【PyTorch】学习率调整策略汇总
文章目录
-
- 写在前面
- 直接修改
- lr_scheduler
-
- 自定义调整(LambdaLR)
- 等指数调整(MultiplicativeLR)
- 等间隔调整(StepLR)
- 温馨提示
- 引用参考
写在前面
目前pytorch中的学习率调整策略分为两种:
- 直接修改 ;
- 调用
lr_scheduler中封装好的类。
直接修改
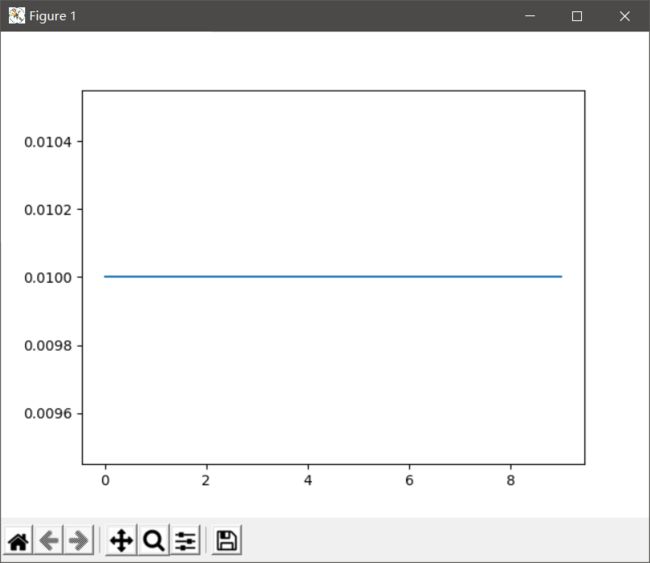
修改前
import torch.nn as nn
from torch.optim import Adam
import matplotlib.pyplot as plt
from torch.optim import lr_scheduler
class Net(nn.Module):
def __init__(self):
super().__init__()
self.main = nn.Linear(1, 1)
def forward(self, x):
return self.main(x)
if __name__ == "__main__":
model = Net()
optimizer = Adam(model.parameters(), lr=0.01)
lr_list = []
for epoch in range(10):
lr = optimizer.param_groups[0]['lr']
lr_list.append(lr)
optimizer.step()
plt.plot(range(10), lr_list)
plt.show()
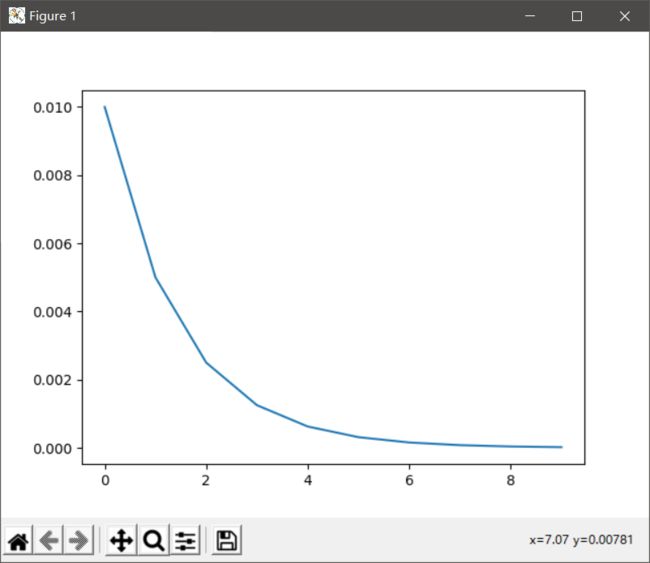
修改后(每经过一个epoch,衰减0.5个乘法因子)
import torch.nn as nn
from torch.optim import Adam
import matplotlib.pyplot as plt
from torch.optim import lr_scheduler
class Net(nn.Module):
def __init__(self):
super().__init__()
self.main = nn.Linear(1, 1)
def forward(self, x):
return self.main(x)
if __name__ == "__main__":
model = Net()
optimizer = Adam(model.parameters(), lr=0.01)
lr_list = []
for epoch in range(10):
lr = optimizer.param_groups[0]['lr']
lr_list.append(lr)
optimizer.step()
optimizer.param_groups[0]['lr']*=0.5
plt.plot(range(10), lr_list)
plt.show()
lr_scheduler
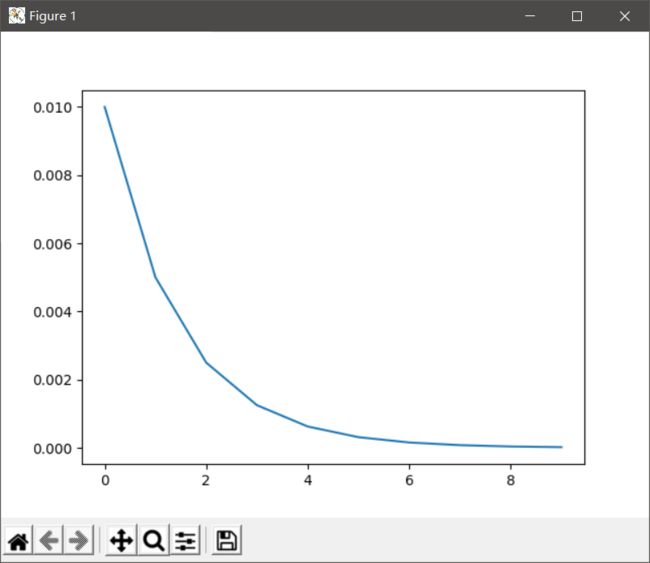
自定义调整(LambdaLR)
CLASS torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=-1, verbose=False)
描述
将每个参数组的学习速率设置为初始lr乘以给定函数。当last_epoch=-1,设置初始lr为lr。
参数
optimizer(Optimizer):优化器。lr_lambda(function or list):给定整数参数epoch计算乘数的函数;或者一个这样的函数列表,对应于optimizer.param_groups中的每一个组。last_epoch(int):上一个epoch的索引。默认是-1。verbose(bool):如果为True,则针对每个更新向stdout打印一条消息;默认False。
示例
import torch.nn as nn
from torch.optim import Adam
import matplotlib.pyplot as plt
from torch.optim import lr_scheduler
class Net(nn.Module):
def __init__(self):
super().__init__()
self.main = nn.Linear(1, 1)
def forward(self, x):
return self.main(x)
if __name__ == "__main__":
model = Net()
optimizer = Adam(model.parameters(), lr=0.01)
scheduler = lr_scheduler.LambdaLR(optimizer, lambda epoch: 0.5**epoch)
lr_list = []
for epoch in range(10):
lr = optimizer.param_groups[0]['lr']
lr_list.append(lr)
optimizer.step()
scheduler.step()
plt.plot(range(10), lr_list)
plt.show()
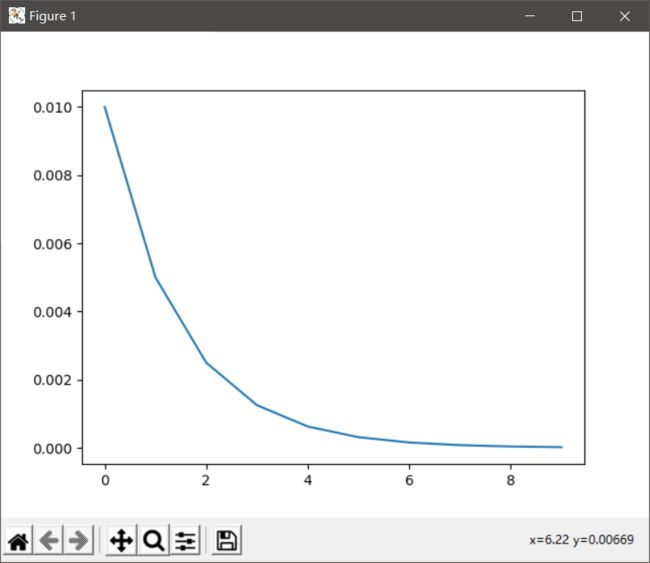
等指数调整(MultiplicativeLR)
CLASS torch.optim.lr_scheduler.MultiplicativeLR(optimizer, lr_lambda, last_epoch=-1, verbose=False)
描述
将每个参数组的学习率乘以指定函数中给定的因子。当last_epoch=-1,设置初始lr为lr。
参数
optimizer(Optimizer):优化器。lr_lambda(function or list):给定整数参数epoch计算乘数的函数;或者一个这样的函数列表,对应于optimizer.param_groups中的每一个组。last_epoch(int):上一个epoch的索引。默认是-1。verbose(bool):如果为True,则针对每个更新向stdout打印一条消息;默认False。
示例
import torch.nn as nn
from torch.optim import Adam
import matplotlib.pyplot as plt
from torch.optim import lr_scheduler
class Net(nn.Module):
def __init__(self):
super().__init__()
self.main = nn.Linear(1, 1)
def forward(self, x):
return self.main(x)
if __name__ == "__main__":
model = Net()
optimizer = Adam(model.parameters(), lr=0.01)
scheduler = lr_scheduler.MultiplicativeLR(optimizer, lambda epoch: 0.5)
lr_list = []
for epoch in range(10):
lr = optimizer.param_groups[0]['lr']
lr_list.append(lr)
optimizer.step()
scheduler.step()
plt.plot(range(10), lr_list)
plt.show()
等间隔调整(StepLR)
CLASS torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1, verbose=False)
描述
每step_size个epoch,通过gamma衰减所有参数组的学习率。需要注意的是,这种衰减可以与外部的学习速率变化同时发生。当last_epoch=-1,设置初始lr为lr。
参数
optimizer(Optimizer):优化器。step_size(int):学习速率衰减周期。gamma(float):学习速率衰减的乘法因子;默认0.1。last_epoch(int):上一个epoch的索引。默认是-1。verbose(bool):如果为True,则针对每个更新向stdout打印一条消息;默认False。
示例
import torch.nn as nn
from torch.optim import Adam
import matplotlib.pyplot as plt
from torch.optim import lr_scheduler
class Net(nn.Module):
def __init__(self):
super().__init__()
self.main = nn.Linear(1, 1)
def forward(self, x):
return self.main(x)
if __name__ == "__main__":
model = Net()
optimizer = Adam(model.parameters(), lr=0.01)
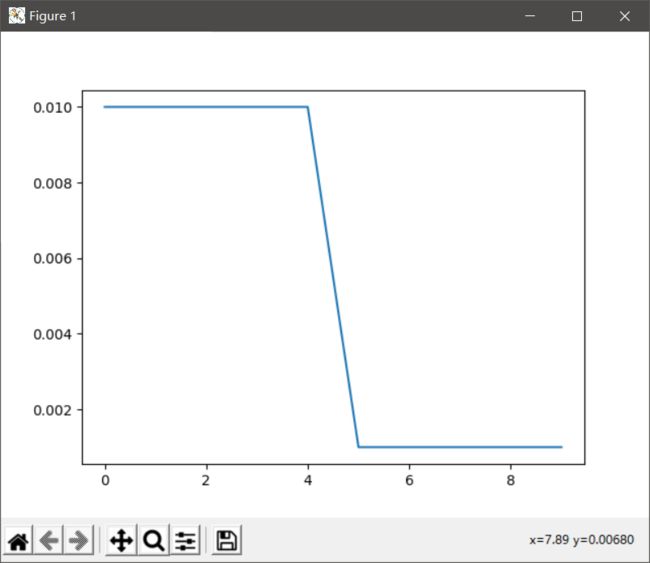
scheduler = lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.1)
lr_list = []
for epoch in range(10):
lr = optimizer.param_groups[0]['lr']
lr_list.append(lr)
optimizer.step()
scheduler.step()
plt.plot(range(10), lr_list)
plt.show()
温馨提示
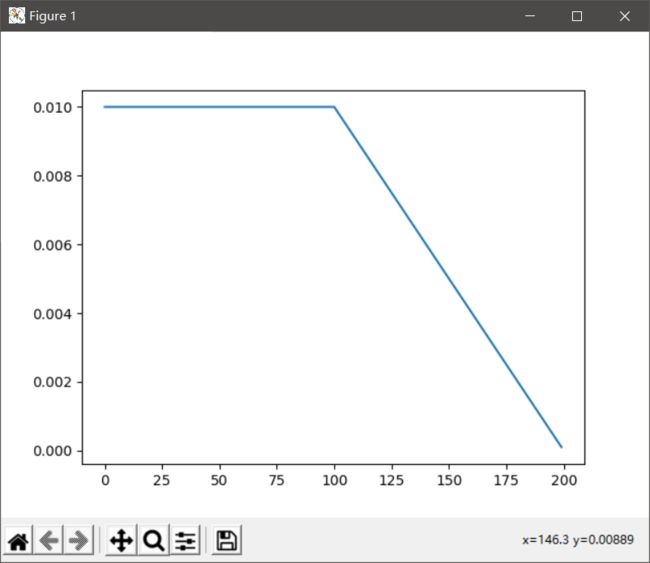
学习率调整策略中最为灵活的还是LambdaLR,可以自定义函数来调整学习率。比如我想实现一个复杂的调整过程:总共200个epoch,前100个epoch保证学习率固定且为0.01,后100个epoch中学习率线性衰减直到0。
import torch.nn as nn
from torch.optim import Adam
import matplotlib.pyplot as plt
from torch.optim import lr_scheduler
class Net(nn.Module):
def __init__(self):
super().__init__()
self.main = nn.Linear(1, 1)
def forward(self, x):
return self.main(x)
if __name__ == "__main__":
model = Net()
optimizer = Adam(model.parameters(), lr=0.01)
scheduler = lr_scheduler.LambdaLR(optimizer, lambda epoch: 1 - max(0, epoch - 100) / 100)
lr_list = []
for epoch in range(200):
lr = optimizer.param_groups[0]['lr']
lr_list.append(lr)
optimizer.step()
scheduler.step()
plt.plot(range(200), lr_list)
plt.show()
引用参考
https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate