
说到计算广告,或者个性化推荐,甚至一般的互联网产品,无论是运营、产品还是技术,最为关注的指标,就是点击率。业界也经常流传着一些故事,某某科学家通过建立更好的点击率预测模型,为公司带来了上亿的增量收入。点击率这样一个简单直接的统计量,为什么要用复杂的数学模型来刻画呢?这样的模型又是如何建立与评估的呢?我们这一期就来谈谈这个问题。
一、为什么要建立一个点击率模型?
无论是人工运营还是机器决策,我们都希望对某条广告或内容可能的点击率有一个预判,以便判断哪些条目应该被放在更重要的位置上。这件事儿看起来并不难,比如说我有十条内容,在历史上呈现出来的点击率各个不同,那么只需要根据历史点击率的统计做决策即可,似乎并没有什么困难。
然并卵。直接统计历史点击率的方法,虽然简单易操作,却会碰到一个非常棘手的问题。首先,大家要建立一个概念:不考虑位置、时间等一系列环境因素,绝对的点击率水平是没有什么太大意义的。比方说,下面的一个广告,分别被放在图中的两个位置上,统计得到前者的点击率是2%,后者的点击率是1%,究竟哪个广告好一些呢?其实我们得不出任何结论。
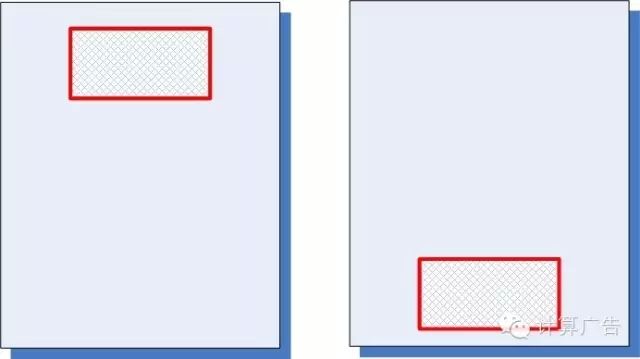
于是,聪明的运营想到一个办法,干脆我在不同的位置上分别统计点击率,然后分别排序。这个思路从道理上来说无懈可击,相当于直接求解联合分布;不过,其实用价值并不高:在每个位置上分别统计,大多数广告或内容条目的数据都太少,比如说100次展示,产生了一次点击,这难道能得出1%点击率的结论么?
那能不能再换一个思路,找到一些影响点击率的一些关健因素,对这些因素分别统计?这实际上已经产生了“特征”这样的建模思路了。比如说,广告位是一个因素,广告本身是一个因素,用户的性别是一个因素,在每个因素上分别统计点击率,从数据充分性上是可行的。不过这又产生了一个新的问题:我知道了男性用户的平均点击率、广告位S平均点击率、某广告A的平均点击率,那么如何评估某男性用户在广告位S上看到广告A的点击率呢?直觉的方法,是求上面三个点击率的几何平均。不过这里面有一个隐含的假设:即这三个因素是相互独立的。然而当特征多起来以后,这样的独立性假设是很难保证的。
特征之间独立性,经常对我们的结论影响很大。比如说,中国的癌症发病率上升,到底是“中国”这个因素的原因呢?还是“平均寿命”这个因素的原因呢?显然这两个因素有一些相关性,因此简单的分别统计,往往也是行不通的。
那么怎么办呢?这就要统计学家和计算机科学家出马,建立一个综合考虑各种特征,并根据历史数据调整出来的点击率模型,这个模型既要考虑各种特征的相关性,又要解决每个特征数据充分性的问题,并且还要能在大量的数据上自动训练优化。这就是点击率模型的意义,这是一项伟大的、光荣的、正确的、有着极大实用价值和战略意义的互联网+和大数据时代的重要工作。那位说了,有必要抬得这么高么?当然有必要!因为这门手艺我也粗通一点儿,不吹哪行。
二、怎样建立一个点击率模型?
这个问题比较简单,我们就不多谈了。(想骂街的读者,请稍安勿躁,继续往下看。)
三、如何评估一个点击率模型?
评估点击率模型的好坏,有各种定性的或定量的、线上的或线下的方法。但是不论什么样的评测方法,其本质都是一样,就是要看这个模型区别被点击的展示与没被点击的展示之间的区别。当然,如果能找到一个离线可以计算的量化指标,是再好不过了。
这样的指标是有一个,就是如下图所示的ROC曲线下的面积,术语上称为AUC。(关于ROC和AUC的详细介绍,请大家参考《计算广告》第*章。)AUC这个数值越大,对应的模型区别能力就越强。
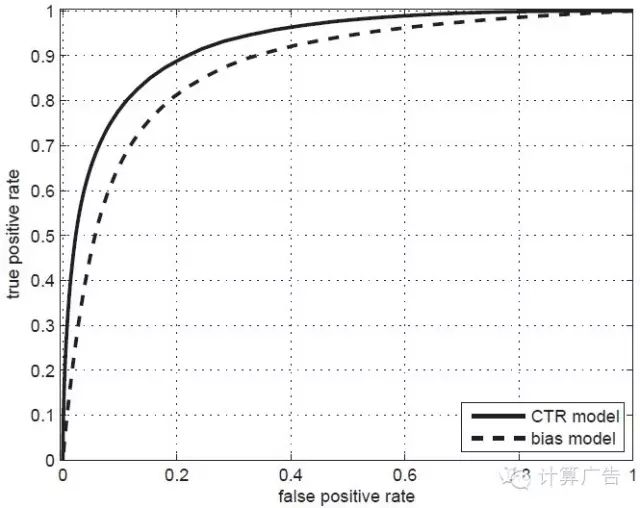
好了,为了让大家深入理解点击率模型评测的关键,我们要谈到一个常见的口水仗:有一天,有两位工程师在闲谈,一位叫小优,一位叫小度。他们分别负责某视频网站和某网盟广告的点击率建模。小优说:最近可把我忙坏了,上线了个全新的点击率模型,把AUC从0.62提高到0.67,效果真不错!哪知道小度听了哈哈大笑:这数据你也好意思拿出来说,我们的AUC早就到0.9以上了!
那么,是不是小度的模型比小优真的好那么多呢?当然不是,我们看看该视频网站和网盟的广告位分布,就一目了然了。
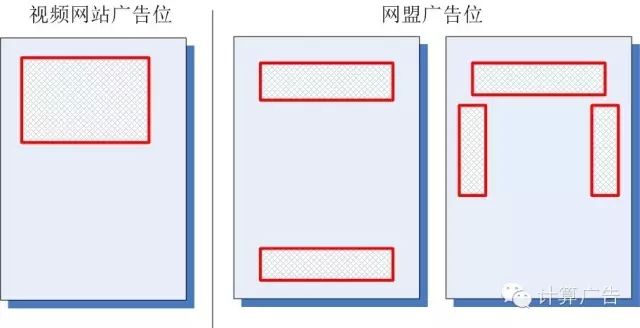
什么?你还没有明白,那么我建议你自己好好把这个问题想清楚。不论你是运营还是产品,经过了这样的思考,你的数据解读能力会上一个台阶。
好了,三个关键点说完了,我知道有的读者还会对第二点表示没看懂,那干脆我们就再多说一点儿,将2015年11月15日王超在计算广告读者微信群里所做的题为“点击率预估趋势浅析”的分享内容整理发布在下面。没有坚持到这里就把文章关掉的码农们,让他们后悔一辈子去吧!
今天分享一下点击率预估近年来的一些趋势。主要结合刘鹏老师的一些指导,以及自身工作的一些经验,有偏颇的地方请大家多多指正。
在计算广告第一版的书里,主要讲到了经典的点击率预估模型逻辑回归,特征工程,模型的评估等,相信对大多数场景来说这一步是必做的基线版本。后续可以在此基础上做一些更细致的特征工程和模型工作。考虑到群里的朋友都已经拿到了这本书,今天先跳过书里覆盖的内容,讲一些目前书里没有提及的部分。如果对书里内容还不够了解的朋友,建议第一步还是把书中基础性的内容仔细掌握。
LR+人工特征工程风光不再
讲近年来点击率预估的发展趋势,我想先从近年来一次最具参考意义和号召力的criteo举办的点击率预估比赛作为切入点说起。
为什么要拿这次比赛来说?首先criteo是全球一家专注在效果广告的公司,在业界很有影响力,计算广告书中对其也有介绍,比赛的数据质量不错。其次前三名有10w美金的激励,继KDD cup 2012 track2之后,算是点击率预估问题上最知名的一次比赛,很多kdd cup的往届冠军都前来参加。最后呢这次比赛都是脱敏过的特征,没有具体的特征含义,使得难以结合领域知识做更细致的特征工程,更多考量模型的工作,比较适合我们今天讨论的话题,另外比赛时间是从去年6月到9月三个月的时间,参赛者们的方案相对也会比较细致。
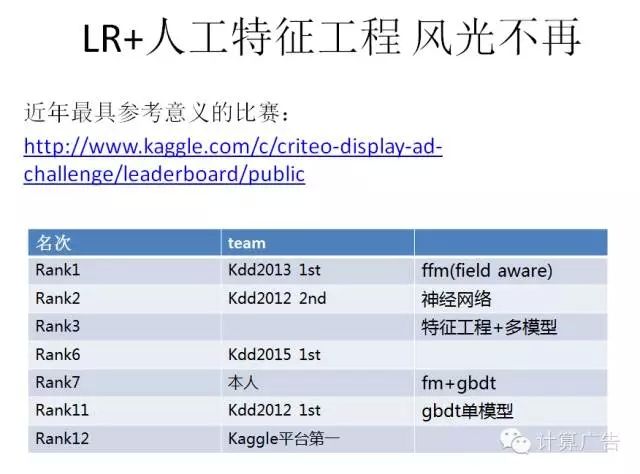
从leadboard中可以看到在700多支team里,Kdd 2012年起的各届冠军,这些比赛型的选手,基本占据了前十的位置,我是第7。其次,从使用的模型上,基本以fm和gbdt,还有神经网络这些非线性模型为主。可以这么说,在比赛里,逻辑回归加大量的人工特征工程的方案已经很难排到比赛前列,靠逻辑回归一个模型包打天下,已经成为过去时。
特征,特征

在接下来讲具体模型之前,先来回顾一下我们为什么要做大量的特征工程。点击率预估的主要场景,是在各种长尾的流量上,对一个给定的<用户,广告,上下文>三元组做出精准估计。在这种long tail的场景下,用户或上下文对广告的偏好,基本都是一些相对weak的signal,我们需要把这些弱信号package在一起,才能去更好的发现当前场景下用户感兴趣的广告。
特征工程是各个公司相对模型来说更看重保密的部分,因为从其中会大致了解到该公司的数据分布,这方面的公开资料不会太多。大体来说,有这么俩部分工作:
首先了解行业的领域知识,去寻找和设计强信号依然重要,比如搜索广告里query和广告创意的相关性是强信号,电商领域图片和价格特征是强信号等。这部分工作是和各家公司业务紧密相关的。
其次如果采用的是逻辑回归这种广义线性模型,需要手动构造特征变换,才能更好处理非线性问题。常见的特征变换方法比如特征组合,特征选择,特征离散化归一化等,多数时候通过eyeballing和统计学的方法来完成。工程师自然是希望能将更多的精力放在设计业务上的强信号特征上面,而特征变换自动的由模型来完成。出于这样的考虑,非线性模型逐渐在取代LR,比如通过FM,GBDT去自动挖掘组合特征,通过GBDT去做特征选择,离散化等,正如上述比赛中看到的。
最后基于一些深度学习的方法,也能够做一些特征发现的事情,举个典型的例子就是语音识别里,dnn已经把MFCC这种人工特征取代了,wer有显著的降低。而在广告领域,DNN目前基本在百度等大公司也正在探索中,发展比较快,这部分今天简单提一下。
模型选择

点击率预估的模型,如果包括各个模型的变种,可能不下数十种。根据自己的业务如何选择相关的模型,我想从三个维度说下个人选择模型时候的观点,偏颇之处请大家多多指正。
第一,线性模型还是非线性模型。一般在模型的初期线性模型会作为首选方法采用,有经验的工程师对业务领域中的强信号比较熟悉,能够快速rush完几个版本的特征工程后达到一个不错的基线水平。而当从业务中抽象出强信号越来越困难时,往往就会伴随着比较暴力的特征工程去捕捉业务里的弱信号。随着这一过程的深入,模型训练的代价在快速增长,而收益却逐渐逼近上限。而非线性模型的长期优势则比较明显,模型泛化能力强,调参成本相对较小,能在训练代价和模型精度上达到更好的tradeoff,百度等大公司都已经从LR过渡到了DNN。
第二,基于Sparse的特征(静态特征)建模,还是Dense的特征(动态特征)建模。这一点可能没有细看书的朋友不太熟悉,简单说就是当某个特征被触发时,不再用1,而是用这个特征历史上一段时间(或者多个时间窗口)的点击率作为其特征取值。当特征动起来以后,通过特征侧捕捉动态信号,模型就不用快速更新了,可以说dense建模的方案相对更加简单优雅。曾经做过这样的实验,当采用动态特征加Offline模型,和静态特征加Online模型,俩者收益是相当的。
这里补充重点说明一点,如果基于sparse特征建模的话,knowledge完全存储在模型处,而基于dense特征建模,知识存放在模型和特征(点击率)俩处,喂给模型的点击率特征是否置信,直接决定了这个方案的鲁棒性。这里有俩个问题,一个是在某些场景下,点击率是有bias的,比如展示广告里,头部流量上点击率被高估,点击率高是因为其广告位置比较好,如果不消去bias,则会产生强者愈强的马太效应。另一个问题是长尾流量上,对于某个特征值的pv较少,ctr不再置信,也需要去平滑。计算广告书中针对这俩个问题介绍了相关的方案COEC+平滑可供参考。
第三,应用Online的更新方式去更新模型,还是batch的方式。Online的方式对应的最优化算法主要是minibatch sgd,Offline的方式可以应用计算广告书里说的LBFGS,Trust region这些。按我个人经验,minibatch sgd的更新方式对头部的数据学习的会更快更充分,因此更善于fine tuning the head part。而Offline的方式全局优化历史数据,对于长尾稀疏特征,就比sgd的方式要精细些了。如果业务场景时效性较强,更关注头部,用一个Online keep更新的模型就足够了,比如新闻推荐的场景。但是如果业务场景有很多长尾流量,需要精细的预估,一个batch的Offline model是必要的,为了业务的时效性考虑,可以用batch的模型结果去初始化Online的模型更新,定期的batch结合Online的delta更新,比如搜索广告的场景。
模型演进概述
上述的模型选择都是结合业务场景做出的选择,这里按我个人理解给出一个连贯一些的点击率预估模型演进的过程:
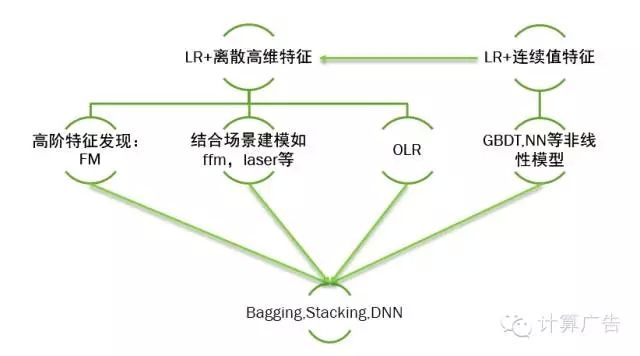
之前提及过,一般会以高维sparse特征的LR模型作为基线模型,也有用dense特征直接结合LR来建模的。由于LR是线性分类器,后者需要对dense特征手工加各种非线性变换,遇到瓶颈后会转向前者,或者改成使用GBDT,NN等非线性模型。而高维sparse特征结合LR的方案,人工在特征工程遇到一定瓶颈后,会采用FM等方案自动做特征发现,为了解决时效性的问题,会结合batch的训练加上Online的更新方式,或者直接转向完全Online的方案如ftrl。还有一个方向是会结合自身的业务场景,对模型的损失函数做一些创新,比如yahoo的laser,阿里的coupled group lasso,比赛里的field aware的ffm等等。
在比赛里为了提升效果,很常见的一个策略是把各个模型融合在一起,最简单的有把各个模型的结果做线性加权,也有把各个模型进行stacking的方案,比如Facebook的gbdt+lr,再有把各个模型的信息喂给dnn去学习的。对这三种方案来说,效果最好的,我个人比较相信,是用dnn去做模型的blending(融合)。注意这里说的DNN不是指具体的某个模型dbn,cnn,而是指将各种浅层模型的中间权重,预估结果,原始的静态,动态特征等作为DNN的输入,使用dnn后馈的输入梯度来联合更新这些结构的参数。对DNN大家可能比较诟病的是其训练效率,但我觉得在大公司可能还好,听在百度的朋友说DNN的开发代价和训练开销随着探索在逐步降低,不一定比gbdt等非线性模型代价高很多。
当然,对小公司来说,直接走到DNN有点用力过猛,我在这里简要介绍一下FM+gbdt去融合的方案:第一步当然也是基于大规模稀疏特征LR。第二步,为了更好的刻画长尾,自动发现组合特征,采用了FM。在同样的训练时间下,AUC提升,模型泛化性能可控。第三步:为了更好的fine tuning头部和提升时效性,采用了用gbdt加动态特征的模型。最后呢,把这两个模型简单的做线性融合,由于俩个模型的特征和模型差异性较大,融合后auc也有显著的提升。
对于gbdt,开源的实现有很多,但效果差别比较大,这里推荐一个开源实现xgboost,很多kaggle上的比赛借助这个工具都拿到了好名次。之前我写过一篇叫做xgboost导读和实战的文章,对原始paper中的公式给出了一些推导细节,这里不再详述。简单的说原始paper里是在函数空间上梯度下降求解,在求解步长时一般都是固定学习率。而xgboost对损失函数做了二阶的泰勒展开,考虑了损失函数的二阶梯度信息,并加入了正则项整体求最优解,有比较好的泛化性能。另外在具体建树的分裂节点过程也不是大多数实现里基于信息增益等,而是结合具体目标函数的真实下降量。有人做过各实现的评测,xgboost在性能和效果上都是相当不错的。
BSP->SSP
几个典型的模型基本就简要讲到这里,最后讲一下模型求解的优化算法,计算广告书里给出了不少经典的优化凸优化算法的原理和实现代码,LBFGS,trust region等,这些凸优化算法基本上都是扫一遍样本,迭代的更新一次模型参数,想要提升模型训练收敛的效率,主要思路是降低扫样本的成本,比如把样本cache在内存里,另外就是降低迭代轮数,比如书里提到的admm。
这样的batch做迭代的优化方法现在被称为一种叫做BSP(Bulk Synchronous Parallel)的方式,与之相对应的叫做SSP(StalenessSynchronous Parallel),主要是基于异步的minibatch sgd的优化算法来更新,加上了一个bounded的一致性协议来保证收敛。补充一点的是,很多实现中其实是完全异步来实现的,更为简单一些。SSP的方式虽然单轮迭代的网络开销不小,但是扫一遍样本,minibatch sgd可以更新很多次模型,迭代的次数相对LBFGS会降低很多,所以整体的时间开销相对也会少很多,另外可以结合online更新进一步降低训练时间。从底层消息通讯的工程架构上来说,ssp的方式主要是异步的push pull,基于消息队列如zeromq等去实现,相对bsp的这样的同步原语,实现起来相对简单优雅些,也有一些不错的开源实现比如李沐的dmlc。
ssp方式的缺点是数据量少的时候minibatch sgd的优势相对不明显,需要多调调参数,没有batch算法省事。总体说来,趋势是在从bsp的架构往ssp的架构在转,包括一些dnn的实现,基于SSP的方式加Online更新后训练模型的开销相对已经较小了。
·END·
本文由计算广告授权梅花网转载,版权归原作者所有,未经授权,请勿转载,谢谢!
点击率预估的几个经典模型简介

点击率预估是大数据技术应用的最经典问题之一,在计算广告,推荐系统,金融征信等等很多领域拥有广泛的应用。本文不打算对这个话题做个全面叙述,一方面这过于庞大,另一方面也已经有很多文章和演讲材料相当不错。本文只打算对已有的一些文字作个补充,从贴近实际的角度列举一些经过商业检验的点击率模型。
最经典的模型当然是逻辑回归,这是绝大多数商业公司的选择,简单的逻辑回归有实现容易,训练快速等优点。自从逻辑回归出现后,针对它的改进主要围绕两方面:如何正则化;如何最优化。正则化是机器学习的重要技术,它的主要目的是让防止模型过拟合,目前比较常用的正则化有L1和L2。通常L2在减少预测错误上表现更好,这是因为当两个特征相关时,L1会只选择一个,而让另外一个系数为0,因此可以产生稀疏解;而L2则会同时保留2个特征然后另它们的权重系数收缩。因此在数据维度有限时,L2会既有防止过拟合的优点,还不会导致模型预测损失。然而对于大规模机器学习框架,L1的稀疏解会更有吸引力,加入L1正则化的损失函数在优化后,绝大多数特征的权重都是0。这个特性可以大大减少点击率预估时的内存占用,并提高预测的速度。关于最优化,因为逻辑回归的损失函数是一个可以求导的凸函数,所以通常可以采用梯度下降或者拟牛顿进行最优化。不论是梯度下降,还是拟牛顿,都是频率派的最优化手段,贝叶斯学派也有自己的手段,这就是微软的AdPredictor提出的Bayesian Probit Regression[3]。AdPredictor有一些比较好的特性:它只需要一次迭代就可以收敛到最优解,而不是像梯度法或者拟牛顿法那样需要反复迭代;它不仅能预测出一个样本是正样本的概率,而且还可以给出对于这个概率预测值的置信度,因此很多在线广告公司都采用AdPredictor作为其点击率预估的方法。由于AdPredictor假设特征权重的先验分布遵循高斯分布,因此它相当于是L2正则化,这在许多大规模场景下难以接受,因此Google在13年发表的FTRL-Proximal提供了既是L1正则化,又具备AdPredictor优点的方案,FTRL-Proximal公式较多,读者可以从[7]获得更完整的叙述。
另一方面,回到模型本身,采用简单的线性模型会导致其他一些问题,比如高维场景下,究竟应当如何选择特征,大部分公司以来人工特征工程,随着过程深入,这种方式的收益会逐步达到上限。此外,简单线性模型无法捕捉特征之间的关联,这对于提升长尾用户行为的点击率尤其关键。有一些公司在这些方面也做了不少工作。首先比较重要的是Facebook的工作[4],它的主要贡献在于通过利用非线性模型GBDT来进行特征选择,GBDT的输出作为线性模型逻辑回归的输入,通过这样的级联产生了明显的提升。这种手段应当可以作为新一代点击率预估系统的标准配置。
关于特征关联发现,先来看看排名第一的重定向广告公司Criteo的工作,在其点击率方案中[5]直接利用x_u*M*x_a来修正sigmoid函数,其中M为一个矩阵,x_u和x_a分别代表用户和广告特征,因此矩阵的大小取决于用户和广告特征的基数。通常,这两个数字都会很大,因此矩阵就会变得非常很大和稀疏,Criteo主要是借助于特征Hashing来减少矩阵尺寸,但这会导致冲突情况下无法判断是哪些特征组合信号强的问题。
再来看看Linkedin的LASER系统,由于LASER的作者源自Yahoo内容优化和推荐引擎团队,因此我们可以认为LASER跟Yahoo的工作如出一辙。
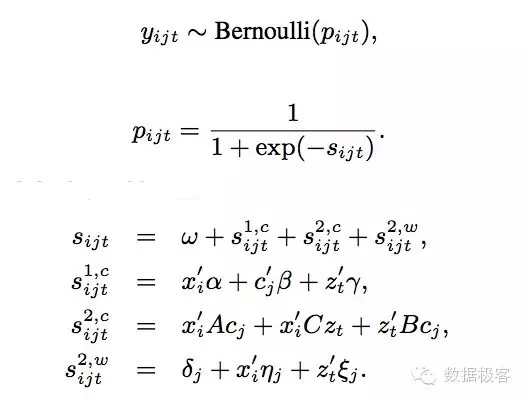
LASER点击率预估系统建模跟Criteo类似,都很简单直接,但是引入了上下文信息和更多特征。Y_ijt表示用户i对于广告j在上下文t下是否会点击。相比传统的逻辑回归只用简单的单一种类特征,LASER同时引入了用户特征x_i,广告特征c_j,以及上下文特征z_t,并且还要考虑这些特征之间的相互关联信息。这种建模的思路是解决冷启动问题的有效方式,因为这意味着即便没有很多的用户行为数据,也可以根据特征之间的关联信息作出不算太离谱的预测,当然,如果能够有用户行为数据,则可以锦上添花,为此,LASER把传统逻辑回归的Logit对数差异函数s_ijt分成图中所示的三个组成部分:第一个部分表达了概率密度跟所有一阶特征的关系;第二部分表达了概率密度跟所有特征之间关联程度的关系,包括用户特征和广告特征之间,广告特征和上下文特征之间,以及用户特征和上下文特征之间三种关联,因此称为二阶特征。整个模型如果光有这部分数据,也能够做出比较靠谱的预测,因此把这两部份加起来称作冷启动。相比之下,第三部分称作为热启动,用来表示用户当前对于冷启动选择出的Top K广告的偏好转移,为便于快速实时计算,这部分只包含广告和上下文的一阶特征。
可以看到,冷启动部分是LASER的主要工作,为训练这部分模型,LASER采用了交替方向乘子ADMM算法和L2正则化。ADMM是一种求解优化问题的计算框架,适用于求解分布式凸优化问题,ADMM 通过将大的全局问题分解为多个较小、较容易求解的局部子问题,并通过协调子问题的解而得到大的全局问题的解。在高精度要求下,ADMM 的收敛很慢;但在中等精度要求下,ADMM 的收敛速度可以接受(几十次迭代),因此ADMM非常适合大规模机器学习使用。在LASER里,又采用了一些额外优化,比如在不同分区同时进行计算,然后拿各分区的均值作为ADMM初始化参数,并且动态调节各分区计算的步长,这样在实际中把ADMM的迭代次数可以降到更低(如十多次迭代),因此一方面提升了训练性能,另一方面,也让整个冷启动部分的训练可以在一些不适合机器学习的框架如Hadoop上运行良好。在Spark还不稳定的2013年,这样做的价值是显而易见的。在稀疏方面,LASER没有考虑太多,因此大规模特征,比如百万维以上,是不能采用的。
再来看看阿里的[2]CGL,意思是Coupled Group Lasso,就是在损失函数中分别用Group Lasso去正则化用户特征和广告特征。在文章前边我们提到逻辑回归正则化主要有L1和L2,其中L1也可叫Lasso,L2也可叫Ridge,除了L1和L2之外,还有一些其他的手段,比如结合L1和L2优点的Elastic Net,而Group Lasso是对Lasso的推广,通过预先定义分组,以组为单位进行变量选择。为了建模特征之间的关联,CGL把普通逻辑回归的sigmoid函数修改为如下:
其中x_u和x_a分别代表用户和广告特征,因此x_u*M*x_a就可以表征特征之间的关联,而把矩阵M分解W*V'后就可以转化成图中的形式。采用这种方法改写的原因是避免引入过于庞大的M矩阵,因此模型的参数可以少很多。
在解决特征组合的手段中,除了上面提到的针对逻辑回归的工作之外,还有FM(Factorization Machine),FM的建模跟LASER其实有一些类似,看下边公式就知道了,都是把线性关系和特征笛卡尔积共同列出做统一优化,因此也具备特征关联发现功能。
在以FM为核心的几个方案赢得一些点击率预估大赛之后,FM已经为更多的公司所接受,从竞赛和学术方案走向商业成熟。
前边列举的主要是机器学习手段,而我们知道深度学习系统也能够给点击率预估带来很大收益,百度是这方面的先行者之一,由于相关资料少我们就不单独列举了。由于LASER是笔者团队曾经实现的系统,因此篇幅有些不合时宜得多。关于如何设计一个现代的点击率系统,请诸位参考德川同学撰写的“关于点击率模型,你知道这三点就够了”一文,德川同学采用的GBDT+FM,是经过商业检验的优秀方案,也是非基于深度学习的点击率预估系统的最佳实践之一。
参考文献:
[1] LASER: A Scalable Response Prediction Platform For Online Advertising, Deepak Agarwal, WSDM 2014
[2] Coupled group lasso for web-scale ctr prediction in display advertising, Yan, Ling and Li, Wu-jun and Xue, Gui-Rong and Han, Dingyi, ICML 2014
[3] Web-scale bayesian click-through rate prediction for sponsored search advertising in microsoft's bing search engine, Graepel, Thore and Candela, Joaquin Q and Borchert, Thomas and Herbrich, Ralf, ICML 2010
[4] Practical lessons from predicting clicks on ads at facebook, He, Xinran and Pan, ADKDD 2014
[5] Simple and scalable response prediction for display advertising, Chapelle, Olivier, ACM Transactions on Intelligent Systems and Technology 2014
[6] Click-through prediction for advertising in twitter timeline, Li, Cheng and Lu, Yue and Mei, Qiaozhu, SIGKDD 2015
[7] 冯扬, 在线最优化求解