Pytorch--学习率调整策略的使用(自定义学习率衰减)
文章目录
-
- 优化器的学习率和参数
-
- optimizer的param_groups
- 多学习率
- 封装好的lr调整策略
-
- 函数衰减-LambdaLR
- 固定步长衰减-StepLR
- 多步长衰减-MultiStepLR
- 指数衰减-ExponentialLR
- 余弦退火衰减-CosineAnnealingLR
- 自定义学习率衰减
-
- warm up
学习率的调整在训练的过程中很重要,通常情况下随着训练的进行,模型的参数值逐渐趋于收敛,学习率会越来越小。
即使如此,学习率的衰减速率的变化也是会有所不同,对于一些特殊的任务我们更是希望能以一些比较特别的方式甚至自己定义的方式来调节学习率,下面就来记录一下Pytorch的学习率调整策略。
优化器的学习率和参数
首先来看一下Pytorch的优化模块,torch.optim。
optim模块提供了大量和优化,学习有关的类和函数。
其中包括SGD, Adam, RMSprop优化器。他们都继承于一个超类,Optimizer,简单看一下这个类的方法
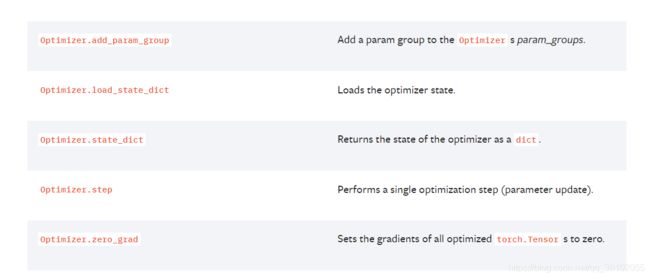
包含了我们最常使用的step和zero_grad方法。前者用于把方向传播的结果结合学习率进行计算,并且更新到参数上,后者负责清空梯度。还有state_dict和load_state_dict方法,可以用于获取优化器参数信息和加载优化器参数信息,可以用于保存训练状态。
optimizer的param_groups
接下来我们来看看优化器的初始化参数,以官方的为例
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
optimizer = optim.Adam([var1, var2], lr=0.0001)
第一行是我们组常用的形式,通过parameter的方式把模型的可训练参数以迭代器的形式返回并传给optimizer。第二种则是直接把参数以列表的形式传给优化器,var1和var2都是可训练参数。
这里参数都会被放到optimizer的param_groups里,以字典的方式存放,比如:
from torch.optim import Adam
optm_2 = Adam(lr=0.01, params=[
torch.nn.parameter.Parameter(torch.randn(2, 1)),
torch.nn.parameter.Parameter(torch.randn(2, 1))
])
print(optm_2.param_groups)
"""
输出:
[{'params': [Parameter containing:
tensor([[-1.1422],
[-1.6955]], requires_grad=True), Parameter containing:
tensor([[ 0.5786],
[-0.2614]], requires_grad=True)], 'lr': 0.01, 'betas': (0.9, 0.999), 'eps': 1e-08, 'weight_decay': 0, 'amsgrad': False}]
"""
可以看到两个参数都被放到了params的value中。并且还记录他们当前对应的学习率lr。这里也是我们修改学习率的关键,如果我们想要自定义学习率衰减,就需要手动的修改这个lr。
多学习率
有时对于不同的参数我们可能希望设置不同的学习率初始值,比如对模型进行微调时,对微调模块的参数可能希望变化小一点此时我们的所有参数就没法共用一个学习率了我们需要为不同的参数配置不同的学习率。
此时我们传入param的就要是一个dict列表,每个dict记录了不同的初始学习率
optm_2 = Adam(lr=0.001, params=[
{'params': torch.nn.parameter.Parameter(torch.randn(2, 1)), 'lr': 0.02},
{'params': torch.nn.parameter.Parameter(torch.randn(2, 1))}
])
print(optm_2.param_groups)
"""
[ {'params': [Parameter containing:
tensor([[-1.2393],
[ 0.4665]], requires_grad=True)], 'lr': 0.02, 'betas': (0.9, 0.999), 'eps': 1e-08, 'weight_decay': 0, 'amsgrad': False},
{'params': [Parameter containing:
tensor([[-0.2851],
[ 1.4226]], requires_grad=True)], 'lr': 0.001, 'betas': (0.9, 0.999), 'eps': 1e-08, 'weight_decay': 0, 'amsgrad': False}]
"""
dict的key和value就是param_group的值,如果不声明lr这个key的话默认就会使用参数里的lr。这样我们就可以给不同的模块的参数设置不同的学习率了。
封装好的lr调整策略
pytroch封装好了一些学习率调整策略供我们使用,他们都在torch.optim的子模块lr_scheduler。
其具体的使用方式如下:
- 初始化scheduler和optimizer
model = [Parameter(torch.randn(2, 2, requires_grad=True))]
optimizer = SGD(model, 0.1)
scheduler = ExponentialLR(optimizer, gamma=0.9)
- 训练时,step
model = [Parameter(torch.randn(2, 2, requires_grad=True))]
optimizer = SGD(model, 0.1)
scheduler = ExponentialLR(optimizer, gamma=0.9)
for epoch in range(20):
for input, target in dataset:
optimizer.zero_grad()
output = model(input)
loss = loss_fn(output, target)
loss.backward()
optimizer.step()
scheduler.step()
optimizer.step()用于更新参数,而scheduler的用于调整学习率,这里需要注意scheduler的step要用于epoch上,而不是batch上。
函数衰减-LambdaLR
lr_scheduler.LambdaLR即函数衰减,我们可以自定义一个函数作为乘法因子控制衰减。
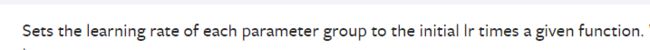
即我们的初始学习率会乘以我们设置函数的结果作为当前的学习率。这个设置的函数会有一个参数,即epoch。
接下来来举个例子
optm = Adam(lr=0.001, params=[
{'params': torch.nn.parameter.Parameter(torch.randn(2, 1)), 'lr': 0.02},
{'params': torch.nn.parameter.Parameter(torch.randn(2, 1))}
])
fun_1 = lambda epoch: 1 / (epoch + 1)
fun_2 = lambda epoch: epoch + 1
scheduler = lr_scheduler.LambdaLR(optm, lr_lambda=[fun_1, fun_2], verbose=True)
这里的fun_1和fun_2是分别对应的两个学习率的函数,一个是调整0.02一个是调整0.001。verbose开启之后,会在控制台输出学习率的调整信息
for epoch in range(5):
optm.zero_grad()
optm.step()
scheduler.step()
"""
Adjusting learning rate of group 0 to 2.0000e-02.
Adjusting learning rate of group 1 to 1.0000e-03.
Adjusting learning rate of group 0 to 1.0000e-02.
Adjusting learning rate of group 1 to 2.0000e-03.
Adjusting learning rate of group 0 to 6.6667e-03.
Adjusting learning rate of group 1 to 3.0000e-03.
Adjusting learning rate of group 0 to 5.0000e-03.
Adjusting learning rate of group 1 to 4.0000e-03.
Adjusting learning rate of group 0 to 4.0000e-03.
Adjusting learning rate of group 1 to 5.0000e-03.
Adjusting learning rate of group 0 to 3.3333e-03.
Adjusting learning rate of group 1 to 6.0000e-03.
"""
我们可以看到这里有两个group,正是对应了我们param_groups里的两个字典里的lr。
我们从上面也可以看出学习率的变化是lr x fun_1(epoch)和 lr x fun_2(epoch)
固定步长衰减-StepLR
StepLR则是类似于越阶式的衰减方式,它的衰减是一个断崖式的下落。
在每经过固定的epoch之后,lr就会乘以一次gamma,即衰减为原来的gamma倍。
optm = Adam(lr=0.1, params=[
{'params': torch.nn.parameter.Parameter(torch.randn(2, 1))}
])
scheduler = lr_scheduler.StepLR(optm, step_size=2, gamma=0.9, verbose=True)
for epoch in range(5):
optm.zero_grad()
optm.step()
scheduler.step()
"""
Adjusting learning rate of group 0 to 1.0000e-01.
Adjusting learning rate of group 0 to 1.0000e-01.
Adjusting learning rate of group 0 to 9.0000e-02.
Adjusting learning rate of group 0 to 9.0000e-02.
Adjusting learning rate of group 0 to 8.1000e-02.
Adjusting learning rate of group 0 to 8.1000e-02.
"""
上面的step_size就是固定的epoch,这里设为2,表示每经过两个epoch就更新一次
我们写一个函数来展示学习率
import matplotlib.pyplot as plt
def plot(optm, scheduler, epoch=100):
x = range(epoch)
y = []
for epoch in range(epoch):
optm.zero_grad()
optm.step()
y.append(optm.param_groups[0]['lr'])
scheduler.step()
plt.plot(x, y)
plt.xlabel('epoch')
plt.ylabel('lr')
plt.legend()
plt.show()
optm = Adam(lr=0.1, params=[
{'params': torch.nn.parameter.Parameter(torch.randn(2, 1))}
])
scheduler = lr_scheduler.StepLR(optm, step_size=5, gamma=0.9)
def plot(optm, scheduler, epoch=100):
x = range(epoch)
y = []
for epoch in range(epoch):
optm.zero_grad()
optm.step()
y.append(optm.param_groups[0]['lr'])
scheduler.step()
plt.plot(x, y)
plt.xlabel('epoch')
plt.ylabel('lr')
plt.legend()
plt.show()
plot(optm, scheduler)

多步长衰减-MultiStepLR
多步长衰减,可以指定衰减的步长区间,举个例子
optm = Adam(lr=0.1, params=[
{'params': torch.nn.parameter.Parameter(torch.randn(2, 1))}
])
scheduler = lr_scheduler.MultiStepLR(optm, milestones=[50, 60, 70, 100], gamma=0.9)
plot(optm, scheduler)
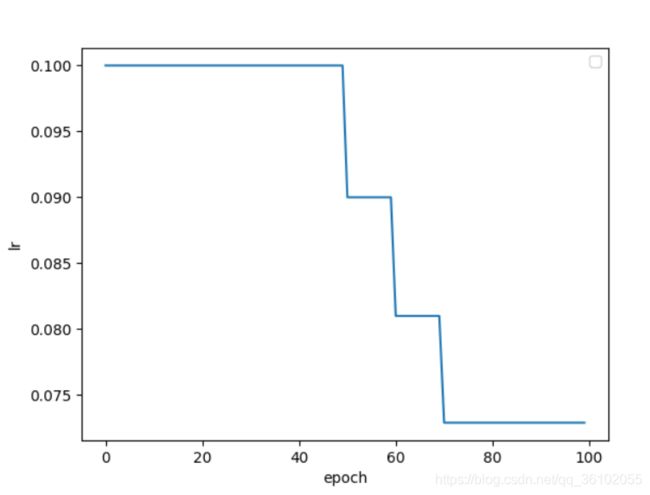
可以看到我们在50, 60, 70时分别更新了一次,这也正是milestones参数所控制的
指数衰减-ExponentialLR
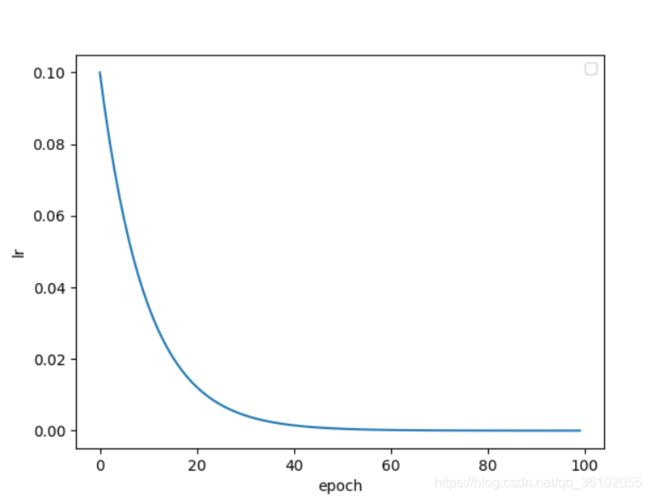
指数衰减,就是每一个epoch都会衰减的StepLR,其gamma就是对应的底数,epoch就是指数
optm = Adam(lr=0.1, params=[
{'params': torch.nn.parameter.Parameter(torch.randn(2, 1))}
])
scheduler = lr_scheduler.ExponentialLR(optm, gamma=0.9)
plot(optm, scheduler)
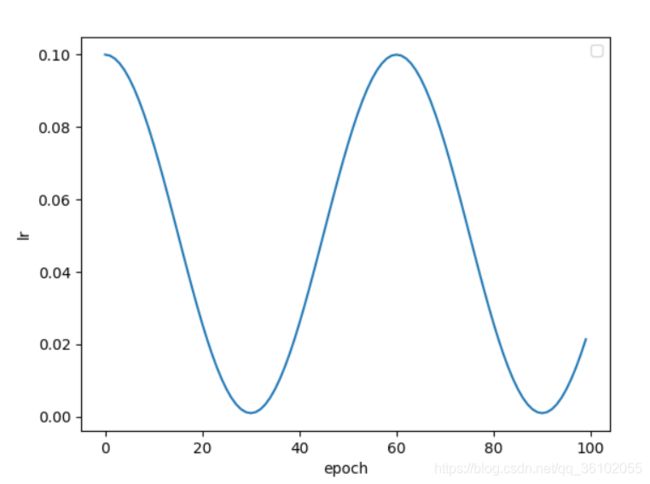
余弦退火衰减-CosineAnnealingLR
余弦退火衰减会使学习率产生周期性的变化,其主要参数有两个,一个是T_max表示周期,一个是eta_min表示学习率的最小值。
optm = Adam(lr=0.1, params=[
{'params': torch.nn.parameter.Parameter(torch.randn(2, 1))}
])
scheduler = lr_scheduler.CosineAnnealingLR(optm, T_max=30, eta_min=0.001)
plot(optm, scheduler)
自定义学习率衰减
有时我们希望自己去调整学习率,比如我们希望使用warm_up策略来调整Transformer学习率。这里我们可以自己写一个函数来封装optimizer,手动修改param_groups里的lr。
warm up
warm up衰减策略与上述的策略有些不同,它是先从一个极低的学习率开始增加,增加到某一个值后再逐渐减少。
这样训练模型更加稳定,因为在刚开始时模型的参数都是随机初始化的,此时如果学习率应该取小一点,这样就不会使模型一下子跑偏。
随着训练的增加,逐渐的模型对数据比较熟悉,此时可以增大学习率加快收敛速度
最后随着参数逐渐收敛,在学习率增大到某个数值后开始衰减。
我们可以用以下这个公式计算这个学习率
L R = i n i t i a l _ l r ∗ m i n ( 1 s t e p , s t e p w a r m 3 2 ) LR=initial\_lr*min(\frac{1}{\sqrt{step}}, \frac{step}{warm^{\frac{3}{2}}}) LR=initial_lr∗min(step1,warm23step)
initial_lr是初始学习率,step是步数,也就是step了几次,这里也可以换成epoch。warm表示热身的步数也就是前面增长的步数。
接下来我们实现这个scheduler
class WarmupLR:
def __init__(self, optimizer, num_warm) -> None:
self.optimizer = optimizer
self.num_warm = num_warm
self.lr = [group['lr'] for group in self.optimizer.param_groups]
self.num_step = 0
def __compute(self, lr) -> float:
return lr * min(self.num_step ** (-0.5), self.num_step * self.num_warm ** (-1.5))
def step(self) -> None:
self.num_step += 1
lr = [self.__compute(lr) for lr in self.lr]
for i, group in enumerate(self.optimizer.param_groups):
group['lr'] = lr[i]