【中文翻译】Deep Learning for Face Anti-Spoofing: A Survey
Deep Learning for Face Anti-Spoofing: A Survey
- 摘要:
- 1 INTRODUCTION
- 2 BACKGROUND
-
- 2.1 Face Spoofing Attacks
- 2.2 Datasets for Face Anti-Spoofing
- 2.3 Evaluation Metrics
- 2.4 Evaluation Protocols
- 3 DEEP FAS WITH COMMERCIAL RGB CAMERA
-
- 3.1 Hybrid Method
- 3.2 Common Deep Learning Method
-
- 3.2.1 Direct Supervision with Binary Cross Entropy Loss
- 3.2.2 Pixel-wise Supervision
- 3.3 Generalized Deep Learning Method
-
- 3.3.1 Generalization to Unseen Domain
-
- Domain Adaptation
- Domain Generalization
- Federate Learning
- 3.3.2 Generalization to Unknown Attack Types
-
- Zero/Few-Shot Learning
- Anomaly Detection
- 4 DEEP FAS WITH ADVANCED SENSOR
-
- 4.1 Uni-Modal Deep Learning upon Specialized Sensor
- 4.2 Multi-Modal Deep Learning
-
- Multi-Modal Fusion
- Cross-Modal Translation
- 5 DISCUSSION AND FUTURE DIRECTIONS
-
- 5.1 Architecture, Supervision and Interpretability
- 5.2 Representation Learning
- 5.3 Real-World Open-Set FAS
- 5.4 Generic and Unified PA Detection
- 6 CONCLUSION
摘要:
人脸反欺骗(FAS)最近引起了越来越多的关注,因为它在保护人脸识别系统免受呈现攻击presentation attacks (PAs)方面发挥着至关重要的作用。随着越来越多新颖类型的逼真呈现攻击presentation attacks涌现,基于手工特征的传统FAS方法由于其有限的表示能力而变得不可靠。随着近十年来大规模学术数据集的出现,基于深度学习的FAS取得了卓越的表现,并主导了这一领域。但是,该领域的现有关注主要集中在手工制作的功能上,这些功能已经过时,对FAS社区的进步毫无启发性。在本文中,为了激发未来的研究,我们首次全面回顾了基于深度学习的FAS的最新进展。它涵盖了几个新颖而富有洞察力的组成部分:
1)除了使用二进制标签进行监督(例如,"0"表示真正的,"1"表示PAs),我们还研究了具有像素级监督的最新方法(例如,伪深度图);
2)除了传统的数据集内评价方法(traditional intra-dataset evaluation)外,我们还收集和分析了专为领域泛化(domain generalization)和开放集FAS(open-set FAS)设计的最新方法;
3)除了商用RGB相机外,我们还总结了多模态(例如,深度和红外)或专用(例如,光场和闪光)传感器下的深度学习应用。
我们通过逐步处理当前悬而未决的问题并突出潜在的前景来结束这项调查。
1 INTRODUCTION
人脸识别技术[1]以其便捷性和显著的准确性,在签到、移动支付等一些交互式智能应用中得到了应用。然而,现有的人脸识别系统很容易受到打印print、回放replay、化妆makeup、3d面具3D-mask等呈现攻击(PAs)的攻击。因此,为了保证人脸识别系统的安全性,人脸反欺诈(FAS)技术得到了学术界和业界的广泛关注。如图1所示,人脸反欺诈 face anti-spoofing(即“人脸呈现攻击检测 face anti-spoofing”或“人脸活体检测face liveness detection”)是计算机视觉中一个非常活跃的研究课题,近年来发表的文章越来越多。
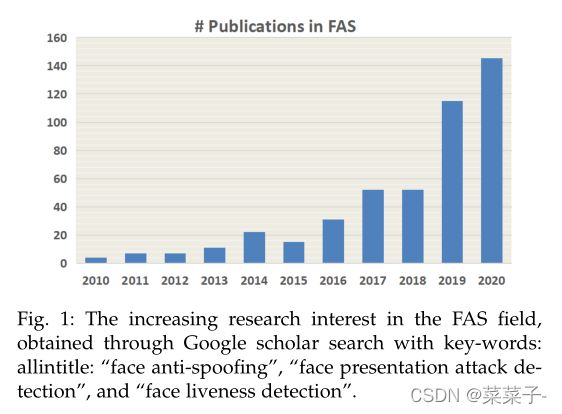
在早期,已有大量传统的基于手工特征的呈现攻击检测方法 presentation attack detection (PAD)被提出。传统算法大多是基于人的活动线索human liveness cues和手工特征human liveness cues进行设计,需要丰富的任务感知先验知识进行设计。在基于活动线索liveness cues的方法中,研究了眨眼eye-blinking、脸头运动face and head move-ment(例如点头和微笑)、注视追踪gaze tracking和远程生理信号gaze tracking(如rPPG)对动态识别的影响。然而,这些生理活动线索通常是从长期互动的面部视频中捕捉到的,不利于实际应用。而且,这些活动线索很容易被视频攻击所模仿,使其不可靠。另一方面,经典手工描述符(如LBP、SIFT、URF、HOG和DoG)被设计用于从各种颜色空间(RGB、HSV和YCbCr)中提取有效的欺骗模式。从表1可以看出,2018年之前的FAS调查主要集中在这一类。
随后,针对静态和动态人脸PAD分别提出了几种混合(手工+深度学习)的和基于端到端深度学习的方法。大多数作品将FAS作为一个二元分类问题(例如,‘0’表示真实人脸,而‘1’表示欺骗人脸),因此受到一个简单的二元交叉熵损失的监督。但是,具有二进制损失的卷积神经网络 (CNN) 可能会发现可以分隔两个类(例如,屏幕边框)的任意线索,但不能发现忠实的欺骗模式(?)。最近,像素级监督pixel-wise supervision吸引了更多的关注,因为它提供了更细粒度的上下文感知监督信号,这有利于深度学习学习固有的欺骗线索。一方面,伪深度标签pseudo depth labels、反射贴图pseudo depth labels、二进制掩码标签binary mask label 和 3D 点云图binary mask label是典型的像素辅助监督pixel-wise auxiliary supervisions,它们描述了像素级/补丁级的本地实时/欺骗线索(which describe the local live/spoof cues in pixel/patch level。)另一方面,除了物理引导的辅助信号外,一些生成深度FAS方法generative deep FAS methods通过宽松的像素重建约束对固有的欺骗模式进行建模。如表1所示,2018年至2020年的最新FAS调查调查了有限数量的(<50)基于深度学习的方法,这些方法很难为社区研究人员提供全面的阐述。请注意,在以前的调查中引入的大多数数据驱动方法都受到传统二进制损失的监督,并且仍然有一个空白来总结出现的像素级监督方法。

同时,具有丰富攻击类型和记录传感器的大规模公共FAS数据集的出现也极大地促进了研究社区的发展。首先,包含大量样本和受试者的数据集已经发布。例如,从10177名受试者记录的CelebA-Spoof,分别包含156384和469153张真实人脸图像和PAs。其次,除了常见的PA类型(如print and replay attack)外,一些最新的数据集还包含更丰富的具有挑战性的PA类型(如SiW-M和WMCA,超过10种PA类型)。然而,从表1中我们可以发现,现有的调查只调查了少数(<15)古老的小规模FAS数据集,无法为基于深度学习的方法提供公平的基准。第三,在记录的方式和硬件方面,除了商用可见RGB相机,多模态和专用传感器有利于FAS任务。如CASIA-SURF和WMCA显示了PAD融合RGB/深度/近红外信息的有效性,而多光谱SWIR和四方向极化相机 four-directional polarized cameras的专用系统对欺骗材料感知效果显著。然而,以往的研究大多集中在使用商用可见相机的单一RGB模态上,而忽视了深度学习在多模态和专用系统上用于高安全性场景的应用。
从评估协议的角度来看,传统的“数据集内部内类型intra-dataset intra-type”和“跨数据集内类型intra-dataset intra-type”协议在以往的FAS调查中被广泛研究(见表1)。由于FAS在实践中实际上是一个开放集问题,不确定的差距(如:环境和攻击类型)之间的训练和测试条件应加以考虑。然而,目前尚无文献考虑未见的域泛化intra-dataset intra-type和未知的PAD等问题。目前研究的大多数FAS方法都是根据预定义的情景和PAs来设计或训练FAS模型。因此,训练后的模型容易在几个特定的域和攻击类型上过拟合,容易受到未知域和未知攻击的攻击。为了弥补学术研究和实际应用之间的差距,在本文中,我们充分研究了四种FAS协议下的基于深度学习的方法,包括具有挑战性的领域泛化domain generalization和开放集PAD情况。与现有文献相比,本工作的主要贡献如下:
●据我们所知,这是第一篇全面涵盖(>100)具有广义协议的单模态和多模态FAS深度学习方法的调查论文。与之前仅考虑二进制损失监督方法的调查相比,我们还详细阐述了具有辅助auxiliary/生成像素监督generative pixel-wise supervision的方法。
●与现有的只有有限数量(<15)小尺度数据集的研究不同,我们对过去到现在的35个公共数据集(包括各种PAs和先进的记录传感器)进行了详细的比较。
●本文介绍了深度学习在四种实际FAS协议(即数据集内内类型intra-dataset intra-type、跨数据集内类型intra-dataset intra-type、数据集内跨类型intra-dataset cross-type和跨数据集跨类型intra-dataset cross-type测试)上的最新进展。因此,它为读者提供了不同应用场景下最先进的方法(如看不见的域泛化unseen domain generalization、未知的攻击检测unseen domain generalization等)。
●表3、表4、表5、表6和表10对现有的具有深刻分类意义的深度FAS方法进行了综合比较,并进行了简要总结和深入讨论。
本文的结构如下:第二节介绍了研究背景,包括演示攻击presentation attacks、数据集datasets、评估指标datasets和FAS任务的协议protocols for the FAS task。第3节介绍了基于可见RGB的FAS的两种检测信号(即二进制损失binary loss和像素损失binary loss),以及针对未知域unseen domains和未知攻击unseen domains的广义学习方法。第4节给出了关于记录传感器recording sensors和模式modalities的比较,然后介绍了特定记录输入的方法。第五部分讨论了深度FAS的研究现状,并指出了未来的发展方向。最后,在第6节给出结论。研究人员可以在https://github.com/ZitongYu/DeepFAS上追踪最新的名单。
2 BACKGROUND
在本节中,我们将首先介绍常见的人脸欺骗攻击,然后研究现有的FAS数据集及其评估指标和协议。
2.1 Face Spoofing Attacks
对自动人脸识别(automatic face recognition AFR)系统的攻击通常分为两类:数字操作digital manipulation和物理呈现攻击physical presentation attacks。前者在数字虚拟领域通过无形的视觉操作欺骗人脸系统,后者通常通过在成像传感器面前将人脸呈现在物理介质上误导真实的AFR系统。在本文中,我们主要研究人脸呈现物理攻击的检测,其流程如图2(a)所示。可以看出,FAS与AFR系统的融合有两种方案:1)并行融合,采用FAS与AFR系统的预测评分。合并后的新最终分数用于确定样本是否来自真正的用户;2)早期人脸PAs检测和欺骗拒绝的串行方案,从而避免了欺骗人脸进入后续的人脸识别阶段。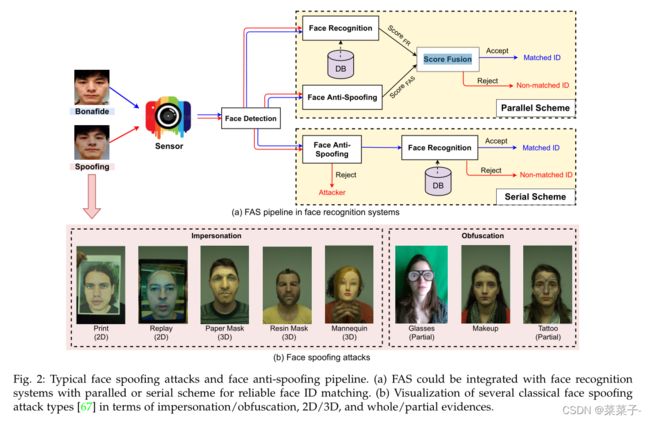
图2(b)给出了几种具有代表性的欺骗攻击类型。根据攻击者的意图,人脸PAs可分为两种典型情况:1)模拟 impersonation,即利用欺骗手段,将真实用户的面部属性复制到照片、电子屏幕、3D蒙版等特殊媒介上,从而被识别为他人;2)模糊处理obfuscation,即使用各种方法来隐藏或去除攻击者的身份,如眼镜、化妆、假发和伪装的脸。
根据PAs的几何特性,将其大致分为2D攻击和3D攻击。2D PAs是通过使用照片或视频向传感器呈现面部属性来实现的。平面/包裹打印的照片,眼睛/嘴巴切割的照片,以及视频的数字回放都是常见的2D攻击变体。随着3D打印技术的成熟,人脸3D掩模已经成为威胁AFR系统的一种新型PA。与传统的2D pa相比,人脸面具在颜色、纹理和几何结构方面更加真实。3D口罩由不同材料制成,例如硬/硬口罩可由纸张、树脂、石膏或塑料制成,而柔性口罩通常由硅或乳胶制成。
考虑到面部区域的覆盖,PAs也可以被分割为整体攻击或部分攻击。如图2(b)所示,与覆盖整个面部区域的常见PAs(如打印照片、视频回放、3D面具)相比,少数局部攻击仅针对面部特定区域(如部分切割的打印照片、在眼睛区域佩戴搞笑眼镜、在脸颊区域局部纹身),它们更模糊,更有挑战性。
2.2 Datasets for Face Anti-Spoofing
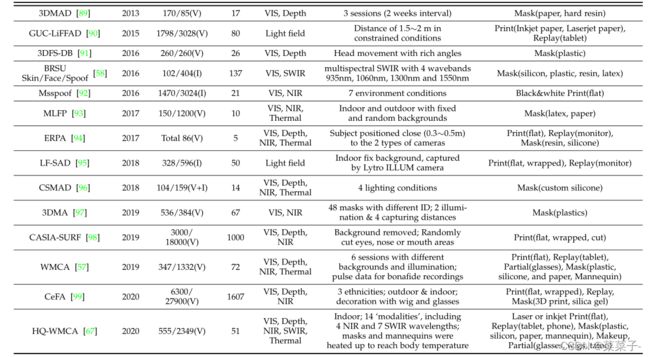
在训练和评估阶段,大规模和多样化的数据集对于基于深度学习的方法至关重要。我们在表2中根据数据量data amount、受试者数量data amount、模式modality/传感器sensor、环境设置environmental setup和攻击类型environmental setup总结了流行的公共FAS数据集。我们还在图3(a)和(b)中分别可视化了不同环境条件和模式下的一些样品。

从表2可以看出,早期阶段(即2010年- 2015年)大多数数据集只包含一些攻击类型(例如,打印和重播攻击)简单记录条件下(如室内场景),对于广义FAS训练和评估来说,样本的变化有限。随后,数据集的发展有三个主要趋势:1)大规模数据量。最近,CelebA-Spoof和HiFiMask数据集相继发布,分别包含60多万张图片和5万段视频,其中大部分为PAs;2)数据分布多样化。除了常见的可控室内场景下的打印和重放攻击外,近年来越来越多的新型攻击类型和复杂的记录条件被考虑在内。例如,在SiW-M中有13种细粒度的攻击类型,而HiFiMask由三种材料(透明、石膏、树脂)在六种光照条件和六种室内/室外场景下记录的3D蒙版攻击组成;3)多种模式和专用传感器。除了传统的可见RGB相机,一些最近的数据集还考虑了各种模式(如NIR,深度Depth,热Thermal和SWIR)和其他专门的传感器(如Light field camera)。所有这些先进的因素促进了FAS领域的学术研究和产业部署。

2.3 Evaluation Metrics
由于FAS系统通常关注的是bonafide和PA接受和拒绝的概念,因此被广泛使用的两个基本指标错误拒绝率(False rejection Rate, FRR)和错误接受率(False acceptance Rate, FAR)。错误接受欺骗攻击的比例定义了FAR,而FRR表示错误拒绝的真实访问的比例。FAS遵循ISO/IEC DIS 30107- 3:17标准来评估FAS系统在不同场景下的性能。在内部测试和交叉测试场景中,最常用的度量标准是总错误率(HTER)、平均错误率(EER)和曲线下面积(AUC)。HTER是通过计算FRR(错误拒绝的真实分数的比率)和FAR(错误接受的PA的比率)的平均值来确定的。EER是HTER的一个特定值,此时FAR和FRR相等。AUC表示bonafide和spoofing之间的可分离程度。
最近,ISO标准中提出的攻击呈现分类错误率(Attack Presentation Classification错误率,APCER)、Bonafide呈现分类错误率(Bonafide Presentation Classification错误率,BPCER)和平均分类错误率(Average Classification错误率,ACER)也被用于数据集内测试。BPCER和APCER分别度量攻击的真实分类错误率和攻击分类错误率。ACER是BPCER和APCER的均值,用来评估数据集内性能的可靠性。
错误拒绝率FRR
错误接受率FAR
总错误率HTER
平均错误率EER
曲线下面积AUC
攻击呈现分类错误率APCER
Bonafide呈现分类错误率BPCER
平均分类错误率ACER
2.4 Evaluation Protocols
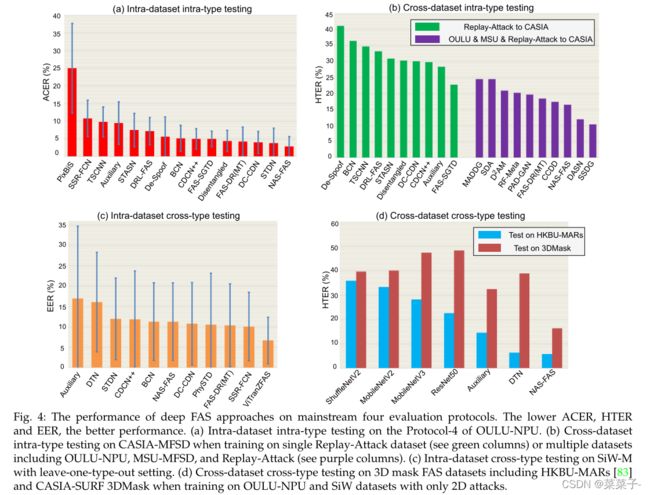
为了评估深度FAS模型的识别和泛化能力,建立了各种协议。我们在图4中总结了四种具有代表性的深度FAS方法的发展。
●Intra-Dataset Intra-Type Protocol:
数据集内类型协议被广泛应用于大多数FAS数据集,用于评估模型在具有轻微域偏移情况下的欺骗检测的识别能力。由于训练和测试数据来自相同的数据集,它们在记录环境、被试行为等方面具有相似的域分布(示例见图3(a))。最经典的数据集内类型内测试是OULU-NPU数据集的Contlic-4,该协议上最近深度FAS方法的性能比较如图4(a)所示。由于通过深度学习具有很强的辨别特征表示能力,许多方法(例如,CDCN++ 、FAS-SGTD 、Disentangled、FAS-DR(MT) 、DC-CDN 、STDN和 NASFAS )在外部环境、攻击介质和记录摄像机变化的小域变化下都达到了满意的性能(<5% ACER)。
●Cross-Dataset Intra-Type Protocol:
该协议侧重于跨数据集级别的领域泛化能力测试,通常先在一个或多个数据集(源域)上训练模型,然后在不可见的数据集(转移目标域)上进行测试。我们在图4(b)中总结了最近在两个最喜欢的跨数据集测试上的深度FAS方法。从绿色柱可以看出,在Replay-Attack训练和在CASIA-MFSD测试时,由于严重的灯光和摄像机分辨率变化,大多数深度模型表现很差(>20% HTER)。相比之下,在多源数据集(如OULU-NPU、MSU-MFSD和Replay-Attack)上训练时,基于域泛化的方法获得了可接受的性能(特别是SSDG , HTER值为10.4%)。在实际的交叉测试用例中,容易获得的目标域数据量较小,也可以利用目标域数据进行域自适应,进一步减少域偏移。
●Intra-Dataset Cross-Type Protocol:
协议采用“留下一种攻击类型”来验证模型对未知攻击类型的泛化,即有一种攻击类型只出现在测试阶段。考虑到丰富的(13种)攻击类型,本协议研究了SiW-M,结果如图4©所示。在所有攻击类型中,大多数深度模型的EER值都在10%左右,且标准差较大,这表明该协议存在巨大的挑战。得益于大规模的预训练,ViTranZFAS达到了惊人的6.7%的EER,这意味着转移学习在未知攻击类型检测中的应用前景广阔。
●Cross-Dataset Cross-Type Protocol:
尽管上面提到的三种协议模拟了现实世界应用程序中的大多数因素,但它们并不考虑最具挑战性的情况,即跨数据集跨类型测试。提出了一种“跨数据集跨类型协议”来衡量FAS模型在未知域和未知攻击类型上的泛化程度。本协议混合使用OULU-NPU和SiW(含2D攻击)进行训练,混合使用HKBU-MARs和3DMask(含3D攻击)进行测试。从图4(d)可以看出,最近的深度模型(DTN和NAS-FAS)对于HKBU-MARs上实验室控制的低保真3D掩模检测具有较好的泛化能力,但在3DMask上检测不受限制的高保真3D掩模的性能仍不令人满意。
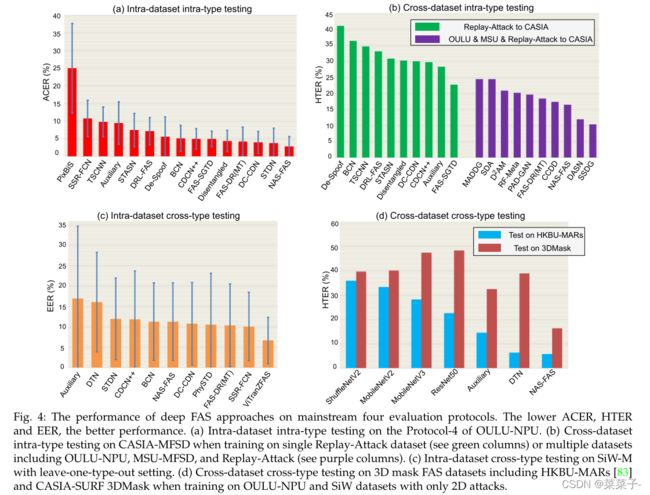
除了这四种主流评估协议外,第5节还将讨论有关实际协议设置的更多新趋势(例如,半/无监督semi-/un-supervised,现实世界的开放集 real-world open-set和动态多模态dynamic multimodality)。
3 DEEP FAS WITH COMMERCIAL RGB CAMERA
由于商用RGB相机广泛应用于现实生活中的许多应用场景(如门禁系统、移动设备解锁等),本节我们将对现有的基于深度学习的商用RGB相机FAS方法进行综述,主要分为三类:1)结合手工和深度学习特征的混合学习方法;2)常见的基于端到端监督的深度学习方法;3)将深度学习方法推广到未知领域和未知攻击类型。总结拓扑如图5的上支(蓝色部分)所示。几个里程碑式的深度FAS方法如图6所示。

3.1 Hybrid Method
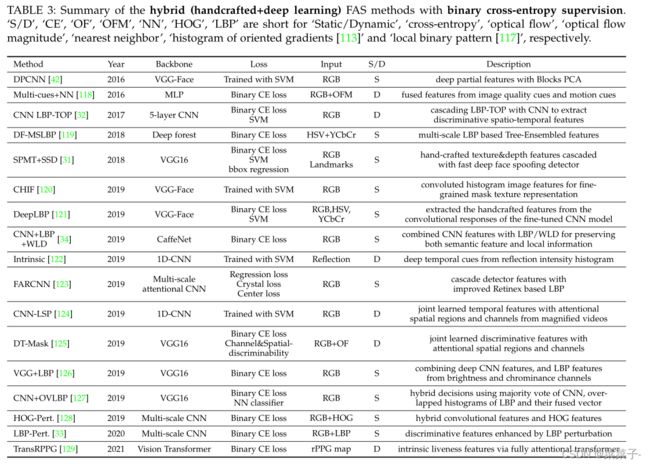
尽管深度学习和cnn在许多计算机视觉任务(如图像分类,语义分割,目标检测)中取得了很大的成功,但由于训练数据的数量有限和多样性,它们在FAS任务中存在过拟合问题。由于手工特征(如LBP、HOG描述符、图像质量、光流运动和rPPG线索)已被证明具有区分真伪和真伪的能力,最近的一些混合作品将手工特征与深度特征结合起来研究FAS。这些混合方法的典型特性如表3所示。
有些FAS方法首先从人脸输入中提取手工制作的特征,然后使用cnn进行语义特征表示(范例见图7(a))。Feng等人提出了基于剪切波的图像质量特征shearlet-based image quality features和基于密集光流的运动特征 dense opticalflow-based motion features提取,这些多线索通过多层感知器(MLP)进行集成。Cai和Chen考虑基于颜色的多尺度LBP特征进行局部纹理描述,再将其发送到级联随机森林进行深度特征表示。类似地,Khammari提取LBP和Weber local descriptor (WLD)编码的CNN特征,将这些特征组合在一起,保证了局部强度和边缘方向信息的保留。Li等从反射率图像中提取强度差分布直方图,然后利用1D CNN捕捉光照变化。Yu等从人脸视频中构建时空rPPG地图,利用全注意力视觉转换器捕捉人脸的周期性心跳活力特征。
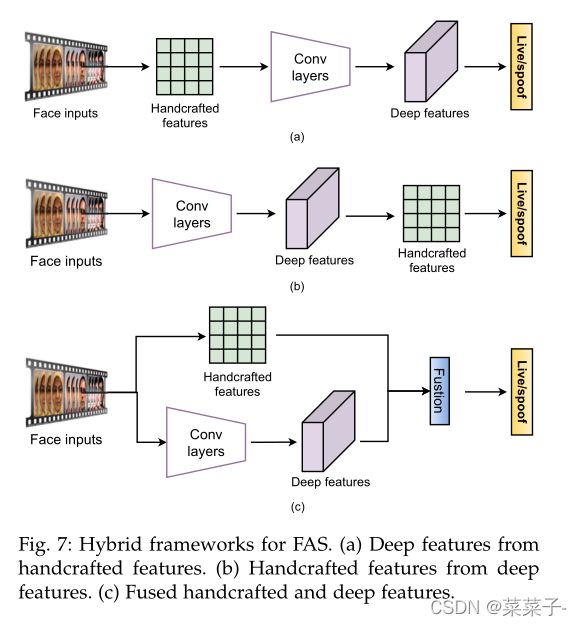
其他几种混合FAS方法从深度卷积特征中提取手工特征,遵循图7(b)所示的混合框架。Li等人从精细调优的VGG-face模型的卷积响应中提取深层特征,然后使用块主成分分析(PCA)进行降维,再进行二值分类。Li等和Agarwalet等从卷积特征映射中提取颜色LBP描述符,然后使用SVM进行live/spoof分类。除了从单个图像中捕获静态线索外,Asim等人和Shao等人分别使用LBP-TOP和光流从顺序卷积特征中提取深动态纹理特征。
如图7(C )所示,另一个最受欢迎的混合框架是融合手工和深度卷积特征,以获得更通用的表示。Li等人通过1D CNN提取强度变化特征,并使用类似的局部模式(LSP)从运动放大的人脸视频中提取运动模糊的宽度,然后在SVM分类器之前进行后期融合。Sharifi提出通过融合手工制作的局部二值模式重叠直方图(OVLBP)和深层VGG16的预测分数来检测欺骗攻击。Chen等人和Song等人提出了一个两阶段框架,该框架首先训练一个深层人脸检测器(分别是单镜头检测器(Single Shot detector, SSD)和Faster R-CNN)进行欺骗预检测,然后与手工制作的特征级联进行最终预测。Rehmana等人提出使用HOG和LBP映射对低阶卷积特征进行扰动,以实现区别表示增强。
3.2 Common Deep Learning Method
得益于先进的CNN体系结构和正则化技术的发展,以及最近发布的大规模FAS数据集,基于端到端深度学习的方法越来越受到关注,并主导了FAS领域。与混合方法不同,混合方法集成了部分手工制作的特征,但没有可学习的参数,而基于深度学习的人脸识别方法是直接学习人脸输入到欺骗检测的映射函数。常见的深度学习框架通常包括: 1)具有二元交叉熵损失binary cross-entropy loss的直接监督(见图8 (a)); 2)带辅助任务的像素级监督(见图8(b))或生成模型(见图8(c ))。
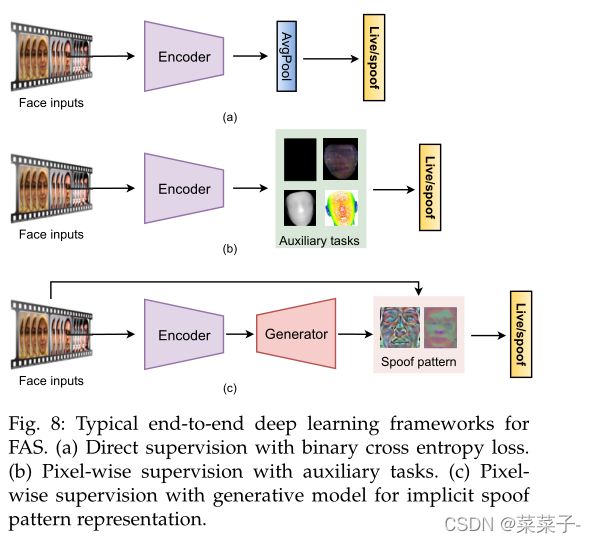
3.2.1 Direct Supervision with Binary Cross Entropy Loss
由于可以直观地将FAS视为二值(bonafide vs. PA)分类任务,许多端到端深度学习方法都直接使用二值交叉熵(CE)损失以及其他扩展损失(如三重损失triplet loss)进行监督,如表4所示。
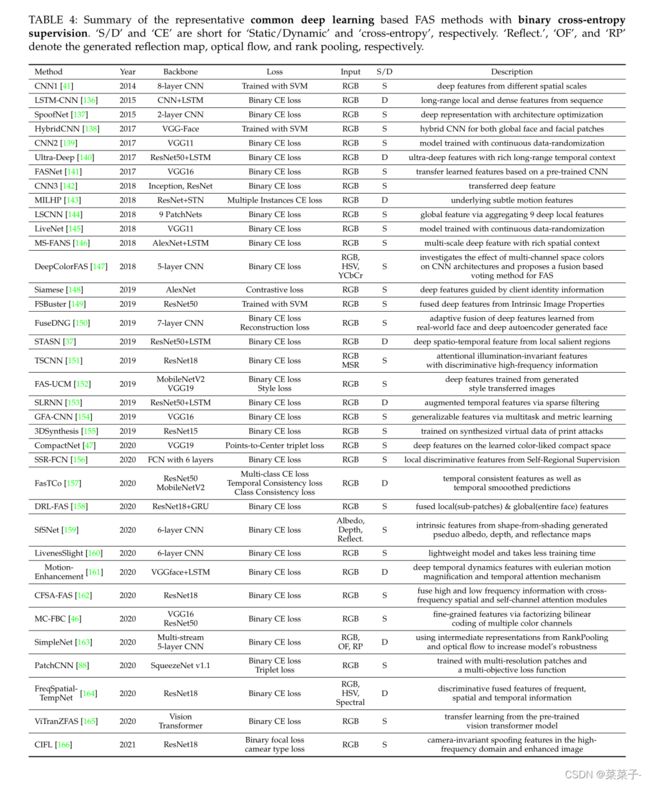
一方面,研究人员提出了各种由二进制CE损失监督的FAS网络结构。Yang et al.提出了第一个使用8层浅层CNN进行特征表示的端到端深度FAS方法。随后,在ImageNet上对FAS模型进行预训练被广泛用于缓解过拟合问题。Lucena等人和Chen等人对预先训练的VGG16和ResNet18 FAS模型进行微调。Deb和Jain提出使用全卷积网络(FCN)以自我监督的方式从人脸图像中学习局部判别线索。一些工作也考虑轻量级的移动级网络(例如,MobileNetV2)来有效的FAS。除了cnn, George和Marcel还利用预训练的视觉变压器来实现端到端FAS。根据bonafide和PAs之间的动态差异,有几篇论文利用长短时记忆(Long - Short Term Memory, LSTM)级联帧级CNN特征对时间线索进行聚合。
另一方面,也有一些关于修改二进制CE损失的研究,以提供更有鉴别性的监控信号。Xu等人没有使用二元约束,而是将FAS重新定义为细粒度的分类问题,并使用视频类型的标签(如打印和重播)进行多类监督。Hao和Almeida等分别在FAS中引入对比损失和三重损失来增强深度嵌入特征的识别。Li等人提出了一种点到中心的三态丢失来学习类内距离小、类间距离大、bonafide和PAs之间有安全间隔的紧致空间。Chen等人采用二元焦损耗来引导模型较好地区分硬样例,并增加了live/spoof样本之间的距离。
3.2.2 Pixel-wise Supervision
由二进制损失直接监督的深层模型可能很容易学习不准确的模式(如屏幕边框)。相比之下,像素级的监督可以提供更细粒度和上下文任务相关的线索,从而更好地学习内在特征。一方面,基于物理线索和判别设计理念,开发了伪深度标签pseudo depth labels、二进制掩码标签binary mask label和反射映射reflection maps等辅助监督信号,用于局部live/spoof线索描述;另一方面,具有显式像素监督的生成模型generative models with explicit pixel-wise supervision(例如,原始人脸输入重建original face input reconstruction)最近用于通用欺骗模式估计。我们在表5中总结了具有代表性的像素化监督方法。
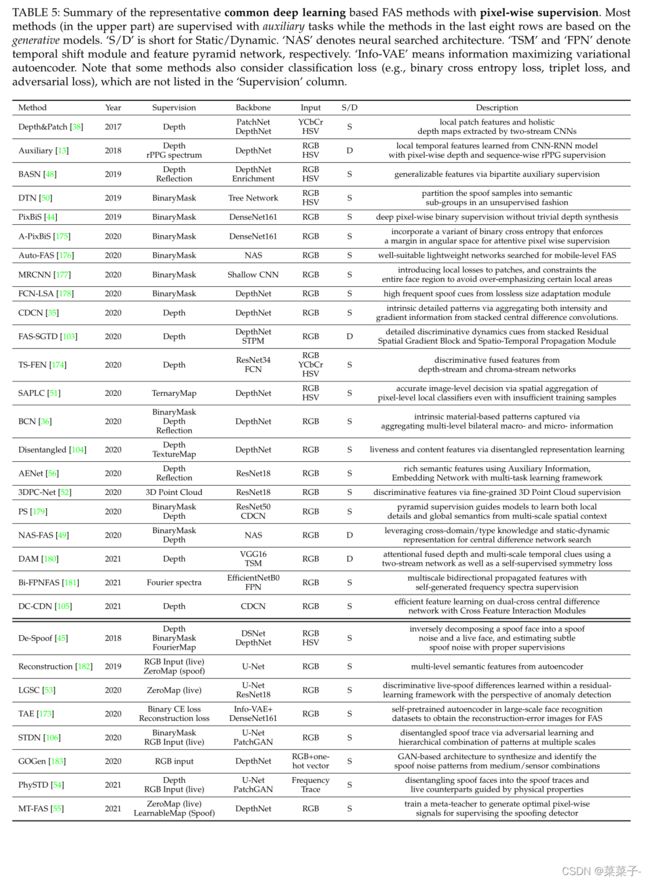
Pixel-wise supervision with Auxiliary Task
根据人类对FAS的先验知识,大多数PAs(如普通的印刷纸和电子屏幕)没有真正的人脸深度信息,可以作为判别监督信号。因此,最近的一些作品采用像素级的伪深度标签来引导深度模型,强制它们预测实时样本的真实深度,而对欺骗样本的零映射。Atoum等人的首先利用伪深度标签来指导多尺度的FCN(为简单起见,即“depthnet”)。因此,训练有素的DepthNet能够预测整体深度图,作为决策证据。Wang等人基于生成的伪深度标签,设计了一种用于挖掘细粒度局部深度线索的对比深度损失(对比度深度损失,CDL),该方法也被应用于训练中心差分卷积网络(CDCN)。同样,Peng等人将深度监督流与另一种颜色(RGB、HSV、YCbCr)流融合,以获得更鲁棒的表示。
每个训练样本的三维形状标签合成成本高且不够准确,这也缺乏具有真实深度的PAs(如3D面具和人体模型)的合理性。相比之下,二进制掩码标签更容易生成,且对所有PAs更具有通用性。具体来说,对每个空间位置的深度嵌入特征进行二元监督。换句话说,通过二进制掩码标签,我们可以发现pa是否出现在相应的补丁中,这是攻击类型不可知的,在空间上是可解释的。George和Marcel是第一个引入深度像素级二进制监督来预测级联最终二进制分类的中间置信图的人。类似地,Liu等人使用二值分类和逐像素掩模回归对叶节点进行约束。Hossaind等提出在计算深度像素级二进制损耗之前,增加一个注意模块来进行特征细化。Yu等人使用像素级二进制监督搜索轻量级FAS架构。Liu等人利用带有像素级二进制监督的Early Spoof Regressor来增强生成器的鉴别性。Ma等提出了一种对局部patch具有局部二值分类损失的多区域CNN。
除了主流的深度图和二元掩模标签外,还有几种信息辅助监督(如伪反射图、3D点云图、三元图、傅立叶谱)。根据活性皮肤和欺骗介质与面部材料相关反照率的差异,Kim等人建议使用深度和反射标签来监督深层模型。此外,Yu等人利用多个像素级监督(二进制掩码、反射图和深度图)同时训练双边卷积网络。同样,Zhang等人采用伪反射和深度标签引导网络学习丰富的语义特征。与考虑所有空间位置的二进制掩模标签不同,Sun等人删除了与面部无关的部分,并将整个面部区域保留为称为"三元映射"的精细二进制掩码,从而消除了面部外的噪声。为了减少密集深度图的冗余,Li等人使用稀疏的3D点云图来有效地监督轻量级模型。此外,带有傅里叶贴图和LBP纹理贴图的其他辅助监督的深度模型也显示出其出色的表示能力。
Pixel-wise Supervision with Generative Model
尽管在辅助任务中存在细粒度的监督信号,但仍难以理解深层黑箱模型是否代表内在的FAS特征。最近,一个热门的趋势是挖掘欺骗样本中存在的视觉欺骗模式,旨在提供一个更直观的解释样本的欺骗性。我们在表5的下半部分用像素级监督总结了这种生成模型。Jourabloo等人的是第一个将FAS重新定义为欺骗噪声建模问题的人,并使用一种编码器-解码器架构,通过有意义的像素级监督来估计潜在的欺骗模式(例如,对活人脸的噪声映射进行零映射)。Chen等人提出使用基于U-Net的自动编码器对活样本进行原始图像重构,对欺骗样本进行零映射。Feng et al.提出了一个由欺骗线索发生器和辅助分类器组成的联合框架。该生成器最小化了活样本的欺骗线索,而对欺骗样本的欺骗线索没有明确的约束。Mohammadi等人利用大规模的人脸识别数据集对自动编码器进行预处理,重构人脸,然后利用该自动编码器输出的重构误差图像进行欺骗检测。Liu等人采用对抗学习框架将欺骗人脸分解为欺骗轨迹和实时对应对象。该欺骗痕迹生成器解开若干恶搞痕迹元素,如添加组件(如云纹图案)和内画组件(如欺骗覆盖区域)。Stehouwer等人利用基于GAN的架构来生成具有记录传感器和演示仪器的不同组合的欺骗样本,然后级联CNN以进行传感器和介质识别。
除了直接的欺骗模式生成,Qin等人提出通过元教师框架自动生成像素级标签,该框架能够为学生FAS模型提供更合适的监督,以学习充分和内在的欺骗线索。然而,[55]中只生成可学习的spoof supervision。因此,如何在实时采样和欺骗采样中自动生成最优的像素级信号仍是一个值得探讨的问题。
3.3 Generalized Deep Learning Method
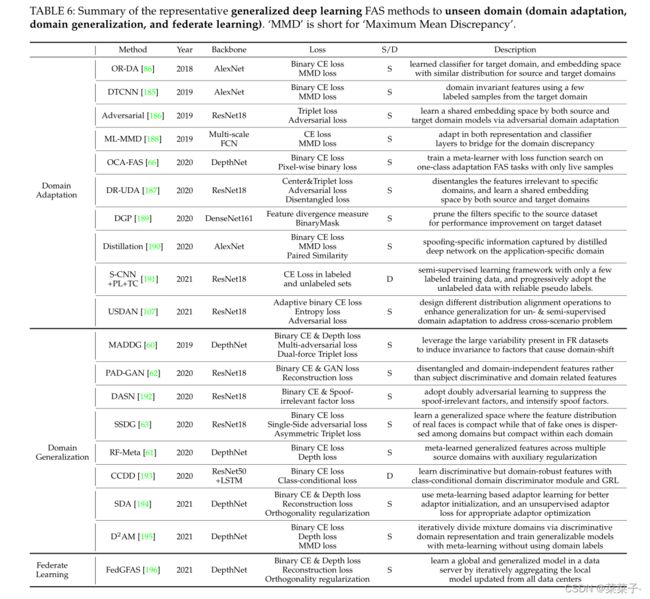
常见的基于端到端深度学习的FAS方法在不可见的主导条件(如光照、面部外观和相机质量)和未知的攻击类型(如新材料制作的高保真面具)上可能泛化较差。因此,这些方法在安全需求较强的实际应用中是不可靠的。有鉴于此,越来越多的研究者关注于提高深度FAS模型的泛化能力。一方面,领域自适应和泛化技术domain adaptation and generalization techniques被用来在无限的领域变化下实现鲁棒的live/spoof分类。另一方面,采用零样本/少样本学习和异常检测框架对未知人脸PA类型进行检测。表6和表7分别总结了在未知域和未知攻击类型上具有代表性的广义深度FAS方法。
3.3.1 Generalization to Unseen Domain
如图9所示,源域和目标域之间存在严重的域偏移,直接对源数据集(如OULU-NPU、casa - mfsd、Replay-Attack)进行深度模型训练时,容易导致在有偏的目标数据集(如MSU-MFSD)上的性能较差。领域自适应技术利用目标领域的知识来弥补源领域和目标领域之间的差距。相比之下,域泛化有助于直接从多个源域学习广义特征表示,而无需访问任何目标数据,这对于实际部署更实用。考虑到训练数据通常不会在数据所有者(域)之间直接共享的法律和隐私问题,在学习广义FAS模型的同时,引入联邦学习框架来保护数据隐私。
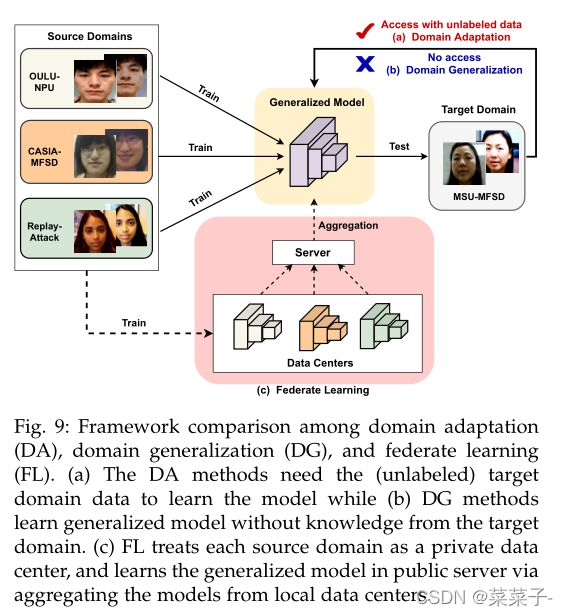
Domain Adaptation
域自适应技术缓解了源域和目标域之间的差异。在大多数方法中,源和目标特征的分布是在一个学习过的特征空间中匹配的。如果特征具有相似的分布,则对源样本的特征进行训练的分类器也可以用于对目标live/spoof样本进行分类。Li等人提出了无监督域自适应,通过学习映射函数,通过最小化源域数据和目标域数据之间的PCA嵌入特征空间。同样,Tu等采用基于核的MMD作为域损耗项,测量源和目标域的分布距离。在另一篇论文中,为使源和目标域编码器共同优化,获得源和目标域共有的特征空间,提出了无监督对抗域自适应的UDA-Net。与之前只对最后的分类器层进行适配不同,[188]的作者在表示层和分类器层上都考虑了多层适配。Mohammadi等人提出将特征发散度高的滤波器从一个数据集到另一个数据集不能很好地泛化,从而提高网络在目标数据集上的性能。Li等人提出从训练有素的教师网络中提取特定应用领域的深度模型,该模型通过特征MMD和来自两个领域的成对样本相似度嵌入进行正则化。Quan等提出了一种半监督学习FAS方法,该方法仅使用少量已标记的训练数据进行训练前处理,在训练过程中逐步采用可靠的未标记数据,丰富训练数据的多样性,减少领域差距。Jia等人通过跨源域和目标域的边缘和条件分布对齐,提出了一种具有域不变特征空间的统一的无监督和半监督域自适应网络。
虽然领域自适应有利于利用无标记目标数据最小化源域和目标域之间的分布差异,但在许多现实的FAS场景中,收集大量无标记目标数据(特别是欺骗攻击)用于训练是困难和昂贵的。
Domain Generalization
域泛化假设在可见的多个源域和未见过但相关的目标域下存在一个广义特征空间,在此空间上,从可见的源域中学习的模型可以很好地推广到看不见的目标领域。Shao等人提出在双力三重挖掘约束和辅助人脸深度监督下,通过多对抗判别域概化框架学习多个源域共享的广义特征空间。Wang等人提出将广义FAS特征从主体判别特征和域依赖特征中分离出来。类似地,在[192]中,通过学习有效地抑制欺骗相关因素(如相机传感器和照明),可以提高对不可见域的泛化能力。Jia等考虑到不同域的欺骗人脸之间分布差异较大,提出学习广义特征空间,真实人脸的特征分布紧凑,而假人脸的特征分布分散在域之间,但在每个域内紧凑。Shao等人提出在具有丰富领域知识(如辅助深度)的细粒度元学习过程中,通过寻找广义学习方向来正则化模型。[194]的作者使用域适配器扩展了基于元学习的域泛化方法,以在推理时利用未标记的目标域数据。Chen等人在没有使用域标签的情况下,提出了一种使用域动态调整元学习训练广义FAS模型的方法,该方法通过有区别的域表示迭代划分混合域。
综上所述,领域概化是近两年来FAS研究的新热点,研究了领域概化与自适应相结合、无领域标签学习等一些潜在且令人兴奋的趋势。然而,仍然缺乏揭开歧视和普遍化能力面纱的作品。换句话说,域泛化有利于 FAS 模型在看不见的领域中表现良好,但目前还不清楚它是否会在可见的场景中恶化欺骗检测的辨别能力。
Federate Learning
对不同分布和不同类型的人脸图像进行训练可以得到广义的FAS模型。在现实中,由于法律和隐私问题,训练人脸数据不会在数据所有者之间直接共享。为了应对这一挑战,FAS引入了联邦学习,这是一种分布式和隐私保护的机器学习技术,在保持数据隐私的同时,利用不同数据所有者提供的丰富的实时/欺骗信息。具体来说,每个数据中心/所有者在本地训练自己的FAS模型。然后,服务器通过迭代聚合所有数据中心的模型更新来学习全局FAS模型,而不访问每个数据中心的原始私有数据。最后,利用融合的全局FAS模型进行推理。为了增强sever模型的泛化能力,[196]提出了一种联邦域解纠缠策略,将每个数据中心视为一个域,将FAS模型分解为每个数据中心的域不变部分和域特定部分。
联邦学习的目的是解决数据集的隐私问题。但是它忽略了FAS模型层面的隐私问题,因为全局模型的训练需要多个团队共享各自的本地模型,这可能会损害商业竞争。
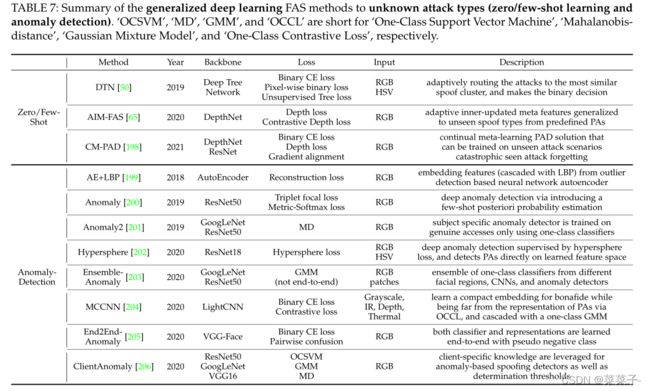
3.3.2 Generalization to Unknown Attack Types
除了领域转移问题外,在实际应用中,FAS模型也容易受到新出现的PAs的影响。以往的深度学习方法大多将FAS表述为一个紧密集合的问题来检测各种预定义的PAs,这需要大量的训练数据来覆盖尽可能多的攻击。然而,经过训练的模型可以很容易地过拟合几种常见的攻击(例如,打印和重播),并且仍然容易受到未知攻击类型(例如,面具和化妆)的攻击。目前,针对未知欺骗攻击检测的研究主要集中在广义FAS模型的开发上。一方面,在目标攻击类型样本很少或甚至没有样本的情况下,采用零/少样本学习方法来改进新型欺骗检测。另一方面,也可以将FAS视为一类分类任务,将真实样本紧密地聚在一起,用异常检测来检测非分布的PA样本。
Zero/Few-Shot Learning
一种新的攻击检测方法是用足够的新攻击样本来调整FAS模型。然而,由于欺骗不断发展,为每一次新的攻击收集标记数据是昂贵和耗时的。为了克服这一挑战,一些学者提出将FAS视为一个开放集零和少样本学习问题。零样本学习的目的是从预定义的PA中学习广义和判别特征,用于未知的新型PA检测。少样本学习的目的是通过学习预定义的PAs和收集到的很少的新攻击样本,使FAS模型快速适应新的攻击。
Liu等人设计了一种深度树网络(Deep Tree Network, DTN)来学习预定义攻击的语义属性,并以无监督的方式将欺骗样本划分为语义子组。DTN自适应地将已知或未知PAs路由到最相似的欺骗集群,并做出二进制决策。Qin等人通过使用自适应内更新学习速度策略融合训练元学习者,将样本头和少样本的FAS任务统一在一起。对元学习者进行零样本和少样本任务的训练,同时提高了预定义PAs和新PAs的识别能力和泛化能力。然而,直接在新攻击中使用少样本元学习很容易导致对预定义PAs的灾难性遗忘。为了解决这一问题,Perez-Cabo等人提出了一种连续少样本学习范式,该范式从连续的数据流中逐步扩展获得的知识,并通过元学习解决方案使用少量训练样本检测新的PAs。
虽然少样本学习有利于FAS模型对未知攻击的检测,但当目标攻击类型的数据不可适应(即零样本情况)时,性能明显下降。我们观察到,检测失败通常发生在具有挑战性的攻击类型(如透明面具、搞笑眼、化妆等),这些攻击类型的外表分布与真伪相似。
Anomaly Detection
FAS异常检测假设活样本的特征表示更相似、更紧凑,属于正常类,而欺骗样本的特征由于攻击类型和攻击材料的高方差,在异常样本空间中分布差异较大。基于此假设,异常检测通常首先训练一个可靠的一类分类器,对活样本进行准确的聚类。然后,在活动样本簇边缘之外的任何样本(如未知攻击)都将被检测为攻击。
Arashloo等人首先引入了FAS的异常检测。他们在跨类型测试协议上评估了20个不同的一类和二类系统,并证明了基于异常的方法并不比二元分类方法差。Nikisins等提出提取Image Quality Measures (IMQ)特征,然后使用高斯混合模型(GMM)作为一类分类器来预测活样本的概率分布。Xiong和AbdAlmageed提出了一种基于LBP特征提取器的基于单类支持向量机和自动编码器的离群点检测算法,用于开集未知PA检测。Fatemifar等人提出使用深度CNN表示来训练一类特定于客户的分类器,并基于特定于主题的得分分布为每个客户设置一个不同的阈值来进行推理决策。Baweja等人提出了一种端到端异常检测方法,将一类分类器和特征表示与原始真实类和伪负类一起训练。
一些作品不仅使用实时样本,还通过度量学习,使用实时样本和欺骗样本来训练广义异常检测系统。Pérez-Cabo等人提出通过三重态焦点丢失来正则化FAS模型,以学习判别特征表示,然后引入少数镜头后验概率估计以进行未知攻击检测。Li等人提出用一种新颖的超球损失函数来监督深度FAS模型,以保持活样本的类内紧凑性,而活样本和欺骗样本的类间分离。未知攻击可以在学习后的特征空间中直接检测出来,而不需要额外的分类器。George和Marcel设计了一种一类对比损失(OCCL),迫使网络在远离攻击表征的情况下学习一种紧凑的真实类嵌入。然后将一类GMM级联,用于检测新的攻击类型。
尽管基于异常检测的FAS方法对未知攻击检测具有泛化能力,但在现实开放集场景(即已知和未知攻击)中,与传统的live/spoof分类相比,基于异常检测的FAS方法的识别能力会下降。
4 DEEP FAS WITH ADVANCED SENSOR
就日常人脸识别应用(如移动解锁和区域访问控制)的安全性和硬件成本而言,基于商用RGB摄像头的FAS将是一个很好的折衷解决方案。然而,一些高安全性的场景(人脸支付和保险库入口警卫)要求非常低的错误接收错误。最近,各种模式的先进传感器被开发出来,以促进超声固定FAS。表8列出了各种用于FAS的传感器和硬件模块在环境条件(光照和距离)和攻击类型(打印、回放和3D掩模)方面的优缺点。

与单眼可见RGB相机(VIS)相比,立体相机(VIS- stereo)有利于二维欺骗检测的三维几何信息重建。当VIS-Flash与动态闪光灯装配在演示人脸上时,[209]能够捕捉基于内在反射的材料线索来检测所有三种攻击类型。
除了可见的RGB模式外,深度和近红外模式在实际的FAS部署中也被广泛使用,成本可接受。飞行时间(Time of Flight, TOF)和三维结构光(3D Structured Light, SL)两种深度传感器已嵌入主流手机平台(如Iphone、三星、OPPO、华为)。它们为二维欺骗检测提供了精确的人脸三维深度分布。与SL相比,TOF对光照和距离等环境条件更有鲁棒性。相比之下,近红外模态是除VIS外的一种互补光谱(900 ~ 1800nm),它有效地利用了真实人脸和欺骗人脸之间的反射差异,但在远距离成像质量较差。此外,VIS-NIR集成硬件模块对于许多门禁系统具有很高的性价比。
同时,还介绍了几种有效的传感器。短波红外(SWIR),波长为940nm和1450nm,通过测量水分吸收来区分人脸图像中的活皮肤材料和非皮肤像素,对一般的欺骗攻击检测是可靠的。热成像相机是一种通过面部温度估计来实现高效FAS的替代传感器。然而,当受试者戴上透明口罩时,它的表现就不佳了。昂贵的光场相机和四向偏振传感器分别根据其对面部深度和反射/折射光的出色表示,探索了FAS。
4.1 Uni-Modal Deep Learning upon Specialized Sensor
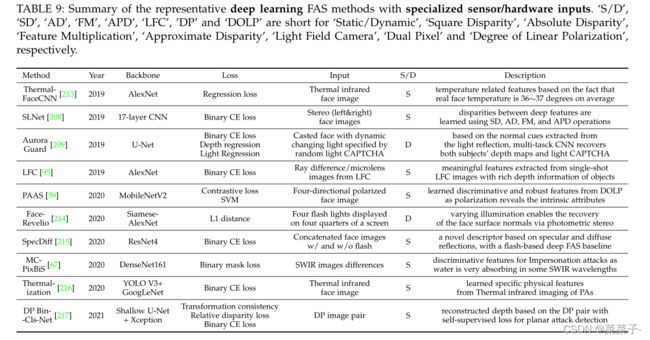
基于专为不同成像的传感器/硬件,研究人员开发了传感器感知的高效FAS深度学习方法,总结如表9所示。Seo和Chung提出了一种轻量级的Thermal FaceCNN,从热图像中估计面部温度,并检测温度异常(如温度超出范围36到37度)的欺骗。他们发现热图像比RGB图像更适合于重放攻击检测。Rehman等人在CNN中引入视差层来提取基于Stereo的FAS的动态视差图,提高了CNN对未知类型人脸PA的性能和鲁棒性。相比之下,Wu等人提出了一种使用双像素(DP)传感器图像的简单而鲁棒的FAS方法,与基于立体的方案相比,该方法获得了更好的FAS性能。其中,DP图像对深度图生成采用FCN, live/spoof分类采用Xception网络。Liu等人提出从单镜头光场相机中提取光线差和微镜头图像,然后使用一个浅层CNN进行人脸PAD。由于光场成像中具有丰富的三维信息,该方法具有分类细粒度欺骗类型的潜力。Tian et al.提出了一种使用片上集成极化成像传感器的实时FAS方法,该方法将DOLP图像传输到轻量级的MobileNetV2上,用于广义面部PAD。在[67]中,仅通过精心选择SWIR图像差异作为输入,Multi-Channel CNN能够几乎完美地检测出所有的模拟攻击,同时保证低的真实分类错误。
除了使用专用的硬件,如红外点投影仪和专用摄像机,一些深度FAS方法是基于带有额外环境闪光的可见摄像机开发的。在[209]和[214]中,利用智能手机屏幕上的动态闪光从多个方向照亮用户的脸,从而实现通过光度立体视觉恢复人脸表面法线。然后将这些动态的正常线索输入CNN,预测面部深度和轻CAPTCHA,进行PA检测。类似地,Ebihara等人设计了一种新颖的描述符来表示镜面反射和漫反射,利用了有flash和没有flash输入的不同提示,其性能优于端到端ResNet的连接flash输入。
4.2 Multi-Modal Deep Learning
随着硬件制造和集成技术的发展,具有可接受成本的多模态FAS系统在实际应用中得到了越来越多的应用。与此同时,基于多模态深度学习的方法成为FAS研究领域的热点。表10收集了具有代表性的多模态融合和跨模态翻译方法。

Multi-Modal Fusion
主流的多模态FAS方法主要集中在特征级融合策略上。Zhang et al.提出了SD-Net,该网络使用了一种特征重加权机制,在RGB、深度和近红外模式之间选择信息通道特征。[222]和[221]的作者在SD-Net的基础上引入了一个多模态多层融合分支,进一步增强了模式之间的语境线索。除了模式间的信道加权外,Wang等在特征融合前提出了每个模式分支的空间和信道注意模块,以增强对个体模式特征的识别。Shen等采用patch-level输入的CNN提取欺骗特异性的判别特征,并对多模态特征设计了模态特征擦除(Modal Feature Erasing)操作,以防止过拟合和更好的融合。Liu等人提出了一种适用于每个模态的静态-动态融合机制,以及一种部分共享的融合策略来学习模态之间的互补特征。George和Marcel提出了一种跨模态焦点损耗来调节各模态的损耗贡献,这有利于学习模态之间的互补信息,同时减少过拟合的影响。
与上述使用特征级融合的方法不同,很少有研究考虑输入级和决策级融合。在[223]和[226]中,通过叠加归一化的图像,从灰度、深度和近红外模式融合合成图像,然后馈送到深PA探测器。Liu等人构建了一个两阶段级联框架,分别从多重预处理深度输入(即归一化、尺度嵌入和方向嵌入)和复合可见-近红外输入(即堆栈、求和和差分)来表示基于深度和反照率的特征。Yu等人提出从RGB、深度和近红外模式融合单个模型的预测二进制分数,该方法优于CeFA数据集上的输入和特征级融合。Zhang等人设计了一种具有集成和级联的决策级融合策略。首先,将几个训练良好的深度模型的评分进行聚合,然后与IR模型的评分进行级联,最终进行live/spoof分类。
Cross-Modal Translation
多模态FAS系统需要额外的传感器来成像不同模式的人脸输入。然而,在一些传统的场景中,只有部分模式(如RGB)可以使用。为了解决推理阶段的模态缺失问题,一些作品采用跨模态转换技术为多模态FAS生成缺失模态数据。蒋等首先提出了一种新颖的多类别(实时/欺骗,真实/合成)image translation cycle-GAN,为RGB人脸图像生成相应的NIR图像,然后从RGB的堆叠输入中学习融合特征,并为FAS生成NIR图像。Liu等人遵循类似的跨模态转换框架,具有新颖的基于子空间的模态正则化,以从源RGB输入生成高保真目标NIR模态。Mallat和Dugelay提出了一种可见到热转换方案,使用级联细化网络合成来自RGB面部图像的热攻击。一个主要问题是域转移和未知攻击可能会显著影响生成的模态的质量。
尽管自2019年以来,多模态FAS呈上升趋势,但与基于RGB的方法相比,其进展仍然缓慢。与此同时,一些先进的传感器(如SWIR、光场和偏振)价格昂贵,在现实世界部署时不可携带。应该探索更高效的FAS专用传感器以及多模态方法。
5 DISCUSSION AND FUTURE DIRECTIONS
由于最近在深度学习方面的进展,FAS在过去几年里得到了快速的改善。在此,我们讨论了当前发展的局限性,并总结了一些潜在的研究方向。
5.1 Architecture, Supervision and Interpretability
从第3节和第4节可以看出,对于深度FAS,大多数研究人员选择的是现成的网络架构和手工制作的监督信号,这可能是次优的,难以充分利用大规模的训练数据。虽然最近的一些研究已经将AutoML应用于FAS中,用于搜索非常适合的体系结构损失函数和辅助监督,但它们关注的是单模态和单帧配置,而忽略了时间或多模态情况。因此,一个很有前途的方向是自动搜索和找到最适合多模式使用的时态架构。这样,就可以在形态中发现更合理的融合策略,而不是粗糙的手工设计。此外,在动态监控设计中应考虑丰富的时间背景,而不是静态的二进制或像素级监控。
另一方面,设计高效的网络体系结构对于实现移动设备的实时FAS至关重要。在过去的一年中,大多数研究集中在解决FAS的准确性和泛化问题上,只有少数研究考虑轻量级或提炼CNNs以实现高效部署。除了有很强的归纳偏见的CNN,研究人员还应该在效率和计算成本方面重新考虑一些灵活的架构(如视觉转换器)的使用。
近年来,可解释性FAS的研究取得了很大进展。一些方法尝试使用可视解释工具(如grade - cam)或软选通策略,根据特征激活来定位欺骗区域。此外,辅助监督和生成FAS模型用于估计底层的欺骗映射。所有这些试验都有助于理解和定位欺骗模式,并说服FAS的决定。然而,由于缺乏宝贵的像素级欺骗注释,估计的欺骗映射仍然粗糙,容易受到不准确线索(如手)的影响。更先进的特征可视化方式feature visualization manners和细粒度的像素欺骗分割fine-grained pixel-wise spoof segmentation应发展为可解释的FAS interpretable FAS。
5.2 Representation Learning
学习识别和内在特征表示是可靠的FAS的关键。之前的一些研究已经证明了迁移学习transfer learning和解纠缠学习disentangled learning对FAS的有效性。前者利用从其他大规模数据集中预先训练的语义特征来缓解过拟合问题,而后者旨在从噪声表示中分离出固有的欺骗线索intrinsic spoofing。此外,将FAS重新定义为细粒度识别问题来学习类型区分表示是值得探索的,这是受到人类可以通过识别特定攻击类型来检测欺骗这一事实的启发。
研究人员还应该充分利用真实/欺骗训练数据,无论是否带有增强表示的标签。一方面,对大规模的组合数据集进行自我监督可以降低过拟合的风险,积极挖掘内在知识(如人脸内部斑块之间的高度相似性)。另一方面,在现实场景中,从各种人脸识别终端连续采集日常未标记的人脸数据,可用于半监督学习。一个挑战是如何充分利用未标记的不平衡(即,live>>spoof)数据,避免意外的性能下降。此外,对于FAS合适的数据增强策略鲜有研究。对抗学习可能是一个很好的选择自适应数据增强在更多样化的领域。
5.3 Real-World Open-Set FAS
如2.4节所述,传统的FAS评估协议通常在一个或几个小规模数据集中考虑域内、跨域和跨类型测试。这些协议中最先进的方法不能保证在实际场景中始终保持良好的性能,因为 1)数据量(特别是测试集)相对较小,因此高性能不是非常令人信服; 2)协议集中于单一因素(例如,可见/不可见域或已知/未知攻击类型),不能满足复杂的现实场景的需要。最近,更实用的协议如GrandTest和open-set被提出。GrandTest包含大规模的混合域数据large-scale mixed-domain data,而open-set testing考虑了模型对已知和未知攻击类型的识别和泛化能力。然而,现实世界中具有同时域simultaneous domains和攻击类型的开放集情况仍然被忽视。应该探索更全面的协议(例如,领域和类型感知的开放集domain- and type-aware open-set来进行公平和实用的评估,以弥合学术界和工业界之间的差距。
至于多模式协议,假设具有多种模式的训练数据可用并且两种测试设置被广泛使用:1)具有相应的多种模式 2) 仅单一模式(通常为 RGB)。但是,根据不同的用户终端设备,在实际部署中存在各种模态组合(例如,RGB-NIR、RGB-D、NIR-D 和 RGB-D-NIR)。因此,为每个多模态组合训练单个模型是非常昂贵和低效的。虽然可以通过跨模态转换生成伪模态,但与真实世界的传感器相比,伪模态的保真度和稳定性仍然较弱。设计一个动态多模态框架,将学习到的多模态知识传播到各种模态组合中,是实现无限多模态部署的一个可能方向。
5.4 Generic and Unified PA Detection
通过其他相关任务(如通用PAD和数字人脸攻击检测)了解人脸PAD的本质属性对可解释的FAS很重要。一方面,“通用”假设人脸和其他对象表示攻击都可能有独立的内容,但共享固有的欺骗模式。例如,对不同物体(如脸和足球)的重放攻击是由相同的玻璃材料制作的,并带有异常的反射线索。因此,通用的PAD和材料识别数据集可以在人脸PAD中引入,以多任务学习方式实现常见的live/spoof特征表示。
除了常见的pa外,通用PAD还应考虑两种物理对抗攻击(AFR-aware and FAS-aware)。如图10所示,攻击者可以打印并佩戴对抗生成器获得的物理眼镜和帽子,或包含特征模式的特殊贴纸,这些特征模式被证明对基于深度学习的AFR系统有效。此外,眼睛区域附近的难以察觉的化妆已被证实可用于攻击商用AFR系统。除了感知afr的对抗攻击外,对抗打印/重播攻击在物理广播之前使用扰动来欺骗FAS系统。因此,需要建立具有多种物理对抗攻击和标注攻击定位标签的大规模FAS数据集。

另一方面,除了面部呈现的物理攻击外,还有许多针对面部视频的恶意数字操作攻击(如Deepfake)。尽管生成方式和视觉质量不同,但这些攻击的某些部分可能仍然具有一致性。在[243]中,提出了一个统一的数字和物理人脸攻击检测框架,以学习联合表征进行相干攻击。然而,由于数据收集成本的原因,数字攻击和物理攻击在数量上存在严重的不平衡。换句话说,与高成本的表示攻击high-cost presentation attacks相比,更容易产生大规模的数字攻击large-scale digital attacks。这种不平衡的分布可能会损害多任务学习过程中的数字/物理内在表征digital/physical intrinsic representation,这需要在未来进行思考。
6 CONCLUSION
本文介绍了基于深度学习的方法、数据集以及人脸抗欺骗(FAS)协议的当代研究。对这些方法进行了全面的分类。介绍了各种FAS检测方法和传感器的优缺点,并提出了可能的研究方向。