python 线程、进程与协程 (十)
(一)线程与多线程
线程
(1) 线程,有时被称为轻量级进程(Lightweight Process,LWP),是程序执行流的最小单元。
(2)一个标准的线程由线程ID,当前指令指针(PC),寄存器集合和堆栈组成。有了这些它能够记录自己运行到了什么地方,可以称为线程的上下文。
(3)线程的运行可能被抢占(中断)或暂时的被挂起(也叫睡眠)让其它的线程运行,这叫做让步。
(4)线程也有就绪、阻塞和运行三种基本状态。就绪状态是指线程具备运行的所有条件,逻辑上可以运行,在等待处理机;运行状态是指线程占有处理机正在运行;阻塞状态是指线程在等待一个事件(如某个信号量),逻辑上不可执行。
(5)线程是进程中的一个实体,是被系统独立调度和分派的基本单位,线程自己不独立拥有系统资源,但它可与同属一个进程的其它线程共享该进程所拥有的全部资源。
多线程
(1)每一个应用程序都至少有一个进程和一个线程。线程是程序中一个单一的顺序控制流程。在单个程序中同时运行多个线程完成不同的被划分成一块一块的工作,称为多线程。
很好理解,开发软件就是每个人或者每个小组负责一个模块,当所有人(组)相关的模块都编写完后,就开始合并代码,然后就测试,修复bug。
(2)除非代码依赖第方资源,否则在单处理器的机器上使用多线程,不会加速代码的执行速度,甚至会增加一些线程管理的开销。
实际上,在单处理器的系统中,每个线程会被安排成每次只运行一小会,然后就把CPU让出来,让其它的线程去运行。比如线程切换等等,这些都是要花费资源和时间的,所以在单CPU机器上使用多线程有时候不但感觉不到执行速度变快,反而变慢了。
(3)多线程会从多处理器或者多核的机器上获益,它会在每个处理器上并行执行每个线程,从而提高执行速度。
(4)线程之间可以共享运行结果。但是这样做有一定的危险,比如两个线程更新同一个数据,但是这两个线程运行的结果不一样,这叫做竞态条件,这个会造成竞争危害,会发生不可预测的结果。所以利用锁机制可以保护数据。
Python中的多线程
python的多线程并没有想象中的那么理想,是因为有一个叫GIL的东西在限制。那什么是GIL呢?GIL中文名叫全局解释器锁,是python虚拟机上用作互斥线程的一种机制,它的作用就是要保证在任何情况下虚拟机上只有一个线程被运行,而其它线程都处在等待GIL锁被释放的状态。所以它是个“伪多线程",它的情况就跟上面说的在单处理器机器上运行多线程一样,不会加速代码的执行速度,甚至会增加一些线程管理的开销。
python虚拟机上多线程是按如下方式执行的:
a、设置 GIL
b、切换到一个线程去运行;
c、运行指定数量的字节码指令或者线程主动让出控制(可以调用 time.sleep(0));
d、把线程设置为睡眠状态;
e、解锁 GIL;
f、再次重复以上所有步骤
在调用外部代码(如 C/C++扩展函数)的时候,GIL将会被锁定,直到这个函数结束为止(由于在这期间没有Python的字节码被运行,所以不会做线程切换)。比如带有I/O操作(会调用内建的操作系统C代码,I/O操作就是输入输出操作,要想详细了解它可以参考其它资料)的线程,GIL会在这个I/O操作被调用之前就被释放。
对于纯计算的程序,没有I/O操作,解释器会根据sys.ssetcheckinterval()的设置来自动进行线程间的切换,默认情况下是每隔100个时钟就会释放GIL锁从而轮换到其它线程执行。
那为什么Python中还要在多线程中引入GIL呢?是为了保证对虚拟机内部共享资源访问的互斥性。python对象的对象管理与引用计数器密切相关,当计数器的值为0,该对象会被垃圾回收器回收(不了解这块知识的可以在网上查找相关资料或者看《Python源码解析》这本书),当撤销对一个对象的引用时,python解释器会对该对象以及其计数器管理进行以下两步操作:
a.使引用计数器减1
b.判断计数器的值是否为0,如果为0,则销毁该对象
假设现在有A、B两个线程同时引用同一个对象obj,这时obj对象的引用计数器的值就为2,如果现在A线程打算撤销对obj的引用,当执行完第一步”使引用计数器值减1“的时候,由于存在多线程调度机制,A恰好在这个关键点被挂起了,而进入了B线程执行的状态,如果这个时候B线程也是要撤销对obj的引用,并且完成了上面的a,b两个步骤,这时obj的引用计数器就是0了,obj对象就被销毁了,内存被释放出来了,麻烦就可能出现了,当A线程再次被唤醒时,它肯定会接着执行上面的b步骤,结果发现已经面目全非了,那么其操作结果完全未知。所以引入了GIL,保证对虚拟机内部共享资源访问的互斥性。
GIL的引入使多线程不能在多核系统中发挥优势,但也带来了一些好处,就是大大简化了Python线程中共享资源的管理。不过Python提供了其它方式绕过了GIL的局限性来充分利用多核的计算能力,比如多进程multiprocessing模块、C语言扩展方式、ctypes库等等。
(二)进程
进程(有时被称为重量级进程)是程序的一次执行。每个进程都有自己的地址空间、内存、数据栈以及其它记录其运行轨迹的辅助数据。操作系统管理在其上运行的所有进程,并为这些进程公平地分配时间。进程也可以通过fork和spawn操作来完成其它的任务,不过各个进程有自己的内存空间、数据栈等,所以只能使用进程间通讯(IPC),而不能直接共享信息。
(三)协程
(1)协程是一种用户级的轻量级线程,不同于线程的地方在于协程不是操作系统进行切换,而是由程序员编码进行切换的,也就是说切换是由程序员控制的,这样就没有了线程所谓的安全问题。
(2)协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈。
python里面怎么使用协程?答案是使用gevent模块。使用协程,可以不受线程开销的限制。所以最推荐的方法,是多进程+协程(可以看作是每个进程里都是单线程,而这个单线程是协程化的)多进程+协程下,避开了CPU切换的开销,又能把多个CPU充分利用起来。
threading模块
下面来讲讲Python的threading模块。首先来看看threading模块有哪些方法和类吧。

主要有:
Thread :线程类,这是用的最多的一个类,可以指定线程函数执行或者继承自它都可以实现子线程功能。
Timer:与Thread类似,但要等待一段时间后才开始运行,是Thread的子类。
Lock :原锁,是一个同步原语,当它锁住时不归某个特定的线程所有,这个可以对全局变量互斥时使用。
RLock :可重入锁,使单线程可以再次获得已经获得的锁,即可以被相同的线程获得多次。
Condition :条件变量,能让一个线程停下来,等待其他线程满足某个“条件”。
Event:事件对象,是线程间最简单的通信机制之一:线程可以激活在一个事件对象上等待的其他线程。
Semaphore:信号量对象,是个变量,管理一个内置的计数器,指定可同时访问资源或者进入临界区的线程数。
BoundedSemaphore :有界信号量对象,与semaphore类似,但不允许超过初始值;
ThreadError:线程错误信息类。
active_count()和activeCount():返回当前活着的Thread对象个数。
current_thread()和currentThread():返回当前的Thread对象,对应于调用者控制的线程。如果调用者控制的线程不是通过threading模块创建的,则返回一个只有有限功能的虚假线程对象。
enumerate():返回当前活着的Thread对象的列表。该列表包括守护线程、由current_thread()创建的虚假线程对象和主线程。它不包括终止的线程和还没有开始的线程。
settrace(func):为所有从threading模块启动的线程设置一个跟踪函数。在每个线程的run()方法调用之前,func将传递给sys.settrace()(该函数是设置系统的跟踪函数)。
setprofile(func):为所有从threading模块启动的线程设置一个profile函数。在每个线程的run()调用之前,func将传递给sys.setprofile()(这个函数用于设置系统的探查函数)。
stack_size([size]):返回创建新的线程时该线程使用的栈的大小,
可选的size参数指定后来创建的线程使用栈的大小,它必须是0(使用平台的或者配置的默认值)或不少于32,768(32kB)的正整数。
其它一些以"_"开头的,有些是引入其它模块的函数,然后起了个别名,比如_format_exc,它的定义如下:
其它一些以"_"开头的,有些是引入其它模块的函数,然后起了个别名,比如_format_exc,它的定义如下:
from traceback import format_exc as _format_exc
有些其实是类,比如RLock的定义如下:
def RLock(*args, **kwargs):
"""Factory function that returns a new reentrant lock.
A reentrant lock must be released by the thread that acquired it. Once a
thread has acquired a reentrant lock, the same thread may acquire it again
without blocking; the thread must release it once for each time it has
acquired it.
"""
return _RLock(*args, **kwargs)
_RLock其实是个类,内部调用的类,RLock其实是个函数,返回一个类,感兴趣的可以去看看threading.py相关代码。
由于篇幅比较长,不正之处欢迎批评指正,当然更希望大家有耐心、仔细看完,同时能实践一下示例并仔细体会。
(一)Thread对象
这个类表示在单独的一个控制线程中运行的一个活动。有两种创建方法:创建线程要执行的函数,把这个函数传递进Thread对象里,让它来执行;而是从Thread类中继承,然后在子类中覆盖run()方法,在子类中不应该覆盖其它方法(init()除外),也就是只覆盖该类的__init__()和run()方法。
Thread类主要方法:
start():开始线程的活动。每个线程对象必须只能调用它一次。
run():表示线程活动的方法,可以在子类中覆盖这个方法。
join([timeout]):是用来阻塞当前上下文,直至该线程运行结束,一个线程可以被join()多次,timeout单位是秒。
name:一个字符串,只用于标识的目的。它没有语义。多个线程可以被赋予相同的名字。初始的名字通过构造函数设置。
getName()/setName():作用于name的两个函数,从字面就知道是干嘛的,一个是获取线程名,一个是设置线程名
ident:线程的ID,如果线程还未启动则为None,它是一个非零的整数当一个线程退出另外一个线程创建时,线程的ID可以重用,即使在线程退出后,其ID仍然可以访问。
is_alive()/isAlive():判断线程是否还活着。
daemon:一个布尔值,指示线程是(True)否(False)是一个守护线程。它必须在调用start()之前设置,否则会引发RuntimeError。它的初始值继承自创建它的线程;主线程不是一个守护线程,所以在主线程中创建的所有线程默认daemon = False。
何为守护线程?举个例子,在程序运行中,执行一个主线程,如果主线程又创建一个子线程,主线程和子线程就分兵两路,当主线程完成想退出时,会检验子线程是否完成。 对于普通线程,如果子线程的任务没有结束,主线程不会退出,整个程序也不会退出;对于守护线程,即使子线程任务还没有结束,如果主线程退出该线程也会退出。
isDaemon()/setDaemon():作用与daemon的函数,一个是判断是不是守护线程,一个是设置守护线程。
下面通过简单的例子来展示Thread的使用方法,希望对你理解能有帮助,当然更希望你能动手操作下,了解上面方法的用处。
将函数传递到Thread对象
#coding=utf-8
import threading
import datetime
import time
def thread_fun(num):
time.sleep(num)
now = datetime.datetime.now()
print "线程名:%s ,now is %s"\
%( threading.currentThread().getName(), now)
def main(thread_num):
thread_list = list()
# 先创建线程对象
for i in range(0, thread_num):
thread_name = "thread_%s" %i
thread_list.append(threading.Thread(target = thread_fun, name = thread_name, args = (2,)))
# 启动所有线程
for thread in thread_list:
thread.setName("good")#修改线程名
print thread.is_alive()#判断线程是否是活的
print thread.ident
thread.start()
print thread.ident
print thread.is_alive()
thread.join()
print thread.is_alive()
if __name__ == "__main__":
main(3)
运行结果如下:
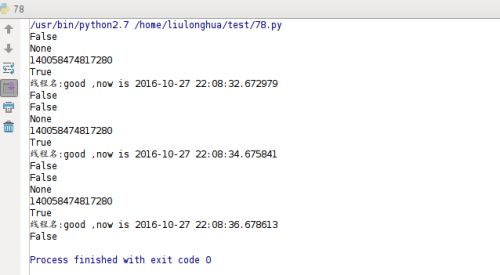
上面的例子只是展示了几个简单的Thread类的方法,其它方法大家可以自己动手试试,体会下。这里再讲下threading.Thread()
它的原型是:
class threading.Thread(group=None, target=None, name=None, args=(), kwargs={})
group应该为None;被保留用于未来实现了ThreadGroup类时的扩展。
target是将被run()方法调用的可调用对象。默认为None,表示不调用任何东西。
name是线程的名字。默认情况下,以“Thread-N”的形式构造一个唯一的名字,N是一个小的十进制整数。
args是给调用目标的参数元组。默认为()。
kwargs是给调用目标的关键字参数的一个字典。默认为{}。
继承自threading.Thread类:
继承的话,主要是重定义__init__()和run()。
#coding=utf-8
import threading
class MyThread(threading.Thread):
def __init__(self,group=None,target=None,name=None,args=(),kwargs=None):
threading.Thread.__init__(self,group,target,name,args,kwargs)
self.name = "Thread_%s"%threading.active_count()
def run(self):
print "I am %s" %self.name
if __name__ == "__main__":
for thread in range(0, 5):
t = MyThread()
t.start()
运行结果就不贴出来了。
(二)Lock互斥锁
如果多个线程访问同时同一个资源,那么就有可能对这个资源的安全性造成破坏,还好Python的threading模块中引入了互斥锁对象,可以保证共享数据操作的完整性。每个对象都对应于一个可称为” 互斥锁” 的标记,这个标记用来保证在任一时刻,只能有一个线程访问该对象这时候可以使用threading模块提供的Lock类。它主要有两个方法:acquire()和 release()
acquire(blocking=True, timeout=-1)
获取锁,设置为locked状态,blocking参数表示是否阻塞当前线程等待,timeout表示阻塞时的等待时间 。如果成功地获得lock,则acquire()函数返回True,否则返回False,timeout超时时如果还没有获得lock仍然返回False。
release()
释放锁,设置为unlocked状态,当在未锁定的锁上调用时,会引发ThreadError。没有返回值。
下面的代码是没有设锁时,100个线程访问一个资源,从运行结果来看对资源的完整性造成了一定的影响。
#coding=utf-8
import threading
import time
num = 0
class MyThread(threading.Thread):
def __init__(self,target=None,name=None,args=(),kwargs=None):
threading.Thread.__init__(self,target=target,name=name,args=args,kwargs=kwargs)
def run(self):
global num
time.sleep(1)#这句不能少,要不然看不到对公共资源完整性的破坏,当然也可以将该句放在
#num += 1的后面,有兴趣可以试试
num += 1
self.setName("Thread-%s" % num)
print("I am %s, set counter:%s" % (self.name, num))
if __name__ == "__main__":
for i in range(0, 100):
my_thread = MyThread()
my_thread.start()
运行结果如下:

看看部分数据的完整性遭到了“破坏”
再看看使用互斥锁的例子
#coding=utf-8
import threading
import time
num = 0
lock = threading.Lock()
class MyThread(threading.Thread):
def __init__(self,target=None,name=None,args=(),kwargs=None):
threading.Thread.__init__(self,target=target,name=name,args=args,kwargs=kwargs)
def run(self):
global num
time.sleep(1)
if lock.acquire():
num += 1
self.setName("Thread-%s" % num)
print("I am %s, set counter:%s" % (self.name, num))
lock.release()
if __name__ == "__main__":
for i in range(0, 100):
my_thread = MyThread()
my_thread.start()
运行结果大家可以动手试试。
同步阻塞
当一个线程调用Lock对象的acquire()方法获得锁时,这把锁就进入“locked”状态。因为每次只有一个线程可以获得锁,所以如果此时另一个线程试图获得这个锁,该线程就会变为“block“同步阻塞状态。直到拥有锁的线程调用锁的release()方法释放锁之后,该锁进入“unlocked”状态。线程调度程序从处于同步阻塞状态的线程中选择一个来获得锁,并使得该线程进入运行状态。
死锁
是指两个或两个以上的进程在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程
(三)可重入锁RLock
用法和Lock用法一样,只RLock支持嵌套,而Lock不支持嵌套;RLock允许在同一线程中被多次acquire(如果使用RLock,那么acquire和release必须成对出现,即调用了n次acquire,必须调用n次的release才能真正释放所占用的琐),而Lock却不允许这种情况,否则会出现死锁。看下面例子:
#coding=utf-8
import threading
import time
num = 0
lock = threading.Lock()
class MyThread(threading.Thread):
def __init__(self,target=None,name=None,args=(),kwargs=None):
threading.Thread.__init__(self,target=target,name=name,args=args,kwargs=kwargs)
def run(self):
global num
time.sleep(1)
if lock.acquire():
num += 1
self.setName("Thread-%s" % num)
print("I am %s, set counter:%s" % (self.name, num))
if lock.acquire():
num += 1
self.setName("Thread-%s" % num)
print("I am %s, set counter:%s" % (self.name, num))
lock.release()
lock.release()
if __name__ == "__main__":
for i in range(0, 100):
my_thread = MyThread()
my_thread.start()
上面的例子使用Lock锁嵌套使用,运行后就出现了死锁,运行不下去,“卡住了”。
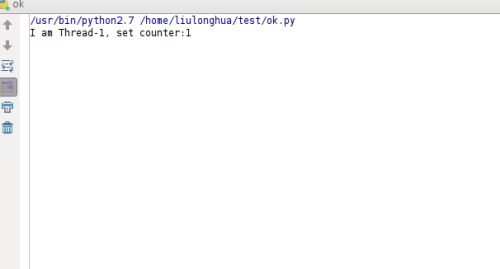
这个时候就出现了RLock,它支持在同一线程中可以多次请求同一资源。RLock内部维护着一个Lock和一个counter变量,counter记录了acquire的次数,从而使得资源可以被多次require。直到一个线程所有的acquire都被release,其他的线程才能获得资源。所以将上面的代码中
lock = threading.Lock()
改为
lock = threading.RLock()
就不会出现死锁情况。
(四)条件变量Condition
除了互斥锁外,对复杂线程同步问题,Python提供了Condition对象来支持解决。Condition被称为条件变量,除了提供与Lock类似的acquire和release方法外,还提供了wait和notify方法。线程首先acquire一个条件变量,然后判断一些条件。如果条件不满足则wait;如果条件满足,进行一些处理改变条件后,通过notify方法通知其他线程,其他处于wait状态的线程接到通知后会重新判断条件。不断的重复这一过程,从而解决复杂的同步问题。
除了acquire和release方法外还有如下方法:
wait([timeout]):
w释放内部所占用的琐,同时线程被挂起,直至接收到通知被唤醒或超时(如果提供了timeout参数的话)。当线程被唤醒并重新占有琐的时候,程序才会继续执行下去。
notify():
唤醒一个挂起的线程(如果存在挂起的线程),该方法不会释放所占用的琐。
notify_all()/notifyAll()
唤醒所有挂起的线程(如果存在挂起的线程),这些方法不会释放所占用的琐。
同时要主要这四个方法只有在占用琐(acquire)之后才能调用,否则将会报RuntimeError异常。
Condition其实是一把高级的锁,它内部维护着一个锁对象(默认是RLock),当然你也可以通过它的构造函数传递一个Lock/RLock对象给它。我们可以看看它的__init__()函数的定义:
def __init__(self, lock=None, verbose=None):
_Verbose.__init__(self, verbose)
if lock is None:
lock = RLock()
self.__lock = lock
# Export the lock's acquire() and release() methods
self.acquire = lock.acquire
self.release = lock.release
# If the lock defines _release_save() and/or _acquire_restore(),
# these override the default implementations (which just call
# release() and acquire() on the lock). Ditto for _is_owned().
try:
self._release_save = lock._release_save
except AttributeError:
pass
try:
self._acquire_restore = lock._acquire_restore
except AttributeError:
pass
try:
self._is_owned = lock._is_owned
except AttributeError:
pass
self.__waiters = []
是不是一目了然。条件变量的经典问题就是生产者与消费者的例子了。假设某代工厂的两个车间,一个车间生产某种配件,另一个车间需要这些配件进行组装产品,那么前者就是生产者(Producer),后者就是消费者(Consumer),当配件数低于1000就需要生产,多余5000个可以暂停生产,生产者一秒中可生产200个,消费者的策略是剩余数量少于800就不组装了,一秒钟可消费100个。代码如下
#coding=utf-8
import threading
import time
left_num = 500#假设初始剩余数为500
con = threading.Condition()
class Producer(threading.Thread):
"""生产者"""
def __init__(self, target=None, name=None, args=(), kwargs=None):
threading.Thread.__init__(self, target=target, name=name, args=args, kwargs=kwargs)
def run(self):
global left_num
is_product = True
while True:
if con.acquire():
if left_num > 5000:#大于5000可以暂停生产
is_product = False#不用继续生产
con.wait()#该“生产线”挂起
elif left_num < 1000:
is_product = True#继续生产
left_num += 200
msg = self.name+' produce 200, left_num=%s'%left_num
print msg
con.notify()
else:
#对于剩余数量处在中间的,就要分情况讨论了,一旦开启“生产”就要等
#到生产到指定数目才能停止,仔细想想很好理解的
if is_product:
left_num += 200
msg = self.name + ' produce 200, left_num=%s' % left_num
print msg
con.notify()
else:
con.wait()
con.release()
time.sleep(1)
class Consumer(threading.Thread):
"""消费者"""
def __init__(self, target=None, name=None, args=(), kwargs=None):
threading.Thread.__init__(self, target=target, name=name, args=args, kwargs=kwargs)
def run(self):
global left_num
while True:
if con.acquire():
if left_num < 800:#少于800不组装
con.wait()
else:
left_num -= 100
msg = self.name+' consume 100, left_num=%s'%left_num
print msg
con.notify()
con.release()
time.sleep(1)
def test():
for i in range(1):
p = Producer()
p.start()
for i in range(1):
c = Consumer()
c.start()
if __name__ == '__main__':
test()
大家可以把代码复制下来运行看看,仔细体会下,当累计剩余数大于5000后,就停止了“生产",之后只有消费者在运作,当剩余数低于1000,生产者”生成线"重启生产,直到累计剩余数大于5000,后又停止生产,以此类推。示例中展示的都是生产者与消费者都只有一条”流水线”,实际上,生产者有多条”流水线",消费者也有多条"流水线“,其实都一样,将上面代码的for循环的范围改下就可以了。还有一点,Condition可以接受一个Lock/RLock对象,大家可以试试创建一个Lock/RLock传递给Condition,如下:
lock = threading.Lock()
con = threading.Condition(lock)
效果是一样的,大家可以动手试试。
(五)事件对象Event
事件对象是线程间最简单的通信机制之一:线程可以激活在一个事件对象上等待的其他线程。类似于一个线程向其它多个线程“发号施令”的模式,其它线程都会持有一个Event的对象,这些线程都会等待这个事件的“发生”,如果此事件一直不发生,那么这些线程将会阻塞,直至事件的“发生”。
主要方法有:
set():
将内部标志设置为true。 所有等待它成为真正的线程都被唤醒。如果内部标志 false,当程序执行 event.wait() 方法时就会阻塞;如果值为True,event.wait() 方法
clear():
将内部标志重置为false,随后调用wait()的线程将阻塞,直到调用set(),再次将内部标志设置为true。
wait([timeout]):
用来阻塞当前线程,直到event的内部标志位被设置为true或者timeout超时。如果内部标志位为true则wait()函数立即返回。当timeout参数存在而不是None时,它应该是一个浮点数,以秒为单位指定操作的超时(或其分数)。
is_set()/isSet():
判断内部标准的值,为true则返回true,为false则返回false。
看下面一个简单的例子吧
#coding=utf-8
import threading
import time
def worker(event,name):
print('Thread %s Waiting for redis ready...'%name)
event.wait()
print('redis ready, and connect to redis server and Thread %s do some work at %s'% (name,time.ctime()))
time.sleep(1)
readis_ready = threading.Event()
t1 = threading.Thread(target=worker, args=(readis_ready,"t1"), name='t1')
t1.start()
t2 = threading.Thread(target=worker, args=(readis_ready,"t2"), name='t2')
t2.start()
print('first of all, check redis server, make sure it is OK, and then trigger the redis ready event')
time.sleep(3)
readis_ready.set()
运行结果如下:

t1和t2线程开始的时候都阻塞在等待redis服务器启动的地方,一旦主线程确定了redis服务器已经正常启动,那么会触发redis_ready事件,各个工作线程就会去连接redis去做响应的工作。
(六)信号量Semaphore/BoundedSemaphore
Semaphore是一个变量,控制着对公共资源或者临界区的访问,维护着一个计数器,指定可同时访问资源或者进入临界区的线程数。每次有一个线程获得信号量时,计数器-1。若计数器为0,其他线程就停止访问信号量,直到另一个线程释放信号量,同时计数器不能为负数。
Semaphore对象接受一个正整数参数,默认情况是1,即threading.Semaphore([value])
主要方法是acquire()和release()。调用acquire()时,获取信号量并且计数器减1;调用release()时释放信号量,并且计数器加1。
BoundedSemaphore 与Semaphore的唯一区别在于前者将在调用release()时检查计数器的值是否超过了计数器的初始值,如果超过了将抛出一个异常。下面有个简单的例子:
#coding=utf-8
import threading
import time
semaphore = threading.Semaphore(5)#信号量
def func():
if semaphore.acquire():
time.sleep(2)
print (threading.currentThread().getName() + ' get semaphore')
semaphore.release()
for i in range(10):
t1 = threading.Thread(target=func)
t1.start()
开了十个线程,但使用semaphore限制了最多有5个进程同时执行,结果就不贴了,大家可以比较下使用semaphore和不使用semaphore时的效果,比较下就知道区别了。
(七)Timer 对象
这个类表示一个动作应该在一个特定的时间之后运行,也就是一个定时器。Timer是Thread的子类, 因此也可以使用函数创建自定义线程。Timers通过调用它们的start()方法作为线程启动。timer可以通过调用cancel()方法(在它的动作开始之前)停止。timer在执行它的动作之前等待的时间间隔可能与用户指定的时间间隔不完全相同
threading.Timer(interval, function, args=[], kwargs={})
创建一个timer,在interval秒过去之后,它将以参数args和关键字参数kwargs运行function 。
cancel()
停止timer,并取消timer动作的执行。这只在timer仍然处于等待阶段时才工作。
这里贴出Timer的源码,其实用法和Thread对象一样,就多了一个参数interval.
def Timer(*args, **kwargs):
"""Factory function to create a Timer object.
Timers call a function after a specified number of seconds:
t = Timer(30.0, f, args=[], kwargs={})
t.start()
t.cancel() # stop the timer's action if it's still waiting
"""
return _Timer(*args, **kwargs)
class _Timer(Thread):
"""Call a function after a specified number of seconds:
t = Timer(30.0, f, args=[], kwargs={})
t.start()
t.cancel() # stop the timer's action if it's still waiting
"""
def __init__(self, interval, function, args=[], kwargs={}):
Thread.__init__(self)
self.interval = interval
self.function = function
self.args = args
self.kwargs = kwargs
self.finished = Event()
def cancel(self):
"""Stop the timer if it hasn't finished yet"""
self.finished.set()
def run(self):
self.finished.wait(self.interval)
if not self.finished.is_set():
self.function(*self.args, **self.kwargs)
self.finished.set()
另外,Lock、RLock、Condition、Semaphore和BoundedSemaphore对象里定义了__enter__()和__exit__()函数,而这两个真是上下文管理协议的必要条件(有兴趣可以参看之前博文 Python:with语句和上下文管理器对象),这就说明,在with语句中可以使用这些对象。比如最简单的
import threading
some_rlock = threading.RLock()
with some_rlock:
print "some_rlock is locked while this executes"
有兴趣的可以去看看threading.py里面的源码。
Queue模块
Queue模块是提供队列操作的模块,队列是线程间最常用的交换数据的形式。该模块提供了三种队列:
Queue.Queue(maxsize):先进先出,maxsize是队列的大小,其值为非正数时为无线循环队列
Queue.LifoQueue(maxsize):后进先出,相当于栈
Queue.PriorityQueue(maxsize):优先级队列。
其中LifoQueue,PriorityQueue是Queue的子类。三者拥有以下共同的方法:
qsize():返回近似的队列大小。为什么要加“近似”二字呢?因为当该值大于0的时候并不保证并发执行的时候get()方法不被阻塞,同样,对于put()方法有效。
empty():返回布尔值,队列为空时,返回True,反之返回False。
full():当设定了队列大小的时候,如果队列满了,则返回True,否则返回False。
put(item[,block[,timeout]]):向队列里添加元素item,block设置为False的时候,如果队列满了则抛出Full异常。如果block设置为True,timeout设置为None时,则会一种等到有空位的时候再添加进队列;否则会根据timeout设定的超时值抛出Full异常。
put_nowwait(item):等价与put(item,False)。block设置为False的时候,如果队列为空,则抛出Empty异常。如果block设置为True,timeout设置为None时,则会一种等到有空位的时候再添加进队列;否则会根据timeout设定的超时值抛出Empty异常。
get([block[,timeout]]):从队列中删除元素并返回该元素的值,如果timeout是一个正数,它会阻塞最多超时秒数,并且如果在该时间内没有可用的项目,则引发Empty异常。
get_nowwait():等价于get(False)
task_done():发送信号表明入列任务已完成,经常在消费者线程中用到。
join():阻塞直至队列所有元素处理完毕,然后再处理其它操作。
(一)源码分析
Queue模块用起来很简单很简单,但我觉得有必要把该模块的相关源代码贴出来分析下,会学到不少东西,看看大神们写的代码多么美观,多么结构化模块化,再想想自己写的代码,都是泪呀,来学习学习。为了缩减篇幅,源码的注释部分被删减掉。
from time import time as _time
try:
import threading as _threading
except ImportError:
import dummy_threading as _threading
from collections import deque
import heapq
__all__ = ['Empty', 'Full', 'Queue', 'PriorityQueue', 'LifoQueue']
class Empty(Exception):
"Exception raised by Queue.get(block=0)/get_nowait()."
pass
class Full(Exception):
"Exception raised by Queue.put(block=0)/put_nowait()."
pass
class Queue:
def __init__(self, maxsize=0):
self.maxsize = maxsize
self._init(maxsize)
self.mutex = _threading.Lock()
self.not_empty = _threading.Condition(self.mutex)
self.not_full = _threading.Condition(self.mutex)
self.all_tasks_done = _threading.Condition(self.mutex)
self.unfinished_tasks =
def get_nowait(self):
return self.get(False)
def _init(self, maxsize):
self.queue = deque()
def _qsize(self, len=len):
return len(self.queue)
def _put(self, item):
self.queue.append(item)
def _get(self):
return self.queue.popleft()
通过后面的几个函数分析知道,Queue对象是在collections模块的queue基础上(关于collections模块参考 Python:使用Counter进行计数统计及collections模块),加上threading模块互斥锁和条件变量封装的。
deque是一个双端队列,很适用于队列和栈。上面的Queue对象就是一个先进先出的队列,所以首先_init()函数定义了一个双端队列,然后它的定义了_put()和_get()函数,它们分别是从双端队列右边添加元素、左边删除元素,这就构成了一个先进先出队列,同理很容易想到LifoQueue(后进先出队列)的实现了,保证队列右边添加右边删除就可以。可以贴出源代码看看。
class LifoQueue(Queue):
'''Variant of Queue that retrieves most recently added entries first.'''
def _init(self, maxsize):
self.queue = []
def _qsize(self, len=len):
return len(self.queue)
def _put(self, item):
self.queue.append(item)
def _get(self):
return self.queue.pop()
虽然它的"queue"没有用queue(),用列表也是一样的,因为列表append()和pop()操作是在最右边添加元素和删除最右边元素。
再来看看PriorityQueue,他是个优先级队列,这里用到了heapq模块的heappush()和heappop()两个函数。heapq模块对堆这种数据结构进行了模块化,可以建立这种数据结构,同时heapq模块也提供了相应的方法来对堆做操作。其中_init()函数里self.queue=[]可以看作是建立了一个空堆。heappush() 往堆中插入一条新的值 ,heappop() 从堆中弹出最小值 ,这就可以实现优先级(关于heapq模块这里这是简单的介绍)。源代码如下:
class PriorityQueue(Queue):
'''Variant of Queue that retrieves open entries in priority order (lowest first).
Entries are typically tuples of the form: (priority number, data).
'''
def _init(self, maxsize):
self.queue = []
def _qsize(self, len=len):
return len(self.queue)
def _put(self, item, heappush=heapq.heappush):
heappush(self.queue, item)
def _get(self, heappop=heapq.heappop):
return heappop(self.queue)
基本的数据结构分析完了,接着分析其它的部分。
mutex 是个threading.Lock()对象,是互斥锁;not_empty、 not_full 、all_tasks_done这三个都是threading.Condition()对象,条件变量,而且维护的是同一把锁对象mutex(关于threading模块中Lock对象和Condition对象可参考上篇博文Python:线程、进程与协程(2)——threading模块)。
其中:
self.mutex互斥锁:任何获取队列的状态(empty(),qsize()等),或者修改队列的内容的操作(get,put等)都必须持有该互斥锁。acquire()获取锁,release()释放锁。同时该互斥锁被三个条件变量共同维护。
self.not_empty条件变量:线程添加数据到队列中后,会调用self.not_empty.notify()通知其它线程,然后唤醒一个移除元素的线程。
self.not_full条件变量:当一个元素被移除出队列时,会唤醒一个添加元素的线程。
self.all_tasks_done条件变量 :在未完成任务的数量被删除至0时,通知所有任务完成
self.unfinished_tasks : 定义未完成任务数量
再来看看主要方法:
(1)put()
源代码如下:
def put(self, item, block=True, timeout=None):
self.not_full.acquire() #not_full获得锁
try:
if self.maxsize > 0: #如果队列长度有限制
if not block: #如果没阻塞
if self._qsize() == self.maxsize: #如果队列满了抛异常
raise Full
elif timeout is None: #有阻塞且超时为空,等待
while self._qsize() == self.maxsize:
self.not_full.wait()
elif timeout < 0:
raise ValueError("'timeout' must be a non-negative number")
else: #如果有阻塞,且超时非负时,结束时间=当前时间+超时时间
endtime = _time() + timeout
while self._qsize() == self.maxsize:
remaining = endtime - _time()
if remaining <= 0.0: #到时后,抛异常
raise Full
#如果没到时,队列是满的就会一直被挂起,直到有“位置”腾出
self.not_full.wait(remaining)
self._put(item) #调用_put方法,添加元素
self.unfinished_tasks += 1 #未完成任务+1
self.not_empty.notify() #通知非空,唤醒非空挂起的任务
finally:
self.not_full.release() #not_full释放锁
默认情况下block为True,timeout为None。如果队列满则会等待,未满则会调用_put方法将进程加入deque中(后面介绍),并且未完成任务加1还会通知队列非空。
如果设置block参数为Flase,队列满时则会抛异常。如果设置了超时那么在时间到之前进行阻塞,时间一到抛异常。这个方法使用not_full对象进行操作。
(2)get()
源码如下:
def get(self, block=True, timeout=None):
self.not_empty.acquire() #not_empty获得锁
try:
if not block: #不阻塞时
if not self._qsize(): #队列为空时抛异常
raise Empty
elif timeout is None: #不限时时,队列为空则会等待
while not self._qsize():
self.not_empty.wait()
elif timeout < 0:
raise ValueError("'timeout' must be a non-negative number")
else:
endtime = _time() + timeout
while not self._qsize():
remaining = endtime - _time()
if remaining <= 0.0:
raise Empty
self.not_empty.wait(remaining)
item = self._get() #调用_get方法,移除并获得项目
self.not_full.notify() #通知非满
return item #返回项目
finally:
self.not_empty.release() #释放锁
逻辑跟put()函数一样,参数默认情况下队列空了则会等待,否则将会调用_get方法(往下看)移除并获得一个项,最后返回这个项。这个方法使用not_empty对象进行操作。
不过我觉得put()与get()两个函数结合起来理解比较好。not_full与not_empty代表的是两种不同操作类型的线程,not_full可以理解成is-not-full,即队列是否满了,默认是没有满,没有满时not_full这个条件变量才能获取锁,并做一些条件判断,只有符合条件才能向队列里加元素,添加成功后就会通知not_empty条件变量队列里不是空的,“我”刚刚添加进了一个元素,满足可以执行删除动作的基本条件了(队列不是空的,想想如果是空的执行删除动作就没有意义了),同时唤醒一些被挂起的执行移除动作的线程,让这些线程重新判断条件,如果条件准许就会执行删除动作,然后又通知not_full条件变量,告诉“它”队列不是满的,因为“我”刚才删除了一个元素(想想如果队列满了添加元素就添加不进呀,就没意义了),满足了添加元素的基本条件(队列不是满的),同时唤醒一些被挂起的执行添加动作的线程,这些线程又会进行条件判断,符合条件就会添加元素,否则继续挂起,依次类推,同时这样也保证了线程的安全。正与前面所说,当一个元素被移除出队列时,会唤醒一个添加元素的线程;当添加一个元素时会唤醒一个删除元素的线程。
这是我想了一段时间得出的一种我个人理解的解释,不知道对不对或者说合不合理,如果有大神对这部分知识很熟悉了解,欢迎留言批评指正。
(3)task_done()
源码如下:
def task_done(self):
self.all_tasks_done.acquire() #获得锁
try:
unfinished = self.unfinished_tasks - 1 #判断队列中一个线程的任务是否全部完成
if unfinished <= 0: #是则进行通知,或在过量调用时报异常
if unfinished < 0:
raise ValueError('task_done() called too many times')
self.all_tasks_done.notify_all()
self.unfinished_tasks = unfinished #否则未完成任务数量-1
finally:
self.all_tasks_done.release() #最后释放锁
这个方法判断队列中一个线程的任务是否全部完成,首先会通过all_tasks_done对象获得锁,如果是则进行通知,最后释放锁。
(4)join()
源码如下:
def join(self):
self.all_tasks_done.acquire()
try:
while self.unfinished_tasks: #如果有未完成的任务,将调用wait()方法等待
self.all_tasks_done.wait()
finally:
self.all_tasks_done.release()
阻塞方法,当队列中有未完成进程时,调用join方法来阻塞,直到他们都完成。
其它的方法都比较简单,也比较好理解,有兴趣可以去看看Queue.py里的源码,要注意的是任何获取队列的状态(empty(),qsize()等),或者修改队列的内容的操作(get,put等)都必须持有互斥锁mutex。
(二)简单例子
(1)一个简单例子
实现一个线程不断生成一个随机数到一个队列中
实现一个线程从上面的队列里面不断的取出奇数
实现另外一个线程从上面的队列里面不断取出偶数
import random,threading,time
from Queue import Queue
is_product = True
class Producer(threading.Thread):
"""生产数据"""
def __init__(self, t_name, queue):
threading.Thread.__init__(self,name=t_name)
self.data=queue
def run(self):
while 1:
if self.data.full():
global is_product
is_product = False
else:
if self.data.qsize() <= 7:#队列长度小于等于7时添加元素
is_product = True
for i in range(2): #每次向队列里添加两个元素
randomnum=random.randint(1,99)
print "%s: %s is producing %d to the queue!" % (time.ctime(), self.getName(), randomnum)
self.data.put(randomnum,False) #将数据依次存入队列
time.sleep(1)
print "deque length is %s"%self.data.qsize()
else:
if is_product:
for i in range(2): #
randomnum = random.randint(1, 99)
print "%s: %s is producing %d to the queue!" % (time.ctime(), self.getName(), randomnum)
self.data.put(randomnum,False) # 将数据依次存入队列
time.sleep(1)
print "deque length is %s" % self.data.qsize()
else:
pass
print "%s: %s finished!" %(time.ctime(), self.getName())
#Consumer thread
class Consumer_even(threading.Thread):
def __init__(self,t_name,queue):
threading.Thread.__init__(self,name=t_name)
self.data=queue
def run(self):
while 1:
if self.data.qsize() > 7:#队列长度大于7时开始取元素
val_even = self.data.get(False)
if val_even%2==0:
print "%s: %s is consuming. %d in the queue is consumed!" % (time.ctime(),self.getName(),val_even)
time.sleep(2)
else:
self.data.put(val_even)
time.sleep(2)
print "deque length is %s" % self.data.qsize()
else:
pass
class Consumer_odd(threading.Thread):
def __init__(self,t_name,queue):
threading.Thread.__init__(self, name=t_name)
self.data=queue
def run(self):
while 1:
if self.data.qsize() > 7:
val_odd = self.data.get(False)
if val_odd%2!=0:
print "%s: %s is consuming. %d in the queue is consumed!" % (time.ctime(), self.getName(), val_odd)
time.sleep(2)
else:
self.data.put(val_odd)
time.sleep(2)
print "deque length is %s" % self.data.qsize()
else:
pass
#Main thread
def main():
queue = Queue(20)
producer = Producer('Pro.', queue)
consumer_even = Consumer_even('Con_even.', queue)
consumer_odd = Consumer_odd('Con_odd.',queue)
producer.start()
consumer_even.start()
consumer_odd.start()
producer.join()
consumer_even.join()
consumer_odd.join()
if __name__ == '__main__':
main()
这个例子跟上篇博文Python:线程、进程与协程(2)——threading模块中介绍Condition的例子很像,就是构造了一个长度为20的队列,当队列1元素个数小于8时就忘队列中添加元素,当队列满后,就不再添加,当队列元素大于7个时,才会取元素,否则不取元素。有兴趣的可以动手试试,仔细体会下。
(2)线程池
在使用多线程处理任务时也不是线程越多越好,由于在切换线程的时候,需要切换上下文环境,依然会造成cpu的大量开销。为解决这个问题,线程池的概念被提出来了。预先创建好一个较为优化的数量的线程,让过来的任务立刻能够使用,就形成了线程池。在python中,没有内置的较好的线程池模块,需要自己实现或使用第三方模块。
#coding=utf-8
import queue
import threading
import contextlib
import time
StopEvent = object() # 创建空对象
class ThreadPool(object):
def __init__(self, max_num, max_task_num = None):
if max_task_num:
self.q = queue.Queue(max_task_num)
else:
self.q = queue.Queue()
self.max_num = max_num
self.cancel = False
self.terminal = False
self.generate_list = []
self.free_list = []
def run(self, func, args, callback=None):
"""
线程池执行一个任务
:param func: 任务函数
:param args: 任务函数所需参数
:param callback: 任务执行失败或成功后执行的回调函数,回调函数有两个参数1、任务函数执行状态;2、任务函数返回值(默认为None,即:不执行回调函数)
:return: 如果线程池已经终止,则返回True否则None
"""
if self.cancel:
return
if len(self.free_list) == 0 and len(self.generate_list) < self.max_num:
self.generate_thread()
w = (func, args, callback,)
self.q.put(w)
def generate_thread(self):
"""
创建一个线程
"""
t = threading.Thread(target=self.call)
t.start()
def call(self):
"""
循环去获取任务函数并执行任务函数
"""
current_thread = threading.currentThread
self.generate_list.append(current_thread)
event = self.q.get()
while event != StopEvent:
func, arguments, callback = event
try:
result = func(*arguments)
success = True
except Exception as e:
success = False
result = None
if callback is not None:
try:
callback(success, result)
except Exception as e:
pass
with self.worker_state(self.free_list, current_thread):
if self.terminal:
event = StopEvent
else:
event = self.q.get()
else:
self.generate_list.remove(current_thread)
def close(self):
"""
执行完所有的任务后,所有线程停止
"""
self.cancel = True
full_size = len(self.generate_list)
while full_size:
self.q.put(StopEvent)
full_size -= 1
def terminate(self):
"""
无论是否还有任务,终止线程
"""
self.terminal = True
while self.generate_list:
self.q.put(StopEvent)
self.q.empty()
@contextlib.contextmanager
def worker_state(self, state_list, worker_thread):
"""
用于记录线程中正在等待的线程数
"""
state_list.append(worker_thread)
try:
yield
finally:
state_list.remove(worker_thread)
# How to use
pool = ThreadPool(5)
def callback(status, result):
# status, execute action status
# result, execute action return value
pass
def action(i):
print(i)
for i in range(30):
ret = pool.run(action, (i,), callback)
time.sleep(5)
print(len(pool.generate_list), len(pool.free_list))
print(len(pool.generate_list), len(pool.free_list))
# pool.close()
# pool.terminate()
multiprocessing模块
multiprocessing模块是Python提供的用于多进程开发的包,multiprocessing包提供本地和远程两种并发,通过使用子进程而非线程有效地回避了全局解释器锁。
(一)创建进程Process 类
创建进程的类,其源码在multiprocessing包的process.py里,有兴趣的可以对照着源码边理解边学习。它的用法同threading.Thread差不多,从它的类定义上就可以看的出来,如下:
class Process(object):
'''
Process objects represent activity that is run in a separate process
The class is analagous to `threading.Thread`
'''
_Popen = None
def __init__(self, group=None, target=None, name=None, args=(), kwargs={}):
assert group is None, 'group argument must be None for now'
count = _current_process._counter.next()
self._identity = _current_process._identity + (count,)
self._authkey = _current_process._authkey
self._daemonic = _current_process._daemonic
self._tempdir = _current_process._tempdir
self._parent_pid = os.getpid()
self._popen = None
self._target = target
self._args = tuple(args)
self._kwargs = dict(kwargs)
self._name = name or type(self).__name__ + '-' + \
':'.join(str(i) for i in self._identity)
Process([group [, target [, name [, args [, kwargs]]]]])
group实质上不使用,是保留项,便于以后扩展。
target表示调用对象,
args表示调用对象的位置参数元组
kwargs表示调用对象的字典
name为别名,即进程的名字
它的方法/属性跟threading.Thread也有很多类似的地方,主要有:
start():开始进程活动。
run():表示进程的活动方法,可以在子类中覆盖它。
join([timeout]):是用来阻塞当前上下文,直至该进程运行结束,一个进程可以被join()多次,timeout单位是秒。
terminate():结束进程。在Unix上使用的是SIGTERM,在Windows平台上使用TerminateProcess
is_alive():判断进程是否还活着。
name:一个字符串,表示进程的名字,也可以通过赋值语句利用它来修改进程的名字
ident:进程的ID,如果进程没开始,结果是None
pid:同ident,大家可以看看ident和pid的实现,是利用了os模块的getpid()方法。
authkey:设置/获取进程的授权密码。当初始化多进程时,使用os.urandom()为主进程分配一个随机字符串。当创建一个Process对象时,它将继承其父进程的认证密钥, 但是可以通过将authkey设置为另一个字节字符串来改变。这里authkey为什么既可以设置授权密码又可以获取呢?那是因为它的定义使用了property装饰器,源码如下:
@property
def authkey(self):
return self._authkey
@authkey.setter
def authkey(self, authkey):
'''
Set authorization key of process
'''
self._authkey = AuthenticationString(authkey)
这是property的一个高级用法,如果理解了其实也很简单,有兴趣的去查看其它资料。
daemon:一个布尔值,指示进程是(True)否(False)是一个守护进程。它必须在调用start()之前设置,否则会引发RuntimeError。它的初始值继承自创建它的进程;进程不是一个守护进程,所以在进程中创建的所有进程默认daemon = False。
exitcode:返回进程退出时的代码。进程运行时其值为None,如果为–N,表示被信号N结束。
(1)一个简单的单进程例子
#coding=utf-8
import multiprocessing
import datetime
import time
def worker(interval):
n = 5
while n > 0:
print "The now is %s"% datetime.datetime.now()
time.sleep(interval)
n -= 1
if __name__ == "__main__":
p = multiprocessing.Process(target = worker, args = (3,))
p.start()#开始进程
#p.terminate()#结束进程
#p.join(9)#阻塞当前上下文
print "p.authkey",p.authkey#获取进程的授权密码
p.authkey = u"123"#设置进程的授权密码
print "p.authkey", p.authkey#获取进程的授权密码
print "p.pid:", p.pid,p.ident#进程ID
p.name = 'helloworld'#修改进程名字
print "p.name:", p.name#进程名字
print "p.is_alive:", p.is_alive()#是否是活的
运行结果如下图:

上面的代码有两行注释掉的,大家可以把注释去掉,体会、理解这两个方法的用处,在此不贴我的运行结果了。
(2)自定义进程类,并开启多个进程
import multiprocessing
import datetime
import time
class MyProcess(multiprocessing.Process):
"""
自定义进程类
"""
def __init__(self,interval,group=None,target=None,name=None,args=(),kwargs={}):
multiprocessing.Process.__init__(self,group,target,name,args,kwargs=kwargs)
self.interval = interval
def run(self):
n = 5
while n > 0:
print("the time is %s"%datetime.datetime.now())
time.sleep(self.interval)
n -= 1
def worker_1(interval):
print "worker_1"
time.sleep(interval)
print "end worker_1"
def worker_2(interval):
print "worker_2"
time.sleep(interval)
print "end worker_2"
def worker_3(interval):
print "worker_3"
time.sleep(interval)
print "end worker_3"
if __name__ == "__main__":
p1 = MyProcess(interval=2,target = worker_1, args = (2,))
p2 = MyProcess(interval=2,target = worker_2, args = (3,))
p3 = MyProcess(interval=2,target = worker_3, args = (4,))
p1.start()
p2.start()
p3.start()
print "current process",multiprocessing.current_process(),multiprocessing.active_children()
print("The number of CPU is:" + str(multiprocessing.cpu_count()))
for p in multiprocessing.active_children():
print("child p.name:" + p.name + "\tp.id" + str(p.pid))
print "END!!!!!!!!!!!!!!!!!"
运行结果如下:

看看打印出来的时间,三个进程应该是并行执行的。
(二)进程间通信
multiprocessing模块支持两种进程间的通信方式:Queue(队列)和Pipe(管道)。
(1)Queue
multiprocessing中的Queue类的定义在queues.py文件里。和Queue.Queue差不多,multiprocessing中的Queue类实现了Queue.Queue的大部分方法(可以参考上篇博文Python:线程、进程与协程(3)——Queue模块及源码分析),但task_done()和join()没有实现,主要方法和属性有
qsize():返回Queue的大小
empty():返回一个布尔值,表示Queue是否为空
full():返回一个布尔值,表示Queue是否满
put(item[, block[, timeout]]):向队列里添加元素item,block设置为False的时候,如果队列满了则抛出Full异常。如果block设置为True,timeout设置为None时,则会一种等到有空位的时候再添加进队列;否则会根据timeout设定的超时值抛出Full异常。
put_nowait(item):等价与put(item,False)。
get([block[, timeout]]):从队列中删除元素并返回该元素的值,如果timeout是一个正数,它会阻塞最多超时秒数,并且如果在该时间内没有可用的项目,则引发Empty异常。
get_nowait():等价于get(False)
close():表示该Queue不在加入新的元素
join_thread():加入后台线程。这只能在调用close()之后使用。它阻塞直到后台线程退出,确保缓冲区中的所有数据都已刷新到管道。默认情况下,如果进程不是队列的创建者,则退出, 它将尝试加入队列的后台线程。 该进程可以调用cancel_join_thread()来做
cancel_join_thread():在阻塞中阻止join_thread(),防止后台线程在进程退出时被自动连接 ,肯能会导致数据丢失。
(2)Pipe
Pipe不是类,是函数,该函数定义在 multiprocessing中的connection.py里,函数原型Pipe(duplex=True),
返回一对通过管道连接的连接对象conn1和conn2。
如果duplex是True(默认值),则管道是双向的。
如果duplex是False,则管道是单向的:conn1只能用于接收消息,conn2只能用于发送消息。
Pipe()返回的两个连接对象表示管道的两端,每个连接对象都有send()和recv()方法(还有其它方法),分别是发送和接受消息。下面举个简单的例子,一个发送数据,一个接受数据
#coding=utf-8
import multiprocessing
import time
def proc1(pipe):
"""
发送数据
"""
while True:
for i in xrange(100):
print "send: %s" %(i)
pipe.send(i)#发送数据
time.sleep(1)
def proc2(pipe):
"""
接收数据
"""
while True:
print "proc2 rev:", pipe.recv()#接受数据
time.sleep(1)
if __name__ == "__main__":
pipe1,pipe2 = multiprocessing.Pipe()#返回两个连接对象
p1 = multiprocessing.Process(target=proc1, args=(pipe1,))
p2 = multiprocessing.Process(target=proc2, args=(pipe2,))
p1.start()
p2.start()
p1.join()
p2.join()
运行结果如下:
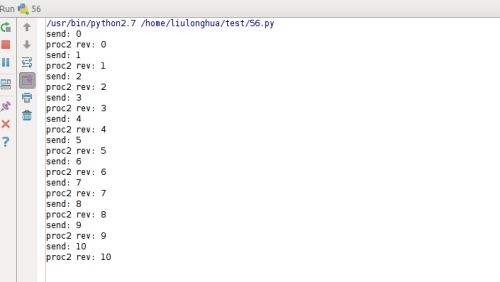
(三)进程间的同步
multiprocessing包含与threading中所有同步原语等同的原语,它也有Lock,RLock,Even,Condition,Semaphore,BoundedSemaphore。用法都差不多,它们的定义在 multiprocessing包的synchronize.py文件里,在此不过多介绍,有兴趣的可以参考Python:线程、进程与协程(2)——threading模块里相关的概念理解。如果理解了相关概念,在 multiprocessing模块中使用是一样的,看下面这个简单的例子吧,有两个进程要向某个文件中写入内容,为了避免访问冲突,可以使用锁。
#coding=utf-8
import multiprocessing
def worker_with(lock, f):
with lock:#Lock等对象也是支持上下文管理器协议的。
fs = open(f, 'a+')
n = 10
while n > 1:
fs.write("Lockd acquired via with\n")
n -= 1
fs.close()
def worker_no_with(lock, f):
lock.acquire()
try:
fs = open(f, 'a+')
n = 10
while n > 1:
fs.write("Lock acquired directly\n")
n -= 1
fs.close()
finally:
lock.release()
if __name__ == "__main__":
lock = multiprocessing.Lock()#定义锁
f = "/home/liulonghua/files.txt"
w = multiprocessing.Process(target = worker_with, args=(lock, f))
nw = multiprocessing.Process(target = worker_no_with, args=(lock, f))
w.start()
nw.start()
print "end"
multiprocessing提供了threading包中没有的IPC(比如Pipe和Queue),效率上更高。应优先考虑Pipe和Queue,避免使用Lock/Event/Semaphore/Condition等同步方式 (因为它们占据的不是用户进程的资源)。
多进程应该避免共享资源。在多线程中,我们可以比较容易地共享资源,比如使用全局变量或者传递参数。在多进程情况下,由于每个进程有自己独立的内存空间,以上方法并不合适。此时我们可以通过共享内存和Manager的方法来共享资源。但这样做提高了程序的复杂度,并因为同步的需要而降低了程序的效率。下篇博文再接着讲进程共享和进程池等。
Python的multiprocessing模块创建进程Process 类,进程间通信,进程间的同步三个部分,下面接着介绍学习进程共享。
(1)内存共享
在多进程情况下,由于每个进程有自己独立的内存空间,怎样能实现内存共享呢?multiprocessing模块提供了Value, Array,这两个是函数,详细定义在sharedctypes.py里,有兴趣的可以去看看(等了解了ctypes模块后回头再分享下我的理解,今天就先放放)
Value
Value的初始化非常简单,直接类似Value(‘d’, 0.0)即可,具体构造方法如下:
multiprocessing.Value(typecode_or_type, *args[,lock])。
返回从共享内存中分配的一个ctypes 对象,其中typecode_or_type定义了返回的类型。它要么是一个ctypes类型,要么是一个代表ctypes类型的code。
ctypes是Python的一个外部函数库,它提供了和C语言兼任的数据类型,可以调用DLLs或者共享库的函数,能被用作在python中包裹这些库。
*args是传递给ctypes的构造参数
对于共享整数或者单个字符,初始化比较简单,参照下图映射关系:
| Type Code | C Type | Python Type |
|---|---|---|
| ‘c’ | char | character |
| ‘b’ | signed char | int |
| ‘B’ | unsigned char | int |
| ‘u’ | Py_UNICODE | unicode character |
| ‘h’ | signed short | int |
| ‘H’ | unsigned short | int |
| ‘i’ | signed int | int |
| ‘I’ | unsigned int | int |
| ‘l’ | signed long | int |
| ‘L’ | unsigned long | int |
| ‘f’ | float | float |
| ‘d’ | double | float |
比如整数1,可用Value(‘h’,1)
如果共享的是字符串,则在上表是找不到映射关系的,就是没有对应的Type code可用。所以我们需要使用原始的ctype类型,对应关系如下:
| ctypes type | C type | Python type |
|---|---|---|
| c_bool | _Bool | bool (1) |
| char | char | 1-character string |
| c_wchar | wchar_t | 1-character unicode string |
| c_byte | char | int/long |
| c_ubyte | unsigned char | int/long |
| c_short | short | int/long |
| c_ushort | unsigned short | int/long |
| c_int | int | int/long |
| c_uint | unsigned in | int/long |
| c_long | long | int/long |
| c_ulong | unsigned long | int/long |
| c_longlong | __int64 or long long | int/long |
| c_ulonglong | unsigned __int64 or unsigned long long | int/long |
| c_float | float | float |
| c_double | double | float |
| c_longdouble | long double | float |
| c_char_p | char * (NUL terminated) | string or None |
| c_wchar_p | wchar_t * (NUL terminated) | unicode or None |
| c_void_p | void * | int/long or None |
比如上面的Value(‘h’,1)也可以用Value(c_short,1),字符串的话,可以用Value(c_char_p,“hello”),很好理解的。
它返回的是个对象,所以,它也有一些属性和方法,而返回的对象是基于SynchronizedBase类,该类的定义如下:
class SynchronizedBase(object):
def __init__(self, obj, lock=None):
self._obj = obj
self._lock = lock or RLock()
self.acquire = self._lock.acquire
self.release = self._lock.release
def __reduce__(self):
assert_spawning(self)
return synchronized, (self._obj, self._lock)
def get_obj(self):
return self._obj
def get_lock(self):
return self._lock
def __repr__(self):
return '<%s wrapper for %s>' % (type(self).__name__, self._obj)
所以它的属性和方法有:
value:获取值
get_lock():获取锁对象
acquire/release:参考RLock对象的acquire方法,release方法,是一样的,一个是获取锁,一个是释放锁。很好理解的。
下面举个例子来体会一下这些方法
#coding=utf-8
import time
from multiprocessing import Value,Process
def fun(val):
for i in range(10):
time.sleep(0.5)
val.value += 1
v = Value('i',0)
p_list = [Process(target=fun,args=(v,)) for i in range(10)]
for p in p_list:
p.start()
for p in p_list:
p.join()
print v.value
上述代码是多个进程修改v值,我们期待它输出的是100,但是实际上并输出的并不是100,Value的构造函数默认的lock是True,它会创建一个锁对象用于同步访问控制,这就容易造成一个错误的意识,认为Value在多进程中是安全的,但实际上并不是,要想真正的控制同步访问,需要实现获取这个锁。所以需要修改fun()函数。如下:
def fun(val):
for i in range(10):
time.sleep(0.5)
with v.get_lock():
val.value += 1
或者如下:
def fun(val):
for i in range(10):
time.sleep(0.5)
if v.acquire():
val.value += 1
v.release()
Array
有了上面的基础,这个就比较好理解了,它返回从共享内存分配的ctypes数组,原型如下:
multiprocessing.Array(typecode_or_type, size_or_initializer, *,lock=True)
ypecode_or_type确定返回数组的元素的类型:它是一个ctypes类型或一个字符类型代码类型的数组模块使用的类型。
size_or_initializer:如果它是一个整数,那么它确定数组的长度,并且数组将被初始化为零。否则,size_or_initializer是用于初始化数组的序列,其长度决定数组的长度。
如果关键字参数中有lock的话,lock为True,则会创建一个新的锁对象,以同步对该值的访问。如果lock是Lock或RLock对象,那么它将用于同步对该值的访问。如果lock是False,那么对返回的对象的访问不会被锁自动保护,因此它不一定是“进程安全的”。
它返回值的属性和方法同Value差不多,有兴趣的可以自己写代码试试,在此不举例子。
(2)服务器进程
通过Manager()返回的一个manager对象控制一个服务器进程,它保持住Python对象并允许其它进程使用代理操作它们。同时它用起来很方便,而且支持本地和远程内存共享。
Manager()返回的manager支持的类型有list, dict, Namespace, Lock, RLock, Semaphore, BoundedSemaphore, Condition, Event, Queue, Value和Array。
该部分的实现在managers.py文件里,
Manager()的定义很简单,如下:
def Manager():
'''
Returns a manager associated with a running server process
The managers methods such as `Lock()`, `Condition()` and `Queue()`
can be used to create shared objects.
'''
from multiprocessing.managers import SyncManager
m = SyncManager()
m.start()
return m
它返回一个已经启动的SyncManager对象,管理器进程将在垃圾收集或其父进程退出时立即关闭。SyncManager继承自BaseManager。BaseManager的定义也在managers.py文件里,有兴趣的可以看看,初始化如下:BaseManager([address[, authkey]])
address:是管理器进程侦听新连接的地址。 如果地址是无,则选择任意一个。
authkey:是将用于检查到服务器进程的传入连接的有效性的认证密钥。 如果authkey是None,那么使用当前进程current_process()的authkey; 否则使用的authkey,它必须是字符串。
一旦创建BaseManager对象,应调用start()或get_server()。serve_forever()以确保管理器对象引用已启动的管理器进程。
BaseManager对象的方法和属性有:
start([initializer [,initargs]]):
启动子过程以启动管理器。 如果初始化程序不是None,那么子程序在启动时会调用initializer(*initargs)
get_server():
返回一个Server对象,它表示在Manager控制下的实际服务器。 Server对象支持serve_forever()方法,Server对象也定义在managers.py文件里,该类的作用用因为解释就是“Server class which runs in a process controlled by a manager object”,有兴趣的可以去看看,了解下。
**connect():**将本地管理器对象连接到远程管理器进程
**shutdown():**停止管理器在使用的进程。这仅在用start()已启动服务器进程时可用,可以被多次调用。
register(typeid [,callable [,proxytype [,exposed [,method_to_typeid [,create_method]]]]]):
可以用于向管理器类注册类型或可调用的类方法。
typeid是用于标识特定类型的共享对象的“类型标识符”。这必须是字符串。
callable是用于为该类型标识符创建可调用的对象。如果将使用from_address()类方法创建管理器实例,或者如果create_method参数为False,那么这可以保留为None。
proxytype是BaseProxy的子类,BaseProxy使用typeid来创建共享对象的代理。如果为None,那么会自动创建一个代理类。
exposed用于指定一个序列的方法名称,该名称可以允许使用typeid的代理对象BaseProxy的_callmethod()方法来访问,(如果exposed为None,则使用proxytype.exposed,如果存在)。在没有指定公开列表的情况下,将可以访问共享对象的所有“公共方法”。(这里的“公共方法”是指具有__call __()方法并且名称不以“_”开头的任何属性。)
method_to_typeid是一个映射,用于指定返回代理的那些公开方法的返回类型。它将方法名映射到typeid字符串。 (如果method_to_typeid为None,则使用proxytype.method_to_typeid,如果存在)。如果方法的名称不是此映射的键,或者映射为None,则方法返回的对象将按值复制。
create_method确定是否应该使用名称typeid创建一个方法,该方法可以用于告诉服务器进程创建一个新的共享对象并为其返回一个代理。默认情况下为True。
**address:**管理器使用的地址
**join(timeout=None):**阻塞
现在可以来看看,SyncManager类的定义了,其实很简单。
class SyncManager(BaseManager):
'''
Subclass of `BaseManager` which supports a number of shared object types.
The types registered are those intended for the synchronization
of threads, plus `dict`, `list` and `Namespace`.
The `multiprocessing.Manager()` function creates started instances of
this class.
'''
SyncManager.register('Queue', Queue.Queue)
SyncManager.register('JoinableQueue', Queue.Queue)
SyncManager.register('Event', threading.Event, EventProxy)
SyncManager.register('Lock', threading.Lock, AcquirerProxy)
SyncManager.register('RLock', threading.RLock, AcquirerProxy)
SyncManager.register('Semaphore', threading.Semaphore, AcquirerProxy)
SyncManager.register('BoundedSemaphore', threading.BoundedSemaphore,
AcquirerProxy)
SyncManager.register('Condition', threading.Condition, ConditionProxy)
SyncManager.register('Pool', Pool, PoolProxy)
SyncManager.register('list', list, ListProxy)
SyncManager.register('dict', dict, DictProxy)
SyncManager.register('Value', Value, ValueProxy)
SyncManager.register('Array', Array, ArrayProxy)
SyncManager.register('Namespace', Namespace, NamespaceProxy)
# types returned by methods of PoolProxy
SyncManager.register('Iterator', proxytype=IteratorProxy, create_method=False)
SyncManager.register('AsyncResult', create_method=False)
上面的Queue()、Event()等等都是该类的方法,比如Event(),它是创建一个共享的threading.Event对象并返回一个代理。当然除了上面这些外,其实我们也可以用register()向管理器注册新的类型,如下:
#coding=utf-8
from multiprocessing.managers import BaseManager
class MathsClass(object):
def add(self, x, y):
return x + y
def mul(self, x, y):
return x * y
class MyManager(BaseManager):
pass
MyManager.register('Maths', MathsClass)
if __name__ == '__main__':
manager = MyManager()
manager.start()
maths = manager.Maths()
print maths.add(4, 3) # prints 7
print maths.mul(7, 8) # prints 56
下面看个简单的例子
#coding=utf-8
import multiprocessing
def fun(ns):
ns.x.append(1)
ns.y.append('x')
if __name__ == '__main__':
manager = multiprocessing.Manager()
ns = manager.Namespace()
ns.x = []
ns.y = []
print "before",ns
p = multiprocessing.Process(target=fun,args=(ns))
p.start()
p.join()
print "after",ns
本程序的目的是想得到x=[1],y=[‘x’],但是没有得到,这是为什么呢?这是因为manager对象仅能传播一个可变对象本身所做的修改,如果一个manager.list()对象,管理列表本身的任何更改会传播到所有其他进程,但是如果容器对象内部还包括可修改对象,则内部可修改对象的任何更改都不会传播到其他进程。上面例子中,ns是一个容器,它本身的改变会传播到所有进程,但是它的内部对象x,y是可变对象,它们的改变不会传播到其他进程,所有没有得到我们所要的结果。可以作如下修改:
#coding=utf-8
import multiprocessing
def fun(ns,x,y):
x.append(1)
y.append('x')
ns.x = x
ns.y = y
if __name__ == '__main__':
manager = multiprocessing.Manager()
ns = manager.Namespace()
ns.x = []
ns.y = []
print "before",ns
p = multiprocessing.Process(target=fun,args=(ns,ns.x,ns.y,))
p.start()
p.join()
print "after",ns
这个例子比较简单,以后碰到好的例子,再跟大家分享。另外Python官方手册上有很多帮助大家理解这些概念的例子,有兴趣的可以去看看,今天就写到这儿了,不正之处欢迎批评指正!下篇博文介绍进程池和线程池。
multiprocessing模块的内存共享(点击此处可以参看),下面讲进程池。有些情况下,所要完成的工作可以上篇博文介绍了multiprocessing模块的内存共享,下面讲进程池。有些情况下,所要完成的工作可以分解并独立地分布到多个工作进程,对于这种简单的情况,可以用Pool类来管理固定数目的工作进程。作业的返回值会收集并作为一个列表返回。Pool可以提供指定数量的进程,供用户调用,当有新的请求提交到pool中时,如果池还没有满,那么就会创建一个新的进程用来执行该请求;但如果池中的进程数已经达到规定最大值,那么该请求就会等待,直到池中有进程结束,才会创建新的进程来它。
在网上找到了一篇非常好的分析进程池源码的文章,在这里跟大家分享下,篇幅比较长,希望大家能够有耐心的看完它,仔细体会。
进程池使用multiprocessing.pool,pool的构造如下:
multiprocessing.Pool([processes[, initializer[, initargs[, maxtasksperchild]]]])
其中:
processes表示pool中进程的数目,默认地为当前CPU的核数可以通过multiprocessing.cpu_count()方法参考你机器上cpu数量。
initializer表示工作进程start时调用的初始化函数。
initargs表示initializer函数的参数,如果initializer不为None,在每个工作进程start之前会调用。
maxtasksperchild表示每个工作进程在退出/被其他新的进程替代前,需要完成的工作任务数,默认为None,表示工作进程存活时间与pool相同,即不会自动退出/被替换。
主要方法:
apply(func[, args[, kwds]]) :apply用于传递不定参数,同python中的apply函数一致(不过内置的apply函数从2.3以后就不建议使用了),主进程会阻塞于函数,主进程的执行流程同单进程一致。
apply_async(func[, args[, kwds[, callback]]]) :与apply用法一致,但它是非阻塞的且支持结果返回后进行回调。
主进程循环运行过程中不等待apply_async的返回结果,在主进程结束后,即使子进程还未返回整个程序也会退出。虽然 apply_async是非阻塞的,但其返回结果的get方法却是阻塞的,如使用result.get()会阻塞主进程。
如果我们对返回结果不感兴趣, 那么可以在主进程中使用pool.close与pool.join来防止主进程退出。注意join方法一定要在close或terminate之后调用。
map(func, iterable[, chunksize]) :map方法与在功能上等价与内置的map(),只不过单个任务会并行运行。它会使进程阻塞直到结果返回。但需注意的是其第二个参数虽然描述的为iterable, 但在实际使用中发现只有在整个队列全部就绪后,程序才会运行子进程。
map_async(func, iterable[, chunksize[, callback]]) :与map用法一致,但是它是非阻塞的。其有关事项见apply_async。
imap(func, iterable[, chunksize]) :与map不同的是, imap的返回结果为iter,需要在主进程中主动使用next来驱动子进程的调用。即使子进程没有返回结果,主进程对于gen_list(l)的 iter还是会继续进行, 另外根据python2.6文档的描述,对于大数据量的iterable而言,将chunksize设置大一些比默认的1要好。
imap_unordered(func, iterable[, chunksize]) :同imap一致,只不过其并不保证返回结果与迭代传入的顺序一致。
close() :关闭pool,使其不再接受新的任务。
terminate() :结束工作进程,不再处理未处理的任务。
join() :主进程阻塞等待子进程的退出, join方法要在close或terminate之后使用。
它的源码在multiprocessing包pool.py里,Pool对象的初始化函数如下:
class Pool(object):
'''
Class which supports an async version of the `apply()` builtin
'''
Process = Process
def __init__(self, processes=None, initializer=None, initargs=(),
maxtasksperchild=None):
self._setup_queues()
self._taskqueue = Queue.Queue()
self._cache = {}
self._state = RUN
self._maxtasksperchild = maxtasksperchild
self._initializer = initializer
self._initargs = initargs
if processes is None:
try:
processes = cpu_count()
except NotImplementedError:
processes = 1
if processes < 1:
raise ValueError("Number of processes must be at least 1")
if initializer is not None and not hasattr(initializer, '__call__'):
raise TypeError('initializer must be a callable')
self._processes = processes
self._pool = []
self._repopulate_pool()
self._worker_handler = threading.Thread(
target=Pool._handle_workers,
args=(self, )
)
self._worker_handler.daemon = True
self._worker_handler._state = RUN
self._worker_handler.start()
self._task_handler = threading.Thread(
target=Pool._handle_tasks,
args=(self._taskqueue, self._quick_put, self._outqueue,
self._pool, self._cache)
)
self._task_handler.daemon = True
self._task_handler._state = RUN
self._task_handler.start()
self._result_handler = threading.Thread(
target=Pool._handle_results,
args=(self._outqueue, self._quick_get, self._cache)
)
self._result_handler.daemon = True
self._result_handler._state = RUN
self._result_handler.start()
self._terminate = Finalize(
self, self._terminate_pool,
args=(self._taskqueue, self._inqueue, self._outqueue, self._pool,
self._worker_handler, self._task_handler,
self._result_handler, self._cache),
exitpriority=15
)
主要数据结构有:
self._inqueue 接收任务队列(SimpleQueue),用于主进程将任务发送给worker进程
self._outqueue 发送结果队列(SimpleQueue),用于worker进程将结果发送给主进程
self._taskqueue 同步的任务队列,保存线程池分配给主进程的任务
self._cache = {} 任务缓存
self._processes worker进程个数
self._pool = [] woker进程队列
进程池工作时,任务的接收、分配。结果的返回,均由进程池内部的各个线程合作完成,来看看进程池内部由那些线程:
_work_handler线程,负责保证进程池中的worker进程在有退出的情况下,创建出新的worker进程,并添加到进程队列(pools)中,保持进程池中的worker进程数始终为processes个。_worker_handler线程回调函数为Pool._handler_workers方法,在进程池state==RUN时,循环调用_maintain_pool方法,监控是否有进程退出,并创建新的进程,append到进程池pools中,保持进程池中的worker进程数始终为processes个。
self._worker_handler = threading.Thread(
target=Pool._handle_workers,
args=(self, )
)
Pool._handle_workers方法在_worker_handler线程状态为运行时(status==RUN),循环调用_maintain_pool方法:
def _maintain_pool(self):
if self._join_exited_workers():
self._repopulate_pool()
_join_exited_workers()监控pools队列中的进程是否有结束的,有则等待其结束,并从pools中删除,当有进程结束时,调用_repopulate_pool(),创建新的进程:
w = self.Process(target=worker,
args=(self._inqueue, self._outqueue,
self._initializer, self._initargs,
self._maxtasksperchild)
)
self._pool.append(w)
w是新创建的进程,它是用来处理实际任务的进程,worker是它的回调函数:
def worker(inqueue, outqueue, initializer=None, initargs=(), maxtasks=None):
assert maxtasks is None or (type(maxtasks) == int and maxtasks > 0)
put = outqueue.put
get = inqueue.get
if hasattr(inqueue, '_writer'):
inqueue._writer.close()
outqueue._reader.close()
if initializer is not None:
initializer(*initargs)
completed = 0
while maxtasks is None or (maxtasks and completed < maxtasks):
try:
task = get()
except (EOFError, IOError):
debug('worker got EOFError or IOError -- exiting')
break
if task is None:
debug('worker got sentinel -- exiting')
break
job, i, func, args, kwds = task
try:
result = (True, func(*args, **kwds))
except Exception, e:
result = (False, e)
try:
put((job, i, result))
except Exception as e:
wrapped = MaybeEncodingError(e, result[1])
debug("Possible encoding error while sending result: %s" % (
wrapped))
put((job, i, (False, wrapped)))
completed += 1
debug('worker exiting after %d tasks' % completed)
所有worker进程都使用worker回调函数对任务进行统一的处理,从源码中可以看出:
它的功能是从接入任务队列中(inqueue)读取出task任务,然后根据任务的函数、参数进行调用(result = (True, func(*args, **kwds),
再将结果放入结果队列中(outqueue),如果有最大处理上限的限制maxtasks,那么当进程处理到任务数上限时退出。
_task_handler线程,负责从进程池中的task_queue中,将任务取出,放入接收任务队列(Pipe)
self._task_handler = threading.Thread(
target=Pool._handle_tasks,
args=(self._taskqueue, self._quick_put, self._outqueue, self._pool)
)
Pool._handle_tasks方法不断从task_queue中获取任务,并放入接受任务队列(in_queue),以此触发worker进程进行任务处理。当从task_queue读取到None元素时,
表示进程池将要被终止(terminate),不再处理之后的任务请求,同时向接受任务队列和结果任务队列put None元素,通知其他线程结束。
_handle_results线程,负责将处理完的任务结果,从outqueue(Pipe)中读取出来,放在任务缓存cache中,
self._result_handler = threading.Thread(
target=Pool._handle_results,
args=(self._outqueue, self._quick_get, self._cache)
)
_terminate,这里的_terminate并不是一个线程,而是一个Finalize对象
self._terminate = Finalize(
self, self._terminate_pool,
args=(self._taskqueue, self._inqueue, self._outqueue, self._pool,
self._worker_handler, self._task_handler,
self._result_handler, self._cache),
exitpriority=15
)
Finalize类的构造函数与线程构造函数类似,_terminate_pool是它的回调函数,args回调函数的参数。
_terminate_pool函数负责终止进程池的工作:终止上述的三个线程,终止进程池中的worker进程,清除队列中的数据。
_terminate是个对象而非线程,那么它如何像线程调用start()方法一样,来执行回调函数_terminate_pool呢?查看Pool源码,发现进程池的终止函数:
def terminate(self):
debug('terminating pool')
self._state = TERMINATE
self._worker_handler._state = TERMINATE
self._terminate()
函数中最后将_terminate对象当做一个方法来执行,而_terminate本身是一个Finalize对象,我们看一下Finalize类的定义,发现它实现了__call__方法:
def __call__(self, wr=None):
try:
del _finalizer_registry[self._key]
except KeyError:
sub_debug('finalizer no longer registered')
else:
if self._pid != os.getpid():
res = None
else:
res = self._callback(*self._args, **self._kwargs)
self._weakref = self._callback = self._args = \
self._kwargs = self._key = None
return res
而方法中 self._callback(*self._args, **self._kwargs) 这条语句,就执行了_terminate_pool函数,进而将进程池终止。
进程池中的数据结构、各个线程之间的合作关系如下图所示:

下面接着看下客户端如何对向进程池分配任务,并获取结果的。
我们知道,当进程池中任务队列非空时,才会触发worker进程去工作,那么如何向进程池中的任务队列中添加任务呢,进程池类有两组关键方法来创建任务,分别是apply/apply_async和map/map_async,实际上进程池类的apply和map方法与python内建的两个同名方法类似,apply_async和map_async分别为它们的非阻塞版本。
首先来看apply_async方法,源码如下:
def apply_async(self, func, args=(), kwds={}, callback=None):
assert self._state == RUN
result = ApplyResult(self._cache, callback)
self._taskqueue.put(([(result._job, None, func, args, kwds)], None))
return result
func表示执行此任务的方法
args、kwds分别表func的位置参数和关键字参数
callback表示一个单参数的方法,当有结果返回时,callback方法会被调用,参数即为任务执行后的结果
每调用一次apply_result方法,实际上就向_taskqueue中添加了一条任务,注意这里采用了非阻塞(异步)的调用方式,即apply_async方法中新建的任务只是被添加到任务队列中,还并未执行,不需要等待,直接返回创建的ApplyResult对象,注意在创建ApplyResult对象时,将它放入进程池的缓存_cache中。
任务队列中有了新创建的任务,那么根据上节分析的处理流程,进程池的_task_handler线程,将任务从taskqueue中获取出来,放入_inqueue中,触发worker进程根据args和kwds调用func,运行结束后,将结果放入_outqueue,再由进程池中的_handle_results线程,将运行结果从_outqueue中取出,并找到_cache缓存中的ApplyResult对象,_set其运行结果,等待调用端获取。
apply_async方法既然是异步的,那么它如何知道任务结束,并获取结果呢?这里需要了解ApplyResult类中的两个主要方法:
def get(self, timeout=None):
self.wait(timeout)
if not self._ready:
raise TimeoutError
if self._success:
return self._value
else:
raise self._value
def _set(self, i, obj):
self._success, self._value = obj
if self._callback and self._success:
self._callback(self._value)
self._cond.acquire()
try:
self._ready = True
self._cond.notify()
finally:
self._cond.release()
del self._cache[self._job]
从这两个方法名可以看出,get方法是提供给客户端获取worker进程运行结果的,而运行的结果是通过_handle_result线程调用_set方法,存放在ApplyResult对象中。
_set方法将运行结果保存在ApplyResult._value中,唤醒阻塞在条件变量上的get方法。客户端通过调用get方法,返回运行结果。
apply方法是以阻塞的方式运行获取进程结果,它的实现很简单,同样是调用apply_async,只不过不返回ApplyResult,而是直接返回worker进程运行的结果:
def apply(self, func, args=(), kwds={}):
assert self._state == RUN
return self.apply_async(func, args, kwds).get()
以上的apply/apply_async方法,每次只能向进程池分配一个任务,那如果想一次分配多个任务到进程池中,可以使用map/map_async方法。首先来看下map_async方法是如何定义的:
def map_async(self, func, iterable, chunksize=None, callback=None):
assert self._state == RUN
if not hasattr(iterable, '__len__'):
iterable = list(iterable)
if chunksize is None:
chunksize, extra = divmod(len(iterable), len(self._pool) * 4)
if extra:
chunksize += 1
if len(iterable) == 0:
chunksize = 0
task_batches = Pool._get_tasks(func, iterable, chunksize)
result = MapResult(self._cache, chunksize, len(iterable), callback)
self._taskqueue.put((((result._job, i, mapstar, (x,), {})
for i, x in enumerate(task_batches)), None))
return result
func表示执行此任务的方法
iterable表示任务参数序列
chunksize表示将iterable序列按每组chunksize的大小进行分割,每个分割后的序列提交给进程池中的一个任务进行处理
callback表示一个单参数的方法,当有结果返回时,callback方法会被调用,参数即为任务执行后的结果
从源码可以看出,map_async要比apply_async复杂,首先它会根据chunksize对任务参数序列进行分组,chunksize表示每组中的任务个数,当默认chunksize=None时,根据任务参数序列和进程池中进程数计算分组数:chunk, extra = divmod(len(iterable), len(self._pool) * 4)。假设进程池中进程数为len(self._pool)=4,任务参数序列iterable=range(123),那么chunk=7, extra=11,向下执行,得出chunksize=8,表示将任务参数序列分为8组。任务实际分组:
task_batches = Pool._get_tasks(func, iterable, chunksize)
def _get_tasks(func, it, size):
it = iter(it)
while 1:
x = tuple(itertools.islice(it, size))
if not x:
return
yield (func, x)
这里使用yield将_get_tasks方法编译成生成器。实际上对于range(123)这样的序列,按照chunksize=8进行分组后,一共16组每组的元素如下:
(func, (0, 1, 2, 3, 4, 5, 6, 7))
(func, (8, 9, 10, 11, 12, 13, 14, 15))
(func, (16, 17, 18, 19, 20, 21, 22, 23))
...
(func, (112, 113, 114, 115, 116, 117, 118, 119))
(func, (120, 121, 122))
分组之后,这里定义了一个MapResult对象:result = MapResult(self._cache, chunksize, len(iterable), callback)它继承自AppyResult类,同样提供get和_set方法接口。将分组后的任务放入任务队列中,然后就返回刚刚创建的result对象。
self._taskqueue.put((((result._job, i, mapstar, (x,), {})
for i, x in enumerate(task_batches)), None))
以任务参数序列=range(123)为例,实际上这里向任务队列中put了一个16组元组元素的集合,元组依次为:
(result._job, 0, mapstar, ((func, (0, 1, 2, 3, 4, 5, 6, 7)),), {}, None)
(result._job, 1, mapstar, ((func, (8, 9, 10, 11, 12, 13, 14, 15)),), {}, None)
……
(result._job, 15, mapstar, ((func, (120, 121, 122)),), {}, None)
注意每一个元组中的 i,它表示当前元组在整个任务元组集合中的位置,通过它,_handle_result线程才能将worker进程运行的结果,以正确的顺序填入到MapResult对象中。
注意这里只调用了一次put方法,将16组元组作为一个整体序列放入任务队列,那么这个任务是否_task_handler线程是否也会像apply_async方法一样,将整个任务序列传递给_inqueue,这样就会导致进程池中的只有一个worker进程获取到任务序列,而并非起到多进程的处理方式。我们来看下_task_handler线程是怎样处理的:
def _handle_tasks(taskqueue, put, outqueue, pool, cache):
thread = threading.current_thread()
for taskseq, set_length in iter(taskqueue.get, None):
i = -1
for i, task in enumerate(taskseq):
if thread._state:
debug('task handler found thread._state != RUN')
break
try:
put(task)
except Exception as e:
job, ind = task[:2]
try:
cache[job]._set(ind, (False, e))
except KeyError:
pass
else:
if set_length:
debug('doing set_length()')
set_length(i+1)
continue
break
else:
debug('task handler got sentinel')
注意到语句 for i, task in enumerate(taskseq),原来_task_handler线程在通过taskqueue获取到任务序列后,并不是直接放入_inqueue中的,而是将序列中任务按照之前分好的组,依次放入_inqueue中的,而循环中的task即上述的每个任务元组:(result._job, 0, mapstar, ((func, (0, 1, 2, 3, 4, 5, 6, 7)),), {}, None)。接着触发worker进程。worker进程获取出每组任务,进行任务的处理:
job, i, func, args, kwds = task
try:
result = (True, func(*args, **kwds))
except Exception, e:
result = (False, e)
try:
put((job, i, result))
except Exception as e:
wrapped = MaybeEncodingError(e, result[1])
debug("Possible encoding error while sending result: %s" % (
wrapped))
put((job, i, (False, wrapped)))
根据之前放入_inqueue的顺序对应关系:
(result._job, 0, mapstar, ((func, (0, 1, 2, 3, 4, 5, 6, 7)),), {}, None)
job, i, func, args, kwds = task
可以看出,元组中 mapstar 表示这里的回调函数func,((func, (0, 1, 2, 3, 4, 5, 6, 7)),)和{}分别表示args和kwds参数。
执行result = (True, func(*args, **kwds))
再来看下mapstar是如何定义的:
def mapstar(args):
return map(*args)
这里mapstar表示回调函数func,它的定义只有一个参数,而在worker进程执行回调时,使用的是func(*args, **kwds)语句,这里多一个参数能够正确执行吗?答案时肯定的,在调用mapstar时,如果kwds为空字典,那么传入第二个参数不会影响函数的调用,而一个无参函数func_with_none_params,在调用时使用func_with_none_params(*(), **{})也是没有问题的,python会自动忽视传入的两个空参数。
看到这里,我们明白了,实际上对任务参数分组后,每一组的任务是通过内建的map方法来进行调用的。
运行之后调用put(job, i, result)将结果放入_outqueue中,_handle_result线程会从_outqueue中将结果取出,并找到_cache缓存中的MapResult对象,_set其运行结果
现在来我们来总结下,进程池的map_async方法是如何运行的,我们将range(123)这个任务序列,将它传入map_async方法,假设不指定chunksize,并且cpu为四核,那么方法内部会分为16个组(0~14组每组8个元素,最后一组3个元素)。将分组后的任务放入任务队列,一共16组,那么每个进程需要运行4次来处理,每次通过内建的map方法,顺序将组中8个任务执行,再将结果放入_outqueue,找到_cache缓存中的MapResult对象,_set其运行结果,等待客户端获取。使用map_async方法会调用多个worker进程处理任务,每个worler进程运行结束,会将结果传入_outqueue,再有_handle_result线程将结果写入MapResult对象,那如何保证结果序列的顺序与调用map_async时传入的任务参数序列一致呢,我们来看看MapResult的构造函数和_set方法的实现。
def __init__(self, cache, chunksize, length, callback):
ApplyResult.__init__(self, cache, callback)
self._success = True
self._value = [None] * length
self._chunksize = chunksize
if chunksize <= 0:
self._number_left = 0
self._ready = True
del cache[self._job]
else:
self._number_left = length//chunksize + bool(length % chunksize)
def _set(self, i, success_result):
success, result = success_result
if success:
self._value[i*self._chunksize:(i+1)*self._chunksize] = result
self._number_left -= 1
if self._number_left == 0:
if self._callback:
self._callback(self._value)
del self._cache[self._job]
self._cond.acquire()
try:
self._ready = True
self._cond.notify()
finally:
self._cond.release()
else:
self._success = False
self._value = result
del self._cache[self._job]
self._cond.acquire()
try:
self._ready = True
self._cond.notify()
finally:
self._cond.release()
MapResult类中,_value保存map_async的运行结果,初始化时为一个元素为None的list,list的长度与任务参数序列的长度相同,_chunksize表示将任务分组后,每组有多少个任务,_number_left表示整个任务序列被分为多少个组。_handle_result线程会通过_set方法将worker进程的运行结果保存到_value中,那么如何将worker进程运行的结果填入到_value中正确的位置呢,还记得在map_async在向task_queue填入任务时,每组中的 i吗,i表示的就是当前任务组的组号,_set方法会根据当前任务的组号即参数 i,并且递减_number_left,当_number_left递减为0时,表示任务参数序列中的所有任务都已被woker进程处理,_value全部被计算出,唤醒阻塞在get方法上的条件变量,是客户端可以获取运行结果。
map函数为map_async的阻塞版本,它在map_async的基础上,调用get方法,直接阻塞到结果全部返回:
def map(self, func, iterable, chunksize=None):
assert self._state == RUN
return self.map_async(func, iterable, chunksize).get()
我们知道,进程池内部由多个线程互相协作,向客户端提供可靠的服务,那么这些线程之间是怎样做到数据共享与同步的呢?在客户端使用apply/map函数向进程池分配任务时,使用self._taskqueue来存放任务元素,_taskqueue定义为Queue.Queue(),这是一个python标准库中的线程安全的同步队列,它保证通知时刻只有一个线程向队列添加或从队列获取元素。这样,主线程向进程池中分配任务(taskqueue.put),进程池中_handle_tasks线程读取_taskqueue队列中的元素,两个线程同时操作taskqueue,互不影响。进程池中有N个worker进程在等待任务下发,那么进程池中的_handle_tasks线程读取出任务后,又如何保证一个任务不被多个worker进程获取到呢?我们来看下_handle_tasks线程将任务读取出来之后如何交给worker进程的:
for taskseq, set_length in iter(taskqueue.get, None):
i = -1
for i, task in enumerate(taskseq):
if thread._state:
debug('task handler found thread._state != RUN')
break
try:
put(task)
except Exception as e:
job, ind = task[:2]
try:
cache[job]._set(ind, (False, e))
except KeyError:
pass
else:
if set_length:
debug('doing set_length()')
set_length(i+1)
continue
break
else:
debug('task handler got sentinel')
在从taskqueue中get到任务之后,对任务中的每个task,调用了put函数,这个put函数实际上是将task放入了管道,而主进程与worker进程的交互,正是通过管道来完成的。
再来看看worker进程的定义:
w = self.Process(target=worker,
args=(self._inqueue, self._outqueue,
self._initializer,
self._initargs, self._maxtasksperchild)
)
其中self._inqueue和self._outqueue为SimpleQueue()对象,实际是带锁的管道,上述_handle_task线程调用的put函数,即为SimpleQueue对象的方法。我们看到,这里worker进程定义均相同,所以进程池中的worker进程共享self._inqueue和self._outqueue对象,那么当一个task元素被put到共享的_inqueue管道中时,如何确保只有一个worker获取到呢,答案同样是加锁,在SimpleQueue()类的定义中,put以及get方法都带有锁,进行同步,唯一不同的是,这里的锁是用于进程间同步的。这样就保证了多个worker之间能够确保任务的同步。与分配任务类似,在worker进程运行完之后,会将结果put会_outqueue,_outqueue同样是SimpleQueue类对象,可以在多个进程之间进行互斥。
在worker进程运行结束之后,会将执行结果通过管道传回,进程池中有_handle_result线程来负责接收result,取出之后,通过调用_set方法将结果写回ApplyResult/MapResult对象,客户端可以通过get方法取出结果,这里通过使用条件变量进行同步,当_set函数执行之后,通过条件变量唤醒阻塞在get函数的主进程。
进程池终止工作通过调用Pool.terminate()来实现,这里的实现很巧妙,用了一个可调用对象,将终止Pool时的需要执行的回调函数先注册好,等到需要终止时,直接调用对象即可。
self._terminate = Finalize(
self, self._terminate_pool,
args=(self._taskqueue, self._inqueue, self._outqueue, self._pool,
self._worker_handler, self._task_handler,
self._result_handler, self._cache),
exitpriority=15
)
在Finalize类的实现了__call__方法,在运行self._terminate()时,就会调用构造self._terminate时传入的self._terminate_pool对象。
使用map/map_async函数向进程池中批量分配任务时,使用了生成器表达式:
self._taskqueue.put((((result._job, i, mapstar, (x,), {}) for i, x in enumerate(task_batches)), None))
生成器表达式很简单,只需把列表解析的的[]换成()即可,上述表达的列表解析表示为:
[(result._job, i, mapstar, (x,), {}) for i, x in enumerate(task_batches)]
这里使用生成器表达式的好处是,它相当于列表解析的扩展,是对内存有好的,因为它只是生成了一个生成器,当我们需要使用该生成器对应的逻辑目标数据时,它才会通过既定逻辑去生成该数据,所以不会大量占用内存。
在Pool中,_worker_handler线程负责监控、创建新的工作进程,在监控工作进程退出时,同时将退出的进程从进程池中删除掉。这类似于,一边遍历一边删除列表。我们来看下下面代码的实现:
>>> l = [1, 2, 3, 3, 4, 4, 4, 5]
>>> for i in l:
if i in [3, 4, 5]:
l.remove(i)
>>> l
[1, 2, 3, 4, 5]
我们看到l没有将所有的3和4都删除掉,这是因为remove改变了l的大小。再看下面的实现:
>>> l = [1, 2, 3, 3, 4, 4, 4, 5]
>>> for i in range(len(l)):
if l[i] in [3, 4]:
del l[i]
Traceback (most recent call last):
File "" , line 2, in <module>
if l[i] in [3, 4]:
IndexError: list index out of range
>>>
同样因为del l[i]时,l的大小改变,继续访问下去导致访问越界。而标准库中的进程池给出了遍历删除的一个正确示例:
for i in reversed(range(len(self._pool))):
worker = self._pool[i]
if worker.exitcode is not None:
worker.join()
cleaned = True
del self._pool[i]
使用reversed,从后向前删除list中的元素,这样会保证所有符合删除条件的元素被删除掉:
>>> l = [1, 2, 3, 3, 4, 4, 4, 5]
>>> for i in reversed(range(len(l))):
if l[i] in [3, 4, 5]:
del l[i]
>>> l
[1, 2]
在Python中还有一个线程池的概念,它也有并发处理能力,在一定程度上能提高系统运行效率;不正之处欢迎批评指正。
线程的生命周期可以分为5个状态:创建、就绪、运行、阻塞和终止。自线程创建到终止,线程便不断在运行、创建和销毁这3个状态。一个线程的运行时间可由此可以分为3部分:线程的启动时间、线程体的运行时间和线程的销毁时间。在多线程处理的情景中,如果线程不能被重用,就意味着每次创建都需要经过启动、销毁和运行3个过程。这必然会增加系统相应的时间,降低了效率。看看之前介绍线程的博文的例子中(点击此处可以阅读),有多少个任务,就创建多少个线程,但是由于Python特有的GIL限制,它并不是真正意义上的多线程,反而会因为频繁的切换任务等开销而降低了性能(点击此处可以了解Python的GIL)。这种情况下可以使用线程池提高运行效率。
线程池的基本原理如下图,它是通过将事先创建多个能够执行任务的线程放入池中,所需要执行的任务通常要被安排在队列任务中。一般情况下,需要处理的任务比线程数目要多,线程执行完当前任务后,会从队列中取下一个任务,知道所有的任务完成。

由于线程预先被创建并放入线程池中,同时处理完当前任务之后并不销毁而是被安排处理下一个任务,因此能够避免多次创建线程,从而节省线程创建和销毁的开销,能带来更好的性能和系统稳定性。所以,说白了,Python的线程池也没有利用到多核或者多CPU的优势,只是跟普通的多线程相比,它不用去多次创建线程,节省了线程创建和销毁的时间,从而提高了性能。
Python中 线程池技术适合处理突发性大量请求或者需要大量线程来完成任务、但每个任务实际处理时间较短的场景,它能有效的避免由于系统创建线程过多而导致性能负荷过大、响应过慢等问题。下面介绍几种利用线程池的方法。
(一)自定义线程池模式
我们可以利用Queue模块和threading模块来实现线程池。Queue用来创建任务队列,threading用来创建一个线程池子。
看下面例子
import Queue,threading
class Worker(threading.Thread):
"""
定义一个能够处理任务的线程类,属于自定义线程类,自定义线程类就需要定义run()函数
"""
def __init__(self,workqueue,resultqueue,**kwargs):
threading.Thread.__init__(self,**kwargs)
self.workqueue = workqueue#存放任务的队列,任务一般都是函数
self.resultqueue = resultqueue#存放结果的队列
def run(self):
while True:
try:
#从任务队列中取出一个任务,block设置为False表示如果队列空了,就会抛出异常
callable,args,kwargs = self.workqueue.get(block=False)
res = callable(*args,**kwargs)
self.resultqueue.put(res)#将任务的结果存放到结果队列中
except Queue.Empty:#抛出空队列异常
break
class WorkerManger(object):
"""
定义一个线程池的类
"""
def __init__(self,num=10):#默认这个池子里有10个线程
self.workqueue = Queue.Queue()#任务队列,
self.resultqueue = Queue.Queue()#存放任务结果的队列
self.workers = []#所有的线程都存放在这个列表中
self._recruitthreads(num)#创建一系列线程的函数
def _recruitthreads(self,num):
"""
创建线程
"""
for i in xrange(num):
worker = Worker(self.workqueue,self.resultqueue)
self.workers.append(worker)
def start(self):
"""
启动线程池中每个线程
"""
for work in self.workers:
work.start()
def wait_for_complete(self):
"""
等待至任务队列中所有任务完成
"""
while len(self.workers):
worker = self.workers.pop()
worker.join()
if worker.isAlive() and not self.workqueue.empty():
self.workers.append(worker)
def add_job(self,callable,*args,**kwargs):
"""
往任务队列中添加任务
"""
self.workqueue.put((callable,args,kwargs))
def get_result(self,*args,**kwargs):
"""
获取结果队列
"""
return self.resultqueue.get(*args,**kwargs)
def add_result(self,result):
self.resultqueue.put(result)
上面定义了一个线程池,它的初始化函数__init__()定义了一些存放相关数据的属性,这在Python的一些内部模块的类的定义中很常见,所有有时候多看看源码其实挺好的,学习大神的编程习惯和编程思想。
另外还要提到一点,Queue模块中的队列,不仅可以存放数据(指字符串,数值,列表,字典等等),还可以存放函数的(也就是任务),上面的代码中,callable是一个函数,当用put()将一个函数添加到队列时,put()接受的参数有函数对象以及该函数的相关参数,而且要是一个整体,所以就有了上面代码中的self.workqueue.put((callable,args,kwargs))。同理,当从这种存放函数的队列中取出数据,它返回的就是一个函数对象包括它的相关参数,有兴趣的可以打印出上面代码中run()里的callable,args,kwargs。如果你对Queue模块不了解,可参考我之前的博文,点击此处即可阅读。
下面就简单的举个小例子吧。
import urllib2,datetime
def open_url(url):
try:
res = urllib2.urlopen(url).getcode()
except urllib2.HTTPError, e:
res = e.code
#print res
res = str(res)
with open('/home/liulonghua/无标题文档','wr') as f:
f.write(res)
return res
if __name__ == "__main__":
urls = [
'http://www.python.org',
'http://www.python.org/about/',
'http://www.onlamp.com/pub/a/python/2003/04/17/metaclasses.html',
'http://www.python.org/doc/',
'http://www.python.org/download/',
'http://www.python.org/getit/',
'http://www.python.org/community/',
'https://wiki.python.org/moin/',
'http://planet.python.org/',
'https://wiki.python.org/moin/LocalUserGroups',
'http://www.python.org/psf/',
'http://docs.python.org/devguide/',
'http://www.python.org/community/awards/'
]
t1 = datetime.datetime.now()
w = WorkerManger(2)
for url in urls:
w.add_job(open_url,url)
w.start()
w.wait_for_complete()
t2 = datetime.datetime.now()
print t2 - t1
最后结果如下:
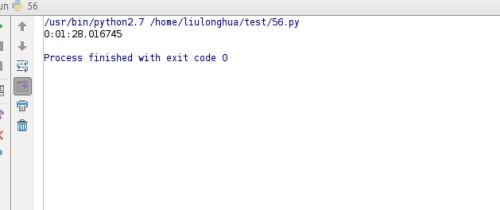
如果把上面代码改成用多线程而不是用线程池,会是怎样的呢?
代码如下:
if __name__ == "__main__":
urls = [
'http://www.python.org',
'http://www.python.org/about/',
'http://www.onlamp.com/pub/a/python/2003/04/17/metaclasses.html',
'http://www.python.org/doc/',
'http://www.python.org/download/',
'http://www.python.org/getit/',
'http://www.python.org/community/',
'https://wiki.python.org/moin/',
'http://planet.python.org/',
'https://wiki.python.org/moin/LocalUserGroups',
'http://www.python.org/psf/',
'http://docs.python.org/devguide/',
'http://www.python.org/community/awards/'
]
t1 = datetime.datetime.now()
for url in urls:
t = threading.Thread(target=open_url,args=(url,))
t.start()
t.join()
t2 = datetime.datetime.now()
print t2-t1
运行结果如下:
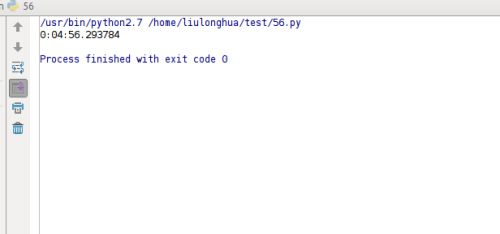
运行效率的差异还是很大的,有兴趣的可以动手试试。
(二)使用现成的线程池模块
下载安装也很简单,用pip工具
sudo pip install threadpool
注意:这里要提到一点,我就陷入这个坑,还好没有花多长时间就解决了。由于我的电脑里有python2.7.12,python3.5,还有一个PyPy5.4.1,上面的指令竟然将threadpool包安装到了PyPy目录下了,所以在python2.7.12里,我import threadpool,它一直报错,如果你的系统里有多个Python版本,又没有用virtualenvs虚拟环境工具,很容易造成这种混乱,虽然我安装了virtualenvs,但在自己的电脑上很少用,这里的解决方法是:
sudo python -m pip install threadpool
以区分PyPy,同理如果是在PyPy环境下安装第三方包的话,用sudo pypy -m pip install packagename,这个在之前的博文中也有介绍,感兴趣的可以点此
该模块主要的类和方法:
1.threadpool.ThreadPool:线程池类,主要是用来分派任务请求和收集运行结果。主要方法有:
(1)init(self,number_workers,q_size,resq_size=0,poll_timeout=5):
建立线程池,并启动对应的num_workers的线程;q_size表示任务请求队列的大小,resq_size表示存放运行结果队列的大小。
(2)createWorkers(self,num_workers,poll_timeout=5):
将num_workers数量对应的线程加入线程池
(3)dismissWorkers(self,num_workers,do_join=False):
告诉num_workers数量的工作线程在执行完当前任务后退出
(4)joinAllDismissWorkers(self):
在设置为退出的线程上执行Thread.join
(5)putRequest(self,request,block=True,timeout=None):
加入一个任务请求到工作队列
(6)pool(self,block=False)
处理任务队列中新请求。也就是循环的调用各个线程结果中的回调和错误回调。不过,当请求队列为空时会抛出 NoResultPending 异常,以表示所有的结果都处理完了。这个特点对于依赖线程执行结果继续加入请求队列的方式不太适合。
(7)wait(self)
等待执行结果,直到所有任务完成。当所有执行结果返回后,线程池内部的线程并没有销毁,而是在等待新任务。因此,wait()之后依然可以在此调用pool.putRequest()往其中添加任务。
\2. threadpool.WorkerThread:处理任务的工作线程,主要有run()方法和dismiss()方法。
3.threadpool.WorkRequest:任务请求类,包含有具体执行方法的工作请求类
init(self,callable,args=None,kwds=None,requestID=None,callback=None,exc_callback=None)
创建一个工作请求。
4.makeRequests(callable_,args_list,callback=None,exc_callback=_handle_thread_exception):
主要函数,用来创建具有相同的执行函数但参数不同的一系列工作请求。
有了上面自定义线程池模式的基础,这个模块不难理解,有兴趣的可以去看看该模块的源码。它的使用步骤一般如下:
(1)引入threadpool模块
(2)定义线程函数
(3)创建线程 池threadpool.ThreadPool()
(4)创建需要线程池处理的任务即threadpool.makeRequests()
(5)将创建的多个任务put到线程池中,threadpool.putRequest
(6)等到所有任务处理完毕theadpool.pool()
将上面的例子用线程池模块进行修改,代码如下:
import threadpool
if __name__ == "__main__":
urls = [
'http://www.python.org',
'http://www.python.org/about/',
'http://www.onlamp.com/pub/a/python/2003/04/17/metaclasses.html',
'http://www.python.org/doc/',
'http://www.python.org/download/',
'http://www.python.org/getit/',
'http://www.python.org/community/',
'https://wiki.python.org/moin/',
'http://planet.python.org/',
'https://wiki.python.org/moin/LocalUserGroups',
'http://www.python.org/psf/',
'http://docs.python.org/devguide/',
'http://www.python.org/community/awards/'
]
t1 = datetime.datetime.now()
pool = threadpool.ThreadPool(2)
requests = threadpool.makeRequests(open_url,urls)
[pool.putRequest(req) for req in requests]
pool.wait()
t2 = datetime.datetime.now()
print t2-t1
执行结果如下:
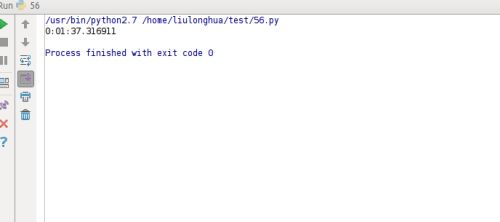
该模块的其它方法,感兴趣的可以自己动手体会下。
(3)multiprocessing.dummy 执行多线程任务
multiprocessing.dummy 模块与 multiprocessing 模块的区别: dummy 模块是多线程,而 multiprocessing 是多进程, api 都是通用的。
Python3里的multiprocessing里也有现成的线程池,如下
from multiprocessing.pool import ThreadPool
有时候看到有人这么用dummy,from multiprocessing.dummy import Pool as ThreadPool ,把它当作了一个线程池。它的属性和方法可以参考进程池。将上面的例子可以用这种方法改下代码如下:
from multiprocessing.dummy import Pool as ThreadPool
if __name__ == "__main__":
urls = [
'http://www.python.org',
'http://www.python.org/about/',
'http://www.onlamp.com/pub/a/python/2003/04/17/metaclasses.html',
'http://www.python.org/doc/',
'http://www.python.org/download/',
'http://www.python.org/getit/',
'http://www.python.org/community/',
'https://wiki.python.org/moin/',
'http://planet.python.org/',
'https://wiki.python.org/moin/LocalUserGroups',
'http://www.python.org/psf/',
'http://docs.python.org/devguide/',
'http://www.python.org/community/awards/'
]
t1 = datetime.datetime.now()
pool =ThreadPool(2)
pool.map(open_url,urls)
pool.close()
pool.join()
t2 = datetime.datetime.now()
print t2-t1
运行结果如下:

=_handle_thread_exception):
主要函数,用来创建具有相同的执行函数但参数不同的一系列工作请求。
有了上面自定义线程池模式的基础,这个模块不难理解,有兴趣的可以去看看该模块的源码。它的使用步骤一般如下:
(1)引入threadpool模块
(2)定义线程函数
(3)创建线程 池threadpool.ThreadPool()
(4)创建需要线程池处理的任务即threadpool.makeRequests()
(5)将创建的多个任务put到线程池中,threadpool.putRequest
(6)等到所有任务处理完毕theadpool.pool()
将上面的例子用线程池模块进行修改,代码如下:
import threadpool
if __name__ == "__main__":
urls = [
'http://www.python.org',
'http://www.python.org/about/',
'http://www.onlamp.com/pub/a/python/2003/04/17/metaclasses.html',
'http://www.python.org/doc/',
'http://www.python.org/download/',
'http://www.python.org/getit/',
'http://www.python.org/community/',
'https://wiki.python.org/moin/',
'http://planet.python.org/',
'https://wiki.python.org/moin/LocalUserGroups',
'http://www.python.org/psf/',
'http://docs.python.org/devguide/',
'http://www.python.org/community/awards/'
]
t1 = datetime.datetime.now()
pool = threadpool.ThreadPool(2)
requests = threadpool.makeRequests(open_url,urls)
[pool.putRequest(req) for req in requests]
pool.wait()
t2 = datetime.datetime.now()
print t2-t1
执行结果如下:
[外链图片转存中…(img-VTLo3K4X-1605589658650)]
该模块的其它方法,感兴趣的可以自己动手体会下。
(3)multiprocessing.dummy 执行多线程任务
multiprocessing.dummy 模块与 multiprocessing 模块的区别: dummy 模块是多线程,而 multiprocessing 是多进程, api 都是通用的。
Python3里的multiprocessing里也有现成的线程池,如下
from multiprocessing.pool import ThreadPool
有时候看到有人这么用dummy,from multiprocessing.dummy import Pool as ThreadPool ,把它当作了一个线程池。它的属性和方法可以参考进程池。将上面的例子可以用这种方法改下代码如下:
from multiprocessing.dummy import Pool as ThreadPool
if __name__ == "__main__":
urls = [
'http://www.python.org',
'http://www.python.org/about/',
'http://www.onlamp.com/pub/a/python/2003/04/17/metaclasses.html',
'http://www.python.org/doc/',
'http://www.python.org/download/',
'http://www.python.org/getit/',
'http://www.python.org/community/',
'https://wiki.python.org/moin/',
'http://planet.python.org/',
'https://wiki.python.org/moin/LocalUserGroups',
'http://www.python.org/psf/',
'http://docs.python.org/devguide/',
'http://www.python.org/community/awards/'
]
t1 = datetime.datetime.now()
pool =ThreadPool(2)
pool.map(open_url,urls)
pool.close()
pool.join()
t2 = datetime.datetime.now()
print t2-t1