Pytorch学习率衰减策略学习记录
对基于深度学习的模型调参是炼丹师的必备技能,而学习率的衰减策略正是调参方法之一,今天就系统地学习一下pytorch自带学习率衰减策略
1)实例化模型和优化器
import torch
from torch.optim.lr_scheduler import *
import torch.nn as nn
from torchvision.models import resnet50
import matplotlib.pyplot as plt
model = resnet50(False)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)2)选择不同的学习率衰减策略
1. LambdaLR
该策略可以将学习率自定义为一个与epoch有关的lambda函数,如:lr_lambda=lambda epoch: 0.95 ** epoch
scheduler1 = LambdaLR(optimizer=optimizer, lr_lambda=lambda epoch: 0.95 ** epoch)
plt.figure()
max_epoch = 30
cur_lr_list = []
for epoch in range(max_epoch):
optimizer.step()
scheduler1.step()
cur_lr = optimizer.param_groups[-1]['lr']
cur_lr_list.append(cur_lr)
print('Current lr:', cur_lr)
x_list = list(range(len(cur_lr_list)))
plt.plot(x_list, cur_lr_list)
plt.show()
plt.savefig('D:/lr_scheduler_learning/lambdalr.png')
2. StepLR
每过step size轮epoch,将当前学习率乘以gamma
scheduler2 = StepLR(optimizer, step_size=10, gamma=0.1)
plt.figure()
max_epoch = 30
cur_lr_list = []
for epoch in range(max_epoch):
optimizer.step()
scheduler2.step()
cur_lr = optimizer.param_groups[-1]['lr']
cur_lr_list.append(cur_lr)
print('Current lr:', cur_lr)
x_list = list(range(len(cur_lr_list)))
plt.plot(x_list, cur_lr_list)
plt.show()
plt.savefig('D:/lr_scheduler_learning/steplr.png')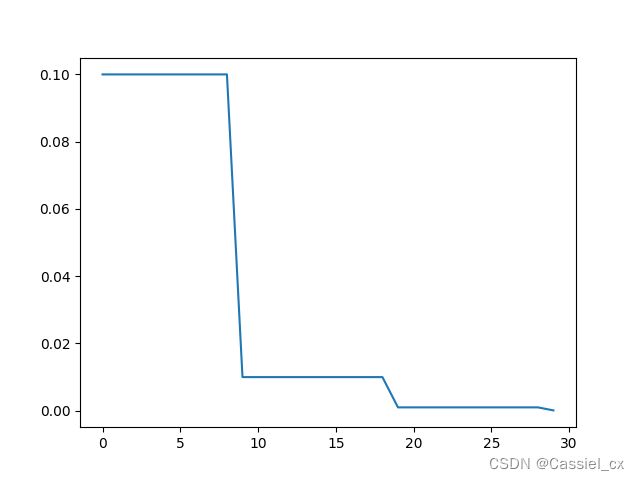
3. MultiStepLR
当epoch为milestones里的元素时,将当前学习率乘以gamma,如:milestones=[5,10,15,20,25],当epoch为5、10、15、20、25时,new_lr = cur_lr * gamma
scheduler3 = MultiStepLR(optimizer, milestones=[5,10,15,20,25], gamma=0.1)
plt.figure()
max_epoch = 30
cur_lr_list = []
for epoch in range(max_epoch):
optimizer.step()
scheduler3.step()
cur_lr = optimizer.param_groups[-1]['lr']
cur_lr_list.append(cur_lr)
print('Current lr:', cur_lr)
x_list = list(range(len(cur_lr_list)))
plt.plot(x_list, cur_lr_list)
plt.show()
plt.savefig('D:/lr_scheduler_learning/multisteplr.png')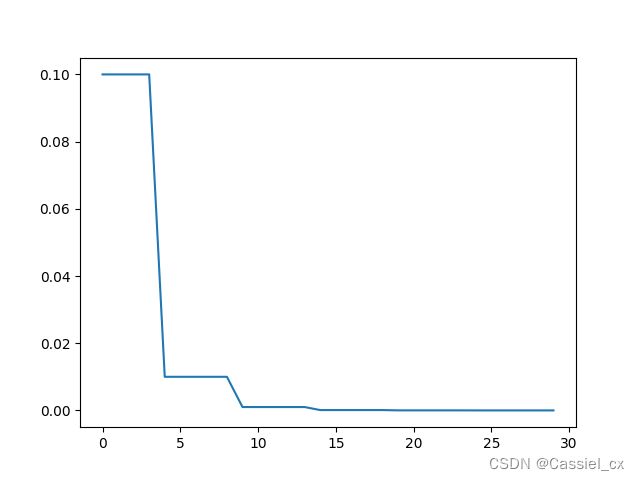
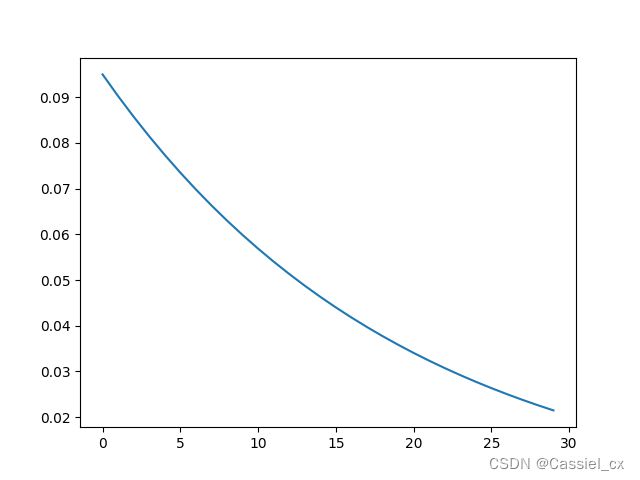
4. ExponentialLR
指数型学习率衰减策略,new_lr = cur_lr * gamma ** cur_epoch
scheduler4 = ExponentialLR(optimizer, gamma=0.8)
plt.figure()
max_epoch = 30
cur_lr_list = []
for epoch in range(max_epoch):
optimizer.step()
scheduler4.step()
cur_lr = optimizer.param_groups[-1]['lr']
cur_lr_list.append(cur_lr)
print('Current lr:', cur_lr)
x_list = list(range(len(cur_lr_list)))
plt.plot(x_list, cur_lr_list)
plt.show()
plt.savefig('D:/lr_scheduler_learning/exponentiallr.png')
5. CosineAnnealingLR
余弦退火学习率,T_max:余弦函数周期的一半,即每T_max*2个epoch循环一次余弦学习率;eta_min:最小学习率。公式如下:
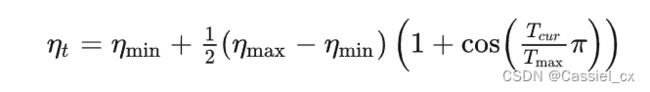
scheduler5 = CosineAnnealingLR(optimizer,T_max=5,eta_min=0.05)
plt.figure()
max_epoch = 30
cur_lr_list = []
for epoch in range(max_epoch):
optimizer.step()
scheduler5.step()
cur_lr = optimizer.param_groups[-1]['lr']
cur_lr_list.append(cur_lr)
print('Current lr:', cur_lr)
x_list = list(range(len(cur_lr_list)))
plt.plot(x_list, cur_lr_list)
plt.show()
plt.savefig('D:/lr_scheduler_learning/cosineannealinglr.png')
6. CyclicLR
base_lr:lr的下限;max_lr:lr的上限;step_size_up:lr从下限到上限需要的epoch数;step_size_down:lr从上限到下限需要的epoch数
scheduler6 = CyclicLR(optimizer, base_lr=0.01, max_lr=0.2, step_size_up=10, step_size_down=5)
plt.figure()
max_epoch = 30
cur_lr_list = []
for epoch in range(max_epoch):
optimizer.step()
scheduler6.step()
cur_lr = optimizer.param_groups[-1]['lr']
cur_lr_list.append(cur_lr)
print('Current lr:', cur_lr)
x_list = list(range(len(cur_lr_list)))
plt.plot(x_list, cur_lr_list)
plt.show()
plt.savefig('D:/lr_scheduler_learning/cycliclr.png')
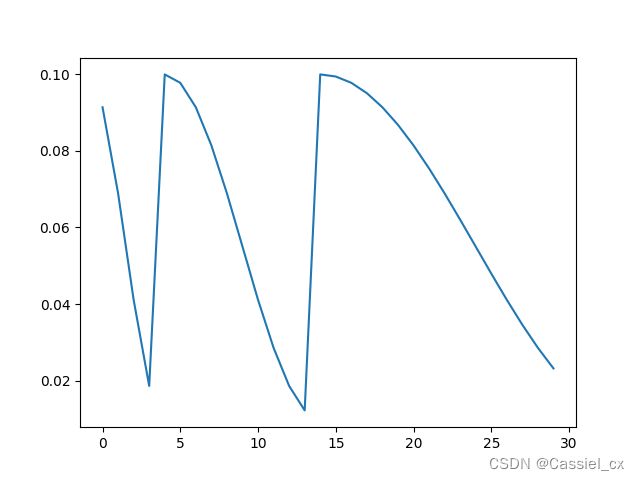
7. CosineAnnealingWarmRestarts
T_0:lr第一次 (周期) 下降到eta_min所需要的epoch数;T_mult:之后lr衰减需要的epoch数变成了前一周期需要的epoch数乘以T_mult
scheduler7 = CosineAnnealingWarmRestarts(optimizer, T_0=5, T_mult=2, eta_min=0.01)
plt.figure()
max_epoch = 30
cur_lr_list = []
for epoch in range(max_epoch):
optimizer.step()
scheduler7.step()
cur_lr = optimizer.param_groups[-1]['lr']
cur_lr_list.append(cur_lr)
print('Current lr:', cur_lr)
x_list = list(range(len(cur_lr_list)))
plt.plot(x_list, cur_lr_list)
plt.show()
plt.savefig('D:/lr_scheduler_learning/cosineannealingwarmrestarts.png')