python的字符串类型
一、python2的字符串类型
在python2中,字符串一般有两种类型,unicode和str。(python3中是Unicode类型)
str类型,字节码类型,根据某种编码把字符串转成对应的字节,一个字符根据不同的编码规则对应不同的字节数。GBK编码一个字符对应两个字节。
unicode类型,则是用unicode编码的字符串,一个字符对应两个字节。
直接赋值字符串,类型为str,str为字节串,会按照开头的encoding来编码成对应的字节。
赋值的时候在字符串前面加个u,类型则为unicode,直接按照unicode编码成两个字节。
# coding=utf-8
s1 = "字节串"
print(type(s1)) #输出 ,按照开头的encoding来编码成相应的字节
print(len(s1)) #输出9,因为按utf8编码,一个汉字占3个字节,3个字就占9个字节
s2 = u"万国码"
print(type(s2)) #输出 ,用unicode编码,2个字节1个字符
print(len(s2)) #输出3,unicode用字符个数来算长度,从这个角度上看,unicode才是真正意义上的字符串类型
E:\PycharmProjects\LEDdisplay2\venv\Scripts\python.exe E:/PycharmProjects/LEDdisplay2/1.py
<type 'str'>
9
<type 'unicode'>
3
Process finished with exit code 0
再举个例子,比如要从一个文件中找出所有后两位是’字符’的词语,在进行判断的时候:
# coding=utf-8
s = '中文字符'
s[-2:] == '字符‘
# 返回false,本以为相等但在python2中是不相等的
# 这里的”字符是用开头的encoding声明解释的,我开头用的是utf8,汉字占3个字节,所以“字符”占了6个字节),而s[-2:]取的是最后两个”双字节“,所以不相同。
s = u'中文字符'
s[-2:] == u'字符’
# 加u强制转换成unicode
# 返回true,这也是为什么说unicode是真正意义上的字符串类型。因为使用的是unicode,”字符“占的是两个”双字节“,一个"双字节“一个字。
对于经常处理中文字符串的人,统一用unicode(加u强制转换成unicode)就可以避免这个坑了。
虽然有些字符串处理函数用str也可以,应该是函数里面帮你处理了编码问题。
二、python3的字符串类型
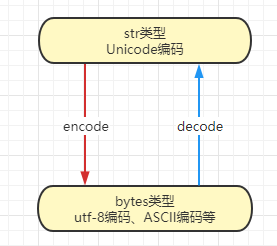
python3中,字符串是以Unicode编码的,是str类型。
如果要在网络上传输,或者保存到磁盘,就需要把str变为以字节为单位的bytes。python3中对bytes类型的数据用带b前缀的单引号或者双引号表示。
以Unicode表示的str通过encode()方法可以编码为指定的bytes。反过来,从网络或磁盘上读取的字节流,即bytes,要把bytes变为str,通过decode()方法。
>>> "ABC".encode("utf-8")
b'ABC'
>>> "中文".encode("utf-8")
b'\xe4\xb8\xad\xe6\x96\x87'
>>> '中文'.encode('ascii')
Traceback (most recent call last):
File "" , line 1, in <module>
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
# 纯英文的str可以用ASCII编码为bytes,内容是一样的,含有中文的str可以用UTF-8编码为bytes。
# 含有中文的str无法用ASCII编码,因为中文编码的范围超过了ASCII编码的范围,Python会报错
# 因为python3中字符串类型是Unicode编码的,所以不需要先decode成Unicode,直接encode成指定编码的bytes
反过来
>>> b'ABC'.decode("utf-8")
'ABC'
>>> b'\xe4\xb8\xad\xe6\x96\x87'.decode("utf-8")
'中文'
>>>
三、python3字符函数举例一二
len()函数,str类型字符串调用时,计算的是字符数,bytes类型调用时,计算的是字节数
>>> len(b'ABC')
3
>>> len(b'\xe4\xb8\xad\xe6\x96\x87')
6
>>> len('中文'.encode('utf-8'))
6
# 1个中文字符经过UTF-8编码后通常会占用3个字节,而1个英文字符只占用1个字节
ord()函数,获取单个字符的整数表示
chr()函数,把单个字符的整数转换为对应的字符
C:\Users\xxx>python3
Python 3.8.7 (tags/v3.8.7:6503f05, Dec 21 2020, 17:59:51) [MSC v.1928 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> ord("A")
65
>>> ord("中")
20013
>>> chr(65)
'A'
>>> chr(25991)
'文'
>>>
chardet.detect(str),查看字符串的编码格式
detect()函数接受一个参数,一个非unicode字符串
它返回一个字典,其中包含自动检测到的字符编码和从0到1的可信度级别。encoding:表示字符编码方式;confidence:表示可信度; language:语言
# encoding: utf-8
import chardet
s = "中文".encode("utf-8")
print(chardet.detect(s))
D:\SoftInstall\Python\Python38\python3.exe E:/PycharmProjects/displayPY3/1.py
{'encoding': 'utf-8', 'confidence': 0.7525, 'language': ''}
Process finished with exit code 0
检测出的编码是ascii,confidence字段表示检测的概率是0.7525(即75.25%)