GoLang之内存对齐、计算结构体内存大小
文章目录
- GoLang之内存对齐、计算结构体内存大小
-
- 1.地址总线、数据总线、机器字长
- 2.内存布局
- 3.内存对齐
-
- 3.1定义、粒度
- 3.2确定对齐边界方法
- 3.3windos64计算int8对齐边界(小于最大对齐边界)
- 3.4windos64确定int16对齐边界(小于最大对齐边界)
- 3.5windos32确定int64(大于最大对齐边界)
- 3.确定结构体对齐边界
-
- 3.1确定结构体对齐边界
- 3.2结构体内存大小(字段)
- 3.3结构体内存大小(嵌套结构体)
- 3.4结构体内存大小(匿名结构体指针)
- 3.3结构体内存布局
GoLang之内存对齐、计算结构体内存大小
1.地址总线、数据总线、机器字长
地址总线:
cpu要向从内存读取到数据,需要通过地址总线把地址传输给内存,内存准备好数据,输出到数据总线,交给cpu,如果地址总线只有8根,那这个地址就只有8位,可以表示256个地址(256byte,256字节),由于表示不了更多的地址就用不了更大的内存,所以256就是8根地址总线最大的地址寻址空间;
要想使用更大的内存,就要有更宽的地址总线,例如32位地址总线就可以寻址4G内存了(2^32=4294967296)(1G=1024MB,1MB=1024KB,1KB=1024字节) (1G=2^30字节) ;
数据总线、机器字长:
每次操作1字节太慢,那就加宽数据总线,要想一次操作4字节(windos32),就要至少32根数据总线(32根即32位,4字节=32位),8字节就要64位数据总线,这里每次操作的字节数就是所谓的机器字长(即windos64)

2.内存布局
如果内存就像我们逻辑上认为的那样一个挨着一个行成的的大矩阵,我们可以访问任意地址,并把它输出到总线

但实际上为了实现更高的访问效率,典型的内存布局是这样的,一个内存条的一面是Rank,一个Chip包括这样的八个Bank,到Bank那里就可以通过选择行选择列来定位一个地址了
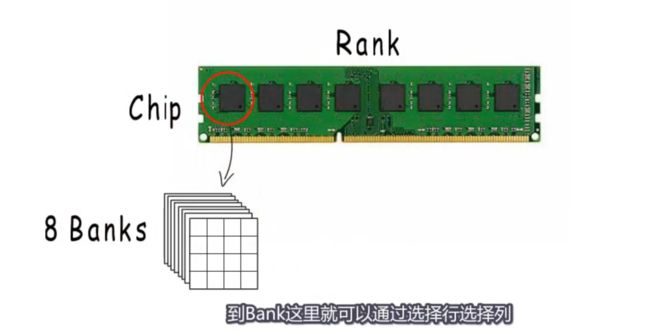
这不像我们逻辑上认为的那样的连续的存在,但它们共用同一个地址,各自选择同一个位置的一个字节,再组合起来作为我们逻辑上认为的连续8个字节,通过这样的并行操作,提高了内存访效率,但如果使用这种设计,adress那里的地址就只能是8的倍数,如果非要错开一个格儿,由于最后一个字节对应的位置与前七个不同,不能在一次操作中倍同一个地址选中,所以这样的地址是不能用的;

之所以有些cpu能够支持访问任意地址,是因为它多做了许多处理,例如你想从地址1开始读8字节的数据,cpu会分两次读,第一次是从0到7,但只取后7字节,第二次从8*15,但只读取第一字节,把两次结果拼接起来拿到所需数据


但是以上的方式必然会影响到性能,所以为了程序顺利高效的运行,编译器会把各种类型的数据安排到合适的地址,并占用合适的长度,这就是内存对齐;
3.内存对齐
3.1定义、粒度
内存对齐:
现代计算机中内存空间都是按照字节(byte)进行划分的,所以从理论上讲对于任何类型的变量访问都可以从任意地址开始,但是在实际情况中,在访问特定类型变量的时候经常在特定的内存地址访问,所以这就需要把各种类型数据按照一定的规则在空间上排列,而不是按照顺序一个接一个的排放,这种就称为内存对齐,内存对齐是指首地址对齐,而不是说每个变量大小对齐。
粒度:
CPU把内存看成一块一块的,一块内存可以是2、4、8、16个字节,CPU访问内存也是一块一块的访问,cpu一次访问一块内存的大小我们定义为粒度;32位CPU访问粒度是4个字节,64位CPU访问粒度是8个字节。内存对齐是为了减少访问内存的次数,提高CPU读取内存数据的效率,如果内存不对齐,访问相同的数据需要更多的访问内存次数。
3.2确定对齐边界方法
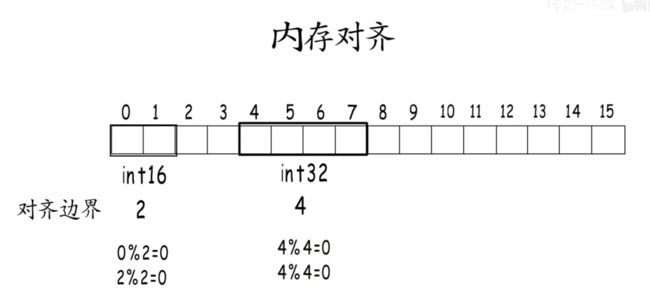
每种类型的对齐值就是它的对齐边界,内存对齐要求数据存储地址以及占用的字节数都要是它的对齐边界的倍数,因此,int32要错开两字节,从4开始存,不能紧接着从2开;
func main() {
fmt.Println(1 % 8)
fmt.Println(0 % 8)
fmt.Println(2 % 8)
fmt.Println(3 % 8)
}
那么,怎么确定每种类型的对齐边界呢?
这与平台有关,Go语言支持这些平台,可以看到常见的32位平台指针宽度和寄存器宽度都是4字节,64位平台上都是8字节,而被Go语言称为寄存器宽度的这个值就可以理解为机器字长,也是平台对应的最大对齐边界

而“数据类型的对其边界” 是取类型大小与平台最大对其边界(字长)中较小的那个,不过要注意同一个类型在不同的平台上大小可能不同及对其边界也可能不同

3.3windos64计算int8对齐边界(小于最大对齐边界)
为什么不统一使用平台最大对齐边界,或者统一按各类型大小来对齐呢?我们来试一下。假设目前是64位平台,最大对齐边界为8字节,int8只有1个字节,按照1字节对齐的话,它可以放在任何位置,因为总能通过一次读取把它完整拿出来



再如果统一对齐到8字节的话,虽然同样只要读取一次,但每个int8型的变量都要浪费7字节,所以对齐到1

3.4windos64确定int16对齐边界(小于最大对齐边界)
int16占两字节,按照两字节对齐开始存的话,可以从如下这些地址开始存,而且能保证只用读取一次

int16占两字节,如果按照1字节对齐就可能存成这样,那就要读两次再截取拼接,会影响到性能

int16占两字节,如果对齐到8字节,与int8类型一样,会浪费内存,所以对齐到2字节最适合,这是小于最大对齐边界的情况

3.5windos32确定int64(大于最大对齐边界)
再来看看大于的情况,假设要在32位平台存储一个int64类型的数据,在如下两字节被占用的情况下,如果对齐到类型大小8,就要从下图中那里开始存(原因:内存对齐要求数据存储地址以及占用的字节数都要是它的对齐边界的倍数)

在如下两字节被占用的情况下,如果对齐到4,就要从图中开始存,内存浪费更少,所以应该选择这个;所以类型边界会那样选择依然是为了减少浪费、提高行能

3.确定结构体对齐边界
3.1确定结构体对齐边界
最后来看看怎么确定一 个结构体的对齐边界呢?首先确定每个成员的对齐边界,取其中成员内存对齐边界中对大的那个,这就是这个结构体的对齐边界

然后我们来存储这个结构体变量,看看它怎么对齐;
内存对齐第一个要求,存储这个结构体的起始地址是对齐边界的倍数,假设如下开始存,结构体的每个成员在存储时,都要把这个起始地址当作地址0,然后再用相对地址来决定自己放在哪

第一个成员a,它要对齐1字节,而这里是相对地址0,计算0%1=0,所以a放在0地址;

然后是第二个成员b,b要对齐到八字节,通过计算1%8=1,即接下来的地址对8取模不等于0,所以要往后挪,所以b要在8地址存储(接下来的地址是指1)


而c要对齐到4字节,16%4=0,接下来的位置就刚好;
d对齐了2字节,位置也刚好,至此已经用了22个字节了

还有内存对齐的结第二个要求,结构体整体占用字节数需要是结构体类型对齐边界(此处是8)的倍数,不够的话要往后扩张一下,所以它要扩充到相对地址23这里,最终这个结构体类型的大小就是24字节,至此,对齐完成

至于为什么要限制类型大小等于对齐边界的整数倍,我们可以这样理解,如果不扩大到对齐边界的整数倍,这个结构体类型大小就是22字节,那么要使用一个长度为2的T类型的数组,按照元素类型大小,会占用44字节的内存,两个元素在下图位置所示,问题出现了,第二个元素并没有对齐,所以只有每个结构体的大小都是对齐值的整数倍才能保证数组中每一个都是内存对齐的

由此可见结构体里字段定义的先后顺序会导致最终内存的占用大小
3.2结构体内存大小(字段)
type Student struct {
a int8
b int16
}
func main() {
var t Student
fmt.Println(unsafe.Sizeof(t))//4
}
type Student struct {
a int8
b int8
c int8
d int8
}
func main() {
var t Student
fmt.Println(unsafe.Sizeof(t)) //4
}
type Student struct {
a int
b int
c int
d int
}
func main() {
var t Student
var a int
fmt.Println(unsafe.Sizeof(a))//8
fmt.Println(unsafe.Sizeof(t)) //32
}

3.3结构体内存大小(嵌套结构体)
type Student struct {
A
a int8
b int8
c int8
d int8
}
type A struct {
m int8
}
func main() {
var t Student
fmt.Println(unsafe.Sizeof(t))//输出:5
}
3.4结构体内存大小(匿名结构体指针)
如果匿名字段是指针的话,那么只是占一个指针的大小:
type T struct {
a int8
b int8
c int8
d int8
m int8
}
type B struct {
*T
}
func main() {
var b B
fmt.Println(unsafe.Sizeof(b)) // 8
}
3.3结构体内存布局
结构体占用一快连续的内存
type Student struct {
a int8
b int8
c int8
d int8
}
func main() {
var t Student
fmt.Printf("%p\n", &t)
fmt.Println(&t.a)
fmt.Println(&t.b)
fmt.Println(&t.c)
fmt.Println(&t.d)
t = Student{1, 2, 4, 5}
fmt.Printf(" %p\n", &t)
fmt.Println(&t.a)
fmt.Println(&t.b)
fmt.Println(&t.c)
fmt.Println(&t.d)
/*
0xc000016098
0xc000016098
0xc000016099
0xc00001609a
0xc00001609b
0xc000016098
0xc000016098
0xc000016099
0xc00001609a
0xc00001609b
*/
}