 32 位系统上对 64 位字的原子访问要保证其是 8bytes 对齐的;当然如果不必要的话,还是用加锁(mutex)的方式更清晰简单